vault backup: 2023-05-15 09:42:13
This commit is contained in:
@@ -0,0 +1,408 @@
|
||||
---
|
||||
title: 30 Git CLI options you should know about
|
||||
updated: 2019-02-26 11:45:37Z
|
||||
created: 2019-02-26 11:26:19Z
|
||||
tags:
|
||||
- Development/Git
|
||||
- Development/Shell
|
||||
---
|
||||
|
||||
|
||||
# 30 Git CLI options you should know about
|
||||
|
||||
You think you know Git? Maybe you do… And yet, I’d bet my shirt that many cool little command-line options remain unknown to you.
|
||||
|
||||
Indeed, as Git versions march on, a lot of such options surface, be it about more comfort, more raw power, or additional safeguards. As they are not a new command per se though, they are usually not touted as much and go under your radar.
|
||||
|
||||
I selected here about thirty options, spread across roughly fifteen commands, that will make your Git life more enjoyable. This makes for an excellent ROI over your next few minutes of reading!
|
||||
|
||||
I will generally put the option right in the section title, intentionally. Still, do not skip a section because you think you know that option: I may use it on another command than the one you think, or for another reason, that may be news to you. Also, I often slap on extra info on associated options and configuration variables.
|
||||
|
||||
(by the way, the French version of this is on Git Attitude, as per usual)
|
||||
|
||||
## Partial (un)staging with -p
|
||||
|
||||
So you opened a file for a specific reason, perhaps make that damned tracker asynchronous… And you notice in passing that ARIAL roles are missing from a few UX items, and that the footer is still hard-coded instead of coming from the layout, and what not…
|
||||
|
||||
When you’re about to commit, you realize that file contains a solid half-dozen (if not more) edits that span multiple unrelated topics. You then have three possible routes:
|
||||
|
||||
|
||||
- You spew a big fat ugly kitchen-sink commit, complete with a lousy message full of “+” signs or, if you’re even lazier, the time-honored useless “Changes,” “Fixes,” “Lots of stuff,” etc.
|
||||
- You copy-paste the file somewhere then start undo-ing, if that’s even possible, to only keep the first top, commit, re-apply changes for the second, commit again, then the third… All of this by hand, naturally. Screw-up probability: 99%.
|
||||
- You read this, or attend our training classes, and now -p !
|
||||
|
||||
The git add -p command is actually a refinement of git add -i: it pre-selects the interactive add patch mode. In practice, you tell it what file you want to operate on, to go even faster. For instance:
|
||||
|
||||
```shell
|
||||
git add -p index.html
|
||||
```
|
||||
|
||||
Let me seize that opportunity to remind you that git add is not about putting a file under version control, but to stage an edit, that is, to confirm that edit as a part of the next commit.
|
||||
|
||||
When you perform such an add, Git will auto-split the content in hunks, which are groups of edits, using proximity inside the file, and unchanged lines for splitting. If your edits are too close together, Git will probably not auto-split, and you’ll have to do it yourself using the s key (Git will provide a plethora of possible commands, by their initials, in a prompt. If in à), use ? to display help), which here stands for split.
|
||||
|
||||
Note that even if you have adjacent edits (edits without unchanged lines between them), you can edit the snapshot on the fly to make it look like what you intend to stage, using the e (edit) command. It’s sort of express Photoshopping for your snapshot. Actually, if you know from the get-go that your file has such adjacent hunks, you can pre-select that mode using the -e option instead of -p. In that case however, Git will not pre-split other hunks for you.
|
||||
|
||||
When you’re done, your file will normally appear as both staged and modified. That’s to be expected, as indeed:
|
||||
|
||||
- the latest committed version isn’t the same as the staged one: your file thus appears staged.
|
||||
- the staged version isn’t the same as the file in the working directory: your file thus appears modified.
|
||||
|
||||
You can check out the diff for the staged version using git diff --staged index.html. If you want to the see the whole staged snapshot, instead of diffs, you can go with git show :0:index.html (that’s a zero, not an O letter).
|
||||
|
||||
After that, be extra careful not to do a git commit -a (for instance, git commit -am “Asynchronous tracker”), as that -a will auto-stage every known edit, thereby overwriting the “sculpted” stage you had put together.
|
||||
|
||||
Finally, few people know that git reset also features a -p option, which has the exact same UX as in add, but obviously does the opposite: it unstages selected hunks. It’s often used to split the latest commit, by doing something like this:
|
||||
|
||||
```shell
|
||||
git reset -p HEAD^
|
||||
```
|
||||
|
||||
Edits are then presented as cancellations of those in the latest commit. You tell which cancellations you want, amend the commit (see below), then complete the extra commit(s) you want with the remaining modifications.
|
||||
|
||||
It’s a very “quick and pro” way of splitting a commit inside an interactive rebase, using its edit command.
|
||||
|
||||
## Properly account for renames using -A
|
||||
|
||||
You may know that, by default (at least before 2.0), git add behaved as git add --no-all or, if you prefer, git add --ignore-removal. It only used the working directory as a basis to compute its list of files to take into account, which therefore included:
|
||||
|
||||
- Modifications to known files
|
||||
- New files
|
||||
|
||||
On the other hand, files known to Git’s index but not found in the disk anymore, which appeared as removed, were left aside.
|
||||
|
||||
This was a problem for renames and moves, which result in both a “deletion” of the old path, and the apparition of the new one.
|
||||
|
||||
To deal with this, we use git add -A, or its longer form git add --all. This takes everything into account. When the index is then aware of both changes, it can “realize” it’s a rename (even if some of the content has changed in the file, too), which later allows git log to follow the file across renames, for instance.
|
||||
|
||||
Starting with Git 2.0, this is the default behavior of git add if you provide a path to it (e.g. git add .). By the way, another important change in 2.0: before it, when you did git add -A with no path, it would only work on the current directory and its subfolders, but from 2.0 on, it will work on the entire repository, wherever you are in it.
|
||||
|
||||
## Get inside untracked directories for status
|
||||
|
||||
I’m sure you noticed: when you add a folder to a repo, git status only lists the folder itself as untracked, not its contents. For instance, let’s say I just added a super plugin to my project, with a JS and CSS file inside:
|
||||
Status does not enter untracked directories by default.
|
||||
|
||||
I find that annoying. We can ask status to get inside using -u:
|
||||
Status can enter untracked directories when asked to.
|
||||
|
||||
I find this so useful that I set the appropriate configuration variable in my global configuration, so it’s always on:
|
||||
|
||||
```shell
|
||||
git config --global status.showUntrackedFiles all
|
||||
```
|
||||
|
||||
## Produce more useful diffs
|
||||
|
||||
The diffs produced by git diff, git log and git show, to name only these, are nice but definitely have room for improvement. Here are three tweaks that are near and dear to my heart:
|
||||
|
||||
```shell
|
||||
git diff -w
|
||||
```
|
||||
|
||||
Or its longer form, git diff --ignore-all-space (which is indeed more explicit). This option lets diffs ignore any whitespace change inside or on the edge of lines, including going from no whitespace to some, and vice-versa. The one exception is no blank lines to some blank lines, and vice-versa.
|
||||
|
||||
This can come back and bite you when you work on files with significant indenting, but for most cases, it’s a great way to “unspam” the display and focus on useful bits.
|
||||
|
||||
Without -w:
|
||||
A diff without -w can contain a lot of cruft
|
||||
|
||||
With -w:
|
||||
Note how using -w lets us focus on more useful bits
|
||||
|
||||
Another option I love is about the core display of diffs. By default, it’s a line-by-line thing, which sometimes doesn’t quite cut it:
|
||||
Line-by-line diffs can make it difficult to spot changes
|
||||
|
||||
You can start by asking diff to only display the line once, using word delimiters, thanks to the --word-diff option. The definition of “word” here is based on whitespace. For editorial content, that’s just fine:
|
||||
Whitespace-delimited “words” are good enough for editorial content
|
||||
|
||||
And by the way, if you dislike these +/- brackets, you can use --word-diff=color to spruce this up. Actually, there’s a shorter form called --color-words (ain’t it cute…).
|
||||
Using —color-words removes the +/- bracketing. Depending on the diff, this may improve, or impair, legibility of the result.
|
||||
|
||||
Anyway, this leaves us with a problem when diff’ing code, as whitespace is seldom the only useful delimiter. Just look at this:
|
||||
Whitespace-based word diffing kinda sucks on code
|
||||
|
||||
To fix this, we’ll go for a regex that says “this is a word.” Taking this to the extreme would be “any character, even just one,” using . (a single period), but if this goes overboard on your specific situation, you can lengthen it, for instance .{3,} for at least 3 characters.
|
||||
|
||||
This would result in quite verbose command lines: --word-diff=color --word-diff-regex=. or so. We’ll go for a shorter version:
|
||||
|
||||
```shell
|
||||
git diff --color-words=.
|
||||
```
|
||||
|
||||
Here goes:
|
||||
Custom colored words diffing for the win!
|
||||
|
||||
If you want to make such an approach systematical (I often do), you can configure diff.wordRegex to the proper value (e.g. .), so any type of word diff (e.g. --color-words) with no argument will use it (an explicit regex in the CLI will of course have priority).
|
||||
|
||||
## Fix the latest commit with --amend
|
||||
|
||||
When looking at the quick recap displayed after a git commit, one often realizes they just slipped up: forgot a file, committed one file too many, that kind of thing…
|
||||
|
||||
An easy way to fix this, as long as you haven’t pushed that commit to your friends, is to put yourself back in the proper situation (e.g. perform the necessary git add, git reset or git rm --cached on the problematic file, perhaps combined with a judicious addition to .gitignore…) then do this:
|
||||
|
||||
```shell
|
||||
git commit --amend
|
||||
```
|
||||
|
||||
This option is actually nothing more than a git reset --soft HEAD^ before the requested commit, but most people do not master reset, so this helps.
|
||||
|
||||
Also note that most of the time, the initial commit message was fine. I doubt that you had originally labeled it “Migrating to Bootstrap 3.1, and by the way mistakenly versioning the server’s root password.” In order to avoid having to re-type that message, or simply having the editor pop up, you can do this:
|
||||
|
||||
```shell
|
||||
git commit --amend --no-edit
|
||||
```
|
||||
|
||||
If you’re still running on a Git older than 1.7.9 (Gawd, look at what you’re missing!) do this instead:
|
||||
|
||||
```shell
|
||||
git commit --amend -C HEAD
|
||||
```
|
||||
|
||||
It’s such a common use case that I often see people alias this as git oops :-)
|
||||
|
||||
In your log, only the latest version of the commit is visible: it’s as if you had never slipped up (how good are you!). The former version(s) of the commit of course remain in your reflog, as the general Git principle holds: “if it’s been committed, it’s virtually impossible to lose.”
|
||||
|
||||
## Smart filtering of logs with -S and -G
|
||||
|
||||
The git log command is packed with options (100+!), many of which it shares with its close cousin git diff.
|
||||
|
||||
A number of these options are there to filter the log even before displaying it (which is vastly faster and useful than grep’ing it afterwards): filtering based on dates, paths, branches, authors and committers, commit messages… but also diff contents. Specifically, active diff lines.
|
||||
|
||||
Diff filtering is extremely useful to hunt down the origin of some code, especially of a bug. Too many people think they should use git blame for this, mostly because of a cargo-culted svn blame reflex, but this command is just as dumb as its svn counterpart:
|
||||
|
||||
- It only displays the commit that touched the line last, without telling you why; for all we know, it may just have trimmed trailing whitespace.
|
||||
- It only displays currently existing lines, so if the issue is that a line was removed, it’s completely useless.
|
||||
|
||||
On the contrary, if you filter diff contents, you’ll indeed know which commit introduced the change you’re interested in.
|
||||
|
||||
If we’re only interested in the presence of a given text in the diff’s active lines (the +/- lines, not the context lines), regardless of why and how it got there, we’ll usually go with -G (this is regex-based, so do remember to escape regex-special characters):
|
||||
|
||||
```shell
|
||||
git log -G 'Secure_?Random' -2 -- path/to/problematic_file
|
||||
```
|
||||
|
||||
(We’re usually only interested in the 1–2 latest commits when doing such a search.)
|
||||
|
||||
On the other hand, if we’re specifically looking for diffs that removed or added the text, we’ll go with -S, which only returns diffs that changed the number of occurrences of the text. By default, -S takes a fixed string, but if you want it to be a regex, just add --pickaxe-regex:
|
||||
|
||||
```shell
|
||||
git log -S 'Secure_?Random' --pickaxe-regex -2 -- path/to/file
|
||||
```
|
||||
|
||||
If you need your texts, or regexes, to be case-insensitive, add -i. Regexes are always processed as extended-syntax (ERE). Finally, if you want to display diffs on the fly (which can make for heavy display, be warned), add the usual -p (all the more reason to filter on the specific file you’re inspecting).
|
||||
|
||||
## Faster branch handling with -b, -v, -vv
|
||||
|
||||
Alright, so first, if you didn’t know yet that git checkout -b creates your new branch on the fly, you now have no excuse.
|
||||
|
||||
I mean, why the heck bother with:
|
||||
|
||||
```shell
|
||||
$ git branch ticket-12
|
||||
$ git checkout ticket-12
|
||||
```
|
||||
|
||||
When you can just go with:
|
||||
|
||||
```shell
|
||||
git checkout -b ticket-12
|
||||
```
|
||||
|
||||
Of course, nothing stops you from using the 2nd argument to specify the base for the new branch (which defaults to HEAD, as is often the case with the Git CLI).
|
||||
|
||||
Extra tip: checkout is smart about one case where -b becomes superfluous: when you want to start working on a remote branch super-feature and don’t have yet a local tracking branch. You can just go:
|
||||
|
||||
```shell
|
||||
git checkout super-feature
|
||||
```
|
||||
|
||||
Git will realize there’s no such local branch, but there is such a branch on the default remote, and will automatically do the equivalent of what follows (assuming here your default remote is called origin, which is common):
|
||||
|
||||
```shell
|
||||
git checkout -b -t super-feature origin/super-feature
|
||||
```
|
||||
|
||||
So why bother with a long call when you can have it short and sweet?
|
||||
|
||||
Let’s know talk about -v and its agressive brother, -vv.
|
||||
|
||||
You’re probably used to listing your local branches with a simple git branch:
|
||||
|
||||
## A simple git branch call lists your local branches
|
||||
|
||||
Did you know that you can get much more info (SHA, spread with any upstream, first line of the commit message) with -v?
|
||||
git branch -v displays a lot more useful info
|
||||
|
||||
You could even go so far as to look up the tracked upstreams with -vv:
|
||||
```shell
|
||||
git branch -vv even looks up your tracked upstreams
|
||||
```
|
||||
|
||||
Ain’t it cool? By default upstreams appear as dark blue, but this sucks on my black background, so I setup color.branch.upstream to cyan…
|
||||
|
||||
## Easier help with -w
|
||||
|
||||
Man pages are well and good, and work everywhere, including through an SSH session… Well, almost everywhere. Several environments don’t handle man very well.
|
||||
|
||||
Not only that, but a vast majority of users don’t know how to interact with man other than scroll through it. Leveraging hyperlinks, in particular, is extremely rare.
|
||||
|
||||
Git publishes all its docs not only in the man format, but also as HTML, a type far easier to use and known to all, links included. To use this format, just add the -w option to git help:
|
||||
|
||||
```shell
|
||||
git help -w reset
|
||||
```
|
||||
|
||||
In a few environments (such as the official Windows installer, I believe) this is actually the default. If you wish to make that happen for you too, you can configure this globally:
|
||||
|
||||
```shell
|
||||
git config --global help.format html
|
||||
```
|
||||
|
||||
If the default selected browser isn’t your preferred one (this is determined by git-web--browse, which is aware of a shit load of them), you can force-configure it with help.browser, setting the proper name or command.
|
||||
|
||||
These HTML files are stored locally (installed by Git), so you don’t even need an Internet access.
|
||||
|
||||
## Better stashing with save and -u
|
||||
|
||||
Too few people are aware of git stash, and those who do know it seldom look up the doc and learn how to use it well. I see most people just firing up a git stash first, then a simple git stash apply later on.
|
||||
|
||||
The default stashing behavior rather blows:
|
||||
|
||||
- It leaves untracked files in the working directory, which is rarely what you want;
|
||||
- it uses a braindead default message, something along the lines of “WIP on master: <whatever the latest commit message was>”.
|
||||
|
||||
Such a message is completely useless, as it doesn’t say anything about what the work in progress (WIP) actually is, making it difficult later on to identify what the stash was about.
|
||||
|
||||
To fix these to issues, all we need to do is go with the save subcommand and its -u option (which includes untracked files), and provide our custom message. For instance:
|
||||
|
||||
```shell
|
||||
git stash save -u 'Beginning of Bootstrap 3 refactoring'
|
||||
```
|
||||
|
||||
You then find yourself on a clean tree: what’s in HEAD, plus ignored files.
|
||||
|
||||
Properly getting your stash back is just as hard, once you’re done with whatever emergency had you stash in the first place.
|
||||
|
||||
Most people just do a git stash apply, which is too bad because in case of success (i.e. no conflict with your new base state), your stash is kept in the stash list, which could entice you later to try re-applying it. Oops.
|
||||
|
||||
What we need is a way, when apply succeeds, to automatically drop. And this is exactly what git stash pop does.
|
||||
|
||||
Although its name may suggest otherwise, it doesn’t limit itself to the latest stash: you can specify any stash (e.g. git stash pop stash@{2}). That being said, I believe stashes are meant to be short-lived, as a workaround for a complex situation or obstacle, and you should seldom have more than one.
|
||||
|
||||
Another gotcha is that apply and pop, by default, do not restore the stage. It is indeed saved individually by save, still by default, so why not auto-restore it, as it is an important piece of information?
|
||||
|
||||
This is because stash is a bit of a coward: if you modified a file that was in the stash’s stage, it would have to merge both and re-stage the result. Git usually auto-stages merges (after a merge, rebase or cherry-pick for instance, with or without rerere assistance), but in this instance, it’ll deny it.
|
||||
|
||||
So, in order not to have to yell should a merge have to happen in the stage, it will by default not restore the stage: its snapshots will become regular local edits again.
|
||||
|
||||
This annoys me to no end, so I always explicitly ask it to restore the stage. Worst-case scenario, it will bump on something and I’ll just have to re-do the command with no stage requirement. So I always use the --index option:
|
||||
|
||||
```shell
|
||||
git stash pop --index
|
||||
```
|
||||
|
||||
Unfortunately, there’s no configuration variable to automate this…
|
||||
|
||||
Ah, and yes, it’s super easy to forget you stashed: so be sure to have a solid prompt (e.g. use the ones provided by the builtin scripts for bash/zsh) and use them with a GIT_PS1_SHOWSTASHSTATE=1 environment setup.
|
||||
|
||||
## Previous active branch: -
|
||||
|
||||
You probably now that in most shells, cd - takes you back to the directory you were in just before the current one (so using this multiple times toggles you between two directories).
|
||||
|
||||
As Git versions marched on, various commands have learned this trick: checkout, merge, cherry-pick and lately rebase. Here’s a classic sequence:
|
||||
|
||||
```shell
|
||||
(topic) $ git checkout master(master)
|
||||
$ git merge -
|
||||
```
|
||||
|
||||
And another one:
|
||||
|
||||
```shell
|
||||
(2-3-stable +) $ git ci -m "fix: no more _ conflict. Fixes #217."
|
||||
(2-3-stable) $ git checkout master(master)
|
||||
$ git cherry-pick -
|
||||
```
|
||||
|
||||
If you’re running a Git version that doesn’t support the dash notation for the command you want (verify this), you can fall back on the universal syntax that dash is syntactic sugar for: @{-1}.
|
||||
|
||||
## Cancel the current merge yet preserve previous local edits
|
||||
|
||||
Git doesn’t really need a clean tree to allow a merge to go ahead: it just needs its working directory to be in good order, which basically means that files to be changed by the merge should not have local edits, and that you shouldn’t have an ongoing stage (to avoid a multi-topic commit eventually).
|
||||
|
||||
So when you find yourself wading through merge conflicts, you may have in your working directory both merge conflicts and local edits that were there before you started the merge.
|
||||
|
||||
If you decide to cancel the merge for whatever reasons, it is tempting to go with good ol’ git reset --hard. This would actually be dangerous, as it would destroy all local edits that were there before the merge, too.
|
||||
|
||||
This is why we have git reset --merge (or its more recent syntax: git merge --abort, which is more in line with its rebase cousin): it resets only changes brought on by the merge.
|
||||
|
||||
```shell
|
||||
(master *) $ git merge cool-featureAuto-merging index.htmlCONFLICT (content): Merge conflict in index.htmlAutomatic merge failed; fix conflicts and then commit the result.(master *+) $ git merge --abort(master *) $
|
||||
```
|
||||
|
||||
You can even do this after a successful merge!
|
||||
|
||||
```shell
|
||||
(master *) $ git merge cool-featureAuto-merging index.htmlMerge made by the `recursive` strategy.[afbd564] Merged `cool-feature` branch
|
||||
|
||||
(master *) $ git reset —merge ORIG_HEAD[ac3489b] Original master tip(master *) $
|
||||
```
|
||||
|
||||
Super classy, isn’t it? This spares us some stashing…
|
||||
|
||||
## Avoid killing a merge when rebasing it
|
||||
|
||||
Rebasing is definitely a wonderful Swiss-army knife, with just one little potential risk: by default, when rebasing a merge commit, it inlines the merge. In a nutshell, you run the following risk (here illustrated by a pull that rebases instead of merging, usually a great idea):
|
||||
By default, rebasing inlines merge commits, which is not such a great idea…
|
||||
|
||||
To avoid this painful scenario, we can ask rebase to preserve merges, using its -p option, or the longer form --preserve-merges. The result will be similar to what follows, although it uses a different CLI context:
|
||||
You can ask rebase to preserve merges, which is usually what you want
|
||||
|
||||
Try to avoid combining that with commit reordering in interactive rebase though, this would yield unexpected results.
|
||||
|
||||
## Be a rebase ninja with -i
|
||||
|
||||
Talking about interactive rebase, this is indeed where rebase really shines, a multi-daily use case being the best-practice reflex of cleaning up your local history before pushing it, which usually goes git rebase -i @{u}.
|
||||
|
||||
Stripping zero-sum commit pairs/groups (e.g. the original and its revert), reordering commits, merging multiple attempts at one fix, rewriting messages, splitting up kitchen sinks… Everything’s possible!
|
||||
|
||||
## Safely cleaning up with -i and -n
|
||||
|
||||
The git clean command is very useful, but potentially destructive: it does impact the working directory (WD), so it could destroy local edits you never committed, so if you slip up, Git won’t be able to recover your work!
|
||||
|
||||
This is probably why, by default, git clean is a no-op, as clean.requireForce defaults to true. You thus would have to git clean -f to start pumping; even then, it would leave directories alone (unless -d) and ignored files too (unless -x).
|
||||
|
||||
The good news is, you can see what your clean would do without any risk, with the traditional -n (or --dry-run) option that many Git commands feature: it will list files and folders to be removed, but will stop at listing.
|
||||
|
||||
And when you do go ahead, you can gain some confidence by using -i (the traditional --interactive), that will launch a sort of shell listing candidates for removal, and letting you filter them, confirm each, etc. No more anguish!
|
||||
|
||||
## Set the upstream on the fly with -u
|
||||
|
||||
So you’re pushing a branch for the first time? You’ll always need to explictly state what the remote is (even if you only have one defined), and what branch you’re pushing (even if it’s the current one), for instance git push origin topic.
|
||||
|
||||
However, this simple push does not set up tracking: your local configuration does not remember the matching between your local topic branch and its upstream, here the topic branch on the origin remote.
|
||||
|
||||
To remedy that, you can at any time re-push with an added -u (or --set-upstream), which will persist that configuration for you, in addition to the push proper. This way you don’t have to specify anything for future pushes and pulls.
|
||||
|
||||
```shell
|
||||
git push -u origin topic
|
||||
```
|
||||
|
||||
Internally, this relies on git branch --set-upstream-to=origin/topic topic, so if you just want to set this up without pushing just yet, do that.
|
||||
|
||||
As a side reminder, you don’t have to track an homonymous upstream: if names need to differ, you’ll just need to use the full push syntax, for instance, to connect a remote christophe-topic branch to your local topic branch:
|
||||
|
||||
```shell
|
||||
git push -u origin topic:christophe-topic
|
||||
```
|
||||
|
||||
This is why the remote branch deletion syntax is as follows:
|
||||
|
||||
```shell
|
||||
git push origin :old-remote-branch
|
||||
```
|
||||
|
||||
You’re essentially saying “replace the remote branch old-remote-branch with nothing at all” so… delete it.
|
||||
Ah well, 36 in the end
|
||||
|
||||
Yeah, that’s 36 options (not counting long form variations), and 4 configuration variables, and one environment setting. I can’t help it, I give, I give…
|
||||
@@ -0,0 +1,58 @@
|
||||
---
|
||||
title: >-
|
||||
30 Jahre Linux: Darum ist das Betriebssystem aus unserem Alltag nicht wegzudenken
|
||||
updated: 2021-09-23 14:19:30Z
|
||||
created: 2021-09-23 14:18:32Z
|
||||
tags:
|
||||
- IT
|
||||
- Linux
|
||||
- IT/OpenSource
|
||||
source: >-
|
||||
https://www.rnd.de/digital/linux-30-jubilaeum-darum-ist-das-betriebssystem-aus-unserem-alltag-nicht-wegzudenken-FJANYEH4Y5YDRTODWN5JAPJGUE.html
|
||||
---
|
||||
|
||||
## [30 Jahre Linux: Darum ist das Betriebssystem aus unserem Alltag nicht wegzudenken](https://www.rnd.de/digital/linux-30-jubilaeum-darum-ist-das-betriebssystem-aus-unserem-alltag-nicht-wegzudenken-FJANYEH4Y5YDRTODWN5JAPJGUE.html)
|
||||
|
||||
Berlin. Die Geschichte des universellen Betriebssystems Linux, das quasi jeder nutzt, begann mit einer gewaltigen Tiefstapelei. „Ich arbeite an einem (freien) Betriebssystem (nur ein Hobby, wird nicht groß und professionell ...)“, schrieb der finnische Student Linus Torvalds am 25. August 1991. Er konnte sich damals nicht vorstellen, dass Linux 30 Jahre später nicht nur auf rund 80 Prozent aller Smartphones laufen wird, sondern in fast jedem modernen Auto und etlichen anderen Geräten steckt. Selbst der Mars-Hubschrauber „Ingenuity“, der zusammen mit dem Bodenfahrzeug „Perseverance“ den roten Planeten erkundet, wird mit Hilfe von Linux angetrieben.
|
||||
|
||||
Linux war anfangs nur dafür gedacht, auf den weit verbreiteten PCs mit x86-Chips von Intel zu laufen. Die von Torvalds festgelegte Architektur war aber schon damals im Prinzip dafür geeignet, unabhängig von der vorhandenen Hardware als Betriebssystem eingesetzt zu werden. Heute laufen sämtliche Hochleistungsrechner der Welt aus der Top-500-Liste mit dem freien Betriebssystem und haben hier dem technisch verwandten Unix den Rang angelaufen. Linux konnte aber auch auf Smartphones laufen, denn das System wurde das Fundament für Android von Google.
|
||||
|
||||
## ZUM THEMA
|
||||
|
||||
## Frei und kostenlos
|
||||
|
||||
Im Unterschied zu kommerziellen Software-Plattformen wie Windows von Microsoft war Linux von Anfang frei im doppelten Wortsinn: frei wie freie Rede und frei wie Freibier. Dass dabei keine Lizenzzahlungen fällig wurden, förderte die Verbreitung ungemein. Dazu kamen frühe technische Grundsatzentscheidungen Torvalds’ und seines Teams, die sich im Rückblick als goldrichtig erwiesen haben, beispielsweise der Einbau des Internet-Protokolls TCP/IP.
|
||||
|
||||
Torvalds und seine Mitstreiter stießen anfangs besonders in der eigenen Szene auf Widerspruch. So konnte sich der einflussreiche Informatiker Andrew Tanenbaum nicht vorstellen, wie ein verteiltes Programmieren gelingen soll: „Ich denke, dass die Koordination von 1000 Primadonnen, die überall auf der ganzen Erde leben, genauso einfach ist wie Katzen zu hüten“, schrieb Tanenbaum in einer inzwischen legendären Debatte im Usenet.
|
||||
|
||||
## Linux ist Open-Source-Pionier
|
||||
|
||||
Doch das verteilte System funktionierte. Und mit der steigenden Verbreitung von Linux wurden auch große Software-Konzerne nervös. „Linux ist ein Krebsgeschwür, das in Bezug auf geistiges Eigentum alles befällt, was es berührt“, polterte 2001 der damalige Microsoft-Chef Steve Ballmer in einem Interview. Er störte sich an der Grundidee der freien Software: Der Quellcode von Software darf kein Betriebsgeheimnis sein, sondern wird allen Interessierten offen bereitgestellt. Dann können andere den Code verbessern und ergänzen, müssen ihn aber wieder für die Community bereitstellen. Unter Ballmers Nachfolger Satya Nadella schloss Microsoft seinen Frieden mit Linux und setzt das System bei einigen Cloud-Anwendungen selbst ein.
|
||||
|
||||
## ZUM THEMA
|
||||
|
||||
Eine Programm-Entwicklung als „Open Source“ wie bei Linux wird inzwischen bei vielen aufwendigen Softwareprojekten quasi vorausgesetzt. So entstand die Corona-Warn-App des RKI quelloffen und unter einer freien Lizenz. Über die Plattform Github konnte der Programmcode eingesehen und Änderungsvorschläge an die App-Macher des Software-Konzerns SAP und der Deutschen Telekom eingereicht werden.
|
||||
|
||||
## Nur 2,4 Prozent Marktanteil bei Desktop-Rechnern
|
||||
|
||||
Linux ist allerdings nicht in sämtlichen Bereichen der Durchmarsch gelungen. Mit der Linux-Variante Android dominiert das System den Massenmarkt der Smartphones. Und auch die meisten Web-Server im Netz laufen unter Linux. Doch ausgerechnet bei der Plattform, für die Linux vor 30 Jahren erfunden wurde, nämlich bei den gewöhnlichen Desktop-Rechnern, spielt das System eine untergeordnete Rolle.
|
||||
|
||||
Die Analytik-Firma Statcounter verzeichnete für Linux zuletzt einen Marktanteil von knapp 2,4 Prozent, während Windows auf 73 Prozent der PCs installiert war. Zum Linux-Lager kann man noch die 1,2 Prozent für die tragbaren Chromebooks mit der Google-Software Chrome OS rechnen, bei der es sich ebenfalls um eine Linux-Variante handelt. Die Dominanz von Microsoft wurde in den vergangenen Jahren noch am ehesten von Apple mit dem Betriebssystem macOS in Frage gestellt. Die Apple-Software kommt derzeit auf 15,4 Prozent Marktanteil.
|
||||
|
||||
## Komplizierte Handhabung
|
||||
|
||||
Dass Linux auf dem PC nie richtig Fuß fassen konnte, hat mehrere Gründe: Zum einen liefern Hersteller wie Lenovo, Dell und HP ihre Geräte nicht „nackt“ ohne Betriebssystem aus, sondern mit vorinstalliertem Windows. Für die Käuferinnen und Käufer ist auch nicht ersichtlich, wie hoch der Anteil für Windows am Kaufpreis ist, denn der wird nicht gesondert ausgewiesen.
|
||||
|
||||
## ZUM THEMA
|
||||
|
||||
- [### Safer Internet Day: Wie sicher ist mein Browser?](https://www.rnd.de/digital/safer-internet-day-wie-sicher-ist-mein-browser-W6K6J4W5Q7GJCPFWDWEN2OMRQM.html)
|
||||
- [### Neues Tails und neuer Tor-Browser sorgen für mehr Privatsphäre](https://www.rnd.de/digital/neues-tails-und-neuer-tor-browser-sorgen-fur-mehr-privatsphare-GTQ6ZGRORYYIANHQRGU4DLPAVM.html)
|
||||
- [### Hacker warnen vor Gefahren der Digitalisierung](https://www.rnd.de/digital/hacker-warnen-vor-gefahren-der-digitalisierung-XIFZF23TKG4ITQCVVXLKSDJUTM.html)
|
||||
|
||||
Lange war es für technische Laien auch recht kompliziert, Linux zu installieren. Inzwischen können zwar Linux-Distributionen wie Ubuntu mit wenigen Mausklicks zum Laufen gebracht werden. Doch dem System eilt immer noch der Ruf voraus, kompliziert zu sein. Und in der frühen Linux-Phase fehlten auch die Anwendungen, die man als Windows- oder Mac-User kennt. Manche gibt es bis heute nicht, etwa Adobe Photoshop, die Office-Programme von Microsoft oder viele Spiele. Linux-Befürworter weisen darauf hin, dass etliche Programme für die Bildbearbeitung, die täglichen Büro-Aufgaben oder zum Spielen längst vorhanden sind. Aber selbst Torvalds räumte 2014 ein, dass es für Programmierer „verdammt kompliziert“ sei, Anwendungen für Linux zur Verfügung zu stellen, weil es kein einheitliches System gebe, sondern die unterschiedlichsten Linux-Distributionen.
|
||||
|
||||
## Entwickler ist auf Hardware-Hersteller angewiesen
|
||||
|
||||
Als der führende Entwickler des Linux-Betriebssystemkerns (Kernel) hat Torvalds nur bedingt Einfluss darauf, wie die unterschiedlichen Varianten gestaltet werden. Außerdem ist er darauf angewiesen, dass Hardware-Hersteller mitziehen und geeignete Treiber zur Verfügung stellen. Wenn ein Hersteller wie der Grafikkartenanbieter Nvidia sich verweigert, bleibt ihm nichts weiter übrig, als ihn auf offener Bühne zu beschimpfen und den Stinkefinger zu zeigen. Um Torvalds ist es in den vergangenen Jahren ruhiger geworden, auch weil sich der Vater des freien Betriebssystems 2018 selbst eine Auszeit nahm.
|
||||
|
||||
Inzwischen ist Torvalds wieder aktiv und teilt auf den Mailing-Listen rund um die Linux-Entwicklung hin und wieder kräftig aus. Zuletzt machte er Schlagzeilen, als er dort Impfskeptiker zurechtwies: „Sie wissen nicht, wovon Sie sprechen, Sie wissen nicht, was mRNA ist und Sie verbreiten dumme Lügen.“
|
||||
@@ -0,0 +1,187 @@
|
||||
---
|
||||
title: A few git tips you didn't know about
|
||||
updated: 2019-02-26 10:21:54Z
|
||||
created: 2019-02-26 10:18:57Z
|
||||
tags:
|
||||
- Development/Git
|
||||
- Development/Shell
|
||||
---
|
||||
|
||||
|
||||
A few git tips you didn't know about
|
||||
|
||||
By Mislav Marohnić on
|
||||
23 Jul 2010
|
||||
|
||||
Notice: some of these commands or flags require git version 1.7.2.
|
||||
On OS X, upgrade easily with Homebrew: brew install git
|
||||
|
||||
## Show branches, tags in git log
|
||||
|
||||
```shell
|
||||
$ git log --oneline --decorate
|
||||
|
||||
7466000 (HEAD, mislav/master, mislav) fix test that fails if current dir is not "hub"
|
||||
494a414 fix cherry-pick of a commit URL
|
||||
4277848 (origin/master, origin/HEAD, master) whoops
|
||||
d270fae bugfix: git init -g
|
||||
9307af3 test deps
|
||||
8ccc17e http://github.com/defunkt/hub/contributors
|
||||
64bb19c bugfix: variable name
|
||||
546726a dont need you
|
||||
3a8d7af (tag: v1.3.1) v1.3.1
|
||||
197f429 (tag: v1.3.0) v1.3.0
|
||||
a1e1a50 not important
|
||||
3c6af16 magic `cherry-pick` supports GitHub commit URLs and "user@sha" notation
|
||||
```
|
||||
|
||||
## Diff by highlighting inline word changes instead of whole lines
|
||||
|
||||
```shell
|
||||
$ git diff --word-diff
|
||||
|
||||
# Returns a Boolean.
|
||||
def command?(name)
|
||||
`type -t [-#{command}`-]{+#{name}`+}
|
||||
$?.success?
|
||||
end
|
||||
```
|
||||
|
||||
This flag works with other git commands that take diff flags such as git log -p and git show.
|
||||
## Short status output
|
||||
|
||||
```shell
|
||||
$ git status -sb
|
||||
|
||||
## thibaudgg...thibaudgg/master [ahead 1, behind 2]
|
||||
M ext/fsevent/fsevent_watch.c
|
||||
?? Makefile
|
||||
?? SCEvents/
|
||||
?? bin/fsevent_watch
|
||||
```
|
||||
|
||||
The default, verbose status output is fine for beginners, but once you get proficient with git there is no need for it. Since I check the status often, I want it to be as concise as possible.
|
||||
|
||||
## Push a branch and automatically set tracking
|
||||
|
||||
```shell
|
||||
$ git push -u origin master
|
||||
|
||||
# pushes the "master" branch to "origin" remote and sets up tracking
|
||||
```
|
||||
|
||||
“Tracking” is essentially a link between a local and remote branch. When working on a local branch that tracks some other branch, you can git pull and git push without any extra arguments and git will know what to do.
|
||||
|
||||
However, git push will by default push all branches that have the same name on the remote. To limit this behavior to just the current branch, set this configuration option:
|
||||
|
||||
$ git config --global push.default tracking
|
||||
|
||||
This is to prevent accidental pushes to branches which you’re not ready to push yet.
|
||||
Easily track a remote branch from someone else
|
||||
|
||||
$ git checkout -t origin/feature
|
||||
|
||||
# creates and checks out "feature" branch that tracks "origin/feature"
|
||||
|
||||
Once your teammate has shared a branch he or she was working on, you need to create a local branch for yourself if you intend to make changes to it. This does that and sets up tracking so that you can just git push after making changes.
|
||||
Checkout a branch, rebase and merge to master
|
||||
|
||||
# on branch "master":
|
||||
$ git checkout feature && git rebase @{-1} && git checkout @{-2} && git merge @{-1}
|
||||
|
||||
# rebases "feature" to "master" and merges it in to master
|
||||
|
||||
The special “@{-n}” syntax means “n-th branch checked out before current one”. When we checkout “feature”, “@{-1}” is a reference to “master”. After rebasing, we need to use “@{-2}” to checkout master because “@{-1}” is a reference to the same branch (“feature”) due to how rebasing works internally.
|
||||
|
||||
Update: Björn Steinbrink points out that this can be done in just 2 commands:
|
||||
|
||||
$ git rebase HEAD feature && git rebase HEAD @{-2}
|
||||
|
||||
Pull with rebase instead of merge
|
||||
|
||||
$ git pull --rebase
|
||||
|
||||
# e.g. if on branch "master": performs a `git fetch origin`,
|
||||
# then `git rebase origin/master`
|
||||
|
||||
Because branch merges in git are recorded with a merge commit, they are supposed to be meaningful—for example, to indicate when a feature has been merged to a release branch. However, during a regular daily workflow where several team members sync a single branch often, the timeline gets polluted with unnecessary micro-merges on regular git pull. Rebasing ensures that the commits are always re-applied so that the history stays linear.
|
||||
|
||||
You can configure certain branches to always do this without the --rebase flag:
|
||||
|
||||
# make `git pull` on master always use rebase
|
||||
$ git config branch.master.rebase true
|
||||
|
||||
You can also set up a global option to set the last property for every new tracked branch:
|
||||
|
||||
# setup rebase for every tracking branch
|
||||
$ git config --global branch.autosetuprebase always
|
||||
|
||||
Find out if a change is part of a release
|
||||
|
||||
$ git name-rev --name-only 50f3754
|
||||
|
||||
"tags/v2.3.8~6"
|
||||
|
||||
It’s not rare that you know a SHA-1 of a commit but aren’t sure where is it located in project’s history. If you’re like me, you probably want to know was that change a part of some release or not. You can use git show to see the commit message, date and the full diff, but this doesn’t help us much—especially since comparing commit dates in a project’s history doesn’t necessarily correspond to the order in which they were applied.
|
||||
|
||||
The name-rev command can tell us the position of a commit relative to tags in the project. The example above is from the Ruby on Rails project. This tells us that this commit is located 6 commits before “v2.3.8” was tagged—we can be certain that this change is now part of Rails 2.3.8, then.
|
||||
|
||||
The command goes even further in its usefulness. Suppose you follow a discussion in which someone mentions a few commits:
|
||||
|
||||
This bug was introduced in e6cadd422b72ba9818cc2f3b22243a6aa754c9f8 but fixed in 50f3754525c61e3ea84a407eb571617f2f39d6fe, if I recall correctly.
|
||||
|
||||
You can copy that to clipboard and pipe the comment to git name-rev, which will recognize commit SHAs and append tag information to each:
|
||||
|
||||
$ pbpaste | git name-rev --stdin
|
||||
|
||||
"This bug was introduced in e6cadd422b72ba9818cc2f3b22243a6aa754c9f8 (tags/v2.3.6~215)
|
||||
but fixed in 50f3754525c61e3ea84a407eb571617f2f39d6fe (tags/v2.3.8~6), if I recall
|
||||
correctly."
|
||||
|
||||
See also: git help describe
|
||||
Find out which branch contains a change
|
||||
|
||||
$ git branch --contains 50f3754
|
||||
|
||||
This filters the lists of branches to only those which have the given commit among their ancestors. To also include remote tracking branches in the list, include the “-a” flag.
|
||||
See which changes from a branch are already present upstream
|
||||
|
||||
# while on "feature" branch:
|
||||
$ git cherry -v master
|
||||
|
||||
+ 497034f2 Listener.new now accepts a hash of options
|
||||
- 2d0333ff cache the absolute images path for growl messages
|
||||
+ e4406858 rename Listener#run to #start
|
||||
|
||||
The cherry command is useful to see which commits have been cherry-picked from a development branch to the stable branch, for instance. This command compares changes on the current (“feature”) branch to upstream (“master”) and indicates which are present on both with the “-” sign. Changes still missing from upstream are marked with “+”.
|
||||
Show the last commit which message matches a regex
|
||||
|
||||
$ git show :/fix
|
||||
# shows the last commit which has the word "fix" in its message
|
||||
|
||||
$ git show :/^Merge
|
||||
# shows the last merge commit
|
||||
|
||||
Fetch a group of remotes
|
||||
|
||||
$ git config remotes.default 'origin mislav staging'
|
||||
$ git remote update
|
||||
|
||||
# fetches remotes "origin", "mislav", and "staging"
|
||||
|
||||
You can define a default list of remotes to be fetched by the remote update command. These can be remotes from your teammates, trusted community members of an opensource project, or similar. You can also define a named group like so:
|
||||
|
||||
$ git config remotes.mygroup 'remote1 remote2 ...'
|
||||
$ git fetch mygroup
|
||||
|
||||
Write commit notes
|
||||
|
||||
$ git notes add
|
||||
# opens the editor to add a note to the last commit
|
||||
|
||||
Git notes are annotations for existing commits. They don’t change the history, so you are free to add notes to any existing commits. Your notes are stored only in your repo, but it’s possible to share notes. There are interesting ideas for possible use-cases for notes, too.
|
||||
Install “hub”
|
||||
|
||||
Hub teaches git about GitHub. If you’re using repos from GitHub on a regular basis, you definitely want to install hub and save a lot of keystrokes—especially if you’re involved in opensource.
|
||||
|
||||
|
||||
@@ -0,0 +1,250 @@
|
||||
---
|
||||
title: 'A sysadmin''s guide to Ansible: How to simplify tasks'
|
||||
updated: 2021-05-18 12:40:08Z
|
||||
created: 2021-05-18 12:40:08Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Ansible
|
||||
source: https://opensource.com/article/18/7/sysadmin-tasks-ansible
|
||||
---
|
||||
|
||||
In my previous article, I discussed [how to use Ansible to patch systems and install applications](https://opensource.com/article/18/3/ansible-patch-systems). In this article, I'll show you how to do other things with Ansible that will make your life as a sysadmin easier. First, though, I want to share why I came to Ansible.
|
||||
|
||||
I started using Ansible because it made patching systems easier. I could run some ad-hoc commands here and there and some playbooks someone else wrote. I didn't get very in depth, though, because the playbook I was running used a lot of [lineinfile](https://docs.ansible.com/ansible/latest/modules/lineinfile_module.html) modules, and, to be honest, my `regex` techniques were nonexistent. I was also limited in my capacity due to my management's direction and instructions: "You can run this playbook only and that's all you can do."
|
||||
|
||||
After leaving that job, I started working on a team where most of the infrastructure was in the cloud. After getting used to the team and learning how everything works, I started trying to find ways to automate more things. We were spending two to three months deploying virtual machines in large numbers—doing all the work manually, including the lifecycle of each virtual machine, from provision to decommission. Our work often got behind schedule, as we spent a lot of time doing maintenance. When folks went on vacation, others had to take over with little knowledge of the tasks they were doing.
|
||||
|
||||
## Diving deeper into Ansible
|
||||
|
||||
Sharing ideas about how to resolve issues is one of the best things we can do in the IT and open source world, so I went looking for help by [submitting issues in Ansible](https://github.com/ansible/ansible/issues/18006) and asking questions in [roles others created](https://github.com/abaez/ansible-role-user/issues/1).
|
||||
|
||||
Reading the documentation (including the following topics) is the best way to get started learning Ansible.
|
||||
|
||||
- [Getting started](http://docs.ansible.com/ansible/latest/user_guide/intro_getting_started.html)
|
||||
- [Best practices](http://docs.ansible.com/ansible/latest/user_guide/playbooks_best_practices.html)
|
||||
- [Ansible Lightbulb](https://github.com/ansible/lightbulb)
|
||||
- [Ansible FAQ](https://docs.ansible.com/ansible/latest/reference_appendices/faq.html)
|
||||
|
||||
If you are trying to figure out what you can do with Ansible, take a moment and think about the daily activities you do, the ones that take a lot of time that would be better spent on other things. Here are some examples:
|
||||
|
||||
- **Managing accounts in systems:** Creating users, adding them to the correct groups, and adding the SSH keys… these are things that used to take me days when we had a large number of systems to build. Even using a shell script, this process was very time-consuming.
|
||||
- **Maintaining lists of required packages:** This could be part of your security posture and include the packages required for your applications.
|
||||
- **Installing applications:** You can use your current documentation and convert application installs into tasks by finding the correct [module](https://docs.ansible.com/ansible/latest/modules/modules_by_category.html) for the job.
|
||||
- **Configuring systems and applications:** You might want to change `/etc/ssh/sshd_config` for different environments (e.g., production vs. development) by adding a line or two, or maybe you want a file to look a specific way in every system you're managing.
|
||||
- **Provisioning a VM in the cloud:** This is great when you need to launch a few virtual machines that are similar for your applications and you are tired of using the UI.
|
||||
|
||||
Now let's look at how to use Ansible to automate some of these repetitive tasks.
|
||||
|
||||
## Managing users
|
||||
|
||||
If you need to create a large list of users and groups with the users spread among the different groups, you can use [loops](https://docs.ansible.com/ansible/latest/user_guide/playbooks_loops.html). Let's start by creating the groups:
|
||||
|
||||
```yaml
|
||||
- name: create user groups
|
||||
group:
|
||||
name: "{{ item }}"
|
||||
loop:
|
||||
\- postgresql
|
||||
\- nginx-test
|
||||
\- admin
|
||||
\- dbadmin
|
||||
\- hadoop
|
||||
```
|
||||
|
||||
You can create users with specific parameters like this:
|
||||
|
||||
```yaml
|
||||
- name: all users in the department
|
||||
user:
|
||||
name: "{{ item.name }}"
|
||||
group: "{{ item.group }}"
|
||||
groups: "{{ item.groups }}"
|
||||
uid: "{{ item.uid }}"
|
||||
state: "{{ item.state }}"
|
||||
loop:
|
||||
- { name: 'admin1', group: 'admin', groups: 'nginx', uid: '1234', state: 'present' }
|
||||
- { name: 'dbadmin1', group: 'dbadmin', groups: 'postgres', uid: '4321', state: 'present' }
|
||||
- { name: 'user1', group: 'hadoop', groups: 'wheel', uid: '1067', state: 'present' }
|
||||
- { name: 'jose', group: 'admin', groups: 'wheel', uid: '9000', state: 'absent' }
|
||||
```
|
||||
|
||||
Looking at the user `jose`, you may recognize that `state: 'absent'` deletes this user account, and you may be wondering why you need to include all the other parameters when you're just removing him. It's because this is a good place to keep documentation of important changes for audits or security compliance. By storing the roles in Git as your source of truth, you can go back and look at the old versions in Git if you later need to answer questions about why changes were made.
|
||||
|
||||
To deploy SSH keys for some of the users, you can use the same type of looping as in the last example.
|
||||
|
||||
```yaml
|
||||
- name: copy admin1 and dbadmin ssh keys
|
||||
authorized_key:
|
||||
user: "{{ item.user }}"
|
||||
key: "{{ item.key }}"
|
||||
state: "{{ item.state }}"
|
||||
comment: "{{ item.comment }}"
|
||||
loop:
|
||||
- { user: 'admin1', key: "{{ lookup('file', '/data/test\_temp\_key.pub'), state: 'present', comment: 'admin1 key' }
|
||||
- { user: 'dbadmin', key: "{{ lookup('file', '/data/vm\_temp\_key.pub'), state: 'absent', comment: 'dbadmin key' }
|
||||
```
|
||||
|
||||
Here, we specify the `user`, how to find the key by using `lookup`, the `state`, and a `comment` describing the purpose of the key.
|
||||
|
||||
## Installing packages
|
||||
|
||||
Package installation can vary depending on the packaging system you are using. You can use [Ansible facts](https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#information-discovered-from-systems-facts) to determine which module to use. Ansible does offer a generic module called [package](http://docs.ansible.com/ansible/latest/modules/package_module.html) that uses `ansible_pkg_mgr` and calls the proper package manager for the system. For example, if you're using Fedora, the package module will call the DNF package manager.
|
||||
|
||||
The package module will work if you're doing a simple installation of packages. If you're doing more complex work, you will have to use the correct module for your system. For example, if you want to ignore GPG keys and install all the security packages on a RHEL-based system, you need to use the yum module. You will have different options depending on your [packaging module](http://docs.ansible.com/ansible/latest/modules/list_of_packaging_modules.html), but they usually offer more parameters than Ansible's generic package module.
|
||||
|
||||
Here is an example using the package module:
|
||||
|
||||
```yaml
|
||||
- name: install a package
|
||||
package:
|
||||
name: nginx
|
||||
state: installed
|
||||
```
|
||||
|
||||
The following uses the yum module to install NGINX, disable `gpg_check` from the repo, ignore the repository's certificates, and skip any broken packages that might show up.
|
||||
|
||||
```yaml
|
||||
- name: install a package
|
||||
yum:
|
||||
name: nginx
|
||||
state: installed
|
||||
disable_gpg_check: yes
|
||||
validate_certs: no
|
||||
skip_broken: yes
|
||||
```
|
||||
|
||||
Here is an example using [Apt](https://docs.ansible.com/ansible/latest/modules/apt_module.html). The Apt module tells Ansible to uninstall NGINX and not update the cache:
|
||||
|
||||
```yaml
|
||||
- name: install a package
|
||||
apt:
|
||||
name: nginx
|
||||
state: absent
|
||||
update_cache: no
|
||||
```
|
||||
|
||||
You can use `loop` when installing packages, but they are processed individually if you pass a list:
|
||||
|
||||
```yaml
|
||||
- name:
|
||||
- nginx
|
||||
- postgresql-server
|
||||
- ansible
|
||||
- httpd
|
||||
```
|
||||
|
||||
NOTE: Make sure you know the correct name of the package you want in the package manager you're using. Some names change depending on the package manager.
|
||||
|
||||
## Starting services
|
||||
|
||||
Much like packages, Ansible has different modules to start [services](http://docs.ansible.com/ansible/latest/modules/list_of_system_modules.html). Like in our previous example, where we used the package module to do a general installation of packages, the [service](http://docs.ansible.com/ansible/latest/modules/service_module.html#service-module) module does similar work with services, including with systemd and Upstart. (Check the module's documentation for a complete list.) Here is an example:
|
||||
|
||||
```yaml
|
||||
- name: start nginx
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
```
|
||||
|
||||
You can use Ansible's service module if you are just starting and stopping applications and don't need anything more sophisticated. But, like with the yum module, if you need more options, you will need to use the systemd module. For example, if you modify systemd files, then you need to do a `daemon-reload`, the service module won't work for that; you will have to use the systemd module.
|
||||
|
||||
```yaml
|
||||
- name: reload postgresql for new configuration and reload daemon
|
||||
systemd:
|
||||
name: postgresql
|
||||
state: reload
|
||||
daemon-reload: yes
|
||||
```
|
||||
|
||||
This is a great starting point, but it can become cumbersome because the service will always reload/restart. This a good place to use a [handler](https://docs.ansible.com/ansible/latest/user_guide/playbooks_intro.html#handlers-running-operations-on-change).
|
||||
|
||||
If you used best practices and created your role using `ansible-galaxy init "role name"`, then you should have the full [directory structure](http://docs.ansible.com/ansible/latest/user_guide/playbooks_best_practices.html#directory-layout). You can include the code above inside the `handlers/main.yml` and call it when you make a change with the application. For example:
|
||||
|
||||
handlers/main.yml
|
||||
```yaml
|
||||
- name: reload postgresql for new configuration and reload daemon
|
||||
systemd:
|
||||
name: postgresql
|
||||
state: reload
|
||||
daemon-reload: yes
|
||||
```
|
||||
|
||||
This is the task that calls the handler:
|
||||
```yaml
|
||||
- name: configure postgresql
|
||||
template:
|
||||
src: postgresql.service.j2
|
||||
dest: /usr/lib/systemd/system/postgresql.service
|
||||
notify: reload postgresql for new configuration and reload daemon
|
||||
```
|
||||
|
||||
It configures PostgreSQL by changing the systemd file, but instead of defining the restart in the tasks (like before), it calls the handler to do the restart at the end of the run. This is a good way to configure your application and keep it idempotent since the handler only runs when a task changes—not in the middle of your configuration.
|
||||
|
||||
The previous example uses the [template module](https://docs.ansible.com/ansible/latest/modules/template_module.html) and a [Jinja2 file](https://docs.ansible.com/ansible/latest/user_guide/playbooks_templating.html). One of the most wonderful things about configuring applications with Ansible is using templates. You can configure a whole file like `postgresql.service` with the full configuration you require. But, instead of changing every line, you can use variables and define the options somewhere else. This will let you change any variable at any time and be more versatile. For example:
|
||||
|
||||
```yaml
|
||||
[database]
|
||||
DB_TYPE = "{{ gitea_db }}"
|
||||
HOST = "{{ ansible_fqdn}}:3306"
|
||||
NAME = gitea
|
||||
USER = gitea
|
||||
PASSWD = "{{ gitea_db_passwd }}"
|
||||
SSL_MODE = disable
|
||||
PATH = "{{ gitea_db_dir }}/gitea.db
|
||||
```
|
||||
|
||||
This configures the database options on the file `app.ini` for [Gitea](https://gitea.io/en-us/). This is similar to writing Ansible tasks, even though it is a configuration file, and makes it easy to define variables and make changes. This can be expanded further if you are using [group_vars](https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#variable-examples), which allows you to define variables for all systems and specific groups (e.g., production vs. development). This makes it easier to manage variables, and you don't have to specify the same ones in every role.
|
||||
|
||||
## Provisioning a system
|
||||
|
||||
We've gone over several things you can do with Ansible on your system, but we haven't yet discussed how to provision a system. Here's an example of provisioning a virtual machine (VM) with the OpenStack cloud solution.
|
||||
|
||||
```yaml
|
||||
- name: create a VM in openstack
|
||||
osp_server:
|
||||
name: cloudera-namenode
|
||||
state: present
|
||||
cloud: openstack
|
||||
region_name: andromeda
|
||||
image: 923569a-c777-4g52-t3y9-cxvhl86zx345
|
||||
flavor_ram: 20146
|
||||
flavor: big
|
||||
auto_ip: yes
|
||||
volumes: cloudera-namenode
|
||||
```
|
||||
|
||||
All OpenStack modules start with `os`, which makes it easier to find them. The above configuration uses the osp-server module, which lets you add or remove an instance. It includes the name of the VM, its state, its cloud options, and how it authenticates to the API. More information about [cloud.yml](https://docs.openstack.org/python-openstackclient/pike/configuration/index.html) is available in the OpenStack docs, but if you don't want to use cloud.yml, you can use a dictionary that lists your credentials using the `auth` option. If you want to delete the VM, just change `state:` to `absent`.
|
||||
|
||||
Say you have a list of servers you shut down because you couldn't figure out how to get the applications working, and you want to start them again. You can use `os_server_action` to restart them (or rebuild them if you want to start from scratch).
|
||||
|
||||
Here is an example that starts the server and tells the modules the name of the instance:
|
||||
|
||||
```ymal
|
||||
- name: restart some servers
|
||||
os_server_action:
|
||||
action: start
|
||||
cloud: openstack
|
||||
region_name: andromeda
|
||||
server: cloudera-namenode
|
||||
```
|
||||
|
||||
Most OpenStack modules use similar options. Therefore, to rebuild the server, we can use the same options but change the `action` to `rebuild` and add the `image` we want it to use:
|
||||
|
||||
```yaml
|
||||
os_server_action:
|
||||
action: rebuild
|
||||
image: 923569a-c777-4g52-t3y9-cxvhl86zx345
|
||||
```
|
||||
|
||||
## Doing other things
|
||||
|
||||
There are modules for a lot of system admin tasks, but what should you do if there isn't one for what you are trying to do? Use the [shell](https://docs.ansible.com/ansible/latest/modules/shell_module.html) and [command](https://docs.ansible.com/ansible/latest/modules/command_module.html) modules, which allow you to run any command just like you do on the command line. Here's an example using the [OpenStack CLI](https://docs.openstack.org/python-openstackclient/pike/):
|
||||
|
||||
```yaml
|
||||
- name: run an opencli command
|
||||
command: "openstack hypervisor list"
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
They are so many ways you can do daily sysadmin tasks with Ansible. Using this automation tool can transform your hardest task into a simple solution, save you time, and make your work days shorter and more relaxed.
|
||||
@@ -0,0 +1,16 @@
|
||||
---
|
||||
title: Add missing indices in Nextcloud database
|
||||
updated: 2022-11-08 08:24:10Z
|
||||
created: 2020-06-04 20:22:20Z
|
||||
tags:
|
||||
- inky
|
||||
- IT/Nextcloud
|
||||
---
|
||||
|
||||
Running as root:
|
||||
|
||||
`sudo -u www-data /usr/bin/php /data/nextcloud-15.0.4/occ db:add-missing-indices`
|
||||
`sudo -u www-data /usr/bin/php /data/nextcloud-15.0.4/occ integrity:check-core`
|
||||
`sudo -u www-data /usr/bin/php /data/nextcloud-15.0.4/occ maintenance:mode --off`
|
||||
|
||||
`occ db:convert-filecache-bigint`
|
||||
@@ -0,0 +1,660 @@
|
||||
---
|
||||
title: Andreas Sommer ‒ I'm a software engineer – Blog – Ansible best practices
|
||||
updated: 2019-08-29 03:35:28Z
|
||||
created: 2019-08-29 03:35:28Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Ansible
|
||||
source: https://andidog.de/blog/2017-04-24-ansible-best-practices
|
||||
---
|
||||
|
||||
[Andreas Sommer](https://andidog.de/ "Andreas Sommer (AndiDog)")
|
||||
|
||||
* [Home](https://andidog.de/)
|
||||
* [Blog](https://andidog.de/blog)
|
||||
* [CV](https://andidog.de/cv)
|
||||
* [RSS](https://andidog.de/blog/rss)
|
||||
|
||||
[# Ansible best practices](https://andidog.de/blog/2017-04-24-ansible-best-practices)
|
||||
|
||||
April 24, 2017
|
||||
|
||||
Ansible can be summarized as tool for running automated tasks on servers that require nothing but Python installed on the remote side. Typically used as configuration management framework, Ansible comes with a set of key benefits:
|
||||
|
||||
* Has simple configuration with YAML, avoiding copy-paste by applying customizable "roles"
|
||||
|
||||
* Uses inventories to scope and define the set of servers
|
||||
|
||||
* Fosters repeatable "playbook" runs, i.e. applying same configuration to a server twice should be idempotent
|
||||
|
||||
* Doesn’t suffer from feature matrix issues because by design it is a framework, not a full-fledged solution for configuration management. You cannot say "it supports only web servers X and Y, but not Z", as principally Ansible allows you to do _anything_ that is possible through manual server configuration.
|
||||
|
||||
|
||||
For a full introduction to Ansible, better read the [documentation](https://docs.ansible.com/ansible/index.html) first. This article assumes you have already made yourself familiar with the concepts and have some existing attempts of getting Ansible working for a certain use case, but want some guidance on improving the way you are working with Ansible.
|
||||
|
||||
The company behind Ansible gives [some official guidelines](https://www.ansible.com/blog/ansible-best-practices-essentials) which mostly relate to file structure, naming and other common rules. While these are helpful, as they are not immediately common sense for beginners, only a fraction of Ansible’s features and complexity of larger setups are touched by that small set of guidelines.
|
||||
|
||||
I would like to present my experience from roughly over 2 years of Ansible experience, during which I have used it for a test environment at work (allowing developers to test systems like in production), for configuring my laptop and eventually for setting up _this_ server and web application, and also my home server (a Raspberry Pi).
|
||||
|
||||
## Table of contents
|
||||
|
||||
* [Why Ansible over other frameworks?](#_why_ansible_over_other_frameworks)
|
||||
* [Choose your type of environment](#_choose_your_type_of_environment)
|
||||
* [Testing](#_testing)
|
||||
* [Staging/production](#_staging_production)
|
||||
* [Both non-production and production with one Ansible setup](#_both_non_production_and_production_with_one_ansible_setup)
|
||||
* [Careful when mixing manual and automated configuration](#_careful_when_mixing_manual_and_automated_configuration)
|
||||
* [Directory structure](#_directory_structure)
|
||||
* [Basic setup](#_basic_setup)
|
||||
* [Ansible configuration](#inventory-safe-default)
|
||||
* [Name tasks](#_name_tasks)
|
||||
* [Avoid skipping items](#avoid-skipping-items)
|
||||
* [Use and abuse of variables](#_use_and_abuse_of_variables)
|
||||
* [Tags](#_tags)
|
||||
* [sudo only where necessary](#_sudo_only_where_necessary)
|
||||
* [Assertions](#_assertions)
|
||||
* [Less code by using repetition primitives](#_less_code_by_using_repetition_primitives)
|
||||
* [Idempotency done right](#_idempotency_done_right)
|
||||
* [Leverage dynamic inventory](#dynamic-inventory)
|
||||
* [Modern Ansible features](#_modern_ansible_features)
|
||||
* [Off-topic: storing sensitive files](#storing-sensitive-files)
|
||||
* [Conclusion](#_conclusion)
|
||||
|
||||
## Why Ansible over other frameworks?
|
||||
|
||||
* Honestly, I did not compare many alternatives because the Ansible environment at work already existed when I joined and soon I believed Ansible to be the best option. The usual suspects Chef and Puppet did not really please me because the recipes do not really look like "infrastructure as code", but are too declarative and hard to understand in detail without looking at many files — while in a typical Ansible playbook, the actions taken can be read top-down like code.
|
||||
|
||||
* Many years ago, I built my own solution to deploy my personal web applications (["Site Deploy"](http://site-deploy.sourceforge.net/documentation/); UI-based). As hobby project, it never became popular or sophisticated enough, and eventually I learned that it suffers from the aforementioned feature matrix problem. Essentially it only supported the features relevant to me 🙄, without providing a framework to support anything on any server. Nevertheless, _Site Deploy_ already had support for configuring hosts with their connection data and services, with the help of variable substitution in most places. Or in other words: the very basic concepts of Ansible.
|
||||
|
||||
* Size of the user-base says a lot (cf. [their 2016 recap](https://www.ansible.com/blog/2016-community-year-in-review))
|
||||
|
||||
* Ansible aims at simple design, and becomes powerful by all the open-source modules to support services, applications, hardware, network, connections, etc.
|
||||
|
||||
* No server-side, persistent component required. Only Python needed to execute modules. Usual connection type is SSH, but custom modules are available for other types.
|
||||
|
||||
* Flat learning curve: once you understand the basic concepts (define hosts in inventory, set variables on different levels, write tasks in playbooks) and you know the commands/steps to configure a host manually, it’s easy to get started writing the same steps down in Ansible’s YAML format.
|
||||
|
||||
* Put simply, Ansible combines a set of hosts (inventory) with a list of applicable tasks (playbooks & roles), customizable with variables (at different places), allowing you to use pre-defined or own task modules and plugins (connection, value lookup, etc.). If you rolled your own, generic configuration management, you probably could not implement its principles much simpler. Since the concepts are so clearly separated, the source code (Python) is easy enough to read, if ever needed. Usually you will only have 2 situations to look into Ansible source code: learning how modules should be implemented and finding out about changed behavior when upgrading Ansible. The latter is not common and only occurred to me when switching from Ansible 1.8/1.9.x to 2.2.x which was quite a big step both in features, deprecations and also Ansible source code architecture itself.
|
||||
|
||||
* Change detection and idempotency. Whenever a task is run, there may be distinct outcomes: successfully changed, failed, skipped, unchanged. After running a playbook, you will have an overview of which tasks actually made changes on the target hosts. Usually, one would design playbooks in a way that running it a second time only gives "unchanged" outcomes, and Ansible’s modules support this idea of idempotency — for example, a `command` task can be marked as "already done that before, no changes required" by specifying `creates: /file/created/by/command` → once the file was successfully created, a repeated execution of the task module will not run the command again.
|
||||
|
||||
|
||||
## Choose your type of environment
|
||||
|
||||
Before we jump into practice, in the first thought we must consider what kind of Ansible-based setup we want to achieve, which greatly depends on the environment: work/personal, production/staging/testing, mixture of those…
|
||||
|
||||
### Testing
|
||||
|
||||
A test environment could have many faces: for instance, at my company we manage a separate Git repo for the test environment, unrelated to any production configuration and therefore very quick to modify for developers without lengthy code reviews or approval by devops, as no production system can be affected. Ansible is used to fully configure the system and our software within a virtual machine.
|
||||
|
||||
To spin up a VM, many solutions exist already — for instance [Vagrant](https://www.vagrantup.com/docs/getting-started/) with a small provisioning script that installs everything required for Ansible (only Python 😉) in the VM. We use a small Fabric script to bootstrap a FreeBSD VM and networking before continuing with Ansible.
|
||||
|
||||
### Staging/production
|
||||
|
||||
You should keep separate inventories for staging and production. If you don’t have staging, you should probably aim at automating staging setup with Ansible, since you already develop the production configuration in playbooks. But if you have both, the below recommendations apply.
|
||||
|
||||
### Both non-production and production with one Ansible setup
|
||||
|
||||
* When deploying both non-production and production environments from the same roles/playbooks, you must take care they don’t interfere with each other. For instance, you don’t want to send real e-mails to customers from staging, use different domain names, etc. The main way to decide on applying non-production vs. production properties should be your use of inventories and variables. An example will be discussed below ([dynamic inventory](#dynamic-inventory)).
|
||||
|
||||
* Careful — developers should not have live credentials such as SSH access to a production server, but probably be able to manage testing/staging systems?!
|
||||
|
||||
* GPG encryption of sensitive files or other protection to disallow unprivileged people from accessing production machines at all (mentioned in section [Storing sensitive files](#storing-sensitive-files))
|
||||
|
||||
* A safe default choice for inventories is required, and the default should most probably _not_ be production. This is described below in the section [Ansible configuration](#inventory-safe-default).
|
||||
|
||||
|
||||
## Careful when mixing manual and automated configuration
|
||||
|
||||
If you already have a production system manually set up — which is almost always the case, at least for initial OS installation steps which cannot be done via Ansible on physical servers — making the switch to fully automated configuration via Ansible is not easy. You may want to introduce automation step-by-step.
|
||||
|
||||
There are many imaginable ways to achieve that migration. I want to propose what I would do, admittedly without any real-world experience because I do not manage any production systems as developer.
|
||||
|
||||
* Develop playbooks and maintain [check mode and the `--diff` option](https://docs.ansible.com/ansible/playbooks_checkmode.html). This is not always easy and sometimes unnerving because you have to think both in normal mode (read-write) and check mode (read-only) when writing tasks, and apply appropriate options for modules that can’t handle it themselves (like `command`):
|
||||
|
||||
* `check_mode: no` (previously called `always_run: yes`)
|
||||
|
||||
* `changed_when`
|
||||
|
||||
* If you use tags: apply `tags: [ always ]` to tasks that e.g. provide results for subsequent tasks
|
||||
|
||||
|
||||
* Take care when making manual changes to servers. While often okay and necessary to react quickly, ensure the responsible people (e.g. devops team) can later reproduce the setup rather sooner than later with playbooks.
|
||||
|
||||
* Use [`{{ ansible_managed }}`](https://docs.ansible.com/ansible/intro_configuration.html#ansible-managed) to mark auto-generated files as such, so nobody unknowingly edits them manually
|
||||
|
||||
* Automate as much setup as you can, but only the parts that you are able to implement via Ansible without risk. For example, if you fear that an automatic database setup could go horribly wrong (like overwrite the existing production database), then rely on your distrust and do those steps manually.
|
||||
|
||||
|
||||
## Directory structure
|
||||
|
||||
Some [common directory layouts](https://docs.ansible.com/ansible/playbooks_best_practices.html#content-organization) are already part of the official documentation. In addition, you may want to separate your playbooks in subdirectories of `playbooks/` once your content grows too large. This cannot really be handled well in best practices because size and purpose of each project varies, so I just leave this on you to decide when time comes to "clean up". Note that if you use several playbook (sub-)directories and files relative to them (such as a custom `library` folder), you may have to symlink into the each directory containing playbooks.
|
||||
|
||||
## Basic setup
|
||||
|
||||
* It should be clear that Ansible uses text files and therefore should be versioned in a VCS like Git. Make sure you ignore files that should not be committed (for example in .gitignore: `*.retry`).
|
||||
|
||||
* Add something like `alias apl=ansible-playbook` in your shell. Or do you want to type `ansible-playbook` all the time?
|
||||
|
||||
* Require users to use at least a certain Ansible version, e.g. the latest version available in OS package managers at the time of starting your endeavors. You could have a little role `check-preconditions` doing this:
|
||||
|
||||
|
||||
# Check and require certain Ansible version. You should document why that
|
||||
# version is required, for instance:
|
||||
#
|
||||
# We require Ansible 2.2.1 or newer, see changelog
|
||||
# (https://github.com/ansible/ansible/blob/devel/CHANGELOG.md#221-the-battle-of-evermore---2017-01-16):
|
||||
# > Fixes a bug where undefined variables in with_* loops would cause a task
|
||||
# > failure even if the when condition would cause the task to be skipped.
|
||||
- name: Check Ansible version
|
||||
assert:
|
||||
that: '(ansible_version.major, ansible_version.minor, ansible_version.revision) >= (2, 2, 1)'
|
||||
msg: 'Please install the recommended version 2.2.1+. You have Ansible {{ ansible_version.string }}.'
|
||||
run_once: yes
|
||||
|
||||
## Ansible configuration
|
||||
|
||||
[`ansible.cfg`](https://docs.ansible.com/ansible/intro_configuration.html) allows you to tweak many settings to be a little saner than the defaults.
|
||||
|
||||
I recommend the following:
|
||||
|
||||
[defaults]
|
||||
# Default to no fact gathering because it's slow and "explicit is better
|
||||
# than implicit". Depending how you use variables, you may rather explicitly
|
||||
# define variables instead of relying on facts. You can enable this on
|
||||
# a per-playbook basis with `gather_facts: yes`.
|
||||
gathering = explicit
|
||||
# You should default either 1) to a non-risky inventory (not production)
|
||||
# or 2) point to a nonexistent one so that the person explicitly needs to
|
||||
# specify which one to use. I find the alternative 1) the least risky,
|
||||
# because 2) may lead to people creating shortcuts to deploy to live machines
|
||||
# which defeats the purpose of having a safer default here.
|
||||
inventory = inventories/test
|
||||
# Cows are scared of playbook developers
|
||||
nocows = 1
|
||||
|
||||
# Point to your local collection of extras, e.g. roles
|
||||
roles_path = ./roles
|
||||
|
||||
[ssh_connection]
|
||||
# Enable SSH multiplexing to increase performance
|
||||
pipelining = True
|
||||
control_path = /tmp/ansible-ssh-%%h-%%p-%%r
|
||||
|
||||
Choosing a safe default for the inventory is obviously important, thinking about recent catastrophic events like the [Amazon S3 outage](https://aws.amazon.com/message/41926/) that originated from a typo. Inventory names should not be confusable with each other, e.g. avoid using a prefix (`inv_live`, `inv_test`) because people hastily using tab completion may quickly introduce a typo.
|
||||
|
||||
If you are annoyed by `*.retry` files being created next to playbooks which hinders filename tab completion, an environment variable `ANSIBLE_RETRY_FILES_SAVE_PATH` lets you put them in a different place. For myself, I never use them as I’m not working with hundreds of hosts matching per playbook, so I just disable them with `ANSIBLE_RETRY_FILES_ENABLED=no`. Since that is a per-person decision, it should be an environment variable and not go into `ansible.cfg`.
|
||||
|
||||
## Name tasks
|
||||
|
||||
While already outlined in the [mentioned best practices article](https://www.ansible.com/blog/ansible-best-practices-essentials), I’d like to stress this point: names, comments and readability enable you and others to understand playbooks and roles later on. Ansible output on its own is too concise to really tell you the exact spot which is currently executing, and sometimes in large setups you will be searching that spot where you canceled (Ctrl+C) or a task failed fatally. Naming even the single tasks comes in handy here. Or tooling like [ARA](https://github.com/openstack/ara) which I personally did not try yet (overkill for me). After all we’re doing programming, and no reasonable language would allow you to make public functions unnamed/anonymous.
|
||||
|
||||
- name: 'Create directories for service {{ daemontools_service_name }}'
|
||||
file:
|
||||
state: directory
|
||||
dest: '{{ item }}'
|
||||
owner: '{{ daemontools_service_user }}'
|
||||
with_items: '{{ daemontools_service_directories }}'
|
||||
|
||||
In recent versions of Ansible, variables in the task `name` will be correctly substituted by their value in the console output, giving you visual feedback which part of the play is executing. That will be especially important once your configuration management project is growing and you run large collections of playbooks that execute a certain role (this example: `daemontools_service`) multiple times, for example to create a couple of permanent services.
|
||||
|
||||
Another advantage of this technique is that you can start where a play canceled/failed previously using the `--start-at-task="Task name"` option. That might not always work, e.g. if a task depends on a previously `register:`-ed variable, but is often helpful to save time by skipping all previously succeeded tasks. If you use static task names like "Install packages", then `--start-at-task="Install packages"` will start at the first occurrence of that task name in the play instead of a specific one ("Install dependencies for service XYZ").
|
||||
|
||||
## Avoid skipping items
|
||||
|
||||
…because it might hurt idempotency. What if your Ansible playbook adds a cronjob based on a boolean variable, and later you change the value to false? Using `when: my_bool` (value now changed to `no`) will skip the task, leaving the cronjob intact even though you expected it to be removed or disabled.
|
||||
|
||||
Here’s a slightly more complicated example: I had to set up a service that should be disabled by default until the developer enables it (because it would log error messages all the time unless the developer had established a required, manual SSH tunnel). Considerations:
|
||||
|
||||
* When configuring that service (let’s call the role `daemontools_service`; [daemontools](https://cr.yp.to/daemontools.html) are great to set up and manage services on *nix), we cannot simply enable/disable the service conditionally: the service should only be disabled initially (first playbook run = service created for the first time on remote machine) and on boot, but its state should be untouched if the developer had already enabled the service manually. Or in other words (since that fact is not easy to find out), leave state untouched if the service was already configured by a previous playbook run (= idempotency).
|
||||
|
||||
* You might also want an option to toggle enabling/disabling the service by default, so I’ll show that as well
|
||||
|
||||
|
||||
- hosts: xyz
|
||||
|
||||
vars:
|
||||
xyz_service_name: xyz-daemon
|
||||
|
||||
# Knob to enable/disable service by default (on reboot, and after
|
||||
# initial configuration)
|
||||
xyz_always_enabled: yes
|
||||
|
||||
roles:
|
||||
- role: daemontools_service
|
||||
daemontools_service_name: '{{ xyz_service_name }}'
|
||||
# Contrived variable, leaving state untouched should be the default
|
||||
# behavior unless you want to risk in production that services are
|
||||
# unintentionally enabled or disabled by a playbook run.
|
||||
daemontools_service_enabled: 'do_not_change_state'
|
||||
daemontools_service_other_variables: ...
|
||||
|
||||
tasks:
|
||||
- name: Disable XYZ service on boot
|
||||
cron:
|
||||
# We know that the role will symlink into /var/service,
|
||||
# as usual for daemontools
|
||||
job: "svc -d /var/service/{{ xyz_service_name }}"
|
||||
name: "xyz_default_disabled"
|
||||
special_time: "reboot"
|
||||
disabled: "{{ xyz_always_enabled }}"
|
||||
# ...or...
|
||||
# state: "{{ 'absent' if xyz_always_enabled else 'present' }}"
|
||||
tags: [ cron ]
|
||||
|
||||
- name: Disable XYZ service initially
|
||||
# After *all* initial configuration steps succeeded, take the service
|
||||
# down (`svc -d`) and mark the service as created so we...
|
||||
shell: "svc -d /var/service/{{ xyz_service_name }} && touch /var/service/{{ xyz_service_name }}/.created"
|
||||
args:
|
||||
# ...don't disable the service again if playbook is run again
|
||||
# (as someone may have enabled the service manually in the meantime).
|
||||
creates: "/var/service/{{ xyz_service_name }}/.created"
|
||||
when: not xyz_always_enabled
|
||||
tags: [ cron ]
|
||||
|
||||
## Use and abuse of variables
|
||||
|
||||
The most important principle for variables is that you should know which variables are used when looking at a portion of "Ansible code" (YAML). As an Ansible beginner, you might have 1) wondered a few times, or looked up, in which [order of precedence](https://docs.ansible.com/ansible/playbooks_variables.html#variable-precedence-where-should-i-put-a-variable) variables are taken into account. Or 2) you might have just given up and asked the author what is happening there. Like in software development, both 1) and 2) are fatal mistakes that hamper productivity — code must be readable (hopefully top-down or by looking within the surrounding 100 lines) and understandable by colleagues and other contributors. The case that you even _had_ to check the precedence shows the problem in the first place! **Variables should be specified at exactly one place** (or two places if a variable has a reasonable, overridable default value), **as close as possible to their usage** while still being at the relevant location and **most variables should be ultimately mandatory** so that Ansible loudly complains if a variable is missing. Let us look at a few examples to see what these basic rules mean.
|
||||
|
||||
[exampleservers]
|
||||
192.168.178.34
|
||||
|
||||
[all:vars]
|
||||
# Global helper variables.
|
||||
#
|
||||
# I tend to use these specific ones because when inside a role, Ansible 1.9.x
|
||||
# did not correctly find files/templates in some cases (if called from playbook
|
||||
# or dependency of other role). Not sure if that is still required for 2.x,
|
||||
# so don't copy-paste without understanding the need! These are really
|
||||
# just examples.
|
||||
my_playbooks_dir={{ inventory_dir + "/../playbooks" }}
|
||||
my_roles_dir={{ inventory_dir + "/../roles" }}
|
||||
|
||||
# With dynamic inventories, you can structure your per-host and per-group
|
||||
# variables in a nicer way than this INI file top-down format. If you use
|
||||
# INI files, at least try to create some structure, like alphabetical sorting
|
||||
# for hosts and groups.
|
||||
[exampleservers:vars]
|
||||
# Here, put only variables that belong to matching servers in general,
|
||||
# not to a functional component
|
||||
ansible_ssh_user=dog
|
||||
|
||||
Let’s look at an example role "mysql" which installs a MySQL server, optionally creates a database and then optionally gives privileges to the database (also allows value `*` for all databases) to a user:
|
||||
|
||||
# ...contrived excerpt...
|
||||
- name: Ensure database {{ database_name }} exists
|
||||
mysql_db:
|
||||
name: 'ourprefix_{{ database_name }}'
|
||||
when: database_name is defined and database_name != "*"
|
||||
|
||||
- name: Ensure database user {{ database_user }} exists and has access to {{ database_name }}
|
||||
mysql_user:
|
||||
name: '{{ database_user }}'
|
||||
password: '{{ database_password }}'
|
||||
priv: '{{ database_name }}.*:ALL'
|
||||
host: '%'
|
||||
when: database_user is defined and database_user
|
||||
# ...
|
||||
|
||||
The good parts first:
|
||||
|
||||
* Once `database_user` is given, the required variable `database_password` is mandatory, i.e. not checked with another `database_password is defined`.
|
||||
|
||||
* Variables used in task names, so that Ansible output clearly tells you what _exactly_ is currently happening
|
||||
|
||||
|
||||
But many things should be fixed here:
|
||||
|
||||
* Role (I called this example role "mysql") is doing way too many things at once without having a proper name. It should be split up into several roles: MySQL server installation, database creation, user & privilege setup. If you really find yourself doing these three things together repeatedly, you can still create an uber-role "mysql" that depends on the others.
|
||||
|
||||
* Role variables should be prefixed with the role name (e.g. `mysql_database_name`) because Ansible has no concept of namespaces or scoping these variables only to the role. This helps finding out quickly where a variable comes from. In contrast, host groups in Ansible are a way to scope variables so they are only available to a certain set of hosts.
|
||||
|
||||
* The database name prefix `ourprefix_` seems to be a hardcoded string. First of all, this led to a bug — privileges are not correctly applied to the user in the second task because the prefix was forgotten. The hardcoded string could be an internal variable (mark those with an underscore!) defined in the defaults file `roles/mysql/defaults/main.yml`: `_database_name_prefix: 'ourprefix_' # comment describing why it’s hardcoded`, and must be used wherever applicable. Whenever the value needs changing, you only need to touch one location.
|
||||
|
||||
* The special value `database_name: '*'` must be considered. Because the role has more than one responsibility (remember software engineering best practices?!), the variables have too many meanings. As said, there had better be a role "mysql_user" that only handles user creation and privileges — inside such a scoped role, using _one_ special value turns out to be less bug-prone.
|
||||
|
||||
* `database_user is defined and database_user` is again only necessary because the role is doing too much. In general, you should almost never use such a conditional. For no real reason, an empty value is principally allowed, and the task skipped in that case, and also if the variable is not specified. Once you decide to rename the variable and forget to replace one occurrence, you suddenly always skip the task. Whenever you can, let Ansible complain loudly when a variable is undefined, instead of e.g. skipping a task conditionally. In this example, splitting up the role is the solution to immediately make the variables mandatory. In other cases, you could introduce a default value for a role variable and allow users to override that value.
|
||||
|
||||
|
||||
Other practices regarding variables and their values and inline templates:
|
||||
|
||||
* Consistently name your variables. Just like code, Ansible plays should be grep-able. A simple text search through your Ansible setup repo should immediately find the source of a variable and other places where it is used.
|
||||
|
||||
* Avoid indirections like includes or `vars_files` if possible to keep relevant variables close to their use. In some cases, these helpers can shorten repeated code, but usually they just add one more level of having to jump around between files to grasp where a value comes from.
|
||||
|
||||
* Don’t use the special one-line dictionary syntax `mysql_db: name="{{ database_name }}" state="present" encoding="utf8mb4"`. YAML is very readable per se, so why use Ansible’s crippled syntax instead? It’s okay to use for single-variable tasks, though.
|
||||
|
||||
* On the same note, remove defaults which are obvious, such as the usual `state: present`. The "official" blog post on best practices recommends otherwise, but I like to keep code short and boilerplate-less.
|
||||
|
||||
* Decide for one quoting style and use it consistently: double quotes (`dest: "/etc/some.conf"`), single quotes (`dest: '/etc/some.conf'`) plus decision if you quote things that don’t need it (`dest: /etc/some.conf`). Keep in mind that `dest: {{ var }}` is not possible (must be quoted), and that `mode: 0755` (chmod) will give an unexpected result (no octal number support), so recommended practice is of course `mode: '0755'`.
|
||||
|
||||
* Also decide for one style for spacing and writing Jinja templates. I prefer `dest: '{{ var|int + 5 }}'` over `dest: '{{var | int + 5}}'` but only staying consistent is key, not the style you choose.
|
||||
|
||||
* You don’t need `---` at the top of YAML files. Just leave them away unless you know what it means.
|
||||
|
||||
|
||||
More rules can be shown best in a playbook example:
|
||||
|
||||
- hosts: web-analytics-database
|
||||
|
||||
vars:
|
||||
# Under `vars`, only put variables that really must be available in several
|
||||
# roles and tasks below. They have high precedence and therefore are prone
|
||||
# to clash with other variables of the same name (if you didn't follow
|
||||
# the principle of only one definition), or may set a value in one of the
|
||||
# below roles that you didn't want to be set! Therefore the role name
|
||||
# prefix is so important (`mysql_user_name` instead of `username` because
|
||||
# the latter might also be used in many other places and is hard to grep
|
||||
# for if used all over the place).
|
||||
|
||||
# When writing many playbooks, you probably don't want to hardcode your
|
||||
# DBA's username everywhere, but define a variable `database_admin_username`.
|
||||
# The rule of putting it as close as possible to its use tells you to
|
||||
# create a group "database-servers" containing all database hosts and put
|
||||
# the variable into `group_vars/database-servers.yml` so it's only available
|
||||
# in the limited scope.
|
||||
# Using variable name prefix `wa_` for "web analytics" as example.
|
||||
wa_mysql_user_name_prefix: '{{ database_admin_username }}'
|
||||
|
||||
roles:
|
||||
- role: mysql_server
|
||||
|
||||
# [Comment describing why we chose MySQL 5.5...]
|
||||
# Alternatively (but more risky than requiring it to be defined explicitly),
|
||||
# this might have a default value in the role, stating the version you
|
||||
# normally use in production.
|
||||
mysql_server_version: '5.5'
|
||||
|
||||
# Admin with full privileges
|
||||
- role: mysql_user
|
||||
mysql_user_name: '{{ wa_mysql_user_name_prefix }}_admin'
|
||||
|
||||
# This should not have a default. Defaulting to `ALL` means that on a
|
||||
# playbook mistake, a new user may get all privileges!
|
||||
mysql_user_privileges: 'ALL'
|
||||
|
||||
# Production passwords should not be committed to version control
|
||||
# in plaintext. See article section "Storing sensitive files".
|
||||
mysql_user_password: '{{ lookup("gpgfile", "secure/web-analytics-database.password") }}'
|
||||
|
||||
# Read-only access
|
||||
- role: mysql_user
|
||||
mysql_user_name: '{{ wa_mysql_user_name_prefix }}_readonly'
|
||||
mysql_user_privileges: 'SELECT'
|
||||
mysql_user_password: '{{ lookup("gpgfile", "secure/web-analytics-database.readonly.password") }}'
|
||||
|
||||
tasks:
|
||||
# With well-developed roles, you don't need extra {pre_}tasks!
|
||||
|
||||
## Tags
|
||||
|
||||
Use tags only for limiting to tasks for speed reasons, as in "only update config files". They should not be used to select a "function" of a playbook or perform regular tasks, or else one fine day you may forget to specify `-t only-do-xyz` and it will take down Amazon S3 or so 😜. It’s a debug and speed tool and not otherwise necessary. Better make your playbooks smaller and more task-focused if you use playbooks for repeated (maintenance) tasks.
|
||||
|
||||
- hosts: webservers
|
||||
|
||||
pre_tasks:
|
||||
- name: Include some vars (not generally recommended, see rules for variables)
|
||||
include_vars:
|
||||
file: myvars.yml
|
||||
# This must be tagged `always` because otherwise the variables are not available below
|
||||
tags: [ always ]
|
||||
|
||||
roles:
|
||||
- role: mysql
|
||||
# ...
|
||||
- role: mysql_user
|
||||
# ...
|
||||
|
||||
tasks:
|
||||
- name: Insert test data into SQL database
|
||||
# Mark with a separate tag that allows you to quickly apply new test
|
||||
# data to the existing MySQL database without having to wait for the
|
||||
# `mysql*` roles to finish (which would probably finish without changes).
|
||||
tags: [ test-sql ]
|
||||
# ...the task...
|
||||
|
||||
- name: Get system info
|
||||
# Contrived example command - in reality you should use `ansible_*` facts!
|
||||
command: 'uname -a'
|
||||
register: _uname_call
|
||||
# This needs tag `always` because the below task requires the result
|
||||
# `_uname_call`, and also has tags.
|
||||
tags: [ always ]
|
||||
check_mode: no
|
||||
# Just assume this task to be "unchanged"; instead tasks that depend
|
||||
# on the result will detect changes.
|
||||
changed_when: no
|
||||
|
||||
- name: Write system info
|
||||
copy:
|
||||
content: 'System: {{ _uname_call.stdout }}'
|
||||
dest: '/the/destination/path'
|
||||
tags: [ info ]
|
||||
|
||||
## sudo only where necessary
|
||||
|
||||
> The command failed, so I used `sudo command` and it worked fine. I’m now doing that everywhere because it’s easier.
|
||||
|
||||
It should be obvious to devops people, and hopefully also software developers, how very wrong this is. Just like you would not do that for manual commands, you also should not use `become: yes` globally for a whole playbook. Better only use it for tasks that actually need root rights. The `become` flag can be assigned to task blocks, avoiding repetition.
|
||||
|
||||
Another downside of "sudo everywhere" is that you have to take care of owner/group membership of directories and files you create, instead of defaulting to creating files owned by the connecting user.
|
||||
|
||||
## Assertions
|
||||
|
||||
If you ever had a to debug a case where a YAML dictionary was missing a key, you will know how bad Ansible is at telling you where an error came from (does not even tell you the dictionary variable name). I have found my own way to deal with that: assert a condition before actually running into the default error message. Only a very simple plugin is required. I opened a [pull request](https://github.com/ansible/ansible/pull/22529) already but the maintainers did not like the approach. Still I will recommend it here because of practical experience.
|
||||
|
||||
In `ansible.cfg`, ensure you have:
|
||||
|
||||
filter_plugins = ./plugins/filter
|
||||
|
||||
Then add the plugin `plugins/filter/assert.py`:
|
||||
|
||||
from ansible import errors
|
||||
|
||||
|
||||
def _assert(value, msg=''):
|
||||
# You can leave this condition away if you think it's too strict.
|
||||
# It's supposed to help find typos and type mistakes in assertion conditions.
|
||||
if not isinstance(value, bool):
|
||||
raise errors.AnsibleFilterError('assert filter requires boolean as input, got %s' % type(value))
|
||||
|
||||
if not value:
|
||||
raise errors.AnsibleFilterError('assertion failed: %s' % (msg or '<no message given>',))
|
||||
return ''
|
||||
|
||||
|
||||
class FilterModule(object):
|
||||
filter_map = {
|
||||
'assert': _assert,
|
||||
}
|
||||
|
||||
def filters(self):
|
||||
return self.filter_map
|
||||
|
||||
And use it like so:
|
||||
|
||||
- name: My task
|
||||
command: 'somecommand {{ (somevar|int > 5)|assert("somevar must be number > 5") }}{{ somevar }}'
|
||||
|
||||
This will only be able to test Jinja expressions, which are mostly but not 100% Python, but that should be enough.
|
||||
|
||||
## Less code by using repetition primitives
|
||||
|
||||
Ever wrote something like this?
|
||||
|
||||
- name: Do something with A
|
||||
command: dosomething A
|
||||
args:
|
||||
creates: /etc/somethingA
|
||||
when: '{{ is_admin_user["A"] }}'
|
||||
|
||||
- name: Do something with B
|
||||
command: dosomething --a-little-different B
|
||||
args:
|
||||
creates: /etc/somethingB
|
||||
when: '{{ is_admin_user["B"] }}'
|
||||
|
||||
A little exaggerated, but chances are that you suffered from copy-pasting too much Ansible code a few times in your configuration management career, and had the usual share of copy-paste mistakes and typos. Use [`with_items` and friends](https://docs.ansible.com/ansible/playbooks_loops.html) to your advantage:
|
||||
|
||||
- name: Do something with {{ item.name }}
|
||||
# At a task-level scope, it's totally okay to use non-mandatory variables
|
||||
# because you have to read only these few lines to understand what it's
|
||||
# doing. Use quoting if you want to support e.g. whitespace in values - just
|
||||
# saying, of course it's unusual on *nix...
|
||||
command: 'dosomething {{ item.args|default("") }} "{{ item.name }}"'
|
||||
args:
|
||||
creates: '/etc/something{{ item.name }}'
|
||||
# This is again following the rule of mandatory variables: making dictionary
|
||||
# keys mandatory protects you from typos and, in this case, from forgetting
|
||||
# to add people to a list. Get a good error message instead of just
|
||||
# `KeyError: B` by using the aforementioned assert module.
|
||||
when: '{{ item.name in is_admin_user|assert("User " + item.name + " missing in is_admin_user") }}{{ is_admin_user[item.name] }}'
|
||||
with_items:
|
||||
- name: A
|
||||
- name: B
|
||||
args: '--a-little-different'
|
||||
|
||||
More readable (once it gets bigger than my contrived example), and still does the same thing without being prone to copy-paste mistakes and complexity.
|
||||
|
||||
## Idempotency done right
|
||||
|
||||
This term was already mentioned a few times above. I want to give more hints on how to achieve repeatable playbook runs. "Idempotent" effectively means that on the second run, everything is green and no actual changes happened, which Ansible calls "ok" but in a well-developed setup means "unchanged" or "read-only action was performed".
|
||||
|
||||
The advantages should be pretty clear: not only can you see the exact `--diff` of what would happen on remote servers but also it gives visual feedback of what has _really_ changed (even if you don’t use diff mode).
|
||||
|
||||
Only a few considerations are necessary when writing tasks and playbooks, and you can get perfect idempotency in most cases:
|
||||
|
||||
* Avoid skipping items in certain cases (explained [above](#avoid-skipping-items))
|
||||
|
||||
* Often you need a `command` or `shell` task to perform very specific work. These tasks are always considered "changed" unless you define e.g. the `creates` argument or use `changed_when`.
|
||||
Example: `changed_when: _previously_registered_process_result.stdout == ''`
|
||||
On the same note, you may want to use `failed_when` in special cases, like if a program exits with code 0 even on errors.
|
||||
|
||||
* Always use same inputs. For example, don’t write a new timestamp into a file at every task run, but detect that the file is already up-to-date and does not need to be changed.
|
||||
|
||||
* Use built-in modules like `lineinfile`, `file`, `synchronize`, `copy` and `template` which support the relevant arguments to get idempotency if used right. They also typically fully support checked mode and other features that are hard to achieve yourself. Avoid `command`/`shell` if built-ins can be used instead.
|
||||
|
||||
* The argument `force: no` can be used for some modules to ensure that a task is only run once. For instance, you want a configuration template copied once if not existent, but afterwards manage it manually or with other tools, use `copy` and `force: no` to only upload the file if not yet existent, but on repeated run don’t make any changes to the existing remote file. This is not exactly related to idempotency but sometimes a valid use case.
|
||||
|
||||
|
||||
## Leverage dynamic inventory
|
||||
|
||||
Who needs to fiddle around carefully in check mode every time you change a production system, if there’s a staging environment which can bear a downtime if something goes wrong? Dynamic inventories can help separate staging and production in the most readable and — you guessed it — dynamic way.
|
||||
|
||||
Separate environments like test, staging or production of course have different properties like
|
||||
|
||||
* IP addresses and networks
|
||||
|
||||
* Host and domain names (FQDN)
|
||||
|
||||
* Set of hosts. Production software may be distributed to multiple servers, while your staging may simply be installed on one server or virtual machine.
|
||||
|
||||
* Other values
|
||||
|
||||
|
||||
Ideally, all of these should be specified in variables, so that you can use different values for each environment in the respective inventory, but with consistent variable names. In your roles and playbooks, you can then mostly ignore the fact that you have different environments — except for tasks that e.g. should not or only run in production, but that should also be decided by a variable (→ `when: not is_production`).
|
||||
|
||||
Check the official introduction to [Dynamic Inventories](https://docs.ansible.com/ansible/intro_dynamic_inventory.html) and [Developing Dynamic Inventory Sources](https://docs.ansible.com/ansible/dev_guide/developing_inventory.html) to understand my example inventory script. It forces the domain suffix `.test` for the "test" environment, and no suffix for the "live" environment.
|
||||
|
||||
#!/usr/bin/env python
|
||||
from __future__ import print_function
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import sys
|
||||
|
||||
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
|
||||
|
||||
# One way to go "dynamic": decide inventory type (test, staging, production)
|
||||
# based on inventory directory. Remember that Ansible calls the first file
|
||||
# found if you specify a directory as inventory. Symlinking the same script
|
||||
# into different directories allows you to use one inventory script
|
||||
# for several environments.
|
||||
IS_LIVE = {'live': True, 'test': False}[os.path.basename(SCRIPT_DIR)]
|
||||
DOMAIN_SUFFIX = '' if IS_LIVE else '.test'
|
||||
|
||||
|
||||
host_to_vars = {
|
||||
'first': {
|
||||
'public_ip': '1.2.3.4',
|
||||
'public_hostname': 'first.mystuff.example.com',
|
||||
},
|
||||
'second': {
|
||||
'public_ip': '1.2.3.5',
|
||||
'public_hostname': 'second.mystuff.example.com',
|
||||
},
|
||||
}
|
||||
groups = {
|
||||
'webservers': ['first', 'second'],
|
||||
}
|
||||
|
||||
|
||||
# Avoid human mistakes by applying test settings everywhere at once (instead
|
||||
# of inline per-variable)
|
||||
for host, variables in host_to_vars.items():
|
||||
if 'public_hostname' in variables:
|
||||
# Just an example. Realistically you may want to change `public_ip`
|
||||
# as well, plus other variables that differ between test and production.
|
||||
variables['public_hostname'] += DOMAIN_SUFFIX
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--debug', action='store_true', default=False)
|
||||
parser.add_argument('--host')
|
||||
parser.add_argument('--list', action='store_true', default=False)
|
||||
args = parser.parse_args()
|
||||
|
||||
def printJson(v):
|
||||
print(json.dumps(v, sort_keys=True, indent=4 if args.debug else None, separators=(',', ': ' if args.debug else ':')))
|
||||
|
||||
if args.host is not None:
|
||||
printJson(host_to_vars.get(args.host, {}))
|
||||
elif args.list:
|
||||
# Allow Ansible to only make one call to this script instead
|
||||
# of one per host.
|
||||
# See https://docs.ansible.com/ansible/dev_guide/developing_inventory.html#tuning-the-external-inventory-script
|
||||
groups['_meta'] = {
|
||||
'hostvars': host_to_vars,
|
||||
}
|
||||
printJson(groups)
|
||||
else:
|
||||
parser.print_usage(sys.stderr)
|
||||
print('Use either --host or --list', file=sys.stderr)
|
||||
exit(1)
|
||||
|
||||
Much more customization is possible with dynamic inventories. Another example: in my company, we use FreeBSD servers with our software installed and managed in jails. For developer testing, we have an Ansible setup to roughly resemble the production configuration. Unfortunately, at the time of writing, Ansible does not directly support configuration of jails or a concept of "child hosts". Therefore, we simply created an SSH connection plugin to connect to jails. Each jail looks like a regular host to Ansible, with the special naming pattern `jailname@servername`. Our dynamic inventory allows us to easily configure the hierarchy of groups > servers > jails and all their variables.
|
||||
|
||||
For personal and simple setups, in which only a few servers are involved, you might as well just use the INI-style inventory file format that Ansible uses by default. For the above example inventory, that would mean to split into two files `test.ini` and `live.ini` and managing them separately.
|
||||
|
||||
Dynamic inventories have one major downside compared to INI files: they don’t allow text diffs. Or in other words, you see the script change when looking at your VCS history, not the inventory diff. If you want a more explicit history, you may want a different setup: auto-generate INI inventory files with some script or template, then commit the INI files whenever you change something. Of course you will have to make sure to actually re-generate the files (potential for human mistakes!). I will leave this as exercise to you to decide.
|
||||
|
||||
## Modern Ansible features
|
||||
|
||||
While you may have introduced Ansible years back when it was still in v1.x or earlier stages, the framework is in very active development both by Red Hat and the community. [Ansible 2.0](https://www.ansible.com/blog/ansible-2.0-launch) introduced many powerful features and preparations for future improvements:
|
||||
|
||||
* [Task blocks (try-except-finally)](https://docs.ansible.com/ansible/playbooks_blocks.html): useful to perform cleanups if a block of tasks should be applied "either all or none of the tasks". Also can reduce repeated code because you can apply `when`, `become` and other flags to a block.
|
||||
|
||||
* [Dynamic includes](https://docs.ansible.com/ansible/playbooks_roles.html#dynamic-versus-static-includes): you can now use variables in includes, e.g. `- include: 'server-setup-{{ environment_name }}.yml'`
|
||||
|
||||
* [Conditional roles](https://docs.ansible.com/ansible/playbooks_conditionals.html#applying-when-to-roles-and-includes) are nothing new. I had some trouble with related bugs in 1.8.x, but those are obviously resolved and `role: […] when: somecondition` can help in some use cases to make code cleaner (similar to task blocks).
|
||||
|
||||
* Plugins were refactored to cater for clean, more maintainable APIs, and more changes will come in 2.x updates (like the persistent connections framework). Migrating your own library to 2.x should be simple in most cases.
|
||||
|
||||
|
||||
## Off-topic: storing sensitive files
|
||||
|
||||
For this special use case, I don’t have a recommendation since I never compared different approaches.
|
||||
|
||||
[Vault support](https://docs.ansible.com/ansible/playbooks_vault.html) seems to be a good start but seems to only support protection by a single password — a password which you then have to share among the team.
|
||||
|
||||
Several [built-in lookups](https://docs.ansible.com/ansible/playbooks_lookups.html) exist for password retrieval and storage, such as "password" (only supports plaintext) and Ansible 2.3’s "passwordstore".
|
||||
|
||||
In my company, we store somewhat sensitive files (such as passwords for financial test systems) in our developers' Ansible test environment repository, but in GPG-encrypted form. A script contains a list of files and people and encrypts the files. The encrypted .gpg files are committed, while original files should be in `.gitignore`. Within playbooks, we use a lookup plugin to decrypt the respective files. That way, access can be limited to a "need to know" group of people. While this is not tested for production use, it may be an idea to try and incorporate this extra level of security if you are dealing with sensitive information.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Ansible can be complex and overwhelming after developing playbooks in a wrong way for a long time. Just like for source code, readability, simplicity and common practices do not come naturally and yet are important to keep your Ansible code base lean and understandable. I’ve shown basic and advanced principles and some examples to structure your setup. Many things are left out of this general article, because either I have no experience with it yet (like Ansible Galaxy) or it would just be too much for an introductory article.
|
||||
|
||||
Happy automation!
|
||||
@@ -0,0 +1,15 @@
|
||||
---
|
||||
tags:
|
||||
- IT
|
||||
- Development/Ansible
|
||||
---
|
||||
|
||||
- [Using Ansible's command and shell modules properly](http://willthames.github.io/2016/09/21/using-command-and-shell-in-ansible.html)
|
||||
- [Usage — Ansible Lint Documentation](https://ansible-lint.readthedocs.io/en/latest/usage.html)
|
||||
- [Best Practices — Ansible Documentation](https://docs.ansible.com/ansible/latest/user\_guide/playbooks\_best_practices.html)
|
||||
- [ansible - Install multiple packages in a single task | ansible Tutorial](https://riptutorial.com/ansible/example/21247/install-multiple-packages-in-a-single-task)
|
||||
- [Installing multiple packages in Ansible - Stack Overflow](https://stackoverflow.com/questions/54944080/installing-multiple-packages-in-ansible)
|
||||
- [ansible.builtin.apt – Manages apt-packages — Ansible Documentation](https://docs.ansible.com/ansible/latest/collections/ansible/builtin/apt_module.html)
|
||||
- [Installing Software and Other Packages - Ansible Tips and Tricks](https://ansible-tips-and-tricks.readthedocs.io/en/latest/os-dependent-tasks/installing_packages/)
|
||||
|
||||
[[Setting up Sonarqube with Ansible - Matt v.d. West]]
|
||||
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,32 @@
|
||||
---
|
||||
tags:
|
||||
- IT
|
||||
- Development/Asciidoctor
|
||||
---
|
||||
|
||||
## Asciidoctor Dokumentation
|
||||
http://asciidoctor.org/docs/user-manual/
|
||||
http://asciidoctor.org/docs/user-manual/#curved
|
||||
http://asciidoctor.org/docs/user-manual/#xref
|
||||
http://asciidoctor.org/docs/user-manual/#inter-document-cross-references
|
||||
http://asciidoctor.org/docs/user-manual/#subs
|
||||
http://asciidoctor.org/docs/user-manual/#stem
|
||||
http://asciidoctor.org/docs/user-manual/#docinfo-file
|
||||
http://asciidoctor.org/docs/user-manual/#user-toc
|
||||
http://asciidoctor.org/docs/user-manual/#user-abstract
|
||||
http://asciidoctor.org/docs/user-manual/#user-preface
|
||||
http://asciidoctor.org/docs/user-manual/#user-dedication
|
||||
http://asciidoctor.org/docs/user-manual/#user-index
|
||||
https://www.google.de/search?client=firefox-b&dcr=0&q=asciidoctor+nomenclaturen&oq=asciidoctor+nomenclature&gs_l=psy-ab.3.0.33i160k1.2236749.2240179.0.2242507.17.17.0.0.0.0.147.1143.14j2.16.0....0...1.1.64.psy-ab..1.15.1026...0j0i19k1j0i22i30i19k1j0i67k1j0i22i30k1.MK-Kb32TERQ
|
||||
|
||||
https://github.com/lordofthejars/continuous-documentation/blob/master/src/main/asciidoc/manual.adoc
|
||||
https://github.com/lordofthejars/continuous-documentation
|
||||
http://www.vogella.com/tutorials/AsciiDoc/article.html
|
||||
|
||||
https://rubygems.org/gems/asciidoctor-latex
|
||||
|
||||
http://www.sphinx-doc.org/en/stable/rest.html
|
||||
http://asciidoctor.org/docs/
|
||||
http://www.vogella.com/tutorials/AsciiDoc/article.html
|
||||
|
||||
https://github.com/asciidoctor/asciidoctor-maven-examples/tree/master/asciidoctor-pdf-with-theme-example
|
||||
@@ -0,0 +1,65 @@
|
||||
---
|
||||
title: Bash Shortcuts
|
||||
updated: 2019-02-26 10:05:06Z
|
||||
created: 2019-02-26 10:04:57Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Shell/Bash
|
||||
- Development/Shell
|
||||
---
|
||||
|
||||
Command Editing Shortcuts
|
||||
|
||||
Ctrl + a – go to the start of the command line
|
||||
Ctrl + e – go to the end of the command line
|
||||
Ctrl + k – delete from cursor to the end of the command line
|
||||
Ctrl + u – delete from cursor to the start of the command line
|
||||
Ctrl + w – delete from cursor to start of word (i.e. delete backwards one word)
|
||||
Ctrl + y – paste word or text that was cut using one of the deletion shortcuts (such as the one above) after the cursor
|
||||
Ctrl + xx – move between start of command line and current cursor position (and back again)
|
||||
Alt + b – move backward one word (or go to start of word the cursor is currently on)
|
||||
Alt + f – move forward one word (or go to end of word the cursor is currently on)
|
||||
Alt + d – delete to end of word starting at cursor (whole word if cursor is at the beginning of word)
|
||||
Alt + c – capitalize to end of word starting at cursor (whole word if cursor is at the beginning of word)
|
||||
Alt + u – make uppercase from cursor to end of word
|
||||
Alt + l – make lowercase from cursor to end of word
|
||||
Alt + t – swap current word with previous
|
||||
Ctrl + f – move forward one character
|
||||
Ctrl + b – move backward one character
|
||||
Ctrl + d – delete character under the cursor
|
||||
Ctrl + h – delete character before the cursor
|
||||
Ctrl + t – swap character under cursor with the previous one
|
||||
|
||||
|
||||
Command Recall Shortcuts
|
||||
|
||||
Ctrl + r – search the history backwards
|
||||
Ctrl + g – escape from history searching mode
|
||||
Ctrl + p – previous command in history (i.e. walk back through the command history)
|
||||
Ctrl + n – next command in history (i.e. walk forward through the command history)
|
||||
Alt + . – use the last word of the previous command
|
||||
|
||||
|
||||
Command Control Shortcuts
|
||||
|
||||
Ctrl + l – clear the screen
|
||||
Ctrl + s – stops the output to the screen (for long running verbose command)
|
||||
Ctrl + q – allow output to the screen (if previously stopped using command above)
|
||||
Ctrl + c – terminate the command
|
||||
Ctrl + z – suspend/stop the command
|
||||
|
||||
|
||||
Bash Bang (!) Commands
|
||||
|
||||
|
||||
Bash also has some handy features that use the ! (bang) to allow you to do some funky stuff with bash commands.
|
||||
|
||||
!! - run last command
|
||||
!blah – run the most recent command that starts with ‘blah’ (e.g. !ls)
|
||||
!blah:p – print out the command that !blah would run (also adds it as the latest command in the command history)
|
||||
!$ – the last word of the previous command (same as Alt + .)
|
||||
!$:p – print out the word that !$ would substitute
|
||||
!* – the previous command except for the last word (e.g. if you type ‘find some_file.txt /‘, then !* would give you ‘find some_file.txt‘)
|
||||
!*:p – print out what !* would substitute
|
||||
|
||||
|
||||
@@ -0,0 +1,131 @@
|
||||
---
|
||||
title: Breaking apart the monolith
|
||||
updated: 2022-08-18 09:56:26Z
|
||||
created: 2022-08-18 09:55:38Z
|
||||
source: https://github.com/readme/guides/maintainer-monolith
|
||||
tags:
|
||||
- IT
|
||||
- IT/OpenSource
|
||||
- Development
|
||||
---
|
||||
|
||||
## [Breaking apart the monolith](https://github.com/readme/guides/maintainer-monolith)
|
||||
|
||||
Why must maintainers be “full stack”?
|
||||
|
||||
In software engineering, it is completely normal to specialize, whether working on product, platform, infrastructure, creative coding, or data science.
|
||||
|
||||
But when it comes to open source, we expect maintainers to be consummate generalists: documentation, community, design, marketing, project management, support... oh, and code. And we expect them to deliver this full-stack maintainership for life.
|
||||
|
||||
For independent open source to be sustainable and accessible to all, we must explore ways of breaking apart the “maintainer monolith.” Fortunately, we don’t have to invent our solutions from scratch—we can look to centuries-old models of servant leadership from the government and social sectors for inspiration.
|
||||
|
||||
The solution may start with a simple file we’ll call MAINTAINERS.md.
|
||||
|
||||
*Note: For the purposes of this article we focus on independent open source, as separate from commercial open source, which has* [*its own, different, issues*](https://www.elastic.co/blog/why-license-change-AWS)*.*
|
||||
|
||||
### **The social contract: Money doesn’t solve burnout**
|
||||
|
||||
Many efforts to “fix” open source have been focused on the **financial** elements, while the **human** side has received a lot of sympathy but not a lot of solutions. The three main support models for independent open source that have emerged are corporate/personal sponsorship, paid support/training, and issue bounties. All are well intentioned and necessary, but together remain insufficient. In the JS ecosystem, [Babel’s funding struggles](https://babeljs.io/blog/2021/05/10/funding-update) have presaged open source developers [turning to venture capital](https://rome.tools/blog/announcing-rome-tools-inc/), or just diverting their efforts to closed source.
|
||||
|
||||
Money is, of course, very helpful toward long-term sustainability and funding dedicated, high-quality maintenance. But:
|
||||
|
||||
- Discretionary funding is biased toward high visibility projects over critical, “boring” infrastructure, exacerbating the natural inequality *by putting a dollar amount on it.*
|
||||
- Automated funding is biased toward older projects (that aren’t necessarily actively maintained and may not need the money) and susceptible to ecosystem manipulation (people can [break up code](https://www.reddit.com/r/webdev/comments/c5z8m3/whats_up_with_all_the_small_packages_in_node/) with the effect of goosing total numbers).
|
||||
- Allocation of funds in a collaborative project is difficult, as contribution isn’t adequately captured by the number of commits or lines of code or issues triaged.
|
||||
- Even the well-funded projects have budgets far below what the maintainers could get in a normal software job anyway.
|
||||
- Realistically only a very small percentage of projects ever attract a meaningful amount of funding, so the majority of open source needs non-financial solutions.
|
||||
|
||||
No matter how you slice it, the conclusion is clear: There will always be some amount of financial sacrifice in choosing to work on open source, and solutions that **only** address financial over human elements may make things worse by ratcheting up expectations for maintainers.
|
||||
|
||||
The motivations for the vast majority of maintainers will likely always be more personal than financial. This is a feature, not a bug: a movement predicated on *giving away* intellectual property encounters many conflicts if we insist that the only way for it to be sustainable is to capture more value. And yet, despite genuine desire for industry impact and personal satisfaction, generation after generation of maintainers starts strong and burns out just as quickly. Some attrition is to be expected—interests and priorities shift as life goes on—but we probably lose more than our fair share of maintainer talent because of our inadequate **social**, not **financial**, contracts.
|
||||
|
||||
Amidst a spate of recent, high-profile burnouts in the community, there’s been an increasing interest in the social contract of open source.
|
||||
|
||||
These are some actual quotes from maintainers:
|
||||
|
||||
- “Sorry everybody, I failed... In order to develop \[Docz\], I need to wake up every day 3 hours earlier and go to bed 3 hours later.” - [Pedro Nauck](https://github.com/pedronauck/docz/issues/1634)
|
||||
- “I do not wish to come off as anything but welcoming, however, I’ve made the decision to keep this project closed to contributions for my own mental health and long term viability of the project.” - [Ben Johnson](https://news.ycombinator.com/item?id=25940195)
|
||||
- “Running a successful open source project is just *Good Will Hunting* in reverse, where you start out as a respected genius and end up being a janitor who gets into fights.” - [Chris Aniszczyk](https://twitter.com/cra)
|
||||
- “For years, I work on open-source projects but that sometimes means to be exposed. I am no longer strong enough for receiving free insults or sometime threats like it was in 2019.” - [Thomas Schneider](https://framagit.org/tom79/fedilab/-/issues/498)
|
||||
- “Maybe we can find a future for package indexes where maintainers of packages are not burdened further because the internet started depending on it. It’s not the fault of the creator that their creation became popular.” - [Armin Ronacher](https://lucumr.pocoo.org/2022/7/9/congratulations/)
|
||||
|
||||
**Does this sound like a healthy social contract to you?**
|
||||
|
||||
Many efforts focus on chastising the unreasonably demanding open source user. Brett Cannon, member of the Python Steering Council, [recently wrote](https://snarky.ca/the-social-contract-of-open-source/) about the philosophical divide between the literal legal open source contract (where software is provided for free, “as is”) and its mismatched social equivalent (where users treat maintainers as a means to an end instead of viewing every commit as a gift). Jan Lehnardt says the only way to cope is to [stop caring](https://writing.jan.io/2017/03/06/sustainable-open-source-the-maintainers-perspective-or-how-i-learned-to-stop-caring-and-love-open-source.html).
|
||||
|
||||
Nadia Eghbal’s books [*Working in Public*](https://www.amazon.com/Working-Public-Making-Maintenance-Software/dp/0578675862) and [*Roads and Bridges*](https://www.fordfoundation.org/work/learning/research-reports/roads-and-bridges-the-unseen-labor-behind-our-digital-infrastructure/) dive deeper into the complex relationships between maintainers and their contributors, users, collaborators, and platforms. Open source has diversified from the Stallman-era “[communitarian kibbutz](https://www.thepullrequest.com/p/nadia-eghbal)” model into what she terms federations, clubs, stadiums, and toys. A clear understanding of what model a given project operates in can help to fine-tune the expectations of participation around it:
|
||||
|
||||

|
||||
|
||||
But perhaps not enough attention has been paid toward reframing the us-vs-them mentality dividing maintainers and everyone else. What if it were a norm for people to smoothly step up and down into service? Maintainership would not become an indefinite, unscoped, unlimited burden.
|
||||
|
||||
### **Look outside tech**
|
||||
|
||||
I'm inspired by social clubs and city governments and believe people are driven by much more than money. They desire social status, power, impact, legacy, community, service, freedom, and a myriad of other motivations. The open source movement is only 20-something years old, but there are far more time-tested forms of public service and communal governance ideas that can invoke these:
|
||||
|
||||
- **Elections and fixed terms.** Local government has its flaws, but by and large it seems to work for many towns and cities. Members of a community see issues that they wish to fix, and run for elections to gain the mandate to fix them. Those that don’t win the election aren’t locked out forever; they can wait for the next term and campaign again. In open source, this could mean project governance becomes more participatory, an alternative to the status quo where a project founder becomes the Benevolent Dictator For Life by default.
|
||||
- **Real budgets with public accountability.** Some amount of prestige does flow from having central financial authority. Social clubs have dues, governments collect taxes, and foundations have memberships. What if voting was tied to some form of financial contribution? This is less about “fixing open source” by financial means as discussed above, but more about raising the stakes and endowing the maintainer position with more than informal power. Public accountability, such as audited accounts and open meetings, would also be essential for meaningful budgets.
|
||||
- **Separate responsibilities**. Nobody in government or society is “full stack.” There is a president, a vice president, a treasurer, a social chair, and so on. This limits the expectations of each role and also helps provide some career progression should the person aspire toward more involved service. It also addresses [the loneliness problem](https://blog.alexellis.io/the-5-pressures-of-leadership/) that many maintainers report having.
|
||||
|
||||
Everything I have discussed so far takes the form of centralized power, but I would be remiss not to acknowledge that Decentralized Autonomous Organizations have arisen to provide a distributed, and necessarily open source, alternative. However these are younger and [much less proven](https://www.gemini.com/cryptopedia/the-dao-hack-makerdao), and until such time that DAOs can write code, I think they can be ignored.
|
||||
|
||||
I am not an expert in government studies and social service, so I hope others will point out better models to study or well-known pitfalls to avoid. But I feel confident that those of us in tech, trying to figure out these very human problems, can have something to learn by borrowing ideas from these time-tested models from outside tech.
|
||||
|
||||
### **What a MAINTAINERS.md could look like**
|
||||
|
||||
Every open source project has a file listing their code dependencies, like package.json or Gemfile or go.mod. The movement toward documenting for human dependencies has been relatively slower on the uptick:
|
||||
|
||||
- [CONTRIBUTING.md](https://github.blog/2012-09-17-contributing-guidelines/) is the earliest (2012) form of human-file, but focuses on documenting internal code style and collaboration instructions, rather than acknowledging present contributors.
|
||||
- [CODEOWNERS.md](https://github.blog/2017-07-06-introducing-code-owners/) is a 2017 addition to GitHub, documenting who owns which parts of a codebase (and therefore needs to sign off on code reviews impacting those).
|
||||
- Last year, [ARCHITECTURE.md](https://matklad.github.io/2021/02/06/ARCHITECTURE.md.html) gained some adoption by introducing project architecture, embraced in projects like [rust-analyzer](https://github.com/rust-analyzer/rust-analyzer/blob/d7c99931d05e3723d878bea5dc26766791fa4e69/docs/dev/architecture.md), [esbuild](https://github.com/evanw/esbuild/blob/master/docs/architecture.md), and [Caddy](https://caddyserver.com/docs/architecture).
|
||||
|
||||
All of these make the open source project more welcoming to new contributors, but are still very focused on code as the primary unit of contribution. In 2016, [Kent C. Dodds](https://twitter.com/kentcdodds/status/703845487552532480) expanded this scope dramatically by introducing [All Contributors](https://allcontributors.org/), which recognizes no less than 33 different types of contributions that people can make to an open source project. However, because contribution is binary and permanent, it can get difficult to manage a long list of drive-by contributions and doesn’t specifically incentivize people to step up as core maintainers.
|
||||
|
||||

|
||||
|
||||
In 2019, GitHub made a big step towards separating out maintainer concerns by [adding triage and maintain roles](https://github.blog/?s=triage): *“If a contributor proves their ability to drive technical discussions or lead development of your project, you can empower them to take on additional issue or repository management responsibilities without needing to also grant the ability to modify your project’s source code or change potentially destructive repository settings.”*
|
||||
|
||||
This move is mostly based on security and trust level, and did not get much fanfare as it is just another collaborator permission setting inside GitHub. However, I believe it was a critical step forward to splitting up the maintainer monolith. I think this idea needs to develop beyond a small platform feature into a prominent element of open source with cultural significance.
|
||||
|
||||
Here’s what a minimal *MAINTAINERS.md* could potentially include:
|
||||
|
||||
```markdown
|
||||
Maintainers Team
|
||||
|
||||
Jun 2021 - May 2023
|
||||
- Tech Lead:
|
||||
- Documentarian:
|
||||
- Issue/PR Triage:
|
||||
|
||||
Jun 2019 - May 2021
|
||||
- Tech Lead:
|
||||
- Documentarian:
|
||||
- Issue/PR Triage:
|
||||
```
|
||||
|
||||
Other roles that can be added as needed:
|
||||
|
||||
- [Community Builder](https://dev.to/dx/technical-community-builder-is-the-hottest-new-job-in-tech-8cl)
|
||||
- Project Manager
|
||||
- User Researcher
|
||||
- Quality Assurance
|
||||
- Feature Owner
|
||||
- Event Planner
|
||||
- Marketing/Developer Relations
|
||||
- Designer
|
||||
- Treasurer
|
||||
- Intern
|
||||
|
||||
I highlighted the first three roles because those are the most central: the reality is that most projects do not have a massive volunteer crew to recruit for these roles. MAINTAINERS.md needs to scale together with project size. The other important element of this design is the limited term, which makes it clear that others can step up if they wish, and that the commitment isn’t for life.
|
||||
|
||||
Although MAINTAINERS.md would primarily be a cultural movement, GitHub and other code hosting platforms can play a huge role in recognizing these forms of specialized maintainership, from pride of placement in the project sidebar, to special badges that recognize maintainers together with the cohort they served on.
|
||||
|
||||
Y Combinator founders are famous for identifying by the cohort they were in as a shibboleth: “I was in YC W18” indicates immediate club membership to another YC founder. Why can’t we create an equivalent career milestone for open source service?
|
||||
|
||||
At Airbyte, where we have hundreds of open source connectors for every kind of data source imaginable, we are experimenting with this separation of concerns by creating an official [community maintainer program](https://airbyte.com/maintainer-program) that provides both special status and monetary rewards for PR and issue triage without needing to assume “full stack” responsibility. This is the first of many steps towards a new [participative model](https://airbyte.com/blog/a-new-license-to-future-proof-the-commoditization-of-data-integration#a-preview-to-airbytes-participative-model) that we hope will blaze the path for the growing group of venture-backed developer tools companies with significant community value add.
|
||||
|
||||
More extreme options are also on the table: for example, if nobody steps up to maintain a project, it might automatically get archived. Risk of loss, even though reversible, has proven to be a key motivator for projects like [Storybook](https://medium.com/storybookjs/the-storybook-story-dd3c1ab0d2ce) and [youtube-dl](https://github.com/ytdl-org/youtube-dl) where the community has stepped in to resuscitate a project.
|
||||
|
||||
### **Taking the next step**
|
||||
|
||||
MAINTAINERS.md is the first step towards finding **human solutions to human problems**: how do you incentivize collaboration and public service at a level far beyond what you can ever pay for? Solving this requires a fuller understanding of human motivations, but here’s the good news: Humanity has been working on solutions for this since before computers existed. Computer science, meet social science.
|
||||
@@ -0,0 +1,898 @@
|
||||
---
|
||||
title: Getting Started | Building web applications with Spring Boot and Kotlin
|
||||
updated: 2023-04-04 06:44:54Z
|
||||
created: 2023-04-04 06:44:54Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/SpringBoot
|
||||
- Development/Kotlin
|
||||
source: https://spring.io/guides/tutorials/spring-boot-kotlin/
|
||||
---
|
||||
|
||||
This tutorial shows you how to build efficiently a sample blog application by combining the power of [Spring Boot](https://spring.io/projects/spring-boot/) and [Kotlin](https://kotlinlang.org/).
|
||||
|
||||
## Creating a New Project
|
||||
|
||||
First we need to create a Spring Boot application, which can be done in a number of ways.
|
||||
|
||||
### Using the Initializr Website
|
||||
|
||||
Visit [https://start.spring.io](https://start.spring.io/) and choose the Kotlin language. Gradle is the most commonly used build tool in Kotlin, and it provides a Kotlin DSL which is used by default when generating a Kotlin project, so this is the recommended choice. But you can also use Maven if you are more comfortable with it. Notice that you can use https://start.spring.io/#!language=kotlin&type=gradle-project-kotlin to have Kotlin and Gradle selected by default.
|
||||
|
||||
1. Select "Gradle - Kotlin" or "Maven" depending on which build tool you want to use
|
||||
2. Enter the following artifact coordinates: `blog`
|
||||
3. Add the following dependencies:
|
||||
- Spring Web
|
||||
- Mustache
|
||||
- Spring Data JPA
|
||||
- H2 Database
|
||||
- Spring Boot DevTools
|
||||
4. Click "Generate Project".
|
||||
|
||||
The .zip file contains a standard project in the root directory, so you might want to create an empty directory before you unpack it.
|
||||
|
||||
### Using command line
|
||||
|
||||
You can use the Initializr HTTP API [from the command line](https://docs.spring.io/initializr/docs/current/reference/html/#command-line) with, for example, curl on a UN*X like system:
|
||||
|
||||
```shell
|
||||
$ mkdir blog && cd blog
|
||||
$ curl https://start.spring.io/starter.zip -d language=kotlin -d type=gradle-project-kotlin -d dependencies=web,mustache,jpa,h2,devtools -d packageName=com.example.blog -d name=Blog -o blog.zip
|
||||
```
|
||||
|
||||
Add `-d type=gradle-project` if you want to use Gradle.
|
||||
|
||||
### Using IntelliJ IDEA
|
||||
|
||||
Spring Initializr is also integrated in IntelliJ IDEA Ultimate edition and allows you to create and import a new project without having to leave the IDE for the command-line or the web UI.
|
||||
|
||||
To access the wizard, go to File | New | Project, and select Spring Initializr.
|
||||
|
||||
Follow the steps of the wizard to use the following parameters:
|
||||
|
||||
- Artifact: "blog"
|
||||
- Type: "Gradle - Kotlin" or "Maven"
|
||||
- Language: Kotlin
|
||||
- Name: "Blog"
|
||||
- Dependencies: "Spring Web Starter", "Mustache", "Spring Data JPA", "H2 Database" and "Spring Boot DevTools"
|
||||
|
||||
## Understanding the Gradle Build
|
||||
|
||||
If you’re using a Maven Build, you can [skip to the dedicated section](#maven-build).
|
||||
|
||||
### Plugins
|
||||
|
||||
In addition to the obvious [Kotlin Gradle plugin](https://kotlinlang.org/docs/gradle.html), the default configuration declares the [kotlin-spring plugin](https://kotlinlang.org/docs/all-open-plugin.html#spring-support) which automatically opens classes and methods (unlike in Java, the default qualifier is `final` in Kotlin) annotated or meta-annotated with Spring annotations. This is useful to be able to create `@Configuration` or `@Transactional` beans without having to add the `open` qualifier required by CGLIB proxies for example.
|
||||
|
||||
In order to be able to use Kotlin non-nullable properties with JPA, [Kotlin JPA plugin](https://kotlinlang.org/docs/reference/compiler-plugins.html#jpa-support) is also enabled. It generates no-arg constructors for any class annotated with `@Entity`, `@MappedSuperclass` or `@Embeddable`.
|
||||
|
||||
`build.gradle.kts`
|
||||
|
||||
```kotlin
|
||||
import org.jetbrains.kotlin.gradle.tasks.KotlinCompile
|
||||
|
||||
plugins {
|
||||
id("org.springframework.boot") version "3.0.1"
|
||||
id("io.spring.dependency-management") version "1.1.0"
|
||||
kotlin("jvm") version "1.8.0"
|
||||
kotlin("plugin.spring") version "1.8.0"
|
||||
kotlin("plugin.jpa") version "1.8.0"
|
||||
}
|
||||
```
|
||||
|
||||
### Compiler options
|
||||
|
||||
One of Kotlin’s key features is [null-safety](https://kotlinlang.org/docs/null-safety.html) \- which cleanly deals with `null` values at compile time rather than bumping into the famous `NullPointerException` at runtime. This makes applications safer through nullability declarations and expressing "value or no value" semantics without paying the cost of wrappers like `Optional`. Note that Kotlin allows using functional constructs with nullable values; check out this [comprehensive guide to Kotlin null-safety](https://www.baeldung.com/kotlin/null-safety).
|
||||
|
||||
Although Java does not allow one to express null-safety in its type-system, Spring Framework provides null-safety of the whole Spring Framework API via tooling-friendly annotations declared in the `org.springframework.lang` package. By default, types from Java APIs used in Kotlin are recognized as [platform types](https://kotlinlang.org/docs/reference/java-interop.html#null-safety-and-platform-types) for which null-checks are relaxed. [Kotlin support for JSR 305 annotations](https://kotlinlang.org/docs/java-interop.html#jsr-305-support) \+ Spring nullability annotations provide null-safety for the whole Spring Framework API to Kotlin developers, with the advantage of dealing with `null` related issues at compile time.
|
||||
|
||||
This feature can be enabled by adding the `-Xjsr305` compiler flag with the `strict` options.
|
||||
|
||||
`build.gradle.kts`
|
||||
```kotlin
|
||||
tasks.withType<KotlinCompile> {
|
||||
kotlinOptions {
|
||||
freeCompilerArgs += "-Xjsr305=strict"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Dependencies
|
||||
|
||||
2 Kotlin specific libraries are required (the standard library is added automatically with Gradle) for such Spring Boot web application and configured by default:
|
||||
|
||||
- `kotlin-reflect` is Kotlin reflection library
|
||||
- `jackson-module-kotlin` adds support for serialization/deserialization of Kotlin classes and data classes (single constructor classes can be used automatically, and those with secondary constructors or static factories are also supported)
|
||||
|
||||
`build.gradle.kts`
|
||||
```kotlin
|
||||
dependencies {
|
||||
implementation("org.springframework.boot:spring-boot-starter-data-jpa")
|
||||
implementation("org.springframework.boot:spring-boot-starter-mustache")
|
||||
implementation("org.springframework.boot:spring-boot-starter-web")
|
||||
implementation("com.fasterxml.jackson.module:jackson-module-kotlin")
|
||||
implementation("org.jetbrains.kotlin:kotlin-reflect")
|
||||
runtimeOnly("com.h2database:h2")
|
||||
runtimeOnly("org.springframework.boot:spring-boot-devtools")
|
||||
testImplementation("org.springframework.boot:spring-boot-starter-test")
|
||||
}
|
||||
```
|
||||
|
||||
Recent versions of H2 require special configuration to properly escape reserved keywords like `user`.
|
||||
|
||||
`src/main/resources/application.properties`
|
||||
```properties
|
||||
spring.jpa.properties.hibernate.globally_quoted_identifiers=true
|
||||
spring.jpa.properties.hibernate.globally_quoted_identifiers_skip_column_definitions = true
|
||||
```
|
||||
|
||||
Spring Boot Gradle plugin automatically uses the Kotlin version declared via the Kotlin Gradle plugin.
|
||||
|
||||
You can now take a [deeper look at the generated application](#understanding-generated-app).
|
||||
|
||||
## Understanding the Maven Build
|
||||
|
||||
### Plugins
|
||||
|
||||
In addition to the obvious [Kotlin Maven plugin](https://kotlinlang.org/docs/reference/using-maven.html), the default configuration declares the [kotlin-spring plugin](https://kotlinlang.org/docs/reference/compiler-plugins.html#spring-support) which automatically opens classes and methods (unlike in Java, the default qualifier is `final` in Kotlin) annotated or meta-annotated with Spring annotations. This is useful to be able to create `@Configuration` or `@Transactional` beans without having to add the `open` qualifier required by CGLIB proxies for example.
|
||||
|
||||
In order to be able to use Kotlin non-nullable properties with JPA, [Kotlin JPA plugin](https://kotlinlang.org/docs/reference/compiler-plugins.html#jpa-support) is also enabled. It generates no-arg constructors for any class annotated with `@Entity`, `@MappedSuperclass` or `@Embeddable`.
|
||||
|
||||
`pom.xml`
|
||||
```xml
|
||||
<build>
|
||||
<sourceDirectory>${project.basedir}/src/main/kotlin</sourceDirectory>
|
||||
<testSourceDirectory>${project.basedir}/src/test/kotlin</testSourceDirectory>
|
||||
<plugins>
|
||||
<plugin>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-maven-plugin</artifactId>
|
||||
</plugin>
|
||||
<plugin>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<artifactId>kotlin-maven-plugin</artifactId>
|
||||
<configuration>
|
||||
<compilerPlugins>
|
||||
<plugin>jpa</plugin>
|
||||
<plugin>spring</plugin>
|
||||
</compilerPlugins>
|
||||
<args>
|
||||
<arg>-Xjsr305=strict</arg>
|
||||
</args>
|
||||
</configuration>
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<artifactId>kotlin-maven-noarg</artifactId>
|
||||
<version>${kotlin.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<artifactId>kotlin-maven-allopen</artifactId>
|
||||
<version>${kotlin.version}</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
</plugin>
|
||||
</plugins>
|
||||
</build>
|
||||
```
|
||||
|
||||
One of Kotlin’s key features is [null-safety](https://kotlinlang.org/docs/null-safety.html) \- which cleanly deals with `null` values at compile time rather than bumping into the famous `NullPointerException` at runtime. This makes applications safer through nullability declarations and expressing "value or no value" semantics without paying the cost of wrappers like `Optional`. Note that Kotlin allows using functional constructs with nullable values; check out this [comprehensive guide to Kotlin null-safety](https://www.baeldung.com/kotlin-null-safety).
|
||||
|
||||
Although Java does not allow one to express null-safety in its type-system, Spring Framework provides null-safety of the whole Spring Framework API via tooling-friendly annotations declared in the `org.springframework.lang` package. By default, types from Java APIs used in Kotlin are recognized as [platform types](https://kotlinlang.org/docs/reference/java-interop.html#null-safety-and-platform-types) for which null-checks are relaxed. [Kotlin support for JSR 305 annotations](https://kotlinlang.org/docs/reference/java-interop.html#jsr-305-support) \+ Spring nullability annotations provide null-safety for the whole Spring Framework API to Kotlin developers, with the advantage of dealing with `null` related issues at compile time.
|
||||
|
||||
This feature can be enabled by adding the `-Xjsr305` compiler flag with the `strict` options.
|
||||
|
||||
Notice also that Kotlin compiler is configured to generate Java 8 bytecode (Java 6 by default).
|
||||
|
||||
### Dependencies
|
||||
|
||||
3 Kotlin specific libraries are required for such Spring Boot web application and configured by default:
|
||||
|
||||
- `kotlin-stdlib` is the Kotlin standard library
|
||||
- `kotlin-reflect` is Kotlin reflection library
|
||||
- `jackson-module-kotlin` adds support for serialization/deserialization of Kotlin classes and data classes (single constructor classes can be used automatically, and those with secondary constructors or static factories are also supported)
|
||||
|
||||
`pom.xml`
|
||||
```xml
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-data-jpa</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-mustache</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-web</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.fasterxml.jackson.module</groupId>
|
||||
<artifactId>jackson-module-kotlin</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<artifactId>kotlin-reflect</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<artifactId>kotlin-stdlib</artifactId>
|
||||
</dependency>
|
||||
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-devtools</artifactId>
|
||||
<scope>runtime</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.h2database</groupId>
|
||||
<artifactId>h2</artifactId>
|
||||
<scope>runtime</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-test</artifactId>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
```
|
||||
|
||||
## Understanding the generated Application
|
||||
|
||||
`src/main/kotlin/com/example/blog/BlogApplication.kt`
|
||||
```kotlin
|
||||
package com.example.blog
|
||||
|
||||
import org.springframework.boot.autoconfigure.SpringBootApplication
|
||||
import org.springframework.boot.runApplication
|
||||
|
||||
@SpringBootApplication
|
||||
class BlogApplication
|
||||
|
||||
fun main(args: Array<String>) {
|
||||
runApplication<BlogApplication>(*args)
|
||||
}
|
||||
```
|
||||
|
||||
Compared to Java, you can notice the lack of semicolons, the lack of brackets on empty class (you can add some if you need to declare beans via `@Bean` annotation) and the use of `runApplication` top level function. `runApplication<BlogApplication>(*args)` is Kotlin idiomatic alternative to `SpringApplication.run(BlogApplication::class.java, *args)` and can be used to customize the application with following syntax.
|
||||
|
||||
`src/main/kotlin/com/example/blog/BlogApplication.kt`
|
||||
```kotlin
|
||||
fun main(args: Array<String>) {
|
||||
runApplication<BlogApplication>(*args) {
|
||||
setBannerMode(Banner.Mode.OFF)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Writing your first Kotlin controller
|
||||
|
||||
Let’s create a simple controller to display a simple web page.
|
||||
|
||||
`src/main/kotlin/com/example/blog/HtmlController.kt`
|
||||
```kotlin
|
||||
package com.example.blog
|
||||
|
||||
import org.springframework.stereotype.Controller
|
||||
import org.springframework.ui.Model
|
||||
import org.springframework.ui.set
|
||||
import org.springframework.web.bind.annotation.GetMapping
|
||||
|
||||
@Controller
|
||||
class HtmlController {
|
||||
|
||||
@GetMapping("/")
|
||||
fun blog(model: Model): String {
|
||||
model["title"] = "Blog"
|
||||
return "blog"
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Notice that we are using here a [Kotlin extension](https://kotlinlang.org/docs/extensions.html) that allows to add Kotlin functions or operators to existing Spring types. Here we import the `org.springframework.ui.set` extension function in order to be able to write `model["title"] = "Blog"` instead of `model.addAttribute("title", "Blog")`. The [Spring Framework KDoc API](https://docs.spring.io/spring-framework/docs/current/kdoc-api/) lists all the Kotlin extensions provided to enrich the Java API.
|
||||
|
||||
We also need to create the associated Mustache templates.
|
||||
|
||||
`src/main/resources/templates/header.mustache`
|
||||
```html
|
||||
<html>
|
||||
<head>
|
||||
<title>{{title}}</title>
|
||||
</head>
|
||||
<body>
|
||||
```
|
||||
|
||||
`src/main/resources/templates/footer.mustache`
|
||||
|
||||
`src/main/resources/templates/blog.mustache`
|
||||
```html
|
||||
{{> header}} <h1>{{title}}</h1> {{> footer}}
|
||||
```
|
||||
|
||||
Start the web application by running the `main` function of `BlogApplication.kt`, and go to `http://localhost:8080/`, you should see a sober web page with a "Blog" headline.
|
||||
|
||||
## Testing with JUnit 5
|
||||
|
||||
JUnit 5 now used by default in Spring Boot provides various features very handy with Kotlin, including [autowiring of constructor/method parameters](https://docs.spring.io/spring/docs/current/spring-framework-reference/testing.html#testcontext-junit-jupiter-di) which allows to use non-nullable `val` properties and the possibility to use `@BeforeAll`/`@AfterAll` on regular non-static methods.
|
||||
|
||||
### Writing JUnit 5 tests in Kotlin
|
||||
|
||||
For the sake of this example, let’s create an integration test in order to demonstrate various features:
|
||||
|
||||
- We use real sentences between backticks instead of camel-case to provide expressive test function names
|
||||
- JUnit 5 allows to inject constructor and method parameters, which is a good fit with Kotlin read-only and non-nullable properties
|
||||
- This code leverages `getForObject` and `getForEntity` Kotlin extensions (you need to import them)
|
||||
|
||||
`src/test/kotlin/com/example/blog/IntegrationTests.kt`
|
||||
```kotlin
|
||||
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
|
||||
class IntegrationTests(@Autowired val restTemplate: TestRestTemplate) {
|
||||
|
||||
@Test
|
||||
fun `Assert blog page title, content and status code`() {
|
||||
val entity = restTemplate.getForEntity<String>("/")
|
||||
assertThat(entity.statusCode).isEqualTo(HttpStatus.OK)
|
||||
assertThat(entity.body).contains("<h1>Blog</h1>")
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
### Test instance lifecycle
|
||||
|
||||
Sometimes you need to execute a method before or after all tests of a given class. Like Junit 4, JUnit 5 requires by default these methods to be static (which translates to [`companion object`](https://kotlinlang.org/docs/object-declarations.html#companion-objects) in Kotlin, which is quite verbose and not straightforward) because test classes are instantiated one time per test.
|
||||
|
||||
But Junit 5 allows you to change this default behavior and instantiate test classes one time per class. This can be done in [various ways](https://junit.org/junit5/docs/current/user-guide/#writing-tests-test-instance-lifecycle), here we will use a property file to change the default behavior for the whole project:
|
||||
|
||||
`src/test/resources/junit-platform.properties`
|
||||
```properties
|
||||
junit.jupiter.testinstance.lifecycle.default = per_class
|
||||
```
|
||||
|
||||
With this configuration, we can now use `@BeforeAll` and `@AfterAll` annotations on regular methods like shown in updated version of `IntegrationTests` above.
|
||||
|
||||
`src/test/kotlin/com/example/blog/IntegrationTests.kt`
|
||||
```kotlin
|
||||
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
|
||||
class IntegrationTests(@Autowired val restTemplate: TestRestTemplate) {
|
||||
|
||||
@BeforeAll
|
||||
fun setup() {
|
||||
println(">> Setup")
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `Assert blog page title, content and status code`() {
|
||||
println(">> Assert blog page title, content and status code")
|
||||
val entity = restTemplate.getForEntity<String>("/")
|
||||
assertThat(entity.statusCode).isEqualTo(HttpStatus.OK)
|
||||
assertThat(entity.body).contains("<h1>Blog</h1>")
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `Assert article page title, content and status code`() {
|
||||
println(">> TODO")
|
||||
}
|
||||
|
||||
@AfterAll
|
||||
fun teardown() {
|
||||
println(">> Tear down")
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
## Creating your own extensions
|
||||
|
||||
Instead of using util classes with abstract methods like in Java, it is usual in Kotlin to provide such functionalities via Kotlin extensions. Here we are going to add a `format()` function to the existing `LocalDateTime` type in order to generate text with the English date format.
|
||||
|
||||
`src/main/kotlin/com/example/blog/Extensions.kt`
|
||||
```kotlin
|
||||
fun LocalDateTime.format(): String = this.format(englishDateFormatter)
|
||||
|
||||
private val daysLookup = (1..31).associate { it.toLong() to getOrdinal(it) }
|
||||
|
||||
private val englishDateFormatter = DateTimeFormatterBuilder()
|
||||
.appendPattern("yyyy-MM-dd")
|
||||
.appendLiteral(" ")
|
||||
.appendText(ChronoField.DAY_OF_MONTH, daysLookup)
|
||||
.appendLiteral(" ")
|
||||
.appendPattern("yyyy")
|
||||
.toFormatter(Locale.ENGLISH)
|
||||
|
||||
private fun getOrdinal(n: Int) = when {
|
||||
n in 11..13 -> "${n}th"
|
||||
n % 10 == 1 -> "${n}st"
|
||||
n % 10 == 2 -> "${n}nd"
|
||||
n % 10 == 3 -> "${n}rd"
|
||||
else -> "${n}th"
|
||||
}
|
||||
|
||||
fun String.toSlug() = lowercase(Locale.getDefault())
|
||||
.replace("\n", " ")
|
||||
.replace("[^a-z\\d\\s]".toRegex(), " ")
|
||||
.split(" ")
|
||||
.joinToString("-")
|
||||
.replace("-+".toRegex(), "-")
|
||||
```
|
||||
|
||||
We will leverage these extensions in the next section.
|
||||
|
||||
## Persistence with JPA
|
||||
|
||||
In order to make lazy fetching working as expected, entities should be `open` as described in [KT-28525](https://youtrack.jetbrains.com/issue/KT-28525). We are going to use the Kotlin `allopen` plugin for that purpose.
|
||||
|
||||
With Gradle:
|
||||
|
||||
`build.gradle.kts`
|
||||
```kotlin
|
||||
plugins {
|
||||
...
|
||||
kotlin("plugin.allopen") version "1.8.0"
|
||||
}
|
||||
|
||||
allOpen {
|
||||
annotation("jakarta.persistence.Entity")
|
||||
annotation("jakarta.persistence.Embeddable")
|
||||
annotation("jakarta.persistence.MappedSuperclass")
|
||||
}
|
||||
```
|
||||
|
||||
Or with Maven:
|
||||
|
||||
`pom.xml`
|
||||
```xml
|
||||
<plugin>
|
||||
<artifactId>kotlin-maven-plugin</artifactId>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<configuration>
|
||||
...
|
||||
<compilerPlugins>
|
||||
...
|
||||
<plugin>all-open</plugin>
|
||||
</compilerPlugins>
|
||||
<pluginOptions>
|
||||
<option>all-open:annotation=jakarta.persistence.Entity</option>
|
||||
<option>all-open:annotation=jakarta.persistence.Embeddable</option>
|
||||
<option>all-open:annotation=jakarta.persistence.MappedSuperclass</option>
|
||||
</pluginOptions>
|
||||
</configuration>
|
||||
</plugin>
|
||||
```
|
||||
|
||||
Then we create our model by using Kotlin [primary constructor concise syntax](https://kotlinlang.org/docs/reference/classes.html#constructors) which allows to declare at the same time the properties and the constructor parameters.
|
||||
|
||||
`src/main/kotlin/com/example/blog/Entities.kt`
|
||||
```kotlin
|
||||
@Entity
|
||||
class Article(
|
||||
var title: String,
|
||||
var headline: String,
|
||||
var content: String,
|
||||
@ManyToOne var author: User,
|
||||
var slug: String = title.toSlug(),
|
||||
var addedAt: LocalDateTime = LocalDateTime.now(),
|
||||
@Id @GeneratedValue var id: Long? = null)
|
||||
|
||||
@Entity
|
||||
class User(
|
||||
var login: String,
|
||||
var firstname: String,
|
||||
var lastname: String,
|
||||
var description: String? = null,
|
||||
@Id @GeneratedValue var id: Long? = null)
|
||||
```
|
||||
|
||||
Notice that we are using here our `String.toSlug()` extension to provide a default argument to the `slug` parameter of `Article` constructor. Optional parameters with default values are defined at the last position in order to make it possible to omit them when using positional arguments (Kotlin also supports [named arguments](https://kotlinlang.org/docs/reference/functions.html#named-arguments)). Notice that in Kotlin it is not unusual to group concise class declarations in the same file.
|
||||
|
||||
> [!info]
|
||||
> Here we don’t use [`data` classes](https://kotlinlang.org/docs/data-classes.html) with `val` properties because JPA is not designed to work with immutable classes or the methods generated automatically by `data` classes. If you are using other Spring Data flavor, most of them are designed to support such constructs so you should use classes like `data class User(val login: String, …)` when using Spring Data MongoDB, Spring Data JDBC, etc.
|
||||
|
||||
> [!info]
|
||||
> While Spring Data JPA makes it possible to use natural IDs (it could have been the `login` property in `User` class) via [`Persistable`](https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.entity-persistence.saving-entites), it is not a good fit with Kotlin due to [KT-6653](https://youtrack.jetbrains.com/issue/KT-6653), that’s why it is recommended to always use entities with generated IDs in Kotlin.
|
||||
|
||||
We also declare our Spring Data JPA repositories as following.
|
||||
|
||||
`src/main/kotlin/com/example/blog/Repositories.kt`
|
||||
```kotlin
|
||||
interface ArticleRepository : CrudRepository<Article, Long> {
|
||||
fun findBySlug(slug: String): Article?
|
||||
fun findAllByOrderByAddedAtDesc(): Iterable<Article>
|
||||
}
|
||||
|
||||
interface UserRepository : CrudRepository<User, Long> {
|
||||
fun findByLogin(login: String): User?
|
||||
}
|
||||
```
|
||||
|
||||
And we write JPA tests to check whether basic use cases work as expected.
|
||||
|
||||
`src/test/kotlin/com/example/blog/RepositoriesTests.kt`
|
||||
```kotlin
|
||||
@DataJpaTest
|
||||
class RepositoriesTests @Autowired constructor(
|
||||
val entityManager: TestEntityManager,
|
||||
val userRepository: UserRepository,
|
||||
val articleRepository: ArticleRepository) {
|
||||
|
||||
@Test
|
||||
fun `When findByIdOrNull then return Article`() {
|
||||
val johnDoe = User("johnDoe", "John", "Doe")
|
||||
entityManager.persist(johnDoe)
|
||||
val article = Article("Lorem", "Lorem", "dolor sit amet", johnDoe)
|
||||
entityManager.persist(article)
|
||||
entityManager.flush()
|
||||
val found = articleRepository.findByIdOrNull(article.id!!)
|
||||
assertThat(found).isEqualTo(article)
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `When findByLogin then return User`() {
|
||||
val johnDoe = User("johnDoe", "John", "Doe")
|
||||
entityManager.persist(johnDoe)
|
||||
entityManager.flush()
|
||||
val user = userRepository.findByLogin(johnDoe.login)
|
||||
assertThat(user).isEqualTo(johnDoe)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!info]
|
||||
> We use here the `CrudRepository.findByIdOrNull` Kotlin extension provided by default with Spring Data, which is a nullable variant of the `Optional` based `CrudRepository.findById`. Read the great [Null is your friend, not a mistake](https://medium.com/@elizarov/null-is-your-friend-not-a-mistake-b63ff1751dd5) blog post for more details.
|
||||
|
||||
## Implementing the blog engine
|
||||
|
||||
We update the "blog" Mustache templates.
|
||||
|
||||
`src/main/resources/templates/blog.mustache`
|
||||
```html
|
||||
{{> header}} <h1>{{title}}</h1>
|
||||
|
||||
<div class="articles"> {{#articles}} <section>
|
||||
<header class="article-header">
|
||||
<h2 class="article-title"><a href="/article/{{slug}}">{{title}}</a></h2>
|
||||
<div class="article-meta">By <strong>{{author.firstname}}</strong>, on <strong>{{addedAt}}</strong></div>
|
||||
</header>
|
||||
<div class="article-description"> {{headline}} </div>
|
||||
</section> {{/articles}} </div> {{> footer}}
|
||||
```
|
||||
|
||||
And we create an "article" new one.
|
||||
|
||||
`src/main/resources/templates/article.mustache`
|
||||
```hmtl
|
||||
{{> header}} <section class="article">
|
||||
<header class="article-header">
|
||||
<h1 class="article-title">{{article.title}}</h1>
|
||||
<p class="article-meta">By <strong>{{article.author.firstname}}</strong>, on <strong>{{article.addedAt}}</strong></p>
|
||||
</header>
|
||||
|
||||
<div class="article-description"> {{article.headline}}
|
||||
|
||||
{{article.content}} </div>
|
||||
</section> {{> footer}}
|
||||
```
|
||||
|
||||
We update the `HtmlController` in order to render blog and article pages with the formatted date. `ArticleRepository` and `MarkdownConverter` constructor parameters will be automatically autowired since `HtmlController` has a single constructor (implicit `@Autowired`).
|
||||
|
||||
`src/main/kotlin/com/example/blog/HtmlController.kt`
|
||||
```kotlin
|
||||
@Controller
|
||||
class HtmlController(private val repository: ArticleRepository) {
|
||||
|
||||
@GetMapping("/")
|
||||
fun blog(model: Model): String {
|
||||
model["title"] = "Blog"
|
||||
model["articles"] = repository.findAllByOrderByAddedAtDesc().map { it.render() }
|
||||
return "blog"
|
||||
}
|
||||
|
||||
@GetMapping("/article/{slug}")
|
||||
fun article(@PathVariable slug: String, model: Model): String {
|
||||
val article = repository
|
||||
.findBySlug(slug)
|
||||
?.render()
|
||||
?: throw ResponseStatusException(HttpStatus.NOT_FOUND, "This article does not exist")
|
||||
model["title"] = article.title
|
||||
model["article"] = article
|
||||
return "article"
|
||||
}
|
||||
|
||||
fun Article.render() = RenderedArticle(
|
||||
slug,
|
||||
title,
|
||||
headline,
|
||||
content,
|
||||
author,
|
||||
addedAt.format()
|
||||
)
|
||||
|
||||
data class RenderedArticle(
|
||||
val slug: String,
|
||||
val title: String,
|
||||
val headline: String,
|
||||
val content: String,
|
||||
val author: User,
|
||||
val addedAt: String)
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Then, we add data initialization to a new `BlogConfiguration` class.
|
||||
|
||||
`src/main/kotlin/com/example/blog/BlogConfiguration.kt`
|
||||
```kotlin
|
||||
@Configuration
|
||||
class BlogConfiguration {
|
||||
|
||||
@Bean
|
||||
fun databaseInitializer(userRepository: UserRepository,
|
||||
articleRepository: ArticleRepository) = ApplicationRunner {
|
||||
|
||||
val johnDoe = userRepository.save(User("johnDoe", "John", "Doe"))
|
||||
articleRepository.save(Article(
|
||||
title = "Lorem",
|
||||
headline = "Lorem",
|
||||
content = "dolor sit amet",
|
||||
author = johnDoe
|
||||
))
|
||||
articleRepository.save(Article(
|
||||
title = "Ipsum",
|
||||
headline = "Ipsum",
|
||||
content = "dolor sit amet",
|
||||
author = johnDoe
|
||||
))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!info]
|
||||
> Notice the usage of named parameters to make the code more readable.
|
||||
|
||||
And we also update the integration tests accordingly.
|
||||
|
||||
`src/test/kotlin/com/example/blog/IntegrationTests.kt`
|
||||
```kotlin
|
||||
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
|
||||
class IntegrationTests(@Autowired val restTemplate: TestRestTemplate) {
|
||||
|
||||
@BeforeAll
|
||||
fun setup() {
|
||||
println(">> Setup")
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `Assert blog page title, content and status code`() {
|
||||
println(">> Assert blog page title, content and status code")
|
||||
val entity = restTemplate.getForEntity<String>("/")
|
||||
assertThat(entity.statusCode).isEqualTo(HttpStatus.OK)
|
||||
assertThat(entity.body).contains("<h1>Blog</h1>", "Lorem")
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `Assert article page title, content and status code`() {
|
||||
println(">> Assert article page title, content and status code")
|
||||
val title = "Lorem"
|
||||
val entity = restTemplate.getForEntity<String>("/article/${title.toSlug()}")
|
||||
assertThat(entity.statusCode).isEqualTo(HttpStatus.OK)
|
||||
assertThat(entity.body).contains(title, "Lorem", "dolor sit amet")
|
||||
}
|
||||
|
||||
@AfterAll
|
||||
fun teardown() {
|
||||
println(">> Tear down")
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Start (or restart) the web application, and go to `http://localhost:8080/`, you should see the list of articles with clickable links to see a specific article.
|
||||
|
||||
## Exposing HTTP API
|
||||
|
||||
We are now going to implement the HTTP API via `@RestController` annotated controllers.
|
||||
|
||||
`src/main/kotlin/com/example/blog/HttpControllers.kt`
|
||||
```kotlin
|
||||
@RestController
|
||||
@RequestMapping("/api/article")
|
||||
class ArticleController(private val repository: ArticleRepository) {
|
||||
|
||||
@GetMapping("/")
|
||||
fun findAll() = repository.findAllByOrderByAddedAtDesc()
|
||||
|
||||
@GetMapping("/{slug}")
|
||||
fun findOne(@PathVariable slug: String) =
|
||||
repository.findBySlug(slug) ?: throw ResponseStatusException(HttpStatus.NOT_FOUND, "This article does not exist")
|
||||
|
||||
}
|
||||
|
||||
@RestController
|
||||
@RequestMapping("/api/user")
|
||||
class UserController(private val repository: UserRepository) {
|
||||
|
||||
@GetMapping("/")
|
||||
fun findAll() = repository.findAll()
|
||||
|
||||
@GetMapping("/{login}")
|
||||
fun findOne(@PathVariable login: String) =
|
||||
repository.findByLogin(login) ?: throw ResponseStatusException(HttpStatus.NOT_FOUND, "This user does not exist")
|
||||
}
|
||||
```
|
||||
|
||||
For tests, instead of integration tests, we are going to leverage `@WebMvcTest` and [Mockk](https://mockk.io/) which is similar to [Mockito](https://site.mockito.org/) but better suited for Kotlin.
|
||||
|
||||
Since `@MockBean` and `@SpyBean` annotations are specific to Mockito, we are going to leverage [SpringMockK](https://github.com/Ninja-Squad/springmockk) which provides similar `@MockkBean` and `@SpykBean` annotations for Mockk.
|
||||
|
||||
With Gradle:
|
||||
|
||||
`build.gradle.kts`
|
||||
```kotlin
|
||||
testImplementation("org.springframework.boot:spring-boot-starter-test") {
|
||||
exclude(module = "mockito-core")
|
||||
}
|
||||
testImplementation("org.junit.jupiter:junit-jupiter-api")
|
||||
testRuntimeOnly("org.junit.jupiter:junit-jupiter-engine")
|
||||
testImplementation("com.ninja-squad:springmockk:4.0.0")
|
||||
```
|
||||
|
||||
Or with Maven:
|
||||
|
||||
`pom.xml`
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-test</artifactId>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.junit.jupiter</groupId>
|
||||
<artifactId>junit-jupiter-engine</artifactId>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.ninja-squad</groupId>
|
||||
<artifactId>springmockk</artifactId>
|
||||
<version>4.0.0</version>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
`src/test/kotlin/com/example/blog/HttpControllersTests.kt`
|
||||
```kotlin
|
||||
@WebMvcTest
|
||||
class HttpControllersTests(@Autowired val mockMvc: MockMvc) {
|
||||
|
||||
@MockkBean
|
||||
lateinit var userRepository: UserRepository
|
||||
|
||||
@MockkBean
|
||||
lateinit var articleRepository: ArticleRepository
|
||||
|
||||
@Test
|
||||
fun `List articles`() {
|
||||
val johnDoe = User("johnDoe", "John", "Doe")
|
||||
val lorem5Article = Article("Lorem", "Lorem", "dolor sit amet", johnDoe)
|
||||
val ipsumArticle = Article("Ipsum", "Ipsum", "dolor sit amet", johnDoe)
|
||||
every { articleRepository.findAllByOrderByAddedAtDesc() } returns listOf(lorem5Article, ipsumArticle)
|
||||
mockMvc.perform(get("/api/article/").accept(MediaType.APPLICATION_JSON))
|
||||
.andExpect(status().isOk)
|
||||
.andExpect(content().contentType(MediaType.APPLICATION_JSON))
|
||||
.andExpect(jsonPath("\$.[0].author.login").value(johnDoe.login))
|
||||
.andExpect(jsonPath("\$.[0].slug").value(lorem5Article.slug))
|
||||
.andExpect(jsonPath("\$.[1].author.login").value(johnDoe.login))
|
||||
.andExpect(jsonPath("\$.[1].slug").value(ipsumArticle.slug))
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `List users`() {
|
||||
val johnDoe = User("johnDoe", "John", "Doe")
|
||||
val janeDoe = User("janeDoe", "Jane", "Doe")
|
||||
every { userRepository.findAll() } returns listOf(johnDoe, janeDoe)
|
||||
mockMvc.perform(get("/api/user/").accept(MediaType.APPLICATION_JSON))
|
||||
.andExpect(status().isOk)
|
||||
.andExpect(content().contentType(MediaType.APPLICATION_JSON))
|
||||
.andExpect(jsonPath("\$.[0].login").value(johnDoe.login))
|
||||
.andExpect(jsonPath("\$.[1].login").value(janeDoe.login))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!hint]
|
||||
> `$` needs to be escaped in strings as it is used for string interpolation.
|
||||
|
||||
## Configuration properties
|
||||
|
||||
In Kotlin, the recommended way to manage your application properties is to use read-only properties.
|
||||
|
||||
`src/main/kotlin/com/example/blog/BlogProperties.kt`
|
||||
```kotlin
|
||||
@ConfigurationProperties("blog")
|
||||
data class BlogProperties(var title: String, val banner: Banner) {
|
||||
data class Banner(val title: String? = null, val content: String)
|
||||
}
|
||||
```
|
||||
|
||||
Then we enable it at `BlogApplication` level.
|
||||
|
||||
`src/main/kotlin/com/example/blog/BlogApplication.kt`
|
||||
```kotlin
|
||||
@SpringBootApplication
|
||||
@EnableConfigurationProperties(BlogProperties::class)
|
||||
class BlogApplication {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
To generate [your own metadata](https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#configuration-metadata-annotation-processor) in order to get these custom properties recognized by your IDE, [kapt should be configured](https://kotlinlang.org/docs/reference/kapt.html) with the `spring-boot-configuration-processor` dependency as following.
|
||||
|
||||
`build.gradle.kts`
|
||||
```kotlin
|
||||
plugins {
|
||||
...
|
||||
kotlin("kapt") version "1.8.0"
|
||||
}
|
||||
|
||||
dependencies {
|
||||
...
|
||||
kapt("org.springframework.boot:spring-boot-configuration-processor")
|
||||
}
|
||||
```
|
||||
|
||||
> [!info]
|
||||
> Note that some features (such as detecting the default value or deprecated items) are not working due to limitations in the model kapt provides. Also annotation processing is not yet supported with Maven due to [KT-18022](https://youtrack.jetbrains.com/issue/KT-18022), see [initializr#438](https://github.com/spring-io/initializr/issues/438) for more details.
|
||||
|
||||
In IntelliJ IDEA:
|
||||
|
||||
- Make sure Spring Boot plugin in enabled in menu File | Settings | Plugins | Spring Boot
|
||||
- Enable annotation processing via menu File | Settings | Build, Execution, Deployment | Compiler | Annotation Processors | Enable annotation processing
|
||||
- Since [Kapt is not yet integrated in IDEA](https://youtrack.jetbrains.com/issue/KT-15040), you need to run manually the command `./gradlew kaptKotlin` to generate the metadata
|
||||
|
||||
Your custom properties should now be recognized when editing `application.properties` (autocomplete, validation, etc.).
|
||||
|
||||
`src/main/resources/application.properties`
|
||||
```properties
|
||||
blog.title=Blog
|
||||
blog.banner.title=Warning
|
||||
blog.banner.content=The blog will be down tomorrow.
|
||||
```
|
||||
|
||||
Edit the template and the controller accordingly.
|
||||
|
||||
`src/main/resources/templates/blog.mustache`
|
||||
```html
|
||||
{{> header}} <div class="articles"> {{#banner.title}} <section>
|
||||
<header class="banner">
|
||||
<h2 class="banner-title">{{banner.title}}</h2>
|
||||
</header>
|
||||
<div class="banner-content"> {{banner.content}} </div>
|
||||
</section> {{/banner.title}} ...
|
||||
|
||||
</div> {{> footer}}
|
||||
```
|
||||
|
||||
`src/main/kotlin/com/example/blog/HtmlController.kt`
|
||||
```kotlin
|
||||
@Controller
|
||||
class HtmlController(private val repository: ArticleRepository,
|
||||
private val properties: BlogProperties) {
|
||||
|
||||
@GetMapping("/")
|
||||
fun blog(model: Model): String {
|
||||
model["title"] = properties.title
|
||||
model["banner"] = properties.banner
|
||||
model["articles"] = repository.findAllByOrderByAddedAtDesc().map { it.render() }
|
||||
return "blog"
|
||||
}
|
||||
|
||||
// ...
|
||||
```
|
||||
|
||||
Restart the web application, refresh `http://localhost:8080/`, you should see the banner on the blog homepage.
|
||||
|
||||
## Conclusion
|
||||
|
||||
We have now finished to build this sample Kotlin blog application. The source code [is available on Github](https://github.com/spring-guides/tut-spring-boot-kotlin). You can also have a look to [Spring Framework](https://docs.spring.io/spring/docs/current/spring-framework-reference/languages.html#kotlin) and [Spring Boot](https://docs.spring.io/spring-boot/docs/current/reference/html/boot-features-kotlin.html) reference documentation if you need more details on specific features.
|
||||
@@ -0,0 +1,74 @@
|
||||
---
|
||||
title: >-
|
||||
Command Line Argument Parsing for Groovy | Jarrod Roberson: Programming Missives
|
||||
updated: 2019-02-26 12:14:26Z
|
||||
created: 2019-02-26 12:05:41Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Groovy
|
||||
---
|
||||
|
||||
|
||||
|
||||
Groovy has some wrappers around the apache.commons.cli via their CLIBuilder class. This is a pretty old and crusty library that has some significant limitations. I prefer to use the Java Simple Argument Parser (JSAP) library. Especially since they have added the ability to declare argument definitions in a declarative XML file. This reduces the code footprint in your Groovy or Java program significantly. Normally I am adverse to XML configuration programming but in this case the syntax is very succinct and an appropriate use.
|
||||
|
||||
Here is a partial example of argument declarations for an example program that scans for open ports on a server.
|
||||
```xml
|
||||
<jsap>
|
||||
<parameters>
|
||||
<switch>
|
||||
<id>help</id>
|
||||
<shortFlag>h</shortFlag>
|
||||
<longFlag>help</longFlag>
|
||||
<help>Display this help</help>
|
||||
</switch>
|
||||
<flaggedOption>
|
||||
<id>host</id>
|
||||
<stringParser>
|
||||
<classname>StringStringParser</classname>
|
||||
</stringParser>
|
||||
<required>true</required>
|
||||
<shortFlag>h</shortFlag>
|
||||
<longFlag>host</longFlag>
|
||||
<help>Server to use to scan for open ports</help>
|
||||
</flaggedOption>
|
||||
<unflaggedOption>
|
||||
<id>ports</id>
|
||||
<stringParser>
|
||||
<classname>IntegerStringParser</classname>
|
||||
</stringParser>
|
||||
<greedy>true</greedy>
|
||||
<list>true</list>
|
||||
<listSeparator>,</listSeparator>
|
||||
<help>List of ports to scan on the server</help>
|
||||
</unflaggedOption>
|
||||
</parameters>
|
||||
</jsap>
|
||||
```
|
||||
[jsap.xml](https://gist.github.com/jarrodhroberson/8995420#file-jsap-xml) hosted with ❤ by GitHub
|
||||
|
||||
|
||||
|
||||
Then you can use the following boilerplate code to initialize the parser and use it. Assuming the code is saved in file named “main.groovy” and the configuration file is named “main.jsap” and both are built into a .jar file called main.jar
|
||||
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
|
||||
```groovy
|
||||
JSAP jsap = new JSAP(main.getResource("main.jsap"));
|
||||
JSAPResult config = jsap.parse(args)
|
||||
if (config.getBoolean("help") || !config.success())
|
||||
{
|
||||
println "Usage: java -jar main.jar " + jsap.usage
|
||||
println ""
|
||||
println jsap.help
|
||||
if (!config.success())
|
||||
{
|
||||
for (e in config.getErrorMessageIterator())
|
||||
{
|
||||
println e
|
||||
}
|
||||
}
|
||||
System.exit(0)
|
||||
}
|
||||
```
|
||||
[main.groovy](https://gist.github.com/jarrodhroberson/8995431#file-main-groovy) hosted with ❤ by GitHub
|
||||
|
||||
That is basically all the code you need to easily and powerfully parse command line arguments in Groovy.
|
||||
@@ -0,0 +1,165 @@
|
||||
---
|
||||
title: Configuring your Git environment for success
|
||||
updated: 2022-08-18 08:51:22Z
|
||||
created: 2022-08-18 08:50:26Z
|
||||
tags:
|
||||
- Development/Git
|
||||
- Development/Shell
|
||||
source: https://github.com/readme/guides/configure-git-environment
|
||||
---
|
||||
|
||||
## [Configuring your Git environment for success](https://github.com/readme/guides/configure-git-environment)
|
||||
|
||||
In my two years as an open source maintainer, I have found that the biggest barrier for newcomers participating in open source is not actually the coding part. In fact, [Tern](https://github.com/tern-tools/tern) gets lots of Python programmers who know what changes are required in the code. The biggest barrier to entry I’ve seen is the Git workflow surrounding opening and updating a pull request. While opening a new pull request (PR) is a fairly straightforward process, updating that same PR can be difficult if your repository is not set up properly.
|
||||
|
||||
This comes as no surprise to me because when I first started contributing to open source, the hardest part of getting started was trying to understand how I could make Git do what I needed it to. I still remember being asked to update one of my first PRs and, despite my best efforts searching all corners of the internet, I couldn’t figure out how to do it. I ended up closing the pull request, re-cloning my fork, and opening an entirely new pull request 🤦♀️ . The good news is that by the end of reading this article you won’t have to go through the same struggles I did.
|
||||
|
||||
Configuring your Git development environment properly is the best way to avoid frustration as an open source contributor. While the GitHub webUI is fairly intuitive, Git command line operation and dexterity is not. However, you don’t need to be an expert in Git to be successful contributing to open source.
|
||||
|
||||
Open source projects will vary in scope, size, and complexity. The nature of these factors will determine how to pick the project you want to contribute to, but most projects will generally follow a maintainer/contributor model.
|
||||
|
||||
- **Maintainers** are the project leaders and responsible for the overall health and direction of a project. They are the final reviewers of pull requests (PRs) and ultimately responsible for the code that gets merged to the project.
|
||||
|
||||
- **Contributors** commit to the project in the form of documentation, code review, debug, or code contributions. Contributors suggest changes to the project by opening PRs for maintainers to review and ultimately merge to the project’s code base.
|
||||
|
||||
|
||||
These instructions assume that you have a GitHub account, the git package installed in your development environment, and access to a command line shell (the one included in Visual Studios Code will work just fine). Also note that while Git contains a multitude of intricacies, I try to keep the instructions as high level as I can.
|
||||
|
||||
### 1\. General setup
|
||||
|
||||
**Pick your project **
|
||||
|
||||
The very first step in setting up your development environment is to pick the project you want to contribute to. If you’re unsure and want to browse around, take a look at GitHub’s [#good-first-issue](https://github.com/topics/good-first-issue) tag or the Good First Issue [project page](https://goodfirstissue.dev/) for a list of projects with beginner-level work.
|
||||
|
||||
**Optional: Create an SSH key**
|
||||
|
||||
While it’s not required to have an SSH key registered with GitHub, it can make your development workflow easier and more secure. You only have to do it once. GitHub’s documentation around how to do this is great. Check out articles on [generating a new SSH key](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent) and [adding a new SSH key to your GitHub account](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/adding-a-new-ssh-key-to-your-github-account) to learn how to do this.
|
||||
|
||||
**Setting up your Git configs**
|
||||
|
||||
Git config is a tool that sets general Git configuration options and, more specifically, can help you customize your identity. When you open a PR for an open source project, you will likely need to “sign off” your commit. Configuring your username and email can save you time with this step later. To configure your sign-off identity, run:
|
||||
|
||||
```shell
|
||||
git config --global user.name "Your Name" git config --global user.email "your.email@address.com"
|
||||
```
|
||||
|
||||
**Fork the project**
|
||||
|
||||
Once you’ve configured your identity with GitHub, you need to fork the project you are planning to contribute to. Because write access to open source projects is controlled by the maintainer(s), you won’t ever be making direct changes to the project repository. Instead, we fork (AKA copy) the project source code to our own personal account so we have somewhere to make changes without affecting the original repository. It’s easiest to fork the project via the GitHub WebUI. Once you navigate to the GitHub page of the project you would like to contribute to, look for a “Fork” button in the upper right hand corner.
|
||||
|
||||
**Clone your fork**
|
||||
|
||||
Once you’ve forked the main project repository, the next step is to clone *your fork* of the project to your working environment. You’ll want to do this on the command line using your shell of choice:
|
||||
|
||||
```shell
|
||||
git clone git@github.com:rnjudge/tern.git cd tern
|
||||
```
|
||||
|
||||
|
||||
### 2\. Branch/environment setup
|
||||
|
||||
You can think of branches in Git as a way to organize and separate your changes. Different branches can point to different sets of changes without muddling the two sets of changes together. In the next set of steps we will set up your working branches so that you can easily update and rebase your work with the main project repository.
|
||||
|
||||
**Add an upstream remote repository**
|
||||
|
||||
A remote repository is a Git repository that’s hosted somewhere on the internet. When you clone your fork of the project, you are creating a local copy of your forked remote repository. When you run **git clone** ([git clone](https://github.com/git-guides/git-clone)), Git automatically gives your remote repository the name **origin**. You can list your remotes using the **git remote** command. After running the clone command above, you should see your “origin” remote listed:
|
||||
|
||||
```shell
|
||||
$ git remote -v origin git@github.com:rnjudge/tern.git (fetch) origin git@github.com:rnjudge/tern.git (push)
|
||||
```
|
||||
|
||||
Your fork of the “origin” remote repository you cloned is not automatically kept up to date with the main project. This means that if changes get merged to the main project repository, your cloned fork will not know about those changes by default. This matters when we want to rebase a PR to match with the main project repository. In order to make this easier in the future, we add a remote repository named “**upstream**” that points to the main project.
|
||||
|
||||
If and only if you have your SSH key setup, run: `$ git remote add upstream git@github.com:tern-tools/tern.git` Otherwise, add the remote using https:
|
||||
|
||||
`$ git remote add upstream https://github.com/tern-tools/tern.git`
|
||||
|
||||
**Create a “home base” branch to track changes on the main project**
|
||||
|
||||
“Home base branch” is not a technical Git or GitHub term, but a phrase I use to describe a branch we’ll use to keep track of upstream repository changes, which will help us easily rebase our PRs in the future. This means you won’t use your home base branch for development or to make changes to source code. Rather, you’ll use it to rebase your development branches and create new working branches from it. The up branch helps you easily stay in sync with the upstream repository.
|
||||
|
||||
In this example, my home base branch is named **up** (but you can name it whatever you want). Your other development branches will be based on this **up** branch as well. In the following set of commands, Tern’s main branch is named **main**. In some repositories, it may still be named **master** so you might need to edit the commands accordingly. Run these commands to setup your **up** branch to track changes in the upstream project repo:
|
||||
|
||||
```shell
|
||||
$ git fetch upstream
|
||||
$ git checkout -b up upstream/main
|
||||
$ git push origin up:refs/heads/main
|
||||
```
|
||||
|
||||
*Note that you will only need to set up the* ***up*** *branch once.*
|
||||
|
||||
### 3\. General workflow
|
||||
|
||||
Now that you have created your home base branch, you’re ready to start coding! The following workflow will help you make changes, submit a new PR, and update the same PR if necessary.
|
||||
|
||||
**Create a working branch**
|
||||
|
||||
The **up** branch is your home base branch that we'll use to create working branches. The working branches are where we will actually make changes to the code. Whenever you want to create a new working branch, run the following commands:
|
||||
|
||||
First, make sure **up** branch is current.
|
||||
|
||||
`$ git checkout up $ git pull --rebase`
|
||||
|
||||
Then, create and switch to your working branch. `$ git checkout -b working_branch_name`
|
||||
|
||||
The working branch can be named whatever you want.
|
||||
|
||||
**Make and commit your changes**
|
||||
|
||||
Any changes you make to the project source code will be associated with the working branch you’re on (to see what branch you’re on, run “**git checkout**” and look for the asterisk). Once you think your changes are sufficient and ready to be submitted to the upstream project, you’ll first need to add the files for staging. Staging your changed files for commit is a way of telling Git that the files are ready to be committed. In order to stage the files for commit, run:
|
||||
|
||||
`$ git add <file/directory>`
|
||||
|
||||
If you changed a lot of files in one particular directory, you can **git add** entire directories this way as well. Note that Git will only stage files that have been changed if you add an entire directory where some files are unchanged. To check which files have been staged for commit, you can run **git status**. If you want to delete a file as part of your commit, run **git rm file** to both delete the file and stage the removal for commit.
|
||||
|
||||
**Commit your staged changes**
|
||||
|
||||
Once you’ve staged all the desired files for commit, it’s time to commit the changes. Using the **-s** option will sign off your commit using the git config information that you did in the General Setup section.
|
||||
|
||||
`$ git commit -s`
|
||||
|
||||
Important note: I do not encourage using the **-m** option with [git commit](https://github.com/git-guides/git-commit). **git commit -m<msg>** allows you to use the given <msg> as the commit message at the same time that you commit your code changes. This, however, does not allow for writing detailed or well-organized commit messages as the commit messages when using the **-m** option tend to be short one-liners. I gave a talk at [All Things Open](https://2021.allthingsopen.org/) about why and how to write good commit messages (which has also been converted to [blog](https://blogs.vmware.com/opensource/2021/04/14/improve-your-git-commits-in-two-easy-steps/) form). Many open source projects will also have commit message requirements for the project. Look at these before writing your commit message. Once you’ve finished writing your commit message, save and exit the commit message prompt.
|
||||
|
||||
**Push your changes**
|
||||
|
||||
Once you’ve saved and exited the commit message prompt, it’s time to push your changes to your remote fork. Up until now, your changes have lived in the local copy of the “origin” remote repository. Pushing your changes will upload your changes to the remote repository on GitHub.
|
||||
|
||||
`$ git push origin <working_branch_name>`
|
||||
|
||||
**Opening the pull request**
|
||||
|
||||
Once you’ve pushed your changes, you can use the GitHub WebUI to open the PR. Simply navigate to the main project page and GitHub will automatically suggest opening a PR from the changes that most recently got pushed to your fork.
|
||||
|
||||
### 4\. Editing your commit after you’ve already opened a PR
|
||||
|
||||
**Rebase your changes with upstream**
|
||||
|
||||
If you are asked to make changes to your PR, it’s possible that other commits could’ve been merged to the upstream repository since you first submitted your changes. In order to make sure you’re not picking up any stale code or files when you update your PR, it’s best to rebase your changes with the upstream remote repository. To do this easily, use the home base branch. Keep in mind that the home base branch is called **up** in this example but you may have named it something else.
|
||||
|
||||
The following set of commands will first fetch any changes from upstream and then apply them to your **up** branch. This means you will update your **up** branch to match with the latest changes in the repository where you are submitting your PR. After you switch back to your working branch, the **git rebase up** command will then update your working branch (that contains your PR changes) to contain the latest changes from upstream (via the **up** branch) while preserving the changes you made on your working branch. This process enables you to pick up changes from the upstream repository so that your PR can be merged into the upstream repository without conflicts. It also ensures that any continuous integration tests that run once your PR is updated or submitted will run against the latest changes to the code base.
|
||||
|
||||
`$ git checkout up $ git pull --rebase $ git checkout <existing_pr_working_branch_name> $ git rebase up`
|
||||
|
||||
Now that your working branch is current, you can make your changes. To make changes to source code files you will edit the file(s), and run **git add** to stage them for commit like you did before. To update your PR with these changes, you can amend your previous commit. Amending your commit will also give you the opportunity to edit your commit message if you need to. If you only need to make changes to the commit message and no source code files, skip the “**git add**” and just run:
|
||||
|
||||
`$ git commit --amend`
|
||||
|
||||
If you don’t need to update your commit message, just save and exit the commit message prompt after running amend. If you want to update your commit message, make changes now before saving and exiting the commit message prompt.
|
||||
|
||||
**Re-push your changes**
|
||||
|
||||
Make sure that you are still on your working branch where you just amended your commit. Amending your commit locally does not update the commit in the remote repository or change the pull request. To update your PR, you’ll need to re-push your changes to your forked remote repository:
|
||||
|
||||
`$ git push -f origin <existing_pr_working_branch_name>`
|
||||
|
||||
The -f/force push option can be dangerous when used incorrectly as it can overwrite the commit history in the remote repository with your own local history. Here, however, it is required because you are amending the old commit and intentionally rewriting git history on your fork to include your latest edits. When you force push here after amending your commit, you are creating a new git commit ID to associate with your changes.
|
||||
|
||||
If you go look at the original PR you opened you’ll see that it now contains your most recent changes. If CI/CD tests are configured for the repository you’re submitting your PR to, you will see those triggered again to re-run on your latest set of changes.
|
||||
|
||||
**Continuing to contribute**
|
||||
|
||||
Remember that your **up** branch is your home base branch that you’ll use to keep track of changes. You won’t use it for development or to make changes to source code. If you want to start working on a new issue for the same project you can start to follow the steps under step 3, “General workflow” since your home base branch would already be set up at this point.
|
||||
|
||||
### Phew, that was a lot!
|
||||
|
||||
I hope this setup helps you find success in open source. If you ever have any questions you can reach out to me on Twitter (@rosejudge5) or via [Tern’s GitHub page](https://github.com/tern-tools/tern).
|
||||
@@ -0,0 +1,387 @@
|
||||
---
|
||||
title: 'Definitive Obsidian Markdown Cheatsheet: Complete Syntax Reference'
|
||||
updated: 2023-03-21 13:49:31Z
|
||||
created: 2023-03-21 13:48:37Z
|
||||
tags:
|
||||
- IT
|
||||
- IT/Tools/Obsidian
|
||||
source: https://facedragons.com/personal-development/obsidian-markdown-cheatsheet/
|
||||
---
|
||||
|
||||
## [Definitive Obsidian Markdown Cheatsheet: Complete Syntax Reference](https://facedragons.com/personal-development/obsidian-markdown-cheatsheet/)
|
||||
|
||||
If you use Obsidian for notes already or are thinking about it but are not sure what markdown is or how to use markdown in Obsidian, this guide is for you. Use this guide as a reference for markdown in Obsidian. Find markdown examples for all your formatting and linking needs in this up-to-date Obsidian markdown syntax reference.
|
||||
|
||||
[Obsidian](https://obsidian.md/) is a note-taking application ideal for [creating a second brain](https://facedragons.com/productivity/how-to-setup-a-second-brain-in-obsidian/) or personal knowledge management system. Obsidian uses markdown (.md) files to store your notes. Markdown files are plain text files. The upside of this is that your notes are easily accessible and can be read with any text editor and will be correctly formatted if you use any markdown editor/viewer.
|
||||
|
||||
The downside is that you need to learn a little bit of markdown to use Obsidian, but with this guide, you’ll have all the markdown you need to become an Obsidian expert.
|
||||
|
||||
| Markdown Element | Syntax | Example |
|
||||
| --- | --- | --- |
|
||||
| Headings 1-6 | # | \# My Heading **See below for more examples** |
|
||||
| Bold | ** | Chocolate is \*\*so good!\*\* |
|
||||
| Italics | * | I read the \*NY Times\* |
|
||||
| Underline | N/A | Only with Plugin |
|
||||
| Strikethrough | ~~ | ~~woops~~ |
|
||||
| Links | \[\] | **See below for examples** |
|
||||
| Embed | ! | **See below for examples** |
|
||||
| Unordered List | – | – first bullet point |
|
||||
| Numbered List | 1. | 1\. Make bread |
|
||||
| Tasks | – \[ \] | – \[x\] Go shopping |
|
||||
| Table | \| | **See below for examples** |
|
||||
| Footnotes | ^\[\] | Yaks are found in TIbet^\[An other Himalayan regions\] |
|
||||
| Tags | # | #tagshavenospaces |
|
||||
| Code Block | “` or ~~~ | ` ``` this is a code block`“` ~~~ so is this ~~~ |
|
||||
| Horizontal rule/ line | — | — |
|
||||
| Images | !\[\]() | !\[Mountains and grass\](https://facedragons.com/images/mountains-grass.jpg) |
|
||||
| Highlight | == | Highlight ==this.== |
|
||||
|
||||
Cheat Sheet for Obsidian Markdown Syntax, a Reference Table
|
||||
|
||||
## Markdown Headings
|
||||
|
||||
There are six possible headings you can use in Obsidian, they are numbered from 1 (biggest) to 6 (smallest). The special character for creating headings is the hash symbol #. To make an H1 type # with a space after it, two hashes for an H2, etc.
|
||||
|
||||
Using headings instead of bolded text will be more useful later if you want to link to a specific section (see below) or for making a table of contents etc.
|
||||
|
||||
Here is the markdown for each heading and the resulting heading that will appear in your note.
|
||||
|
||||
```
|
||||
# Heading 1
|
||||
## Heading 2
|
||||
### Heading 3
|
||||
#### Heading 4
|
||||
##### Heading 5
|
||||
###### Heading 6
|
||||
```
|
||||
|
||||
## Heading 1
|
||||
|
||||
## Heading 2
|
||||
|
||||
### Heading 3
|
||||
|
||||
#### Heading 4
|
||||
|
||||
##### Heading 5
|
||||
|
||||
###### Heading 6
|
||||
|
||||
## Text Formatting in Obsidian
|
||||
|
||||
If you’re used to using Microsoft Word, Google Docs, or Pages, you’re probably used to having a bar at the top of the page with all your formatting options. In Obsidian, you can use markdown to change your formatting, here’s how:
|
||||
|
||||
### Bold
|
||||
|
||||
To make something bold you surround it with two stars (**) on either side.
|
||||
|
||||
```
|
||||
**Two Stars for Bolded Text**
|
||||
```
|
||||
|
||||
**Two Stars for Bolded Text**
|
||||
|
||||
### Italics
|
||||
|
||||
To make something italic you surround it with one star (*) on either side.
|
||||
|
||||
```
|
||||
*One Star for Italicized Text*
|
||||
```
|
||||
|
||||
*One Star for Italicized Text*
|
||||
|
||||
### Strikethrough
|
||||
|
||||
To strikethrough or cross out your text, surround the text with two tildes (~~). Sometimes called the wiggly line, this character is usually found to the left of the number 1 on your keyboard (SHIFT `)
|
||||
|
||||
```
|
||||
~~Two Tildes for Strikethrough Text~~
|
||||
```
|
||||
|
||||
~~Two Tildes for Strikethrough Text~~
|
||||
|
||||
### Highlight
|
||||
|
||||
To highlight text, surround the text with two equals symbols on each side
|
||||
|
||||
```
|
||||
==Two Equals Signs for Highlighted Text==
|
||||
```
|
||||
|
||||
==Two Equals Signs for Highlighted Text==
|
||||
|
||||
## How to Make Links in Obsidian
|
||||
|
||||
In Obsidian links are created with double square brackets \[\[\]\].
|
||||
|
||||
### Link to a Note
|
||||
|
||||
The most basic link in Obsidian is a note link, it requires only double square brackets. Obsidian will open a dialog box to help you select the note you want to link to.
|
||||
|
||||
```
|
||||
[[Link to a note within Obsidian]]
|
||||
```
|
||||
|
||||
### Link to a Heading within a Note
|
||||
|
||||
```
|
||||
Link to a [[note's specific heading #Heading]]
|
||||
```
|
||||
|
||||
### Link to a Block within a Note
|
||||
|
||||
```
|
||||
Link to a [[note's specific ^Block]]
|
||||
```
|
||||
|
||||
### Link to a Note but Change the Display text
|
||||
|
||||
Sometimes you want to link to a note but want to change the anchor text, you can do this with the pipe symbol |. The text after the pipe symbol will be displayed.
|
||||
|
||||
```
|
||||
Link to a [[note title | prefered display text]]
|
||||
```
|
||||
|
||||
### Link to a Website
|
||||
|
||||
To create a link to an external website, add parenthesis after the square brackets with the URL.
|
||||
|
||||
```
|
||||
[Link to a website](https://facedragons.com)
|
||||
```
|
||||
|
||||
[Link to a website](https://facedragons.com/)
|
||||
|
||||
## Embedding in Obsidian
|
||||
|
||||
Embedding a note within another note is a great way to keep content up-to-date. If you copied and pasted the content, later you would need to update the original and then anywhere you pasted it.
|
||||
|
||||
By embedding the original note into new notes, you only have to update the original and all will be updated.
|
||||
|
||||
```
|
||||
![[Note to Embed]]
|
||||
```
|
||||
|
||||
Blocks can also be embedded if you don’t want the entire note.
|
||||
|
||||
```
|
||||
![[linkexample^Block]]
|
||||
```
|
||||
|
||||
Headings too.
|
||||
|
||||
```
|
||||
![[linkexample#Heading]]
|
||||
```
|
||||
|
||||
The trick for changing the display text will work when embedding too.
|
||||
|
||||
```
|
||||
![[linkexample|Change Display Text]]
|
||||
```
|
||||
|
||||
### Embedding Images and Other Files in Obsidian Notes
|
||||
|
||||
The easiest way to embed a file into your notes is to use drag and drop. Images, videos, audio and other files can be embedded this way. When using drag and drop, the file will be added to your vault where ever you set up files to be stored.
|
||||
|
||||
*If you haven’t set up a location for your files, you can do so in **Settings>Files & Links>Attachment Folder Path***
|
||||
|
||||
```
|
||||
![[Image.jpg]]
|
||||

|
||||
```
|
||||
|
||||
```
|
||||
![[Video.mp4]]
|
||||
```
|
||||
|
||||
```
|
||||
![[Audio.mp3]]
|
||||
```
|
||||
|
||||
```
|
||||
![[Document.pdf]]
|
||||
```
|
||||
|
||||
To link a file that exists online somewhere, enter the URL within parentheses after the link
|
||||
|
||||
```
|
||||

|
||||
```
|
||||
|
||||
Table of supported file types and formats
|
||||
|
||||
1. Markdown files: `md`;
|
||||
2. Image files: `png`, `jpg`, `jpeg`, `gif`, `bmp`, `svg`;
|
||||
3. Audio files: `mp3`, `webm`, `wav`, `m4a`, `ogg`, `3gp`, `flac`;
|
||||
4. Video files: `mp4`, `webm`, `ogv`;
|
||||
5. PDF files: `pdf`.
|
||||
|
||||
## Creating Lists
|
||||
|
||||
Lists can be started with either a dash with a space after it (- ) or a one with a period and space (1. )Hitting the return key will continue the list, tab will indent and Shift tab will return to the outer list.
|
||||
|
||||
### Unordered List (Bullet Points)
|
||||
|
||||
- First Item
|
||||
- Second Item
|
||||
- Third Item
|
||||
- Tab to embed an item
|
||||
- Continue adding embedded items
|
||||
- Shift-Tab to return
|
||||
|
||||
```
|
||||
- First Item
|
||||
- Second Item
|
||||
- Third Item
|
||||
- Tab to embed an item
|
||||
- Continue adding embedded items
|
||||
- Shift Tab to return
|
||||
```
|
||||
|
||||
### Enumerated List (Numbered List or Ordered List)
|
||||
|
||||
1. First Item
|
||||
2. Second Item
|
||||
3. Third Item
|
||||
1. Tab to Embed an Item
|
||||
2. Return to continue adding embedded items
|
||||
4. Shift-Tab to return
|
||||
|
||||
```
|
||||
1. First Item
|
||||
2. Second Item
|
||||
3. Third Item
|
||||
1. Tab to Embed an Item
|
||||
2. Return to continue adding embedded items
|
||||
4. Shift Tab to return
|
||||
```
|
||||
|
||||
### Checklist or To-do List
|
||||
|
||||
A checklist is a special kind of unordered list, when created it will become a list of clickable checkboxes. It can be tricky to create the first time, here is the exact key you need:
|
||||
|
||||
- **Remember, there is a space after the dash and between the square brackets, otherwise, your checklist won’t work.**
|
||||
|
||||
```
|
||||
- [ ] First Task
|
||||
- [x] Second Task
|
||||
- [ ] Third Task
|
||||
- [x] Tab to Embed a task
|
||||
- [ ] Return to continue adding embedded tasks
|
||||
- [ ] Shift Tab to return
|
||||
```
|
||||
|
||||
## Make Tables
|
||||
|
||||
Tables in markdown may look ugly when you are creating them, but they will turn into beautiful and in-proportion tables when you’re finished.
|
||||
|
||||
- **Remember, rows and columns don’t need to be in line in your markdown, they will be fixed after you like off or enable “reading view.”**
|
||||
|
||||
```
|
||||
| Heading | Heading 2 |
|
||||
| ----------- | ----------- |
|
||||
| First Row | Second Column |
|
||||
| Second Row | Second Column|
|
||||
| Third Row | Second Column |
|
||||
```
|
||||
|
||||
| Heading | Heading 2 |
|
||||
| --- | --- |
|
||||
| First Row | Second Column |
|
||||
| Second Row | Second Column |
|
||||
| Third Row | Second Column |
|
||||
|
||||
Footnotes will be necessary if you are using Obsidian to do academic work such as essays, theses, or dissertations.
|
||||
|
||||
```
|
||||
Here is a sentence with a ^[This Footnote is found at the bottom of the page] footnote.
|
||||
```
|
||||
|
||||
Here is a sentence with a <sup>\[1\]</sup>footnote.
|
||||
|
||||
Tags in Obsidian work in the same way as hashtags on Twitter or Instagram. Tags can be used for categories, genres, or any other way you can think of.
|
||||
|
||||
- Remember, a hash and text (#text) with no space is a tag, and a hash and text with a space between (# text) them is an H1 Heading
|
||||
|
||||
```
|
||||
#tagexample
|
||||
```
|
||||
|
||||
## Adding Code to Your Notes
|
||||
|
||||
There are two options for inserting code into your notes, either a code block or `inline code`
|
||||
|
||||
### Code Block
|
||||
|
||||
A code block is added with any of the following three methods
|
||||
|
||||
- Three tildes on the first and last line of the code block ~~~
|
||||
- Three ticks on the first and last line of the code block “`
|
||||
- Four spaces
|
||||
|
||||
```
|
||||
~~~
|
||||
Code block with Tildes
|
||||
~~~
|
||||
|
||||
```
|
||||
Code Block with ticks
|
||||
```
|
||||
|
||||
Code Block with four spaces
|
||||
|
||||
|
||||
```
|
||||
|
||||
### In-Line Code
|
||||
|
||||
```
|
||||
Insert tick marks around `any text` to turn it into in-line code
|
||||
```
|
||||
|
||||
Insert tick marks around `any text` to turn it into in-line code
|
||||
|
||||
## Other Markdown Syntax in Obsidian
|
||||
|
||||
### Horizontal Line, Separator, or Horizontal Rule
|
||||
|
||||
To add a horizontal line or separator in your note use three dashes, remember to add a space after the dashes to make it work.
|
||||
|
||||
```
|
||||
---
|
||||
```
|
||||
|
||||
### Queries
|
||||
|
||||
Queries will embed a list of results into your note, the query below will return any notes with the tag #Bible for example. You can add more than one parameter, as shown further down.
|
||||
|
||||
```
|
||||
```query
|
||||
#Bible
|
||||
```
|
||||
```
|
||||
|
||||
```
|
||||
```query
|
||||
#Bible + New Testament
|
||||
```
|
||||
```
|
||||
|
||||
- **If you add a horizontal line below some text, it will turn the text into a Heading**
|
||||
|
||||
### Template Syntax
|
||||
|
||||
I have a whole [guide on Obsidian’s template syntax](https://facedragons.com/productivity/obsidian-templates-with-examples/) with tons of examples of templates you can copy and paste and use immediately. Here are the three basic template syntaxes you can use in Obsidian:
|
||||
|
||||
- {{title}}
|
||||
- {{date}}
|
||||
- {{time}}
|
||||
|
||||
## More Obsidian Articles and Guides from Face Dragons
|
||||
|
||||
- [How to Sync Your Obsidian Vault Across Devices](https://facedragons.com/foss/sync-obsidian-across-devices/)
|
||||
- [What Is a Second Brain? Tasks, Projects & Notes, Oh My!](https://facedragons.com/productivity/what-is-a-second-brain/)
|
||||
- [10 Advanced Self Improvement Tips for High Performers](https://facedragons.com/personal-development/self-improvement-tips/)
|
||||
- [86 Best Indoor Hobbies List](https://facedragons.com/lifestyle/best-indoor-hobbies/)
|
||||
@@ -0,0 +1,100 @@
|
||||
---
|
||||
title: README.md · master · InstitutMaupertuis
|
||||
updated: 2019-08-28 07:45:15Z
|
||||
created: 2019-08-28 07:45:15Z
|
||||
tags:
|
||||
- IT/Tools/Mattermost
|
||||
- IT/Tools/Gitlab
|
||||
- Administration
|
||||
source: >-
|
||||
https://gitlab.com/InstitutMaupertuis/mattermost-old-messages/blob/master/README.md
|
||||
---
|
||||
|
||||
This guide will help you delete old messages and attachments from your Mattermost Open Source edition server.
|
||||
|
||||
This procedure is very similar to what the [data retention](https://docs.mattermost.com/administration/data-retention.html) option of Mattermost `Enterprise Edition E20` does.
|
||||
|
||||
⚠ Run this at your own risk! I strongly suggest making a backup of your Mattermost directories and MySQL database before running these commands ⚠
|
||||
|
||||
This will be the limit date for the messages to keep (messages before this date will be deleted). Use [https://www.epochconverter.com/](https://www.epochconverter.com/) or Unix commands to generate the timestamp for your date.
|
||||
|
||||
* For example: `1527811200` corresponds to the first of june 2018.
|
||||
* In Mattermost database timestamps are stored with sub seconds accuracy so you need to multiply this timestamp by 1000 for later use.
|
||||
|
||||
In this example we will use `1527811200000`, tweak the commands with your own timestamp.
|
||||
|
||||
## [](#list-old-messages-attachments)List old messages / attachments
|
||||
|
||||
Open the MySQL prompt on your server and issue these queries
|
||||
|
||||
USE mattermost;
|
||||
SELECT * FROM FileInfo WHERE CreateAt < 1527811200000 LIMIT 10;
|
||||
SELECT * FROM Posts WHERE CreateAt < 1527811200000 LIMIT 10;
|
||||
|
||||
You should see information about the files / messages, this only lists 10 results.
|
||||
|
||||
If you get an empty set make sure you have the right timestamp (multiplied by 1000)
|
||||
|
||||
## [](#delete-old-messages-attachments)Delete old messages / attachments
|
||||
|
||||
### [](#mysql-configuration)MySQL configuration
|
||||
|
||||
Edit `/etc/mysql/mysql.conf.d/mysqld.cnf` and add at the end
|
||||
|
||||
secure_file_priv=""
|
||||
|
||||
Restart MySQL
|
||||
|
||||
sudo service mysql restart
|
||||
|
||||
This will allow us to dump the results of a query into a file on the disk.
|
||||
|
||||
### [](#get-a-list-of-the-attachments)Get a list of the attachments
|
||||
|
||||
* Tweak the user and password corresponding to your credentials.
|
||||
* This will create a temporary directory with a file inside containing the path of each attachment that is to be removed
|
||||
|
||||
#!/bin/bash
|
||||
sudo mkdir /tmp/mysqldump/
|
||||
sudo chown -R mysql:mysql /tmp/mysqldump/
|
||||
sudo rm /tmp/mysqldump/*
|
||||
mysql -u user -p'password' -D mattermost -e "SELECT Path FROM FileInfo \
|
||||
WHERE CreateAt < 1527811200000 \
|
||||
INTO OUTFILE '/tmp/mysqldump/uploaded_files.txt' \
|
||||
FIELDS TERMINATED BY ',' \
|
||||
ENCLOSED BY '' \
|
||||
LINES TERMINATED BY '\n';"
|
||||
|
||||
### [](#script-to-delete-the-attachments)Script to delete the attachments
|
||||
|
||||
Create an executable script with the following content, tweak the `/opt/mattermost/data` with your installation directory of Mattermost.
|
||||
|
||||
#!/bin/bash
|
||||
input="/tmp/mysqldump/uploaded_files.txt"
|
||||
while IFS= read -r line
|
||||
do
|
||||
rm "/opt/mattermost/data/$line"
|
||||
done < "$input"
|
||||
|
||||
Run this script as root to delete the attachments files.
|
||||
|
||||
You can now delete the list of files
|
||||
|
||||
sudo rm -Rf /tmp/mysqldump/
|
||||
|
||||
### [](#delete-the-database-entries)Delete the database entries
|
||||
|
||||
This will delete all the messages/attachments in the database
|
||||
|
||||
mysql -u user -p'password' -D mattermost -e "DELETE FROM FileInfo WHERE CreateAt < 1527811200000;"
|
||||
mysql -u user -p'password' -D mattermost -e "DELETE FROM Posts WHERE CreateAt < 1527811200000;"
|
||||
|
||||
### [](#configuration-mysql)Configuration MySQL
|
||||
|
||||
We can now revert the MySQL configuration at `/etc/mysql/mysql.conf.d/mysqld.cnf`, comment
|
||||
|
||||
#secure_file_priv=""
|
||||
|
||||
Restart MySQL
|
||||
|
||||
sudo service mysql restart
|
||||
@@ -0,0 +1,18 @@
|
||||
---
|
||||
title: Docker
|
||||
updated: 2022-04-05 07:44:15Z
|
||||
created: 2022-04-05 07:43:43Z
|
||||
tags:
|
||||
- IT
|
||||
- Docker
|
||||
---
|
||||
|
||||
Docker
|
||||
|
||||
- https://docs.docker.com/engine/userguide/eng-image/dockerfile_best-practices/#onbuild
|
||||
- https://docs.docker.com/engine/userguide/eng-image/dockerfile_best-practices/#workdir
|
||||
- https://docs.docker.com/engine/reference/builder/#add
|
||||
- https://dzone.com/articles/docker-containers-with-gradle-application-plugin
|
||||
- http://container-solutions.com/how-to-build-docker-images-with-gradle/
|
||||
- http://rick-hightower.blogspot.de/2015/05/using-docker-gradle-to-create-java.html
|
||||
- http://www.sonatype.org/nexus/2017/02/16/using-nexus-3-as-your-repository-part-3-docker-images/
|
||||
@@ -0,0 +1,396 @@
|
||||
---
|
||||
title: Documentation as Code mit Asciidoctor
|
||||
updated: 2023-04-19 13:57:04Z
|
||||
created: 2023-04-19 13:57:04Z
|
||||
tags:
|
||||
- IT
|
||||
- Asciidoctor
|
||||
- Dokumentation
|
||||
- DocumentationAsCode
|
||||
source: >-
|
||||
https://www.heise.de/hintergrund/Documentation-as-Code-mit-Asciidoctor-4642013.html?seite=all
|
||||
---
|
||||
|
||||
1. Documentation as Code mit Asciidoctor
|
||||
- [Git versus Microsoft Word](#nav__git_versus__0 " Git versus Microsoft Word")
|
||||
- [Wer steckt dahinter?](#nav_wer_steckt__1 "Wer steckt dahinter?")
|
||||
- [Willkommen im Projekt](#nav_willkommen_im__2 "Willkommen im Projekt")
|
||||
- [Die Entwicklerdokumentation](#nav_die__3 "Die Entwicklerdokumentation")
|
||||
- [Fachliche Dokumentation](#nav_fachliche__4 "Fachliche Dokumentation")
|
||||
- [IT-Architekturdokumentation](#nav_it_architekturdo__5 "IT-Architekturdokumentation")
|
||||
- [API-Dokumentation mit Beispielen](#nav_api_dokumentatio__6 "API-Dokumentation mit Beispielen")
|
||||
- [Arbeitsalltag mit Docs as Code](#nav_arbeitsalltag__7 "Arbeitsalltag mit Docs as Code")
|
||||
- [Refactoring und Strukturierungen](#nav_refactoring_und__8 "Refactoring und Strukturierungen")
|
||||
- [Ausliefern von Dokumenten](#nav_ausliefern_von__9 "Ausliefern von Dokumenten")
|
||||
- [Publizieren als HTML](#nav_publizieren_als__10 "Publizieren als HTML")
|
||||
- [Publizieren als PDF](#nav_publizieren_als__11 "Publizieren als PDF")
|
||||
- [Fazit](#nav_fazit_12 "Fazit")
|
||||
|
||||
Bei Documentation as Code sind Dokumente Teil von Code-Reviews, und der Continuous-Integration-Server erzeugt nicht nur lauffähige Software, sondern auch die dazu passenden Dokumente als druckfertige PDF- oder Online-Dokumentation. Dieser Artikel stellt Beispiele hierfür vor. Im Fokus steht das Asciidoctor-Projekt, um das in den letzten Jahren ein Ökosystem mit verschiedenen Werkzeugen entstanden ist.
|
||||
|
||||
### Git versus Microsoft Word
|
||||
|
||||
Wer mit Office-Dateiformaten wie Microsoft Word arbeitet, kann seine Dokumente lokal bearbeiten, drucken und per E-Mail oder Dateiablage mit anderen Autoren teilen. Je nach Infrastruktur lassen sich Dokumente gemeinsam via SharePoint oder OneDrive bearbeiten. Spätestens, wenn verschiedene bearbeitete Dokumentenversionen über Organisationsgrenzen zusammenzuführen sind, wird es schwierig. Eine Alternative dazu sind Wikis, in denen die Autoren gemeinsam an Dokumenten arbeiten. Hakelig ist meist das Aufbereiten der Inhalte zu druckfertigen Dokumenten mit ansprechendem Layout. Beide Ansätze kommen an ihre Grenzen, wenn Entwickler verschiedene Versionen der Dokumente zum Beispiel für unterschiedliche Software-Releases parallel pflegen sollen.
|
||||
|
||||
Versionskontrollsysteme wie Git punkten auf der anderen Seite mit einer komfortablen Unterstützung für Release-Branches: Änderungen lassen sich zwischen diesen mit Merges und Cherry-Picks übernehmen. Für jede Zeile und jedes Zeichen können sie zurückverfolgen, wer die Änderung wann und – einen entsprechenden Commit-Kommentar vorausgesetzt – aus welchem Grund durchgeführt hat. Das klappt aber nur, wenn es sich bei den Dateien um Textdateien wie Quellcode handelt. Bei Office-Formaten, die eine binäre Struktur haben, versagen diese Funktionen.
|
||||
|
||||
Nutzt ein Team Dokumentationsformate, die nicht auf binären Strukturen basieren, kann es von einer Versionsverwaltung in Git profitieren. Dann umfassen Code-Reviews nicht nur Änderungen am Programmcode, sondern auch die an der Dokumentation. Einfache Textdateien als Dokumentation sind allerdings keine Lösung, wenn Teams eine hochwertige und gut strukturierte Dokumentation erstellen sollen. Im mathematisch-wissenschaftlichen Bereich ist LaTeX der Platzhirsch: Damit lassen sich sowohl HTML- als auch PDF-Dateien erzeugen. Im Publishing-Bereich gibt es zudem Formate wie DocBook und DITA.
|
||||
|
||||
Um Neueinsteigern schnelle Erfolge bei der Dokumentation zu ermöglichen, sind verschiedene Ökosysteme entstanden. Beispiele dafür sind Markdown, AsciiDoc und reStructuredText. Diese Formate sind alle in ihrem Quellformat in einem Texteditor direkt les- und bearbeitbar. Über Konverter lassen sie sich in hochwertige HTML- und PDF-Ausgaben umwandeln, die Auszeichnungen für Überschriften, Querverweise und Inhaltsverzeichnisse bieten.
|
||||
|
||||
Der Wechsel auf ein solches Format verändert die Arbeitsweise mit Dokumenten im Team:
|
||||
|
||||
- Die Trennung von Inhalt und Formatierung wird gefördert: Inhalte in den Quelldateien werden erst im Build-Server mit Stylesheets und Formatvorlagen zusammengeführt.
|
||||
- Inhalte lassen sich an unterschiedlichen Stellen wiederverwenden, verschieden komponieren und so für verschiedene Empfänger aufbereiten.
|
||||
- Entwickler bearbeiten Dokumente in ihrer Entwicklungsumgebung, sodass die Hürde sinkt, Dokumentation zu schreiben.
|
||||
- Fachanwender erhalten in ihren Dokumenten einen Verweis zur Versionsverwaltung und können Änderungen direkt über die Weboberfläche vornehmen. Je nach Berechtigung und Team-Workflow wird die Änderung direkt übernommen oder erzeugt einen Pull-Request, den eine zweite Person begutachtet.
|
||||
|
||||
Im weiteren Verlauf des Artikels geht es um das Format AsciiDoc. Im Vergleich zu Markdown bietet es eine große Ausdrucksstärke, die alle Elemente umfasst, die für das Erstellen eines Buchs notwendig sind – inklusive mathematischem Formelsatz, Tabellen, Fußnoten und Textauszeichnungen. Gleichzeitig ist es einfach genug, um auch für gelegentliche Nutzer erlernbar zu sein.
|
||||
|
||||
### Wer steckt dahinter?
|
||||
|
||||
AsciiDoc als Sprache und Implementierung startete vor über 15 Jahren mit Stuart Rackham als Maintainer. Der offizielle Nachfolger ist das [Asciidoctor-Projekt](https://asciidoctor.org/) mit dem Project Lead Dan Allan und einer Ruby-Implementierung, die auch für JavaScript- und Java-Umgebungen verfügbar ist.
|
||||
|
||||
Die Website des Asciidoctor-Projekts bietet verschiedene Einstiegspunkte: Eine [Syntax Quick Reference](https://asciidoctor.org/docs/asciidoc-syntax-quick-reference/) für den Kurzeinstieg in die Syntax, einen [Writer's Guide](https://asciidoctor.org/docs/asciidoc-writers-guide/), der Einsteigern die Konzepte vorstellt, und ein [User Manual](https://asciidoctor.org/docs/user-manual/), das alle Details rund um Sprache, Installation von Konvertern sowie Tipps und Kniffe enthält.
|
||||
|
||||
Die eigentliche Asciidoctor-Implementierung konvertiert als Ruby-Kommandozeilenprogramm Quelldateien im AsciiDoc-Format in HTML, PDF, DocBook und andere Formate. Damit eignet sie sich für den Einsatz auf Continuous-Integration-Servern. Verpackt als Plug-in für Gradle, Maven oder npm ist sie Teil von Build-Skripten und benötigt keine zusätzliche Installation von Werkzeugen außerhalb des Build-Tools, da sie die Java- beziehungsweise JavaScript-Runtime des Build-Prozesses nutzt.
|
||||
|
||||
Beim Bearbeiten der Quelldateien finden Entwickler für ihre jeweilige IDE [Plug-ins, die sowohl Syntax-Highlighting als auch Live-Preview unterstützen](https://asciidoctor.org/docs/editing-asciidoc-with-live-preview/).
|
||||
|
||||
### Willkommen im Projekt
|
||||
|
||||
Wenn Entwickler in einem neuen Projekt starten, benötigen sie ein paar Eckdaten: Wie heißt das Projekt? Worum geht es? Wo finde ich weitere Informationen? Im AsciiDoc-Format sieht es wie folgt aus:
|
||||
|
||||
```markdown
|
||||
= Ultimatives App-Projekt
|
||||
|
||||
Mit diesem Projekt machen wir unsere Kundinnen und Kunden glücklich!
|
||||
|
||||
== Was uns einzigartig macht
|
||||
|
||||
- Funktionen, die niemand anderes hat.
|
||||
- Durchdachte Interaktion für alle und Nutzerinnen und Nutzer.
|
||||
- ...
|
||||
|
||||
== So startest du als Entwickler
|
||||
|
||||
Starte die Anwendung im Entwicklungsmodus mit folgenden zwei Kommandos:
|
||||
|
||||
npm install
|
||||
npm run dev
|
||||
|
||||
== Mehr Informationen
|
||||
|
||||
In unserem https://github.com/dummy[GitHub-Repository] findest du unsere Ticket-Verwaltung.
|
||||
```
|
||||
|
||||
Am Anfang steht der Titel, den ein Gleichheitszeichen (=) einleitet. Zwei Gleichheitszeichen leiten die Überschriften der ersten Ebene ein. Aufzählungen starten mit einem Spiegelstrich. Kommandos auf der Kommandozeile sind etwas eingerückt. Ein Link mit URL und als dargestellter Text steht im letzten Abschnitt.
|
||||
|
||||
Dieser Text könnte auch eins zu eins in einer Begrüßungs-E-Mail an neue Entwickler stehen. Als Konvention hat es sich jedoch etabliert, dass ein solcher Text in einer Datei *README.adoc* im Wurzelverzeichnis eines Quellcode-Repositorys steht. *.adoc* ist dabei die übliche Dateiendung für AsciiDoc-Dateien. Versionsverwaltungen wie GitHub oder GitLab erkennen *README* als die Datei, die sie auf der Startseite eines Repositorys automatisch anzeigen. Dabei zeigen sie nicht die Textversion an, sondern formatieren sie ähnlich wie unten dargestellt mit hervorgehobenen Überschriften, Aufzählungen und Links.
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/example-readme-preview-716c78a96159d959.png)
|
||||
Ausgabe des README als HTML (Abb. 1)
|
||||
|
||||
### Die Entwicklerdokumentation
|
||||
|
||||
Wenn Entwickler in einem neuen Projekt anfangen, ist ein *README.adoc* ein erster guter Start. Danach benötigen sie weitere Informationen mit Codebeispielen. Bei der Navigation in einem solchen Dokument hilft ein Inhaltsverzeichnis. Querverweise im Dokument erleichtern selektives, nichtlineares Lesen im Dokument. Hier ein Beispiel aus einem Entwicklungshandbuch. Das Attribut `toc` zu Beginn des Dokuments generiert ein automatisches Inhaltsverzeichnis:
|
||||
|
||||
```asciidoc
|
||||
= Entwicklungshandbuch
|
||||
Vorname Nachname <autor@asciidoctor.org>
|
||||
1.0, 31.10.2019: Halloween Release
|
||||
:toc-title: Inhaltsverzeichnis
|
||||
:toc:
|
||||
:icons: font
|
||||
|
||||
// Bitte den Abschnitten IDs geben, um sie später referenzieren zu können!
|
||||
[[sec:code-conventions]]
|
||||
== Code-Konventionen
|
||||
|
||||
Hier eine kurze Einführung in unsere Code-Konventionen.
|
||||
|
||||
.Beispielcode
|
||||
[source,java]
|
||||
----
|
||||
/**
|
||||
* Beschreibung, warum diese Methode existiert. <1>
|
||||
*/
|
||||
public int calculatePowerOfTwo(int num) {
|
||||
return num * num; // <2>
|
||||
}
|
||||
----
|
||||
<1> Wir dokumentieren unsere Methoden, es sei denn, es sind einfache Getter- und Setter.
|
||||
<2> Du kannst den Wert direkt zurückgeben, ohne ihn vorher in eine Zwischenvariable zu schreiben.
|
||||
|
||||
[[sec:code-review]]
|
||||
== Code-Review
|
||||
|
||||
. Prüfe die <<sec:code-conventions>>!
|
||||
. Gibt es Kommentare, die das "`Warum`" beschreiben?
|
||||
. Gibt es einen Test, der neue Code-Teile abdeckt?
|
||||
|
||||
NOTE: Code-Reviews sind unsere erste Verteidigungslinie gegen Bugs in Produktion!
|
||||
```
|
||||
|
||||
Im Listing des Handbuchs ist der annotierte Quellcode sichtbar. Die einzelnen Nummern im Quellcode verweisen auf kurze Hinweise darunter. Ein Hinweis ist mit `NOTE:` hervorgehoben.
|
||||
|
||||
In eine HTML-Datei konvertiert wird der annotierte Quellcode wie abgebildet dargestellt. Die hervorgehobenen Hinweise stellt die HTML-Ausgabe als Icons dar, da das Attribut `icons` auf den Wert `font` gesetzt wurde. Der Quellcode wird durch Syntax-Highlighting lesbarer.
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/example-devdocs-preview-5e28e2e9a9bfdfc6.png)
|
||||
Ausgabe der Entwicklerdokumentation als HTML (Abb. 2)
|
||||
|
||||
Das vorherige Beispiel enthielt Quellcode, der als Auszug aus einer Datei in das Dokument hineinkopiert wurde. Das kann dazu führen, dass der Quellcode in der Originaldatei angepasst wird, in der Dokumentation jedoch nicht oder nur unvollständig. Dadurch wäre das Codebeispiel veraltet und kompiliert vielleicht nicht mehr. Besser ist es, die Zeilen zu referenzieren statt sie zu kopieren. Hier ein Beispiel zunächst des Quellcodes mit zusätzlichen `tags`-Kommentaren, dann eingebunden in ein Dokument:
|
||||
|
||||
```asciidoc
|
||||
public class Calculator {
|
||||
// tag::mymethod[]
|
||||
public int calculatePowerOfTwo(int num) {
|
||||
return num * num; // <2>
|
||||
}
|
||||
// end::mymethod[]
|
||||
}
|
||||
|
||||
[source,java,indent=0]
|
||||
----
|
||||
include::Calculator.java[tag=mymethod]
|
||||
----
|
||||
<2> Du kannst den Wert direkt zurückgeben...
|
||||
```
|
||||
|
||||
Damit kompilieren die Codebeispiele und sind wie jeder andere Code durch Unit-Tests testbar. Die zusätzliche Option `indent=0` passt die Einrückung an und entfernt die führenden Leerzeichen des ausgeschnittenen Codebeispiels. Das ermöglicht Entwicklungshandbücher von hoher Qualität.
|
||||
|
||||
### Fachliche Dokumentation
|
||||
|
||||
Für eine fachliche Dokumentation braucht es aber mehr als Quellcode und Referenzen. Hier sind Tabellen und Diagramme gefragt, die Inhalte strukturieren und übersichtlicher darstellen können als ein langer Text. Eine einfache Tabelle sieht im Quellcode wie folgt aus:
|
||||
|
||||
```markdown
|
||||
|===
|
||||
|Thema |Text |Mehr...
|
||||
|
||||
|Ein Thema
|
||||
|Text
|
||||
|Noch mehr Text
|
||||
|
||||
|Zweites Thema
|
||||
|Text Nr. 2
|
||||
|Ganz viel Text
|
||||
|===
|
||||
```
|
||||
|
||||
Als HTML-Ausgabe stellt es sich wie folgt dar:
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/abb3-067ddda24b50a64c.png)
|
||||
Darstellung einer Tabelle (Abb. 3)
|
||||
|
||||
Mit zusätzlichen Attributen erlaubt AsciiDoc Textausrichtung und horizontal und vertikal zusammengefasste Zellen. Für mathematisch-wissenschaftliche Darstellungen bietet es Formeln im LaTeX- und AsciiMath-Format. Aus folgendem Text wird mit [MathJax](https://www.mathjax.org/) in der Ausgabe eine gesetzte Formel.
|
||||
|
||||
```asciidoc
|
||||
stem:[sqrt(4) = 2]
|
||||
|
||||
Eine Matrix: stem:[[[a,b\],[c,d\]\](https://www.heise.de/hintergrund/(n),(k))].
|
||||
|
||||
latexmath:[C = \alpha + \beta Y^{\gamma} + \epsilon]
|
||||
```
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/abb4-94dd414d9500f058.png)
|
||||
Darstellung der Formeln in der Ausgabe (Abb. 4)
|
||||
|
||||
UML-Diagramme wie ein Ablaufdiagramm lassen sich über [PlantUML](https://plantuml.com/) als Text beschreiben und als Grafik ausgeben:
|
||||
|
||||
```asciidoc
|
||||
@startuml
|
||||
|Akteur A|
|
||||
start
|
||||
:Schritt 1;
|
||||
|#AntiqueWhite|Akteur B|
|
||||
' Dies ist ein Kommentar im
|
||||
' Quellcode des Diagramms
|
||||
:Schritt 2;
|
||||
:Schritt 3;
|
||||
|Akteur A|
|
||||
:Schritt 4;
|
||||
|Akteur B|
|
||||
:Schritt 5;
|
||||
stop
|
||||
@enduml
|
||||
```
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/abb5-7b5bfc5742569b0d.png)
|
||||
Ablaufdiagramm in der Ausgabe (Abb. 5)
|
||||
|
||||
Auch für diese Diagramme ist in der Versionshistorie nachvollziehbar, wer sie wann und als Teil von welcher Aufgabe warum geändert hat.
|
||||
|
||||
### IT-Architekturdokumentation
|
||||
|
||||
Alle Elemente, die die fachliche Dokumentation nutzt, eignen sich auch für eine IT-Architekturdokumentation: Sie benötigt ebenso Tabellen, Diagramme, Querverweise et cetera. Um nicht bei jedem neuen Projekt von vorne zu beginnen, gibt es frei verfügbare Vorlagen. [Eine solche Vorlage findet sich unter arc42.de](https://arc42.de/). Sie ist in AsciiDoc geschrieben und unterstützt Projekte durch eine erprobte Dokumentationsstruktur. Projekte können sie im Projektverlauf nach und nach füllen. Erklärende Kommentare helfen beim Schreiben der Kapitel, sodass sich auch Einsteiger im Bereich Architekturdokumentation zurechtfinden.
|
||||
|
||||
Das arc42-Projekt zeigt außerdem, wie Dokumentations-Pipelines funktionieren: Die Vorlage wird im AsciiDoc-Format gepflegt. Daraus erstellt ein automatischer Build-Prozess verschiedene Zielformate: unter anderem Word, Markdown, HTML und reStructuredText.
|
||||
|
||||
### API-Dokumentation mit Beispielen
|
||||
|
||||
Neben aufgeschriebenen Texten gibt es in Projekten immer wieder automatisch erzeugte Inhalte. Das sind zum Beispiel technische Datenmodelle, die man aus dem Datenbankschema erzeugt, oder Listen von Fehler-Codes und -beschreibungen, die Entwickler im Programm als Konstanten hinterlegt haben und aus denen Handbücher generiert werden. Hier hilft eine [einfache Template-Sprache wie Freemarker](https://freemarker.apache.org/), um Dokumentationsteile automatisiert zu erstellen.
|
||||
|
||||
Das [Konzept von Spring REST Docs](https://docs.spring.io/spring-restdocs/docs/current/reference/html5/) geht noch etwas weiter: Es nutzt für die Dokumentation von REST-Schnittstellen Beispielanfragen und -antworten, die in automatisierten Testfällen aufgezeichnet werden. Diese ergänzt man um zusätzlichen erklärenden Text. Das Ergebnis ist eine Dokumentation, die mit konkreten Beispielen zeigt, wie die Schnittstelle genutzt werden soll. Im Vergleich zu einer Schnittstellendokumentation im OpenAPI-Format, die nur Methoden und Felder zeigt (Syntax und ggf. etwas Semantik), ist das ein deutlicher Zugewinn von Verwendung und Bedeutung (Pragmatik): Die verschiedenen Aufrufe und Felder werden in einen Kontext gesetzt im Ablauf gezeigt.
|
||||
|
||||
Neben dem vorgestellten AsciiDoc-`include`-Makro bringt Spring REST Docs ein zusätzliches `operation`-Makro mit, das aufgezeichnete Elemente (Snippets) einbindet. Hier ein Auszug aus einem [offiziellen Beispiel des Spring-REST-Docs-Projekts](https://github.com/spring-projects/spring-restdocs/tree/master/samples/rest-notes-spring-hateoas):
|
||||
|
||||
```asciidoc
|
||||
=== Listing notes
|
||||
|
||||
A `GET` request will list all of the service's notes.
|
||||
|
||||
operation::notes-list-example[snippets='response-fields,curl-request,http-response']
|
||||
```
|
||||
|
||||
Ein Test zeichnet die Antworten auf und prüft, ob die erwarteten Felder in der Antwort enthalten sind:
|
||||
|
||||
```java
|
||||
@Test
|
||||
public void notesListExample() throws Exception {
|
||||
|
||||
/* .... */
|
||||
|
||||
this.mockMvc.perform(get("/notes"))
|
||||
.andExpect(status().isOk())
|
||||
.andDo(document("notes-list-example",
|
||||
responseFields(
|
||||
subsectionWithPath("_embedded.notes").description("An array of [Note](#note) resources"),
|
||||
subsectionWithPath("_links").description("Links to other resources"))));
|
||||
}
|
||||
```
|
||||
|
||||
Das `operation`-Makro fügt in der Ausgabe die Beschreibung der Antwortfelder, den Aufruf als `curl`-Befehl und die HTTP-Antwort im JSON-Format ein:
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/abb6-263275e61056170a.png)
|
||||
Ausgabe der API-Dokumentation als HTML (Abb. 6)
|
||||
|
||||
Analog zur Entwicklerdokumentation, die per `include` getestete Codebeispiele anzeigt, entsteht hier eine Schnittstellendokumentation mit getesteten Beispielen.
|
||||
|
||||
### Arbeitsalltag mit Docs as Code
|
||||
|
||||
Die AsciiDoc-Dokumente sind zunächst einfache Textdateien. Bei der Bearbeitung hilft eine Entwicklungsumgebung mit entsprechenden Plug-ins. Bei der Übersicht hilft Strukturierung in handliche Dokumententeile.
|
||||
|
||||
Während sich das erste *README.adoc* noch intuitiv in jedem Texteditor bearbeiten lässt, zeigt die Entwicklungsdokumentation mehr Funktionen. Eine passende Überstützung im Editor erlaubt eine komfortable Bearbeitung der Dateien, zum Beispiel durch Syntax-Highlighting, Navigation zu Includes und Referenzen und Livevorschau bei Änderungen. Entsprechende Plug-ins gibt es etwa für [Eclipse](https://marketplace.eclipse.org/content/asciidoctor-editor), [IntelliJ IDEA](https://github.com/asciidoctor/asciidoctor-intellij-plugin), [Atom](https://atom.io/packages/asciidoc-assistant) und [Visual Studio Code](https://marketplace.visualstudio.com/items?itemName=joaompinto.asciidoctor-vscode).
|
||||
|
||||
Der Autor dieses Artikels ist Maintainer des Plug-ins für IntelliJ IDEA. Es bietet eine Strukturansicht des Dokuments für einen Überblick über die Kapitelstruktur und zur Navigation. Die bekannten Tastaturkürzel funktionieren, um zum Beispiel zu einer Referenz zu springen oder Referenzen über Dateigrenzen umzubenennen. Mit der für IntelliJ IDEA verfügbaren Rechtschreib- und [Grammatikprüfung Grazie](https://plugins.jetbrains.com/plugin/12175-grazie/) zieht die IDE mit Office-Paketen gleich.
|
||||
|
||||
[Mit AsciidoctorFX gibt es außerdem einen Standalone-Editor](https://asciidocfx.com/), der einen großen Funktionsumfang für Vorschau und Plug-ins umfasst. Auf der Website des Editors sind einige Bücher verlinkt, die mit ihm in AsciiDoc geschrieben wurden.
|
||||
|
||||
### Refactoring und Strukturierungen
|
||||
|
||||
Wächst ein Dokument im Umfang, stellen sich die Fragen nach mehr Struktur und die Aufteilung in kleinere, handhabbare Dateien. Wem beim Wort "Master-Dokument" kalte Schauer bei der Erinnerung an vergangene Office-Abenteuer den Rücken herunterlaufen, sei beruhigt: Mit der gleichen `include::[]`-Syntax wie oben bei den eingebundenen Quellcodes lassen sich auch Dokumententeile nachvollziehbar und zuverlässig einbinden. Asciidoctor unterstützt mehrere `include`-Stufen, sodass das Master-Dokument die Kapitel und diese die Unterkapitel einbinden. Verschiedene Master-Dokumente können Kapitel und Unterkapitel unterschiedlich einbinden oder sortieren, sodass ein für den jeweiligen Empfängerkreis maßgeschneidertes Dokument entsteht.
|
||||
|
||||
Selbstdefinierte Attribute erlauben konsistente Textbausteine, Namen oder URLs, die sich dann in allen Kapiteln referenzieren lassen. Zeilen- und Blockkommentare geben Autoren Bearbeitungshinweise und erlauben es, Inhalte vorübergehend auszukommentieren.
|
||||
|
||||
```asciidoc
|
||||
= Hauptdokument
|
||||
|
||||
// selbstdefinierte Attribute für dieses Dokument
|
||||
:homepage: https://my.home.page
|
||||
|
||||
== Willkommen
|
||||
|
||||
Mehr Informationen finden Sie auf unserer {homepage}[Homepage]!
|
||||
|
||||
include::kapitel_ueberblick.adoc[]
|
||||
|
||||
include::kapitel_basisfunktionen.adoc[]
|
||||
|
||||
////
|
||||
Dieses Kapitel ist noch in Arbeit...
|
||||
include::kapitel_03.adoc[]
|
||||
////
|
||||
|
||||
////
|
||||
Dieses Kapitel nur ausgeben, wenn "premiumkunde" als Attribut gesetzt wurde,
|
||||
z. B. über die Kommandozeile wie hier
|
||||
asciidoctor -a premiumkunde dokument.adoc
|
||||
////
|
||||
ifdef::premiumkunde[]
|
||||
include::kapitel_premiumfunktionen.adoc[]
|
||||
endif::[]
|
||||
```
|
||||
|
||||
`ifdef` blendet abhängig von Attributen Teile des Dokuments ein und aus. Die Attribute lassen sich auf der Kommandozeile setzen oder im Build-Prozess zum Beispiel im Gradle- oder Maven-Plug-in für Asciidoctor übergeben.
|
||||
|
||||
### Ausliefern von Dokumenten
|
||||
|
||||
Ist ein erster Entwurf der Dokumente fertig, ist es an der Zeit, sie den Lesern zu präsentieren. Im Browser ist die Dokumentation einfach zugänglich und sie lässt sich als Teil in eine bestehende Website integrieren. Als PDF kann man die Dokumentation als einzelne versionierte Datei zum Beispiel als Handbuch einer Softwarelieferung mitgeben. [Für Präsentationen gibt es eine Integration in reveal.js](https://asciidoctor.org/docs/asciidoctor-revealjs/).
|
||||
|
||||
Die Inhalte der Präsentation schreiben Autoren in AsciiDoc, das Styling erfolgt über Themes ergänzt um individuelles CSS. [Die Präsentation der Folien übernimmt das JavaScript-Paket reveal.js](https://revealjs.com/#/).
|
||||
|
||||
Ein Continuous-Integration-Server erstellt diese Dokumente automatisch nach jeder Änderung an den Quellen; alle Schritte sind über wenige Kommandos automatisierbar. Wer verschiedene Quellen für seine Dokumentationspipeline anbinden möchte und verschiedene Formate und Systeme mit Dokumentation versorgen möchte, [dem sei das Projekt docToolchain ans Herz gelegt](https://doctoolchain.github.io/docToolchain/). Hier finden sich Anleitungen und Skripte, um viele wiederkehrende Aufgaben zu automatisieren. Damit lassen sich Quellen wie Sparx Enterprise Architect anbinden und Ergebnisse etwa nach Confluence publizieren.
|
||||
|
||||
### Publizieren als HTML
|
||||
|
||||
Meist ist ein einzelnes Dokument oder ein Master-Dokument in eine HTML-Datei zu wandeln. Am einfachsten gelingt das über die Kommandozeile, nachdem Ruby beziehungsweise JRuby und dasAsciidoctor Gem installiert sind:
|
||||
|
||||
```shell
|
||||
gem install asciidoctor
|
||||
```
|
||||
|
||||
In JavaScript-Umgebungen wird die Kommandozeilenversion für [Asciidoctor für Node.js](https://github.com/asciidoctor/asciidoctor-cli.js/) wie folgt installiert:
|
||||
|
||||
```shell
|
||||
npm i -g asciidoctor
|
||||
```
|
||||
|
||||
Ein einzelnes Dokument wird dann wie folgt konvertiert:
|
||||
|
||||
```shell
|
||||
asciidoctor document.adoc
|
||||
```
|
||||
|
||||
Das Ergebnis ist eine Datei *document.html*, die sich auf einem Webserver publizieren und im Browser anzeigen lässt. Wer keine Ruby- oder Node.js-Umgebung installieren möchte, kann die Konvertierung beispielsweise über einen Maven- oder Gradle-Build anstoßen.
|
||||
|
||||
Sollen Inhalte zur Laufzeit aufbereitet werden, bietet Asciidoctor APIs in Ruby, Java und JavaScript an. Hier ein JavaScript-Beispiel, das [zunächst ein alternatives Backend "Semantic-HTML für Asciidoctor" lädt und anschließend AsciiDoc in HTML konvertiert](https://github.com/jirutka/asciidoctor-html5s):
|
||||
|
||||
```js
|
||||
const asciidoctor = require("asciidoctor")(),
|
||||
asciidoctorHtml5s = require("asciidoctor-html5s")
|
||||
|
||||
// Register the HTML5s converter and supporting extension.
|
||||
asciidoctorHtml5s.register()
|
||||
|
||||
// default option
|
||||
const defaultOptions = {
|
||||
sourceHighlighter: "highlightjs",
|
||||
backend: "html5s"
|
||||
}
|
||||
|
||||
module.exports = function(content) {
|
||||
this.cacheable && this.cacheable()
|
||||
var params = loaderUtils.getOptions(this)
|
||||
var options = Object.assign({}, defaultOptions, params)
|
||||
var html = asciidoctor.convert(content, options)
|
||||
return "<section>" + html + "</section>"
|
||||
}
|
||||
```
|
||||
|
||||
Damit lassen sich Inhalte für Websites im AsciiDoc-Format verwalten und zur Build- oder Laufzeit in HTML wandeln und anzeigen. Die Inhalte können auf diese Weise vom Layout getrennt und an verschiedenen Stellen wiederverwendet werden.
|
||||
|
||||
Für Dokumentations-Websites integriert sich Asciidoctor in statische Website-Generatoren wie [Jekyll](https://github.com/asciidoctor/jekyll-asciidoc) oder [JBake](https://jbake.org/). Für große Projekte bietet sich [Antora](https://antora.org/) an, das Informationen aus mehreren Repositories und Branches zusammenführen und publizieren kann. Die Open-Source-Projekte [Couchbase](https://docs.couchbase.com/home/index.html) und [Fedora](https://docs.fedoraproject.org/en-US/fedora/f31/) nutzen beide Antora, um Dokumentation ihrer Releases auf einer Website darzustellen. Auf jeder Seite findet sich ein Edit-Button, der es Lesern ermöglicht, die Inhalte der Seite im AsciiDoc-Format im Browser zu bearbeiten.
|
||||
|
||||
### Publizieren als PDF
|
||||
|
||||
Um ein AsciiDoc-Dokument in ein PDF zu wandeln, stehen Nutzern verschiedene Implementierungen zur Verfügung:
|
||||
|
||||
1. Asciidoctor DocBook erzeugt auf Wunsch das DocBook-5.0-Format, aus dem sich über eine LaTeX- oder XSLT-FO-Verarbeitungskette druckfertige Dokumente erzeugen lassen.
|
||||
2. [Asciidoctor PDF Ruby](https://asciidoctor.org/docs/asciidoctor-pdf/) basiert auf Ruby und Prawn und läuft in jeder Ruby-, JRuby- und Java-Umgebung. Hierfür stehen auch Gradle- und Maven-Plug-ins zur Automatisierung zur Verfügung.
|
||||
3. [Asciidoctor PDF JavaScript](https://github.com/Mogztter/asciidoctor-pdf.js) basiert auf JavaScript und Puppeteer, das einen reduzierten Chrome-Browser (Chromium) für die PDF-Erstellung fernsteuert. Der Build lässt sich über npm oder yarn automatisieren, die auch Puppetteer und Chromium installieren.
|
||||
4. [Asciidoctor Latex](https://github.com/asciidoctor/asciidoctor-latex) ist eine Asciidoctor-Erweiterung, mit der man AsciiDoc-Dokumente ohne den Umweg über DocBook mit LaTeX in druckfertige Dokumente und PDFs wandelt.
|
||||
|
||||
Die populärste Implementierung ist die Asciidoctor-PDF-Ruby-Implementierung, da sie PDFs ohne zusätzliche Werkzeuge erstellen kann. Sie liegt derzeit als Release-Candiate-Version vor und unterstützt den kompletten AsciiDoc-Sprachumfang zur Formatierung von Text, Bildern und Tabellen. Über 900 Tests stellen sicher, dass es im Alltag keine Überraschungen gibt. Die Layouts sind parametrisierbar, sodass sich individuelle Schriftarten, Seitenformate und Abstände nutzen lassen. Die aus AsciiDoc generierten PDF können Anwender mit Seiten aus bestehenden PDFs ergänzen.
|
||||
|
||||
Die Implementierung mit dem größten Potenzial für ein individuelles PDF-Layout ist die JavaScript-Implementierung. Sie liegt derzeit als Alpha-Version vor. Während Prawn nur eingeschränktes Styling zulässt, stehen Designern hier die kompletten Möglichkeiten von CSS offen. Im Standardlayout sehen die Dokumente ähnlich wie die der Ruby-Implementierung aus; über Stylesheets lässt sich das Layout anpassen oder komplett individuell gestalten. Beispiele auf der Projektseite zeigen individuelle Layouts für Bücher, Cheatsheets, Briefe und Präsentationen.
|
||||
|
||||
### Fazit
|
||||
|
||||
Mit AsciiDoc nutzen Autoren aus der Softwareentwicklung bekannte Werkzeugen wie Git und IDEs und Methoden wie Code-Reviews, Refactorings, Includes und Continuous Integration. Es entstehen Websites und Handbücher mit Codebeispielen, die kompilieren, und API-Beschreibungen mit zur aktuellen Version passenden Beispielen. AsciiDoc als Sprache und Asciidoctor als Implementierung versetzen Teams in die Lage, Softwaresysteme und ihre Dokumentation aus einem Guss zu erstellen, kontinuierlich weiterzuentwickeln und automatisiert zu publizieren.
|
||||
|
||||
Die Syntax von AsciiDoc erschließt sich beim Lesen von Dokumenten. Für ein erstes *README.adoc* reichen ein paar wenige Syntaxelemente. Für größere und komplexere Dokumente stellt es alle wichtigen Elemente wie Tabellen, Diagramme und Formeln zur Verfügung, die ansprechende und ausdrucksstarke Websites und Bücher benötigen. Bei der Umsetzung hilft die ausführliche Dokumentation auf der Asciidoctor-Website.
|
||||
|
||||
Alles zusammen gute Voraussetzungen, um in Projekten Documentation as Code mit Asciidoctor zuerst auszuprobieren und dann durchgängig zu implementieren.
|
||||
|
||||
*Alexander Schwartz*
|
||||
*arbeitet als Principal IT Consultant bei der msg. Im Laufe der Zeit hatte er mit verschiedensten Server- und Webtechnologien zu tun. Auf Konferenzen und bei User Groups spricht er über seine Erfahrungen, [in seinem Blog schreibt er zu Themen rund um die IT](https://www.ahus1.de/).*
|
||||
+89
@@ -0,0 +1,89 @@
|
||||
---
|
||||
title: >-
|
||||
Dokumentationen als Code: So verwandeln Sie AsciiDoc in PDF, DOCX, Confluence und EPUB
|
||||
updated: 2023-04-19 13:56:19Z
|
||||
created: 2023-04-19 13:56:19Z
|
||||
tags:
|
||||
- IT
|
||||
- Asciidoctor
|
||||
- Dokumentation
|
||||
- DocumentationAsCode
|
||||
source: >-
|
||||
https://entwickler.de/software-architektur/dokumentationen-als-code-so-verwandeln-sie-asciidoc-in-pdf-docx-confluence-und-epub/
|
||||
---
|
||||
|
||||
In der [letzten Folge dieser Kolumne](https://entwickler.de/%22https://jaxenter.de/documentation-modularisierung-63743/%22) haben wir gezeigt, wie Sie Ihre AsciiDoc-Dokumente modular aufbauen können. In der dritten Folge der Kolumne erklären wir am Beispiel der Formate PDF, DOCX, Confluence und EPUB, wie sich verschiedene Ausgabeformate aus Ihrem AsciiDoc-Input erzeugen lassen.
|
||||
|
||||
AsciiDoc-Dokumente lassen sich sehr einfach in viele unterschiedliche Ausgabeformate umwandeln. Am Beispiel HTML5 haben Sie das in Folge eins und zwei der Kolumne schon gesehen. Aber wie lassen sich andere Formate erzeugen?
|
||||
|
||||
Die Dokumentation des Asciidoctor-Plug-ins für Gradle gibt erste Hinweise \[1\]: Mithilfe von Attributen lassen sich verschiedene Backends für verschiedene Ausgabeformate definieren. Im Gepäck hat Asciidoctor dabei verschiedene HTML-Varianten (HTML5 und XHTML), DocBook in zwei Versionen (4.5 und 5.0) und manpages \[2\]. Wer weitere Formate erzeugen möchte, muss etwas tiefer in die Trickkiste greifen.
|
||||
|
||||
## Plug-ins helfen weiter
|
||||
|
||||
Für PDF gibt es verschiedene Alternativen von DocBook-Konvertierung mittels Apache FOP über PDF-Druck der HTML-Ausgabe mit PhantomJS bis hin zum Asciidoctor-PDF-Plug-in in der Alphaversion. Alle Ansätze funktionieren und liefern Resultate unterschiedlicher Qualität. Wir haben mit dem Asciidoctor-PDF-Plug-in die besten Ergebnisse erzielt (Abb. 1), und es sieht ganz danach aus, als würde es bald ein fertiges Release geben.
|
||||
|
||||
[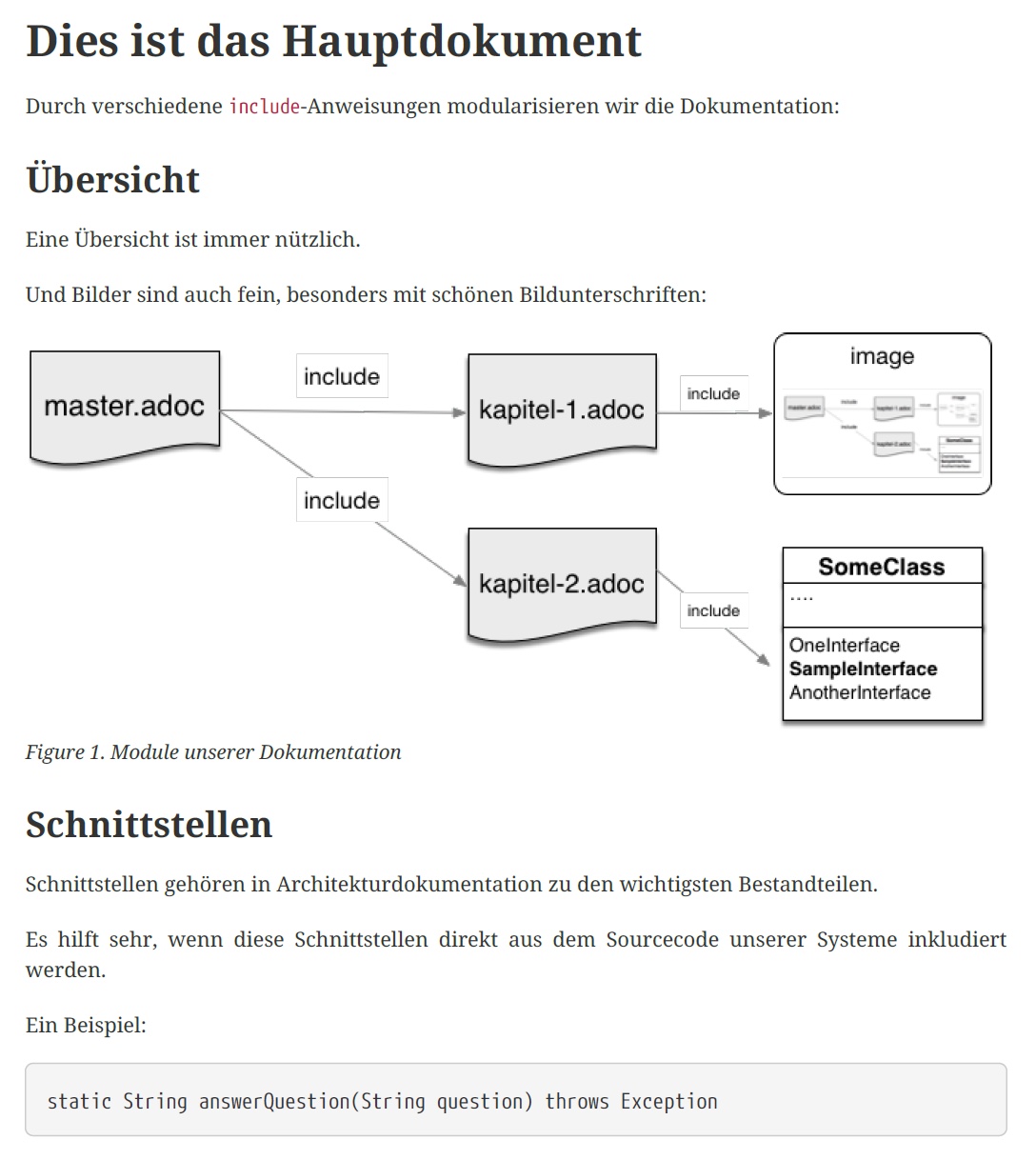](https://jaxenter.de/wp-content/uploads/2017/12/mueller_starke_dac_1.jpg)
|
||||
|
||||
Abb. 1: PDF-Ausgabe des modularisierten Dokuments
|
||||
|
||||
Listing 1 zeigt unser Build-Skript, mit dem sich jetzt neben HTML auch PDF generieren lassen.
|
||||
|
||||
**Listing 1: „build.gradle“ (Auszug)**
|
||||
|
||||
```groovy
|
||||
import org.asciidoctor.gradle.AsciidoctorTask
|
||||
...
|
||||
dependencies {
|
||||
asciidoctor 'org.asciidoctor:asciidoctorj-pdf:1.5.0-alpha.15'
|
||||
}
|
||||
…
|
||||
tasks.withType(AsciidoctorTask) { docTask ->
|
||||
attributes \
|
||||
'source-highlighter': 'coderay',
|
||||
'imagesdir': 'images',
|
||||
'toc': 'left', 'icons': 'font'
|
||||
}
|
||||
...
|
||||
task generatePDF (type: AsciidoctorTask) {
|
||||
attributes \
|
||||
'pdf-stylesdir': 'pdfTheme',
|
||||
'pdf-style': 'custom'
|
||||
|
||||
backends = ['pdf']
|
||||
}
|
||||
```
|
||||
|
||||
Listing 1 zeigt auch die Flexibilität von Gradle – über *tasks.withType(AsciidoctorTask)* werden generelle Einstellungen für Asciidoctor vorgenommen. Anschließend lassen sich für verschiedene Anwendungsfälle mit *task generatePDF (type: AsciidoctorTask)* unterschiedliche Gradle-Build-Tasks erstellen, die dann die fallspezifische Konfiguration setzen. Der Bau der unterschiedlichen Ausgabeformate lässt sich so sauber trennen.
|
||||
|
||||
## Pandoc – das Schweizer Taschenmesser zur Konvertierung
|
||||
|
||||
Reichen HTML und PDF dem Entwickler nicht aus, weil z. B. DOCX der Unternehmensstandard ist oder die umfangreiche Dokumentation sich leichter auf einem E-Book-Reader liest, so lohnt sich ein Blick auf Pandoc \[3\]. Pandoc kann Dokumente aus einer Vielzahl von Ausgangsformaten in fast beliebige Zielformate konvertieren. Praktisch verlustfrei funktioniert das unter anderem mit dem DocBook-Format. AsciiDoc liefert perfektes DocBook – was Pandoc dann zur weiteren Verarbeitung nutzen kann. Listing 2 zeigt den Aufruf von Pandoc zur Konvertierung nach DOCX mittels Gradle-Exec-Task. Genauso gut funktioniert die Konvertierung in das beliebte EPUB-Format.
|
||||
|
||||
**Listing 2: Gradle-Exec-Task**
|
||||
|
||||
```groovy
|
||||
task convertToDocx ( type: Exec) {
|
||||
workingDir 'build/asciidoc/docbook'
|
||||
executable = "pandoc"
|
||||
new File('build/asciidoc/docx/').mkdirs()
|
||||
args = ['-r','docbook',
|
||||
'-t','docx',
|
||||
'-o','../docx/master.docx',
|
||||
'master.xml']
|
||||
}
|
||||
```
|
||||
|
||||
## Jetzt wird’s Groovy!
|
||||
|
||||
Sie wollen noch mehr? Über die HTML-5- und DocBook-Ausgabe \[4\] liegt Ihre Dokumentation in zwei strukturierten Formaten vor, die sich leicht noch weiter verarbeiten lassen. In Gradle steht dem Entwickler zudem Groovy als Skriptsprache, die für die einfache Bearbeitung von XML-Dateien bekannt ist, zur Verfügung.
|
||||
|
||||
Mit diesem Werkzeugkasten lässt sich die Dokumentation auch in einem Wiki veröffentlichen. Das oft verwendete Confluence von Atlassian speichert seine Seiten beispielsweise in einem XHTML-Dialekt und verfügt über ein REST-API. Das Open-Source-Projekt docToolchain \[5\] hat dies als Gradle-Task implementiert, wobei das generierte HTML-Dokument entsprechend der Überschriftenebenen in Seiten und Unterseiten zerlegt wird, um so eine einem Wiki entsprechende Strukturierung zu erreichen (Abb. 2).
|
||||
|
||||
Den vollständigen Code zur Konvertierung eines kleinen Beispiels in HTML, PDF und DOCX finden Sie in unserem Code-Repository \[6\].
|
||||
|
||||
[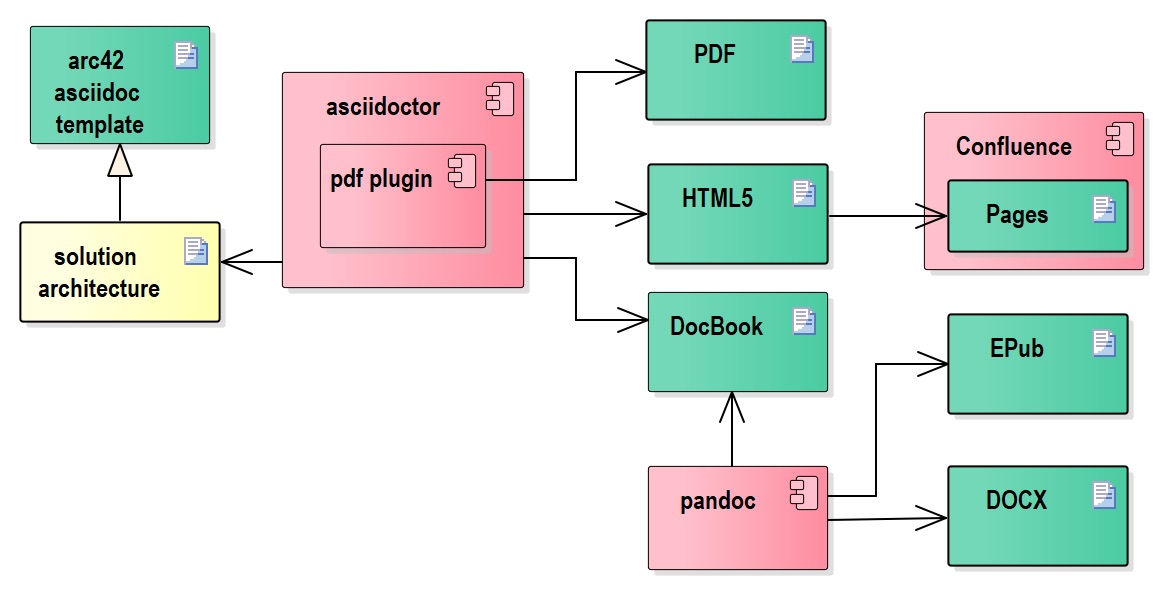](https://jaxenter.de/wp-content/uploads/2017/12/mueller_starke_dac_2.jpg)
|
||||
Abb. 2: Schematische Darstellung der Formatkonvertierungen
|
||||
|
||||
## Fazit
|
||||
|
||||
Das Potenzial, das in der Behandlung von Dokumentation wie Code schlummert, ist riesig. So wird die Dokumentation nicht nur zusammen mit dem Code verwaltet, die Modularisierung der Dokumente vereinfacht auch die Zusammenarbeit zwischen den verschiedenen Eigentümern der Dokumentation. Nutzt der Entwickler dann noch die eigenen Programmierkenntnisse – wie im Beispiel der Konvertierung nach Confluence gezeigt – so erhält er ein mächtiges Werkzeug, von dem wir in den nächsten Folgen noch ausgiebig Gebrauch machen werden. Im nächsten Teil dieser Kolumne betrachten wir AsciiDoc selbst etwas genauer und stellen Ihnen diejenigen Konstrukte vor, die Sie für die Architekturdokumentation und andere technische Dokumente am häufigsten benötigen werden. Bis dahin: Enjoy docs-as-code …
|
||||
@@ -0,0 +1,42 @@
|
||||
---
|
||||
title: 'Emotet: Die gefährlichste Schadsoftware der Welt ist zurück'
|
||||
updated: 2021-11-17 09:37:18Z
|
||||
created: 2021-11-17 09:36:45Z
|
||||
tags:
|
||||
- IT
|
||||
- Sicherheit
|
||||
- Datenschutz
|
||||
source: >-
|
||||
https://www.spiegel.de/netzwelt/web/emotet-die-gefaehrlichste-schadsoftware-der-welt-ist-zurueck-a-d0798d8a-8691-401e-a346-36acbc07ab82
|
||||
---
|
||||
|
||||
## [Emotet: Die gefährlichste Schadsoftware der Welt ist zurück](https://www.spiegel.de/netzwelt/web/emotet-die-gefaehrlichste-schadsoftware-der-welt-ist-zurueck-a-d0798d8a-8691-401e-a346-36acbc07ab82)
|
||||
|
||||
Im Januar verkündeten deutsche Sicherheitsbehörden stolz das Ende von Emotet: Die Infrastruktur hinter der Schadsoftware sei abgeschaltet worden. Doch jetzt wird der Trojaner erneut verbreitet.
|
||||
|
||||
16.11.2021, 10.26 Uhr
|
||||
|
||||

|
||||
Emotet galt als Türöffner für Erpresser-Software (Symbolbild)
|
||||
|
||||
Foto: Alexander Limbach / imago images
|
||||
|
||||
Von einem »bedeutenden Schlag gegen die international organisierte Internetkriminalität« [sprach](https://www.bka.de/DE/Presse/Listenseite_Pressemitteilungen/2021/Presse2021/210127_pmEmotet.html) das Bundeskriminalamt (BKA) Ende Januar, von einer »wesentlichen Verbesserung der Cybersicherheit in Deutschland«. In Kooperation mit Strafverfolgungsbehörden aus sieben weiteren Ländern hatten die deutschen Sicherheitsbehörden [den »König der Schadsoftware« niedergestreckt](https://www.spiegel.de/netzwelt/web/emotet-gestoppt-strafverfolger-zerschlagen-infrastruktur-der-beruechtigten-schadsoftware-a-dbc45b2a-11d5-453e-a8b2-f56088c85133): Emotet.
|
||||
|
||||
Der Titel stammt von Arne Schönbohm, Präsident des Bundesamts für Sicherheit in der Informationstechnik (BSI). Aber auch das BKA sprach von »der gefährlichsten Schadsoftware weltweit«. Emotet war ein extrem erfolgreicher Trojaner, ein Türöffner unter anderem für Ransomware, mit der Behörden und Firmen erpresst werden. Allein in Deutschland hat Emotet Schäden von mindestens 14,5 Millionen Euro verursacht. Kein Wunder also, dass die Strafverfolger nicht nur die Übernahme und Abschaltung der Emotet-Server als Erfolg feierten. Auch die Verbreitung eines Emotet-Updates an infizierte Systeme in aller Welt, mit dem sich die Schadsoftware selbst unbrauchbar machte, schrieben sie sich auf die Fahne – obwohl es für die Aktion [gar keine Rechtsgrundlage gab](https://netzpolitik.org/2021/schadsoftware-bereinigung-bka-nutzt-emotet-takedown-als-tueroeffner-fuer-mehr-befugnisse-und-neue-gesetze/).
|
||||
|
||||
Doch die Freude war nicht von Dauer. Der »König« ist wieder da. IT-Sicherheitsexperten des Bochumer Unternehmens G Data, das die Behörden bei der Abschaltung mit technischen Analysen unterstützt hatte, stellten am Sonntagabend [fest](https://cyber.wtf/2021/11/15/guess-whos-back/), dass Systeme, die bereits mit der Schadsoftware TrickBot infiziert sind, plötzlich eine neue Datei aus dem Internet laden – und die wurde automatisch als Emotet erkannt. Eine erste manuelle Überprüfung erhärtet den Verdacht bisher.
|
||||
|
||||
Bestätigt wurde die Entdeckung kurz darauf unter anderem [von einem Mitarbeiter der Firma Proofpoint](https://twitter.com/wesdrone/status/1460420794207682562) sowie [von Cryptolaemus](https://twitter.com/Cryptolaemus1/status/1460403592658145283), einem Zusammenschluss von Sicherheitsfachleuten, die es sich einst zur Aufgabe gemacht hatten, [den Emotet-Kriminellen das Leben so schwer wie möglich zu machen](https://www.spiegel.de/netzwelt/web/trojaner-emotet-wer-ist-ivan-a-a8bf3c85-cac9-4cb4-8755-d350ff5850f7) – durch ständige Hilfestellung für Systemadministratoren bei der Abwehr der Schadsoftware.
|
||||
|
||||
### Emotet ist bekannt für raffinierte Spammails
|
||||
|
||||
Für Tilman Frosch, Geschäftsführer von G Data Advanced Analytics, kommt das nicht überraschend. Im Gespräch mit dem SPIEGEL sagte er: »Die Kooperation von TrickBot und Emotet ist nicht neu. Aus den früheren Aktivitäten war offensichtlich, dass Logistik zu den Kernfähigkeiten der Emotet-Gruppe gehört.«
|
||||
|
||||
Den an der Zerschlagung Beteiligten müsse auch klar gewesen sein, dass eine Rückkehr von Emotet möglich ist, die Hintermänner aber zumindest Zeit und Geld kosten würde. »Auch eine Störung des Geschäftsmodells ist ein Erfolg«, sagt Frosch. »Der Takedown hat sie zumindest die Einnahmen aus zehn Monaten gekostet«. Die Kosten für den Wiederaufbau der Infrastruktur kommen noch hinzu.
|
||||
|
||||
Insbesondere für Behörden, Firmen und ihre Systemadministratoren, aber auch Internetprovider bedeutet die Emotet-Wiederkehr, dass sie ihre Erkennungssysteme anpassen müssen. Frosch rät Netzbetreibern, die von [abuse.ch](http://abuse.ch/) gelisteten Emotet-Kontroll-Server zu blockieren und Mittelständlern, ihre IT-Systemhäuser zu kontaktieren. Akut gefährdet sind zwar nur Systeme, die bereits mit TrickBot identifiziert sind, doch das kann sich schnell ändern. Frosch sagt: »Wenn Emotet das gleiche Muster verfolgt wie früher, werden die Täter bald raffinierte Spammails versenden«.
|
||||
|
||||
Die können dann jeden erreichen, [davor warnt auch das BSI](https://www.bsi.bund.de/SharedDocs/Cybersicherheitswarnungen/DE/2021/2021-269890-1032.pdf?__blob=publicationFile&v=3): »Es muss davon ausgegangen werden, dass es in Kürze erneut zu umfangreichen Emotet-Spam-Wellen kommen wird, wie sie 2019 und 2020 häufig beobachtet werden konnten. Durch von Emotet nachgeladene weitere Schadsoftware könnte es wieder zu zahlreichen Kompromittierungen von Netzwerken von Behörden und Unternehmen kommen.« Die wirksamste Schutzmaßnahme sei »die Einschränkung von unsignierten Makros«.
|
||||
|
||||
*Hinweis*: Die BSI-Angaben im letzten Absatz wurden ergänzt.
|
||||
@@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Git
|
||||
updated: 2019-02-25 08:06:58Z
|
||||
created: 2019-02-25 08:06:47Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Git
|
||||
---
|
||||
|
||||
https://www.kennwilson.com/notes/2013/08/self-hosted-remote-git-repositories/
|
||||
https://www.perforce.com/blog/git-beyond-basics-using-shallow-clones
|
||||
https://daringfireball.net/projects/markdown/syntax#p
|
||||
https://stackoverflow.com/questions/1474115/find-tag-information-for-a-given-commit
|
||||
https://git-scm.com/docs/git-clone#git-clone---reference-if-ableltrepositorygt
|
||||
https://github.com/progit/progit2/blob/master/Rakefile
|
||||
@@ -0,0 +1,10 @@
|
||||
---
|
||||
tags:
|
||||
- IT
|
||||
- IT/Tools/Gitlab
|
||||
---
|
||||
|
||||
- [`.gitlab-ci.yml` keyword reference | GitLab](https://docs.gitlab.com/ee/ci/yaml/)
|
||||
- [Releases | GitLab](https://docs.gitlab.com/ee/user/project/releases/index.html)
|
||||
- [Unit test report examples | GitLab](https://docs.gitlab.com/ee/ci/testing/unit\_test\_report_examples.html)
|
||||
- [Guided Explorations / DevOps Patterns / Utterly Automated Software and Artifact Versioning with GitVersion · GitLab](https://gitlab.com/guided-explorations/devops-patterns/utterly-automated-versioning)
|
||||
@@ -0,0 +1,28 @@
|
||||
---
|
||||
title: Gitlab get repo urls
|
||||
updated: 2021-05-20 12:31:48Z
|
||||
created: 2021-05-07 21:05:39Z
|
||||
tags:
|
||||
- IT/Tools/Gitlab
|
||||
- Development/REST
|
||||
- Development/Shell
|
||||
---
|
||||
|
||||
```bash
|
||||
curl --header "Private-Token: bFcsw1ebNhoFgKysksU1" https://gitlab.thpeetz.de/api/v4/projects/ | jq '.[] | { id: .id, url: .http_url_to_repo }'
|
||||
curl --header "Private-Token: aJVkcL2a6dDSVhJYzqEn" https://gitlab.thpeetz.de/api/v4/projects\?per_page=100 | jq '.[] | .http_url_to_repo'
|
||||
|
||||
for projectid in $(curl --header "Private-Token: aJVkcL2a6dDSVhJYzqEn" https://gitlab.thpeetz.de/api/v4/projects\?per_page\=100 | jq '.[] | .id')
|
||||
do curl --header "Private-Token: aJVkcL2a6dDSVhJYzqEn" https://gitlab.thpeetz.de/api/v4/projects/$projectid/hooks | jq
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
## Links
|
||||
|
||||
- https://docs.gitlab.com/ee/api/index.html
|
||||
- https://docs.gitlab.com/ee/api/projects.html
|
||||
- https://docs.gitlab.com/ee/user/project/settings/project\_access\_tokens.html
|
||||
- https://docs.gitlab.com/ee/api/remote_mirrors.html
|
||||
|
||||
|
||||
@@ -0,0 +1,50 @@
|
||||
---
|
||||
title: 'Gradle Goodness: Set Project Version In Version Catalog'
|
||||
updated: 2022-12-22 12:26:50Z
|
||||
created: 2022-12-22 12:26:50Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Gradle
|
||||
source: https://blog.mrhaki.com/2022/12/gradle-goodness-set-project-version-in.html
|
||||
---
|
||||
|
||||
### [Gradle Goodness: Set Project Version In Version Catalog](https://blog.mrhaki.com/2022/12/gradle-goodness-set-project-version-in.html)
|
||||
|
||||
The version catalog in Gradle is very useful to have one place in our project to define our project and plugin dependencies with their versions. But we can also use it to define our project version and then refer to that version from the version catalog in our build script file. That way the version catalog is our one place to look for everything related to a version. In the version catalog we have a `versions` section and there we can define a key with a version value. The name of the key could be our project or application name for example. We can use type safe accessors generated by Gradle in our build script to refer to that version.
|
||||
|
||||
In the following example build script written with Kotlin we see how we can refer to the version from the version catalog:
|
||||
|
||||
```kotlin
|
||||
description = "Sample project for Gradle version catalog"
|
||||
version = libs.versions.app.version.get()
|
||||
tasks {
|
||||
register("projectVersion") {
|
||||
doLast {
|
||||
println("Project version: " + version)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
And the version catalog is defined in the following file:
|
||||
|
||||
```properties
|
||||
[versions]
|
||||
app-version = "2.0.1"
|
||||
```
|
||||
|
||||
When we run the task `projectVersion` we see our project version in the output:
|
||||
|
||||
```shell
|
||||
$ gradle projectVersion
|
||||
Task :projectVersion
|
||||
|
||||
Project version: 2.0.1
|
||||
|
||||
BUILD SUCCESSFUL in 831ms
|
||||
|
||||
1 actionable task: 1 executed
|
||||
$
|
||||
```
|
||||
|
||||
Written with Gradle 7.6.
|
||||
+49
@@ -0,0 +1,49 @@
|
||||
---
|
||||
title: 'Gradle Goodness: Setting Plugin Version From Property In Plugins Section'
|
||||
updated: 2023-04-04 08:10:41Z
|
||||
created: 2023-04-04 08:10:41Z
|
||||
tags:
|
||||
- IT
|
||||
- Gradle
|
||||
- Plugin
|
||||
source: >-
|
||||
https://blog.jdriven.com/2021/02/gradle-goodness-setting-plugin-version-from-property-in-plugins-section/
|
||||
---
|
||||
|
||||
The `plugins` section in our Gradle build files can be used to define Gradle plugins we want to use. Gradle can optimize the build process if we use `plugins {…}` in our build scripts, so it is a good idea to use it. But there is a restriction if we want to define a version for a plugin inside the `plugins` section: the version is a fixed string value. We cannot use a property to set the version inside the `plugins` section. We can overcome this by using a `pluginsManagement` section in a settings file in the root of our project. Inside the `pluginsManagement` section we can use properties to set the version of a plugin we want to use. Once it is defined inside `pluginsManagement` we can use it in our project build script without having the specify the version. This allows us to have one place where all plugin versions are defined. We can even use a `gradle.properties` file in our project with all plugin versions and use that in `pluginsManagement`.
|
||||
|
||||
In the following settings file we use `pluginsManagement` to use a project property `springBootPluginVersion` to set the version to use for the Spring Boot Gradle plugin.
|
||||
|
||||
```kotlin
|
||||
// File: settings.gradle.kts
|
||||
pluginManagement {
|
||||
val springBootPluginVersion: String by settings // use project property with version
|
||||
plugins {
|
||||
id("org.springframework.boot") version "${springBootPluginVersion}"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Next in our project build file we can simply reference the id of the Spring Boot Gradle plugin without the version. The version is already resolved in our settings file:
|
||||
|
||||
```kotlin
|
||||
// File: build.gradle.kts
|
||||
plugins {
|
||||
java
|
||||
application
|
||||
id("org.springframework.boot") // no version here: it is set in settings.gradle.kts
|
||||
}
|
||||
|
||||
application {
|
||||
mainClass.set("com.mrhaki.sample.App")
|
||||
}
|
||||
```
|
||||
|
||||
Finally we can add a `gradle.properties` file with the project property (or specify it on the command line or environment variable):
|
||||
|
||||
```properties
|
||||
# File: gradle.properties
|
||||
springBootPluginVersion=2.4.2
|
||||
```
|
||||
|
||||
Written with Gradle 6.8.2.
|
||||
@@ -0,0 +1,92 @@
|
||||
---
|
||||
title: 'Gradle Goodness: Shared Configuration With Conventions Plugin'
|
||||
updated: 2023-04-04 08:09:40Z
|
||||
created: 2023-04-04 08:09:40Z
|
||||
tags:
|
||||
- IT
|
||||
- Gradle
|
||||
- Plugin
|
||||
source: >-
|
||||
https://blog.jdriven.com/2021/02/gradle-goodness-shared-configuration-with-conventions-plugin/
|
||||
---
|
||||
|
||||
When we have a multi-module project in Gradle we sometimes want to have dependencies, task configuration and other settings shared between the multiple modules. We can use the `subprojects` or `allprojects` blocks, but the downside is that it is not clear from the build script of the subproject where the configuration comes from. We must remember it is set from another build script, but there is no reference in the subproject to that connection. It is better to use a plugin with shared configuration and use that plugin in the subprojects. We call this a conventions plugin. This way it is explicitly visible in a subproject that the shared settings come from a plugin. Also it allows Gradle to optimize the build configuration.
|
||||
|
||||
The easiest way to implement the shared configuration in a plugin is using a so-called precompiled script plugin. This type of plugin can be written as a build script using the Groovy or Kotlin DSL with a filename ending with `.gradle` or `.gradle.kts`. The name of the plugin is the first part of the filename before `.gradle` or `.gradle.kts`. In our subproject we can add the plugin to our build script to apply the shared configuration. For a multi-module project we can create such a plugin in the `buildSrc` directory. For a Groovy plugin we place the file in `src/main/groovy`, for a Kotlin plugin we place it in `src/main/kotlin`.
|
||||
|
||||
In the following example we write a script plugin using the Kotlin DSL to apply the `java-library` plugin to a project, set some common dependencies used by all projects, configure the `Test` tasks and set the Java toolchain. First we create a `build.gradle.kts` file in the `buildSrc` directory in the root of our multi-module project and apply the `kotlin-dsl` plugin:
|
||||
|
||||
```kotlin
|
||||
// File: buildSrc/build.gradle.kts
|
||||
plugins {
|
||||
`kotlin-dsl`
|
||||
}
|
||||
|
||||
repositories.mavenCentral()
|
||||
```
|
||||
|
||||
Next we create the conventions plugin with our shared configuration:
|
||||
|
||||
```kotlin
|
||||
// File: buildSrc/src/main/kotlin/java-project-conventions.gradle.kts
|
||||
plugins {
|
||||
`java-library`
|
||||
}
|
||||
|
||||
group = "mrhaki.sample"
|
||||
version = "1.0"
|
||||
|
||||
repositories {
|
||||
mavenCentral()
|
||||
}
|
||||
|
||||
dependencies {
|
||||
val log4jVersion: String by extra("2.14.0")
|
||||
val junitVersion: String by extra("5.3.1")
|
||||
val assertjVersion: String by extra("3.19.0")
|
||||
|
||||
// Logging
|
||||
implementation("org.apache.logging.log4j:log4j-api:${log4jVersion}")
|
||||
implementation("org.apache.logging.log4j:log4j-core:${log4jVersion}")
|
||||
|
||||
// Testing
|
||||
testImplementation("org.junit.jupiter:junit-jupiter-api:${junitVersion}")
|
||||
testRuntimeOnly("org.junit.jupiter:junit-jupiter-engine:${junitVersion}")
|
||||
testImplementation("org.assertj:assertj-core:${assertjVersion}")
|
||||
}
|
||||
|
||||
java {
|
||||
toolchain {
|
||||
languageVersion.set(JavaLanguageVersion.of(15))
|
||||
}
|
||||
}
|
||||
|
||||
tasks.withType<Test> {
|
||||
useJUnitPlatform()
|
||||
}
|
||||
```
|
||||
|
||||
The id of our new plugin is `java-project-conventions` and we can use it in our build script for a subproject as:
|
||||
|
||||
```kotlin
|
||||
// File: rest-api/build.gradle.kts
|
||||
plugins {
|
||||
id("java-project-conventions") // apply shared config
|
||||
application // apply the Gradle application plugin
|
||||
}
|
||||
|
||||
dependencies {
|
||||
val vertxVersion: String by extra("4.0.2")
|
||||
|
||||
implementation(project(":domain")) // project dependency
|
||||
implementation("io.vertx:vertx-core:${vertxVersion}")
|
||||
}
|
||||
|
||||
application {
|
||||
mainClass.set("com.mrhaki.web.Api")
|
||||
}
|
||||
```
|
||||
|
||||
The `rest-api` project will have all the configuration and tasks from `java-library` plugin as configured in the `java-project-conventions` plugin, so we can build it as a Java project.
|
||||
|
||||
Written with Gradle 6.8.2.
|
||||
@@ -0,0 +1,55 @@
|
||||
---
|
||||
tags:
|
||||
- Development/Gradle
|
||||
- Development/Kotlin
|
||||
- IT
|
||||
---
|
||||
|
||||
# Artikel überarbeiten
|
||||
- [ ] Gradle Links aus anderen Notizen sammeln [priority:: medium] [repeat:: every week] [created:: 2023-05-10] [start:: 2023-04-26] [scheduled:: 2023-04-26]
|
||||
- [x] Gradle Links aus anderen Notizen sammeln [priority:: medium] [repeat:: every week] [start:: 2023-04-19] [scheduled:: 2023-04-19] [completion:: 2023-05-10]
|
||||
|
||||
## Offizielle Gradle Dokumentation
|
||||
- [Upgrading your build from Gradle 8.x to the latest](https://docs.gradle.org/8.1/userguide/upgrading\_version\_8.html)
|
||||
- [Publishing Plugins to the Gradle Plugin Portal](https://docs.gradle.org/8.1/userguide/publishing\_gradle\_plugins.html)
|
||||
- [Gradle | What's new in Gradle 8.0](https://gradle.org/whats-new/gradle-8/)
|
||||
- [The Gradle Daemon](https://docs.gradle.org/current/userguide/gradle_daemon.html)
|
||||
- [The Gradle Wrapper](https://docs.gradle.org/8.1/userguide/gradle_wrapper.html)
|
||||
- [Organizing Gradle Projects](https://docs.gradle.org/current/userguide/organizing\_gradle\_projects.html)
|
||||
- [Using Gradle Plugins](https://docs.gradle.org/7.5/userguide/plugins.html)
|
||||
- [Implementing Gradle plugins](https://docs.gradle.org/current/userguide/implementing\_gradle\_plugins.html)
|
||||
- [Designing Gradle plugins](https://docs.gradle.org/current/userguide/designing_gradle_plugins.html)
|
||||
- https://docs.gradle.org/current/userguide/plugins.html
|
||||
- https://docs.gradle.org/current/samples/sample_convention_plugins.html
|
||||
- https://docs.gradle.org/current/userguide/plugins.html
|
||||
- https://docs.gradle.org/current/userguide/declaring_dependencies_between_subprojects.html
|
||||
|
||||
|
||||
## Gradle Userguide
|
||||
- [Gradle Kotlin DSL Primer](https://docs.gradle.org/8.1/userguide/kotlin_dsl.html)
|
||||
- [Introduction to writing Gradle plugins – Tom Gregory](https://tomgregory.com/introduction-to-gradle-plugins/)
|
||||
- [Running integration tests in Gradle – Tom Gregory](https://tomgregory.com/gradle-integration-tests/)
|
||||
- [Arbeiten mit der Gradle-Registrierung - GitHub Docs](https://docs.github.com/de/packages/working-with-a-github-packages-registry/working-with-the-gradle-registry)
|
||||
- [Executing Gradle builds on GitHub Actions](https://docs.gradle.org/current/userguide/github-actions.html)
|
||||
- [How to build Gradle projects with GitHub Actions](https://tomgregory.com/build-gradle-projects-with-github-actions/)
|
||||
- [Java bauen und testen mit Gradle - GitHub Docs](https://docs.github.com/de/actions/automating-builds-and-tests/building-and-testing-java-with-gradle)
|
||||
- [GitHub - qualersoft/robotframework-gradle-plugin: Gradle plugin for using the robot framework with java keyword libraries](https://github.com/qualersoft/robotframework-gradle-plugin)
|
||||
|
||||
## Gradle Plugins
|
||||
- [Maven Plugin Development Gradle Plugin](https://www.benediktritter.de/maven-plugin-development/)
|
||||
- [Maven Plugin Development Gradle Plugin](https://www.benediktritter.de/maven-plugin-development/)
|
||||
|
||||
## Videos
|
||||
- [10 Best Gradle Plugins You Can't Live Without - YouTube](https://www.youtube.com/watch?v=5UJ0igllPuU)
|
||||
- [Gradle project properties best practices (don't be that guy) - YouTube](https://www.youtube.com/watch?v=BvXjlxJg2II)
|
||||
- [Encapsulate task declarations in a plugin (Gradle best practice tip #15)](https://www.youtube.com/watch?v=1hjle_eqEsw)
|
||||
- [How To Run Integration Tests In Gradle](https://www.youtube.com/watch?v=_q5Rxgtn1vg)
|
||||
- [Introduction to writing Gradle plugins](https://www.youtube.com/watch?v=F3DF6bQo6jk)
|
||||
- [How to use Gradle api vs. implementation dependencies (with the Java Library plugin)](https://www.youtube.com/watch?v=K96rDeiKT-g)
|
||||
|
||||
## pygradle
|
||||
- https://www.diycode.cc/projects/linkedin/pygradle
|
||||
- https://github.com/linkedin/pygradle/blob/master/docs/plugins/python.md
|
||||
- https://github.com/linkedin/pygradle/blob/master/docs/getting-started.md
|
||||
- https://github.com/linkedin/pygradle/tree/master/examples/example-project
|
||||
- https://github.com/linkedin/pygradle/blob/master/README.md
|
||||
@@ -0,0 +1,146 @@
|
||||
---
|
||||
title: Groovy - ConfigSlurper
|
||||
updated: 2019-02-26 14:01:45Z
|
||||
created: 2019-02-26 13:57:08Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Groovy
|
||||
---
|
||||
|
||||
# ConfigSlurper
|
||||
|
||||
ConfigSlurper is a utility class within Groovy for writing properties file like scripts for performing configuration. Unlike regular Java properties files ConfigSlurper scripts support native Java types and are structured like a tree.
|
||||
|
||||
Below is an example of how you could configure Log4j with a ConfigSlurper script:
|
||||
|
||||
```groovy
|
||||
log4j.appender.stdout = "org.apache.log4j.ConsoleAppender"
|
||||
log4j.appender."stdout.layout"="org.apache.log4j.PatternLayout"
|
||||
log4j.rootLogger="error,stdout"
|
||||
log4j.logger.org.springframework="info,stdout"
|
||||
log4j.additivity.org.springframework=false
|
||||
```
|
||||
|
||||
To load this into a readable config you can do:
|
||||
|
||||
```groovy
|
||||
def config = new ConfigSlurper().parse(new File('myconfig.groovy').toURL())
|
||||
|
||||
assert "info,stdout" == config.log4j.logger.org.springframework
|
||||
assert false == config.log4j.additivity.org.springframework
|
||||
```
|
||||
|
||||
As you can see from the example above you can navigate the config using dot notation and the return values are Java types like strings and booleans.
|
||||
|
||||
You can also use scoping in config scripts to avoid repeating yourself. So the above config could also be written as:
|
||||
|
||||
```groovy
|
||||
log4j {
|
||||
appender.stdout = "org.apache.log4j.ConsoleAppender"
|
||||
appender."stdout.layout"="org.apache.log4j.PatternLayout"
|
||||
rootLogger="error,stdout"
|
||||
logger {
|
||||
org.springframework="info,stdout"
|
||||
}
|
||||
additivity {
|
||||
org.springframework=false
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Converting to and from Java properties files
|
||||
|
||||
You can convert ConfigSlurper configs to and from Java properties files. For example:
|
||||
|
||||
```groovy
|
||||
java.util.Properties props = // load from somewhere
|
||||
|
||||
def config = new ConfigSlurper().parse(props)
|
||||
|
||||
props = config.toProperties()
|
||||
```
|
||||
|
||||
## Merging configurations
|
||||
|
||||
You can merge config objects so if you have multiple config files and want to create one central config object you can do:
|
||||
|
||||
```groovy
|
||||
def config1 = new ConfigSlurper().parse(..)
|
||||
def config2 = new ConfigSlurper().parse(..)
|
||||
|
||||
config1 = config1.merge(config2)
|
||||
```
|
||||
|
||||
## Serializing a configuration to disk
|
||||
|
||||
You can serialize a config object to disk. Each config object implements the groovy.lang.Writable interface that allows you to write out the config to any java.io.Writer:
|
||||
|
||||
```groovy
|
||||
def config = new ConfigSlurper().parse(..)
|
||||
|
||||
new File("..").withWriter { writer ->
|
||||
config.writeTo(writer)
|
||||
}
|
||||
```
|
||||
|
||||
## Special "environments" Configuration
|
||||
|
||||
The ConfigSlurper class has a special constructor other than the default constructor that takes an "environment" parameter. This special constructor works in concert with a property setting called environments. This allows a default setting to exist in the property file that can be superceded by a setting in the appropriate environments closure. This allows multiple related configurations to be stored in the same file.
|
||||
|
||||
Given this groovy property file:
|
||||
**Sample.groovy**
|
||||
|
||||
```groovy
|
||||
sample {
|
||||
foo = "default_foo"
|
||||
bar = "default_bar"
|
||||
}
|
||||
|
||||
environments {
|
||||
development {
|
||||
sample {
|
||||
foo = "dev_foo"
|
||||
}
|
||||
}
|
||||
test {
|
||||
sample {
|
||||
bar = "test_bar"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Here is the demo code that exercises this configuration:
|
||||
|
||||
```groovy
|
||||
def config = new ConfigSlurper("development").parse(new File('Sample.groovy').toURL())
|
||||
|
||||
assert config.sample.foo == "dev_foo"
|
||||
assert config.sample.bar == "default_bar"
|
||||
|
||||
config = new ConfigSlurper("test").parse(new File('Sample.groovy').toURL())
|
||||
|
||||
assert config.sample.foo == "default_foo"
|
||||
assert config.sample.bar == "test_bar"
|
||||
```
|
||||
|
||||
Note: the environments closure is not directly parsable. Without using the special environment constructor the closure is ignored.
|
||||
|
||||
The value of the environment constructor is also available in the configuration file, allowing you to build the configuration like this:
|
||||
|
||||
```groovy
|
||||
switch (environment) {
|
||||
case 'development':
|
||||
baseUrl = "devServer/"
|
||||
break
|
||||
case 'test':
|
||||
baseUrl = "testServer/"
|
||||
break
|
||||
default:
|
||||
baseUrl = "localhost/"
|
||||
}
|
||||
```
|
||||
|
||||
# Further information
|
||||
|
||||
[Using Groovy ConfigSlurper to Configure Spring Beans](http://jroller.com/page/0xcafebabe?entry=using_groovy_configslurper_to_configure)
|
||||
@@ -0,0 +1,121 @@
|
||||
---
|
||||
title: Groovy - Reading XML using Groovy's XmlSlurper
|
||||
updated: 2019-02-26 11:58:40Z
|
||||
created: 2019-02-26 11:55:12Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Groovy
|
||||
---
|
||||
|
||||
This example assumes the following class is already on your CLASSPATH:
|
||||
|
||||
XmlExamples.groovy
|
||||
```groovy
|
||||
class XmlExamples {
|
||||
static def CAR_RECORDS = '''
|
||||
<records>
|
||||
<car name='HSV Maloo' make='Holden' year='2006'>
|
||||
<country>Australia</country>
|
||||
<record type='speed'>Production Pickup Truck with speed of 271kph</record>
|
||||
</car>
|
||||
<car name='P50' make='Peel' year='1962'>
|
||||
<country>Isle of Man</country>
|
||||
<record type='size'>Smallest Street-Legal Car at 99cm wide and 59 kg in weight</record>
|
||||
</car>
|
||||
<car name='Royale' make='Bugatti' year='1931'>
|
||||
<country>France</country>
|
||||
<record type='price'>Most Valuable Car at $15 million</record>
|
||||
</car>
|
||||
</records>
|
||||
'''
|
||||
}
|
||||
```
|
||||
Here is an example of using XmlSlurper:
|
||||
```groovy
|
||||
def records = new XmlSlurper().parseText(XmlExamples.CAR_RECORDS)
|
||||
def allRecords = records.car
|
||||
assert 3 == allRecords.size()
|
||||
def allNodes = records.depthFirst().collect{ it }
|
||||
assert 10 == allNodes.size()
|
||||
def firstRecord = records.car[0]
|
||||
assert 'car' == firstRecord.name()
|
||||
assert 'Holden' == firstRecord.@make.text()
|
||||
assert 'Australia' == firstRecord.country.text()
|
||||
def carsWith_e_InMake = records.car.findAll{ it.@make.text().contains('e') }
|
||||
assert carsWith_e_InMake.size() == 2// alternative way to find cars with 'e' in makeassert 2 == records.car.findAll{ it.@make =~ '.*e.*' }.size()
|
||||
// makes of cars that have an 's' followed by an 'a' in the countryassert ['Holden', 'Peel'] == records.car.findAll{ it.country =~ '.*s.*a.*' }.@make.collect{ it.text() }
|
||||
def expectedRecordTypes = ['speed', 'size', 'price']
|
||||
assert expectedRecordTypes == records.depthFirst().grep{ it.@type != '' }.'@type'*.text()
|
||||
assert expectedRecordTypes == records.'**'.grep{ it.@type != '' }.'@type'*.text()
|
||||
def countryOne = records.car[1].country
|
||||
assert 'Peel' == countryOne.parent().@make.text()
|
||||
assert 'Peel' == countryOne.'..'.@make.text()
|
||||
// names of cars with records sorted by yeardef sortedNames = records.car.list().sort{ it.@year.toInteger() }.'@name'*.text()
|
||||
assert ['Royale', 'P50', 'HSV Maloo'] == sortedNames
|
||||
assert ['Australia', 'Isle of Man'] == records.'**'.grep{ it.@type =~ 's.*' }*.parent().country*.text()
|
||||
assert 'co-re-co-re-co-re' == records.car.children().collect{ it.name()[0..1] }.join('-')
|
||||
assert 'co-re-co-re-co-re' == records.car.'*'.collect{ it.name()[0..1] }.join('-')
|
||||
```
|
||||
Notes:
|
||||
|
||||
- If your elements contain characters such as dashes, you can enclose the element name in double quotes. Meaning for:
|
||||
|
||||
```xml
|
||||
<foo>
|
||||
<foo-bar>test</foo-bar>
|
||||
</foo>
|
||||
```
|
||||
|
||||
You do the following:
|
||||
|
||||
```groovy
|
||||
def foo = new XmlSlurper().parseText(FOO_XML)
|
||||
assert "test" == foo."foo-bar".text()
|
||||
```
|
||||
|
||||
You can also parse XML documents using namespaces:
|
||||
|
||||
```groovy
|
||||
def wsdl = '''
|
||||
<definitions name="AgencyManagementService"
|
||||
xmlns:ns1="http://www.example.org/NS1"
|
||||
xmlns:ns2="http://www.example.org/NS2">
|
||||
<ns1:message name="SomeRequest">
|
||||
<ns1:part name="parameters" element="SomeReq" />
|
||||
</ns1:message>
|
||||
<ns2:message name="SomeRequest">
|
||||
<ns2:part name="parameters" element="SomeReq" />
|
||||
</ns2:message>
|
||||
</definitions>
|
||||
'''
|
||||
|
||||
def xml = new XmlSlurper().parseText(wsdl).declareNamespace(ns1: 'http://www.example.org/NS1', ns2: 'http://www.example.org/NS2')
|
||||
println xml.'ns1:message'.'ns1:part'.size()
|
||||
println xml.'ns2:message'.'ns2:part'.size()
|
||||
```
|
||||
|
||||
XmlSlurper has a declareNamespace method which takes a Map of prefix to URI mappings. You declare the namespaces and just use the prefixes in the GPath expression.
|
||||
|
||||
```groovy
|
||||
new XmlSlurper().parseText(blog).declareNamespace(dc: "http://purl.org/dc/elements/1.1/").channel.item.findAll { item ->
|
||||
d.any{entry -> item."dc:date".text() =~ entry.key} && a.any{entry -> item.tags.text() =~ entry
|
||||
}
|
||||
```
|
||||
|
||||
Some remarks:
|
||||
|
||||
- name or "*:name" matches an element named "name" irrespective of the namespace it's in (i.e. this is the default mode of operation)
|
||||
- ":name" matches an element named "name" only id the element is not in a namespace
|
||||
- "prefix:name" matches an element names "name" only if it is in the namespace identified by the prefix "prefix" (and the prefix to namespace mapping was defined by a previous call to declareNamespace)
|
||||
|
||||
You can generate namespaced elements in StreamingMarkupBuilder very easily:
|
||||
|
||||
```groovy
|
||||
System.out << new StreamingMarkupBuilder().bind {
|
||||
mkp.declareNamespace(dc: "http://purl.org/dc/elements/1.1/")
|
||||
|
||||
root {
|
||||
dc.date()
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,99 @@
|
||||
---
|
||||
title: Groovy - Updating XML with XmlSlurper
|
||||
updated: 2019-02-26 14:08:18Z
|
||||
created: 2019-02-26 14:03:46Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Groovy
|
||||
---
|
||||
|
||||
# Updating XML with XmlSlurper
|
||||
|
||||
Here is an example of updating XML using XmlSlurper:
|
||||
|
||||
```groovy
|
||||
// require(groupId:'xmlunit', artifactId:'xmlunit', version:'1.1')import org.custommonkey.xmlunit.Diff
|
||||
import org.custommonkey.xmlunit.XMLUnit
|
||||
import groovy.xml.StreamingMarkupBuilder
|
||||
|
||||
def input = '''
|
||||
<shopping>
|
||||
<category type="groceries">
|
||||
<item>Chocolate</item>
|
||||
<item>Coffee</item>
|
||||
</category>
|
||||
<category type="supplies">
|
||||
<item>Paper</item>
|
||||
<item quantity="4">Pens</item>
|
||||
</category>
|
||||
<category type="present">
|
||||
<item when="Aug 10">Kathryn's Birthday</item>
|
||||
</category>
|
||||
</shopping>
|
||||
'''
|
||||
|
||||
def expectedResult = '''
|
||||
<shopping>
|
||||
<category type="groceries">
|
||||
</category>
|
||||
<category type="supplies">
|
||||
<item>Iced Tea</item>
|
||||
<item quantity="6" when="Urgent">Pens</item>
|
||||
</category>
|
||||
<category type="present">
|
||||
<item>Mum's Birthday</item>
|
||||
<item when="Oct 15">Monica's Birthday</item>
|
||||
</category>
|
||||
<category>
|
||||
<item>Wine</item>
|
||||
</category>
|
||||
</shopping>
|
||||
'''
|
||||
|
||||
def root = new XmlSlurper().parseText(input)
|
||||
|
||||
// modify groceries: quality items pleasedef groceries = root.category.find{ it.@type == 'groceries' }
|
||||
(0..<groceries.item.size()).each {
|
||||
groceries.item[it] = 'Luxury ' + groceries.item[it]
|
||||
}
|
||||
|
||||
// modify supplies: we need extra pensdef pens = root.category.find{ it.@type == 'supplies' }.item.findAll{ it.text() == 'Pens' }
|
||||
pens.each { p ->
|
||||
p.@quantity = (p.@quantity.toInteger() + 2).toString()
|
||||
p.@when = 'Urgent'
|
||||
}
|
||||
|
||||
// modify presents: August has come and gonedef presents = root.category.find{ it.@type == 'present' }
|
||||
presents.replaceNode{ node ->
|
||||
category(type:'present'){
|
||||
item("Mum's Birthday")
|
||||
item("Monica's Birthday", when:'Oct 15')
|
||||
}
|
||||
}
|
||||
|
||||
// append child at the end of shopping
|
||||
root.appendNode {
|
||||
category {
|
||||
item("Wine")
|
||||
}
|
||||
}
|
||||
|
||||
// delete all occurrences of a specific element inside a specific parent
|
||||
root.category[0].item.replaceNode {}
|
||||
|
||||
// update the text of a specific element
|
||||
root.category[1].item[0] = "Iced Tea"
|
||||
|
||||
// check the whole document using XmlUnitdef outputBuilder = new StreamingMarkupBuilder()
|
||||
String result = outputBuilder.bind{ mkp.yield root }
|
||||
|
||||
XMLUnit.setIgnoreWhitespace(true)
|
||||
def xmlDiff = new Diff(result, expectedResult)
|
||||
assert xmlDiff.similar()
|
||||
|
||||
// check the when attributes (can't do before now due to delayed setting)def resultRoot = new XmlSlurper().parseText(result)
|
||||
def removeNulls(list) { list.grep{it} }
|
||||
assert removeNulls(resultRoot.'*'.item.@when) == [ "Urgent", "Oct 15" ]
|
||||
```
|
||||
|
||||
|
||||
@@ -0,0 +1,121 @@
|
||||
---
|
||||
title: Groovy - Using Enums
|
||||
updated: 2019-02-25 15:14:55Z
|
||||
created: 2019-02-25 15:14:44Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Groovy
|
||||
---
|
||||
|
||||
|
||||
|
||||
Some examples (inspired by the Java Enum Tutorial):
|
||||
|
||||
```groovy
|
||||
enum Day {
|
||||
SUNDAY, MONDAY, TUESDAY, WEDNESDAY,
|
||||
THURSDAY, FRIDAY, SATURDAY
|
||||
}
|
||||
|
||||
def tellItLikeItIs(Day day) {
|
||||
switch (day) {
|
||||
case Day.MONDAY:
|
||||
println "Mondays are bad."
|
||||
break
|
||||
case Day.FRIDAY:
|
||||
println "Fridays are better."
|
||||
break
|
||||
case Day.SATURDAY:
|
||||
case Day.SUNDAY:
|
||||
println "Weekends are best."
|
||||
break
|
||||
default:
|
||||
println "Midweek days are so-so."
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
tellItLikeItIs(Day.MONDAY) // => Mondays are bad.
|
||||
tellItLikeItIs(Day.WEDNESDAY) // => Midweek days are so-so.
|
||||
tellItLikeItIs(Day.FRIDAY) // => Fridays are better.
|
||||
tellItLikeItIs(Day.SATURDAY) // => Weekends are best.
|
||||
```
|
||||
|
||||
Or with a bit of refactoring, you could write the switch like this:
|
||||
|
||||
```groovy
|
||||
def today = Day.SATURDAY
|
||||
switch (today) {
|
||||
// Saturday or Sunday
|
||||
case [ Day.SATURDAY, Day.SUNDAY ]:
|
||||
println "Weekends are cool"
|
||||
break
|
||||
// a day between Monday and Friday
|
||||
case Day.MONDAY..Day.FRIDAY:
|
||||
println "Boring work day"
|
||||
break
|
||||
default:
|
||||
println "Are you sure this is a valid day?"
|
||||
}
|
||||
```
|
||||
|
||||
Here is a coin example:
|
||||
|
||||
```groovy
|
||||
enum Coin {
|
||||
penny(1), nickel(5), dime(10), quarter(25)
|
||||
Coin(int value) { this.value = value }
|
||||
private final int value
|
||||
public int value() { return value }
|
||||
}
|
||||
|
||||
assert Coin.values().size() == 4
|
||||
|
||||
def pocketMoney = 2 * Coin.quarter.value() + 5 * Coin.dime.value()
|
||||
assert pocketMoney == 100
|
||||
|
||||
// another way to do abovedef coins = [ Coin.quarter ] * 2 + [ Coin.dime ] * 5
|
||||
println coins // => [ quarter, quarter, dime, dime, dime, dime, dime ]
|
||||
println coins.sum{ it.value() } // => 100
|
||||
```
|
||||
|
||||
Here is a planet example:
|
||||
|
||||
```groovy
|
||||
enum Planet {
|
||||
MERCURY(3.303e+23, 2.4397e6),
|
||||
VENUS(4.869e+24, 6.0518e6),
|
||||
EARTH(5.976e+24, 6.37814e6),
|
||||
MARS(6.421e+23, 3.3972e6),
|
||||
JUPITER(1.9e+27, 7.1492e7),
|
||||
SATURN(5.688e+26, 6.0268e7),
|
||||
URANUS(8.686e+25, 2.5559e7),
|
||||
NEPTUNE(1.024e+26, 2.4746e7)
|
||||
private final double mass // in kilograms
|
||||
private final double radius // in metres
|
||||
Planet(double mass, double radius) {
|
||||
this.mass = mass
|
||||
this.radius = radius
|
||||
}
|
||||
private double mass() { return mass }
|
||||
private double radius() { return radius }
|
||||
// universal gravitational constant (m3 kg-1 s-2)
|
||||
public static final double G = 6.67300E-11
|
||||
double surfaceGravity() { return G * mass / (radius * radius) }
|
||||
double surfaceWeight(double otherMass) { return otherMass * surfaceGravity() }
|
||||
}
|
||||
|
||||
double earthWeight = 75.0 // kgdouble mass = earthWeight/Planet.EARTH.surfaceGravity()
|
||||
for (p in Planet.values()) {
|
||||
printf("Your weight on %s is %f%n", p, p.surfaceWeight(mass))
|
||||
}
|
||||
|
||||
// =>// Your weight on MERCURY is 28.331821// Your weight on VENUS is 67.874932// Your weight on EARTH is 75.000000// Your weight on MARS is 28.405289// Your weight on JUPITER is 189.791814// Your weight on SATURN is 79.951165// Your weight on URANUS is 67.884540// Your weight on NEPTUNE is 85.374605
|
||||
```
|
||||
|
||||
Note: there are currently issues with using Groovy enums in conjunction with GroovyShell. Best bet would be to check Jira if you are having problems, e.g. http://jira.codehaus.org/browse/GROOVY-2135
|
||||
|
||||
|
||||
Evernote hilft dir, nichts zu vergessen und alles mühelos zu ordnen und zu organisieren. Evernote herunterladen.
|
||||
|
||||
|
||||
@@ -0,0 +1,458 @@
|
||||
---
|
||||
title: Groovy - Using MarkupBuilder for Agile XML creation
|
||||
updated: 2019-02-26 13:51:30Z
|
||||
created: 2019-02-26 13:44:24Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Groovy
|
||||
---
|
||||
|
||||
Two principles of Agile development are DRY (don't repeat yourself) and merciless refactoring. Thanks to excellent IDE support it isn't too hard to apply these principles to coding Java and Groovy but it's a bit harder with XML.
|
||||
|
||||
The good news is that Groovy's Builder notation can help. Whether you are trying to refactor your Ant build file(s) or manage a family of related XML files (e.g. XML request and response files for testing Web Services) you will find that you can make great advances in managing your XML files using builder patterns.
|
||||
|
||||
|
||||
Scenario: Consider we have a program to track the sales of copies of [GINA](http://groovy.canoo.com/gina) (smile) . Books leave a warehouse in trucks. Trucks contain big boxes which are sent off to various countries. The big boxes contain smaller boxes which travel to different states and cities around the world. These boxes may also contain smaller boxes as required. Eventually some of the boxes contain just books. Either GINA or some potential upcoming Groovy titles. Suppose the delivery system produces XML files containing the items in each truck. We are responsible for writing the system which does some fancy reporting.
|
||||
|
||||
|
||||
If we are a vigilant tester, we will have a family of test files which allow us to test the many possible kinds of XML files we need to deal with. Instead of having to manage a directory full of files which would be hard to maintain if the delivery system changed, we decide to use Groovy to generate the XML files we need. Here is our first attempt:
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
xml.truck(id:'ABC123') {
|
||||
box(country:'Australia') {
|
||||
box(country:'Australia', state:'QLD') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for VBA Macro writers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW') {
|
||||
box(country:'Australia', state:'NSW', city:'Sydney') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for COBOL Programmers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW', suburb:'Albury') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for Fortran Programmers')
|
||||
}
|
||||
}
|
||||
}
|
||||
box(country:'USA') {
|
||||
box(country:'USA', state:'CA') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for Ruby programmers')
|
||||
}
|
||||
}
|
||||
box(country:'Germany') {
|
||||
box(country:'Germany', city:'Berlin') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for PHP Programmers')
|
||||
}
|
||||
}
|
||||
box(country:'UK') {
|
||||
box(country:'UK', city:'London') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for Haskel Programmers')
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
There is quite a lot of replication in this file. Lets refactor out two helper methods standardBook1 and standardBook2 to remove some of the duplication. We now have something like this:
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
// standard bookdef standardBook1(builder) { builder.book(title:'Groovy in Action', author:'Dierk K??nig et al') }
|
||||
// other standard booksdef standardBook2(builder, audience) { builder.book(title:"Groovy for ${audience}") }
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
xml.truck(id:'ABC123') {
|
||||
box(country:'Australia') {
|
||||
box(country:'Australia', state:'QLD') {
|
||||
standardBook1(xml)
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'VBA Macro writers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW') {
|
||||
box(country:'Australia', state:'NSW', city:'Sydney') {
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'COBOL Programmers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW', suburb:'Albury') {
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'Fortran Programmers')
|
||||
}
|
||||
}
|
||||
}
|
||||
box(country:'USA') {
|
||||
box(country:'USA', state:'CA') {
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'Ruby Programmers')
|
||||
}
|
||||
}
|
||||
box(country:'Germany') {
|
||||
box(country:'Germany', city:'Berlin') {
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'PHP Programmers')
|
||||
}
|
||||
}
|
||||
box(country:'UK') {
|
||||
box(country:'UK', city:'London') {
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'Haskel Programmers')
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
Next, let's refactor out a few more methods to end up with the following:
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
// define standard book and version allowing multiple copiesdef standardBook1(builder) { builder.book(title:'Groovy in Action', author:'Dierk K??nig et al') }
|
||||
def standardBook1(builder, copies) { (0..<copies).each{ standardBook1(builder) } }
|
||||
// another standard bookdef standardBook2(builder, audience) { builder.book(title:"Groovy for ${audience}") }
|
||||
// define standard boxdef standardBox1(builder, args) {
|
||||
def other = args.findAll{it.key != 'audience'}
|
||||
builder.box(other) { standardBook1(builder); standardBook2(builder, args['audience']) }
|
||||
}
|
||||
// define standard country boxdef standardBox2(builder, args) {
|
||||
builder.box(country:args['country']) {
|
||||
if (args.containsKey('language')) {
|
||||
args.put('audience', args['language'] + ' programmers')
|
||||
args.remove('language')
|
||||
}
|
||||
standardBox1(builder, args)
|
||||
} }
|
||||
|
||||
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
xml.truck(id:'ABC123') {
|
||||
box(country:'Australia') {
|
||||
box(country:'Australia', state:'QLD') {
|
||||
standardBook1(xml, 2)
|
||||
standardBook2(xml, 'VBA Macro writers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW') {
|
||||
[Sydney:'COBOL', Albury:'Fortran'].each{ city, language ->
|
||||
standardBox1(xml, [country:'Australia', state:'NSW',
|
||||
city:"${city}", audience:"${language} Programmers"])
|
||||
} } }
|
||||
standardBox2(xml, [country:'USA', state:'CA', language:'Ruby'])
|
||||
standardBox2(xml, [country:'Germany', city:'Berlin', language:'PHP'])
|
||||
standardBox2(xml, [country:'UK', city:'London', language:'Haskel'])
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
This is better. If the format of our XML changes, we will minimise the changes required in our builder code. Similarly, if we need to produce multiple XML files, we can add some for loops, closures or if statements to generate all the files from one or a small number of source files.
|
||||
|
||||
We could extract out some of our code into a helper method and the code would become:
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
def standard = new StandardBookDefinitions(xml)
|
||||
xml.truck(id:'ABC123') {
|
||||
box(country:'Australia') {
|
||||
box(country:'Australia', state:'QLD') {
|
||||
standard.book1(2)
|
||||
standard.book2('VBA Macro writers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW') {
|
||||
[Sydney:'COBOL', Albury:'Fortran'].each{ city, language ->
|
||||
standard.box1(country:'Australia', state:'NSW',
|
||||
city:"${city}", audience:"${language} Programmers")
|
||||
} } }
|
||||
standard.box2(country:'USA', state:'CA', language:'Ruby')
|
||||
standard.box2(country:'Germany', city:'Berlin', language:'PHP')
|
||||
standard.box2(country:'UK', city:'London', language:'Haskel')
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
So far we have just produced the one XML file. It would make sense to use similar techniques to produce all the XML files we need. We can take this in several directions at this point including using GStrings, using database contents to help generate the content or making use of templates.
|
||||
|
||||
We won't look at any of these, instead we will just augment the previous example just a little more.
|
||||
|
||||
First we will slightly expand our helper class. Here is the result:
|
||||
StandardBookDefinitions.groovy
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
class StandardBookDefinitions {
|
||||
private def builder
|
||||
StandardBookDefinitions(builder) {
|
||||
this.builder = builder
|
||||
}
|
||||
def removeKey(args, key) { return args.findAll{it.key != key} }
|
||||
// define standard book and version allowing multiple copies
|
||||
def book1() { builder.book(title:'Groovy in Action', author:'Dierk K??nig et al') }
|
||||
def book1(copies) { (0..<copies).each{ book1() } }
|
||||
// another standard book
|
||||
def book2(audience) { builder.book(title:"Groovy for ${audience}") }
|
||||
// define standard box
|
||||
def box1(args) {
|
||||
def other = removeKey(args, 'audience')
|
||||
builder.box(other) { book1(); book2(args['audience']) }
|
||||
}
|
||||
// define standard country box
|
||||
def box2(args) {
|
||||
builder.box(country:args['country']) {
|
||||
if (args.containsKey('language')) {
|
||||
args.put('audience', args['language'] + ' programmers')
|
||||
args.remove('language')
|
||||
}
|
||||
box1(args)
|
||||
} }
|
||||
// define deep box
|
||||
def box3(args) {
|
||||
def depth = args['depth']
|
||||
def other = removeKey(args, 'depth')
|
||||
if (depth > 1) {
|
||||
builder.box(other) {
|
||||
other.put('depth', depth - 1)
|
||||
box3(other)
|
||||
}
|
||||
} else {
|
||||
box2(other)
|
||||
} }
|
||||
// define deep box
|
||||
def box4(args) {
|
||||
builder.box(country:'South Africa'){
|
||||
(0..<args['number']).each{ book1() }
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
And now we will use this helper class to generate a family of related XML files. For illustrative purposes, we will just print out the generated files rather than actually store the files.
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
def writer = new StringWriter()
|
||||
xml = new MarkupBuilder(writer)
|
||||
standard = new StandardBookDefinitions(xml)
|
||||
def shortCountry = 'UK'def longCountry = 'The United Kingdom of Great Britain and Northern Ireland'def shortState = 'CA'def longState = 'The State of Rhode Island and Providence Plantations'def countryForState = 'USA'
|
||||
|
||||
def generateWorldOrEuropeXml(world) {
|
||||
xml.truck(id:'ABC123') {
|
||||
if (world) {
|
||||
box(country:'Australia') {
|
||||
box(country:'Australia', state:'QLD') {
|
||||
standard.book1(2)
|
||||
standard.book2('VBA Macro writers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW') {
|
||||
[Sydney:'COBOL', Albury:'Fortran'].each{ city, language ->
|
||||
standard.box1(country:'Australia', state:'NSW',
|
||||
city:"${city}", audience:"${language} Programmers")
|
||||
} } }
|
||||
standard.box2(country:'USA', state:'CA', language:'Ruby')
|
||||
}
|
||||
standard.box2(country:'Germany', city:'Berlin', language:'PHP')
|
||||
standard.box2(country:'UK', city:'London', language:'Haskel')
|
||||
}
|
||||
}
|
||||
|
||||
def generateSpecialSizeXml(depth, number) {
|
||||
xml.truck(id:'DEF123') {
|
||||
standard.box3(country:'UK', city:'London', language:'Haskel', depth:depth)
|
||||
standard.box4(country:'UK', city:'London', language:'Haskel', number:number)
|
||||
box(country:'UK') {} // empty box
|
||||
}
|
||||
}
|
||||
|
||||
def generateSpecialNamesXml(country, state) {
|
||||
xml.truck(id:'GHI123') {
|
||||
if (state) {
|
||||
box(country:country, state:state){ standard.book1() }
|
||||
} else {
|
||||
box(country:country){ standard.book1() }
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
generateWorldOrEuropeXml(true)
|
||||
generateWorldOrEuropeXml(false)
|
||||
generateSpecialSizeXml(10, 10)
|
||||
generateSpecialNamesXml(shortCountry, '')
|
||||
generateSpecialNamesXml(longCountry, '')
|
||||
generateSpecialNamesXml(countryForState, shortState)
|
||||
generateSpecialNamesXml(countryForState, longState)
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
This will be much more maintainable over time than a directory full of hand-crafted XML files.
|
||||
|
||||
Here is what will be produced:
|
||||
|
||||
```xml
|
||||
<truck id='ABC123'>
|
||||
<box country='Australia'>
|
||||
<box state='QLD' country='Australia'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for VBA Macro writers' />
|
||||
</box>
|
||||
<box state='NSW' country='Australia'>
|
||||
<box city='Albury' state='NSW' country='Australia'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for Fortran Programmers' />
|
||||
</box>
|
||||
<box city='Sydney' state='NSW' country='Australia'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for COBOL Programmers' />
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
<box country='USA'>
|
||||
<box state='CA' country='USA'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for Ruby programmers' />
|
||||
</box>
|
||||
</box>
|
||||
<box country='Germany'>
|
||||
<box city='Berlin' country='Germany'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for PHP programmers' />
|
||||
</box>
|
||||
</box>
|
||||
<box country='UK'>
|
||||
<box city='London' country='UK'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for Haskel programmers' />
|
||||
</box>
|
||||
</box>
|
||||
</truck>
|
||||
<truck id='ABC123'>
|
||||
<box country='Germany'>
|
||||
<box city='Berlin' country='Germany'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for PHP programmers' />
|
||||
</box>
|
||||
</box>
|
||||
<box country='UK'>
|
||||
<box city='London' country='UK'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for Haskel programmers' />
|
||||
</box>
|
||||
</box>
|
||||
</truck>
|
||||
<truck id='DEF123'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box country='UK'>
|
||||
<box city='London' country='UK'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for Haskel programmers' />
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
<box country='South Africa'>
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
</box>
|
||||
<box country='UK' />
|
||||
</truck>
|
||||
<truck id='GHI123'>
|
||||
<box country='UK'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
</box>
|
||||
</truck>
|
||||
<truck id='GHI123'>
|
||||
<box country='The United Kingdom of Great Britain and Northern Ireland'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
</box>
|
||||
</truck>
|
||||
<truck id='GHI123'>
|
||||
<box state='CA' country='USA'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
</box>
|
||||
</truck>
|
||||
<truck id='GHI123'>
|
||||
<box state='The State of Rhode Island and Providence Plantations' country='USA'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
</box>
|
||||
</truck>
|
||||
```
|
||||
|
||||
Things to be careful about when using markup builders is not to overlap variables you currently have in scope. The following is a good example
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
def book = "MyBook"
|
||||
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
xml.shelf() {
|
||||
book(name:"Fight Club") {
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
When run this will actually get the error
|
||||
|
||||
```
|
||||
aught: groovy.lang.MissingMethodException: No signature of method: java.lang.String.call() is applicable for argument types: (java.util.LinkedHashMap, HelloWorld$_run_closure1_closure2) values: {["name":"Fight Club"],
|
||||
```
|
||||
|
||||
This is because we have a variable above called book, then we are trying to create an element called book using the markup. Markups will always honor for variables/method names in scope first before assuming something should be interpreted as markup. But wait, we want a variable called book AND we want to create an xml element called book! No problem, use delegate variable.
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
def book = "MyBook"
|
||||
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
xml.shelf() {
|
||||
delegate.book(name:"Fight Club") {
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
@@ -0,0 +1,21 @@
|
||||
---
|
||||
title: >-
|
||||
Groovy Goodness: Use GrabResolver for Custom Repositories - Messages from mrhaki
|
||||
updated: 2019-02-26 11:54:37Z
|
||||
created: 2019-02-26 11:53:45Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Groovy
|
||||
---
|
||||
## Groovy Goodness: Use GrabResolver for Custom Repositories
|
||||
|
||||
In Groovy we can use the @Grab annotation to define dependencies and automatically download them from public repositories. But maybe we have created our own package and we want to use it in our Groovy script. Our own package is deployed to a customer Maven 2 compatible repository with the url http://customserver/repo, so it is not available to the general public. We can use @GrabResolver to add this repository as a source to look for dependencies in our script. In the following sample code we assume the module groovy-samples, version 1.0 is deployed in the repository accessible via http://customserver/repo:
|
||||
|
||||
```groovy
|
||||
@GrabResolver(name='custom', root='http://customserver/repo', m2Compatible='true')
|
||||
@Grab('com.mrhaki:groovy-samples:1.0')
|
||||
import com.mrhaki.groovy.Sample
|
||||
|
||||
def s = new Sample()
|
||||
s.justToShowGrabResolver() // Just a sample
|
||||
```
|
||||
@@ -0,0 +1,57 @@
|
||||
---
|
||||
title: 'Groovy Goodness: Working with Lines in Strings - Messages from mrhaki'
|
||||
updated: 2019-02-26 13:56:12Z
|
||||
created: 2019-02-26 13:52:49Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Groovy
|
||||
---
|
||||
|
||||
In Groovy we can create multiline strings, which contain line separators. But we can also read text from an file containing line separators. The Groovy String GDK contains method to work with strings that contain line separators. We can loop through the string line by line, or we can do split on each line. We can even convert the line separators to the platform specific line separators with the denormalize() method or linefeeds with the normalize() method.
|
||||
|
||||
```groovy
|
||||
def multiline = '''\
|
||||
Groovy is closely related to Java,
|
||||
so it is quite easy to make a transition.
|
||||
'''
|
||||
|
||||
// eachLine takes a closure with one argument, that
|
||||
// contains the complete line.
|
||||
multiline.eachLine {
|
||||
if (it =~ /Groovy/) {
|
||||
println it // Output: Groovy is closely related to Java,
|
||||
}
|
||||
}
|
||||
|
||||
// or eachLine has a closure with two argument, the current line
|
||||
// and the line count.
|
||||
multiline.eachLine { line, count ->
|
||||
if (count == 0) {
|
||||
println "line $count: $line" // Output: line 0: Groovy is closely related to Java,
|
||||
}
|
||||
}
|
||||
|
||||
def platformLinefeeds = multiline.denormalize()
|
||||
def linefeeds = multiline.normalize()
|
||||
|
||||
// Read all lines and convert to list.
|
||||
def list = multiline.readLines()
|
||||
assert list instanceof ArrayList
|
||||
assert 2 == list.size()
|
||||
assert 'Groovy is closely related to Java,' == list[0]
|
||||
|
||||
def records = """\
|
||||
mrhaki\tGroovy
|
||||
hubert\tJava
|
||||
"""
|
||||
|
||||
// splitEachLine will split each line with the specified
|
||||
// separator. The closure has one argument, the list of
|
||||
// elements separated by the separator.
|
||||
records.splitEachLine('\t') { items ->
|
||||
println items[0] + " likes " + items[1]
|
||||
}
|
||||
// Output:
|
||||
// mrhaki likes Groovy
|
||||
// hubert likes Java
|
||||
```
|
||||
@@ -0,0 +1,78 @@
|
||||
---
|
||||
title: How Mermaid diagrams work in Obsidian - Ensley Tan - Medium
|
||||
updated: 2023-04-12 08:40:57Z
|
||||
created: 2023-04-12 08:40:57Z
|
||||
tags:
|
||||
- IT
|
||||
- IT/Tools/Obsidian
|
||||
source: >-
|
||||
https://medium.com/@ensleytan/how-mermaid-diagrams-work-in-obsidian-b7680fe00fa8
|
||||
---
|
||||
|
||||
I’m a sucker for features that are native to an app that I’m using and recently I’ve been learning how mermaid diagrams work in Obsidian. (I have been told about Excalidraw, but I draw horribly with my mouse and you need to download the Excalidraw plugin for it to work in Obsidian.)
|
||||
|
||||
## What’s Mermaid
|
||||
|
||||
It’s a way of creating diagrams using simple markup language. No drawing skills needed! No additional installation is needed either. Most useful for quickly jotting down a sequence of steps or a set of interconnected relationships.
|
||||
|
||||
Here are the two diagrams I use the most, as the syntax and variables they require are easy to remember.
|
||||
|
||||
## **A Simple flowchart / graph**
|
||||
|
||||

|
||||
|
||||
The syntax used is:
|
||||
|
||||

|
||||
|
||||
The first thing to tell mermaid is that you want to create a flowchart. There are other types of charts, more on that below.
|
||||
|
||||
The second thing is to declare which direction the chart should progress. You have a choice of TB (Top-Bottom), LR (Left-Right) or their opposites, BT and RL.
|
||||
|
||||

|
||||
|
||||
Charts can go BT, TB, LR, RL!
|
||||
|
||||
Then you can start adding the nodes you want and what sort of connection they have.
|
||||
|
||||
The most simple node consists of a single word. But if you want to have multiple words in one node, they need to be enclosed with square brackets and any alphanumeric string. I used “1” here, but even “Elephant” will work!
|
||||
|
||||
You also need to use an alphanumeric prefix and specific brackets if you want to change the shape of the node:
|
||||
|
||||

|
||||
|
||||
Node types
|
||||
|
||||
Lastly, you can show different and multiple relationships between the nodes. You can change the thickness of the links and whether there should be arrows. You can also add text to state the nature of the link.
|
||||
|
||||

|
||||
Different types of connections between nodes
|
||||
|
||||
## Pie chart
|
||||
|
||||
The pie chart works largely the same way, but with even fewer details needed. You just need to indicate groups and each group’s share of the pie.
|
||||
|
||||

|
||||
|
||||
## Other diagrams that work well in Obsidian
|
||||
|
||||
There are a whole list of other interesting charts in Mermaid. But I have found that the syntax becomes more complicated, meaning that I’m less likely to use them on the fly. More details on how to use them and the other diagram types I didn’t share [here](https://mermaid-js.github.io/mermaid/#/sequenceDiagram).
|
||||
|
||||
Below I’ve shared two other sorts of diagrams which I think work pretty well in Obsidian. All of the diagrams can have different colours, shapes etc if you feel like playing around with those.
|
||||
|
||||
## Sequence Diagram
|
||||
|
||||

|
||||
|
||||
## Gantt Chart
|
||||
|
||||

|
||||
|
||||
**Take a look at the rest of my articles on Obsidian:**
|
||||
|
||||
- [How to use Obsidian or any note-taking app for work (aka don’t fall for PKM candy)](https://medium.com/@ensleytan/how-to-use-obsidian-or-any-note-taking-app-for-work-aka-dont-fall-for-pkm-candy-d1f5396e4eb1)
|
||||
- [When you should consider switching to Obsidian](https://medium.com/@ensleytan/when-should-you-consider-switching-to-obsidian-6f37a1a68ecf?source=friends_link&sk=69246013e5222bc1cee1c0597df74aa4)
|
||||
- [Obsidian’s Graph Analysis plugin](https://medium.com/@ensleytan/obsidians-graph-analysis-plugin-c9c107da3331)
|
||||
- [Using Obsidian’s Graph View for real](https://medium.com/@ensleytan/using-obsidians-graph-view-for-real-99fd94153514?source=friends_link&sk=d68022880cda9ebcced0b926b11670a5)
|
||||
- [Using Obsidian for group KM](https://medium.com/@ensleytan/using-obsidian-for-group-km-145646068cd7?source=friends_link&sk=8c0b3dc4adaeadc8671b8da30ce7fa92)
|
||||
- [Obsidian for making sense of things](https://medium.com/@ensleytan/obsidian-for-making-sense-of-things-7b407c572846?source=friends_link&sk=3fb7dfa421f644e9994766abdf3ffe39)
|
||||
@@ -0,0 +1,343 @@
|
||||
---
|
||||
title: 'How to Use Obsidian Dataview: A Complete Beginners Guide'
|
||||
updated: 2023-03-27 15:00:05Z
|
||||
created: 2023-03-27 15:00:05Z
|
||||
tags:
|
||||
- IT
|
||||
- IT/Tools/Obsidian
|
||||
source: >-
|
||||
https://beingpax.medium.com/how-to-use-obsidian-dataview-a-complete-beginners-guide-2a275c274936
|
||||
---
|
||||
|
||||
## A Non-technical Guide
|
||||
|
||||

|
||||
|
||||
Obsidian dataview is one of the most widely used community plugins in obsidian. It turns your knowledge base into a database that you can query from.
|
||||
|
||||
If you are a non-technical person, dataview can scare you. But it doesn’t have to. This non-technical guide will help you to go from scratch to building your own database of personal knowledge in obsidian.
|
||||
|
||||
Using the dataview plugin in obsidian is like using obsidian on steroids. Before we begin the guide, let me show you some of the possibilities of obsidian. The setups I’ve used in my obsidian vault:
|
||||
|
||||
## View the most recent notes
|
||||
|
||||
<a id="e24c"></a>```dataview
|
||||
List
|
||||
From ""
|
||||
Sort file.mtime DESC
|
||||
Limit 5
|
||||
```
|
||||
|
||||
It searches my entire vault and lists the recently modified 5 notes:
|
||||
|
||||

|
||||
|
||||
## View notes that need to be processed
|
||||
|
||||
<a id="3c41"></a>```dataview
|
||||
Table file.ctime as created
|
||||
From #todevelop and -"008 TEMPLATES"
|
||||
sort ASCE
|
||||
Limit 20
|
||||
```
|
||||
|
||||
It searches my vault with notes tagged #todevelop and lists them in ascending order excluding notes from the Templates folder. Here’s the result:
|
||||
|
||||

|
||||
This is kind of mess. Showing all the books. But you see the result.
|
||||
|
||||
## View books that I’m reading currently
|
||||
|
||||
<a id="6ba5"></a>```dataview
|
||||
Table ("!\[|100\](https://beingpax.medium.com/" + cover\_url + ")") as Cover, author as Author, total\_page as "Pages", category as Category, Bar as Progress
|
||||
From #book
|
||||
where contains(status,"Reading")
|
||||
```
|
||||
|
||||
It searches my vault for #book and where the status is reading. It is rendered in table format with a cover, author, pages, category, and progress bar. Here is the result:
|
||||
|
||||
|
||||
|
||||
Table transformed to cards using minimal theme CSS
|
||||
|
||||
## Reading list
|
||||
|
||||
Similarly, there’s another query that shows me all the books that I’ve on my reading list on my obsidian vault.
|
||||
|
||||
<a id="1e62"></a>```dataview
|
||||
Table ("!\[|100\](https://beingpax.medium.com/" + cover\_url + ")") as Cover, author as Author, total\_page as "Pages", category as "Category"
|
||||
From #book
|
||||
where contains(status,"To Read")
|
||||
```
|
||||
|
||||

|
||||
Now you’ve got a glance at what is possible with the obsidian dataview plugin, let’s learn how to use it. But before that, we need to **understand YAML.**
|
||||
|
||||
## What is YAML
|
||||
|
||||
YAML stands for Yet Another Markup Language. It is also called frontmatter which is designed to add metadata to your notes. The metadata is readable to humans as well as obsidian.
|
||||
|
||||
This metadata is what is used by obsidian dataview to query notes.
|
||||
|
||||
Metadata is the data about data. Here’s an example of metadata.
|
||||
|
||||

|
||||
Example of Metadata
|
||||
|
||||
Here is a video file I took from my PC. If you go to the properties and details section, everything you see is metadata. The data about this particular video. The length, resolution, bitrate, and everything. All of this is added automatically.
|
||||
|
||||
In obsidian also, notes have some metadata such as the creation date, and modification date that is added automatically. But if you want to create an advanced database or search queries, you have to manually add metadata to your notes.
|
||||
|
||||
## How to add YAML/Frontmatter?
|
||||
|
||||
As the name itself suggests, frontmatter should be added at the top of your notes. To add metadata, you must add three dashes in two separate lines.
|
||||
|
||||
<a id="f0f9"></a>\-\-\-
|
||||
\-\-\-
|
||||
|
||||
Now everything you write in between these dashes will be metadata. For example:
|
||||
|
||||
<a id="390f"></a>\-\-\-
|
||||
tag: book
|
||||
Author: Pax
|
||||
status: Reading
|
||||
Rating: ⭐⭐⭐⭐⭐
|
||||
\-\-\-
|
||||
|
||||
This is a simple example of adding metadata in markdown notes. This metadata is used by the dataview plugin for querying your vault.
|
||||
|
||||
Here’s an example of the YAML frontmatter of one of my book notes. We will be using book notes in my obsidian vault for examples.
|
||||
|
||||

|
||||
Frontmatter added automatically with book search plugin
|
||||
|
||||
## Installing Dataview
|
||||
|
||||
If you haven’t installed the dataview plugin, install it from the community plugins section. Go to options and check the settings.
|
||||
|
||||

|
||||
|
||||
## How to use Dataview
|
||||
|
||||
To use obsidian dataview you will have to start with ```(three backticks). This will create a code block. Then write dataview after three backticks.
|
||||
|
||||
<a id="8a3f"></a>```dataview
|
||||
```
|
||||
|
||||
Dataview will work now. But it won’t show any result because we haven’t added any parameters.
|
||||
|
||||
## Different query formats available in obsidian
|
||||
|
||||
## List
|
||||
|
||||
Simply write the following code:
|
||||
|
||||
<a id="2116"></a>```dataview
|
||||
List
|
||||
```
|
||||
|
||||
It will render all the notes that you have in your obsidian vault as a list.
|
||||
|
||||
**Result:**
|
||||
|
||||

|
||||
|
||||
## Table
|
||||
|
||||
The table format is similar to the list. The only difference is that it uses multiple columns.
|
||||
|
||||
<a id="4e48"></a>```dataview
|
||||
Table
|
||||
```
|
||||
|
||||
This will render a table but with only one column. To add columns, add this:
|
||||
|
||||
<a id="f3ee"></a>```dataview
|
||||
Table author,category, my_rate, status
|
||||
```
|
||||
|
||||
**Remember:** While creating table headers, the table column should be exactly the same as you have in your notes metadata(No uppercase or lowercase difference). This is the result:
|
||||
|
||||

|
||||
If the notes don’t have the metadata for what you specified, it will return ‘ — ’ in the table.
|
||||
|
||||
If you want to use a different header, use the code as follows:
|
||||
|
||||
<a id="67d8"></a>```dataview
|
||||
Table author as Author,category as Category, my_rate as Rating, status as Status
|
||||
```
|
||||
|
||||
|
||||
|
||||
The header has changed as we specified.
|
||||
|
||||
## Tasks
|
||||
|
||||
I don’t use obsidian as a task manager. But if you want to use it, the obsidian dataview plugin can become handy. Here’s the dataview code you need and how it will render:
|
||||
|
||||
<a id="d378"></a>```dataview
|
||||
Task
|
||||
```
|
||||
|
||||

|
||||
I tried to use obsidian as my content planner but abandoned it. So these are some random results.
|
||||
|
||||
## Calendar
|
||||
|
||||
The calendar dataview query will display a dot per file on the date that file was modified or created.
|
||||
|
||||
<a id="2f34"></a>```dataview
|
||||
Calendar file.ctime
|
||||
```
|
||||
|
||||
|
||||
|
||||
The large number of dots is because I had to do the setup of my vault due to an error.
|
||||
|
||||
## Advanced Query (From)
|
||||
|
||||
I will show all of the advanced queries in a table format. Because understanding this will help you to use this in almost all other query formats.
|
||||
|
||||
The **from** query helps you to specify what you are looking for. Notes from a particular folder? Notes with a particular hashtag? Notes excluding a particular folder, etc.
|
||||
|
||||
Here’s an example of the previous table format query:
|
||||
|
||||
<a id="a4fe"></a>```dataview
|
||||
Table author as Author,category as Category, my_rate as Rating, status as Status
|
||||
From #book
|
||||
```
|
||||
|
||||
This will query notes with #book only. The results?
|
||||
|
||||

|
||||
If you want to **query from a particular folder**, use this: From “FOLDER_NAME”
|
||||
|
||||
<a id="dbf2"></a>```dataview
|
||||
Table author as Author,category as Category, my_rate as Rating, status as Status
|
||||
From "003 RESOURCES"
|
||||
```
|
||||
|
||||
To **query from a sub-folder** use this: From “FOLDER_NAME/SUBFOLDER”
|
||||
|
||||
<a id="c04e"></a>From "001 PROJECTS/Twitter"
|
||||
|
||||
To query notes with an incoming link:
|
||||
|
||||
<a id="8e34"></a>From \[\[Note 1\]\]
|
||||
|
||||
To query notes with outgoing link:
|
||||
|
||||
<a id="8afc"></a>From outgoing(\[\[Note1\]\])
|
||||
|
||||
## Multiple queries
|
||||
|
||||
If you want to query a note with multiple metadata: use this
|
||||
|
||||
<a id="a6fb"></a>From #book and "003 RESOURCES"
|
||||
|
||||
This will query notes with #book and which are inside the “003 RESOURCES" folder.
|
||||
|
||||
<a id="6e92"></a>From #book or "003 RESOURCES"
|
||||
|
||||
This will query notes that either has a #book or are inside the “003 RESOURCES" folder.
|
||||
|
||||
To exclude particular notes you can use — sign
|
||||
|
||||
<a id="cf92"></a>From #book and -"008 TEMPLATES"
|
||||
|
||||
To conclude from queries, look this:
|
||||
|
||||
- **For tag:** From #tag
|
||||
- **For folder or subfolder:** From “Folder”
|
||||
- **For Single files:** From “path/to/file”
|
||||
- **For links:** From \[\[Notes\]\]
|
||||
- **For Outgoing links:** outgoing(\[\[Note\]\])
|
||||
|
||||
## Advanced Query(WHERE)
|
||||
|
||||
Where filter can be used to further improve your notes database. Let’s say I want to query the books that I’ve finished reading. Here’s how the where filter would be used:
|
||||
|
||||
<a id="bcea"></a>```dataview
|
||||
Table author as Author,category as Category, my_rate as Rating, status as Status
|
||||
From #book and -"008 TEMPLATES"
|
||||
Where contains(status,"Completed")
|
||||
```
|
||||
|
||||
Look at the metadata I’ve in my book notes for reference in “How to add YAML section?”
|
||||
|
||||
Here’s how the query result will appear:
|
||||
|
||||

|
||||
Note: The notes in your metadata are used for all the queries. If you don’t have proper data, it will cause errors.
|
||||
|
||||
Let’s say you want to exclude all the notes that contain completed status. To do that you need to add the ‘!’ mark before contains like this:
|
||||
|
||||
<a id="5b0d"></a>```dataview
|
||||
Table author as Author,category as Category, my_rate as Rating, status as Status
|
||||
From #book and -"008 TEMPLATES"
|
||||
Where !contains(status,"Completed")
|
||||
```
|
||||
|
||||
This will exclude notes that contain completed status:
|
||||
|
||||
|
||||
|
||||
**Another example:**
|
||||
|
||||
Find the notes that you created recently. This will list the notes that have been created in the last 1 day.
|
||||
|
||||
<a id="fd6b"></a>```dataview
|
||||
List
|
||||
From ""
|
||||
Where file.ctime >= date(today) - dur(1 day)
|
||||
```
|
||||
|
||||
## Sort your notes
|
||||
|
||||
There is another great community plugin called sortable. It allows you to sort your database without editing it every time you want to sort it. If you don’t want to use it, you can use the code as well:
|
||||
|
||||
<a id="3666"></a>```dataview
|
||||
Table author as Author,category as Category, my_rate as Rating, status as Status
|
||||
From #book and -"008 TEMPLATES"
|
||||
Where contains(status,"Completed")
|
||||
Sort file.mtime DESC
|
||||
|
||||
This will sort the files according to their modified time. You can use different other metadata too. For example, I’ve book notes in my vault and they also have metadata for no. of pages. I can sort them by pages using the dataview code:
|
||||
|
||||
<a id="09de"></a>```dataview
|
||||
Table author as Author,category as Category, my\_rate as Rating, status as Status, total\_page as Pages
|
||||
From #book and -"008 TEMPLATES"
|
||||
Where contains(status,"Completed")
|
||||
Sort total_page Asc
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Limit the queries
|
||||
|
||||
You may have a lot of notes in your vault. If you don’t want to see all of your notes. If you want to **restrict the results to a particular number** you can use the limit function.
|
||||
|
||||
<a id="75b3"></a>```dataview
|
||||
Table author as Author,category as Category, my\_rate as Rating, status as Status, total\_page as Pages
|
||||
From #book and -"008 TEMPLATES"
|
||||
Where contains(status,"Completed")
|
||||
Sort total_page Asc
|
||||
Limit 7
|
||||
```
|
||||
|
||||
**The result?**
|
||||
|
||||

|
||||
No. of queries limited to 7
|
||||
|
||||
The obsidian dataview plugin is simple. **Don’t let the large setups scare you.** Start with simple dataview queries like a list or table. Then slowly start using other dataview functions as required.
|
||||
|
||||

|
||||
|
||||
## Obsidian Note-Taking
|
||||
|
||||
## Not a Medium Member Yet?
|
||||
|
||||
If you liked this story, you will love the [**medium subscription**](https://beingpax.medium.com/membership). With only *$5 a month*(less than the price of a cup of coffee), you get unlimited access to the best stories and articles written on the web.
|
||||
|
||||
This is [***my referral link***](https://beingpax.medium.com/membership)*.* If you sign up using this link, I earn a small commission with no additional charges to you.
|
||||
@@ -0,0 +1,376 @@
|
||||
---
|
||||
title: titles - How to customize my titlepage? - TeX
|
||||
updated: 2019-08-21 14:59:24Z
|
||||
created: 2019-08-21 14:59:24Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/LaTeX
|
||||
source: https://tex.stackexchange.com/questions/209993/how-to-customize-my-titlepage
|
||||
---
|
||||
|
||||
[The titlepage is one of the first pages of a book or thesis. This page contains only the title in a fashion similar to the rest of the text within the book.](http://en.wikipedia.org/wiki/Title_page)
|
||||
|
||||
That is what Wikipedia tells us, now we have a perspective to follow, the titlepage should match the appearance of the rest of the book or thesis. Let us look at the standard scrbook titlepage.
|
||||
|
||||
```latex
|
||||
\documentclass{scrbook}
|
||||
\usepackage[utf8]{inputenc}
|
||||
\usepackage[T1]{fontenc}
|
||||
\usepackage[english,french]{babel}
|
||||
\makeatletter
|
||||
\newcommand{\fakechap}[1]{{\noindent\normalfont\sectfont\nobreak\size@chapter{}#1\par}\chapterheadendvskip\noindent\ignorespaces}
|
||||
\makeatother
|
||||
\subject{Doctoral thesis}
|
||||
\title{On ducks and their love for dissertations}
|
||||
\subtitle{A fiction story telling the truth}
|
||||
\author{domi}
|
||||
\publishers{Published by the publisher\\ at a secret location}
|
||||
%\extratitle{Stories of ducks}
|
||||
\uppertitleback{\vspace{3cm}I want to thank Scrooge MacDuck for his financial Support}
|
||||
\date{}
|
||||
\usepackage{blindtext}
|
||||
\begin{document}
|
||||
\frontmatter
|
||||
\maketitle
|
||||
|
||||
\tableofcontents
|
||||
\addchap{Résumé}
|
||||
Résumé de la thèse en français\dots
|
||||
\blindtext
|
||||
\vfill
|
||||
|
||||
\selectlanguage{english}
|
||||
\fakechap{Summary}
|
||||
Résumé de la thèse en anglais\dots
|
||||
\blindtext
|
||||
\vfill
|
||||
|
||||
\selectlanguage{french}
|
||||
\end{document}}
|
||||
```
|
||||
|
||||

|
||||
|
||||
Command `\maketitle` places the predefined elements on the first page. If you want, you can change the font using the usual `\addtokomafont`-mechanism.
|
||||
|
||||
There are more elements available, e.g. `\publishers`, `\titlehead` and `\extratitle`. Additional elements are only typeset if they have been define by the user with some argument. In other words, no space is reserved just in case.
|
||||
|
||||
Book classes do not provide an `abstract` environment as it is usual for books to have a whole chapter to sum up the contents. I defined a `\fakechap` command to have both on the same page and look alike. To be honest, it is a bit of a hack, a chapter should be of its own. Please note the difference in using `\addchap`. If you are interested, you can find out more at [How to use unnumbered chapters with KOMA-script?](https://tex.stackexchange.com/questions/193767/how-to-use-unnumbered-chapters-with-koma-script/193799#193799).
|
||||
|
||||
What happens if we are using `\extratitle` to the above MWE?
|
||||
An additional pair of pages has been generated in the very beginning. Seems to be a strange location for a title. This is a fact of history, as books didn't have a hard cover a while back. This extra title protected the book from dirt. It is also called a _bastard title_.
|
||||
|
||||
Default option for book classes is the start of new chapters on odd (right hand) pages. That means for us, we get a blank page between title and the first chapter. If we set `\uppertitleback` we can place a thanks note, or something else. You can even use spaces if you need to customize a little bit.
|
||||
|
||||
But who decided where the elements set with `\title`, `\author` and co are placed? It is the author of the class. In the case of KOMA-script it was Markus Kohm. That brings us to our next question:
|
||||
|
||||
Relatively simple, as LaTeX is a macro language to place boxes. It is like having a huge lego set and put pieces together until satisfied with the solution.
|
||||
|
||||
As we now want to do the titlepage with our own hands, we don't call `\maketitle` that would do the default stuff. Since we don't use `\maketitle` we don't need to set the fields for it. No need for `\title{this is the title}` et al. _If you are using `\maketitle` together with the `titlepage`-environment, you are doing something wrong._
|
||||
|
||||
```latex
|
||||
\documentclass{report}
|
||||
\usepackage{blindtext}
|
||||
\begin{document}
|
||||
\begin{titlepage}
|
||||
Dixie dancing ducks
|
||||
|
||||
A story of love, hate and fame
|
||||
\end{titlepage}
|
||||
\chapter{Summary}
|
||||
\blindtext
|
||||
\end{document}
|
||||
```
|
||||
|
||||

|
||||
|
||||
Not very pleasing to the eye. We forgot to use the right pieces to modify it. Some tweaks lead us to this:
|
||||
|
||||
```latex
|
||||
\documentclass{report}
|
||||
\usepackage{blindtext}
|
||||
%\usepackage{showframe}
|
||||
\begin{document}
|
||||
\begin{titlepage}
|
||||
\vspace*{9em}{\centering\Huge\usefont{T1}{qzc}{m}{it}
|
||||
Dixie dancing ducks\par}
|
||||
\vspace{1em}
|
||||
{\hfill\itshape A story of love, hate and fame}
|
||||
\clearpage
|
||||
\vspace*{\fill}\hfill \parbox{.4\textwidth}{
|
||||
\raggedleft
|
||||
\scriptsize Delilah was a sad duck with a dream, being a
|
||||
Dixie dancer some day. She wasn't the best looking duck
|
||||
in town but she never cared about superficial things.
|
||||
Practicing a lot she finally became a professional Dixie
|
||||
dancer. She even fell in love. Will Delilah overcome the
|
||||
infamy and hate of her \emph{new gained friends}?
|
||||
}
|
||||
\end{titlepage}
|
||||
\chapter{Summary}
|
||||
\blindtext
|
||||
\end{document}
|
||||
```
|
||||
|
||||

|
||||
|
||||
Looks much better, but the page number is screwed. Using a KOMA-class can save the day.
|
||||
|
||||
* * *
|
||||
|
||||
Now an example that might be used as a cover for a thesis. Using the `addmargin`-environment, we can get some asynchronity for the titlepage. Package `mwe` gives us some dummy pictures, we could use the universities logo instead.
|
||||
|
||||
> 
|
||||
|
||||
```latex
|
||||
\documentclass{scrreprt}
|
||||
\usepackage{graphicx}
|
||||
\begin{document}
|
||||
\begin{titlepage}
|
||||
\begin{addmargin}[4cm]{-1cm}
|
||||
\centering
|
||||
\hfill\includegraphics[width=2cm]{example-image-1x1}\par
|
||||
\vspace{4\baselineskip}
|
||||
{\Huge Peter Piper picked a peck\\ of pickled peppers\par}
|
||||
\vspace{4\baselineskip}
|
||||
by\par
|
||||
{\Large\textsc{Crazy Capybara}\par}
|
||||
\vfill
|
||||
in order to get a fancy degree at\par
|
||||
{\em The university of applied dice rolling}
|
||||
\end{addmargin}
|
||||
\end{titlepage}
|
||||
\end{document}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
A titlepage for a scientific article is also possible. If the journal provides no template, there is mostly no use in bothering to implement their style, they will happily do it for you.
|
||||
|
||||
This will be just an example, if you are really working on a titlepage for a journal, take the solid approach as mentioned later on. Al this manual fixing up should not been done twice to get the same output.
|
||||
|
||||
```latex
|
||||
\documentclass[twoside,ngerman]{article}
|
||||
\usepackage{blindtext}
|
||||
\usepackage{babel}
|
||||
\usepackage{hyperref}
|
||||
|
||||
\begin{document}
|
||||
\twocolumn[%
|
||||
\centering
|
||||
\begin{minipage}{.75\textwidth}
|
||||
\begin{center}
|
||||
{\large
|
||||
Pendulum\par}
|
||||
presents\par
|
||||
{\Large The sonic recreation of \\the end of the world\par}
|
||||
\end{center}
|
||||
\vspace{\baselineskip}
|
||||
\setlength{\parskip}{\smallskipamount}
|
||||
Ladies and gentlemen, We understand that you Have come tonight
|
||||
To bear witness to the sound Of drum And Bass.
|
||||
|
||||
We regret to announce That this is not the case, As instead We
|
||||
come tonight to bring you The sonic recreation of the end of
|
||||
the world.
|
||||
|
||||
Ladies and gentlemen, Prepare To \dots\par
|
||||
\rule{7em}{.4pt}\par
|
||||
Rob Swire, Gareth McGrillen, and Paul
|
||||
Harding;\par \href{mailto:someone@gmail.com}{Mail the
|
||||
authors}
|
||||
\end{minipage}
|
||||
\vspace{2\baselineskip}
|
||||
]
|
||||
\section{Hold Your Colour}
|
||||
\blindtext
|
||||
|
||||
\blindtext
|
||||
\end{document}
|
||||
```
|
||||
|
||||

|
||||
|
||||
A collection of different titlepages that can lead to your very own customized titlepage can be found at [Titlepage](http://ctan.org/pkg/titlepages). I'll also try to collect some [titlepages on github](https://github.com/johannesbottcher/titlepages).
|
||||
|
||||
The natural approach to use the rock solid KOMA-interface is impossible, as the author of `classicthesis` decided to implement things in _another_ way. We would have to put the commands inside the definition, which feels like rape to me, so no example for this. We are back at putting lego pieces together
|
||||
|
||||
```latex
|
||||
\documentclass[12pt,a4paper,footinclude=true,twoside,headinclude=true,headings=optiontoheadandtoc]{scrbook}
|
||||
%\usepackage{geometry}
|
||||
%\geometry{marginparsep=8pt,left=3.5cm,right=3.5cm,top=3cm,bottom=3cm}
|
||||
\usepackage[parts,pdfspacing,dottedtoc]{classicthesis}
|
||||
\usepackage[utf8]{inputenc}
|
||||
\makeatletter
|
||||
\newcommand{\fakechap}[1]{{\noindent\normalfont\sectfont\nobreak\size@chapter{}#1\par}\chapterheadendvskip\noindent\ignorespaces}
|
||||
\makeatother
|
||||
\usepackage{blindtext}
|
||||
\begin{document}
|
||||
\frontmatter
|
||||
\begin{titlepage}
|
||||
\vspace*{7em}
|
||||
\begin{center}
|
||||
{\Large \spacedallcaps{is it really worth the trouble?}
|
||||
\bigbreak}
|
||||
An assessment of spent time adjusting badly
|
||||
implemented \LaTeX{} templates \\[2em]
|
||||
{\scriptsize \spacedlowsmallcaps{The author}}
|
||||
\end{center}
|
||||
\end{titlepage}
|
||||
|
||||
\tableofcontents
|
||||
\addchap{Résumé}
|
||||
Résumé de la thèse en français\dots
|
||||
\blindtext[13]
|
||||
\vfill
|
||||
|
||||
\fakechap{Summary}
|
||||
No, simple as that.
|
||||
\blindtext
|
||||
\vfill
|
||||
\end{document}}
|
||||
```
|
||||
|
||||

|
||||
|
||||
The titlepage looks ok, but---having an up to date TeX installation---we get a huge warning and looking at the next page we are shocked. Our predefined _fakechap_ doesn't match. `classicthesis` loads package `titlesec` which is incompatible with KOMA. `titlesec` adds features to the LaTeX standard classes, `memoir` has its own way of customizing things, `KOMA` as well. Some functionality is broken.
|
||||
|
||||
For advanced users
|
||||
|
||||
If the layout of the titlepage is fixed by some rules or guidelines of a corporate design, we need to make sure the user doesn't change the appearance. We use the same concept of defining a titlepage, but hide it in a package file (or possibly a class file). Just like the standard classes, we define a set of macros for the user (`author`, `title`, `degree` etc.). The user can input his or her data in the document with no need to care about what is going on in the background and can just call `\maketitle`. A very basic and non-advanced example:
|
||||
|
||||
```latex
|
||||
\begin{filecontents}{domititlepage.sty}
|
||||
\ProvidesPackage{domititlepage}[2014/11/03 titlepages domi style]
|
||||
%There is absolutely no warranty for this demo package
|
||||
% https://tex.stackexchange.com/questions/209993/how-to-add-a-flyleaf-code/210280#210280
|
||||
\RequirePackage{etoolbox}
|
||||
\ifundef{\KOMAClassName}{
|
||||
\@ifclassloaded{memoir}{\PackageWarningNoLine{domititlepage}{Using
|
||||
memoir. Memoir has its own mechanism of
|
||||
generating stuff. Not loading
|
||||
`scrextend'. Aborting now}
|
||||
\endinput
|
||||
}{
|
||||
\typeout{You seem to be using a standard class.
|
||||
Using package `scrextend' for nice
|
||||
features}
|
||||
\RequirePackage[extendedfeature=title]{scrextend}
|
||||
}
|
||||
\typeout{non-KOMA branch}
|
||||
}{
|
||||
\typeout{Using a KOMA class, no need to load package scrextend}
|
||||
}
|
||||
\newcommand{\@supervisor}{}
|
||||
\newcommand{\supervisor}[1]{\gdef\@supervisor{#1}}
|
||||
\newkomafont{supervisor}{\normalfont\normalsize}
|
||||
\newcommand{\@degree}{}
|
||||
\newcommand{\degree}[1]{\gdef\@degree{#1}}
|
||||
\newkomafont{degree}{\normalfont\normalsize}
|
||||
\newcommand*{\@thanksnote}{}
|
||||
\newcommand*{\thanksnote}[1]{\gdef\@thanksnote{#1}}
|
||||
\newkomafont{thanksnote}{\small\itshape}
|
||||
\newcommand{\@@thanksnote}{\begin{minipage}{\linewidth}
|
||||
\usekomafont{thanksnote}\@thanksnote\par\end{minipage}\par}
|
||||
\renewcommand{\maketitle}{%
|
||||
\begin{titlepage}
|
||||
\setlength{\parindent}{\z@}
|
||||
\setlength{\parskip}{\z@}
|
||||
\typeout{Typesetting the titlepage}
|
||||
\vspace{-1em}
|
||||
\begin{minipage}[t]{\textwidth}
|
||||
\centering
|
||||
University for theoretical and applied animal dance in Duckburg\par
|
||||
\end{minipage}\par
|
||||
\vspace{7em}
|
||||
{\LARGE\centering\usefont{T1}{qcs}{b}{n} \@title\par}
|
||||
\vspace{5em}
|
||||
{\usekomafont{author}\centering \@author\par}
|
||||
\vspace{2em}
|
||||
\ifx\@degree\@empty \else
|
||||
{\centering\usekomafont{degree}\@degree\par}
|
||||
\fi
|
||||
\next@tpage
|
||||
\ifx\@thanksnote\@empty\hbox{} \else
|
||||
{\@@thanksnote}
|
||||
\fi
|
||||
\vfill
|
||||
\begin{minipage}{10em}
|
||||
\raggedright
|
||||
\usefont{T1}{qcr}{m}{n}
|
||||
No animals were harmed
|
||||
during the production of
|
||||
this printed work\par
|
||||
\end{minipage}
|
||||
\end{titlepage}%
|
||||
}
|
||||
\end{filecontents}
|
||||
\documentclass{scrbook}
|
||||
\usepackage{domititlepage}
|
||||
\usepackage{blindtext}
|
||||
\author{Paulo Lee Peterson}
|
||||
\title{Polka loving Platypus}
|
||||
%\degree{Master of Stuff}
|
||||
%\thanksnote{Thanks to Daisy for her support}
|
||||
|
||||
\begin{document}
|
||||
\maketitle
|
||||
\chapter{Introduction to Polka dancing}
|
||||
\blindtext
|
||||
\end{document}
|
||||
```
|
||||
|
||||
The above uses a little trick to save us time, it writes the contents of the first environment (filecontents) to a new file (called `domititlepage.sty`), which gives us a solid LaTeX-package the user can load in the preamble.
|
||||
|
||||
The heading of this section said something about a solid method, right before the example, i said it is non-advanced. What is going on? We are defining some simple to remember commands like `author` and `degree`. As the appearance of the titlepage is given and therefore fixed, it doesn't matter in which order the user types in its data, our `\maketitle` command takes care of typesetting everything where it is supposed to be according to the guidelines. A few things a kept variable. There is an easy to use interface to set the font of some elements provided by KOMA-scripts font selection features. The user can decide whether he wants to give a thanksnote or leave that out. The package handles this.
|
||||
|
||||
Almost all code is hidden from the user, who might be intimidated, hence the user cannot change anything without a bit of effort. This seems to be quite solid, so why is it non advanced? The above is a syntax/language mix-up of `TeX`, `LaTe2eX` and maybe a bit of LaTeX3 in the future. This is quite bad style.
|
||||
|
||||

|
||||
|
||||
The author of KOMA-script started a project called `titlepage` a few years back collecting different titlepages, defining different languages and hence making the titlepages rock solid. The zip folder can be downloaded at the [KOMA-project website](http://www.komascript.de/titlepage).
|
||||
|
||||
Package `titlepage` provides a new interface for `\maketitle` making it possible to give the relevant information in a quite handy _key-value-syntax_. Not all styles (loaded by `\TitlePageStyle{<style>}`) support all possible fields.
|
||||
|
||||
The thing is though, in order to get the titlepage of your university available with the `titlepage` package, you need to get in contact with the author of KOMA-script.
|
||||
|
||||
```latex
|
||||
%% Copyright (c) 2011 by Markus Kohm <komascript(at)gmx.info>
|
||||
\documentclass[a4paper,pagesize]{scrbook}
|
||||
\usepackage[utf8]{inputenc}
|
||||
\usepackage[ngerman]{babel}
|
||||
\usepackage[T1]{fontenc}
|
||||
\usepackage{lmodern}
|
||||
\usepackage[demo]{graphicx}% remove option demo if you have the logo
|
||||
\usepackage{xcolor}
|
||||
\usepackage{titlepage}
|
||||
\begin{document}
|
||||
\TitlePageStyle{KIT}
|
||||
\maketitle[%
|
||||
mainlogo={\textcolor{red}{%
|
||||
\includegraphics[width=40mm,height=18.5mm]{KITLogo_RGB}}},%
|
||||
% You may additionally change titlehead. Original definition of titlehead
|
||||
% is:
|
||||
titlehead={\usetitleelement{mainlogo}\hspace*{\fill}},%
|
||||
title=\textcolor{red}{Titel der Arbeit\\im Stil \texttt{KIT}},%
|
||||
subject=\textcolor{red}{Klassifizierung der Arbeit},%
|
||||
author=\textcolor{red}{Markus~Kohm},%
|
||||
faculty=\textcolor{red}{Fakultät für Informatik},%
|
||||
chair=\textcolor{red}{%
|
||||
Institute for Program Structures\\and Data Organization (IPA)},%
|
||||
advisor={\textcolor{red}{Titel Vorname Nachname}\and
|
||||
\textcolor{red}{Titel Vorname Nachname}},%
|
||||
referee={\textcolor{red}{Titel Vorname Nachname}\and
|
||||
\textcolor{red}{Titel Vorname Nachname}},%
|
||||
duration=\textcolor{red}{XX. Monat 20XX -- XX. Monat 20XX},%
|
||||
university=\textcolor{red}{\KITlongname},%
|
||||
homepage=\textcolor{red}{\KITurl}%
|
||||
]
|
||||
\end{document}
|
||||
```
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
[The Wikibook page on Title Creation](https://en.wikibooks.org/wiki/LaTeX/Title_Creation), you can find some more examples linked there
|
||||
@@ -0,0 +1,19 @@
|
||||
---
|
||||
title: How to delete a remote Git tag
|
||||
updated: 2019-02-26 10:01:25Z
|
||||
created: 2019-02-26 10:01:02Z
|
||||
tags:
|
||||
- Development/Git
|
||||
- Development/Shell
|
||||
---
|
||||
|
||||
You probably won't need to do this often (if ever at all) but just in case, here is how to delete a tag from a remote Git repository.
|
||||
|
||||
If you have a tag named '12345' then you would just do this:
|
||||
|
||||
```shell
|
||||
git tag -d 12345
|
||||
git push origin :refs/tags/12345
|
||||
```
|
||||
|
||||
That will remove '12345' from the remote repository.
|
||||
+93
@@ -0,0 +1,93 @@
|
||||
---
|
||||
title: >-
|
||||
I'm replacing Evernote with Joplin, a multi-platform, open source note taking application
|
||||
updated: 2021-08-23 09:18:13Z
|
||||
created: 2021-08-23 09:18:13Z
|
||||
source: https://jjude.com/joplin
|
||||
tags;
|
||||
- IT
|
||||
- IT/Tools/Joplin
|
||||
---
|
||||
|
||||
## Joseph Jude
|
||||
|
||||
[Home](https://jjude.com/ "Home")[About](https://jjude.com/about "About")[Posts](https://jjude.com/posts "Posts")
|
||||
|
||||
### With Joplin, I am finally ditching Evernote
|
||||
|
||||

|
||||
|
||||
I have been using Evernote for close to a decade now. It has notes from all the books I have read, best paras from the articles I liked, and even reasons for investing in specific stocks. With about 2000 notes, it serves as my external brain.
|
||||
|
||||
Evernote has a fantastic ecosystem. I can email note, I can send an article from Pocket, and I can clip a webpage from Firefox. I can use the app on every platform. I can use Evernote even under Linux, using a 3rd party application.
|
||||
|
||||
Ever since the future of Evernote became uncertain, I started looking for an alternative. My expectations are simple (at least I like to think so):
|
||||
|
||||
- It should work on Mac, Android, and Linux, the platforms I use
|
||||
- It should store data locally. If an app becomes my external brain, I better have access to the data all the time and have a backup too.
|
||||
- It would be a bonus if it stored data in plaintext because text format will stay for decades.
|
||||
- It should have browser integration so I can clip interesting webpages
|
||||
|
||||
I searched far and wide and tried many of the “coolest” apps. But nothing came close to Evernote. Even after all these years, Evernote is still the undisputed king of note-taking.
|
||||
|
||||
Recently, I came across an interesting open-source application called [Joplin](https://joplinapp.org/). Joplin is the first application that ticks every expectation I have.
|
||||
|
||||
I have been using Joplin for a week now diving deep into all the features it has—including its terminal application. In Joplin, I might have found the application to replace Evernote finally.
|
||||
|
||||
Here are some of the positives and negatives of Joplin.
|
||||
|
||||
## Positives
|
||||
|
||||
- It has almost all the features of Evernote that I care - notebooks, notes, tags, images, web clipping, sync, and apps for multi-platform.
|
||||
- It stores everything locally in text files. So even if Joplin vanishes, I will still have access to my notes.
|
||||
- Search in the desktop app is reasonably fast and accurate.
|
||||
- You can import all your notes from Evernote. I imported around 2000 notes from Evernote.
|
||||
- Joplin can support Dropbox, OneDrive, etc. for sync. I used Dropbox, and the sync is fast.
|
||||
- I can link to other notes with Joplin, which means I can create a wiki within Joplin. If I’m writing a book, this is handy.
|
||||
- Joplin comes with a web clipper equivalent to Evernote. Surprisingly it works without a flaw. This one feature might tie me to Joplin.
|
||||
|
||||
## Negatives
|
||||
|
||||
- Biggest negative for me is that the user experience of the apps is not very appealing like Evernote.
|
||||
- Evernote import was not that clean. Had to go in and edit many of the imported notes.
|
||||
- Initial sync took a lot of time. I left it for the night to complete. Tags took even longer time to sync. Maybe because there were 2000 notes.
|
||||
- It doesn’t have a highlight feature as in Evernote
|
||||
- Desktop app is slow even in rendering the preview of the notes
|
||||
- Mobile app doesn’t have “pull to refresh” feature
|
||||
- Mobile app has “all notes” feature. The desktop apps miss this feature, leading to a cognitive gap when switching between mobile and desktop.
|
||||
- Tried export to pdf on Mac. It leaves out many lines. It is not complete and hence, unusable.
|
||||
- In Evernote, I can share a note with others. Sharing a note is not possible with Joplin.
|
||||
- There is no integration with spell check. When you are typing fast, you tend to make a lot of mistakes. There is a way around, though. There is an option to invoke an external editor. So you can configure to edit your notes in your favorite editor, even if it is vim.
|
||||
- When I delete a note that has an image, the image in the `_resource` directory is not deleted. This leads to orphan images and heavy storage requirement.
|
||||
- It doesn’t have a ‘Recycle bin,’ so in case you accidentally deleted a note, you lost it completely. If you enable autosave in external editors, they usually delete the existing note and create a new note. This will cause Joplin to delete the note and create a new “untitled” note.
|
||||
|
||||
Even though there are many negatives, Joplin meets all my fundamental expectations. I am going to use it for at least six months.
|
||||
|
||||
## How can you get started?
|
||||
|
||||
The [homepage](https://joplinapp.org/) of the application has clear instructions to install applications on all platforms. I followed the given instructions for Evernote export and import too.
|
||||
|
||||
If you have a lot of Evernote notes, then initial sync will take a long time. Better to leave it for the night.
|
||||
|
||||
While you are at it, install the web clipper too. It is awesome.
|
||||
|
||||
## Bonus (git repo with notes)
|
||||
|
||||
Though you type in plaintext, Joplin uses SQLite internally to organize notes. But it has an `export` option. You can combine it with a git repository. Now you have version control for your notes. Here are the steps:
|
||||
|
||||
1. Create a repository in Gitlab / Github
|
||||
2. Clone the repository locally
|
||||
3. Install Joplin terminal application (if you have installed the GUI application via `brew` then `brew` won’t create shortcut links when you install the terminal application. You should alias it)
|
||||
4. Create the following script and run it whenever needed (don’t forget to change the directories!)
|
||||
|
||||
```shell
|
||||
BACKUP_DIR="~/joplin"
|
||||
JOPLIN_BIN="/usr/local/Cellar/joplin/1.0.141_1/bin/joplin"
|
||||
NOW=$( date '+%F_%H:%M:%S' )
|
||||
|
||||
rm -rf $BACKUP_DIR/notes
|
||||
$JOPLIN_BIN --profile ~/.config/joplin-desktop/ export --format md $BACKUP_DIR/notes
|
||||
cd $BACKUP_DIR
|
||||
git add .
|
||||
git commit -m "update-$NOW"
|
||||
```
|
||||
@@ -0,0 +1,61 @@
|
||||
---
|
||||
title: Improve Your Git Commits in Two Easy Steps
|
||||
updated: 2022-08-18 09:37:09Z
|
||||
created: 2022-08-18 09:36:29Z
|
||||
source: >-
|
||||
https://blogs.vmware.com/opensource/2021/04/14/improve-your-git-commits-in-two-easy-steps/
|
||||
tags:
|
||||
- Development/Git
|
||||
- Commit
|
||||
---
|
||||
|
||||
## [Improve Your Git Commits in Two Easy Steps](https://blogs.vmware.com/opensource/2021/04/14/improve-your-git-commits-in-two-easy-steps/)
|
||||
|
||||
In any successful open-source project, quality git commits are essential. Yes, your code should be technically sound, well-tested and functional, but breaking up your changes into readable chunks and writing informative commit messages are equally as important as the actual code being committed to the project. Well-structured and well-written git commits ensure your code is maintainable, approachable and can be easily debugged. Whether you’re a seasoned veteran or brand new to an open-source community, writing quality git commits is an essential step towards getting your changes merged. Excellent commits have two attributes:
|
||||
|
||||
1. Each commit only does one thing
|
||||
2. Each commit message is its own self-contained story
|
||||
|
||||
I spoke on this topic recently at OpenSource101. The recording of my presentation is below.
|
||||
|
||||
[Improve Your Git Commits in Two Easy Steps – Rose Judge – VMware – Open Source 101](https://www.youtube.com/watch?v=6gWSEKESYJw)
|
||||
|
||||
## Each commit does only one thing
|
||||
|
||||
At a high level, think of your commit like a recipe. If you had ingredients and were told to use them to make a cake, where would you start? First, you would probably look for a recipe that tells you how to make it. Now imagine all the directions for the recipe are crammed into one big paragraph instead of separated into steps – it would be pretty hard to follow along, right? The same is true for your git commits. Think of your pull request, which is the sum of all your commits, as the recipe. Each commit in that pull request should be one step of the recipe that tells you how to make the cake.
|
||||
|
||||
Separating your commits into smaller chunks makes your changelog easier to navigate if there’s ever a regression in your code. Your commits are essentially a list of steps that you can trace to find where the problem was introduced. If all your past changes are represented as one big change, it’s going to be difficult to narrow down where exactly the error occurred. But, if your changes are separated into smaller commits that each only do one thing, it will be much easier to isolate the commit that broke the build. Once you find that commit, reverting a smaller patch that only does one thing will be much easier than if that patch contained many changes.
|
||||
|
||||
As you start to break up your commits to only do one thing, consider what each change is doing. Isolate your non-functional changes into their own commits (i.e., changes where no code is changing). Next, dissect your functional changes into their own commits. For example, if you are creating a new function ‘foo’ while also renaming another function ‘bar,’ each of those individual changes can be their own commits. If you are doing any code cleanup, those changes can also be their own commits. Finally, no commit should break the build. This means that at each commit the code should compile.
|
||||
|
||||
## Each commit message is its own self-contained story
|
||||
|
||||
Once you’ve broken up your changes so each commit only does one thing, it’s time to write a commit message for each change. Your commit message title should contain a summary of *what* changed. The body of the commit message will be your explanation as to *why* and in what *context* the changes are being made.
|
||||
|
||||
In general, keep the reviewer in mind when you are writing your commit message. Assume they are not familiar with the code you’re changing and have no context about why the change is being made. Summarize any relevant information in the body – this may include information about how you arrived at your proposed solution, why the fix is necessary, notes on performance improvements, error messages the commit is addressing, bug references or links to relevant discussions. If you provide outside URLs in your commit message, it’s important that enough context exists in the commit message itself that the reviewer doesn’t have to click on the link to understand the changes. Think of any URL you provide as supportive evidence in addition to your summary of the relevant information.
|
||||
|
||||
A good commit message boils down to a good story. It has a beginning, middle and end with all relevant details self-contained and clearly summarized. A self-contained commit message will explain any assumptions being made in the explanation and reference future or past commits in context so the reviewer can easily comprehend the changes being proposed. The more detail and clarity you provide as to why you are making the change, the faster the reviewer(s) will be able to provide feedback and ultimately, merge your change.
|
||||
|
||||
## The power of good commits
|
||||
|
||||
Well-organized commits and thoroughly explained commit messages add numerous benefits to a project:
|
||||
|
||||
- *Makes future debugging and code cleanup easier*
|
||||
|
||||
If you encounter a regression in the future and you need to figure out which change caused the problem, working with smaller commits that only do one thing makes it easier to find the exact change where the issue was introduced and revert it, if necessary.
|
||||
|
||||
- *Protection when a contributor leaves a project*
|
||||
|
||||
Good commits are an easy insurance policy to protect against attrition in a project. If anyone contributing to your project suddenly leaves the community, good commits will make it possible for the project to continue even when an author of a patch set is not around to answer questions.
|
||||
|
||||
- *Enables time zone collaboration*
|
||||
|
||||
Good commits enable the development process to continue even while contributors in differing time zones sleep. If someone has a question about a particular commit, they can read the commit message and get all the context they need instead of waiting to ask the author directly.
|
||||
|
||||
- *Makes your project approachable for new contributors*
|
||||
|
||||
Think of your commit messages in the same way you think of documentation for your project – if your commits are detailed and organized, new contributors will get up and come running to contribute to your project sooner.
|
||||
|
||||
Writing good commits is a skill that will take time to master – but practice is the only way to improve. So start practicing today. If you’re the maintainer of a project, add your projects git commit requirements to the Contributing Guide. If you’re a contributor working on a project with no commit requirements, consider opening an issue (or better yet, a pull request!) to add these requirements to the project documentation.
|
||||
|
||||
When you’re writing and opening pull requests for a project, lead by example and write the commit messages that you would want to read. Break up your commits in such a way that if you had to debug your code a year from now it would be a pleasant experience. By that same token, hold others accountable for their commits. Whether you are a maintainer or a contributor, encourage others to break up their commits to only do one thing and write informative commit messages for them. Holding others accountable for their work creates a culture of continuous improvement and makes your project, as well as the engineers who work on it, better. Then, enjoy a slice of cake!
|
||||
@@ -0,0 +1,14 @@
|
||||
---
|
||||
title: Install Git Credential Manager
|
||||
updated: 2021-03-14 22:35:24Z
|
||||
created: 2021-03-14 22:31:17Z
|
||||
tags:
|
||||
- git
|
||||
---
|
||||
|
||||
OpenSUSE:
|
||||
`zypper in git-credential-libsecret`
|
||||
|
||||
Configure Credential Manager:
|
||||
`git config --global credential.helper /usr/lib/git/git-credential-libsecret`
|
||||
|
||||
@@ -0,0 +1,24 @@
|
||||
---
|
||||
title: Installation Asciidoctor Toolchain
|
||||
updated: 2019-03-25 15:13:53Z
|
||||
created: 2019-03-25 15:10:07Z
|
||||
latitude: 51.33970000
|
||||
longitude: 12.37310000
|
||||
tags:
|
||||
- Development/Asciidoctor
|
||||
- Development/Toolchain
|
||||
- Development/Ruby/Gem
|
||||
---
|
||||
|
||||
Installation der Toolchain
|
||||
|
||||
<pre><code>
|
||||
gem install asciidoctor-diagram
|
||||
gem install prawn --version 1.3.0
|
||||
gem install addressable --version 2.4.0
|
||||
gem install prawn-svg --version 0.21.0
|
||||
gem install prawn-templates --version 0.0.3
|
||||
gem install prawn-templates --version 0.0.
|
||||
gem install asciidoctor-pdf --pre
|
||||
gem install coderay
|
||||
</code></pre>
|
||||
@@ -0,0 +1,87 @@
|
||||
---
|
||||
title: Jenkins Pipeline
|
||||
updated: 2019-02-25 07:46:07Z
|
||||
created: 2019-02-25 07:45:44Z
|
||||
tags:
|
||||
- IT
|
||||
- IT/Tools/Jenkins
|
||||
---
|
||||
|
||||
https://wilsonmar.github.io/jenkins2-pipeline/
|
||||
https://gist.github.com/bradkarels/7cff6b3e2b45eea30c21
|
||||
https://stackoverflow.com/questions/36651432/how-to-implement-post-build-stage-using-jenkins-pipeline-plug-in
|
||||
https://jenkins.io/doc/book/pipeline/syntax/#post
|
||||
https://jenkins.io/doc/pipeline/examples/#jobs-in-parallel
|
||||
https://wiki.jenkins.io/display/JENKINS/GitHub+pull+request+builder+pluginhttps://www.google.de/search?q=jenkins+github+pull+request+builder+pipeline&ie=utf-8&oe=utf-8&client=firefox-b&gfe_rd=cr&ei=z7xoWayYCaLSXqrrmEg#q=jenkins+github+pull+request+builder+webhook
|
||||
|
||||
https://gist.github.com/pcholakov/8770648
|
||||
https://github.com/akiko-pusu/redmine-build-notifier-plugin
|
||||
|
||||
https://blog.couchbase.com/deployment-pipeline-docker-jenkins-java-couchbase/
|
||||
https://db-engines.com/de/system/H2%3BSQLite
|
||||
https://stackoverflow.com/questions/38221836/how-to-manipulate-the-build-result-of-a-jenkins-pipeline-job
|
||||
https://support.cloudbees.com/hc/en-us/articles/218554077-How-to-set-current-build-result-in-Pipeline-
|
||||
https://support.cloudbees.com/hc/en-us/articles/207127338-How-to-iterate-through-the-done-build-and-rerun-only-steps-that-failed-in-Workflow
|
||||
https://stackoverflow.com/questions/37917471/jenkins-envinject-plugin-pipeline-job
|
||||
https://wiki.jenkins.io/display/JENKINS/EnvInject+Plugin#EnvInjectPlugin-Atjoblevel
|
||||
|
||||
https://stackoverflow.com/questions/36547680/how-to-do-i-get-the-output-of-a-shell-command-executed-using-into-a-variable-fro
|
||||
https://jenkins.io/doc/pipeline/steps/workflow-durable-task-step/#code-sh-code-shell-script
|
||||
https://stackoverflow.com/questions/3404936/show-which-git-tag-you-are-on
|
||||
https://stackoverflow.com/questions/41014693/get-latest-git-tag-from-the-current-commit
|
||||
https://github.com/jenkinsci/JenkinsPipelineUnit
|
||||
https://github.com/stchar/pipeline-sharedlib-testharness
|
||||
https://github.com/jenkinsci/JenkinsPipelineUnit/blob/master/src/test/groovy/com/lesfurets/jenkins/TestSharedLibraryCPS.groovy
|
||||
https://github.com/jenkinsci/JenkinsPipelineUnit/blob/master/src/test/jenkins/lib/utils.jenkins
|
||||
https://github.com/jenkinsci/JenkinsPipelineUnit/blob/master/src/test/groovy/com/lesfurets/jenkins/TestUtilsLib.groovy
|
||||
https://github.com/stchar/pipeline-sharedlib-testharness/blob/master/src/test/groovy/TestJenkinsCommonLib.groovy
|
||||
http://www.adam-bien.com/roller/abien/entry/accessing_the_current_build_user
|
||||
https://dev.to/jalogut/centralise-jenkins-pipelines-configuration-using-shared-libraries
|
||||
https://jenkins.io/doc/book/pipeline/shared-libraries/#pretesting-library-changes
|
||||
http://javadoc.jenkins-ci.org/junit/hudson/tasks/junit/package-summary.html
|
||||
https://mvnrepository.com/artifact/org.jenkins-ci.plugins/structs
|
||||
https://github.com/jenkinsci/junit-plugin/blob/master/pom.xml
|
||||
https://stackoverflow.com/questions/37257587/jenkins-groovy-lang-missingpropertyexception-no-such-property-for-class-scrip
|
||||
https://www.linux.com/blog/how-git-your-first-contribution-open-source-community
|
||||
https://github.com/jenkinsci/JenkinsPipelineUnit/issues/49
|
||||
https://github.com/jenkinsci/JenkinsPipelineUnit/issues/50
|
||||
https://github.com/jenkinsci/JenkinsPipelineUnit
|
||||
https://stackoverflow.com/questions/39920437/how-to-access-junit-test-counts-in-jenkins-pipeline-project
|
||||
https://github.com/macg33zr/pipelineUnit
|
||||
https://github.com/jenkinsci/JenkinsPipelineUnit/issues/15
|
||||
http://mrhaki.blogspot.de/2011/04/groovy-goodness-change-scope-script.html
|
||||
https://github.com/jenkinsci/JenkinsPipelineUnit/blob/master/src/main/groovy/com/lesfurets/jenkins/unit/BasePipelineTest.groovy
|
||||
https://github.com/macg33zr/pipelineUnit/blob/master/pipelineTests/groovy/testSupport/PipelineTestHelper.groovy
|
||||
https://github.com/jenkinsci/JenkinsPipelineUnit/tree/master/src/main/groovy/com/lesfurets/jenkins/unit
|
||||
https://github.com/jenkinsci/JenkinsPipelineUnit/issues/43
|
||||
https://github.com/stchar/pipeline-sharedlib-testharness
|
||||
https://stackoverflow.com/questions/45142634/mock-groovy-script-using-spock
|
||||
|
||||
https://jenkins.io/blog/2017/06/27/speaker-blog-SAS-jenkins-world/
|
||||
https://jenkins.io/doc/book/pipeline/shared-libraries/
|
||||
https://dzone.com/refcardz/continuous-delivery-with-jenkins-workflow
|
||||
https://dev.to/pencillr/jenkins-pipelines-and-their-dirty-secrets-2
|
||||
https://github.com/jenkinsci/pipeline-plugin/blob/master/TUTORIAL.md
|
||||
https://github.com/lesfurets/JenkinsPipelineUnit/blob/master/README.md
|
||||
https://jenkins.io/doc/pipeline/examples/#load-from-file
|
||||
https://jenkins.io/doc/book/pipeline/development/#replay
|
||||
https://jenkins.io/doc/pipeline/steps/workflow-scm-step/
|
||||
https://jenkins.io/doc/book/pipeline/shared-libraries/#using-libraries
|
||||
https://github.com/jenkinsci/pipeline-examples/tree/master/pipeline-examples/get-build-cause
|
||||
https://jenkins.io/doc/pipeline/examples/
|
||||
https://jenkins.io/doc/book/pipeline/getting-started/
|
||||
https://jenkins.io/doc/book/pipeline/syntax/
|
||||
https://jenkins.io/doc/book/pipeline/development/
|
||||
https://stackoverflow.com/questions/44943438/jenkins-shared-library-instantiate-util-class-and-use-in-workflowscript
|
||||
https://issues.jenkins-ci.org/browse/JENKINS-41940
|
||||
https://github.com/ansible/awx
|
||||
https://github.com/jenkinsci/pipeline-examples/blob/master/docs/BEST_PRACTICES.md
|
||||
https://github.com/Diabol/jenkins-pipeline-shared-library-template
|
||||
http://beingdevops.com/2017/08/31/steps-implement-jenkins-pipeline-code/
|
||||
https://issues.jenkins-ci.org/browse/JENKINS-35132
|
||||
https://issues.jenkins-ci.org/browse/JENKINS-37845
|
||||
https://wiki.jenkins.io/display/JENKINS/GitHub+Plugin
|
||||
https://jira.corp.ebay.com/browse/ES-6480?filter=38712
|
||||
|
||||
https://plugins.jenkins.io/script-security
|
||||
https://github.com/jenkinsci/groovy-postbuild-plugin/pull/11/files
|
||||
@@ -0,0 +1,23 @@
|
||||
---
|
||||
tags:
|
||||
- IT
|
||||
- MP4
|
||||
- VOB
|
||||
- DVD
|
||||
- VRO
|
||||
- Konvertierung
|
||||
---
|
||||
|
||||
## Dateiformat VRO
|
||||
|
||||
Verwendet von dem inzwischen entsorgten DVD-Rekorder.
|
||||
|
||||
## Konvertierung
|
||||
|
||||
```shell
|
||||
ffmpeg -i /path/to/VR_MOVIE.VRO -vcodec libx264 Video.mp4
|
||||
```
|
||||
|
||||
```shell
|
||||
ffmpeg -i "concat:VTS_01_1.VOB|VTS_02_1.VOB|VTS_03_1.VOB" -vcodec libx264 Video.mp4
|
||||
```
|
||||
@@ -0,0 +1,17 @@
|
||||
---
|
||||
tags:
|
||||
- IT
|
||||
- WMA
|
||||
- MP3
|
||||
- Konvertierung
|
||||
---
|
||||
|
||||
## Dateiformat WMA
|
||||
|
||||
*W*indows *M*edia *A*udio
|
||||
|
||||
## Konvertierung
|
||||
|
||||
```shell
|
||||
ffmpeg -i Song.wma -acodec mibmp3lame -ab 192k Song.mp3
|
||||
```
|
||||
@@ -0,0 +1,36 @@
|
||||
---
|
||||
tags:
|
||||
- IT
|
||||
- Development/Kotlin
|
||||
---
|
||||
|
||||
## Offizielle Dokumentation
|
||||
|
||||
- [IDEs for Kotlin development | Kotlin](https://kotlinlang.org/docs/kotlin-ide.html)
|
||||
- [Get started with Kotlin | Kotlin](https://kotlinlang.org/docs/getting-started.html)
|
||||
- [Kotlin command-line compiler | Kotlin](https://kotlinlang.org/docs/command-line.html)
|
||||
- [Kotlin: Ein Tutorial für Einsteiger](https://entwickler.de/programmierung/kotlin-ein-tutorial-fur-einsteiger)
|
||||
|
||||
## Quarkus
|
||||
|
||||
- [Using Kotlin - Quarkus](https://quarkus.io/guides/kotlin)
|
||||
- [Creating a Microservice With Quarkus, Kotlin, and Gradle - DZone](https://dzone.com/articles/creating-a-microservice-with-quarkus-kotlin-and-gr)
|
||||
- [Creating a Reactive CRUD todo app with Kotlin, MongoDB, Panache and Quarkus | by David | Geek Culture | Medium](https://medium.com/geekculture/building-a-reactive-crud-todo-app-with-kotlin-mongodb-panache-and-quarkus-1bcac2335e23)
|
||||
- [Guide to Quarkus with Kotlin - Piotr's TechBlog](https://piotrminkowski.com/2020/08/09/guide-to-quarkus-with-kotlin/)
|
||||
|
||||
## Weiterführende Links
|
||||
|
||||
- [Kotlin: Ein Tutorial für Einsteiger](https://entwickler.de/programmierung/kotlin-ein-tutorial-fur-einsteiger)
|
||||
- [Kotlin: Ein Tutorial für Einsteiger](https://entwickler.de/programmierung/kotlin-ein-tutorial-fur-einsteiger)
|
||||
- [Kotlin: Ein Tutorial für Einsteiger, Teil 2](https://entwickler.de/programmierung/kotlin-ein-tutorial-fur-einsteiger-teil-2/)
|
||||
- [Kotlin: Ein Tutorial für Einsteiger, Teil 3](https://entwickler.de/programmierung/kotlin-ein-tutorial-fur-einsteiger-teil-3/)
|
||||
- [Kotlin: Ein Tutorial für Einsteiger, Teil 4](https://entwickler.de/programmierung/kotlin-ein-tutorial-fur-einsteiger-teil-4/)
|
||||
- [Deine erste Android-App in Kotlin (So einfach ist es)](https://lerneprogrammieren.de/einfache-kotlin-app/)
|
||||
- [Tutorial | Building web applications with Spring Boot and Kotlin](https://spring.io/guides/tutorials/spring-boot-kotlin/)
|
||||
- [Compose Multiplatform Framework | JetBrains: Developer Tools for Professionals and Teams](https://www.jetbrains.com/lp/compose-mpp/)
|
||||
- [compose-jb/examples/issues at master · JetBrains/compose-jb](https://github.com/JetBrains/compose-jb/tree/master/examples/issues)
|
||||
- [compose-jb/examples/todoapp at master · JetBrains/compose-jb · GitHub](https://github.com/JetBrains/compose-jb/tree/master/examples/todoapp)
|
||||
- [compose-jb/tutorials/Getting_Started at master · JetBrains/compose-jb · GitHub](https://github.com/JetBrains/compose-jb/tree/master/tutorials/Getting_Started)
|
||||
- [JetBrains/compose-jb: Compose Multiplatform, a modern UI framework for Kotlin that makes building performant and beautiful user interfaces easy and
|
||||
enjoyable.](https://github.com/JetBrains/compose-jb)
|
||||
- [GitHub - techdev-solutions/janitor: keeping your pocket clean since 2016](https://github.com/techdev-solutions/janitor)
|
||||
@@ -0,0 +1,14 @@
|
||||
---
|
||||
tags:
|
||||
- IT
|
||||
- Development/LaTeX
|
||||
---
|
||||
|
||||
- [https://de.wikipedia.org/wiki/Hilfe:TeX](https://de.wikipedia.org/wiki/Hilfe:TeX)
|
||||
- [Kopf- und Fußzeile mit scrlayer-scrpage .:. goLaTeX - Mein LaTeX-Forum](https://golatex.de/kopf-und-fusszeile-mit-scrlayer-scrpage-t14339.html)
|
||||
- [Layout II: Kopf- und Fußzeilen · Tobi W_](https://tobiw.de/tbdm/layout-2)
|
||||
- [Seitenlayout — Grundkurs LaTeX 0.1.0c Dokumentation](https://www.grund-wissen.de/informatik/latex/seitenlayout.html)
|
||||
- [Set header using scrlayer-scrpage - TeX - LaTeX Stack Exchange](https://tex.stackexchange.com/questions/225250/set-header-using-scrlayer-scrpage)
|
||||
- [TeX-FAQ · Tobi W_](https://tobiw.de/tex-faq- )
|
||||
- [Titelseite mit KOMA-Script Wiki .:. goLaTeX](https://golatex.de/wiki/Titelseite_mit_KOMA-Script)
|
||||
- [LaTeX-Tutorial](https://www.kubieziel.de/computer/latex-tutorial.html)
|
||||
@@ -0,0 +1,366 @@
|
||||
---
|
||||
title: Laying out roles, inventories and playbooks – Random stuff
|
||||
updated: 2019-09-17 13:52:45Z
|
||||
created: 2019-09-17 13:52:45Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Ansible
|
||||
source: https://leucos.github.io/ansible-files-layout
|
||||
---
|
||||
|
||||
_(revised 20181110 per @theenglishway suggestions)_
|
||||
|
||||
I have been writing playbooks for quite a while now. Along the way, I went through various stages, and used different ways to layout Ansible files. I guess that after going down this trial and error path, I finally came up with something I will stick to.
|
||||
|
||||
I am not saying that this is the be-all and end-all of Ansible files layout but may be it will fast forward you to a saner file layout, and you’ll be able to move on from there. This post will probably help you if you are new to Ansible, trying to figure out what to put and where. I hope it will prove usefull if you have some Ansible experience too.
|
||||
|
||||
## Some terminology
|
||||
|
||||
In this post, I will mostly talk about 3 things: roles, inventories and playbooks. Other items do exist (plays, tasks, …) but those 3 elements shape the big picture of the layout.
|
||||
|
||||
### Roles
|
||||
|
||||
A role is a collection of tasks and templates (among other things, but those are the most common) focused on one very specific goal. For instance, you can have a role that installs nginx, another that deploys ssh keys for admins, etc…
|
||||
|
||||
Nginx role will install and configure nginx. Nothing else. It won’t create DNS entries, trim logs, add a ftp server or anything. It just installs nginx. Period.
|
||||
|
||||
### Inventories
|
||||
|
||||
An inventory is a list of hosts, eventually assembled into groups, on which you will run ansible playbooks. Ansible automatically puts all defined hosts in the aptly named group `all`.
|
||||
|
||||
For instance, you could have hosts `www1` and `www2`, assembled in group `webservers`, and later reference the group or individual hosts, depending on your needs.
|
||||
|
||||
Inventories can also come with variables applied to hosts or groups (including `all`).
|
||||
|
||||
Inventories can be dynamic. If the inventory file is executable, Ansible will run it and use its output as the inventory (note that, in this case, the format is not the same as static inventory).
|
||||
|
||||
You can of course have multiple inventories, segregated from each other. We will take advantage from this later on.
|
||||
|
||||
### Playbooks
|
||||
|
||||
The last piece of the puzzle is the playbook. The playbook is the pivot between and inventory and roles. This is where you basically tell Ansible: _please install roles foo, bar and baz on machines alice, bob and charlie_.
|
||||
|
||||
## Role layout
|
||||
|
||||
Role layout is pretty well documented at Ansible website. A role contains several directories. All directories are optional besides `tasks`. For each directory, the entry point is `main.yml`. Thus, the only compulsory file in a role is `tasks/main.yml`.
|
||||
|
||||
ansible-foobar/
|
||||
├── defaults
|
||||
│ └── main.yml
|
||||
├── files
|
||||
├── handlers
|
||||
│ └── main.yml
|
||||
├── meta
|
||||
│ └── main.yml
|
||||
├── tasks
|
||||
│ ├── check_vars.yml
|
||||
│ ├── foobar.yml
|
||||
│ └── main.yml
|
||||
└── templates
|
||||
└── foobar.conf.j2
|
||||
|
||||
|
||||
Let’s cover briefly the layout an see the function of each file and directory.
|
||||
|
||||
### `defaults/main.yml`
|
||||
|
||||
This directory contains defaults for variables used in roles. I encourage you to define every variable used in your role, for several reasons:
|
||||
|
||||
* this file will be a nice and always up to date reference list of settings configuration in your roles
|
||||
* having configured variables will prevent your role failing in an uncontrolled way (more on this later).
|
||||
|
||||
If some of these variables are used in templates to generate config files, I highly encourage you to use your target OS defaults. The principle of least surprise should apply here.
|
||||
|
||||
Best practices assumes that you are using _pseudo-namespacing_ for your role’s variables (e.g. for role `foobar`, all variables should begin with `foobar_`) to avoid collisions with other roles.
|
||||
|
||||
### `files/`
|
||||
|
||||
This directory holds files that do not require Jinja interpolation, and can be copied as-is on the remote nodes.
|
||||
|
||||
### `handlers/main.yml`
|
||||
|
||||
This is where you define handlers that get notified by tasks. Handlers are just standard tasks. You can use `include` in this file if you want to separate handlers (for different OSes versions for instances), but try to keep the file number as low as possible so you don’t end up hunting down stuff everywhere.
|
||||
|
||||
If your handler restarts any service, you have to make sure that the service config file is valid before attempting to restart it. Some daemons allow this (e.g. nginx, haproxy, apache). If your service does not, provide some fallback mechanism. You don’t want your playbook to screw up your running system because you typoed a configuration variable. See the `validate` option in the [template module](http://docs.ansible.com/template_module.html).
|
||||
|
||||
Note that handlers are just standard tasks.
|
||||
|
||||
### `meta/main.yml`
|
||||
|
||||
This metadata has (AFAIK) only two variables:
|
||||
|
||||
* `galaxy_info`: meta information for galaxy about your role. You just don’t need this if you don intend to push your role to Galaxy. For details on the format, see TODO: find ref
|
||||
* `dependencies`: what roles this role depends on.
|
||||
|
||||
The latter is of utmost importance, and setting it right deserves a blog post on it’s own. Until then, the rule of thumb to remember is to **only include compulsory role dependencies for the target host**.
|
||||
|
||||
This means that adding `nginx` dependency in a `php-fpm` role sounds perfectly reasonable[1](#fn:1). However, adding a `mysql` dependency to your web application role is not, because `mysql` can be deployed on another server.
|
||||
|
||||
**A note 3 years later**: I do not use dependencies anymore. I had issues regarding role’s defaults variables behavior. Also, the playbook is the main focus area when building infrastructure code. Having explicit dependencies in the playbook is the way to go. No weird or hard to track magic.
|
||||
|
||||
### `tasks/main.yml`
|
||||
|
||||
This file is the tasks entry point. However, it should be mostly empty. Why ? Because you want to use Ansible tags. Tags are a great way to limit task execution for an Ansible run, where only tagged tasks are run.
|
||||
|
||||
For instance, in a playbook that deploys your application, you could choose to run only tasks regarding nginx.
|
||||
|
||||
The problem is that tagging every task in `main.yml` would be cumbersome, error prone, and clutter the code unnecessarily.
|
||||
|
||||
The best way to tag all your tasks is to include your real task file from `tasks/main.yml` and tag the whole file:
|
||||
|
||||
- import_tasks: foobar.yml
|
||||
tags:
|
||||
- foobar
|
||||
|
||||
Here, I name the real task file `foobar.yml` with the same name as the role (quite handy with `find` or `locate`; no need to guess which `main.yml` you are looking for) and apply the tag `foobar` to all tasks in the role.
|
||||
|
||||
You can repeat this if you have a big list of tasks and want to split them in several files. You could, for instance, separate configuration and installation matters, and add another specific tag for each of them:
|
||||
|
||||
- import_tasks: foobar-install.yml
|
||||
tags:
|
||||
- foobar
|
||||
- foobar:install
|
||||
|
||||
- import_tasks: foobar-config.yml
|
||||
tags:
|
||||
- foobar
|
||||
- foobar:config
|
||||
|
||||
Here I added two tags to the installation part (`foobar` and `foobar:install`), and two for the configuration part (`foobar` and `foobar:config`).
|
||||
|
||||
Note that the `:` between, for instance, `foobar` and `config` has no meaning. Ansible treats tags as dumb strings. It is just a personnal convention (Redis like) for refining tags.
|
||||
|
||||
With this setup, you could run only the configuration part of your role by issuing:
|
||||
|
||||
`ansible-playbook playbook.yml -t foobar:config`
|
||||
|
||||
The `-t` and `-l` combination is a very powerful weapon to target a specific host with a precise change (think of this as pointing to a matrix cell targetting host (i.e. row) and tag (i.e. column)).
|
||||
|
||||
#### A word of caution
|
||||
|
||||
Do not overdo tags: most of the time, this is YAGNI (You Ain’t Gonna Need It). Create a tag if you’re gonna need it. It can be hard to mentally predict what will happen if you do too much. Beware of the `never` tag, that will skip tasks **unless** you explicitely use another tag.
|
||||
|
||||
For instance:
|
||||
|
||||
- import_tasks: foobar-uninstall.yml
|
||||
tags
|
||||
- never
|
||||
- foobar
|
||||
|
||||
will execute tasks in `foobar-uninstall.yml` if tag `foobar` is specified at the command line.
|
||||
|
||||
### `tasks/check_vars.yml`
|
||||
|
||||
I use this file to ensure that required variables are defined.
|
||||
|
||||
#
|
||||
# Checking that required variables are set
|
||||
#
|
||||
- name: Checking that required variables are set
|
||||
fail: msg="{{ item }} is not defined"
|
||||
when: item not in vars
|
||||
loop:
|
||||
- foobar_database
|
||||
- foobar_deploy_user
|
||||
|
||||
Then, include this file in `tasks/main.yml`:
|
||||
|
||||
- import_tasks: check_vars.yml
|
||||
tags:
|
||||
- foobar
|
||||
- foobar:check
|
||||
- check
|
||||
|
||||
- import_tasks: foobar.yml
|
||||
tags:
|
||||
- foobar
|
||||
|
||||
### `templates/*`
|
||||
|
||||
This is the place where templates (i.e. files with interpolated variables goes). While this is not necessary, I often reference them using a relative path like so:
|
||||
|
||||
- name: Template foo
|
||||
template:
|
||||
src: ../templates/foo.conf.j2
|
||||
dest: /some/place/in/the/node/filesystem/foo.conf
|
||||
|
||||
The goal of using relative path is to be able to hit `gf` in Vim and open the file directly. You can get rid of that and just use `src: foo.conf.j2`. It is just a readability/convenience tradeoff.
|
||||
|
||||
The file name I use is the **intended filename at the destination**, appended with `.j2` so it is clear that it is a Jinja2 template, and easier to search (`find` or `locate`).
|
||||
|
||||
Some folks like to replicate the destination hierarchy (e.g. `src: etc/sysconfig /network-scripts/ifcfg-ethx.cfg.j2`). This is a matter of taste, but personaly I don’t see the point of having those deep hierarchies in the role if the naming is correct.
|
||||
|
||||
### `vars/main.yml`
|
||||
|
||||
It is sometimes difficult to grok the difference between `vars/main.yml` and `defaults/main.yml`. After all, they both contain variable assignements.
|
||||
|
||||
I do not always use a `vars/main.yml`, but when I do, I put “constants like” variables in it. These are variables that are not intended to be overriden.
|
||||
|
||||
For instance the github repository for a particular piece of code (e.g. your web application) will certainly go there. However, the version you want to deploy won’t.
|
||||
|
||||
All in all, it is just a mechanism to take those values out of tasks files readability and role life cycle.
|
||||
|
||||
## Inventories and playbook layout
|
||||
|
||||
A playbook glues together roles and inventories. Thus playbooks depend on roles and inventories. But while you have mechanisms to list roles requirements in a playbook, you don’t have any for inventories.
|
||||
|
||||
Since the playbook can not live without the targeted inventories I include my inventories in my playbooks.
|
||||
|
||||
playbook-foobar/
|
||||
├── ansible.cfg
|
||||
├── requirements.txt
|
||||
├── roles/
|
||||
│ └── requirements.yml
|
||||
├── inventories
|
||||
│ ├── development
|
||||
│ | ├── group_vars
|
||||
│ | │ └── all
|
||||
│ | └── hosts
|
||||
│ ├── integration
|
||||
│ | ├── group_vars
|
||||
│ | │ └── all
|
||||
│ | └── hosts
|
||||
│ └── production
|
||||
│ ├── group_vars
|
||||
│ │ └── all
|
||||
│ └── hosts
|
||||
├── site.yml
|
||||
└── playbooks
|
||||
├── 10_database.yml
|
||||
└── 20_stuff.yml
|
||||
|
||||
|
||||
### `ansible.cfg`, `roles/` and `roles/requirements.yml`
|
||||
|
||||
This file controles ansible behaviour. You can have one in `/etc/ansible` or as a personal dotfile (`~/.ansible.cfg`). Adding an `ansible.cfg` file in the playbook root will ensure that the required settings for the playbook to run are really there. The precedence order for Ansible config files is[2](#fn:2):
|
||||
|
||||
1. `ANSIBLE_CONFIG` (an environment variable pointing to a file)
|
||||
2. `ansible.cfg` (in the current directory)
|
||||
3. `.ansible.cfg` (in the home directory)
|
||||
4. `/etc/ansible/ansible.cfg`
|
||||
|
||||
Ansible will use the first config file found.
|
||||
|
||||
In this config file, I always set at least two options:
|
||||
|
||||
hostfile = ./inventories/dev
|
||||
roles_path = ./roles:/some/path/to/roles/repos
|
||||
|
||||
The first one (`hostfile`) sets which inventory Ansible will use. More explanations will come below.
|
||||
|
||||
The second one set the path where Ansible will look for roles. I typically set two directories here (separated by `:`, like shell’s `PATH`):
|
||||
|
||||
* the first directory will be used by ansible galaxy to install imported roles. I set it to `./roles` but the name doesn’t matter. Don’t forget to add the directory content (except `requirements.yml`) in your playbook’s `.gitignore` like so:
|
||||
|
||||
!/roles
|
||||
/roles/*
|
||||
!/roles/requirements.yml
|
||||
|
||||
|
||||
* sometimes I add a second directory that points to my roles developmenent directory path
|
||||
|
||||
The advantages for this setup are two fold: first, you have a dedicated path, ignored by your SCM, where you will download roles. The roles will be searched there first. Secondly, if a role is not found, it will be searched in your role development directory. This let you hack on your roles while writing a playbook. You don’t need to go through a _commit/push/install_ cycle when you are coding your roles for this playbook.
|
||||
|
||||
Roles dependencies for your playbook are listed in `requirements.yml` and can be installed with `ansible-galaxy install -r requirements.yml`:
|
||||
|
||||
# Role on galaxy
|
||||
- you.rolename
|
||||
# Public role on github
|
||||
- name: role-public
|
||||
src: https://github.com/erasme/role-public.git
|
||||
# Private role on github
|
||||
- name: role-private
|
||||
src: git+ssh://git@github.com/you/role-private.git
|
||||
|
||||
### `inventories/`
|
||||
|
||||
This directory holds all inventories you want to apply your playbook too. The most common pattern is to use per-environment inventories: one for `development`, one for `integration`, another for `production`, etc…
|
||||
|
||||
Of course, the `hostfile` variable in `ansible.cfg` should point to `development` to avoid accidentaly messing with production. Executing the playbook on non-development inventories will force you tu use the `-i`, which is a good safety measure.
|
||||
|
||||
While you can define variables in groups (in `group_vars`) and hosts (`host_vars`), you should stuff as much variables as possible in `group_vars/all`. The rationale is that it is much easier to find a variable when a single file is involved. Variables scattered in a dozen of files are _not_ manageable.
|
||||
|
||||
And when you’ll want to create an additional inventory (e.g. create `production` from `development`), it will be much easier to change a single file and set the variables to proper values than to do the same in several files.
|
||||
|
||||
Note that `group_vars/all` can be a directory containing several files. I usually split variables in a clear text file (`group_vars/all/all`) and a ciphered one (`group_vars/all_secret`) using the transparent vaulting techniques described in [this post](https://leucos.github.io/articles/transparent-vault-revisited/).
|
||||
|
||||
**Note 3 years later**: now ansible allow you to vault a single variable in an inventory. Use it !
|
||||
|
||||
Here is a handy bash alias that crypts text selected with a mouse:
|
||||
|
||||
`alias vault_clip_crypt='echo Passing $(xclip -rmlastnl -o) to ansible-vault && echo -n "$(xclip -rmlastnl -o)" | ansible-vault encrypt_string'`
|
||||
|
||||
### `site.yml` and `playbooks/`
|
||||
|
||||
This directory contains the playbooks themselves. I always create a “master” playbook called `site.yml` in the playbook root directory, which includes all other playbooks located in `playbooks/`.
|
||||
|
||||
I prefix playbooks with a number (Basic style) so I get a sense of the order playbook will be executed just by looking at `playbooks/` content.
|
||||
|
||||
For instance:
|
||||
|
||||
#!/usr/bin/env ansible-playbook
|
||||
|
||||
- import_playbook: playbooks/10_database.yml
|
||||
- import_playbook: playbooks/20_stuff.yml
|
||||
|
||||
The rationale is to be able to use `ansible-pull` easily if needed (`ansible- pull`, by default, tries to execute a playbook called`site.yml`). The other point is to split playbook in related parts.
|
||||
|
||||
For instance, you could have a playbook the takes care of setting up the database, another that will set the OS level stuff (e.g. ssh keys, firewalling, …), another one that takes care of deploying your web application, etc… When needed, You can use all the playbooks at once with `site.yml`, or just focus on a specific problem running the appropriate playbook (no need to run the ssh-key setup if you’re just deploying the latest version of your web application).
|
||||
|
||||
The shebang line at the top of the file (`#!/usr/bin/env ansible-playbook`) will make the playbook directly executable (adjust `ansible-playbook` path and `chmod +x` the playbook file). You can still pass additional `ansible-playbook` parameters if required.
|
||||
|
||||
### `requirements.txt`
|
||||
|
||||
This file contains the result of a `pip freeze`. I now only use `pip` under `virtualenv` to install ansible and required modules. It makes it really easy to switch ansible (and even python) version between projects.
|
||||
|
||||
So when someone needs to work on this project, the workflow is simple:
|
||||
|
||||
git clone http://github.com/some/playbook-repos
|
||||
cd playbook-repos
|
||||
mkvirtualenv playbook-repos --no-site-packages
|
||||
pip install -r requirements.txt
|
||||
ansible-galaxy install -r roles/requirements.yml
|
||||
|
||||
|
||||
and you’re good to go.
|
||||
|
||||
## Layout Antipatterns
|
||||
|
||||
When I started using Ansible, I cumulated several antipatterns at the same time: trying to emcompass all my infrastructure in a single inventory containing per-host fine grained variables, used in a single playbook, without using any role.
|
||||
|
||||
While this sounds feasible, it is doomed to failure unless you manage a very small infrastructure. Let’s zoom in briefly on each mistake.
|
||||
|
||||
### Trying to encompass all your infrastructure in one playbook
|
||||
|
||||
Is is tempting to aim for a one-liner that will magically deploy all your infrastructure in one shot. This gives you some bragging rights at your next meetup, and feels like the ultimate sysadmin masterpiece.
|
||||
|
||||
However, it has many drawbacks:
|
||||
|
||||
* it will be slow: do you really want to run a playbook over dozens of more tasks or roles, just to change an entry in `/etc/hosts` ? Yes, there are workaround for this, but it will require some command line magic, a lot of thinking.
|
||||
|
||||
* it mixes bananas and apples: you should strive for separation of concerns in your playbooks if you want be able to read them (and, as a consequence, maintain them).
|
||||
|
||||
|
||||
As a consequence, your infrastructure code will be unnecessary hard to test and maintain.
|
||||
|
||||
### Per-host fine grained variables
|
||||
|
||||
This is a corolary of the previous antipattern: when you try to encompass your whole infrastructure, you start to think, inheritance, variables overriding and refining.
|
||||
|
||||
And while doing this, you add considerable complexity to your inventories. It is very hard to track down variables definitions when you overrides them in `group_vars/some_group`, `group_vars/all`, `hosts_vars/machine`, role defaults, …
|
||||
|
||||
Now this can get even worse when you use the `hash_behavior: merge` Ansible configuration setting: it introduces more confusion, and makes your Ansible work potentially unshareable with people using `hash_behaviour: replace`. Since I am [guilty](https://github.com/ansible/ansible/commit/e28e538c6ed7520ecef305c776eb6036aff42d06) on this one, it is time to make some apologies. Sorry folks. Michael DeHaan did not like it, and he was right.
|
||||
|
||||
### Single playbook
|
||||
|
||||
A single playbook relates to the first Sin again, but also applies to more focused playbooks where you only deploy one thing. Splitting your playbooks between various logically related roles will fasten your deployments. Again, why running ssh key distribution, storage cluster deployment, web stack, middlewares and application when you just change the color of a button in your web app ?
|
||||
|
||||
Split your playbook in related parts that reflects your stack architecture. They will be faster and easier to use.
|
||||
|
||||
### No roles (tasks only)
|
||||
|
||||
Well, this is obvious. Even if you don’t want to share, make roles and strive for code reuse. Reused code will save you time of course, but it is also battle tested since it is used more frequently.
|
||||
|
||||
Tasks-only playbook can be used for a quick hit and run, solving a transient problem that doesn’t offer any code reuse opportunities.
|
||||
|
||||
I also try to avoid tasks along roles in playbooks: this hurts the abstraction level you manage to build using roles. When thinking in terms of roles, you don’t need to think about the nitty gritty details of the roles when reading your playbooks. If your roles are thouroughly tested, you can read your infrastructure in seconds. Add tasks to the mix, and you loose this superpower.
|
||||
@@ -0,0 +1,20 @@
|
||||
---
|
||||
title: Löschen von Diensten unter Windows 10
|
||||
updated: 2021-05-27 07:35:00Z
|
||||
created: 2021-05-27 07:32:00Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Powershell
|
||||
- Windows-10
|
||||
---
|
||||
|
||||
Auflisten der Dienste aus der Powershell:
|
||||
```powershell
|
||||
Get-WmiObject win32_service | Select Name, Displayname, State, Startmode | Sort Name
|
||||
```
|
||||
|
||||
Entfernen der Dienste:
|
||||
Aufruf der Konsole als Administrator
|
||||
```powershell
|
||||
sc delete <SERVICENAME>
|
||||
```
|
||||
@@ -0,0 +1,23 @@
|
||||
## Installation
|
||||
|
||||
### Verwendung
|
||||
|
||||
- [Obsidian Callouts](https://help.obsidian.md/Editing+and+formatting/Callouts)
|
||||
- [Obsidian Tasks](https://obsidian-tasks-group.github.io/obsidian-tasks/)
|
||||
- [[How to Use Obsidian Dataview A Complete Beginners Guide]]
|
||||
- [[How Mermaid diagrams work in Obsidian - Ensley Tan]]
|
||||
- [Capture Information](https://help.obsidian.md/How+to/Capture+information)
|
||||
- [[A Beginner’s Guide to Creating a Medium Knowledge Base in Obsidian]]
|
||||
- [[Definitive Obsidian Markdown Cheatsheet Complete Syntax Reference]]
|
||||
|
||||
|
||||
### Plugins
|
||||
|
||||
- [Obsidian Admonition](https://github.com/valentine195/obsidian-admonition)
|
||||
- [[The Must-Have Obsidian plugins Personal Knowledge Journal]]
|
||||
- [Dataview task and project examples](https://forum.obsidian.md/t/dataview-task-and-project-examples/17011)
|
||||
- [Obsidian Dataview Tasks.md](https://gist.github.com/dom8509/50a1ae4a8adf01c1f70dc68ce3657195)
|
||||
- [Obsidian Tasks](https://obsidian-tasks-group.github.io/obsidian-tasks/)
|
||||
- [Obsidian Dataview](https://notes.nicolevanderhoeven.com/Obsidian+Dataview)
|
||||
- [Obsidian Task Management Queries](https://thesweetsetup.com/obsidian-task-management-queries/)
|
||||
- [My Obsidian Setup (Part 2)](https://medium.com/technology-hits/my-obsidian-setup-part-2-1b82050fac0f)
|
||||
@@ -0,0 +1,275 @@
|
||||
---
|
||||
title: Processing Files In Place With Groovy | Mindful Mischief
|
||||
updated: 2019-02-26 13:43:38Z
|
||||
created: 2019-02-26 13:37:04Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Groovy
|
||||
---
|
||||
|
||||
I recently had the need to process a bunch of files and directory structures that were emitted from a generation process that I didn’t have control over. The basic needs were to delete some files, delete some directories, and to modify selected content of some of the files. This is a very straight forward, trivial thing to do but I was looking for a solution that was both cross platform and very quick to develop. I also had to deal with a bit of XML and wanted an easy way to parse and modify XML documents in a natural way. This post shows how to do this using a Groovy script. I’ve been using Groovy for testing of Java code and other one off random tasks for a couple years now but it still surprises me how fast you can accomplish certain tasks yet keep your code readable and at a relatively high level of abstraction, especially compared to shell scripts, sed, awk.
|
||||
|
||||
In a nutshell, the following method will process a file in place.
|
||||
|
||||
```groovy
|
||||
def processFileInplace(file, Closure processText) {
|
||||
def text = file.text
|
||||
file.write(processText(text))}
|
||||
```
|
||||
|
||||
If you know Groovy, this probably doesn’t require any additional explanation. But if you don’t know Groovy, don’t worry. The remainder of this post shows examples of using this method and touches on a few details regarding file and directory deletion.
|
||||
|
||||
# Deleting Files and Directories
|
||||
|
||||
I hesitated even writing anything about deleting files and recursively deleting directory structures because it is so trivial and the Groovy documentation on Files has a huge number of examples. But that being said, I wanted the script to read as cleanly a possible for people maintaining it in the future that might not know Groovy. There are a couple of ways to recursively delete directories and the syntax isn’t consistent with how you delete a File. So I simply created two methods encapsulate these operations an make it read cleaner.
|
||||
|
||||
```groovy
|
||||
def deleteDirectory(directory){
|
||||
new AntBuilder().delete(dir: directory)}
|
||||
|
||||
def deleteFile(file){
|
||||
file.delete()}
|
||||
```
|
||||
|
||||
Another, more Groovy-like (i.e. uses closures) option for recursively deleting directories is shown here.
|
||||
|
||||
Using those methods, file and directory deletion is consistent and clean.
|
||||
|
||||
```groovy
|
||||
basedir = ...
|
||||
|
||||
deleteDirectory(new File(basedir + ".settings"))
|
||||
deleteFile(new File(basedir + ".project"))
|
||||
deleteFile(new File(basedir + ".classpath"))
|
||||
```
|
||||
|
||||
# Processing Text Files In Place
|
||||
|
||||
Processing text files in place can be done with a simple method that takes the file to be modified and a closure that performs the modifications. This is the method I introduced above.
|
||||
|
||||
```groovy
|
||||
def processFileInplace(file, Closure processText) {
|
||||
def text = file.text
|
||||
file.write(processText(text))}
|
||||
```
|
||||
|
||||
The closure can be arbitrarily complex as long as it returns the String value of what you want the file contents to look like after modification. For example, you can use any of the basic Java or the expanded Groovy string methods and utilities.
|
||||
|
||||
```groovy
|
||||
projectName = 'My New Project'
|
||||
overview = new File(basedir + "overview.txt")
|
||||
processFileInplace(overview) { text ->
|
||||
text.replaceAll(/The Old Project/, '\\${projectName}')}
|
||||
```
|
||||
|
||||
You are by no means limited to a single operation within the closure.
|
||||
|
||||
```groovy
|
||||
projectName = 'My New Project'def today = Calendar.getInstance()def todayFormatted = String.format('%tY/%<tm/%<td', today)
|
||||
|
||||
howTo = new File(basedir + "how-to.txt")
|
||||
processFileInplace(howTo) { text ->
|
||||
text = text.replaceAll(/The Old Project/, '\\${projectName}')
|
||||
text = text.replace(/<name>Legacy System 1982<\/name>/, '<name>New and Improved</name>')
|
||||
text.replace(/<date>1982/10/12<\/date>/, '<date>${todayFormatted}</date>')}
|
||||
```
|
||||
|
||||
# Bring on XML
|
||||
|
||||
Unfortunately, XML can often be much more difficult to deal with than it should be. Groovy has some great utilities for simplifying XML processing. Details on these utilities can be found on the Groovy web site. I’ll combine a couple of these in the following examples.
|
||||
|
||||
## Example XML Document
|
||||
|
||||
Below is an XML document that will be used in the examples.
|
||||
|
||||
```xml
|
||||
<?xml version="1.0" encoding="UTF-8"?><CustomerManagement>
|
||||
<MetaData>
|
||||
</MetaData>
|
||||
<Customers>
|
||||
<Customer name="Kermit The Frog">
|
||||
<HelpDeskCalls>
|
||||
<Call Id="1">
|
||||
<Status Id="In Progress"/>
|
||||
</Call>
|
||||
<Call Id="2">
|
||||
<Status Id="Completed"/>
|
||||
</Call>
|
||||
<Call Id="3">
|
||||
<Status Id="UnableToResolve"/>
|
||||
</Call>
|
||||
</HelpDeskCalls>
|
||||
</Customer>
|
||||
<Customer name="Fozzie Bear">
|
||||
<HelpDeskCalls>
|
||||
<Call Id="5">
|
||||
<Status Id="Completed"/>
|
||||
</Call>
|
||||
</HelpDeskCalls>
|
||||
</Customer>
|
||||
</Customers></CustomerManagement>
|
||||
```
|
||||
|
||||
## Removing Content From XML
|
||||
|
||||
Given the example XML document, say we wanted to remove all the HelpDeskCalls for Kermit the Frog where the Status is “UnableToResolve.”
|
||||
|
||||
```groovy
|
||||
customers = new File(basedir + "important-customers.xml")
|
||||
processFileInplace(customers) { text ->
|
||||
customerManagement = new XmlSlurper().parseText(text)
|
||||
customer = customerManagement.Customer.Customer.find{ it.@name.text().contains('Kermit') }
|
||||
customer.HelpDeskCalls.Call.findAll{ it.Status.@Id.text().equals('UnableToResolve')}.replaceNode{}
|
||||
serializeXml(customerManagement)}
|
||||
```
|
||||
|
||||
So what are each of the lines in the closure doing?
|
||||
|
||||
1. Parses the text in the file using an XmlSlurper
|
||||
2. Finds all Customers whose names contain Kermit.
|
||||
3. Removes Call elements from Kermit where the Status of the Call is equal to UnableToResolve.
|
||||
4. Calls a method that serializes the XML as a string.
|
||||
|
||||
The second and third lines are using GPath to query the XML. GPath provides a consistent expression language over both Groovy/Java POJO’s and XML. The serialzeXML() method is a short, custom method to turn the GPathResult created by the XmlSlurper back into a String. This method requires that you import a few
|
||||
|
||||
```groovy
|
||||
import groovy.xml.XmlUtilimport groovy.xml.StreamingMarkupBuilderimport groovy.util.slurpersupport.GPathResult
|
||||
|
||||
// ...
|
||||
|
||||
def String serializeXml(GPathResult xml){
|
||||
XmlUtil.serialize(new StreamingMarkupBuilder().bind {
|
||||
mkp.yield xml
|
||||
} )}
|
||||
```
|
||||
|
||||
Refer to the link above on Groovy XML Processing for more details on this. It uses StreamingMarkupBuilder and XmlUtils to turn the XML back into a String.
|
||||
|
||||
## Adding Content To XML
|
||||
|
||||
Say you wanted to add some CustomerManagers to the MetaData section of our example XML file. You can do that again using the XmlSlurper and our processFileInPlace method.
|
||||
|
||||
```groovy
|
||||
customers = new File(basedir + "important-customers.xml")
|
||||
processFileInplace(customers) { text ->
|
||||
customerManagement = new XmlSlurper().parseText(text)
|
||||
customerManagement.MetaData.appendNode{
|
||||
CustomerManagers{
|
||||
Manager(Name: "Animal")
|
||||
Manager(Name: "Swedish Chef")
|
||||
Manager(Name: "Gonzo")
|
||||
}
|
||||
}
|
||||
serializeXml(customerManagement)}
|
||||
```
|
||||
|
||||
The above results in the important-customers.xml file now containing
|
||||
|
||||
```xml
|
||||
<?xml version="1.0" encoding="UTF-8"?><CustomerManagement>
|
||||
<MetaData>
|
||||
<CustomerManagers>
|
||||
<Manager Name="Animal"/>
|
||||
<Manager Name="Swedish Chef"/>
|
||||
<Manager Name="Gonzo"/>
|
||||
</CustomerManagers>
|
||||
</MetaData>
|
||||
<Customers>
|
||||
<Customer name="Kermit The Frog">
|
||||
<HelpDeskCalls>
|
||||
<Call Id="1">
|
||||
<Status Id="In Progress"/>
|
||||
</Call>
|
||||
<Call Id="2">
|
||||
<Status Id="Completed"/>
|
||||
</Call>
|
||||
<Call Id="3">
|
||||
<Status Id="UnableToResolve"/>
|
||||
</Call>
|
||||
</HelpDeskCalls>
|
||||
</Customer>
|
||||
<Customer name="John Doe">
|
||||
<HelpDeskCalls>
|
||||
<Call Id="5">
|
||||
<Status Id="Completed"/>
|
||||
</Call>
|
||||
</HelpDeskCalls>
|
||||
</Customer>
|
||||
</Customers></CustomerManagement>
|
||||
```
|
||||
|
||||
# A Full Example
|
||||
|
||||
The above examples can be combined into a full script. Obviously you can structure this to your needs. The script can be executed directly from the command line.
|
||||
|
||||
```shell
|
||||
./processFiles.groovy
|
||||
```
|
||||
|
||||
```groovy
|
||||
#!/usr/bin/env groovy
|
||||
|
||||
import groovy.xml.XmlUtilimport groovy.xml.StreamingMarkupBuilderimport groovy.util.slurpersupport.GPathResult
|
||||
|
||||
if(args.length < 1){
|
||||
println "You must provide a base directory as an argument to the script."
|
||||
System.exit(1)}
|
||||
|
||||
basedir = args[0] + "/"println "Current working path: " + new File(".").getAbsolutePath()
|
||||
|
||||
def processFileInplace(file, Closure processText) {
|
||||
def text = file.text
|
||||
file.write(processText(text))}
|
||||
|
||||
def deleteDirectory(directory){
|
||||
new AntBuilder().delete(dir: directory)}
|
||||
|
||||
def deleteFile(file){
|
||||
file.delete()}
|
||||
|
||||
def String serializeXml(GPathResult xml){
|
||||
XmlUtil.serialize(new StreamingMarkupBuilder().bind {
|
||||
mkp.yield xml
|
||||
} )}
|
||||
|
||||
projectName = 'My New Project'def today = Calendar.getInstance()def todayFormatted = String.format('%tY/%<tm/%<td', today)
|
||||
|
||||
deleteDirectory(new File(basedir + ".settings"))
|
||||
deleteFile(new File(basedir + ".project"))
|
||||
deleteFile(new File(basedir + ".classpath"))
|
||||
|
||||
overview = new File(basedir + "overview.txt")
|
||||
processFileInplace(overview) { text ->
|
||||
text.replaceAll(/The Old Project/, '\\${projectName}')}
|
||||
|
||||
howTo = new File(basedir + "how-to.txt")
|
||||
processFileInplace(howTo) { text ->
|
||||
text = text.replaceAll(/The Old Project/, '\\${projectName}')
|
||||
text = text.replace(/<name>Legacy System 1982<\/name>/, '<name>New and Improved</name>')
|
||||
text.replace(/<date>1982/10/12<\/date>/, '<date>${todayFormatted}</date>')}
|
||||
|
||||
// Delete anything that makes our call center people look bad :-0
|
||||
customers = new File(basedir + "important-customers.xml")
|
||||
processFileInplace(customers) { text ->
|
||||
customerManagement = new XmlSlurper().parseText(text)
|
||||
customer = customerManagement.Customer.Customer.find{ it.@name.text().contains('Kermit') }
|
||||
customer.HelpDeskCalls.Call.findAll{ it.Status.@Id.text().equals('UnableToResolve')}.replaceNode{}
|
||||
serializeXml(customerManagement)}
|
||||
|
||||
// Add information on the CustomerManagers
|
||||
customers = new File(basedir + "important-customers.xml")
|
||||
processFileInplace(customers) { text ->
|
||||
customerManagement = new XmlSlurper().parseText(text)
|
||||
customerManagement.MetaData.appendNode{
|
||||
CustomerManagers{
|
||||
Manager(Name: "Animal")
|
||||
Manager(Name: "Swedish Chef")
|
||||
Manager(Name: "Gonzo")
|
||||
}
|
||||
}
|
||||
serializeXml(customerManagement)}
|
||||
```
|
||||
|
||||
# Conclusion
|
||||
|
||||
Processing files in place using Groovy is both easy and powerful. A single two-line method provides the basis for modifying the content of a file in any way you may need.
|
||||
@@ -0,0 +1,66 @@
|
||||
---
|
||||
title: Publishing Credentials Sample
|
||||
updated: 2022-09-14 11:09:41Z
|
||||
created: 2022-09-14 11:09:41Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Gradle
|
||||
- Development/Maven
|
||||
source: https://docs.gradle.org/current/samples/sample_publishing_credentials.html
|
||||
---
|
||||
|
||||
- [Groovy DSL](https://docs.gradle.org/current/samples/zips/sample_publishing_credentials-groovy-dsl.zip)
|
||||
- [Kotlin DSL](https://docs.gradle.org/current/samples/zips/sample_publishing_credentials-kotlin-dsl.zip)
|
||||
|
||||
This sample shows how credentials can be used when publishing artifacts to a Maven repository using [project properties](https://docs.gradle.org/current/userguide/build_environment.html#sec:project_properties). This approach allows you to keep sensitive configuration out of your project’s source code and inject it only when needed.
|
||||
|
||||
The code in the `maven-repository-stub` directory builds a plugin used to stub the Maven repository in order to demonstrate the authentication flow. It expects the following hardcoded credentials on the server stub:
|
||||
|
||||
In a real project, your build would point to a private repository for your organization.
|
||||
|
||||
The published project has some sample Java code to be compiled and distributed as a Java library. Gradle build file registers a publication to a Maven repository using provided credentials:
|
||||
|
||||
build.gradle
|
||||
```groovy
|
||||
publishing {
|
||||
publications {
|
||||
library(MavenPublication) {
|
||||
from components.java
|
||||
}
|
||||
}
|
||||
repositories {
|
||||
maven {
|
||||
name = 'mySecureRepository'
|
||||
credentials(PasswordCredentials)
|
||||
// url = uri(<<some repository url>>)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Credentials will be required by the build only if the task requiring them is to be executed - in this case the task publishing to the secure repository. This allows to build the project without worrying about the credentials. Try running `./gradlew jar` and it will succeed. Run `./gradlew publish` and it will tell you what is missing right away, without executing the build. Credentials can and should be kept externally from the project sources and be known only by those having to publish artifacts, perhaps injected by a CI server.
|
||||
|
||||
Credential values are provided using Gradle properties and can be passed to the publish task in multiple ways:
|
||||
|
||||
- via command-line properties:
|
||||
|
||||
```shell
|
||||
$ ./gradlew publish -PmySecureRepositoryUsername=secret-user -PmySecureRepositoryPassword=secret-password
|
||||
```
|
||||
|
||||
- via environment variables:
|
||||
|
||||
```shell
|
||||
$ ORG\_GRADLE\_PROJECT\_mySecureRepositoryUsername=secret-user ORG\_GRADLE\_PROJECT\_mySecureRepositoryPassword=secret-password ./gradlew publish
|
||||
```
|
||||
|
||||
- by setting the properties in `gradle.properties` file:
|
||||
|
||||
```properties
|
||||
mySecureRepositoryUsername=secret-user
|
||||
mySecureRepositoryPassword=secret-password
|
||||
```
|
||||
|
||||
and running
|
||||
|
||||
The sensitive data is kept outside of the project sources since the `gradle.properties` file can reside in the user’s `~/.gradle` directory.
|
||||
@@ -0,0 +1,19 @@
|
||||
---
|
||||
tags:
|
||||
- IT
|
||||
- Quarkus
|
||||
- Development/REST
|
||||
---
|
||||
|
||||
- [Datasources - Quarkus](https://quarkus.io/guides/datasource)
|
||||
- [Get Started - Quarkus](https://quarkus.io/get-started/)
|
||||
- [Guide to Quarkus with Kotlin - Piotr's TechBlog](https://piotrminkowski.com/2020/08/09/guide-to-quarkus-with-kotlin/)
|
||||
- [RESTful Webservices mit Quarkus](https://blog.codecentric.de/restful-webservices-mit-quarkus)
|
||||
- [Quarkus - Hello world example using Kotlin!](https://techwasti.com/quarkus-hello-world-example-using-kotlin)
|
||||
- [SmallRye Health - Quarkus](https://quarkus.io/guides/smallrye-health)
|
||||
- [Using OpenAPI and Swagger UI - Quarkus](https://quarkus.io/guides/openapi-swaggerui)
|
||||
- [Simplified Hibernate ORM with Panache - Quarkus](https://quarkus.io/guides/hibernate-orm-panache)
|
||||
- [Simplified Hibernate ORM with Panache and Kotlin - Quarkus](https://quarkus.io/guides/hibernate-orm-panache-kotlin)
|
||||
- [Testing Quarkus with Kotlin, JUnit and MockK | Novatec - Novatec](https://www.novatec-gmbh.de/en/blog/testing-quarkus-with-kotlin-junit-and-mockk/)
|
||||
- [piomin/sample-quarkus-applications: Example application built using Quarkus framework](https://github.com/piomin/sample-quarkus-applications)
|
||||
- [quarkus-quickstarts/Fruit.kt at main · quarkusio/quarkus-quickstarts](https://github.com/quarkusio/quarkus-quickstarts/blob/main/hibernate-orm-panache-kotlin-quickstart/src/main/kotlin/org/acme/hibernate/orm/panache/Fruit.kt)
|
||||
@@ -0,0 +1,166 @@
|
||||
---
|
||||
title: Service - OpenSSH | Ubuntu
|
||||
updated: 2022-01-06 10:46:40Z
|
||||
created: 2022-01-06 10:46:20Z
|
||||
tags:
|
||||
- IT
|
||||
- IT/SSH
|
||||
- IT/Linux/Ubuntu
|
||||
source: https://ubuntu.com/server/docs/service-openssh
|
||||
---
|
||||
|
||||
## [OpenSSH Server](https://ubuntu.com/server/docs/service-openssh)
|
||||
|
||||
## Introduction
|
||||
|
||||
OpenSSH is a powerful collection of tools for the remote control of, and transfer of data between, networked computers. You will also learn about some of the configuration settings possible with the OpenSSH server application and how to change them on your Ubuntu system.
|
||||
|
||||
OpenSSH is a freely available version of the Secure Shell (SSH) protocol family of tools for remotely controlling, or transferring files between, computers. Traditional tools used to accomplish these functions, such as telnet or rcp, are insecure and transmit the user’s password in cleartext when used. OpenSSH provides a server daemon and client tools to facilitate secure, encrypted remote control and file transfer operations, effectively replacing the legacy tools.
|
||||
|
||||
The OpenSSH server component, sshd, listens continuously for client connections from any of the client tools. When a connection request occurs, sshd sets up the correct connection depending on the type of client tool connecting. For example, if the remote computer is connecting with the ssh client application, the OpenSSH server sets up a remote control session after authentication. If a remote user connects to an OpenSSH server with scp, the OpenSSH server daemon initiates a secure copy of files between the server and client after authentication. OpenSSH can use many authentication methods, including plain password, public key, and Kerberos tickets.
|
||||
|
||||
## Installation
|
||||
|
||||
Installation of the OpenSSH client and server applications is simple. To install the OpenSSH client applications on your Ubuntu system, use this command at a terminal prompt:
|
||||
|
||||
```
|
||||
sudo apt install openssh-client
|
||||
```
|
||||
|
||||
To install the OpenSSH server application, and related support files, use this command at a terminal prompt:
|
||||
|
||||
```
|
||||
sudo apt install openssh-server
|
||||
```
|
||||
|
||||
## Configuration
|
||||
|
||||
You may configure the default behavior of the OpenSSH server application, sshd, by editing the file `/etc/ssh/sshd_config`. For information about the configuration directives used in this file, you may view the appropriate manual page with the following command, issued at a terminal prompt:
|
||||
|
||||
```
|
||||
man sshd_config
|
||||
```
|
||||
|
||||
There are many directives in the sshd configuration file controlling such things as communication settings, and authentication modes. The following are examples of configuration directives that can be changed by editing the `/etc/ssh/sshd_config` file.
|
||||
|
||||
> **Tip**
|
||||
>
|
||||
> Prior to editing the configuration file, you should make a copy of the original file and protect it from writing so you will have the original settings as a reference and to reuse as necessary.
|
||||
>
|
||||
> Copy the `/etc/ssh/sshd_config` file and protect it from writing with the following commands, issued at a terminal prompt:
|
||||
>
|
||||
> ```
|
||||
> sudo cp /etc/ssh/sshd_config /etc/ssh/sshd_config.original
|
||||
> sudo chmod a-w /etc/ssh/sshd_config.original
|
||||
> ```
|
||||
|
||||
Furthermore since losing an ssh server might mean losing your way to reach a server, check the configuration after changing it and before restarting the server:
|
||||
|
||||
```
|
||||
sudo sshd -t -f /etc/ssh/sshd_config
|
||||
```
|
||||
|
||||
The following are *examples* of configuration directives you may change:
|
||||
|
||||
- To set your OpenSSH to listen on TCP port 2222 instead of the default TCP port 22, change the Port directive as such:
|
||||
|
||||
> Port 2222
|
||||
|
||||
- To make your OpenSSH server display the contents of the `/etc/issue.net` file as a pre-login banner, simply add or modify this line in the `/etc/ssh/sshd_config` file:
|
||||
|
||||
> Banner /etc/issue.net
|
||||
|
||||
After making changes to the `/etc/ssh/sshd_config` file, save the file, and restart the sshd server application to effect the changes using the following command at a terminal prompt:
|
||||
|
||||
```
|
||||
sudo systemctl restart sshd.service
|
||||
```
|
||||
|
||||
> **Warning**
|
||||
>
|
||||
> Many other configuration directives for sshd are available to change the server application’s behavior to fit your needs. Be advised, however, if your only method of access to a server is ssh, and you make a mistake in configuring sshd via the `/etc/ssh/sshd_config` file, you may find you are locked out of the server upon restarting it. Additionally, if an incorrect configuration directive is supplied, the sshd server may refuse to start, so be extra careful when editing this file on a remote server.
|
||||
|
||||
## SSH Keys
|
||||
|
||||
SSH allow authentication between two hosts without the need of a password. SSH key authentication uses a *private key* and a *public key*.
|
||||
|
||||
To generate the keys, from a terminal prompt enter:
|
||||
|
||||
```
|
||||
ssh-keygen -t rsa
|
||||
```
|
||||
|
||||
This will generate the keys using the *RSA Algorithm*. At the time of this writing, the generated keys will have 3072 bits. You can modify the number of bits by using the `-b` option. For example, to generate keys with 4096 bits, you can do:
|
||||
|
||||
```
|
||||
ssh-keygen -t rsa -b 4096
|
||||
```
|
||||
|
||||
During the process you will be prompted for a password. Simply hit *Enter* when prompted to create the key.
|
||||
|
||||
By default the *public* key is saved in the file `~/.ssh/id_rsa.pub`, while `~/.ssh/id_rsa` is the *private* key. Now copy the `id_rsa.pub` file to the remote host and append it to `~/.ssh/authorized_keys` by entering:
|
||||
|
||||
```
|
||||
ssh-copy-id username@remotehost
|
||||
```
|
||||
|
||||
Finally, double check the permissions on the `authorized_keys` file, only the authenticated user should have read and write permissions. If the permissions are not correct change them by:
|
||||
|
||||
```
|
||||
chmod 600 .ssh/authorized_keys
|
||||
```
|
||||
|
||||
You should now be able to SSH to the host without being prompted for a password.
|
||||
|
||||
## Import keys from public keyservers
|
||||
|
||||
These days many users have already ssh keys registered with services like launchpad or github. Those can be easily imported with:
|
||||
|
||||
```
|
||||
ssh-import-id <username-on-remote-service>
|
||||
```
|
||||
|
||||
The prefix `lp:` is implied and means fetching from launchpad, the alternative `gh:` will make the tool fetch from github instead.
|
||||
|
||||
## Two factor authentication with U2F/FIDO
|
||||
|
||||
OpenSSH 8.2 [added support for U2F/FIDO hardware authentication devices](https://www.openssh.com/txt/release-8.2). These devices are used to provide an extra layer of security on top of the existing key-based authentication, as the hardware token needs to be present to finish the authentication.
|
||||
|
||||
It’s very simple to use and setup. The only extra step is generate a new keypair that can be used with the hardware device. For that, there are two key types that can be used: `ecdsa-sk` and `ed25519-sk`. The former has broader hardware support, while the latter might need a more recent device.
|
||||
|
||||
Once the keypair is generated, it can be used as you would normally use any other type of key in openssh. The only requirement is that in order to use the private key, the U2F device has to be present on the host.
|
||||
|
||||
For example, plug the U2F device in and generate a keypair to use with it:
|
||||
|
||||
```
|
||||
$ ssh-keygen -t ecdsa-sk
|
||||
Generating public/private ecdsa-sk key pair.
|
||||
You may need to touch your authenticator to authorize key generation. <-- touch device
|
||||
Enter file in which to save the key (/home/ubuntu/.ssh/id_ecdsa_sk):
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in /home/ubuntu/.ssh/id_ecdsa_sk
|
||||
Your public key has been saved in /home/ubuntu/.ssh/id_ecdsa_sk.pub
|
||||
The key fingerprint is:
|
||||
SHA256:V9PQ1MqaU8FODXdHqDiH9Mxb8XK3o5aVYDQLVl9IFRo ubuntu@focal
|
||||
```
|
||||
|
||||
Now just transfer the public part to the server to `~/.ssh/authorized_keys` and you are ready to go:
|
||||
|
||||
```
|
||||
$ ssh -i .ssh/id_ecdsa_sk ubuntu@focal.server
|
||||
Confirm user presence for key ECDSA-SK SHA256:V9PQ1MqaU8FODXdHqDiH9Mxb8XK3o5aVYDQLVl9IFRo <-- touch device
|
||||
Welcome to Ubuntu Focal Fossa (GNU/Linux 5.4.0-21-generic x86_64)
|
||||
(...)
|
||||
ubuntu@focal.server:~$
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
- [Ubuntu Wiki SSH](https://help.ubuntu.com/community/SSH) page.
|
||||
|
||||
- [OpenSSH Website](http://www.openssh.org/)
|
||||
|
||||
- [OpenSSH 8.2 release notes](https://www.openssh.com/txt/release-8.2)
|
||||
|
||||
- [Advanced OpenSSH Wiki Page](https://wiki.ubuntu.com/AdvancedOpenSSH)
|
||||
@@ -0,0 +1,242 @@
|
||||
---
|
||||
title: Setting up Sonarqube with Ansible - Matt v.d. Westhuizen
|
||||
updated: 2019-09-09 15:03:11Z
|
||||
created: 2019-09-09 15:03:11Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Ansible
|
||||
- Sonarqube
|
||||
source: https://medium.com/@mattpwest/setting-up-sonarqube-with-ansible-fcabadee6953
|
||||
---
|
||||
|
||||
[](https://medium.com/@mattpwest?source=post_page-----fcabadee6953----------------------)
|
||||
|
||||
Early last year (2017) I was embarking on a new project for a client and was setting up code quality measurements with [Sonarqube](https://www.sonarqube.org/) when I noticed that our Sonarqube server at work was a bit out of date.
|
||||
|
||||
We were running 5.1 which at the time was about 2 years old. It seemed it had been setup a few years ago by an employee that had since left the company and no-one really had enough of an idea of what was going on there to make an upgrade viable.
|
||||
|
||||
Fortunately the contract with the client required setting up build infrastructure for them in their environment, so we were able to spin up a Sonarqube server on their infrastructure to use for the project, but I still wanted to upgrade or replace the old server for the next project and for all other teams to use. Unfortunately the project I was on got a bit crazy plus the way we set it up for the client used a Docker instance, which wasn’t quite the approach we wanted to take with our server.
|
||||
|
||||
The result is that I’m only revisiting this side-project now a full year later. My requirements are simple:
|
||||
|
||||
* Sonarqube 7.1
|
||||
* Ubuntu Server 18.04 (latest LTS)
|
||||
* [Infrastructure as code](https://en.wikipedia.org/wiki/Infrastructure_as_Code) approach to ensure the new server will be maintainable for years to come
|
||||
|
||||
Here’s a diagram that shows what we’ll be building:
|
||||
|
||||

|
||||
|
||||
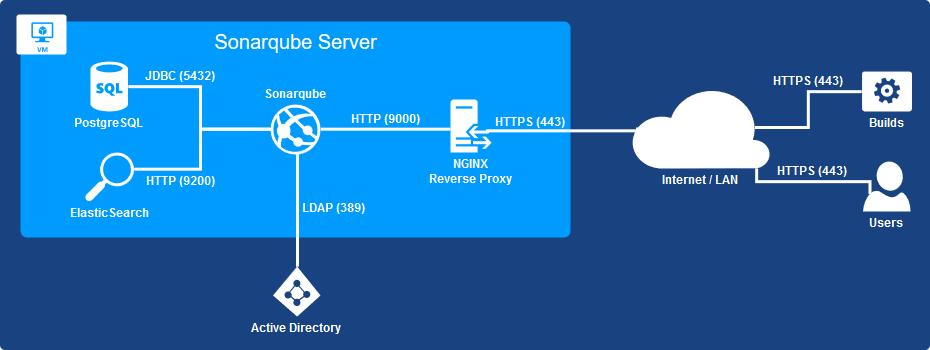
|
||||
|
||||
My day job as software engineer only occasionally allows me to play with infrastructure, so my toolbox is limited to what I’ve been exposed in my 12 years of working to or have had time to learn on my own:
|
||||
|
||||
* **Linux:** 15+ years of experience, mostly Debian flavours
|
||||
* **Docker:** 2+ years of experience, not a master, but I haven’t yet run into any problems I couldn’t surmount.
|
||||
* **Ansible:** 1+ years of experience, again not a master, but I’ve been able to solve most problems I’ve run across.
|
||||
|
||||
If I only used Linux I would probably have stopped at Docker and Docker Compose and called it good enough, but unfortunately I tend to spend a lot of time in Windows between projects requiring SQL Server databases and project administration. SQL Server is less of a problem now that that’s [available on Linux as a Docker image](https://docs.microsoft.com/en-us/sql/linux/quickstart-install-connect-docker?view=sql-server-linux-2017), but Linux is still not officially supported by the IT department at work, so unless I want to spend my weekends fiddling with Linux I have to use Windows at work.
|
||||
|
||||
While Docker in theory has Windows support, I ran into a brick wall last time I tried to use it, with a long-standing showstopper bug that prevented me from just using Docker... I ended up with a Vagrant virtual machine running Ubuntu and running Docker in there to get around it. At first this was very annoying…
|
||||
|
||||
Eventually I realised that this is a crucial aspect of maintainable infrastructure as code… With normal software development projects one of the first things we consider when setting up our project is how people on the team will run it locally for doing development — something which is often overlooked with infrastructure projects.
|
||||
|
||||
Someone will set up a new server by hand and everything will be awesome for 6–12 months, when someone else decides they want to upgrade the server to the latest version of the software, but then can’t because there’s no development environment where they can test their changes.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
> **Principle 1:** **Testability** is the key to **maintainability**. For an infrastructure project this means Vagrant VMs that imitate the target environment as closely as possible to allow testing of changes without risking production data or stability.
|
||||
|
||||
Putting the issues of running Docker on anything other than Linux aside, it’s an awesome tool! Docker Hub has an image for just about anything you can imagine and I’ve been able to leverage this many times to get new bits of infrastructure up and running quickly so we could try them out.
|
||||
|
||||
However once you enter an enterprise context a few cracks begin to appear. On my last project the client required us to use SuSE Enterprise Linux, which isn’t supported by the open-source version of Docker, so we had to get an expensive license. On top of that client infrastructure teams rarely have experience with Docker, so servers don’t have Docker installed in the first place leaving you with some manual setup to do before you can deploy. Alternatively you can automate this step with Ansible, but then you probably just end up with two things that the client infrastructure team don’t understand.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
> **Principle 2:** **KISS**. Keep it simple stupid. Try not to use all the things if you can avoid it. Use Docker **or** Ansible - not both.
|
||||
|
||||
Docker is awesome for putting everything you need to run your application into nice little package that you can distribute to your servers, but what if those servers don’t have Docker and Docker Compose already installed for you? Do you manually install them on all of the servers that make up DEV, QA and PROD?
|
||||
|
||||
How do you handle other tasks that crop up from time to time like changing configuration across all your servers, showing a down for maintenance page during deployments or backing up the database before a deployment?
|
||||
|
||||
Here my answer is to use an automated provisioning and deployment tool like Ansible. I am biased towards preferring Ansible, because of my love of Linux and thanks to its light-weight nature — Ansible simply uses SSH to connect to your servers and run commands, whereas Puppet and Chef require you to install an agent on the server before they can be managed.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
> **Principle 3: Automate all the things!** Don’t become the key person dependency on your team — automate everything to empower your team to help themselves.
|
||||
|
||||
With those 3 principles in mind let’s move on to setting up our Sonarqube server. There will be roughly 2 steps:
|
||||
|
||||
1. Create a `Vagrantfile` to provide a local test environment.
|
||||
2. Create an Ansible play to set up the target VM with PostgreSQL and Sonarqube (using the [official Docker image](https://hub.docker.com/_/sonarqube/) would be much less work, but it means maintainers would need to know Docker as well, so it violates the KISS principle in that sense).
|
||||
|
||||
Throughout the remainder of this article I’ll be referring to code examples from the [GitHub repository](https://github.com/entelect/sonarqube-server) I created for this project.
|
||||
|
||||
The first thing to do is to create a development environment that we can use for developing our infrastructure by testing our changes on our local machine. To do this we’ll use [Vagrant](https://www.vagrantup.com/downloads.html) (2.1.1 at the time of writing).
|
||||
|
||||
By this point I’ve mentioned Vagrant about 5 times — in case you’re still wondering what Vagrant is, their website defines it as follows:
|
||||
|
||||
> Vagrant is a tool for building and managing virtual machine environments in a single workflow. With an easy-to-use workflow and focus on automation, Vagrant lowers development environment setup time, increases production parity, and makes the “works on my machine” excuse a relic of the past.
|
||||
>
|
||||
> — [Vagrant Getting Started](https://www.vagrantup.com/intro/index.html)
|
||||
|
||||
What this equates to in real terms is that you write a small Ruby script that defines a group of virtual machines and how they should be set up. You can then simply run `vagrant up` from the command line, which will download the necessary VM images, start them up in your virtualisation tool of choice (I usually use the default Oracle Virtualbox) and then applies your scripted customisation to them. You can then simply SSH into these hosts with `vagrant ssh {hostname}` or just `vagrant ssh` to SSH into the default host (which is the first one in your `Vagrantfile`).
|
||||
|
||||
The `Vagrantfile` for this project looks as follows:
|
||||
|
||||
Line 16 selects the VM image from [Vagrant Cloud](https://app.vagrantup.com/boxes/search) to use as a base. In our case we’re using the latest Ubuntu Server 18.04 LTS (code-name bionic64).
|
||||
|
||||
Lines 18–22 define the control host that we’ll use to run Ansible plays.
|
||||
|
||||
Line 21 sets up the control host using `files/vagrant/control.ubuntu.sh`.
|
||||
|
||||
Lines 24–36 define the sonar01 host which is the target host we‘ll be setting up to run Sonarqube.
|
||||
|
||||
Lines 25–27 customise the sonar01 host to have more RAM than the default 512 MB.
|
||||
|
||||
Lines 31–34 expose the Sonarqube, PostgreSQL and NGINX HTTP(S) ports to the localhost, which allows you to access Sonarqube at [http://localhost:9000](http://localhost:9000/) or at [https://sonar.entelect.co.za/](https://sonar.entelect.co.za/) — the latter provided that you have a hosts file entry pointing `sonar.entelect.co.za` at `127.0.0.1`.
|
||||
|
||||
Line 35 sets up the sonar01 host using `files/vagrant/generic.ubuntu.sh`.
|
||||
|
||||
* * *
|
||||
|
||||
The `control.ubuntu.sh` script is responsible for setting up our Ansible control host, using the following bash script:
|
||||
|
||||
Lines 1–3 ensure that the control host has an RSA key pair for identifying itself.
|
||||
|
||||
Line 5 copies the public key out of the VM into the host OS so we can later copy it into the trusted hosts file of the target host.
|
||||
|
||||
Lines 7–11 configure SSH on the control host to not prompt the user to trust a new host they are SSHing into.
|
||||
|
||||
Lines 15–17 install Python 3, Python 3 PIP and then Ansible via Python 3 PIP, which gets us the version of Ansible that uses Python 3 instead of Python 2.
|
||||
|
||||
Lines 19–22 install some roles from defined in `requirements.yml` from Ansible Galaxy. In particular I am using [jdauphant.nginx](https://galaxy.ansible.com/jdauphant/nginx/) to install NGINX and [jdauphant.ssl-certs](https://galaxy.ansible.com/jdauphant/ssl-certs/) for generating the self-signed certificates.
|
||||
|
||||
* * *
|
||||
|
||||
The `files/vagrant/generic.ubuntu.sh` script is responsible for setting up our sonar01 target host, using the following simple bash script that just authorizes your control host to SSH into sonar01:
|
||||
|
||||
That covers setting up our development environment. To use it execute the following from the command line:
|
||||
|
||||
* `vagrant up` will start all the hosts defined in the `Vagrantfile`.
|
||||
* `vagrant ssh` will SSH you into the control host.
|
||||
* `cd /vagrant` will put you in the VM folder that maps the host OS folder you are running from, so this is where you can access your Ansible plays later on to run them.
|
||||
|
||||
Before we dive into how we’re going to use Ansible, let’s quickly go over what Ansible is. On their website they describe the product as:
|
||||
|
||||
> **Ansible** is the simplest way to automate apps and IT infrastructure. Application Deployment + Configuration Management + Continuous Delivery.
|
||||
|
||||
What this equates to in real terms is that you write relatively simple [YAML](https://en.wikipedia.org/wiki/YAML) scripts called **Plays** in Ansible parlance. These scripts are made up of commands which are executed on target machines over SSH. The commands in Ansible can come from one of two places:
|
||||
|
||||
* [**Modules**](http://docs.ansible.com/ansible/latest/user_guide/modules_intro.html) which are mostly provided by Ansible (you can build your own as well).
|
||||
* [**Roles**](http://docs.ansible.com/ansible/latest/user_guide/playbooks_reuse_roles.html) which are themselves essentially just more Plays designed with re-usability in mind.
|
||||
|
||||
The last part of the puzzle is called an **Inventory**. An inventory file defines groups of servers and configuration and you’ll typically have an inventory file per environment that you want to work with (for example DEV, QA and PRD).
|
||||
|
||||
When you want to perform a task you automated with Ansible, you run a **Play** against an **Inventory** from your **Control** host, which should have SSH access into all of the servers you are managing. The diagram below attempts to illustrate how this might be set up:
|
||||
|
||||

|
||||
|
||||
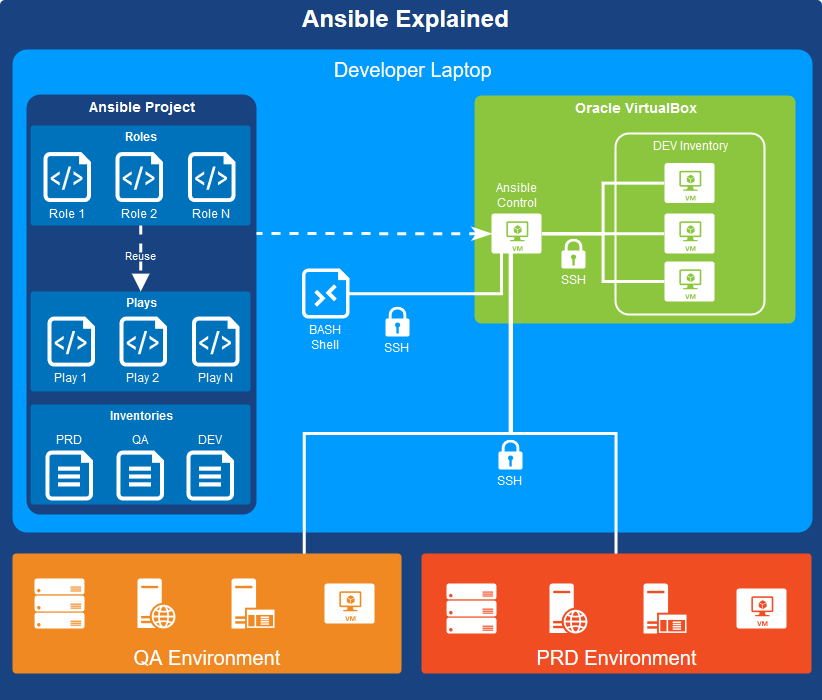
|
||||
|
||||
A better setup from a security point-of-view would be to have a Control host in your infrastructure layers instead of using the developer’s VM as a control host, but the approach shown above is probably the simplest setup you can use to get started short of using your laptop directly as a Control host (this is only viable on Linux though, Ansible doesn’t support Windows Control hosts).
|
||||
|
||||
Since I chose to set up Sonarqube myself instead of using a packaged version from Docker or a role shared on Ansible Galaxy, I needed a guide for how to set up Sonarqube. I couldn’t find one for the latest version of Sonarqube (7.1.1) and Ubuntu (18.04), so I used [this one](https://www.vultr.com/docs/how-to-install-sonarqube-on-ubuntu-16-04) for Sonarqube 6.4 on Ubuntu 16.04 to give me some basic guidance.
|
||||
|
||||
Let’s start with the inventory file as that’s the simplest:
|
||||
|
||||
Lines 3–4 define a group of servers called `sonar`, containing a single server with a host name of `sonar01`. In more production or QA scenarios this is often multiple servers for clustering.
|
||||
|
||||
Lines 6–7 define a group of servers called `control`, containing a single server with a host name of `control`. This is to allow us to use Ansible scripts to automate changes to the control host itself.
|
||||
|
||||
Lines 9–10 configure Ansible to use Python 3 instead of the default Python 2. This reduces the amount of setup we need to do on our target hosts.
|
||||
|
||||
Lines 12–13 tell Ansible that when it’s operating on the control host, it’s working on localhost, so it doesn’t need to SSH.
|
||||
|
||||
Lines 15–19 define various configuration variables that will allow us to configure our Sonarqube setup.
|
||||
|
||||
Line 20 defines the server DNS name.
|
||||
|
||||
* * *
|
||||
|
||||
The Ansible playbook I wrote for setting up Sonarqube is nearly 130 lines long, so to simplify explaining it I’ve broken it up into smaller bite sized chunks.
|
||||
|
||||
The first part is the header of the play along with 3 tasks for installing Oracle Java 8 and PostgreSQL on the target hosts:
|
||||
|
||||
Line 2 defines the target group of this play. In this case it will execute on the group `sonar` which if you remember the inventory file, includes a single host called `sonar01` in our local development environment.
|
||||
|
||||
Line 3 tells Ansible that this play should be run with `root` user privileges. Since we are not connecting to our target host using the root user, that implies that Ansible will use `sudo` to execute our commands with escalated privileges.
|
||||
|
||||
Lines 4–14 use the additional roles downloaded from Ansible Galaxy to set up NGINX as a reverse proxy with SSL.
|
||||
|
||||
Line 13 defines the an NGINX configuration template to use for configuring NGINX.
|
||||
|
||||
Lines 16–18 install the `ppa:webupd8team/java` PPA as an additional package sources and runs `apt-get update` to refresh the list of available packages.
|
||||
|
||||
Lines 20–21 is a bit of magic I got off [Stack Exchange](https://askubuntu.com/questions/190582/installing-java-automatically-with-silent-option) to turn off the interactive license prompts that occur when you install the `oracle-java8-installer` package.
|
||||
|
||||
Lines 23–30 install all of the OS packages we need for Sonarqube and/or our Ansible play to work using `apt-get install`. Specifically lines 17–19 are installing tools used by our Ansible scripts rather than things that are strictly necessary for running Sonarqube.
|
||||
|
||||
* * *
|
||||
|
||||
The second part of the play takes care of setting up PostgreSQL:
|
||||
|
||||
Lines 1–12 are how you should setup Sonarqube with Ansible… unfortunately I ran into a bug with the PostgreSQL commands not working properly when using `sudo` on newer version of Ubuntu, so I had to get a bit creative.
|
||||
|
||||
Lines 14–19 copy a Bash script to the server that I used to manually setup our Sonarqube PostgreSQL DB user and password and to create a Sonarqube database.
|
||||
|
||||
Lines 21–25 strips carriage returns out of the file — a problem you should only run into when running scripts you copied from a Windows host as we’re doing in this case. If you don’t do this the Bash interpreter chokes on the carriage returns causing your script to fail.
|
||||
|
||||
Lines 27–30 executes the script, creating the user and database.
|
||||
|
||||
The script I used to hack around the problem was quite simple:
|
||||
|
||||
* * *
|
||||
|
||||
The third and final part of the play takes care of installing and setting up Sonarqube:
|
||||
|
||||
Lines 1–4 create a non-root user for running Sonarqube. This was necessary, because Sonarqube uses ElasticSearch for some of its functionality and the version included in Sonarqube 7.x cannot run as the `root` user (presumably for security reasons).
|
||||
|
||||
Lines 6–9 downloads the Sonarqube distribution configured by the `sonar_version` variable in the inventory file.
|
||||
|
||||
Lines 11–16 unzips the file.
|
||||
|
||||
Lines 18–23 creates a symbolic link `/srv/sonarqube` to whatever Sonarqube version we extracted (for example `/srv/sonarqube-7.1.1`) — this allows us to simplify our service configuration by assuming that `/srv/sonarqube` is the current version that should be running.
|
||||
|
||||
Lines 25–44 configure Sonarqube with our database settings by editing the default files included in the installation zip file.
|
||||
|
||||
Lines 46–51 edit the launch script to configure it run with the non-root user we set up earlier.
|
||||
|
||||
Lines 53–56 copies over our service configuration file that will allow us to manage Sonarqube as we do other Ubuntu services with `service {name} start`, `service {name} status` and `service {name} stop`.
|
||||
|
||||
Lines 58–66 configure some operating system limits to the values recommended by the Sonarqube installation documentation.
|
||||
|
||||
Lines 68–73 starts our Sonarqube service and enables it, which means it will start automatically on boot.
|
||||
|
||||
That covers the main points of setting up this project. To try it out on your machine you can simply clone the repository:
|
||||
|
||||
`git clone [https://github.com/entelect/sonarqube-server](https://github.com/entelect/sonarqube-server)`
|
||||
|
||||
Using a Git Bash shell on Windows or your regular shell on Linux run the following from the project directory:
|
||||
|
||||
vagrant plugin install vagrant-hostmanager
|
||||
vagrant up
|
||||
vagrant ssh
|
||||
cd /vagrant
|
||||
ansible-playbook -i inventories/dev/local plays/sonar.yml
|
||||
|
||||
Wait a little bit after the play finishes to give everything time to start up, then try to hit: [http://localhost:9000](http://localhost:9000/). You should see your very own Sonarqube running locally in a VM:
|
||||
|
||||

|
||||
|
||||
That’s it! Hopefully this will be helpful to anyone else looking to set up Sonarqube on a VM.
|
||||
|
||||
Some of the further enhancements I plan to make in the near future are:
|
||||
|
||||
* Configure LDAP authentication so users can log in with their domain credentials.
|
||||
@@ -0,0 +1,82 @@
|
||||
---
|
||||
title: Setup mutt with Gmail on CentOS and Ubuntu
|
||||
updated: 2019-07-03 16:04:09Z
|
||||
created: 2019-07-03 16:03:16Z
|
||||
tags:
|
||||
- IT
|
||||
- IT/Tools/mutt
|
||||
source: https://www.linux.com/blog/setup-mutt-gmail-centos-and-ubuntu
|
||||
---
|
||||
|
||||
[Setup mutt with Gmail on CentOS and Ubuntu](https://www.linux.com/blog/setup-mutt-gmail-centos-and-ubuntu)
|
||||
**Gmail Setup**
|
||||
|
||||
In gmail, go click the gear icon, go to `Settings`, go to the tab `Forwarding POP/IMAP`, and click the `Configuration instructions` link in `IMAP Access` row.
|
||||
|
||||
Then click `I want to enable IMAP`. At the bottom of the page, under the paragraph about configuring your mail client, select `Other`. Note the mail server information and use that information for further settings as shown in the next section.
|
||||
|
||||
Before proceeding further visit [](https://www.google.com/settings/security/lesssecureapps)[https://www.google.com/settings/security/lesssecureapps](https://www.google.com/settings/security/lesssecureapps) and check`Turn on` radio button.
|
||||
|
||||
**Install mutt**
|
||||
|
||||
_CentOS_
|
||||
|
||||
```shell
|
||||
yum install mutt
|
||||
```
|
||||
|
||||
_Ubuntu_
|
||||
|
||||
```shell
|
||||
sudo apt-get install mutt
|
||||
```
|
||||
|
||||
**Configure Mutt**
|
||||
|
||||
Create
|
||||
|
||||
```shell
|
||||
mkdir -p ~/.mutt/cache/headers
|
||||
mkdir ~/.mutt/cache/bodies
|
||||
touch ~/.mutt/certificates
|
||||
```
|
||||
|
||||
Create mutt configuration file `muttrc`
|
||||
|
||||
```shell
|
||||
touch ~/.mutt/muttrc
|
||||
```
|
||||
|
||||
Open muttrc
|
||||
|
||||
```shell
|
||||
vim ~/.mutt/muttrc
|
||||
```
|
||||
|
||||
Add following configurations
|
||||
|
||||
```shell
|
||||
set ssl_starttls=yes
|
||||
set ssl_force_tls=yes
|
||||
set imap_user = 'This e-mail address is being protected from spambots. You need JavaScript enabled to view it'
|
||||
set imap_pass = 'PASSWORD'
|
||||
set from='This e-mail address is being protected from spambots. You need JavaScript enabled to view it'
|
||||
set realname='Your Name'
|
||||
set folder = imaps://imap.gmail.com/
|
||||
set spoolfile = imaps://imap.gmail.com/INBOX
|
||||
set postponed="imaps://imap.gmail.com/[Gmail]/Drafts"
|
||||
set header_cache = "~/.mutt/cache/headers"
|
||||
set message_cachedir = "~/.mutt/cache/bodies"
|
||||
set certificate_file = "~/.mutt/certificates"
|
||||
set smtp_url = 'smtps://This e-mail address is being protected from spambots. You need JavaScript enabled to view it:This e-mail address is being protected from spambots. You need JavaScript enabled to view it:465/'
|
||||
set move = no
|
||||
set imap_keepalive = 900
|
||||
```
|
||||
|
||||
Make appropriate changes, like `change_this_user_name` to your gmail user name and `PASSWORD` to your gmail password. And save the file.
|
||||
|
||||
Now you are ready to send, receive and read email using email client Mutt by simply typing `mutt`.
|
||||
|
||||
For the first time it will prompt to accept SSL certificates; press `a` to always accept these certificates.
|
||||
|
||||
Now you will be presented with your Gmail inbox.
|
||||
@@ -0,0 +1,50 @@
|
||||
---
|
||||
title: Sorting List in Groovy Language
|
||||
updated: 2019-02-26 12:17:53Z
|
||||
created: 2019-02-26 12:16:19Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Groovy
|
||||
---
|
||||
|
||||
While writing my code in groovy scripting language, I encountered a problem on how to sort a list or an array of objects. As a newbie in groovy, I was eager to look for simpler groovy way to sort a list and was so surprise when I read a blog article. I learned a very easy and readable way of sorting.
|
||||
|
||||
## Sort Numbers
|
||||
|
||||
```groovy
|
||||
def numberList = [4,2,5,3,1]
|
||||
assert [1,2,3,4,5] = numberList.sort()
|
||||
```
|
||||
|
||||
|
||||
## Sort Letters
|
||||
|
||||
```groovy
|
||||
def alphaList = [c,d,a,b,e]
|
||||
assert [a,b,c,d,e] = alphaList.sort()
|
||||
```
|
||||
|
||||
|
||||
## Sort Object by its Field
|
||||
|
||||
```groovy
|
||||
// Create a object under file name Student.groovy
|
||||
class Student{
|
||||
int id
|
||||
String fullName
|
||||
}
|
||||
|
||||
//Explanation
|
||||
def studentList = [ new Student(id: 2, name: Beta),
|
||||
new Student(id: 1, name: Charley),
|
||||
new Student(id: 3, name: Alpha)
|
||||
]
|
||||
|
||||
//output will be Charley, Beta, Alpha
|
||||
studentList.sort{ it.id }
|
||||
|
||||
//output will be Alpha, Beta, Charley
|
||||
studentList.sort{ it.name }
|
||||
```
|
||||
|
||||
Take note of the use of the sort closure sort {} verses the sort() method.As of now, I am not sure how that works but as long as it solves my problem and test is working. I am good!
|
||||
@@ -0,0 +1,14 @@
|
||||
---
|
||||
tags:
|
||||
- IT
|
||||
- StarTrek
|
||||
- WindowManager
|
||||
- LCARS
|
||||
---
|
||||
|
||||
## Links
|
||||
- [=/\\=\_\_ www.gtjlcars.de\_\_\_ Welcomepage\_\_ \n=/\\=\_\_ LCARS -Michael Okuda - PADD's - Excel für LCARS.](https://www.gtjlcars.de/index01.htm)
|
||||
- [GitHub - lcarsde/lcarsde-onboard-theme: Onboard on-screen keyboard theme for lcarsde](https://github.com/lcarsde/lcarsde-onboard-theme)
|
||||
- [lcarsde - LCARS Desktop Environment](https://lcarsde.github.io/)
|
||||
- [Make Linux look like Star Trek LCARS - by Bryan Lunduke](https://lunduke.substack.com/p/make-linux-look-like-star-trek-lcars)
|
||||
- [Star Trek & Open Source: Commander Datas Desktop - Golem.de](https://www.golem.de/news/star-trek-open-source-commander-datas-desktop-2211-169220.html)
|
||||
@@ -0,0 +1,82 @@
|
||||
---
|
||||
title: 'Task management and Personal Kanban: how I use GitLab Issues'
|
||||
updated: 2020-10-14 07:23:23Z
|
||||
created: 2020-10-14 07:20:54Z
|
||||
tags:
|
||||
- Development/Git
|
||||
- IT/Tools/Gitlab
|
||||
- Task
|
||||
- Kanban
|
||||
source: >-
|
||||
http://gbraad.nl/blog/task-management-and-personal-kanban-how-i-use-gitlab-issues.html
|
||||
---
|
||||
|
||||
# [Task management and Personal Kanban: how I use GitLab Issues](http://gbraad.nl/blog/task-management-and-personal-kanban-how-i-use-gitlab-issues.html)
|
||||
|
||||
Working on personal and work-related tasks can be overwhelming, especially when you lose sight of what actually needs to be done. What makes it more difficult is that you are constantly interrupted. I have tried many different things, and apps, but nothing really worked. Do not try to make your process of working to fit the tool, but make sure you have a tool that fits the way you work.
|
||||
|
||||
## Kanban
|
||||
|
||||
Kanban (or 看板) originated as a scheduling system to improving manufacturing efficiency. The word literally means signboard in Japanese, and in Chinese it can be read as 'Look board'. It emphasizes on visualization of tasks that need to be done, are being worked on, and have finished.
|
||||
|
||||
In software development you often see people use Trello or other kanban-like boards to visualize work that is on their 'backlog', 'doing', 'done'. Although these tools work quite well, it did not fit my workflow or where I do most of my work.
|
||||
|
||||
## GitLab issues
|
||||
|
||||
Quite recently, GitLab released a version of their sourcecode management tool that allows to visualize issues on a board. And I started to evaluate it, as GitLab is part of my workflow in general. I host many of my private repositories there for backup purposes, use it to publish my resume with the CI runners, etc. And I can tell you, that the issue boards was exactly what I was looking for.
|
||||
|
||||
Below is a screenshot of what it looks like:
|
||||

|
||||
Note: the image shown here is from an early iteration and still has too many items in 'doing'. This actually made me realize where my time was spent.
|
||||
|
||||
### How to set-up
|
||||
|
||||
All you need to do is create a private repository. In my case, I created a 'personal' project. All the issues you create, will only be visible to you. After you have done this, you can create a board from the Issues. Just start with the defaults first and customize it along the way... This made it work best for me.
|
||||
|
||||
### Workflow
|
||||
|
||||
When you create an issue, just tag it accordingly. I use it to group tasks for different topics or things I work on. Now when you open the board, you will see your issue is on the 'backlog'. From there you can drag it to a swimlane. I have several that helps to organize tasks, such as 'blog' and 'urgent'. When you drag, it will assign the label to the issue according to the name of the swimlane.
|
||||
|
||||
### Offline use?
|
||||
|
||||
There is, however, a small issue with the setup. It only allows me to work online. In the end I noticed this is actually not a big problem.
|
||||
|
||||
## Single-tasking
|
||||
|
||||
Kanban helps you to visualize your tasks at hand, but it still requires discipline to actually make it work. Therefore, you need to understand that 'multi-tasking' does not exist! I recently read 'Singletasking: Get More Done-One Thing at a Time', and it help me a lot to realize that I was going the right direction with my personal kanban. However, I was still trying to do too many things at once. Mostly due to interruptions. This led me to appreciate the offline problem I have.
|
||||
|
||||
If I have an interruption, or some other urgent matter, I would first record it on my phone in a file called 'reminder', which lives in the same personal repository. This file is synced using git, so it travels with me and it allows me to use it as a general reminder/todo record keeping, and decide later what to do with the entries.
|
||||
|
||||
## Tools
|
||||
|
||||
On my desktop I only need to use a browser to keep track of tasks being worked on. Even the reminder file can be opened from here.
|
||||
|
||||
On my phone I use the following apps:
|
||||

|
||||
|
||||
Writeily Pro, SGit, and Labcoat. Using SGit I sync several important repositories to my phone, such as my 'personal', 'knowledge-base', and some private specific projects for training/teaching, etc.
|
||||
|
||||
Writeily Pro opens the SGit repos folder as it's document folder: `/sdcard/Android/data/me.sheimi.sgit/files/repo` in my case. Writely's usage was not without problems for me. Especially when dealing with some 'larger' files.
|
||||
|
||||
Using Labcoat I am able to create and change basic information of an issue, such as closing it and adding comments. But I usually do all interactions online now, and else use my offline reminder file. I only use Labcoat only in rare cases. Probably also because the tool misses some of the more wanted features as labelling and tagging issues.
|
||||
|
||||
I haven't found a good way to use the command line yet. I did start with a small [client](https://gitlab.com/gbraad/gitlab-client), but so far it only reads and doesn't filter anything. Hope I can allocate more time to deal with this at some point. At the moment I do not really need it.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Task management is not something you learn by just reading a book or keeping a todo-list inside an application. It really is a discipline. And it depends on you, how you will deal with it. This article does not go into a lot of detail on my own process, as this is a personal quest. Just experiment and see what works best for you.
|
||||
|
||||
I have read several books, and in the section 'More information' below, you can find these resources. It involves in keeping your tasks *visualized* and *limiting* the amount you work on at the same time. It is up to you how to balance private and work.
|
||||
|
||||
I also learned that to keep things organized, I started to keep a public [knowledge base](https://gitlab.com/gbraad/knowledge-base/). This way I am better able to keep knowledge available and at hand. Before, I would keep it in an earlier version of a reminder file and this cluttered everything and actually not made me remember things. I am still working on writing things done in a more general way, written towards possible others who will read it. But this is a work-in-progress, as part of my personal continous improvement.
|
||||
|
||||
I will certainly refine my process over time, and might even change it again completely. As long as it works for me. I'll keep you updated and might write related articles about time management and knowledge techniques I have used over the years. One I still love the most is mind-mapping... and I have applied it to organizing work before. It is a great way to organize thoughts.
|
||||
|
||||
## More information
|
||||
|
||||
I suggest to read more about personal kanban.
|
||||
|
||||
- [Personal Kanban 101](http://www.personalkanban.com/pk/personal-kanban-101/)
|
||||
- Knowledge-base: [Personal kanban](https://gitlab.com/gbraad/knowledge-base/blob/master/books/personal-kanban.md)
|
||||
- Knowledge-base: [Singletasking](https://gitlab.com/gbraad/knowledge-base/blob/master/books/singletasking.md)
|
||||
- [Presentation](https://hguemar.fedorapeople.org/personal-kanban/) of a friend's experience with Personal Kanban
|
||||
@@ -0,0 +1,293 @@
|
||||
---
|
||||
title: The JVM Test Suite Plugin
|
||||
updated: 2022-09-19 17:00:53Z
|
||||
created: 2022-09-19 17:00:53Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Gradle
|
||||
- Development/Gradle/Plugin
|
||||
source: https://docs.gradle.org/current/userguide/jvm_test_suite_plugin.html
|
||||
---
|
||||
|
||||
The JVM Test Suite plugin (plugin id: `jvm-test-suite`) provides a DSL and API to model multiple groups of automated tests into test suites in JVM-based projects. Tests suites are intended to grouped by their purpose and can have separate dependencies and use different testing frameworks.
|
||||
|
||||
For instance, this plugin can be used to define a group of Integration Tests, which might run much longer than unit tests and have different environmental requirements.
|
||||
|
||||
## [](#sec:jvm_test_suite_usage)[Usage](#sec:jvm_test_suite_usage)
|
||||
|
||||
This plugin is applied automatically by the `java` plugin but can be additionally applied explicitly if desired. The plugin cannot be used without a JVM language plugin applied as it relies on several conventions of the `java` plugin.
|
||||
|
||||
Example 1. Applying the JVM Test Suite plugin
|
||||
|
||||
|
||||
build.gradle
|
||||
```groovy
|
||||
plugins {
|
||||
id 'java'
|
||||
id 'jvm-test-suite'
|
||||
}
|
||||
```
|
||||
|
||||
The plugins adds the following objects to the project:
|
||||
|
||||
- A `testing` extension (type: [TestingExtension](https://docs.gradle.org/current/dsl/org.gradle.testing.base.TestingExtension.html)) to the project used to configure test suites.
|
||||
- A test suite named `test` (type: [JvmTestSuite](https://docs.gradle.org/current/dsl/org.gradle.api.plugins.jvm.JvmTestSuite.html)).
|
||||
- A `test` [SourceSet](https://docs.gradle.org/current/dsl/org.gradle.api.tasks.SourceSet.html).
|
||||
- Several configurations derived from the `test` SourceSet name: `testImplementation`, `testCompileOnly`, `testRuntimeOnly`
|
||||
- A single test suite target backed by a task named `test`.
|
||||
|
||||
The `test` task, SourceSet and derived configurations are identical in name and function to those used in prior Gradle releases.
|
||||
|
||||
## [](#sec:jvm_test_suite_tasks)[Tasks](#sec:jvm_test_suite_tasks)
|
||||
|
||||
The JVM Test Suite plugin adds the following task to the project:
|
||||
|
||||
`test` — [Test](https://docs.gradle.org/current/dsl/org.gradle.api.tasks.testing.Test.html)
|
||||
|
||||
*Depends on*: `testClasses` from the `java` plugin, and all tasks which produce the test runtime classpath
|
||||
|
||||
Runs the tests using the framework configured for the default test suite.
|
||||
|
||||
Additional instances of [Test](https://docs.gradle.org/current/dsl/org.gradle.api.tasks.testing.Test.html) tasks will be automatically created for each test suite added via the `testing` extension.
|
||||
|
||||
## [](#sec:jvm_test_suite_configuration)[Configuration](#sec:jvm_test_suite_configuration)
|
||||
|
||||
### [](#sec:jvm_test_suite_terminology)[Terminology and Modeling](#sec:jvm_test_suite_terminology)
|
||||
|
||||
The JVM Test Suite Plugin introduces some modeling concepts backed by new APIs. Here are their definitions.
|
||||
|
||||
#### [](#test_suite)[Test Suite](#test_suite)
|
||||
|
||||
A test suite is a collection of JVM-based tests.
|
||||
|
||||
#### [](#test_suite_target)[Test Suite Target](#test_suite_target)
|
||||
|
||||
For the initial release of this plugin, each test suite has a single target. This results in a 1:1:1 relationship between test suite, test suite target and a matching [Test](https://docs.gradle.org/current/dsl/org.gradle.api.tasks.testing.Test.html) task. The name of the `Test` task is derived from the suite name. Future iterations of the plugin will allow defining multiple targets based other attributes, such as a particular JDK/JRE runtime.
|
||||
|
||||
Each test suite has some configuration that is common across for all tests contained in the suite:
|
||||
|
||||
- Testing framework
|
||||
- Sources
|
||||
- Dependencies
|
||||
|
||||
In the future, other properties may be specified in the test suite which may influence the toolchains selected to compile and run tests.
|
||||
|
||||
The `Test` task associated with the target inherits its name from the suite. Other properties of the `Test` task are configurable.
|
||||
|
||||
#### [](#test_suite_type)[Test Suite Type](#test_suite_type)
|
||||
|
||||
Each test suite must be assigned a type. Types can be used to group related test suites across multiple Gradle projects within a build.
|
||||
|
||||
The type of a test suite can be configured using the suites’s [test type property](https://docs.gradle.org/current/dsl/org.gradle.api.plugins.jvm.JvmTestSuite.html#getTestType). The type **must be unique** across all test suites in the same Gradle project. By convention, the type is set to the name of the test suite, converted to dash-case - with the exception of the built-in test suite, which uses the value ['unit-test'](https://docs.gradle.org/current/javadoc/org/gradle/api/attributes/TestSuiteType.html#UNIT_TEST--).
|
||||
|
||||
Common values are available as constants in [TestSuiteType](https://docs.gradle.org/current/javadoc/org/gradle/api/attributes/TestSuiteType.html).
|
||||
|
||||
## Configuration Examples
|
||||
|
||||
Here are several examples to illustrate the configurability of test suites.
|
||||
|
||||
## [](#declare_an_additional_test_suite)[Declare an additional test suite](#declare_an_additional_test_suite)
|
||||
|
||||
build.gradle
|
||||
```groovy
|
||||
testing {
|
||||
suites { (1)
|
||||
test { (2)
|
||||
useJUnitJupiter() (3)
|
||||
}
|
||||
integrationTest(JvmTestSuite) { (4)
|
||||
dependencies {
|
||||
implementation project (5)
|
||||
}
|
||||
targets { (6)
|
||||
all {
|
||||
testTask.configure {
|
||||
shouldRunAfter(test)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
tasks.named('check') { (7)
|
||||
dependsOn(testing.suites.integrationTest)
|
||||
}
|
||||
```
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| **1** | Configure all test suites for this project. |
|
||||
| **2** | Configure the built-in `test` suite. This suite is automatically created for backwards compatibility. You **must** specify a testing framework to use in order to run these tests (e.g. JUnit 4, JUnit Jupiter). This suite is the only suite that will automatically have access to the production source’s `implementation` dependencies, all other suites must explicitly declare these. |
|
||||
| **3** | Declare this test suite uses JUnit Jupiter. The framework’s dependencies are automatically included. It is always necessary to explicitly configure the built-in `test` suite even if JUnit4 is desired. |
|
||||
| **4** | Define a new suite called `integrationTest`. Note that all suites other than the built-in `test` suite will by convention work as if `useJUnitJupiter()` was called. You do **not** have to explicitly configure the testing framework on these additional suites, unless you wish to change to another framework. |
|
||||
| **5** | Add a dependency on the production code of the project to the `integrationTest` suite targets. By convention, only the built-in `test` suite will automatically have a dependency on the production code of the project. |
|
||||
| **6** | Configure all targets of this suite. By convention, test suite targets have no relationship to other `Test` tasks. This example shows that the slower integration test suite targets should run after all targets of the `test` suite are complete. |
|
||||
| **7** | Configure the `check` task to depend on all `integrationTest` targets. By convention, test suite targets are not associated with the `check` task. |
|
||||
|
||||
Invoking the `check` task on the above configured build should show output similar to:
|
||||
|
||||
\> Task :compileJava
|
||||
\> Task :processResources NO-SOURCE
|
||||
\> Task :classes
|
||||
\> Task :jar
|
||||
\> Task :compileTestJava
|
||||
\> Task :processTestResources NO-SOURCE
|
||||
\> Task :testClasses
|
||||
\> Task :test
|
||||
\> Task :compileIntegrationTestJava
|
||||
\> Task :processIntegrationTestResources NO-SOURCE
|
||||
\> Task :integrationTestClasses
|
||||
\> Task :integrationTest
|
||||
\> Task :check
|
||||
|
||||
BUILD SUCCESSFUL in 0s
|
||||
6 actionable tasks: 6 executed
|
||||
|
||||
Note that the `integrationTest` test suite does not run until after the `test` test suite completes.
|
||||
|
||||
## [](#sec:configuring_the_built_in_test_suite)[Configure the built-in `test` suite](#sec:configuring_the_built_in_test_suite)
|
||||
|
||||
build.gradle
|
||||
```groovy
|
||||
testing { (1)
|
||||
suites {
|
||||
test {
|
||||
useTestNG() (1)
|
||||
targets {
|
||||
all {
|
||||
testTask.configure { (2)
|
||||
// set a system property for the test JVM(s) systemProperty 'some.prop', 'value'
|
||||
options { (3)
|
||||
preserveOrder = true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| **1** | Declare the `test` test suite uses the TestNG test framework. |
|
||||
| **2** | Lazily configure the test task of all targets of the suite; note the return type of `testTask` is `TaskProvider<Test>`. |
|
||||
| **3** | Configure more detailed test framework options. The `options` will be a subclass of `org.gradle.api.tasks.testing.TestFrameworkOptions`, in this case it is `org.gradle.api.tasks.testing.testng.TestNGOptions`. |
|
||||
|
||||
## [](#configure_dependencies_of_a_test_suite)[Configure dependencies of a test suite](#configure_dependencies_of_a_test_suite)
|
||||
|
||||
build.gradle
|
||||
```groovy
|
||||
testing {
|
||||
suites {
|
||||
test { (1)
|
||||
dependencies { // Note that this is equivalent to adding dependencies to testImplementation in the top-level dependencies block
|
||||
implementation 'org.assertj:assertj-core:3.21.0' (2)
|
||||
annotationProcessor 'com.google.auto.value:auto-value:1.9' (3)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| **1** | Configure the built-in `test` test suite. |
|
||||
| **2** | Add the assertj library to the test’s compile and runtime classpaths. The `dependencies` block within a test suite is already scoped for that test suite. Instead of having to know the global name of the configuration, test suites have a consistent name that you use in this block for declaring `implementation`, `compileOnly`, `runtimeOnly` and `annotationProcessor` dependencies. |
|
||||
| **3** | Add the Auto Value annotation processor to the suite’s annotation processor classpath so that it will be run when compiling the tests. |
|
||||
|
||||
The `dependencies` block within a test suite does not provide access to the same methods as the top-level `dependencies` block. For instance, the [platform()](https://docs.gradle.org/current/dsl/org.gradle.api.artifacts.dsl.DependencyHandler.html#org.gradle.api.artifacts.dsl.DependencyHandler:platform%28java.lang.Object%29) and [enforcedPlatform()](https://docs.gradle.org/current/dsl/org.gradle.api.artifacts.dsl.DependencyHandler.html#org.gradle.api.artifacts.dsl.DependencyHandler:platform%28java.lang.Object%29) methods are not available.
|
||||
|
||||
To use these and similar methods, you need to access the top-level dependencies handler directly with `project.dependencies.platform(…)` or `project.dependencies.enforcedPlatform(…)`.
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| | Though it is discouraged, as suggested by the comment in the snippet above, you can also access the configurations of a test suite in a top-level `dependencies` block after creating the test suite. The configurations used by test suites are normal Gradle configurations, but their exact names should be considered an implementation detail subject to change. For this reason, configuration via the suite’s own `dependencies` block is recommended. |
|
||||
|
||||
## [](#configure_source_directories_of_a_test_suite)[Configure source directories of a test suite](#configure_source_directories_of_a_test_suite)
|
||||
|
||||
build.gradle
|
||||
```groovy
|
||||
testing {
|
||||
suites {
|
||||
integrationTest(JvmTestSuite) { (1)
|
||||
sources { (2)
|
||||
java { (3)
|
||||
srcDirs = ['src/it/java'] (4)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| **1** | Declare and configure a suite named `integrationTest`. The `SourceSet` and synthesized `Test` tasks will be based on this name. |
|
||||
| **2** | Configure the `sources` of the test suite. |
|
||||
| **3** | Configure the `java` SourceDirectorySet of the test suite. |
|
||||
| **4** | Overwrite the `srcDirs` property, replacing the conventional `src/integrationTest/java` location with `src/it/java`. |
|
||||
|
||||
## [](#configure_the_type_of_a_test_suite)[Configure the type of a test suite](#configure_the_type_of_a_test_suite)
|
||||
|
||||
build.gradle
|
||||
```groovy
|
||||
testing {
|
||||
suites {
|
||||
secondaryTest(JvmTestSuite) {
|
||||
testType = TestSuiteType.INTEGRATION_TEST (1)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| **1** | This suite would use a type value of 'secondary-test' by default. This explicitly sets the type to 'integration-test'. |
|
||||
|
||||
## [](#configure_the_test_task_for_a_test_suite)[Configure the `Test` task for a test suite](#configure_the_test_task_for_a_test_suite)
|
||||
|
||||
build.gradle
|
||||
```groovy
|
||||
testing {
|
||||
suites {
|
||||
integrationTest {
|
||||
targets {
|
||||
all { (1)
|
||||
testTask.configure {
|
||||
maxHeapSize = '512m' (2)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| **1** | Configure the `integrationTest` task created by declaring a suite of the same name. |
|
||||
| **2** | Configure the `Test` task properties. |
|
||||
|
||||
`Test` tasks associated with a test suite target can also be configured directly, by name. It is not necessary to configure via the test suite DSL.
|
||||
|
||||
## [](#sec:outgoing_variants)[Outgoing Variants](#sec:outgoing_variants)
|
||||
|
||||
Each test suite creates an outgoing variant containing its test execution results. These variants are designed for consumption by the [Test Report Aggregation Plugin](https://docs.gradle.org/current/userguide/test_report_aggregation_plugin.html#test_report_aggregation_plugin).
|
||||
|
||||
The attributes will resemble the following. User-configurable attributes are highlighted below the sample.
|
||||
|
||||
outgoingVariants task output
|
||||
|
||||
```
|
||||
-------------------------------------------------- Variant testResultsElementsForTest (i) -------------------------------------------------- Description = Directory containing binary results of running tests for the test Test Suite's test target.
|
||||
|
||||
Capabilities
|
||||
- org.gradle.sample:list:1.0.2 (default capability)
|
||||
Attributes
|
||||
- org.gradle.category = verification
|
||||
- org.gradle.testsuite.name = test (1) - org.gradle.testsuite.target.name = test (2) - org.gradle.testsuite.type = unit-test (3) - org.gradle.verificationtype = test-results
|
||||
|
||||
Artifacts
|
||||
- build/test-results/test/binary (artifactType = directory)
|
||||
```
|
||||
@@ -0,0 +1,415 @@
|
||||
---
|
||||
title: The Must-Have Obsidian plugins | Personal Knowledge Management Journal
|
||||
updated: 2023-03-27 14:59:38Z
|
||||
created: 2023-03-27 14:59:38Z
|
||||
tags:
|
||||
- IT
|
||||
- IT/Tools/Obsidian
|
||||
source: https://pkmjournal.com/the-must-have-obsidian-plugins-5a99821b18b2
|
||||
---
|
||||
|
||||
## Boost your note-taking productivity with these awesome plugins
|
||||
|
||||

|
||||
The logo of Obsidian
|
||||
|
||||
In this article, I’ll list my favorite plugins for [Obsidian](https://obsidian.md/). Most of those are part of my [Obsidian Starter Kit](https://developassion.gumroad.com/l/obsidian-starter-kit).
|
||||
|
||||
## Introduction
|
||||
|
||||
Obsidian has a really large community and a huge library of community plugins. Those plugins really add a lot of value to Obsidian and make for a much better user experience. Exploring those can be daunting as there are [hundreds](https://obsidian-plugin-stats.vercel.app/plugins) (600+ at the time of writing). Let me spare you some time and introduce you to the very best plugins out there!
|
||||
|
||||
## Built-in plugins
|
||||
|
||||
Obsidian comes out of the box with a set of “core” plugins that are disabled by default. You can enable/disable those through the options, under “Core plugins”. Many of those are super useful.
|
||||
|
||||
Here’s a short overview:
|
||||
|
||||
- Audio recorder: easily record audio from Obsidian and add the recording as attachment
|
||||
- Backlinks: show links from other notes to the current one
|
||||
- Command palette: hit “Cmd/Ctrl + P” to show the palette and quickly execute commands
|
||||
- Daily notes: create or open today’s daily note. I don’t recommend this plugin because the “Periodic Notes” plugin discussed later in this article is much more powerful
|
||||
- File explorer: see the files and folders in the vault
|
||||
- File recovery: recover files
|
||||
- Format converter: convert Markdown from other applications to Obsidian’s own format
|
||||
- Graph view: View a graph that displays links between notes
|
||||
- Notes composer: manipulate notes (merge, split, refactor)
|
||||
- Outgoing links: show links from the current note to other ones. Also detects unlinked mentions
|
||||
- Outline: display the outline of the current note
|
||||
- Page preview: preview the content of links by pressing Ctrl/Cmd while hovering those
|
||||
- Publish: publish notes through Obsidian Publish
|
||||
- Quick switcher: Use “Ctrl/Cmd + O” to navigate between notes
|
||||
- Random note
|
||||
- Search
|
||||
- Slash commands: Allows triggering commands by typing “/” in the editor
|
||||
- Starred: star frequently used files and searches
|
||||
- Sync: synchronize files using Obsidian Sync
|
||||
- Tag pane: display your tags and their number of occurrences
|
||||
- Templates: insert templates. This one is great, but the “Templater” plugin discussed afterwards is much more powerful
|
||||
- Word count: display the word count
|
||||
|
||||

|
||||
Obsidian core plugins
|
||||
|
||||
## Calendar
|
||||
|
||||
This plugin adds a useful calendar to the sidebar of Obsidian. It provides a simple way to navigate between your daily notes. I use it all the time instead of navigating through the file tree. At a glance, you can see the days for which you have taken daily notes. The second use case of this plugin is to easily create a future daily note. This is useful when you want to add a reminder for yourself.
|
||||
|
||||
Link: https://github.com/liamcain/obsidian-calendar-plugin
|
||||
|
||||

|
||||
Obsidian calendar plugin
|
||||
|
||||
## Periodic notes
|
||||
|
||||
Using the periodic notes plugin, you can easily create periodic notes (i.e., daily, weekly, monthly, quarterly and yearly notes).
|
||||
|
||||
You can associate a specific template with each periodicity (e.g. a template for daily notes, another for weekly notes, etc). This plugin is also well integrated with the calendar plugin above. When you click on a date in the calendar, it creates the corresponding daily note.
|
||||
|
||||
With this plugin, [journaling](https://dsebastien.net/blog/2021-10-07-periodic-journaling-part-1) is much easier to do on a regular basis, and so are weekly, monthly, quarterly and yearly [periodic reviews](https://dsebastien.net/blog/2022-05-16-periodic-reviews).
|
||||
|
||||
Link: https://github.com/liamcain/obsidian-periodic-notes
|
||||
|
||||

|
||||
Open today’s daily note from the toolbar
|
||||
|
||||

|
||||
An example daily note
|
||||
|
||||
## Rollover daily todos
|
||||
|
||||
If your list of tasks for the day is part of your daily notes (which I recommend), then this plugin is a must-have. It will automatically copy the incomplete tasks to the list of the next day. This makes it a breeze to continue where you left things off.
|
||||
|
||||
Link: https://github.com/shichongrui/obsidian-rollover-daily-todos
|
||||
|
||||

|
||||
The rollover daily todos plugin configuration
|
||||
|
||||
## Dataview
|
||||
|
||||
Dataview is the most powerful Obsidian plugin there is. Using it, you can add queries to your notes to fetch information from your knowledge base.
|
||||
|
||||
To give you an idea of how powerful it is, take a look at these examples, taken directly from the [Obsidian Starter Kit](https://developassion.gumroad.com/l/obsidian-starter-kit):
|
||||
|
||||
Find quotes corresponding to a specific author:
|
||||
|
||||
<a id="fab4"></a>LIST FROM #quotes and \[\[<% tp.file.title %>\]\]
|
||||
SORT file.name ASC
|
||||
|
||||
Find recently modified notes:
|
||||
|
||||
<a id="0de0"></a>$=dv.list(dv.pages('').sort(f=>f.file.mtime.ts,"desc").limit(5).file.link)
|
||||
|
||||
Find orphan notes:
|
||||
|
||||
<a id="6f91"></a>TABLE file.ctime AS "updated"
|
||||
FROM "" WHERE length(file.inlinks) = 0
|
||||
AND length(file.outlinks) = 0
|
||||
AND length(file.tags) = 0
|
||||
AND file.name != "Orphans"
|
||||
SORT file.mtime desc
|
||||
|
||||
Find duplicate notes:
|
||||
|
||||
<a id="2cc3"></a>// Reference: https://github.com/claremacrae/obsidian-experiments-plugin/issues/1#issuecomment-1139556976
|
||||
function listFileNameIssues(dv) {
|
||||
let pages = dv.pages();
|
||||
let groups = pages.groupBy(p => p.file.name.toLowerCase());
|
||||
for (let group of groups) {
|
||||
let count = 0
|
||||
for (let page of group.rows.sort(p => p.file.path, 'asc')) {
|
||||
count += 1;
|
||||
}
|
||||
|
||||
if (count === 1 ) {
|
||||
continue;
|
||||
}
|
||||
|
||||
for (let page of group.rows.sort(p => p.file.path, 'asc')) {
|
||||
dv.paragraph(page.file.link + ': ' + page.file.path);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
listFileNameIssues(dv);
|
||||
|
||||
Pick random notes:
|
||||
|
||||
<a id="80f6"></a>const limit = 10;
|
||||
const notes = dv.pages().sort(() => Math.random()).slice (0, limit).map(note => note.file.link);
|
||||
dv.list(notes);
|
||||
|
||||
Count the number of notes:
|
||||
|
||||
<a id="f0fd"></a>$=dv.pages().length
|
||||
|
||||
And this is just the tip of the iceberg. Check out the [official documentation of the dataview plugin](https://blacksmithgu.github.io/obsidian-dataview/) for more details about its possibilities.
|
||||
|
||||
Link: https://github.com/blacksmithgu/obsidian-dataview
|
||||
|
||||
## Templater
|
||||
|
||||
The templater plugin is a powerful templating engine for Obsidian. It provides many functions to help you create really cool templates.
|
||||
|
||||
Here’s an example, again taken from the [Obsidian Starter Kit](https://developassion.gumroad.com/l/obsidian-starter-kit) which uses the Templater plugin extensively:
|
||||
|
||||
<a id="26ac"></a>\-\-\-
|
||||
tags:
|
||||
\- weekly_notes
|
||||
\-\-\-
|
||||
|
||||
\# <% tp.file.title %>
|
||||
<< \[\[<% tp.date.now("YYYY-\[W\]WW", "P-1W") %>\]\] | \[\[<% tp.date.now("YYYY-\[W\]WW", "P+1W") %>\]\] >>
|
||||
Current month: \[\[<% tp.date.now("YYYY-MM") %>\]\] | Next month: \[\[<% tp.date.now("YYYY-MM", "P+1M") %>\]\]
|
||||
Year note: \[\[<% tp.date.now("YYYY") %>\]\]
|
||||
|
||||
\## Goals
|
||||
-
|
||||
|
||||
\## Achievements
|
||||
-
|
||||
|
||||
\## Discoveries
|
||||
\### \[\[<% tp.date.now("YYYY-MM-DD") %>\]\]
|
||||
-
|
||||
|
||||
\### \[\[<% tp.date.now("YYYY-MM-DD", 1) %>\]\]
|
||||
-
|
||||
|
||||
\### \[\[<% tp.date.now("YYYY-MM-DD", 2) %>\]\]
|
||||
-
|
||||
|
||||
\### \[\[<% tp.date.now("YYYY-MM-DD", 3) %>\]\]
|
||||
-
|
||||
|
||||
\### \[\[<% tp.date.now("YYYY-MM-DD", 4) %>\]\]
|
||||
-
|
||||
|
||||
\### \[\[<% tp.date.now("YYYY-MM-DD", 5) %>\]\]
|
||||
-
|
||||
|
||||
\### \[\[<% tp.date.now("YYYY-MM-DD", 6) %>\]\]
|
||||
-
|
||||
|
||||
\## Challenges
|
||||
-
|
||||
|
||||
\## Gratitude
|
||||
-
|
||||
|
||||
Once you have created a template, you can easily add it to any note using the `ALT/Cmd + E` shortcut.
|
||||
|
||||
Take a look at the [Templater plugin reference documentation](https://silentvoid13.github.io/Templater/) to learn more about its capabilities.
|
||||
|
||||
Link: https://github.com/SilentVoid13/Templater
|
||||
|
||||
## Auto Note Mover
|
||||
|
||||
The Auto Note Mover is one of my favorite Obsidian plugin. It provides a way to automatically move notes around within your knowledge base. This is great as it removes the need to manually file notes.
|
||||
|
||||
Link: https://github.com/farux/obsidian-auto-note-mover
|
||||
|
||||

|
||||
Auto Note Mover rules
|
||||
|
||||
## Homepage
|
||||
|
||||
The homepage plugin does exactly what it says: it lets you create a homepage for your knowledge base. I personally rely on this plugin to create my productivity dashboard. The homepage is just a note like any other, meaning that you can add whatever you want to it: text, titles, images, tasks, dataview queries, etc.
|
||||
|
||||
Link: https://github.com/mirnovov/obsidian-homepage
|
||||
|
||||
## Kanban
|
||||
|
||||
This plugin makes it possible to create [Kanban boards](https://en.wikipedia.org/wiki/Kanban_board) in Obsidian. Thanks to this plugin, you could manage your entire todo list within Obsidian instead of using other tools such as Trello.
|
||||
|
||||
Link: https://github.com/mgmeyers/obsidian-kanban
|
||||
|
||||

|
||||
A Kanban board
|
||||
|
||||
## Paste image renamer
|
||||
|
||||
The Paste image renamer allows you to rename images and attachments when you add those to your Obsidian vault. This is a must-have.
|
||||
|
||||
Link: https://github.com/reorx/obsidian-paste-image-rename
|
||||
|
||||

|
||||
Adding an image with the Paste image renamer plugin
|
||||
|
||||
## Linter
|
||||
|
||||
This Obsidian plugin formats and styles notes automatically, based on the rules you configure. This helps a lot to maintain a consistent knowledge base.
|
||||
|
||||
Link: https://github.com/platers/obsidian-linter
|
||||
|
||||
## Tag Wrangler
|
||||
|
||||
==The Tag Wrangler plugin helps you rename, merge, toggle, and search tags from the Obsidian tag pane.==
|
||||
|
||||
Link: https://github.com/pjeby/tag-wrangler
|
||||
|
||||

|
||||
Managing tags with the Tag wrangler plugin
|
||||
|
||||
## Text transporter
|
||||
|
||||
The Text Transporter plugin is a Swiss Army Knife of text manipulation for Obsidian. Clearly a must-have to apply transformations to your notes.
|
||||
|
||||
Link: https://github.com/TfTHacker/obsidian42-text-transporter
|
||||
|
||||
## Notes refactor
|
||||
|
||||
This plugin lets you copy/extract text selections from a note into other ones. It completements the features offered by the text transporter plugin.
|
||||
|
||||
Link: https://github.com/lynchjames/note-refactor-obsidian
|
||||
|
||||
## Various complements
|
||||
|
||||
This plugin boosts productivity by automatically completing what you type, proposing to add links when some text matches the title of a note, etc.
|
||||
|
||||
Link: https://github.com/tadashi-aikawa/obsidian-various-complements-plugin
|
||||
|
||||

|
||||
Auto-completion with the Various complements plugin
|
||||
|
||||
## Tasks
|
||||
|
||||
The Obsidian Tasks plugin helps you track tasks across your Obsidian vault. It supports due dates, recurring tasks, querying, filtering, etc. This plugin, combined with the Kanban plugin is a killer combo.
|
||||
|
||||
Check out the [official plugin documentation](https://obsidian-tasks-group.github.io/obsidian-tasks/) for more details.
|
||||
|
||||
Link: https://github.com/obsidian-tasks-group/obsidian-tasks
|
||||
|
||||
## Extract URL
|
||||
|
||||
This plugin makes it really easy to capture external content into Obsidian. It extracts Markdown compatible with Obsidian out of URLs. Thanks to this plugin, you can paste the URL of a Website in an Obsidian note, invoke a command, and have the URL be replaced by the content converted into Markdown.
|
||||
|
||||
Link: https://github.com/trashhalo/obsidian-extract-url
|
||||
|
||||
Estracting markdown from URLs
|
||||
|
||||
## Find unlinked files
|
||||
|
||||
This plugin enables you to quickly identify orphaned notes (i.e., notes with no backlinks) and notes with broken links.
|
||||
|
||||
Link: https://github.com/Vinzent03/find-unlinked-files
|
||||
|
||||
## Natural language dates
|
||||
|
||||
This plugin allows you to use natural language dates more easily.
|
||||
|
||||
Link: https://github.com/argenos/nldates-obsidian
|
||||
|
||||
Processing natural language dates
|
||||
|
||||
## Excalidraw
|
||||
|
||||
This plugin integrates [Excalidraw](https://excalidraw.com/). This provides a great way to create mind maps and other schemas.
|
||||
|
||||
Link: https://github.com/zsviczian/obsidian-excalidraw-plugin
|
||||
|
||||

|
||||
Excalidraw
|
||||
|
||||
## Mind Map
|
||||
|
||||
An Obsidian plugin for displaying markdown notes as mind maps using [Markmap](https://markmap.js.org/).
|
||||
|
||||
Link: https://github.com/lynchjames/obsidian-mind-map
|
||||
|
||||

|
||||
Example of a note turned into a Mind Map
|
||||
|
||||
## Outliner
|
||||
|
||||
Allows you to work with your lists exactly like in Workflowy, RoamResearch or LogSeq
|
||||
|
||||
Link: https://github.com/vslinko/obsidian-outliner
|
||||
|
||||
Outliner plugin in action
|
||||
|
||||
## Image in editor
|
||||
|
||||
Enables you to view Images, Transclusions, iFrames and PDF Files within the Editor without a necessity to switch to the Preview mode.
|
||||
|
||||
Link: https://github.com/ozntel/oz-image-in-editor-obsidian
|
||||
|
||||
## Recent files
|
||||
|
||||
Display a list of most recently opened files.
|
||||
|
||||
Link: https://github.com/tgrosinger/recent-files-obsidian
|
||||
|
||||
## Table editor
|
||||
|
||||
An editor for Markdown tables. It can open CSV data and data from Microsoft Excel, Google Sheets, Apple Numbers and LibreOffice Calc as Markdown tables from Obsidian Markdown editor.
|
||||
|
||||
Link: https://github.com/ganesshkumar/obsidian-table-editor
|
||||
|
||||
## Smart random note
|
||||
|
||||
This plugin adds a way to open a random note based on the list of search results. This is a great addition to explore your knowledge base randomly (always useful to re-discover old/forgotten notes)
|
||||
|
||||
Link: https://github.com/erichalldev/obsidian-smart-random-note
|
||||
|
||||
## Zoom
|
||||
|
||||
This plugin lets you “zoom” into headings and lists. This makes it much easier to focus on specific parts of long notes.
|
||||
|
||||
Link: https://github.com/vslinko/obsidian-zoom
|
||||
|
||||
The Zoom plugin in action
|
||||
|
||||
## Doubleshift
|
||||
|
||||
Obsidian Plugin to open the command palette by pressing shift twice. Software developers will love this one!
|
||||
|
||||
Link: https://github.com/Qwyntex/doubleshift
|
||||
|
||||
## Vault statistics
|
||||
|
||||
Status bar item with vault statistics such as number of notes, files, attachments, and links.
|
||||
|
||||
Link: https://github.com/bkyle/obsidian-vault-statistics-plugin
|
||||
|
||||
## Tomorrow’s daily note
|
||||
|
||||
Easily open tomorrow’s daily note
|
||||
|
||||
Link: https://github.com/frankolson/obsidian-tomorrows-daily-note
|
||||
|
||||
## Obsidian Git
|
||||
|
||||
Backup your Obsidian.md vault with git. A bit technical but really valuable!
|
||||
|
||||
Link: https://github.com/denolehov/obsidian-git
|
||||
|
||||
## And more…
|
||||
|
||||
There are many other really interesting plugins for Obsidian. Here are some you might want to check out as well:
|
||||
|
||||
- Admonition: https://github.com/valentine195/obsidian-admonition
|
||||
- Banners: https://github.com/noatpad/obsidian-banners
|
||||
- Day Planner: https://github.com/lynchjames/obsidian-day-planner
|
||||
- Emotion picker: https://github.com/dartungar/obsidian-emotion-picker
|
||||
- Icon shortcodes: https://github.com/aidenlx/obsidian-icon-shortcodes
|
||||
- Kindle: https://github.com/hadynz/obsidian-kindle-plugin
|
||||
- Simple embeds: https://github.com/samwarnick/obsidian-simple-embeds
|
||||
- Review: https://github.com/ryanjamurphy/review-obsidian
|
||||
- Syntax highlight: https://github.com/deathau/cm-editor-syntax-highlight-obsidian
|
||||
- Page count: https://github.com/ReaderGuy42/Obsidian-Page-Count
|
||||
- Reading time: https://github.com/avr/obsidian-reading-time
|
||||
- Better word count: https://github.com/lukeleppan/better-word-count
|
||||
- Dialogue: https://github.com/holubj/obsidian-dialogue-plugin
|
||||
|
||||
## Conclusion
|
||||
|
||||
In this article, I’ve listed the best Obsidian plugins I know of, and then some. The Obsidian developer community is large and very productive. The plugin ecosystem of Obsidian adds a ton of value and really deserves your time and attention. Check those plugins out and tell me which ones you love most. I’m also curious about which plugins you think I should add to this list!
|
||||
|
||||
That’s it for today! ✨
|
||||
|
||||
## About Sébastien
|
||||
|
||||
Hello everyone! I’m Sébastien Dubois. I’m an author, founder, and CTO. I write books and articles about personal knowledge management (PKM), personal organization, software development & IT, and productivity. I also craft lovely digital products 🚀
|
||||
|
||||
If you’ve enjoyed this article and want to read more, then subscribe to [my newsletter](https://newsletter.dsebastien.net/), check out my [PKM Library](https://developassion.gumroad.com/l/PersonalKnowledgeManagementLibrary), and the [Obsidian Starter Kit](https://developassion.gumroad.com/l/obsidian-starter-kit) 🔥.
|
||||
@@ -0,0 +1,14 @@
|
||||
---
|
||||
title: Update list of domains for LetsEncrypt certificates
|
||||
updated: 2022-10-09 17:38:01Z
|
||||
created: 2021-05-07 13:15:33Z
|
||||
tags:
|
||||
- IT/LetsEncrypt
|
||||
- Apache
|
||||
- Webserver
|
||||
---
|
||||
|
||||
Das folgende Kommando erweitert die Liste der Domains und/oder aktualisiert die Zertifikate:
|
||||
```bash
|
||||
certbot certonly --webroot -w /var/www/html -d thpeetz.de -d gitlab.thpeetz.de -d jenkins.thpeetz.de -d sonar.thpeetz.de -d cloud.thpeetz.de -d kontor.thpeetz.de -d mattermost.thpeetz.de -d openkm.thpeetz.de -d typo3.thpeetz.de -d projects.thpeetz.de -d www.thpeetz.de -d kontor-test.thpeetz.de -d gitea.thpeetz.de -d nexus.thpeetz.de -d openproject.thpeetz.de
|
||||
```
|
||||
@@ -0,0 +1,220 @@
|
||||
---
|
||||
title: Vollständiges Handbuch zur Verwendung von AsciiDoc unter Linux - WebSetNet
|
||||
updated: 2020-04-13 18:11:27Z
|
||||
created: 2020-04-13 17:54:20Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Asciidoctor
|
||||
source: https://websetnet.net/de/complete-guide-using-asciidoc-linux/
|
||||
---
|
||||
|
||||
[Complete Guide](https://websetnet.net/de/complete-guide-using-asciidoc-linux/)
|
||||
|
||||
_**Kurz: Dieses detaillierte Handbuch beschreibt die Vorteile von AsciiDoc und zeigt Ihnen, wie Sie AsciiDoc in Linux installieren und verwenden.**_
|
||||
|
||||
Im Laufe der Jahre habe ich viele verschiedene Tools verwendet, um Artikel, Berichte oder Dokumentationen zu schreiben. Ich denke, alles begann für mich mit Luc Barthelets Epistole auf Apple IIc vom französischen Editor Version Soft. Dann wechselte ich zu GUI-Tools mit dem hervorragenden Microsoft Word 5 für Apple Macintosh, dann zu dem weniger überzeugenden (für mich) StarOffice unter Sparc Solaris, das bereits als OpenOffice bekannt war, als ich definitiv zu Linux wechselte. Alle diese Werkzeuge waren _wirklich_ [Textverarbeitungen](https://www.computerhope.com/jargon/w/wordssor.htm).
|
||||
|
||||
Aber ich wurde nie wirklich davon überzeugt [WYSIWYG](https://en.wikipedia.org/wiki/WYSIWYG) Redakteure. Also habe ich viele verschiedene mehr oder weniger menschenlesbare Textformate untersucht: [troff](https://en.wikipedia.org/wiki/Troff), [HTML](https://en.wikipedia.org/wiki/HTML), [RTF](https://en.wikipedia.org/wiki/Rich_Text_Format), [TeX](https://en.wikipedia.org/wiki/TeX)/[Latex](https://en.wikipedia.org/wiki/LaTeX), [XML](https://en.wikipedia.org/wiki/XML) und schlussendlich [AsciiDoc](https://en.wikipedia.org/wiki/AsciiDoc) Welches ist das Werkzeug, das ich heute am meisten verwende? Tatsächlich benutze ich es gerade, um diesen Artikel zu schreiben!
|
||||
|
||||
Wenn ich diese Geschichte geschrieben habe, war es, weil die Schleife irgendwie geschlossen ist. Epistole war ein Textverarbeitungsprogramm der Textkonsolen-Ära. Soweit ich mich erinnere, gab es Menüs, und Sie können mit der Maus Text auswählen. Der größte Teil der Formatierung erfolgte jedoch durch Hinzufügen nicht aufdringlicher Tags zum Text. Genau wie bei AsciiDoc. Natürlich war es nicht die erste Software, die das tat. Aber es war das erste, das ich benutzt habe!
|
||||
|
||||

|
||||
|
||||
## Warum AsciiDoc (oder ein anderes Textdateiformat)?
|
||||
|
||||
Ich sehe zwei Vorteile in der Verwendung von Textformaten für das Schreiben: Erstens gibt es eine klare Trennung zwischen dem Inhalt und der Präsentation. Dieses Argument ist offen für Diskussionen, da einige Textformate wie TeX oder HTML eine gute Disziplin erfordern, um diese Trennung einzuhalten. Und auf der anderen Seite können Sie mit der Verwendung eines gewissen Grades der Trennung erreichen [Vorlagen und Stylesheets](https://wiki.openoffice.org/wiki/Documentation/OOo3_User_Guides/Getting_Started/Templates_and_Styles) mit WYSIWYG-Editoren. Ich stimme dem zu. Trotzdem finde ich Präsentationsprobleme mit GUI-Tools aufdringlich. Wenn Sie Textformate verwenden, können Sie sich nur auf den Inhalt konzentrieren, ohne dass Sie beim Schreiben durch einen Schriftstil oder eine Witwenlinie gestört werden. Aber vielleicht bin es nur ich? Ich kann jedoch nicht zählen, wie oft ich mit dem Schreiben aufgehört habe, nur um ein kleines Stylingproblem zu beheben - und meine Inspiration verloren zu haben, als ich zum Text zurückkam. Wenn Sie nicht einverstanden sind oder eine andere Erfahrung haben, zögern Sie nicht, mir im Kommentarbereich unten zu widersprechen!
|
||||
|
||||
Jedenfalls wird mein zweites Argument weniger der persönlichen Interpretation unterliegen: Dokumente, die auf Textformaten basieren, sind hoch _interoperabel_. Nicht nur Sie können sie mit jedem Texteditor auf jeder Plattform bearbeiten, aber Sie können Textrevisionen mit einem Tool wie [git](https://en.wikipedia.org/wiki/Git) or [SVN](https://en.wikipedia.org/wiki/Apache_Subversion)oder automatisieren Sie Textänderung unter Verwendung der allgemeinen Werkzeuge wie [Durst](https://en.wikipedia.org/wiki/Sed), [AWK](https://en.wikipedia.org/wiki/AWK), [Perl](https://en.wikipedia.org/wiki/Perl) und so weiter. Um Ihnen ein konkretes Beispiel zu geben: Wenn Sie ein textbasiertes Format wie AsciiDoc verwenden, benötige ich nur einen Befehl, um ein hochgradig personalisiertes Mailing aus einem Masterdokument zu erstellen, während für denselben Job mit einem WYSIWYG-Editor eine geschickte Verwendung von „Feldern“ erforderlich gewesen wäre. und durch mehrere Assistentenbildschirme gehen.
|
||||
|
||||
## Was ist AsciiDoc?
|
||||
|
||||
Streng genommen ist AsciiDoc ein Dateiformat. Es definiert syntaktische Konstrukte, die einem Prozessor helfen, die Semantik der verschiedenen Teile Ihres Textes zu verstehen. Normalerweise, um eine schön formatierte Ausgabe zu erzeugen.
|
||||
|
||||
Auch wenn diese Definition abstrakt erscheinen mag, ist dies etwas Einfaches: Einige Schlüsselwörter oder Zeichen in Ihrem Dokument haben eine besondere Bedeutung, die das Rendering des Dokuments verändern. Dies ist das exakt gleiche Konzept wie die Tags in HTML. Ein Hauptunterschied zu AsciiDoc besteht jedoch darin, dass die Eigenschaft des Quelldokuments erhalten bleibt _leicht_ für Menschen lesbar.
|
||||
|
||||
Kariert [unser GitHub-Repository](https://github.com/itsfoss/asciidoc-intro/tree/master/coffee) Um zu vergleichen, wie die gleiche Ausgabe mit wenigen gemeinsamen Textdateien Format erzeugt werden kann: (Kaffee Manpage Idee mit freundlicher Genehmigung von [http://www.linuxjournal.com/article/1158](https://href.li/?http://www.linuxjournal.com/article/1158))
|
||||
|
||||
* `coffee.man` benutzt das ehrwürdige _troff_ Prozessor (basierend auf dem 1964 [ABFLIESSEN](https://en.wikipedia.org/wiki/TYPSET_and_RUNOFF) Programm). Es wird heute meistens zum Schreiben verwendet [Manpages](https://en.wikipedia.org/wiki/Man_page). Sie können es versuchen, nachdem Sie das heruntergeladen haben `Kaffee.*` Dateien durch Eingabe `Mann ./coffee.man` an Ihrer Eingabeaufforderung.
|
||||
* `Kaffee.tex` verwendet das _Latex_ Syntax (1985), um meist das gleiche Ergebnis zu erzielen, jedoch für eine PDF-Ausgabe. LaTeX ist ein Satzprogramm, das besonders für wissenschaftliche Publikationen geeignet ist, da es mathematische Formeln und Tabellen gut formatieren kann. Sie können das PDF mit der LaTeX-Quelle erstellen `pdflatex kaffee.tex`
|
||||
* `Kaffee.html` verwendet das HTML-Format (1991), um die Seite zu beschreiben. Sie können diese Datei direkt mit Ihrem bevorzugten Webbrowser öffnen, um das Ergebnis zu sehen.
|
||||
* `Kaffee.adoc`, schließlich, verwendet die AsciiDoc-Syntax (2002). Sie können sowohl HTML als auch PDF aus dieser Datei erzeugen:
|
||||
|
||||
```shell
|
||||
asciidoc coffee.adoc # HTML-Ausgabe a2x --format pdf ./coffee.adoc # PDF-Ausgabe (dblatex) a2x --fop --format pdf ./coffee.adoc # PDF-Ausgabe (Apache FOP)
|
||||
```
|
||||
|
||||
Nachdem Sie das Ergebnis gesehen haben, öffnen Sie diese vier Dateien mit Ihrem Favoriten [Texteditor](https://en.wikipedia.org/wiki/Text_editor) (nano, vim, SublimeText, gedit, Atom,…) und vergleichen Sie die Quellen: Es besteht eine große Wahrscheinlichkeit, dass Sie der Meinung sind, dass die AsciiDoc-Quellen leichter zu lesen sind - und wahrscheinlich auch zu schreiben sind.
|
||||
|
||||
## Wie installiere ich AsciiDoc unter Linux?
|
||||
|
||||
AsciiDoc ist aufgrund der vielen Abhängigkeiten relativ komplex zu installieren. Ich meine komplex, wenn Sie es aus Quellen installieren möchten. Für die meisten von uns ist die Verwendung unseres Paketmanagers wahrscheinlich der beste Weg:
|
||||
|
||||
```shell
|
||||
apt-get installieren asciidoc fop
|
||||
```
|
||||
|
||||
oder der folgende Befehl:
|
||||
|
||||
```shell
|
||||
yum installieren acsiidoc fop
|
||||
```
|
||||
|
||||
(FOP wird nur benötigt, wenn Sie die [Apache FOP](https://en.wikipedia.org/wiki/Formatting_Objects_Processor) Backend für die PDF-Generierung - dies ist das PDF-Backend, das ich selbst verwende)
|
||||
|
||||
Weitere Details zur Installation finden Sie unter [die offizielle AsciiDoc Webseite](https://href.li/?http://www.methods.co.nz/asciidoc/INSTALL.html). Im Moment brauchen Sie nur ein wenig Geduld, da die Installation von AsciiDoc zumindest auf meinem minimalen Debian-System erfordert, dass 360MB heruntergeladen wird (hauptsächlich wegen der LaTeX-Abhängigkeit). Welche, abhängig von Ihrer Internet-Bandbreite, Ihnen viel Zeit geben kann, um den Rest dieses Artikels zu lesen.
|
||||
|
||||
## AsciiDoc Tutorial: Wie schreibe ich in AsciiDoc?
|
||||
|
||||
Ich sagte es mehrmals, AsciiDoc ist ein Menschenlesbares _Textdateiformat_. So können Sie Ihre Dokumente mit dem Texteditor Ihrer Wahl schreiben. Es gibt sogar spezielle Texteditoren. Aber ich werde hier nicht darüber sprechen - einfach weil ich sie nicht benutze. Wenn Sie jedoch eine davon verwenden, zögern Sie nicht, Ihr Feedback über den Kommentarbereich am Ende dieses Artikels zu teilen.
|
||||
|
||||
Ich habe nicht vor, hier ein weiteres AsciiDoc-Syntax-Tutorial zu erstellen: Es gibt bereits viele davon im Web. Daher werde ich nur die sehr grundlegenden syntaktischen Konstrukte erwähnen, die Sie in praktisch jedem Dokument verwenden werden. Aus dem oben zitierten einfachen Beispiel für den Befehl „Kaffee“ können Sie Folgendes ersehen:
|
||||
|
||||
* **Titel** in AsciiDoc werden identifiziert, indem man sie mit zugrunde legt `===` or ```---``` (abhängig von der Titelebene),
|
||||
* **fett** Zeichenspannen werden zwischen Starts geschrieben,
|
||||
* und weiterführende **Kursivschrift** zwischen Unterstrichen.
|
||||
|
||||
Das sind ziemlich häufige Konventionen, die wahrscheinlich auf die Zeit vor der HTML-E-Mail zurückgehen. Außerdem benötigen Sie möglicherweise zwei andere häufige Konstrukte, die in meinem vorherigen Beispiel nicht dargestellt sind: **Hyperlinks** und weiterführende **Bilder** Einschluss, dessen Syntax ziemlich selbsterklärend ist.
|
||||
|
||||
```
|
||||
// Link Hypertext Links: https: //itsfoss.com [ItsFoss Linux Blog] // Inline Bilder image: https: //itsfoss.com/wp-content/uploads/2017/06/itsfoss-text-logo.png [ ItsFOSS Text Logo] // Bilder blockieren image :: https: //itsfoss.com/wp-content/uploads/2017/06/itsfoss-text-logo.png [ItsFOSS Text Logo]
|
||||
```
|
||||
|
||||
Aber die AsciiDoc-Syntax ist viel reicher. Wenn Sie mehr wollen, kann ich Sie auf diesen netten AsciiDoc Cheatsheet hinweisen: [http://powerman.name/doc/asciidoc](https://href.li/?http://powerman.name/doc/asciidoc)
|
||||
|
||||
## Wie rendert man die endgültige Ausgabe?
|
||||
|
||||
Ich gehe davon aus, dass Sie bereits einen Text nach dem AsciiDoc-Format geschrieben haben. Wenn dies nicht der Fall ist, können Sie herunterladen [Tauchen Sie hier in die Geschichten unserer zufriedenen Kunden ein](https://raw.githubusercontent.com/itsfoss/asciidoc-intro/master) einige Beispieldateien, die direkt aus der AsciiDoc-Dokumentation kopiert wurden:
|
||||
|
||||
```
|
||||
# Laden Sie das AsciiDoc-Benutzerhandbuch als Quelldokument herunter BASE = 'https: //raw.githubusercontent.com/itsfoss/asciidoc-intro/master' wget "$ {BASE}" / {asciidoc.txt, customers.csv}
|
||||
```
|
||||
|
||||
Seit AsciiDoc ist _für Menschen lesbar_Sie können den AsciiDoc-Quelltext direkt per E-Mail an jemanden senden, und der Empfänger kann diese Nachricht ohne weiteres lesen. Möglicherweise möchten Sie jedoch eine besser formatierte Ausgabe bereitstellen. Zum Beispiel als HTML für die Webpublikation (genau wie ich es für diesen Artikel getan habe). Oder als PDF zum Drucken oder Anzeigen.
|
||||
|
||||
In allen Fällen benötigen Sie eine _Prozessor_. In der Tat benötigen Sie unter der Haube mehrere Prozessoren. Weil Ihr AsciiDoc-Dokument in verschiedene Zwischenformate umgewandelt wird, bevor die endgültige Ausgabe erstellt wird. Da mehrere Werkzeuge verwendet werden, sprechen wir manchmal von einem Ausgang, von dem eines der Eingang des nächsten ist _Werkzeugkette_.
|
||||
|
||||
Selbst wenn ich hier einige innere Arbeitsdetails erkläre, müssen Sie verstehen, dass das meiste davon vor Ihnen verborgen bleibt. Es sei denn, Sie müssen die Tools zunächst installieren - oder Sie möchten einige Schritte des Prozesses optimieren.
|
||||
|
||||
### In der Praxis?
|
||||
|
||||
Für die HTML-Ausgabe benötigen Sie nur die `Asciidoc` Werkzeug. Für kompliziertere Toolchains empfehle ich dir, die `a2x` Tool (Teil der AsciiDoc-Distribution), das die erforderlichen Prozessoren in der folgenden Reihenfolge auslöst:
|
||||
|
||||
```
|
||||
# Alle Beispiele basieren auf dem AsciiDoc Benutzerhandbuch Quelldokument # HTML Ausgabe asciidoc asciidoc.txt firefox asciidoc.html # XHTML Ausgabe a2x --format = xhtml asciidoc.txt # PDF Ausgabe (LaTeX Prozessor) a2x --format = pdf asciidoc. txt # PDF-Ausgabe (FOP-Prozessor) a2x --fop --format = pdf asciidoc.txt
|
||||
```
|
||||
|
||||
Auch wenn es direkt eine HTML-Ausgabe erzeugen kann, ist die Kernfunktionalität des `Asciidoc` Werkzeug bleibt übrig, um das AsciiDoc-Dokument in das Zwischenprodukt zu transformieren [DocBook](https://en.wikipedia.org/wiki/DocBook) Format. DocBook ist ein XML-basiertes Format, das häufig für die Veröffentlichung von technischen Dokumentationen verwendet wird (aber nicht darauf beschränkt ist). DocBook ist ein semantisches Format. Das heißt, es beschreibt Ihren Dokumentinhalt. Aber _nicht_ seine Präsentation. Die Formatierung wird also der nächste Schritt der Transformation sein. Unabhängig davon, welches Ausgabeformat verwendet wird, wird das DocBook-Zwischendokument über ein [XSLT](https://en.wikipedia.org/wiki/XSLT) Prozessor, um entweder direkt die Ausgabe (z. B. XHTML) oder ein anderes Zwischenformat zu erzeugen.
|
||||
|
||||
Dies ist der Fall, wenn Sie ein PDF-Dokument erzeugen, bei dem das DocBook-Dokument (nach Ihrem Wunsch) entweder als LaTeX-Zwischendarstellung oder als umgewandelt wird [XSL-FO](https://en.wikipedia.org/wiki/XSL_Formatting_Objects) (eine XML-basierte Sprache für die Seitenbeschreibung). Schließlich wird ein dediziertes Tool diese Darstellung in PDF konvertieren.
|
||||
|
||||
Die zusätzlichen Schritte für PDF-Generationen sind insbesondere dadurch gerechtfertigt, dass die Toolchain die Paginierung für die PDF-Ausgabe verarbeiten muss. Dies ist für ein Stream-Format wie HTML nicht erforderlich.
|
||||
|
||||
### dblatex oder fop?
|
||||
|
||||
Da es zwei PDF-Backends gibt, ist die übliche Frage _"Welches ist das Beste?"_ Etwas, das ich nicht für dich beantworten kann.
|
||||
|
||||
Beide Prozessoren haben [Vor-und Nachteile](https://href.li/?http://www.methods.co.nz/asciidoc/userguide.html#_pdf_generation). Und letztendlich wird die Wahl ein Kompromiss zwischen Ihren Bedürfnissen und Ihrem Geschmack sein. Ich ermutige Sie daher, sich die Zeit zu nehmen, beide zu testen, bevor Sie das Backend auswählen, das Sie verwenden werden. Wenn Sie dem LaTeX-Pfad folgen, [dblatex](https://href.li/?http://dblatex.sourceforge.net/) wird das Backend sein, das verwendet wird, um das PDF zu erzeugen. Während es sein wird [Apache FOP](https://xmlgraphics.apache.org/fop/) Wenn Sie das XSL-FO-Zwischenformat bevorzugen. Vergessen Sie also nicht, die Dokumentation dieser Tools zu lesen, um zu sehen, wie einfach es sein wird, die Ausgabe an Ihre Bedürfnisse anzupassen. Es sei denn natürlich, Sie sind mit der Standardausgabe zufrieden!
|
||||
|
||||
## Wie kann ich die Ausgabe von AsciiDoc anpassen?
|
||||
|
||||
### AsciiDoc zu HTML
|
||||
|
||||
Out-of-the-Box, AsciiDoc produziert ziemlich schöne Dokumente. Aber früher oder später wirst du ihr Aussehen anpassen.
|
||||
|
||||
Die genauen Änderungen hängen vom verwendeten Backend ab. Für die HTML-Ausgabe können die meisten Änderungen durch Ändern der [CSS](https://en.wikipedia.org/wiki/Cascading_Style_Sheets) Stylesheet, das dem Dokument zugeordnet ist.
|
||||
|
||||
Angenommen, ich möchte alle Abschnittsüberschriften in Rot anzeigen. Ich könnte Folgendes erstellen `custom.css` Datei:
|
||||
|
||||
```
|
||||
h2 {Farbe: rot; }
|
||||
```
|
||||
|
||||
Und bearbeiten Sie das Dokument mit dem leicht modifizierten Befehl:
|
||||
|
||||
```
|
||||
# Setzen Sie das Attribut 'stylesheet' auf # den absoluten Pfad zu unserer benutzerdefinierten CSS-Datei asciidoc -a stylesheet = $ PWD / custom.css asciidoc.txt
|
||||
```
|
||||
|
||||
Sie können Änderungen auch auf einer feineren Ebene vornehmen, indem Sie a hinzufügen _Rolle_ Attribut zu einem Element. Dies wird übersetzt in ein _Klasse_ Attribut im generierten HTML.
|
||||
|
||||
Versuchen Sie beispielsweise, unser Testdokument so zu ändern, dass das Rollenattribut dem ersten Absatz des Textes hinzugefügt wird:
|
||||
|
||||
```
|
||||
[role = "Zusammenfassung"] AsciiDoc ist ein Textdokumentformat ....
|
||||
```
|
||||
|
||||
Fügen Sie dann der folgenden Regel die folgende hinzu `custom.css` Datei:
|
||||
|
||||
```
|
||||
.summary {font-style: kursiv; }
|
||||
```
|
||||
|
||||
Erneutes Generieren des Dokuments:
|
||||
|
||||
```
|
||||
asciidoc -a stylesheet = $ PWD / custom.css asciidoc.txt
|
||||
```
|
||||
|
||||
[](https://websetnet.b-cdn.net/wp-content/uploads/2018/10/unnamed-file-252.png)
|
||||
|
||||
1. et voila: Der erste Absatz wird jetzt kursiv angezeigt. Mit ein bisschen Kreativität, etwas Geduld und ein paar CSS-Tutorials, sollten Sie in der Lage sein, Ihr Dokument nach Ihrem Willen anzupassen.
|
||||
|
||||
### AsciiDoc zu PDF
|
||||
|
||||
Das Anpassen der PDF-Ausgabe ist etwas komplexer. Nicht aus Sicht des Autors, da der Quelltext identisch bleibt. Verwenden Sie schließlich dasselbe Rollenattribut wie oben, um die Teile zu identifizieren, die einer speziellen Behandlung bedürfen.
|
||||
|
||||
Sie können CSS jedoch nicht mehr verwenden, um die Formatierung für die PDF-Ausgabe zu definieren. Für die gebräuchlichsten Einstellungen gibt es Parameter, die Sie über die Befehlszeile einstellen können. Einige Parameter können sowohl mit der _dblatex_ und die _Geck_ Backends, andere sind spezifisch für jedes Backend.
|
||||
|
||||
Eine Liste der unterstützten dblatex-Parameter finden Sie unter [http://dblatex.sourceforge.net/doc/manual/sec-params.html](https://href.li/?http://dblatex.sourceforge.net/doc/manual/sec-params.html)
|
||||
|
||||
Eine Liste der DocBook XSL-Parameter finden Sie unter [http://docbook.sourceforge.net/release/xsl/1.75.2/doc/param.html](https://href.li/?http://docbook.sourceforge.net/release/xsl/1.75.2/doc/param.html)
|
||||
|
||||
Da die Margin-Anpassung eine ziemlich häufige Anforderung ist, sollten Sie sich das auch ansehen: [http://docbook.sourceforge.net/release/xsl/current/doc/fo/general.html](https://href.li/?http://docbook.sourceforge.net/release/xsl/current/doc/fo/general.html)
|
||||
|
||||
Wenn die Parameternamen zwischen den beiden Backends etwas konsistent sind, unterscheiden sich die Befehlszeilenargumente, die verwendet werden, um diese Werte an die Backends zu übergeben _dblatex_ und weiterführende _Geck_. Überprüfen Sie also zuerst Ihre Syntax, wenn dies anscheinend nicht funktioniert. Aber um ehrlich zu sein, konnte ich beim Schreiben dieses Artikels das nicht schaffen `body.font.family` Parameter arbeiten mit dem _dblatex_ Backend. Da benutze ich normalerweise _Geck_Vielleicht habe ich etwas verpasst? Wenn Sie mehr Hinweise dazu haben, werde ich mehr als glücklich sein, Ihre Vorschläge im Kommentarbereich am Ende dieses Artikels zu lesen!
|
||||
|
||||
Erwähnenswert ist die Verwendung von nicht standardmäßigen Schriftarten - auch mit _Geck_–Erfordern Sie zusätzliche Arbeit. Aber es ist ziemlich gut auf der Apache-Website dokumentiert: [https://xmlgraphics.apache.org/fop/trunk/fonts.html#bulk](https://xmlgraphics.apache.org/fop/trunk/fonts.html#bulk)
|
||||
|
||||
```
|
||||
# XSL-FO / FOP a2x -v --format pdf --fop --xsltproc-opts = '- stringparam page.margin.inner 10cm' --xsltproc-opts = '- stringparam body.font.family Helvetica' --xsltproc-opts = '- stringparam body.font.size 8pt' asciidoc.txt # dblatex # (body.font.family _should_ funktioniert, aber anscheinend nicht?!?) a2x -v --format pdf --dblatex-opts = '- Parameter page.margin.inner = 10cm' --dblatex-opts = '- stringparam body.font.family Helvetica' asciidoc.txt
|
||||
```
|
||||
|
||||
### Feinkörnige Einstellung für die PDF-Erzeugung
|
||||
|
||||
Globale Parameter sind nett, wenn Sie nur einige vordefinierte Einstellungen anpassen müssen. Wenn Sie jedoch das Dokument fein abstimmen oder das Layout komplett ändern möchten, benötigen Sie zusätzliche Anstrengungen.
|
||||
|
||||
Im Kern der DocBook-Verarbeitung gibt es [XSLT](https://en.wikipedia.org/wiki/XSLT). XSLT ist eine Computersprache, ausgedrückt in XML-Notation, die es ermöglicht, eine beliebige Transformation von einem XML-Dokument in… etwas anderes zu schreiben. XML oder nicht.
|
||||
|
||||
Zum Beispiel müssen Sie das erweitern oder ändern [DocBook XSL Stylesheet](https://href.li/?http://www.sagehill.net/docbookxsl/) um den XSL-FO-Code für die neuen Stile zu erstellen, die Sie möchten. Und wenn du das benutzt _dblatex_ Im Backend muss dazu eventuell das entsprechende DocBook-to-LaTeX XSLT Stylesheet modifiziert werden. In diesem Fall müssen Sie möglicherweise auch ein benutzerdefiniertes LaTeX-Paket verwenden. Aber darauf werde ich mich nicht konzentrieren _dblatex_ ist nicht das Backend, das ich selbst benutze. Ich kann dich nur auf das hinweisen [offizielle Dokumentation](https://href.li/?http://dblatex.sourceforge.net/doc/manual/sec-custom.html) wenn du mehr wissen willst. Aber noch einmal, wenn Sie damit vertraut sind, teilen Sie bitte Ihre Tipps und Tricks im Kommentarbereich!
|
||||
|
||||
Auch wenn nur auf konzentriert _Geck_Ich habe hier nicht wirklich den Raum, um den gesamten Vorgang zu beschreiben. Daher zeige ich Ihnen nur die Änderungen, mit denen Sie ein ähnliches Ergebnis erzielen können wie mit wenigen CSS-Zeilen in der obigen HTML-Ausgabe. Das heißt: Abschnittsüberschriften in rot und a _Zusammenfassung_ Absatz in Kursivschrift.
|
||||
|
||||
Der Trick, den ich hier verwende, besteht darin, ein neues XSLT-Stylesheet zu erstellen, das das ursprüngliche DocBook-Stylesheet importiert, aber die Attributsätze oder Vorlagen für die Elemente, die wir ändern wollen, überschreibt:
|
||||
|
||||
```
|
||||
<? xml version = '1.0'?> <xsl: stylesheet xmlns: xsl = "http://www.w3.org/1999/XSL/Transform" xmlns: exsl = "http://exslt.org/common" exclude-result-prefixes = "exsl" xmlns: fo = "http://www.w3.org/1999/XSL/Format" version = '1.0'> <! - Importieren Sie das standardmäßige DocBook Stylesheet für XSL-FO - -> <xsl: import href = "/ etc / asciidoc / docbook-xsl / fo.xsl" /> <! - DocBook XSL definiert viele Attributgruppen, mit denen Sie die Ausgabeelemente steuern können -> <xsl: attribute- set name = "section.title.level1.properties"> <xsl: attribute name = "farbe"> # FF0000 </ xsl: attribute> </ xsl: attribute-set> <! - Für feinkörnige Änderungen muss XSLT-Templates schreiben oder überschreiben, wie ich es unten für 'Zusammenfassung' simpara (Absätze) getan habe -> <xsl: template match = "simpara [@ role = 'summary']"> <! - Capture geerbtes Ergebnis -> <xsl: variable name = "basesult"> <xsl: apply-imports /> </ xsl: variable> <! - Passen Sie das Ergebnis an -> <xsl: for-each select = "exsl: node- set ($ basesult) / node () "> <xsl: kopieren> <xsl: copy-of select =" @ * "/> <xsl: a attribute name = "font-style"> kursiv </ xsl: attribut> <xsl: copy-of select = "knoten ()" /> </ xsl: copy> </ xsl: for-each> </ xsl: template > </ xsl: stylesheet>
|
||||
```
|
||||
|
||||
Dann müssen Sie anfordern `a2x` Verwenden Sie das benutzerdefinierte XSL-Stylesheet, um die Ausgabe zu erstellen, anstatt die Standardausgabe mithilfe der `--xsl-Datei` Option:
|
||||
|
||||
```
|
||||
a2x -v --format pdf --fop --xsl-datei =. / custom.xsl asciidoc.txt
|
||||
```
|
||||
|
||||
[](https://websetnet.b-cdn.net/wp-content/uploads/2018/10/unnamed-file-253.png)
|
||||
|
||||
Mit ein wenig Vertrautheit mit XSLT, den hier gegebenen Hinweisen und einigen Fragen zu Ihrer bevorzugten Suchmaschine sollten Sie in der Lage sein, mit der Anpassung der XSL-FO-Ausgabe zu beginnen.
|
||||
|
||||
Aber ich werde nicht lügen, einige scheinbar einfache Änderungen in der Dokumentenausgabe erfordern möglicherweise, dass Sie einige Zeit damit verbringen, die DocBook XML- und XSL-FO-Handbücher zu durchsuchen, die Stylesheet-Quellen zu untersuchen und einige Tests durchzuführen, bevor Sie schließlich das erreichen, was Sie wollen .
|
||||
|
||||
## Meine Meinung
|
||||
|
||||
Das Schreiben von Dokumenten mit einem Textformat hat enorme Vorteile. Und wenn Sie in HTML veröffentlichen müssen, gibt es nicht viel Grund dafür _nicht_ mit AsciiDoc. Die Syntax ist sauber und ordentlich, die Verarbeitung ist einfach und das Ändern der Präsentation bei Bedarf erfordert meist einfach zu erlernende CSS-Kenntnisse.
|
||||
|
||||
Und selbst wenn Sie die HTML-Ausgabe nicht direkt verwenden, kann HTML heute mit vielen WYSIWYG-Anwendungen als Austauschformat verwendet werden. Als Beispiel habe ich dies hier getan: Ich habe die HTML-Ausgabe dieses Artikels in den WordPress-Editionsbereich kopiert und so die gesamte Formatierung beibehalten, ohne etwas direkt in WordPress eingeben zu müssen.
|
||||
|
||||
Wenn Sie als PDF veröffentlichen müssen, bleiben die Vorteile für den Verfasser gleich. Die Dinge werden sicherlich schwieriger, wenn Sie das Standardlayout in der Tiefe ändern müssen. In einem Unternehmensumfeld bedeutet dies wahrscheinlich, dass Sie ein mit XSLT qualifiziertes Dokument einstellen, um die Stylesheets zu erstellen, die Ihrem Branding oder Ihren technischen Anforderungen entsprechen - oder dass jemand im Team diese Fähigkeiten erwerben kann. Sobald dies erledigt ist, wird es eine Freude sein, Text mit AsciiDoc zu schreiben. Und sehen, wie diese Schriften automatisch in schöne HTML-Seiten oder PDF-Dokumente konvertiert werden!
|
||||
|
||||
Wenn Sie schließlich AsciiDoc entweder zu einfach oder zu komplex finden, können Sie sich einige andere Dateiformate mit ähnlichen Zielen ansehen: [Markdown](https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet), [Textil-](https://txstyle.org/), [reStructuredText](https://href.li/?http://docutils.sourceforge.net/docs/user/rst/quickstart.html) or [AsciiDoctor](https://href.li/?http://asciidoctor.org/) um nur einige zu nennen. Auch wenn es auf Konzepten basiert, die bis in die frühen Tage der Computerverarbeitung zurückreichen, ist das von Menschen lesbare Textformat-Ökosystem ziemlich reichhaltig. Wahrscheinlich reicher war es nur 20 Jahren. Als Beweis, viele moderne [statische Website-Generatoren](https://www.smashingmagazine.com/2015/11/modern-static-website-generators-next-big-thing/) basieren auf ihnen. Leider ist dies für diesen Artikel nicht möglich. Also lassen Sie es uns wissen, wenn Sie mehr darüber erfahren möchten!
|
||||
|
||||
[Frequenz](https://itsfoss.com/asciidoc-guide/)
|
||||
@@ -0,0 +1,56 @@
|
||||
---
|
||||
title: What are GitLab Flow best practices?
|
||||
updated: 2023-04-04 08:41:06Z
|
||||
created: 2023-04-04 08:41:06Z
|
||||
tags:
|
||||
- IT
|
||||
- IT/Tools/Gitlab
|
||||
source: >-
|
||||
https://about.gitlab.com/topics/version-control/what-are-gitlab-flow-best-practices/
|
||||
---
|
||||
|
||||
When software development teams rush to accelerate delivery, they may end up with messy or complex workflows. Organizations that have transitioned from another [version control](https://about.gitlab.com/topics/version-control/) system are especially likely to deal with challenging processes that may slow down development. When teams use [GitLab Flow](https://about.gitlab.com/topics/version-control/what-is-gitlab-flow/), they can use feature driven development and feature branches with issue tracking to ensure every team member works efficiently. Using these GitLab Flow tips, software development teams can simplify the process and produce a more efficient and cleaner outcome.
|
||||
|
||||
**1\. Use feature branches rather than direct commits on the main branch.**
|
||||
|
||||
Using feature branches is a simple way to develop and keep the [source code](https://about.gitlab.com/stages-devops-lifecycle/source-code-management/) clean. If a team has recently transitioned to Git from SVN, for example, they’ll be used to a trunk-based workflow. When using Git, developers should create a branch for anything they’re working on so that contributors can easily start the [code review process](https://about.gitlab.com/topics/version-control/what-is-code-review/) before merging.
|
||||
|
||||
**2\. Test all commits, not only ones on the main branch.**
|
||||
|
||||
Some developers set up their CI to only test what has been merged into the `main` branch, but this is too late in the software development lifecyle, and everyone - from developers to product managers - should feel feel confident that the `main` branch always has green tests. It’s inefficient for developers to have to test `main` before they start developing new features.
|
||||
|
||||
**3\. Run every test on all commits. (If tests run longer than 5 minutes, they can run in parallel.)**
|
||||
|
||||
When working on a `feature` branch and adding new commits, run tests right away. If the tests are taking a long time, try running them in parallel. Do this server-side in merge requests, running the complete test suite. If there is a test suite for development and another only for new versions, it’s worthwhile to set up \[parallel\] tests and run them all.
|
||||
|
||||
**4\. Perform code reviews before merging into the main branch.**
|
||||
|
||||
Don’t test everything at the end of a week or project. Code reviews should take place as soon as possible, because developers are more likely to identify issues that could cause problems later in the lifecycle. Since they’ll find problems earlier, they’ll have an easier time creating solutions.
|
||||
|
||||
**5\. Deployments are automatic based on branches or tags.**
|
||||
|
||||
If developers don’t want to deploy `main` every time, they can create a `production` branch. Rather than using a script or doing it manually, teams can use automation or have a specific branch that triggers a [production deploy](https://docs.gitlab.com/ee/ci/yaml/#environment).
|
||||
|
||||
**6\. Tags are set by the user, not by CI.**
|
||||
|
||||
Developers should use `tags` so that the CI will perform an action rather than having the CI change the repository. If teams require detailed metrics, they should have a server report detailing new versions.
|
||||
|
||||
**7\. Releases are based on tags.**
|
||||
|
||||
Each tag should create a new release. This practice ensures a clean, efficient development environment.
|
||||
|
||||
**8\. Pushed commits are never rebased.**
|
||||
|
||||
When pushing to a public branch, developers shouldn’t rebase it, because that makes it difficult to identify the improvement and test results, while [cherry picking](https://git-scm.com/docs/git-cherry-pick). Sometimes this tip can be ignored when asking someone to squash and rebase at the end of a code review process to make something easier to revert. However, in general, the guideline is: Code should be clean, and history should be realistic.
|
||||
|
||||
**9\. Everyone starts from main and targets main.**
|
||||
|
||||
This tip prevents long branches. Developers check out `main`, build a feature, create a merge request, and target `main` again. They should do a complete review **before** merging and eliminating any intermediate stages.
|
||||
|
||||
**10\. Fix bugs in main first and release branches second.**
|
||||
|
||||
After identifying a bug, a problematic action someone could take is fix it in the just-released version and not fix it in `main`. To avoid it, developers should always fix forward by pushing the change in `main`, then cherry-pick it into another `patch-release` branch.
|
||||
|
||||
**11\. Commit messages reflect intent.**
|
||||
|
||||
Developers should not only say what they did, but also why they did it. An even more useful tactic is to explain why this option was selected over others to help future contributors understand the development process. Writing descriptive commit messages is useful for code reviews and future development.
|
||||
+39
@@ -0,0 +1,39 @@
|
||||
---
|
||||
title: >-
|
||||
Why character array is better than String for Storing password in Java? Example
|
||||
updated: 2022-04-05 07:56:33Z
|
||||
created: 2022-04-05 07:56:10Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Java
|
||||
source: >-
|
||||
https://javarevisited.blogspot.com/2012/03/why-character-array-is-better-than.html
|
||||
---
|
||||
|
||||
## [Why character array is better than String for Storing password in Java? Example](https://javarevisited.blogspot.com/2012/03/why-character-array-is-better-than.html#axzz7PZJBp33O)
|
||||
|
||||
**Why character array is better than String for storing a password in Java** was a recent question asked to one of my friends in a java interview. he was interviewing for a Technical lead position and has over 6 years of experience. Both [Character array and String](http://javarevisited.blogspot.com/2012/02/how-to-convert-char-to-string-in-java.html) can be used to store text data but choosing one over the other is a difficult question if you haven't faced the situation already. But as my friend said any question related to String must have a clue on a special property of Strings like immutability and he used that to convince the interviewer. here we will explore some reasons why should you use char\[\] for storing passwords than String.
|
||||
|
||||
This article is in continuation of my earlier interview question post on String e.g. [Why String is immutable in Java](http://javarevisited.blogspot.com/2010/10/why-string-is-immutable-in-java.html) or [How Substring can cause a memory leak in Java](http://javarevisited.blogspot.com/2011/10/how-substring-in-java-works.html) if you haven't read those you may find them interesting.
|
||||
Here are a few reasons which make sense to believe that character array is a better choice for storing the password in Java than String:
|
||||
|
||||
1) Since **Strings are immutable in Java** if you store the password as plain text it will be available in memory until the Garbage collector clears it and since String is used in the String pool for reusability there is a pretty high chance that it will remain in memory for a long duration, which poses a security threat.
|
||||
Since anyone who has access to memory dump can find the password in clear text and that's another reason you should always use an encrypted password than plain text. Since Strings are immutable there is no way the contents of Strings can be changed because [any change will produce new String](http://javarevisited.blogspot.com/2011/07/string-vs-stringbuffer-vs-stringbuilder.html), while if you char\[\] you can still set all his elements as blank or zero. So **Storing the password in a character array clearly mitigates security risk of stealing passwords**.
|
||||
|
||||
2) **Java itself recommends** using getPassword() method of JPasswordField which returns a char\[\] and deprecated getText() method which returns password in clear text stating security reason. Its good to follow advice from Java team and adhering to a standard rather than going against it.
|
||||
|
||||
3) With String there is always a risk of printing plain text in a [log file or console](http://javarevisited.blogspot.com/2011/05/top-10-tips-on-logging-in-java.html) but if use [Array](http://javarevisited.blogspot.com/2012/01/anonymous-array-example-java-create.html) you won't print contents of the array instead its memory location gets printed. though not a real reason still makes sense.
|
||||
|
||||
```java
|
||||
String strPassword="Unknown";
|
||||
char[] charPassword= new char[]{'U','n','k','w','o','n'};
|
||||
System.out.println("String password: " + strPassword);
|
||||
System.out.println("Character password: " + charPassword);
|
||||
```
|
||||
|
||||
```
|
||||
String password: Unknown
|
||||
Character password: \[C@110b053
|
||||
```
|
||||
|
||||
That's all on *why character array is a better choice than String for storing passwords in Java*. Though using char\[\] is not just enough you need to erase content to be more secure. I also suggest working with hash'd or [encrypted password](http://javarevisited.blogspot.com/2012/02/how-to-encode-decode-string-in-java.html) instead of plain text and clearing it from memory as soon as authentication is completed.
|
||||
@@ -0,0 +1,126 @@
|
||||
---
|
||||
title: >-
|
||||
groovy-option-parser - GOP -- groovy option parser. A command line option parsing alternative to CliBuilder - Google Project Hosting
|
||||
updated: 2019-02-26 14:22:17Z
|
||||
created: 2019-02-26 14:13:19Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/Groovy
|
||||
---
|
||||
|
||||
# Groovy Option Parser
|
||||
|
||||
GOP is a command line option parsing alternative to CliBuilder.
|
||||
|
||||
I wrote GOP for a couple reasons:
|
||||
|
||||
- Needed a small project to learn groovy
|
||||
- Replicate the option parsing behaviour of the excellent Ruby library, clip. Clip makes it simple to define options and simple to use the parsed parameters.
|
||||
- CliBuilder is confusing and made me think too hard
|
||||
|
||||
## An example is the easiest explanation
|
||||
|
||||
```groovy
|
||||
def parser = new org.computoring.gop.Parser(description: "An example parser demonstrating the features and uses of GOP.")
|
||||
parser.with {
|
||||
// support for required options
|
||||
// required options cannot have default values, that doesn't make much sense
|
||||
required 'f', 'foo-bar', [description: 'A required option with a short name, a long name, and a description']
|
||||
|
||||
// support for optional options
|
||||
optional 'b', [
|
||||
longName: 'bar-baz', // longName can be specified this way also
|
||||
default: 'xyz',
|
||||
description: 'An optional option with a short name, a long name, a default value, and a description'
|
||||
]
|
||||
|
||||
// support for flag (boolean) options
|
||||
flag 'c' // a flag option without a long name or a description, flags default to false
|
||||
flag 'd', 'debug', [
|
||||
default: true,
|
||||
description: 'A flag option with a default value of true'
|
||||
]
|
||||
|
||||
// short names are not required, pass in null
|
||||
optional null, 'optional-long-opt', [ description: 'An optional option without a shortname.' ]
|
||||
required null, 'required-long-opt', [ description: 'A required option without a shortname.' ]
|
||||
|
||||
// support for parameter validation. The parameter is passed to the validation closure. The value
|
||||
// returned from the closure is assigned back to the option.
|
||||
required 'i', 'count', [
|
||||
description: 'A required, validated option',
|
||||
validate: {
|
||||
Integer.parseInt it // the value of the parsed option with be an Integer in this case
|
||||
}
|
||||
]
|
||||
|
||||
// Support for remainder validation. Whatever is remaining after the options are parsed is passed into
|
||||
// the remainder closure. Whatever is returned from the closure is available as parser.remainder.
|
||||
// In this case a command is required after parameters.
|
||||
remainder {
|
||||
if(!it) throw new IllegalArgumentException("missing command")
|
||||
it
|
||||
}
|
||||
}
|
||||
|
||||
// typically, I'll call parse like this. If anything blows up I catch Exception and
|
||||
// print the parser.usage to stderr and exit
|
||||
try {
|
||||
// A script at this point would call parse with the command line args,
|
||||
// def params = parser.parse(args)
|
||||
// '--' stops option parsing
|
||||
def params = parser.parse("-f foo_value --debug --count 123 --required-long-opt wookie -- --not-an-option some other stuff".split())
|
||||
|
||||
// parsed as -f, referenced here as params.'foo-bar'
|
||||
assert params.'foo-bar' == 'foo_value'
|
||||
|
||||
// -b not supplied, 'xyz' is the default value
|
||||
assert params.b == 'xyz'
|
||||
|
||||
// -c not supplied, flag options default to false
|
||||
assert params.c == false
|
||||
|
||||
// --debug was supplied and flag option set to true
|
||||
assert params.debug == true
|
||||
|
||||
// -i and --count validate and convert their parsed value into an Integer
|
||||
assert params.count instanceof Integer
|
||||
assert params.i == 123
|
||||
|
||||
assert params.'required-long-opt' == 'wookie'
|
||||
|
||||
// verify the remainder contains everything after '--'
|
||||
assert parser.remainder.join(' ') == '--not-an-option some other stuff'
|
||||
}
|
||||
catch( Exception e ) {
|
||||
System.err << parser.usage
|
||||
System.exit(1)
|
||||
}
|
||||
```
|
||||
|
||||
The example above will generate usage output like this
|
||||
|
||||
```
|
||||
An example parser demonstrating the features and uses of GOP.
|
||||
Required
|
||||
-f, --foo-bar A required option with a short name, a long name, and a description
|
||||
--required-long-opt A required option without a shortname.
|
||||
-i, --count A required, validated option
|
||||
|
||||
Optional
|
||||
-b, --bar-baz [xyz] An optional option with a short name, a long name, a default value, and a description
|
||||
--optional-long-opt An optional option without a shortname.
|
||||
|
||||
Flags
|
||||
-c [false]
|
||||
-d, --debug [true] A flag option with a default value of true
|
||||
```
|
||||
|
||||
A couple interesting features
|
||||
|
||||
- Flag and optional options can have default values
|
||||
- Options can specify a validation closure that parsed values are passed through remaining parameters after parsing can be validated
|
||||
- Formatted usage statement is created for you.
|
||||
- Homepage: http://code.google.com/p/groovy-option-parser/
|
||||
- Downloads: http://code.google.com/p/groovy-option-parser/downloads/list
|
||||
- Issue tracker: http://code.google.com/p/groovy-option-parser/issues/list
|
||||
@@ -0,0 +1,61 @@
|
||||
---
|
||||
title: xml - case-insensitive matching in xpath? - Stack Overflow
|
||||
updated: 2019-02-26 14:12:35Z
|
||||
created: 2019-02-26 14:09:09Z
|
||||
tags:
|
||||
- IT
|
||||
- Development/xml
|
||||
- Development/xpath
|
||||
---
|
||||
|
||||
|
||||
case-insensitive matching in xpath?
|
||||
|
||||
For example, for the xml below
|
||||
|
||||
```xml
|
||||
<CATALOG>
|
||||
<CD title="Empire Burlesque"/>
|
||||
<CD title="empire burlesque"/>
|
||||
<CD title="EMPIRE BURLESQUE"/>
|
||||
<CD title="EmPiRe BuRLeSQuE"/>
|
||||
<CD title="Others"/>
|
||||
<CATALOG>
|
||||
```
|
||||
|
||||
How to match the first 4 records with xpath like `//CD[@title='empire burlesque']`. Is there xpath function to do this? Other solutions like PHP function are also accepted.
|
||||
|
||||
XPath 2 has a lower-case (and upper-case) string function. That's not quite the same as case-insensitive, but hopefully it will be close enough:
|
||||
|
||||
```xml
|
||||
//CD[lower-case(@title)='empire burlesque']
|
||||
```
|
||||
|
||||
If you are using XPath 1, there is a hack using translate.
|
||||
|
||||
One of the flags is i for case-insensitive matching.
|
||||
|
||||
The following XPATH using the matches() function with the case-insensitive flag:
|
||||
|
||||
```xml
|
||||
//CD[matches(@title,'empire burlesque','i')]
|
||||
```
|
||||
|
||||
One possible PHP solution:
|
||||
|
||||
```php
|
||||
// load XML to SimpleXML
|
||||
$x = simplexml_load_string($xmlstr);
|
||||
|
||||
// index it by title once
|
||||
$index = array();
|
||||
foreach ($x->CD as &$cd) {
|
||||
$title = strtolower((string)$cd['title']);
|
||||
if (!array_key_exists($title, $index)) $index[$title] = array();
|
||||
$index[$title][] = &$cd;
|
||||
}
|
||||
|
||||
// query the index
|
||||
$result = $index[strtolower("EMPIRE BURLESQUE")];
|
||||
```
|
||||
|
||||
Reference in New Issue
Block a user