vault backup: 2026-06-10 17:52:01
This commit is contained in:
@@ -0,0 +1,10 @@
|
||||
---
|
||||
tags:
|
||||
- infos/quote
|
||||
reference:
|
||||
- "[[Nelson Mandela]]"
|
||||
---
|
||||
|
||||
>[!quote]
|
||||
>Bildung ist die mächtigste Waffe,um die Welt zu verändern.
|
||||
> *Nelson Mandela*
|
||||
@@ -0,0 +1,68 @@
|
||||
---
|
||||
weight:
|
||||
meditation:
|
||||
pushUps: 0
|
||||
plank: 0
|
||||
journal: Privat daily
|
||||
journal-date: 2026-06-10
|
||||
journal-start-date: 2026-06-10
|
||||
journal-end-date: 2026-06-10
|
||||
---
|
||||
```calendar-timeline
|
||||
```
|
||||
|
||||
## Journal
|
||||
|
||||
## Ziele
|
||||
|
||||
##### [[2026-W24#^24i|Woche]] | [[2026-06#^06i|Monat]] | [[2026-Q2#^q2i|Quartal]] | [[2026## Jahresziele|Jahr]]
|
||||
|
||||
## Aufgaben
|
||||
|
||||
> [!hint]- Aktuelle Aufgaben
|
||||
>```tasks
|
||||
>not done
|
||||
>happens on 2026-06-10
|
||||
>path regex does not match /^Resources\/Templates\/.*/
|
||||
>path regex does not match /^Übersicht\/.*/
|
||||
>```
|
||||
|
||||
> [!todo]- Aktive Aufgaben
|
||||
>```tasks
|
||||
>not done
|
||||
>happens before 2026-06-10
|
||||
>path regex does not match /^Resources\/Templates\/.*/
|
||||
>path regex does not match /^Übersicht\/.*/
|
||||
>```
|
||||
|
||||
> [!warning]- Heute fällig
|
||||
>```tasks
|
||||
>not done
|
||||
>has due date
|
||||
>due on 2026-06-10
|
||||
>path regex does not match /^Resources\/Templates\/.*/
|
||||
>path regex does not match /^Übersicht\/.*/
|
||||
>```
|
||||
|
||||
> [!error]- Überfällig
|
||||
>```tasks
|
||||
>not done
|
||||
>has due date
|
||||
>due before 2026-06-10
|
||||
>path regex does not match /^Resources\/Templates\/.*/
|
||||
>path regex does not match /^Übersicht\/.*/
|
||||
>```
|
||||
|
||||
> [!done]- Erledigte Aufgaben
|
||||
>```dataview
|
||||
>TASK
|
||||
>FROM !"Resources/Templates"
|
||||
>WHERE completed AND completion = date(2026-06-10)
|
||||
>```
|
||||
|
||||
## Geburtstage
|
||||
```dataview
|
||||
TABLE birthday as Geburtstag, truncate(string(date(today) - birthday),2, "") AS Alter
|
||||
FROM "Infos/Kontakte"
|
||||
WHERE birthday.month = 06 AND birthday.day = 10
|
||||
```
|
||||
@@ -11,7 +11,7 @@ journal-end-date: 2026-06-10
|
||||
```
|
||||
|
||||
## Journal
|
||||
- [ ] 09:15 - 09:30 [[Managed Services Team Daily]]
|
||||
- [x] 09:15 - 09:30 [[Managed Services Team Daily]] [completion:: 2026-06-10]
|
||||
|
||||
## Ziele
|
||||
|
||||
|
||||
@@ -0,0 +1,12 @@
|
||||
---
|
||||
tags:
|
||||
- infos/author
|
||||
---
|
||||
## Infos
|
||||
|
||||
## Bücher
|
||||
|
||||
## Zitate
|
||||
```dataview
|
||||
list from [[]] and !outgoing([[]]) and #infos/quote
|
||||
```
|
||||
@@ -1,169 +0,0 @@
|
||||
---
|
||||
title: 10 Core Java Best Practices with an industry strength code sample
|
||||
tags:
|
||||
- IT/Development/Java
|
||||
---
|
||||
|
||||
Home › 13 Technical Key Areas Interview Q&A › Best Practice › 10 Core Java Best Practices with an industry strength code sample
|
||||
10 Core Java Best Practices with an industry strength code sample
|
||||
Posted on October 8, 2014 by Arulkumaran — 2 Comments ↓
|
||||
|
||||
|
||||
Best Practices is one of the key areas, and often you can impress your interviewers, peers, and code reviewers by applying the best practices to your code. If you are an interviewer, you can show a piece of code that is badly written, and ask for the recommendations as to how she/he will improve the code. This will reveal a lot about a candidate’s attitude and ability towards writing quality code.
|
||||
|
||||
Here is a sample class “BatchRunKey” that can be used as a key class to store data in Maps.
|
||||
Q1. Can you list the best practices applied in the “BatchRunKey” class shown below?
|
||||
|
||||
```java
|
||||
package com.myapp.model;
|
||||
|
||||
import com.myapp.ValuationTypeCd;
|
||||
import java.util.Date;
|
||||
import javax.annotation.concurrent.Immutable;
|
||||
import org.apache.commons.lang.builder.CompareToBuilder;
|
||||
import org.apache.commons.lang.builder.EqualsBuilder;
|
||||
import org.apache.commons.lang.builder.HashCodeBuilder;
|
||||
import org.apache.commons.lang.builder.ToStringBuilder;
|
||||
import org.apache.commons.lang.builder.ToStringStyle;
|
||||
import org.slf4j.Logger;
|
||||
import org.slf4j.LoggerFactory;
|
||||
import org.springframework.util.Assert;
|
||||
|
||||
@Immutable public final class BatchRunKey implements Comparable<BatchRunKey> {
|
||||
private static final Logger LOG = LoggerFactory.getLogger(BatchRunKey.class);
|
||||
final private long batchId;
|
||||
final private String entity;
|
||||
final private Date valuationDate;
|
||||
final ValuationTypeCd valuationType;
|
||||
private final Logger logger = LoggerFactory.getLogger(getClass());
|
||||
private BatchRunKey(long batchId, String entity, Date valuationDate, ValuationTypeCd valuationType) {
|
||||
super();
|
||||
this.batchId = batchId;
|
||||
this.entity = entity;
|
||||
this.valuationDate = valuationDate;
|
||||
this.valuationType = valuationType;
|
||||
}
|
||||
public static BatchRunKey newInstance(long batchId, String entity, Date valuationDate, ValuationTypeCd valuationType) {
|
||||
Assert.notNull(batchId);
|
||||
Assert.notNull(entity);
|
||||
Assert.notNull(valuationDate);
|
||||
Assert.notNull(valuationType); return new BatchRunKey(batchId, entity, valuationDate, valuationType);
|
||||
}
|
||||
public long getBatchId() {
|
||||
return batchId;
|
||||
}
|
||||
public String getEntity() {
|
||||
return entity;
|
||||
}
|
||||
public Date getValuationDate() {
|
||||
return new Date(valuationDate.getTime()); //defensive copy
|
||||
}
|
||||
public ValuationTypeCd getValuationType() {
|
||||
return valuationType;
|
||||
}
|
||||
@Override public int hashCode() {
|
||||
return new HashCodeBuilder().append(batchId).append(entity)
|
||||
.append(valuationDate).append(valuationType)
|
||||
.toHashCode();
|
||||
}
|
||||
@Override public boolean equals(final Object obj) {
|
||||
if(obj == null) {
|
||||
return false;
|
||||
}
|
||||
if (obj instanceof BatchRunKey) {
|
||||
final BatchRunKey runKey = (BatchRunKey) obj;
|
||||
return new EqualsBuilder().append(this.batchId, runKey.batchId)
|
||||
.append(this.entity, runKey.entity)
|
||||
.append(this.valuationDate, runKey.valuationDate)
|
||||
.append(this.valuationType, runKey.valuationType)
|
||||
.isEquals();
|
||||
}
|
||||
return false;
|
||||
}
|
||||
@Override public int compareTo(BatchRunKey runKey) {
|
||||
return new CompareToBuilder().append(this.batchId, runKey.batchId)
|
||||
.append(this.entity, runKey.entity)
|
||||
.append(this.valuationDate, runKey.valuationDate)
|
||||
.append(this.valuationType, runKey.valuationType)
|
||||
.toComparison();
|
||||
}
|
||||
@Override public String toString() {
|
||||
LOG.debug("Executing toString()");
|
||||
return ToStringBuilder.reflectionToString(this, ToStringStyle.SHORT_PREFIX_STYLE);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The enum class for “ValuationTypeCd”
|
||||
|
||||
```java
|
||||
package com.myapp.model;
|
||||
public enum ValuationTypeCd { WEEKLY, MONTHLY,YEARLY; }
|
||||
```
|
||||
|
||||
A1. The best practices applied in summary are
|
||||
|
||||
1. Make your objects immutable where possible as immutable classes are inherently thread safe and less error prone as the state cannot be changed once constructed. The “BatchRunKey” class is immutable as it cannot be modified once constructed by invoking the public “newInstance(…)” method for the following reasons:
|
||||
|
||||
The member variables are marked as final, hence once constructed cannot be reassigned.
|
||||
No setter methods to mutate the object.
|
||||
The conctructor access modifier is private, hence cannot be invoked from outside this class. It is only being invoked by the “newInstance(…)” factory method.
|
||||
The “getValuationDate()” method creates a new instance of the date object to not allow the object reference to escape. If it escapes, the “valuationDate” can be mutated from outside. So, the date object is defensively copied, and the copied object is returned instead of returning “this.valuationDate”.
|
||||
|
||||
2. Don’t reinvent the wheel, and use proven third-party libraries. Apache commons library classes “EqualsBuilder”, “CompareToBuilder”, “HashCodeBuilder”, and “ToStringBuilder” are used here as opposed to reinventing the wheel by writing your own implementation logic. The code is also easier to read and understand. For example, if you have to write your own “hashCode() & equals()” logic, it will look something like
|
||||
|
||||
```java
|
||||
@Override public int hashCode() {
|
||||
final int prime = 31;
|
||||
int result = 1;
|
||||
result = prime * result + (int) (batchId ^ (batchId >>> 32));
|
||||
result = prime * result + ((entity == null) ? 0 : entity.hashCode());
|
||||
result = prime * result + ((valuationDate == null) ? 0 : valuationDate.hashCode());
|
||||
result = prime * result + ((valuationType == null) ? 0 : valuationType.hashCode());
|
||||
return result;
|
||||
}
|
||||
@Override public boolean equals(Object obj) {
|
||||
if (this == obj) return true;
|
||||
if (obj == null) return false;
|
||||
if (getClass() != obj.getClass()) return false;
|
||||
BatchRunKey other = (BatchRunKey) obj;
|
||||
if (batchId != other.batchId) return false;
|
||||
if (entity == null) {
|
||||
if (other.entity != null) return false;
|
||||
}
|
||||
else if (!entity.equals(other.entity)) return false;
|
||||
if (valuationDate == null) {
|
||||
if (other.valuationDate != null) return false;
|
||||
} else if (!valuationDate.equals(other.valuationDate)) return false;
|
||||
if (valuationType != other.valuationType) return false; return true;
|
||||
}
|
||||
```
|
||||
|
||||
Yaak, harder to read compared to the original code with Apache library classes. The Apache XXXBuilder classes use the builder design pattern for better readability. From Java 7 onwards, you have the “java.util.Objects” class, which consists of static utility methods for operating on objects.
|
||||
|
||||
You can also make us of the Google Gauva library, Spring utility classes, etc to not reinvent the wheel in many different scenarios. The “Assert” class used in the “newInstance(…)” method to validate for null values is from the “org.springframework.util” package.
|
||||
|
||||
3. Using the Comparable interface to sort the objects naturally. The “compareTo(…)” method and the “equals(..)” methods are implemented by adhering to the contract that:
|
||||
|
||||
“compareTo only returns 0, if a call to equals on the same objects would return true”
|
||||
|
||||
The JavaDoc for “Comparable” states that:
|
||||
|
||||
“The natural ordering for a class C is said to be consistent with equals if and only if e1.compareTo(e2) == 0 has the same boolean value as e1.equals(e2) for every e1 and e2 of class C. Note that null is not an instance of any class, and e.compareTo(null) should throw a NullPointerException even though e.equals(null) returns false.”
|
||||
|
||||
So, having the JavaDoc handy and referring to it whilst coding is another best practice .
|
||||
|
||||
4.The toString( ) method from the Object class is overriden as it is handy for logging and debugging purpose. If you don’t override it, you will only get the memory address of the object as opposed to getting more meanigful values of batchId, entity, valuationDate, and valuationType, which are handy for debugging and auditing.
|
||||
|
||||
5. Using log4j as opposed to System.out.println(……) . The reason is that unlike the log4j framework, with “System.out.println (….)” you cannot change log levels, turn it off, customize it by using different appenders, etc.
|
||||
|
||||
6. Enums are favored to static final variables. The “ValuationTypeCd” is an enum.
|
||||
|
||||
7. The @Override annotation is used to ensure that the method names are not misspelled. If you mis-spell the method name, you will get a compile-time error.
|
||||
|
||||
8. The Factory method is favored over constructors as they have more meaningful names like “newInstance()”, and can decide on certain criteria which instance to create/return, extendable with Open/Close principle, and more reusable/testable.
|
||||
|
||||
9. The “newInstance()” method is also implemented with the “fail-fast” approach. The “Assert.notNull(…)” checks ensure that null values are not passed by the caller. If a null value is passed, it throw a validation exception. It also acts as a documentation in terms of “batchId, entity, valuationDate, and valuationType” being mandatory and accepting only non-null values.
|
||||
|
||||
10. A Java package ” com.myapp.model” is used for organizing Java classes into namespaces. Packages ensure uniqueness and provide more meaning as you know that “BatchRunKey” is a model class.
|
||||
You may also like
|
||||
@@ -1,77 +0,0 @@
|
||||
---
|
||||
title: 30+ Java Code Review Checklist Items | Java-Success.com
|
||||
---
|
||||
|
||||
# 30+ Java Code Review Checklist Items
|
||||
Posted on February 17, 2015 by Arulkumaran — No Comments ↓
|
||||
|
||||
|
||||
This Java code review checklist is not only useful during code reviews, but also to answer an important Java job interview question,
|
||||
|
||||
**Q. How would you go about evaluating code quality of others’ work?**
|
||||
|
||||
You also learn a lot from peer code reviews. What has been written well? Why was it done this way? Could this have been written differently?, etc. This is one of the benefits of volunteering to review code via open-source project contribution.
|
||||
|
||||
## Functionality
|
||||
|
||||
| Checklist | Description/example |
|
||||
| ---------- | --------------------|
|
||||
| Functionality is implemented in a simple, maintainable, and reusable manner. | Keep in mind some of the design principles like SOLID design principles, Don’t Repeat Yourself (DRY), and Keep It Simple ans Stupid (KISS). Also, think about the OO concepts — A PIE. Abstraction, Polymorphism, Inheritance, and Encapsulation. These principles and concepts are all about accomplishing “Low coupling” and “High cohesion“. Apply functional programming (FP) paradigm where it makes more sense.|
|
||||
|
||||
## Clean code
|
||||
| Checklist | Description/example |
|
||||
| --------- | ------------------- |
|
||||
| Use of descriptive and meaningful variable, method and class names as opposed to relying too much on comments. | E.g. calculateGst(BigDecimal amount), BalanceLoader.java, etc. Bad: List list; Good: List<String> users; |
|
||||
| Class and functions should be small and focus on doing one thing. No duplication of code.| E.g. CustomerDao.java for data access logic only, Customer.java for domain object, CustomerService.java for business logic, and CustomerValidator.java for validating input fields, etc. Similarly, separate functions like processSalary(String customerCode) will invoke other sub functions with meaningful names like evaluateBonus(String customerCode), evaluateLeaveLoading(String customerCode), etc |
|
||||
| Functions should not take too many input parameters. | Bad: processOrder(String customerCode, String customerName, String deliveryAddress, BigDecimal unitPrice, int quantity, BigDecimal discountPercentage); Good: processOrder(CustomerDetail customer, OrderDetail order); where CustomerDetail is a value object with attributes like customerCode, customerName, etc.
|
||||
| Use a standard code formatting template. |Share the template across the development team.|
|
||||
| Declare the variables with the smallest possible scope.| For example, if a variable “tmp” is used only inside a loop, then declare it inside the loop, and not outside.|
|
||||
| Don’t preserve or create variables that you don’t use again.| E.g. instead of boolean removed = myItems.remove(item); return removed; Do: return myItems.remove(item);
|
||||
| Omit needless and commented out code. No System.out.println statements either.| You have source control for the history. Use proper logging frameworks like slf4j and logback for logging.|
|
||||
|
||||
|
||||
## Fundamentals
|
||||
|
||||
| Checklist | Description/example |
|
||||
| --------- | ------------------- |
|
||||
| Make a class final and the object immutable where possible. | Immutable classes are inherently thread-safe and more secured. For example, the Java String class is immutable and declared as final.|
|
||||
| Minimize the accessibility of the packages, classes and its members like methods and variables. | E.g. private, protected, default, and public access modifiers.|
|
||||
| Code to interface as opposed to implementation.| Bad: ArrayList<String> names = new ArrayList<String>(); Good: List<String> names = new ArrayList<String>(); |
|
||||
| Use right data types. | For example, use BigDecimal instead of floating point variables like float or double for monetary values. Use enums instead of int constants.|
|
||||
| Avoid finalizers and properly override equals, hashCode, and toString methods.| The equals and hashCode contract must be correctly implemented to prevent hard to debug defects.|
|
||||
| Write fail-fast code by validating the input parameters.| Apply design by contract.|
|
||||
| Return an empty collection or throw an exception as opposed to returning a null. Also, be aware of the implicit autoboxing and unboxing gotchas.| **NullpointerException** is one of the most common exceptions in Java.|
|
||||
|
||||
|
||||
## Key Areas like Security, Exception Handling, Performance, Memory/Resource leaks, Concurrency, etc
|
||||
|
||||
| Checklist | Description/example |
|
||||
| --------- | ------------------- |
|
||||
| Don’t log sensitive data. | **Security.** |
|
||||
| Clearly document security related information. | **Security.** |
|
||||
| Sanitize user inputs. | **Security.** |
|
||||
| Favor immutable objects. | **Security.** |
|
||||
| Use Prepared statements as opposed to ordinary statements. **Security** to prevent SQL injection attack. |
|
||||
| Release resources (Streams, Connections, etc). | **Security** to prevent denial of service attack (DoS) and resource leak issues. |
|
||||
| Don’t let sensitive information like file paths, server names, host names, etc escape via exceptions. | **Security** and **Exception Handling**. |
|
||||
| Follow proper security best practices like SSL (one-way, two-way, etc), encrypting sensitive data, authentication/authorization, etc. | **Security.** |
|
||||
| Use exceptions as opposed to return codes. | **Exception Handling**. |
|
||||
| Don’t ignore or suppress exceptions. Standardize the use of checked and unchecked exceptions. Throw exceptions early and catch them late. | **Exception Handling**. |
|
||||
| Write thread-safe code with proper synchronization and use of immutable objects. Also, document thread-safety. | **Concurrency**. |
|
||||
| Keep synchronization section small and favor the use of the new concurrency libraries to prevent excessive synchronization. | **Concurrency** and **Performance**. |
|
||||
| Reuse objects via flyweight design pattern. | **Performance**.|
|
||||
| Presence of long lived objects like ThreaLocal and static variables holding references to lots of short lived objects. | **Memory Leak** and **Performance** |
|
||||
| Badly constructed SQL, REGEX, etc. | **Performance.** E.g. Cartesian joins in SQL and back tracking regular expressions. |
|
||||
| Inefficient Java coding and algorithms in frequently executed methods leading to death by thousand cuts. | **Performance** |
|
||||
|
||||
## Other general programming
|
||||
|
||||
| Checklist | Description/example |
|
||||
| --------- | ------------------- |
|
||||
| Favor using well proven frameworks and libraries as opposed to reinventing the wheel by writing your own. | E.g. Apache commons libraries, Google Gauva libraries, Spring libraries, XML/JSON libraries, etc. |
|
||||
| Presence of JUnit and JBehave test cases. | Check the test coverage and quality of the unit tests with proper mock objects to be able to easily maintain and run independently/repeatedly. - Test only a unit of code at a time (e.g. one function). - Unit tests must be independent of each other. They should run independendtly. - Set up should not be too complicated. - Mockout external states and services that you are not asserting. For example, retrieving data from a database. - Avoid unneccessary assertions. - Start with functions that have the fewest dependencies, and work your way up. - Write unit tests for negative scenarios like throwing exceptions, negative values, null values, etc. - Don’t have try/catch inside unit tests. Use throws Exception statement in test case declaration itself. - Don’t have ant System.out.println(…..) |
|
||||
| Ensure that the unit tests are written properly. | Don’t write unit tests for the sake of writing one. |
|
||||
| Presence of hard coded config values. | Externalize configuration data in a .properties file. Sensitive information like password must be encrypted. |
|
||||
| Presence and implementation of non functional requirements like archiving, auditing, and purging data and application monitoring where required. | It is easy to ignore these non functional requirements.|
|
||||
|
||||
|
||||
@@ -1,158 +0,0 @@
|
||||
---
|
||||
title: A Command Line Email Client to Send Mails from Terminal
|
||||
source: https://www.tecmint.com/send-mail-from-command-line-using-mutt-command/
|
||||
---
|
||||
|
||||
[A Command Line Email Client to Send Mails from Terminal](https://www.tecmint.com/send-mail-from-command-line-using-mutt-command/)
|
||||
As a System admin, sometimes we need to send mails to users or someone else from the server and for that we used to go with a web based interface to send email, is it really that handy ? Absolutely No.
|
||||
|
||||

|
||||
|
||||
Mutt Command Line Email Client
|
||||
|
||||
Here in this tutorial, we’ll be using the **mutt** (a terminal email client) command to send email from command line interlace.
|
||||
|
||||
##### What is Mutt?
|
||||
|
||||
**Mutt** is a command line based **Email** client. It’s a very useful and powerful tool to send and read mails from command line in **Unix** based systems. Mutt also supports **POP** and **IMAP** protocols for receiving mails. It opens with a coloured interface to send Email which makes it user friendly to send emails from command line.
|
||||
|
||||
##### Mutt Features
|
||||
|
||||
Some other important features of **Mutt** is as follows:
|
||||
|
||||
1. Its very Easy to install and configure.
|
||||
2. Allows us to send emails with **attachments** from the command line.
|
||||
3. It also has the features to add **BCC** (**Blind carbon copy**) and **CC** (**Carbon copy**) while sending mails.
|
||||
4. It allows message **threading**.
|
||||
5. It provides us the facility of mailing **lists**.
|
||||
6. It also support so many mailbox formats like **maildir**, **mbox**, **MH** and **MMDF**.
|
||||
7. Supports at least **20** languages.
|
||||
8. It also support **DSN** (**Delivery Status Notification**).
|
||||
|
||||
### How to Install Mutt in Linux
|
||||
|
||||
We can install **Mutt Client** in our Linux box very easily with any package installers as shown.
|
||||
|
||||
\# apt-get install mutt (For Debian / Ubuntu based system)
|
||||
|
||||
\# yum install mutt (For RHEL / CentOS / Fedora based system)
|
||||
|
||||
##### Configuration files
|
||||
|
||||
Configuration files of **Mutt Email** client.
|
||||
|
||||
1. **Main Configuration file**: To make changes globally for all users For mutt, you can make changes in its mail configuration file “**/etc/Muttrc**“.
|
||||
2. **User Configuration file of Mutt** : If you want to set some specific configuration for a particular user for Mutt, you can configure those settings in **~/.muttrc** or **~/.mutt/muttrc** files.
|
||||
|
||||
##### Basic Syntax of mutt command
|
||||
|
||||
mutt options recipient
|
||||
|
||||
##### Read Emails with Mutt
|
||||
|
||||
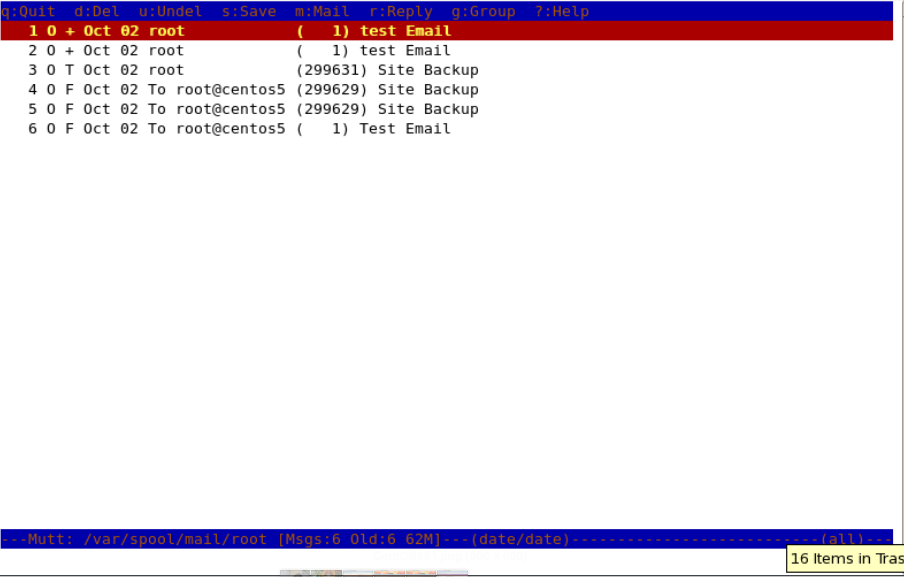
To read emails of the user with you are currently logged in, you just need to run “**mutt**” on the terminal, it will load the current user’s mailbox.
|
||||
|
||||
\[root@tecmint ~\]# mutt
|
||||
|
||||
|
||||
|
||||
Read Mail from Terminal
|
||||
|
||||
To read the emails of a specific user, you need to specify which mail file to read. For example, You (as **root**) wants to read mails of user “**John**“, you need to specify his mail file with “**-f”** option with mutt command.
|
||||
|
||||
\[root@tecmint ~\]# mutt -f /var/spool/mail/john
|
||||
|
||||
You may also use “**-R**” option to open a mailbox in **read-only** mode.
|
||||
|
||||
##### Send an email with mutt command
|
||||
|
||||
In this example, following command will send a test **Email** to **john@tecmint.com**. The “**-s**” option is used to specify **Subject** of the mail.
|
||||
|
||||
\[root@tecmint ~\]# mutt -s "Test Email" john@tecmint.com
|
||||
|
||||
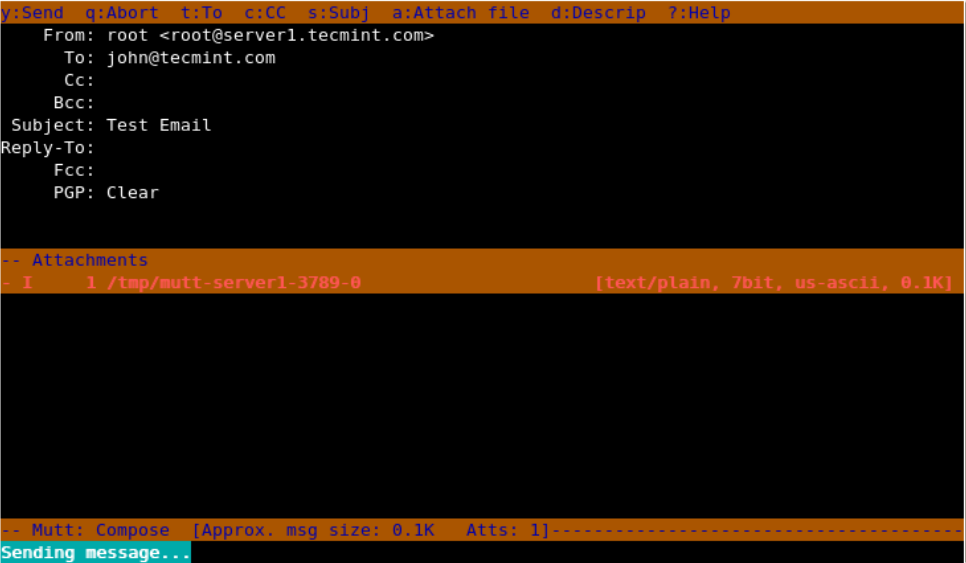
When you enter the above command in the terminal, it opens up with an interface and confirms the recipient address and subject of the mail and opens up the interface, here you can make changes to recipient mail address.
|
||||
|
||||
1. Change recipient email address pressing **t**.
|
||||
2. Change Cc address with **c**.
|
||||
3. Attach files as attachments with **a**.
|
||||
4. Quit from the interface with **q**.
|
||||
5. Send that email by pressing **y.**
|
||||
|
||||
**Note**: When you press “**y**” it shows the status below that mutt is sending mail.
|
||||
|
||||
|
||||
|
||||
Send Mail from Terminal
|
||||
|
||||
##### Add Carbon copy(Cc) and Blind Carbon copy(Bcc)
|
||||
|
||||
We can add **Cc** and **Bcc** with mutt command to our email with “**-c**” and “**-b**” option.
|
||||
|
||||
\[root@tecmint ~\]# mutt -s "Subject of mail" -c <email add for CC> -b <email-add for BCC> mail address of recipient
|
||||
|
||||
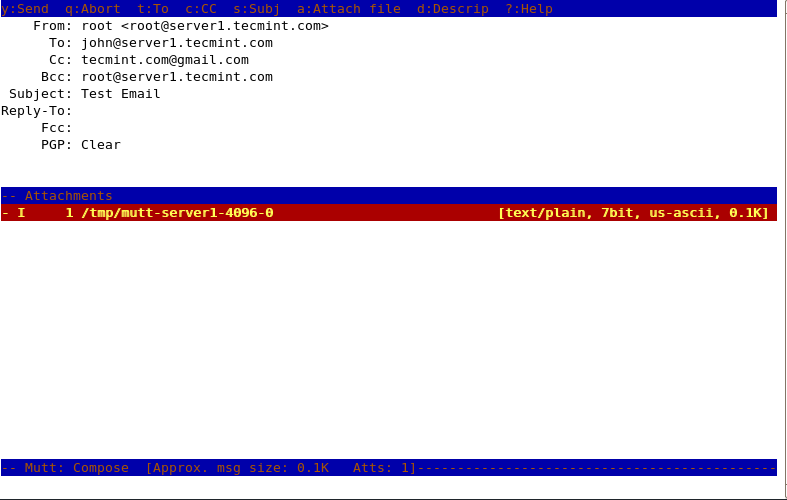
\[root@tecmint ~\]# mutt -s “Test Email” -c tecmint.com@gmail.com -b root@server1.tecmint.com john@server1.tecmint.com
|
||||
|
||||
Here in this example, **root** is sending email to **john@server1.tecmint.com** and putting **tecmint.com@gmail.com** as **Cc** address and **root@server1.tecmint.com** as **Bcc**.
|
||||
|
||||
|
||||
|
||||
Send Mail as CC or BCC in Terminal
|
||||
|
||||
##### Send Emails with Attachments
|
||||
|
||||
We can send email from command line with **attachments** by using “**-a**” option with mutt command.
|
||||
|
||||
\[root@tecmint ~\]# mutt -s "Subject of Mail" -a <path of attachment file> -c <email address of CC> mail address of recipient
|
||||
|
||||
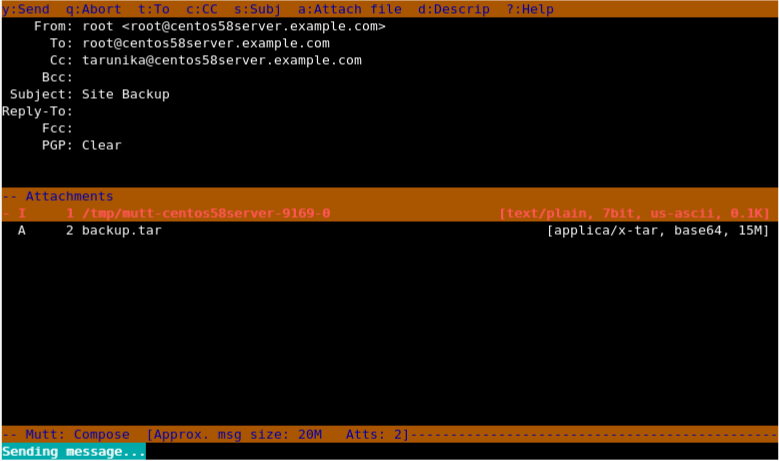
\[root@tecmint ~\]# mutt -s "Site Backup" -a /backups/backup.tar -c tarunika@centos58server.example.com root@centos58server.example.com
|
||||
|
||||
|
||||
|
||||
Send Email Attachment from Terminal
|
||||
|
||||
Here in above snapshot, you can see that it shows attachment attached with the mail.
|
||||
|
||||
##### Use of muttrc file
|
||||
|
||||
If we want to change the senders name and email, then we need to Create a file in that particular user’s home directory.
|
||||
|
||||
\[root@tecmint ~\]# cat .muttrc
|
||||
|
||||
Add the following lines to it. Save and close it.
|
||||
|
||||
set from = "user@domain.com"
|
||||
set realname = "Realname of the user"
|
||||
|
||||
##### Getting Help
|
||||
|
||||
To print the help menu of “**mutt**”, we need to specify “**-h**” option with it.
|
||||
|
||||
\[root@tecmint ~\]# mutt -h
|
||||
|
||||
Mutt 1.4.2.2i (2006-07-14)
|
||||
usage: mutt \[ -nRyzZ \] \[ -e <cmd> \] \[ -F <file> \] \[ -m <type> \] \[ -f <file> \]
|
||||
mutt \[ -nx \] \[ -e <cmd> \] \[ -a <file> \] \[ -F <file> \] \[ -H <file> \]
|
||||
mutt \[ -i <file> \] \[ -s <subj> \] \[ -b <addr> \] \[ -c <addr> \] <addr> \[ ... \]
|
||||
mutt \[ -n \] \[ -e <cmd> \] \[ -F <file> \] -p -v\[v\]
|
||||
options:
|
||||
-a <file> attach a file to the message
|
||||
-b <address> specify a blind carbon-copy (BCC) address
|
||||
-c <address> specify a carbon-copy (CC) address
|
||||
-e <command> specify a command to be executed after initialization
|
||||
-f <file> specify which mailbox to read
|
||||
-F <file> specify an alternate muttrc file
|
||||
-H <file> specify a draft file to read header from
|
||||
-i <file> specify a file which Mutt should include in the reply
|
||||
-m <type> specify a default mailbox type
|
||||
-n causes Mutt not to read the system Muttrc
|
||||
-p recall a postponed message
|
||||
-R mailbox in read-only mode
|
||||
-s <subj> specify a subject (must be in quotes if it has spaces)
|
||||
-v show version and compile-time definitions
|
||||
-x simulate the mailx send mode
|
||||
-y select a mailbox specified in your `mailboxes' list
|
||||
-z exit immediately if there are no messages in the mailbox
|
||||
-Z open the first folder with new message, exit immediately if none
|
||||
-h this help message
|
||||
|
||||
This is it with **mutt command** for now, read **man pages** of mutt for more information on mutt command.
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,247 +0,0 @@
|
||||
---
|
||||
title: A sysadmins guide to Ansible
|
||||
source: https://opensource.com/article/18/7/sysadmin-tasks-ansible
|
||||
---
|
||||
|
||||
[[Ansible MOC]]
|
||||
|
||||
In my previous article, I discussed [how to use Ansible to patch systems and install applications](https://opensource.com/article/18/3/ansible-patch-systems). In this article, I'll show you how to do other things with Ansible that will make your life as a sysadmin easier. First, though, I want to share why I came to Ansible.
|
||||
|
||||
I started using Ansible because it made patching systems easier. I could run some ad-hoc commands here and there and some playbooks someone else wrote. I didn't get very in depth, though, because the playbook I was running used a lot of [lineinfile](https://docs.ansible.com/ansible/latest/modules/lineinfile_module.html) modules, and, to be honest, my `regex` techniques were nonexistent. I was also limited in my capacity due to my management's direction and instructions: "You can run this playbook only and that's all you can do."
|
||||
|
||||
After leaving that job, I started working on a team where most of the infrastructure was in the cloud. After getting used to the team and learning how everything works, I started trying to find ways to automate more things. We were spending two to three months deploying virtual machines in large numbers—doing all the work manually, including the lifecycle of each virtual machine, from provision to decommission. Our work often got behind schedule, as we spent a lot of time doing maintenance. When folks went on vacation, others had to take over with little knowledge of the tasks they were doing.
|
||||
|
||||
## Diving deeper into Ansible
|
||||
|
||||
Sharing ideas about how to resolve issues is one of the best things we can do in the IT and open source world, so I went looking for help by [submitting issues in Ansible](https://github.com/ansible/ansible/issues/18006) and asking questions in [roles others created](https://github.com/abaez/ansible-role-user/issues/1).
|
||||
|
||||
Reading the documentation (including the following topics) is the best way to get started learning Ansible.
|
||||
|
||||
- [Getting started](http://docs.ansible.com/ansible/latest/user_guide/intro_getting_started.html)
|
||||
- [Best practices](http://docs.ansible.com/ansible/latest/user_guide/playbooks_best_practices.html)
|
||||
- [Ansible Lightbulb](https://github.com/ansible/lightbulb)
|
||||
- [Ansible FAQ](https://docs.ansible.com/ansible/latest/reference_appendices/faq.html)
|
||||
|
||||
If you are trying to figure out what you can do with Ansible, take a moment and think about the daily activities you do, the ones that take a lot of time that would be better spent on other things. Here are some examples:
|
||||
|
||||
- **Managing accounts in systems:** Creating users, adding them to the correct groups, and adding the SSH keys… these are things that used to take me days when we had a large number of systems to build. Even using a shell script, this process was very time-consuming.
|
||||
- **Maintaining lists of required packages:** This could be part of your security posture and include the packages required for your applications.
|
||||
- **Installing applications:** You can use your current documentation and convert application installs into tasks by finding the correct [module](https://docs.ansible.com/ansible/latest/modules/modules_by_category.html) for the job.
|
||||
- **Configuring systems and applications:** You might want to change `/etc/ssh/sshd_config` for different environments (e.g., production vs. development) by adding a line or two, or maybe you want a file to look a specific way in every system you're managing.
|
||||
- **Provisioning a VM in the cloud:** This is great when you need to launch a few virtual machines that are similar for your applications and you are tired of using the UI.
|
||||
|
||||
Now let's look at how to use Ansible to automate some of these repetitive tasks.
|
||||
|
||||
## Managing users
|
||||
|
||||
If you need to create a large list of users and groups with the users spread among the different groups, you can use [loops](https://docs.ansible.com/ansible/latest/user_guide/playbooks_loops.html). Let's start by creating the groups:
|
||||
|
||||
```yaml
|
||||
- name: create user groups
|
||||
group:
|
||||
name: "{{ item }}"
|
||||
loop:
|
||||
\- postgresql
|
||||
\- nginx-test
|
||||
\- admin
|
||||
\- dbadmin
|
||||
\- hadoop
|
||||
```
|
||||
|
||||
You can create users with specific parameters like this:
|
||||
|
||||
```yaml
|
||||
- name: all users in the department
|
||||
user:
|
||||
name: "{{ item.name }}"
|
||||
group: "{{ item.group }}"
|
||||
groups: "{{ item.groups }}"
|
||||
uid: "{{ item.uid }}"
|
||||
state: "{{ item.state }}"
|
||||
loop:
|
||||
- { name: 'admin1', group: 'admin', groups: 'nginx', uid: '1234', state: 'present' }
|
||||
- { name: 'dbadmin1', group: 'dbadmin', groups: 'postgres', uid: '4321', state: 'present' }
|
||||
- { name: 'user1', group: 'hadoop', groups: 'wheel', uid: '1067', state: 'present' }
|
||||
- { name: 'jose', group: 'admin', groups: 'wheel', uid: '9000', state: 'absent' }
|
||||
```
|
||||
|
||||
Looking at the user `jose`, you may recognize that `state: 'absent'` deletes this user account, and you may be wondering why you need to include all the other parameters when you're just removing him. It's because this is a good place to keep documentation of important changes for audits or security compliance. By storing the roles in Git as your source of truth, you can go back and look at the old versions in Git if you later need to answer questions about why changes were made.
|
||||
|
||||
To deploy SSH keys for some of the users, you can use the same type of looping as in the last example.
|
||||
|
||||
```yaml
|
||||
- name: copy admin1 and dbadmin ssh keys
|
||||
authorized_key:
|
||||
user: "{{ item.user }}"
|
||||
key: "{{ item.key }}"
|
||||
state: "{{ item.state }}"
|
||||
comment: "{{ item.comment }}"
|
||||
loop:
|
||||
- { user: 'admin1', key: "{{ lookup('file', '/data/test\_temp\_key.pub'), state: 'present', comment: 'admin1 key' }
|
||||
- { user: 'dbadmin', key: "{{ lookup('file', '/data/vm\_temp\_key.pub'), state: 'absent', comment: 'dbadmin key' }
|
||||
```
|
||||
|
||||
Here, we specify the `user`, how to find the key by using `lookup`, the `state`, and a `comment` describing the purpose of the key.
|
||||
|
||||
## Installing packages
|
||||
|
||||
Package installation can vary depending on the packaging system you are using. You can use [Ansible facts](https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#information-discovered-from-systems-facts) to determine which module to use. Ansible does offer a generic module called [package](http://docs.ansible.com/ansible/latest/modules/package_module.html) that uses `ansible_pkg_mgr` and calls the proper package manager for the system. For example, if you're using Fedora, the package module will call the DNF package manager.
|
||||
|
||||
The package module will work if you're doing a simple installation of packages. If you're doing more complex work, you will have to use the correct module for your system. For example, if you want to ignore GPG keys and install all the security packages on a RHEL-based system, you need to use the yum module. You will have different options depending on your [packaging module](http://docs.ansible.com/ansible/latest/modules/list_of_packaging_modules.html), but they usually offer more parameters than Ansible's generic package module.
|
||||
|
||||
Here is an example using the package module:
|
||||
|
||||
```yaml
|
||||
- name: install a package
|
||||
package:
|
||||
name: nginx
|
||||
state: installed
|
||||
```
|
||||
|
||||
The following uses the yum module to install NGINX, disable `gpg_check` from the repo, ignore the repository's certificates, and skip any broken packages that might show up.
|
||||
|
||||
```yaml
|
||||
- name: install a package
|
||||
yum:
|
||||
name: nginx
|
||||
state: installed
|
||||
disable_gpg_check: yes
|
||||
validate_certs: no
|
||||
skip_broken: yes
|
||||
```
|
||||
|
||||
Here is an example using [Apt](https://docs.ansible.com/ansible/latest/modules/apt_module.html). The Apt module tells Ansible to uninstall NGINX and not update the cache:
|
||||
|
||||
```yaml
|
||||
- name: install a package
|
||||
apt:
|
||||
name: nginx
|
||||
state: absent
|
||||
update_cache: no
|
||||
```
|
||||
|
||||
You can use `loop` when installing packages, but they are processed individually if you pass a list:
|
||||
|
||||
```yaml
|
||||
- name:
|
||||
- nginx
|
||||
- postgresql-server
|
||||
- ansible
|
||||
- httpd
|
||||
```
|
||||
|
||||
NOTE: Make sure you know the correct name of the package you want in the package manager you're using. Some names change depending on the package manager.
|
||||
|
||||
## Starting services
|
||||
|
||||
Much like packages, Ansible has different modules to start [services](http://docs.ansible.com/ansible/latest/modules/list_of_system_modules.html). Like in our previous example, where we used the package module to do a general installation of packages, the [service](http://docs.ansible.com/ansible/latest/modules/service_module.html#service-module) module does similar work with services, including with systemd and Upstart. (Check the module's documentation for a complete list.) Here is an example:
|
||||
|
||||
```yaml
|
||||
- name: start nginx
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
```
|
||||
|
||||
You can use Ansible's service module if you are just starting and stopping applications and don't need anything more sophisticated. But, like with the yum module, if you need more options, you will need to use the systemd module. For example, if you modify systemd files, then you need to do a `daemon-reload`, the service module won't work for that; you will have to use the systemd module.
|
||||
|
||||
```yaml
|
||||
- name: reload postgresql for new configuration and reload daemon
|
||||
systemd:
|
||||
name: postgresql
|
||||
state: reload
|
||||
daemon-reload: yes
|
||||
```
|
||||
|
||||
This is a great starting point, but it can become cumbersome because the service will always reload/restart. This a good place to use a [handler](https://docs.ansible.com/ansible/latest/user_guide/playbooks_intro.html#handlers-running-operations-on-change).
|
||||
|
||||
If you used best practices and created your role using `ansible-galaxy init "role name"`, then you should have the full [directory structure](http://docs.ansible.com/ansible/latest/user_guide/playbooks_best_practices.html#directory-layout). You can include the code above inside the `handlers/main.yml` and call it when you make a change with the application. For example:
|
||||
|
||||
handlers/main.yml
|
||||
```yaml
|
||||
- name: reload postgresql for new configuration and reload daemon
|
||||
systemd:
|
||||
name: postgresql
|
||||
state: reload
|
||||
daemon-reload: yes
|
||||
```
|
||||
|
||||
This is the task that calls the handler:
|
||||
```yaml
|
||||
- name: configure postgresql
|
||||
template:
|
||||
src: postgresql.service.j2
|
||||
dest: /usr/lib/systemd/system/postgresql.service
|
||||
notify: reload postgresql for new configuration and reload daemon
|
||||
```
|
||||
|
||||
It configures PostgreSQL by changing the systemd file, but instead of defining the restart in the tasks (like before), it calls the handler to do the restart at the end of the run. This is a good way to configure your application and keep it idempotent since the handler only runs when a task changes—not in the middle of your configuration.
|
||||
|
||||
The previous example uses the [template module](https://docs.ansible.com/ansible/latest/modules/template_module.html) and a [Jinja2 file](https://docs.ansible.com/ansible/latest/user_guide/playbooks_templating.html). One of the most wonderful things about configuring applications with Ansible is using templates. You can configure a whole file like `postgresql.service` with the full configuration you require. But, instead of changing every line, you can use variables and define the options somewhere else. This will let you change any variable at any time and be more versatile. For example:
|
||||
|
||||
```yaml
|
||||
[database]
|
||||
DB_TYPE = "{{ gitea_db }}"
|
||||
HOST = "{{ ansible_fqdn}}:3306"
|
||||
NAME = gitea
|
||||
USER = gitea
|
||||
PASSWD = "{{ gitea_db_passwd }}"
|
||||
SSL_MODE = disable
|
||||
PATH = "{{ gitea_db_dir }}/gitea.db
|
||||
```
|
||||
|
||||
This configures the database options on the file `app.ini` for [Gitea](https://gitea.io/en-us/). This is similar to writing Ansible tasks, even though it is a configuration file, and makes it easy to define variables and make changes. This can be expanded further if you are using [group_vars](https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#variable-examples), which allows you to define variables for all systems and specific groups (e.g., production vs. development). This makes it easier to manage variables, and you don't have to specify the same ones in every role.
|
||||
|
||||
## Provisioning a system
|
||||
|
||||
We've gone over several things you can do with Ansible on your system, but we haven't yet discussed how to provision a system. Here's an example of provisioning a virtual machine (VM) with the OpenStack cloud solution.
|
||||
|
||||
```yaml
|
||||
- name: create a VM in openstack
|
||||
osp_server:
|
||||
name: cloudera-namenode
|
||||
state: present
|
||||
cloud: openstack
|
||||
region_name: andromeda
|
||||
image: 923569a-c777-4g52-t3y9-cxvhl86zx345
|
||||
flavor_ram: 20146
|
||||
flavor: big
|
||||
auto_ip: yes
|
||||
volumes: cloudera-namenode
|
||||
```
|
||||
|
||||
All OpenStack modules start with `os`, which makes it easier to find them. The above configuration uses the osp-server module, which lets you add or remove an instance. It includes the name of the VM, its state, its cloud options, and how it authenticates to the API. More information about [cloud.yml](https://docs.openstack.org/python-openstackclient/pike/configuration/index.html) is available in the OpenStack docs, but if you don't want to use cloud.yml, you can use a dictionary that lists your credentials using the `auth` option. If you want to delete the VM, just change `state:` to `absent`.
|
||||
|
||||
Say you have a list of servers you shut down because you couldn't figure out how to get the applications working, and you want to start them again. You can use `os_server_action` to restart them (or rebuild them if you want to start from scratch).
|
||||
|
||||
Here is an example that starts the server and tells the modules the name of the instance:
|
||||
|
||||
```ymal
|
||||
- name: restart some servers
|
||||
os_server_action:
|
||||
action: start
|
||||
cloud: openstack
|
||||
region_name: andromeda
|
||||
server: cloudera-namenode
|
||||
```
|
||||
|
||||
Most OpenStack modules use similar options. Therefore, to rebuild the server, we can use the same options but change the `action` to `rebuild` and add the `image` we want it to use:
|
||||
|
||||
```yaml
|
||||
os_server_action:
|
||||
action: rebuild
|
||||
image: 923569a-c777-4g52-t3y9-cxvhl86zx345
|
||||
```
|
||||
|
||||
## Doing other things
|
||||
|
||||
There are modules for a lot of system admin tasks, but what should you do if there isn't one for what you are trying to do? Use the [shell](https://docs.ansible.com/ansible/latest/modules/shell_module.html) and [command](https://docs.ansible.com/ansible/latest/modules/command_module.html) modules, which allow you to run any command just like you do on the command line. Here's an example using the [OpenStack CLI](https://docs.openstack.org/python-openstackclient/pike/):
|
||||
|
||||
```yaml
|
||||
- name: run an opencli command
|
||||
command: "openstack hypervisor list"
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
They are so many ways you can do daily sysadmin tasks with Ansible. Using this automation tool can transform your hardest task into a simple solution, save you time, and make your work days shorter and more relaxed.
|
||||
@@ -1,11 +0,0 @@
|
||||
---
|
||||
title: Add Certificate Store to java execution on command line
|
||||
tags:
|
||||
- IT/Development/Java
|
||||
---
|
||||
|
||||
Add Certificate Store to java execution on command line
|
||||
|
||||
```shell
|
||||
-Djavax.net.ssl.keyStore=/globe/app/gcadmin/jdk/jdk1.6.0_30/jre/lib/security/cacerts
|
||||
```
|
||||
@@ -1,6 +0,0 @@
|
||||
---
|
||||
title: Add Running Content | Asciidoctor Docs
|
||||
source: https://docs.asciidoctor.org/pdf-converter/latest/theme/add-running-content/
|
||||
---
|
||||
|
||||
https://docs.asciidoctor.org/pdf-converter/latest/theme/add-running-content/
|
||||
@@ -1,650 +0,0 @@
|
||||
---
|
||||
title: Andreas Sommer ‒ I'm a software engineer – Blog – Ansible best practices
|
||||
source: https://andidog.de/blog/2017-04-24-ansible-best-practices
|
||||
tags:
|
||||
- IT/DevOps
|
||||
- IT/Development/Ansible
|
||||
---
|
||||
# [Ansible best practices](https://andidog.de/blog/2017-04-24-ansible-best-practices)
|
||||
|
||||
April 24, 2017
|
||||
|
||||
Ansible can be summarized as tool for running automated tasks on servers that require nothing but Python installed on the remote side. Typically used as configuration management framework, Ansible comes with a set of key benefits:
|
||||
|
||||
* Has simple configuration with YAML, avoiding copy-paste by applying customizable "roles"
|
||||
|
||||
* Uses inventories to scope and define the set of servers
|
||||
|
||||
* Fosters repeatable "playbook" runs, i.e. applying same configuration to a server twice should be idempotent
|
||||
|
||||
* Doesn’t suffer from feature matrix issues because by design it is a framework, not a full-fledged solution for configuration management. You cannot say "it supports only web servers X and Y, but not Z", as principally Ansible allows you to do _anything_ that is possible through manual server configuration.
|
||||
|
||||
|
||||
For a full introduction to Ansible, better read the [documentation](https://docs.ansible.com/ansible/index.html) first. This article assumes you have already made yourself familiar with the concepts and have some existing attempts of getting Ansible working for a certain use case, but want some guidance on improving the way you are working with Ansible.
|
||||
|
||||
The company behind Ansible gives [some official guidelines](https://www.ansible.com/blog/ansible-best-practices-essentials) which mostly relate to file structure, naming and other common rules. While these are helpful, as they are not immediately common sense for beginners, only a fraction of Ansible’s features and complexity of larger setups are touched by that small set of guidelines.
|
||||
|
||||
I would like to present my experience from roughly over 2 years of Ansible experience, during which I have used it for a test environment at work (allowing developers to test systems like in production), for configuring my laptop and eventually for setting up _this_ server and web application, and also my home server (a Raspberry Pi).
|
||||
|
||||
## Table of contents
|
||||
|
||||
* [Why Ansible over other frameworks?](#_why_ansible_over_other_frameworks)
|
||||
* [Choose your type of environment](#_choose_your_type_of_environment)
|
||||
* [Testing](#_testing)
|
||||
* [Staging/production](#_staging_production)
|
||||
* [Both non-production and production with one Ansible setup](#_both_non_production_and_production_with_one_ansible_setup)
|
||||
* [Careful when mixing manual and automated configuration](#_careful_when_mixing_manual_and_automated_configuration)
|
||||
* [Directory structure](#_directory_structure)
|
||||
* [Basic setup](#_basic_setup)
|
||||
* [Ansible configuration](#inventory-safe-default)
|
||||
* [Name tasks](#_name_tasks)
|
||||
* [Avoid skipping items](#avoid-skipping-items)
|
||||
* [Use and abuse of variables](#_use_and_abuse_of_variables)
|
||||
* [Tags](#_tags)
|
||||
* [sudo only where necessary](#_sudo_only_where_necessary)
|
||||
* [Assertions](#_assertions)
|
||||
* [Less code by using repetition primitives](#_less_code_by_using_repetition_primitives)
|
||||
* [Idempotency done right](#_idempotency_done_right)
|
||||
* [Leverage dynamic inventory](#dynamic-inventory)
|
||||
* [Modern Ansible features](#_modern_ansible_features)
|
||||
* [Off-topic: storing sensitive files](#storing-sensitive-files)
|
||||
* [Conclusion](#_conclusion)
|
||||
|
||||
## Why Ansible over other frameworks?
|
||||
|
||||
* Honestly, I did not compare many alternatives because the Ansible environment at work already existed when I joined and soon I believed Ansible to be the best option. The usual suspects Chef and Puppet did not really please me because the recipes do not really look like "infrastructure as code", but are too declarative and hard to understand in detail without looking at many files — while in a typical Ansible playbook, the actions taken can be read top-down like code.
|
||||
|
||||
* Many years ago, I built my own solution to deploy my personal web applications (["Site Deploy"](http://site-deploy.sourceforge.net/documentation/); UI-based). As hobby project, it never became popular or sophisticated enough, and eventually I learned that it suffers from the aforementioned feature matrix problem. Essentially it only supported the features relevant to me 🙄, without providing a framework to support anything on any server. Nevertheless, _Site Deploy_ already had support for configuring hosts with their connection data and services, with the help of variable substitution in most places. Or in other words: the very basic concepts of Ansible.
|
||||
|
||||
* Size of the user-base says a lot (cf. [their 2016 recap](https://www.ansible.com/blog/2016-community-year-in-review))
|
||||
|
||||
* Ansible aims at simple design, and becomes powerful by all the open-source modules to support services, applications, hardware, network, connections, etc.
|
||||
|
||||
* No server-side, persistent component required. Only Python needed to execute modules. Usual connection type is SSH, but custom modules are available for other types.
|
||||
|
||||
* Flat learning curve: once you understand the basic concepts (define hosts in inventory, set variables on different levels, write tasks in playbooks) and you know the commands/steps to configure a host manually, it’s easy to get started writing the same steps down in Ansible’s YAML format.
|
||||
|
||||
* Put simply, Ansible combines a set of hosts (inventory) with a list of applicable tasks (playbooks & roles), customizable with variables (at different places), allowing you to use pre-defined or own task modules and plugins (connection, value lookup, etc.). If you rolled your own, generic configuration management, you probably could not implement its principles much simpler. Since the concepts are so clearly separated, the source code (Python) is easy enough to read, if ever needed. Usually you will only have 2 situations to look into Ansible source code: learning how modules should be implemented and finding out about changed behavior when upgrading Ansible. The latter is not common and only occurred to me when switching from Ansible 1.8/1.9.x to 2.2.x which was quite a big step both in features, deprecations and also Ansible source code architecture itself.
|
||||
|
||||
* Change detection and idempotency. Whenever a task is run, there may be distinct outcomes: successfully changed, failed, skipped, unchanged. After running a playbook, you will have an overview of which tasks actually made changes on the target hosts. Usually, one would design playbooks in a way that running it a second time only gives "unchanged" outcomes, and Ansible’s modules support this idea of idempotency — for example, a `command` task can be marked as "already done that before, no changes required" by specifying `creates: /file/created/by/command` → once the file was successfully created, a repeated execution of the task module will not run the command again.
|
||||
|
||||
|
||||
## Choose your type of environment
|
||||
|
||||
Before we jump into practice, in the first thought we must consider what kind of Ansible-based setup we want to achieve, which greatly depends on the environment: work/personal, production/staging/testing, mixture of those…
|
||||
|
||||
### Testing
|
||||
|
||||
A test environment could have many faces: for instance, at my company we manage a separate Git repo for the test environment, unrelated to any production configuration and therefore very quick to modify for developers without lengthy code reviews or approval by devops, as no production system can be affected. Ansible is used to fully configure the system and our software within a virtual machine.
|
||||
|
||||
To spin up a VM, many solutions exist already — for instance [Vagrant](https://www.vagrantup.com/docs/getting-started/) with a small provisioning script that installs everything required for Ansible (only Python 😉) in the VM. We use a small Fabric script to bootstrap a FreeBSD VM and networking before continuing with Ansible.
|
||||
|
||||
### Staging/production
|
||||
|
||||
You should keep separate inventories for staging and production. If you don’t have staging, you should probably aim at automating staging setup with Ansible, since you already develop the production configuration in playbooks. But if you have both, the below recommendations apply.
|
||||
|
||||
### Both non-production and production with one Ansible setup
|
||||
|
||||
* When deploying both non-production and production environments from the same roles/playbooks, you must take care they don’t interfere with each other. For instance, you don’t want to send real e-mails to customers from staging, use different domain names, etc. The main way to decide on applying non-production vs. production properties should be your use of inventories and variables. An example will be discussed below ([dynamic inventory](#dynamic-inventory)).
|
||||
|
||||
* Careful — developers should not have live credentials such as SSH access to a production server, but probably be able to manage testing/staging systems?!
|
||||
|
||||
* GPG encryption of sensitive files or other protection to disallow unprivileged people from accessing production machines at all (mentioned in section [Storing sensitive files](#storing-sensitive-files))
|
||||
|
||||
* A safe default choice for inventories is required, and the default should most probably _not_ be production. This is described below in the section [Ansible configuration](#inventory-safe-default).
|
||||
|
||||
|
||||
## Careful when mixing manual and automated configuration
|
||||
|
||||
If you already have a production system manually set up — which is almost always the case, at least for initial OS installation steps which cannot be done via Ansible on physical servers — making the switch to fully automated configuration via Ansible is not easy. You may want to introduce automation step-by-step.
|
||||
|
||||
There are many imaginable ways to achieve that migration. I want to propose what I would do, admittedly without any real-world experience because I do not manage any production systems as developer.
|
||||
|
||||
* Develop playbooks and maintain [check mode and the `--diff` option](https://docs.ansible.com/ansible/playbooks_checkmode.html). This is not always easy and sometimes unnerving because you have to think both in normal mode (read-write) and check mode (read-only) when writing tasks, and apply appropriate options for modules that can’t handle it themselves (like `command`):
|
||||
|
||||
* `check_mode: no` (previously called `always_run: yes`)
|
||||
|
||||
* `changed_when`
|
||||
|
||||
* If you use tags: apply `tags: [ always ]` to tasks that e.g. provide results for subsequent tasks
|
||||
|
||||
|
||||
* Take care when making manual changes to servers. While often okay and necessary to react quickly, ensure the responsible people (e.g. devops team) can later reproduce the setup rather sooner than later with playbooks.
|
||||
|
||||
* Use [`{{ ansible_managed }}`](https://docs.ansible.com/ansible/intro_configuration.html#ansible-managed) to mark auto-generated files as such, so nobody unknowingly edits them manually
|
||||
|
||||
* Automate as much setup as you can, but only the parts that you are able to implement via Ansible without risk. For example, if you fear that an automatic database setup could go horribly wrong (like overwrite the existing production database), then rely on your distrust and do those steps manually.
|
||||
|
||||
|
||||
## Directory structure
|
||||
|
||||
Some [common directory layouts](https://docs.ansible.com/ansible/playbooks_best_practices.html#content-organization) are already part of the official documentation. In addition, you may want to separate your playbooks in subdirectories of `playbooks/` once your content grows too large. This cannot really be handled well in best practices because size and purpose of each project varies, so I just leave this on you to decide when time comes to "clean up". Note that if you use several playbook (sub-)directories and files relative to them (such as a custom `library` folder), you may have to symlink into the each directory containing playbooks.
|
||||
|
||||
## Basic setup
|
||||
|
||||
* It should be clear that Ansible uses text files and therefore should be versioned in a VCS like Git. Make sure you ignore files that should not be committed (for example in .gitignore: `*.retry`).
|
||||
|
||||
* Add something like `alias apl=ansible-playbook` in your shell. Or do you want to type `ansible-playbook` all the time?
|
||||
|
||||
* Require users to use at least a certain Ansible version, e.g. the latest version available in OS package managers at the time of starting your endeavors. You could have a little role `check-preconditions` doing this:
|
||||
|
||||
|
||||
# Check and require certain Ansible version. You should document why that
|
||||
# version is required, for instance:
|
||||
#
|
||||
# We require Ansible 2.2.1 or newer, see changelog
|
||||
# (https://github.com/ansible/ansible/blob/devel/CHANGELOG.md#221-the-battle-of-evermore---2017-01-16):
|
||||
# > Fixes a bug where undefined variables in with_* loops would cause a task
|
||||
# > failure even if the when condition would cause the task to be skipped.
|
||||
- name: Check Ansible version
|
||||
assert:
|
||||
that: '(ansible_version.major, ansible_version.minor, ansible_version.revision) >= (2, 2, 1)'
|
||||
msg: 'Please install the recommended version 2.2.1+. You have Ansible {{ ansible_version.string }}.'
|
||||
run_once: yes
|
||||
|
||||
## Ansible configuration
|
||||
|
||||
[`ansible.cfg`](https://docs.ansible.com/ansible/intro_configuration.html) allows you to tweak many settings to be a little saner than the defaults.
|
||||
|
||||
I recommend the following:
|
||||
|
||||
[defaults]
|
||||
# Default to no fact gathering because it's slow and "explicit is better
|
||||
# than implicit". Depending how you use variables, you may rather explicitly
|
||||
# define variables instead of relying on facts. You can enable this on
|
||||
# a per-playbook basis with `gather_facts: yes`.
|
||||
gathering = explicit
|
||||
# You should default either 1) to a non-risky inventory (not production)
|
||||
# or 2) point to a nonexistent one so that the person explicitly needs to
|
||||
# specify which one to use. I find the alternative 1) the least risky,
|
||||
# because 2) may lead to people creating shortcuts to deploy to live machines
|
||||
# which defeats the purpose of having a safer default here.
|
||||
inventory = inventories/test
|
||||
# Cows are scared of playbook developers
|
||||
nocows = 1
|
||||
|
||||
# Point to your local collection of extras, e.g. roles
|
||||
roles_path = ./roles
|
||||
|
||||
[ssh_connection]
|
||||
# Enable SSH multiplexing to increase performance
|
||||
pipelining = True
|
||||
control_path = /tmp/ansible-ssh-%%h-%%p-%%r
|
||||
|
||||
Choosing a safe default for the inventory is obviously important, thinking about recent catastrophic events like the [Amazon S3 outage](https://aws.amazon.com/message/41926/) that originated from a typo. Inventory names should not be confusable with each other, e.g. avoid using a prefix (`inv_live`, `inv_test`) because people hastily using tab completion may quickly introduce a typo.
|
||||
|
||||
If you are annoyed by `*.retry` files being created next to playbooks which hinders filename tab completion, an environment variable `ANSIBLE_RETRY_FILES_SAVE_PATH` lets you put them in a different place. For myself, I never use them as I’m not working with hundreds of hosts matching per playbook, so I just disable them with `ANSIBLE_RETRY_FILES_ENABLED=no`. Since that is a per-person decision, it should be an environment variable and not go into `ansible.cfg`.
|
||||
|
||||
## Name tasks
|
||||
|
||||
While already outlined in the [mentioned best practices article](https://www.ansible.com/blog/ansible-best-practices-essentials), I’d like to stress this point: names, comments and readability enable you and others to understand playbooks and roles later on. Ansible output on its own is too concise to really tell you the exact spot which is currently executing, and sometimes in large setups you will be searching that spot where you canceled (Ctrl+C) or a task failed fatally. Naming even the single tasks comes in handy here. Or tooling like [ARA](https://github.com/openstack/ara) which I personally did not try yet (overkill for me). After all we’re doing programming, and no reasonable language would allow you to make public functions unnamed/anonymous.
|
||||
|
||||
- name: 'Create directories for service {{ daemontools_service_name }}'
|
||||
file:
|
||||
state: directory
|
||||
dest: '{{ item }}'
|
||||
owner: '{{ daemontools_service_user }}'
|
||||
with_items: '{{ daemontools_service_directories }}'
|
||||
|
||||
In recent versions of Ansible, variables in the task `name` will be correctly substituted by their value in the console output, giving you visual feedback which part of the play is executing. That will be especially important once your configuration management project is growing and you run large collections of playbooks that execute a certain role (this example: `daemontools_service`) multiple times, for example to create a couple of permanent services.
|
||||
|
||||
Another advantage of this technique is that you can start where a play canceled/failed previously using the `--start-at-task="Task name"` option. That might not always work, e.g. if a task depends on a previously `register:`-ed variable, but is often helpful to save time by skipping all previously succeeded tasks. If you use static task names like "Install packages", then `--start-at-task="Install packages"` will start at the first occurrence of that task name in the play instead of a specific one ("Install dependencies for service XYZ").
|
||||
|
||||
## Avoid skipping items
|
||||
|
||||
…because it might hurt idempotency. What if your Ansible playbook adds a cronjob based on a boolean variable, and later you change the value to false? Using `when: my_bool` (value now changed to `no`) will skip the task, leaving the cronjob intact even though you expected it to be removed or disabled.
|
||||
|
||||
Here’s a slightly more complicated example: I had to set up a service that should be disabled by default until the developer enables it (because it would log error messages all the time unless the developer had established a required, manual SSH tunnel). Considerations:
|
||||
|
||||
* When configuring that service (let’s call the role `daemontools_service`; [daemontools](https://cr.yp.to/daemontools.html) are great to set up and manage services on *nix), we cannot simply enable/disable the service conditionally: the service should only be disabled initially (first playbook run = service created for the first time on remote machine) and on boot, but its state should be untouched if the developer had already enabled the service manually. Or in other words (since that fact is not easy to find out), leave state untouched if the service was already configured by a previous playbook run (= idempotency).
|
||||
|
||||
* You might also want an option to toggle enabling/disabling the service by default, so I’ll show that as well
|
||||
|
||||
|
||||
- hosts: xyz
|
||||
|
||||
vars:
|
||||
xyz_service_name: xyz-daemon
|
||||
|
||||
# Knob to enable/disable service by default (on reboot, and after
|
||||
# initial configuration)
|
||||
xyz_always_enabled: yes
|
||||
|
||||
roles:
|
||||
- role: daemontools_service
|
||||
daemontools_service_name: '{{ xyz_service_name }}'
|
||||
# Contrived variable, leaving state untouched should be the default
|
||||
# behavior unless you want to risk in production that services are
|
||||
# unintentionally enabled or disabled by a playbook run.
|
||||
daemontools_service_enabled: 'do_not_change_state'
|
||||
daemontools_service_other_variables: ...
|
||||
|
||||
tasks:
|
||||
- name: Disable XYZ service on boot
|
||||
cron:
|
||||
# We know that the role will symlink into /var/service,
|
||||
# as usual for daemontools
|
||||
job: "svc -d /var/service/{{ xyz_service_name }}"
|
||||
name: "xyz_default_disabled"
|
||||
special_time: "reboot"
|
||||
disabled: "{{ xyz_always_enabled }}"
|
||||
# ...or...
|
||||
# state: "{{ 'absent' if xyz_always_enabled else 'present' }}"
|
||||
tags: [ cron ]
|
||||
|
||||
- name: Disable XYZ service initially
|
||||
# After *all* initial configuration steps succeeded, take the service
|
||||
# down (`svc -d`) and mark the service as created so we...
|
||||
shell: "svc -d /var/service/{{ xyz_service_name }} && touch /var/service/{{ xyz_service_name }}/.created"
|
||||
args:
|
||||
# ...don't disable the service again if playbook is run again
|
||||
# (as someone may have enabled the service manually in the meantime).
|
||||
creates: "/var/service/{{ xyz_service_name }}/.created"
|
||||
when: not xyz_always_enabled
|
||||
tags: [ cron ]
|
||||
|
||||
## Use and abuse of variables
|
||||
|
||||
The most important principle for variables is that you should know which variables are used when looking at a portion of "Ansible code" (YAML). As an Ansible beginner, you might have 1) wondered a few times, or looked up, in which [order of precedence](https://docs.ansible.com/ansible/playbooks_variables.html#variable-precedence-where-should-i-put-a-variable) variables are taken into account. Or 2) you might have just given up and asked the author what is happening there. Like in software development, both 1) and 2) are fatal mistakes that hamper productivity — code must be readable (hopefully top-down or by looking within the surrounding 100 lines) and understandable by colleagues and other contributors. The case that you even _had_ to check the precedence shows the problem in the first place! **Variables should be specified at exactly one place** (or two places if a variable has a reasonable, overridable default value), **as close as possible to their usage** while still being at the relevant location and **most variables should be ultimately mandatory** so that Ansible loudly complains if a variable is missing. Let us look at a few examples to see what these basic rules mean.
|
||||
|
||||
[exampleservers]
|
||||
192.168.178.34
|
||||
|
||||
[all:vars]
|
||||
# Global helper variables.
|
||||
#
|
||||
# I tend to use these specific ones because when inside a role, Ansible 1.9.x
|
||||
# did not correctly find files/templates in some cases (if called from playbook
|
||||
# or dependency of other role). Not sure if that is still required for 2.x,
|
||||
# so don't copy-paste without understanding the need! These are really
|
||||
# just examples.
|
||||
my_playbooks_dir={{ inventory_dir + "/../playbooks" }}
|
||||
my_roles_dir={{ inventory_dir + "/../roles" }}
|
||||
|
||||
# With dynamic inventories, you can structure your per-host and per-group
|
||||
# variables in a nicer way than this INI file top-down format. If you use
|
||||
# INI files, at least try to create some structure, like alphabetical sorting
|
||||
# for hosts and groups.
|
||||
[exampleservers:vars]
|
||||
# Here, put only variables that belong to matching servers in general,
|
||||
# not to a functional component
|
||||
ansible_ssh_user=dog
|
||||
|
||||
Let’s look at an example role "mysql" which installs a MySQL server, optionally creates a database and then optionally gives privileges to the database (also allows value `*` for all databases) to a user:
|
||||
|
||||
# ...contrived excerpt...
|
||||
- name: Ensure database {{ database_name }} exists
|
||||
mysql_db:
|
||||
name: 'ourprefix_{{ database_name }}'
|
||||
when: database_name is defined and database_name != "*"
|
||||
|
||||
- name: Ensure database user {{ database_user }} exists and has access to {{ database_name }}
|
||||
mysql_user:
|
||||
name: '{{ database_user }}'
|
||||
password: '{{ database_password }}'
|
||||
priv: '{{ database_name }}.*:ALL'
|
||||
host: '%'
|
||||
when: database_user is defined and database_user
|
||||
# ...
|
||||
|
||||
The good parts first:
|
||||
|
||||
* Once `database_user` is given, the required variable `database_password` is mandatory, i.e. not checked with another `database_password is defined`.
|
||||
|
||||
* Variables used in task names, so that Ansible output clearly tells you what _exactly_ is currently happening
|
||||
|
||||
|
||||
But many things should be fixed here:
|
||||
|
||||
* Role (I called this example role "mysql") is doing way too many things at once without having a proper name. It should be split up into several roles: MySQL server installation, database creation, user & privilege setup. If you really find yourself doing these three things together repeatedly, you can still create an uber-role "mysql" that depends on the others.
|
||||
|
||||
* Role variables should be prefixed with the role name (e.g. `mysql_database_name`) because Ansible has no concept of namespaces or scoping these variables only to the role. This helps finding out quickly where a variable comes from. In contrast, host groups in Ansible are a way to scope variables so they are only available to a certain set of hosts.
|
||||
|
||||
* The database name prefix `ourprefix_` seems to be a hardcoded string. First of all, this led to a bug — privileges are not correctly applied to the user in the second task because the prefix was forgotten. The hardcoded string could be an internal variable (mark those with an underscore!) defined in the defaults file `roles/mysql/defaults/main.yml`: `_database_name_prefix: 'ourprefix_' # comment describing why it’s hardcoded`, and must be used wherever applicable. Whenever the value needs changing, you only need to touch one location.
|
||||
|
||||
* The special value `database_name: '*'` must be considered. Because the role has more than one responsibility (remember software engineering best practices?!), the variables have too many meanings. As said, there had better be a role "mysql_user" that only handles user creation and privileges — inside such a scoped role, using _one_ special value turns out to be less bug-prone.
|
||||
|
||||
* `database_user is defined and database_user` is again only necessary because the role is doing too much. In general, you should almost never use such a conditional. For no real reason, an empty value is principally allowed, and the task skipped in that case, and also if the variable is not specified. Once you decide to rename the variable and forget to replace one occurrence, you suddenly always skip the task. Whenever you can, let Ansible complain loudly when a variable is undefined, instead of e.g. skipping a task conditionally. In this example, splitting up the role is the solution to immediately make the variables mandatory. In other cases, you could introduce a default value for a role variable and allow users to override that value.
|
||||
|
||||
|
||||
Other practices regarding variables and their values and inline templates:
|
||||
|
||||
* Consistently name your variables. Just like code, Ansible plays should be grep-able. A simple text search through your Ansible setup repo should immediately find the source of a variable and other places where it is used.
|
||||
|
||||
* Avoid indirections like includes or `vars_files` if possible to keep relevant variables close to their use. In some cases, these helpers can shorten repeated code, but usually they just add one more level of having to jump around between files to grasp where a value comes from.
|
||||
|
||||
* Don’t use the special one-line dictionary syntax `mysql_db: name="{{ database_name }}" state="present" encoding="utf8mb4"`. YAML is very readable per se, so why use Ansible’s crippled syntax instead? It’s okay to use for single-variable tasks, though.
|
||||
|
||||
* On the same note, remove defaults which are obvious, such as the usual `state: present`. The "official" blog post on best practices recommends otherwise, but I like to keep code short and boilerplate-less.
|
||||
|
||||
* Decide for one quoting style and use it consistently: double quotes (`dest: "/etc/some.conf"`), single quotes (`dest: '/etc/some.conf'`) plus decision if you quote things that don’t need it (`dest: /etc/some.conf`). Keep in mind that `dest: {{ var }}` is not possible (must be quoted), and that `mode: 0755` (chmod) will give an unexpected result (no octal number support), so recommended practice is of course `mode: '0755'`.
|
||||
|
||||
* Also decide for one style for spacing and writing Jinja templates. I prefer `dest: '{{ var|int + 5 }}'` over `dest: '{{var | int + 5}}'` but only staying consistent is key, not the style you choose.
|
||||
|
||||
* You don’t need `---` at the top of YAML files. Just leave them away unless you know what it means.
|
||||
|
||||
|
||||
More rules can be shown best in a playbook example:
|
||||
|
||||
- hosts: web-analytics-database
|
||||
|
||||
vars:
|
||||
# Under `vars`, only put variables that really must be available in several
|
||||
# roles and tasks below. They have high precedence and therefore are prone
|
||||
# to clash with other variables of the same name (if you didn't follow
|
||||
# the principle of only one definition), or may set a value in one of the
|
||||
# below roles that you didn't want to be set! Therefore the role name
|
||||
# prefix is so important (`mysql_user_name` instead of `username` because
|
||||
# the latter might also be used in many other places and is hard to grep
|
||||
# for if used all over the place).
|
||||
|
||||
# When writing many playbooks, you probably don't want to hardcode your
|
||||
# DBA's username everywhere, but define a variable `database_admin_username`.
|
||||
# The rule of putting it as close as possible to its use tells you to
|
||||
# create a group "database-servers" containing all database hosts and put
|
||||
# the variable into `group_vars/database-servers.yml` so it's only available
|
||||
# in the limited scope.
|
||||
# Using variable name prefix `wa_` for "web analytics" as example.
|
||||
wa_mysql_user_name_prefix: '{{ database_admin_username }}'
|
||||
|
||||
roles:
|
||||
- role: mysql_server
|
||||
|
||||
# [Comment describing why we chose MySQL 5.5...]
|
||||
# Alternatively (but more risky than requiring it to be defined explicitly),
|
||||
# this might have a default value in the role, stating the version you
|
||||
# normally use in production.
|
||||
mysql_server_version: '5.5'
|
||||
|
||||
# Admin with full privileges
|
||||
- role: mysql_user
|
||||
mysql_user_name: '{{ wa_mysql_user_name_prefix }}_admin'
|
||||
|
||||
# This should not have a default. Defaulting to `ALL` means that on a
|
||||
# playbook mistake, a new user may get all privileges!
|
||||
mysql_user_privileges: 'ALL'
|
||||
|
||||
# Production passwords should not be committed to version control
|
||||
# in plaintext. See article section "Storing sensitive files".
|
||||
mysql_user_password: '{{ lookup("gpgfile", "secure/web-analytics-database.password") }}'
|
||||
|
||||
# Read-only access
|
||||
- role: mysql_user
|
||||
mysql_user_name: '{{ wa_mysql_user_name_prefix }}_readonly'
|
||||
mysql_user_privileges: 'SELECT'
|
||||
mysql_user_password: '{{ lookup("gpgfile", "secure/web-analytics-database.readonly.password") }}'
|
||||
|
||||
tasks:
|
||||
# With well-developed roles, you don't need extra {pre_}tasks!
|
||||
|
||||
## Tags
|
||||
|
||||
Use tags only for limiting to tasks for speed reasons, as in "only update config files". They should not be used to select a "function" of a playbook or perform regular tasks, or else one fine day you may forget to specify `-t only-do-xyz` and it will take down Amazon S3 or so 😜. It’s a debug and speed tool and not otherwise necessary. Better make your playbooks smaller and more task-focused if you use playbooks for repeated (maintenance) tasks.
|
||||
|
||||
- hosts: webservers
|
||||
|
||||
pre_tasks:
|
||||
- name: Include some vars (not generally recommended, see rules for variables)
|
||||
include_vars:
|
||||
file: myvars.yml
|
||||
# This must be tagged `always` because otherwise the variables are not available below
|
||||
tags: [ always ]
|
||||
|
||||
roles:
|
||||
- role: mysql
|
||||
# ...
|
||||
- role: mysql_user
|
||||
# ...
|
||||
|
||||
tasks:
|
||||
- name: Insert test data into SQL database
|
||||
# Mark with a separate tag that allows you to quickly apply new test
|
||||
# data to the existing MySQL database without having to wait for the
|
||||
# `mysql*` roles to finish (which would probably finish without changes).
|
||||
tags: [ test-sql ]
|
||||
# ...the task...
|
||||
|
||||
- name: Get system info
|
||||
# Contrived example command - in reality you should use `ansible_*` facts!
|
||||
command: 'uname -a'
|
||||
register: _uname_call
|
||||
# This needs tag `always` because the below task requires the result
|
||||
# `_uname_call`, and also has tags.
|
||||
tags: [ always ]
|
||||
check_mode: no
|
||||
# Just assume this task to be "unchanged"; instead tasks that depend
|
||||
# on the result will detect changes.
|
||||
changed_when: no
|
||||
|
||||
- name: Write system info
|
||||
copy:
|
||||
content: 'System: {{ _uname_call.stdout }}'
|
||||
dest: '/the/destination/path'
|
||||
tags: [ info ]
|
||||
|
||||
## sudo only where necessary
|
||||
|
||||
> The command failed, so I used `sudo command` and it worked fine. I’m now doing that everywhere because it’s easier.
|
||||
|
||||
It should be obvious to devops people, and hopefully also software developers, how very wrong this is. Just like you would not do that for manual commands, you also should not use `become: yes` globally for a whole playbook. Better only use it for tasks that actually need root rights. The `become` flag can be assigned to task blocks, avoiding repetition.
|
||||
|
||||
Another downside of "sudo everywhere" is that you have to take care of owner/group membership of directories and files you create, instead of defaulting to creating files owned by the connecting user.
|
||||
|
||||
## Assertions
|
||||
|
||||
If you ever had a to debug a case where a YAML dictionary was missing a key, you will know how bad Ansible is at telling you where an error came from (does not even tell you the dictionary variable name). I have found my own way to deal with that: assert a condition before actually running into the default error message. Only a very simple plugin is required. I opened a [pull request](https://github.com/ansible/ansible/pull/22529) already but the maintainers did not like the approach. Still I will recommend it here because of practical experience.
|
||||
|
||||
In `ansible.cfg`, ensure you have:
|
||||
|
||||
filter_plugins = ./plugins/filter
|
||||
|
||||
Then add the plugin `plugins/filter/assert.py`:
|
||||
|
||||
from ansible import errors
|
||||
|
||||
|
||||
def _assert(value, msg=''):
|
||||
# You can leave this condition away if you think it's too strict.
|
||||
# It's supposed to help find typos and type mistakes in assertion conditions.
|
||||
if not isinstance(value, bool):
|
||||
raise errors.AnsibleFilterError('assert filter requires boolean as input, got %s' % type(value))
|
||||
|
||||
if not value:
|
||||
raise errors.AnsibleFilterError('assertion failed: %s' % (msg or '<no message given>',))
|
||||
return ''
|
||||
|
||||
|
||||
class FilterModule(object):
|
||||
filter_map = {
|
||||
'assert': _assert,
|
||||
}
|
||||
|
||||
def filters(self):
|
||||
return self.filter_map
|
||||
|
||||
And use it like so:
|
||||
|
||||
- name: My task
|
||||
command: 'somecommand {{ (somevar|int > 5)|assert("somevar must be number > 5") }}{{ somevar }}'
|
||||
|
||||
This will only be able to test Jinja expressions, which are mostly but not 100% Python, but that should be enough.
|
||||
|
||||
## Less code by using repetition primitives
|
||||
|
||||
Ever wrote something like this?
|
||||
|
||||
- name: Do something with A
|
||||
command: dosomething A
|
||||
args:
|
||||
creates: /etc/somethingA
|
||||
when: '{{ is_admin_user["A"] }}'
|
||||
|
||||
- name: Do something with B
|
||||
command: dosomething --a-little-different B
|
||||
args:
|
||||
creates: /etc/somethingB
|
||||
when: '{{ is_admin_user["B"] }}'
|
||||
|
||||
A little exaggerated, but chances are that you suffered from copy-pasting too much Ansible code a few times in your configuration management career, and had the usual share of copy-paste mistakes and typos. Use [`with_items` and friends](https://docs.ansible.com/ansible/playbooks_loops.html) to your advantage:
|
||||
|
||||
- name: Do something with {{ item.name }}
|
||||
# At a task-level scope, it's totally okay to use non-mandatory variables
|
||||
# because you have to read only these few lines to understand what it's
|
||||
# doing. Use quoting if you want to support e.g. whitespace in values - just
|
||||
# saying, of course it's unusual on *nix...
|
||||
command: 'dosomething {{ item.args|default("") }} "{{ item.name }}"'
|
||||
args:
|
||||
creates: '/etc/something{{ item.name }}'
|
||||
# This is again following the rule of mandatory variables: making dictionary
|
||||
# keys mandatory protects you from typos and, in this case, from forgetting
|
||||
# to add people to a list. Get a good error message instead of just
|
||||
# `KeyError: B` by using the aforementioned assert module.
|
||||
when: '{{ item.name in is_admin_user|assert("User " + item.name + " missing in is_admin_user") }}{{ is_admin_user[item.name] }}'
|
||||
with_items:
|
||||
- name: A
|
||||
- name: B
|
||||
args: '--a-little-different'
|
||||
|
||||
More readable (once it gets bigger than my contrived example), and still does the same thing without being prone to copy-paste mistakes and complexity.
|
||||
|
||||
## Idempotency done right
|
||||
|
||||
This term was already mentioned a few times above. I want to give more hints on how to achieve repeatable playbook runs. "Idempotent" effectively means that on the second run, everything is green and no actual changes happened, which Ansible calls "ok" but in a well-developed setup means "unchanged" or "read-only action was performed".
|
||||
|
||||
The advantages should be pretty clear: not only can you see the exact `--diff` of what would happen on remote servers but also it gives visual feedback of what has _really_ changed (even if you don’t use diff mode).
|
||||
|
||||
Only a few considerations are necessary when writing tasks and playbooks, and you can get perfect idempotency in most cases:
|
||||
|
||||
* Avoid skipping items in certain cases (explained [above](#avoid-skipping-items))
|
||||
|
||||
* Often you need a `command` or `shell` task to perform very specific work. These tasks are always considered "changed" unless you define e.g. the `creates` argument or use `changed_when`.
|
||||
Example: `changed_when: _previously_registered_process_result.stdout == ''`
|
||||
On the same note, you may want to use `failed_when` in special cases, like if a program exits with code 0 even on errors.
|
||||
|
||||
* Always use same inputs. For example, don’t write a new timestamp into a file at every task run, but detect that the file is already up-to-date and does not need to be changed.
|
||||
|
||||
* Use built-in modules like `lineinfile`, `file`, `synchronize`, `copy` and `template` which support the relevant arguments to get idempotency if used right. They also typically fully support checked mode and other features that are hard to achieve yourself. Avoid `command`/`shell` if built-ins can be used instead.
|
||||
|
||||
* The argument `force: no` can be used for some modules to ensure that a task is only run once. For instance, you want a configuration template copied once if not existent, but afterwards manage it manually or with other tools, use `copy` and `force: no` to only upload the file if not yet existent, but on repeated run don’t make any changes to the existing remote file. This is not exactly related to idempotency but sometimes a valid use case.
|
||||
|
||||
|
||||
## Leverage dynamic inventory
|
||||
|
||||
Who needs to fiddle around carefully in check mode every time you change a production system, if there’s a staging environment which can bear a downtime if something goes wrong? Dynamic inventories can help separate staging and production in the most readable and — you guessed it — dynamic way.
|
||||
|
||||
Separate environments like test, staging or production of course have different properties like
|
||||
|
||||
* IP addresses and networks
|
||||
|
||||
* Host and domain names (FQDN)
|
||||
|
||||
* Set of hosts. Production software may be distributed to multiple servers, while your staging may simply be installed on one server or virtual machine.
|
||||
|
||||
* Other values
|
||||
|
||||
|
||||
Ideally, all of these should be specified in variables, so that you can use different values for each environment in the respective inventory, but with consistent variable names. In your roles and playbooks, you can then mostly ignore the fact that you have different environments — except for tasks that e.g. should not or only run in production, but that should also be decided by a variable (→ `when: not is_production`).
|
||||
|
||||
Check the official introduction to [Dynamic Inventories](https://docs.ansible.com/ansible/intro_dynamic_inventory.html) and [Developing Dynamic Inventory Sources](https://docs.ansible.com/ansible/dev_guide/developing_inventory.html) to understand my example inventory script. It forces the domain suffix `.test` for the "test" environment, and no suffix for the "live" environment.
|
||||
|
||||
#!/usr/bin/env python
|
||||
from __future__ import print_function
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import sys
|
||||
|
||||
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
|
||||
|
||||
# One way to go "dynamic": decide inventory type (test, staging, production)
|
||||
# based on inventory directory. Remember that Ansible calls the first file
|
||||
# found if you specify a directory as inventory. Symlinking the same script
|
||||
# into different directories allows you to use one inventory script
|
||||
# for several environments.
|
||||
IS_LIVE = {'live': True, 'test': False}[os.path.basename(SCRIPT_DIR)]
|
||||
DOMAIN_SUFFIX = '' if IS_LIVE else '.test'
|
||||
|
||||
|
||||
host_to_vars = {
|
||||
'first': {
|
||||
'public_ip': '1.2.3.4',
|
||||
'public_hostname': 'first.mystuff.example.com',
|
||||
},
|
||||
'second': {
|
||||
'public_ip': '1.2.3.5',
|
||||
'public_hostname': 'second.mystuff.example.com',
|
||||
},
|
||||
}
|
||||
groups = {
|
||||
'webservers': ['first', 'second'],
|
||||
}
|
||||
|
||||
|
||||
# Avoid human mistakes by applying test settings everywhere at once (instead
|
||||
# of inline per-variable)
|
||||
for host, variables in host_to_vars.items():
|
||||
if 'public_hostname' in variables:
|
||||
# Just an example. Realistically you may want to change `public_ip`
|
||||
# as well, plus other variables that differ between test and production.
|
||||
variables['public_hostname'] += DOMAIN_SUFFIX
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--debug', action='store_true', default=False)
|
||||
parser.add_argument('--host')
|
||||
parser.add_argument('--list', action='store_true', default=False)
|
||||
args = parser.parse_args()
|
||||
|
||||
def printJson(v):
|
||||
print(json.dumps(v, sort_keys=True, indent=4 if args.debug else None, separators=(',', ': ' if args.debug else ':')))
|
||||
|
||||
if args.host is not None:
|
||||
printJson(host_to_vars.get(args.host, {}))
|
||||
elif args.list:
|
||||
# Allow Ansible to only make one call to this script instead
|
||||
# of one per host.
|
||||
# See https://docs.ansible.com/ansible/dev_guide/developing_inventory.html#tuning-the-external-inventory-script
|
||||
groups['_meta'] = {
|
||||
'hostvars': host_to_vars,
|
||||
}
|
||||
printJson(groups)
|
||||
else:
|
||||
parser.print_usage(sys.stderr)
|
||||
print('Use either --host or --list', file=sys.stderr)
|
||||
exit(1)
|
||||
|
||||
Much more customization is possible with dynamic inventories. Another example: in my company, we use FreeBSD servers with our software installed and managed in jails. For developer testing, we have an Ansible setup to roughly resemble the production configuration. Unfortunately, at the time of writing, Ansible does not directly support configuration of jails or a concept of "child hosts". Therefore, we simply created an SSH connection plugin to connect to jails. Each jail looks like a regular host to Ansible, with the special naming pattern `jailname@servername`. Our dynamic inventory allows us to easily configure the hierarchy of groups > servers > jails and all their variables.
|
||||
|
||||
For personal and simple setups, in which only a few servers are involved, you might as well just use the INI-style inventory file format that Ansible uses by default. For the above example inventory, that would mean to split into two files `test.ini` and `live.ini` and managing them separately.
|
||||
|
||||
Dynamic inventories have one major downside compared to INI files: they don’t allow text diffs. Or in other words, you see the script change when looking at your VCS history, not the inventory diff. If you want a more explicit history, you may want a different setup: auto-generate INI inventory files with some script or template, then commit the INI files whenever you change something. Of course you will have to make sure to actually re-generate the files (potential for human mistakes!). I will leave this as exercise to you to decide.
|
||||
|
||||
## Modern Ansible features
|
||||
|
||||
While you may have introduced Ansible years back when it was still in v1.x or earlier stages, the framework is in very active development both by Red Hat and the community. [Ansible 2.0](https://www.ansible.com/blog/ansible-2.0-launch) introduced many powerful features and preparations for future improvements:
|
||||
|
||||
* [Task blocks (try-except-finally)](https://docs.ansible.com/ansible/playbooks_blocks.html): useful to perform cleanups if a block of tasks should be applied "either all or none of the tasks". Also can reduce repeated code because you can apply `when`, `become` and other flags to a block.
|
||||
|
||||
* [Dynamic includes](https://docs.ansible.com/ansible/playbooks_roles.html#dynamic-versus-static-includes): you can now use variables in includes, e.g. `- include: 'server-setup-{{ environment_name }}.yml'`
|
||||
|
||||
* [Conditional roles](https://docs.ansible.com/ansible/playbooks_conditionals.html#applying-when-to-roles-and-includes) are nothing new. I had some trouble with related bugs in 1.8.x, but those are obviously resolved and `role: […] when: somecondition` can help in some use cases to make code cleaner (similar to task blocks).
|
||||
|
||||
* Plugins were refactored to cater for clean, more maintainable APIs, and more changes will come in 2.x updates (like the persistent connections framework). Migrating your own library to 2.x should be simple in most cases.
|
||||
|
||||
|
||||
## Off-topic: storing sensitive files
|
||||
|
||||
For this special use case, I don’t have a recommendation since I never compared different approaches.
|
||||
|
||||
[Vault support](https://docs.ansible.com/ansible/playbooks_vault.html) seems to be a good start but seems to only support protection by a single password — a password which you then have to share among the team.
|
||||
|
||||
Several [built-in lookups](https://docs.ansible.com/ansible/playbooks_lookups.html) exist for password retrieval and storage, such as "password" (only supports plaintext) and Ansible 2.3’s "passwordstore".
|
||||
|
||||
In my company, we store somewhat sensitive files (such as passwords for financial test systems) in our developers' Ansible test environment repository, but in GPG-encrypted form. A script contains a list of files and people and encrypts the files. The encrypted .gpg files are committed, while original files should be in `.gitignore`. Within playbooks, we use a lookup plugin to decrypt the respective files. That way, access can be limited to a "need to know" group of people. While this is not tested for production use, it may be an idea to try and incorporate this extra level of security if you are dealing with sensitive information.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Ansible can be complex and overwhelming after developing playbooks in a wrong way for a long time. Just like for source code, readability, simplicity and common practices do not come naturally and yet are important to keep your Ansible code base lean and understandable. I’ve shown basic and advanced principles and some examples to structure your setup. Many things are left out of this general article, because either I have no experience with it yet (like Ansible Galaxy) or it would just be too much for an introductory article.
|
||||
|
||||
Happy automation!
|
||||
@@ -1,13 +0,0 @@
|
||||
---
|
||||
title: Anheften, Entfernen und Anpassen von Elementen im Schnellzugriff
|
||||
source: https://support.microsoft.com/de-de/windows/anheften-entfernen-und-anpassen-von-elementen-im-schnellzugriff-7344ff13-bdf4-9f40-7f76-0b1092d2495b
|
||||
---
|
||||
|
||||
Standardmäßig wird Explorer für den Schnellzugriff geöffnet. Sie können festlegen, dass ein Ordner im Schnellzugriff angezeigt wird, damit er leicht zu finden ist. Klicken Sie einfach mit der rechten Maustaste darauf, und wählen Sie **An Schnellzugriff anheften aus.** Wenn Sie den Ordner nicht mehr benötigen, können Sie ihn wieder lösen.
|
||||

|
||||
|
||||
Wenn Sie nur Ihre angehefteten Ordner anzeigen möchten, können Sie zuletzt verwendete Dateien oder häufig verwendete Ordner deaktivieren. Wechseln Sie zur Registerkarte **Ansicht** , und wählen Sie dann **Optionen aus.** Deaktivieren Sie im Abschnitt **Datenschutz** die Kontrollkästchen, und wählen Sie **Übernehmen aus.** Jetzt werden im Schnellzugriff nur Ihre angehefteten Ordner angezeigt. (Wenn Sie sie wieder aktivieren, werden elemente, die Sie zuvor aus dem Schnellzugriff entfernt haben, möglicherweise wieder angezeigt.)
|
||||

|
||||
|
||||
Sie können auch Elemente aus dem Schnellzugriff entfernen. Wenn etwas angezeigt wird, das Nicht mehr angezeigt werden soll, klicken Sie mit der rechten Maustaste darauf, und wählen **Sie Aus Schnellzugriff entfernen aus.** Das Element wird nicht mehr dort angezeigt, selbst wenn Sie es jeden Tag verwenden.
|
||||

|
||||
@@ -1,6 +0,0 @@
|
||||
---
|
||||
title: AsciiDoc Writer’s Guide | Asciidoctor
|
||||
source: https://asciidoctor.org/docs/asciidoc-writers-guide/
|
||||
---
|
||||
|
||||
https://asciidoctor.org/docs/asciidoc-writers-guide/
|
||||
@@ -1,164 +0,0 @@
|
||||
---
|
||||
title: AsciiDoc-Features für Pragmatisches
|
||||
source: https://entwickler.de/software-architektur/asciidoc-features-fur-pragmatisches/
|
||||
---
|
||||
|
||||
In den [letzten Ausgaben](https://entwickler.de/%22https://jaxenter.de/docs-as-code-65644/%22) haben wir gezeigt, wie Sie AsciiDoc-Dokumente modular aufbauen und in verschiedene Zielformate wie PDF, DOCX oder Confluence konvertieren können. Diesmal gehen wir auf ein paar der Features von AsciiDoc ein, die unserer Meinung nach bei Architekturdokumentation nützlich sein können.
|
||||
|
||||
Wie immer finden Sie den Quellcode dieser Kolumne [online](https://github.com/arc42/HHGDAC) \[1\]. Unsere Beispiele übersetzen wir wie in den vorherigen Folgen mit Gradle. Diesmal haben wir jedoch einen Defaulttask für Asciidoctor konfiguriert:
|
||||
|
||||
`> cd folge-4`
|
||||
|
||||
`> gradle`
|
||||
|
||||
Der AsciiDoc-Prozessor erzeugt den HTML-Output im Verzeichnis *build/asciidoc/html5/*, aber das kennen Sie mittlerweile ja schon.
|
||||
|
||||
## Das benötigen wir
|
||||
|
||||
Wenn wir aus der Vogelperspektive auf technische Dokumentation im Allgemeinen oder Dokumentation von Softwarearchitekturen im Speziellen schauen, benötigen wir verschiedene Features. Wir brauchen Text mit einfachen Auszeichnungen wie fett, kursiv oder auch farbig. Hierzu gehören ebenfalls die Überschriften und Listen, letztere entweder mit oder ohne Nummerierung. Denn Aufzählungen kommen in Dokus eben häufig vor, z. B. bei Anforderungen, Stakeholdern oder Schnittstellen. Ebenso bei Querverweisen und Hyperlinks: Von der abstrakten Übersicht möchten Sie auf mögliche Details verweisen, von Anforderungen auf die zugehörigen Teile der Lösung, von Schnittstellen auf deren Implementierung und von speziellen Begriffen auf deren Definitionen im Glossar. Als Nächstes brauchen wir Diagramme.
|
||||
|
||||
Diese nutzen Sie beispielsweise in der Kontextabgrenzung, der Baustein- und Laufzeitsicht sowie in der Deployment- respektive Verteilungssicht. Diagramme werden wir in AsciiDoc inkludieren, aber nicht direkt binär einbetten. Auch auf Bilder wollen wir verweisen können. Sie sollen eine Bildunterschrift erhalten und möglicherweise gewissen Größenvorgaben genügen. Wir widmen den Diagrammen die kommende Folge dieser Kolumne und beschränken uns daher hier aufs Einfachste. Ebenso wichtig wie Diagramme sind Tabellen, beispielsweise für eine priorisierte Übersicht von Qualitätszielen, für die Erläuterung der Bausteine einer Whitebox oder für die Erklärung der wesentlichen Eigenschaften einer Blackbox
|
||||
|
||||
Wir halten Tabellen für eines der effektivsten Strukturierungsmittel von technischen Dokus, und AsciiDoc hilft dabei gehörig weiter. Zu guter Letzt brauchen wir auch Warnungen oder sonstige besondere Auszeichnungen wie Tipps, To-dos oder Hilfen. Sonstiges wie Fußnoten, besondere Schriftarten, Ausrichtungen (rechts- oder linksbündig, zentriert) halten wir für weniger wichtig und werden diese Art von Features daher auslassen. Sie können jedoch relativ sicher sein, dass AsciiDoc auch für diese und ähnliche Sonderwünsche eine pragmatische Lösung bereithält. Im GitHub Repository unserer Kolumne finden Sie unter */folge-4* einige Beispiele dazu \[1\].
|
||||
|
||||
## So setzen wir es um
|
||||
|
||||
Hervorhebungen, fett und kursiv, gehen klar. Aber manchmal hätten Sies gerne bunt? Listing 1 zeigt, wie das in AsciiDoc geht. Dazu finden Sie im Beispiel einige Überschriften (headings), deren Ebenen für AsciiDoc echte Semantik besitzen: Die Schachtelung von Überschriften muss immer linear erfolgen, d. h. eine Überschrift 4 darf nicht direkt auf eine Überschrift 2 folgen, ansonsten gibt es eine Warnung. Das Ergebnis finden Sie in Abbildung 1.
|
||||
|
||||
**Listing 1: Textformate**
|
||||
|
||||
```markdown
|
||||
== Text Basics
|
||||
|
||||
=== Normal, Bold, Italics
|
||||
|
||||
Format text as normal, _italic_, *bold*, `mono`.
|
||||
|
||||
=== Small and Large
|
||||
|
||||
Sometimes [small]#smaller text# is nice,
|
||||
|
||||
sometimes [big]#big# is better.
|
||||
|
||||
|
||||
=== Verbatim
|
||||
|
||||
----
|
||||
> cd folge-4
|
||||
> gradle asciicoctor
|
||||
----
|
||||
|
||||
== Heading Level 1
|
||||
|
||||
=== Heading Level 2
|
||||
Some Text.
|
||||
```
|
||||
|
||||
[](https://jaxenter.de/wp-content/uploads/2018/01/mueller_starke_hhgdac_1.jpg)
|
||||
|
||||
Abb. 1: Textformate und Überschriften
|
||||
|
||||
Listen mit oder ohne Nummerierungen können wir in der Architekturdokumentation bei vielen Gelegenheiten einsetzen. In AsciiDoc funktionieren sie einfach und intuitiv. Listing 2 zeigt einige Beispiele. Beachten Sie, dass Sie durch ein +-Zeichen zwischen Absätzen die jeweilige Einrückung beibehalten können, falls mehrere Absätze zu einem einzelnen Unterpunkt Ihrer Liste gehören.
|
||||
|
||||
**Listing 2: Listen und Aufzählungen**
|
||||
|
||||
```
|
||||
== Lists and Enumerations
|
||||
|
||||
* first entry
|
||||
* one more
|
||||
|
||||
1. number one
|
||||
2. number two
|
||||
|
||||
=== Multi-line lists
|
||||
|
||||
* A list-entry can have multiple lines. +
|
||||
Use the continuation '+'... +
|
||||
So you can write entries of arbitrary length.
|
||||
|
||||
=== Labelled lists (e.g. glossary)
|
||||
|
||||
CPU:: Brain inside computer.
|
||||
DEV:: Brain in front of computer.
|
||||
```
|
||||
|
||||
[](https://jaxenter.de/wp-content/uploads/2018/01/mueller_starke_hhgdac_2.jpg)
|
||||
|
||||
Abb. 2: Listen
|
||||
|
||||
In jeder technischen Dokumentation benötigen wir Verweise, entweder auf externe Infos oder auf andere Teile der Doku. Hyperlinks zu externen Ressourcen erkennt AsciiDoc, optional können Sie den Links sprechende Namen geben. Interne Verweise (*cross-references*) sind interessanter, weil Sie sowohl den Verweis als auch das Sprungziel (*anchor*) definieren müssen. Den Verweis klammern Sie einfach in doppelte <>-Klammern. Das können wir uns gut merken, weil sie wie Pfeile aussehen. Vor den Anchor, also das Sprungziel, schreiben Sie in doppelten eckigen Klammern den gewünschten Anchor-Namen. Listing 3 zeigt ein Beispiel. Dabei versucht AsciiDoc soweit wie möglich dem Don’t-repeat-yourself-Prinzip zu genügen. So bekommt jede AsciiDoc-Überschrift automatisch einen Anchor, ohne dass Sie dafür etwas tun müssen. Den Namen des Anchors *\[\[anchor-name\]\]* können Sie oft weglassen. Details dazu finden Sie in unserem Repository im Verzeichnis *folge-4*.
|
||||
|
||||
**Listing 3: Links und Verweise**
|
||||
|
||||
```
|
||||
== Links
|
||||
=== Hyperlinks
|
||||
|
||||
Just write http://docs.arc42.org, will be converted into a hyperlink.
|
||||
|
||||
You might give links a https://github.com/aim42/aim42/issues/20[nice name]
|
||||
|
||||
=== Cross-References
|
||||
|
||||
<<some-anchor,explanation>> creates a link to the explanation of some-anchor.
|
||||
|
||||
[[some-anchor]]
|
||||
Here is the explanation...
|
||||
```
|
||||
|
||||
[](https://jaxenter.de/wp-content/uploads/2018/01/mueller_starke_hhgdac_3.jpg)
|
||||
|
||||
Abb. 3: Hyperlinks und Querverweise
|
||||
|
||||
Bilder und Diagramme einzufügen funktioniert ähnlich wie die *include*-Anweisungen, die wir für die modulare Dokumentation bereits kennengelernt haben, außer dass wir *image::arc42-logo.png\[\]* schreiben, statt *include*. Das werden wir uns in der nächsten Folge genauer anschauen, weil zu Diagrammen auch noch Bildunterschriften gehören und wir die Diagramme möglicherweise in ihrer Größe anpassen möchten.
|
||||
|
||||
Tabellen benötigen wir beispielsweise für die Stakeholder, die Erklärung der Kontextabgrenzung, die Qualitätsanforderungen in Form von Szenarien oder die kurze Erklärung von Bausteinen und Schnittstellen in den Whitebox-Templates der arc42-Bausteinsicht. Tabellen in AsciiDoc sind ungeheuer vielseitig. Von einer einfachen Syntax mit Pipe-Symbolen (|) bis hin zu CSV- oder sogar Excel-Formaten. Wir beschränken uns hier mal auf ein einfaches Beispiel: eine Tabelle mit priorisierten Qualitätsanforderungen (Listing 4). In eckigen Klammern geben wir die Spalten sowie Optionen für die Tabelle an, das *header* ist selbsterklärend. Interessant ist die Aufzählung *1, 2, 3* bei den Spalten: Die Ziffern geben die relativen Breiten der Spalten an: Im Beispiel hat die zweite Spalte die doppelte Breite der ersten, die dritte Spalte die dreifache. Das Resultat finden Sie in Abbildung 4.
|
||||
|
||||
**Listing 4: Tabellen**
|
||||
|
||||
```
|
||||
== Tables
|
||||
|
||||
[cols="1,2,3",options="header"]
|
||||
|===
|
||||
|Prio | Topic | Description
|
||||
|A-1 |Performance | rendering < 10 secs
|
||||
|A-2 |Flexibility | customizable style sheets
|
||||
|B-1 |Correctness | 99% of links shall be valid
|
||||
|===
|
||||
```
|
||||
|
||||
[](https://jaxenter.de/wp-content/uploads/2018/01/mueller_starke_hhgdac_4.jpg)
|
||||
|
||||
Abb. 4: Tabellen
|
||||
|
||||
Möchten Sie in Ihrer Doku auf Besonderheiten hinweisen, Tipps geben oder auch Warnungen aussprechen? AsciiDoc hilft Ihnen mit *admonitions* weiter. Listing 5 zeigt diese nützlichen Helfer, Abbildung 5 das Ergebnis.
|
||||
|
||||
**Listing 5: Hinweise**
|
||||
|
||||
```
|
||||
== Hinweise und Tipps
|
||||
|
||||
NOTE: Hervorhebungen sind einfach.
|
||||
WARNING: Warnung vor zu vielen Warnungen
|
||||
IMPORTANT: Wichtig
|
||||
|
||||
[TIP]
|
||||
--
|
||||
Das funktioniert auch über +
|
||||
mehrere Zeilen gut, dann allerdings +
|
||||
braucht es die '--'.
|
||||
--
|
||||
```
|
||||
|
||||
[](https://jaxenter.de/wp-content/uploads/2018/01/mueller_starke_hhgdac_5.jpg)
|
||||
|
||||
Abb. 5: Hervorhebungen
|
||||
|
||||
**AsciiDoctor-Versionen**
|
||||
Mit dieser Folge sind wir übrigens auf die aktuelle AsciiDoc-Version 1.5.6 umgestiegen: In der AsciiDoc-Syntax ändert sich dadurch nichts. Aber einige mögliche Fehlerquellen in Dokumentationen erkennt jetzt schon der AsciiDoc-Prozessor, beispielsweise doppelt definierte Sprungmarken (anchors). Die gewünschte Asciidoctor-Version konfigurieren wir in der Datei build.gradle.
|
||||
|
||||
## Fazit
|
||||
|
||||
AsciiDoc vereinfacht das Erstellen technischer Dokumentationen durch seine intuitive, gleichzeitig aber mächtige Syntax. Einfache Dinge sind in AsciiDoc auch einfach machbar, anspruchsvolle Aufgaben wie geschachtelte oder besonders formatierte Tabellen sind möglich. Sie können letztlich auch über das CSS-Styling der fertigen Dokumente fast beliebigen Sonderanforderungen genügen. Und es geht noch viel weiter. In der nächsten Folge zeigen wir, wie Sie mit Diagrammen umgehen können. Wir werden einige Diagramme aus dem Quelltext direkt rendern, andere werden wir als JPGs, PNGs oder SVGs einbauen. Bis dahin mal wieder: Happy Docu Coding.
|
||||
@@ -1,6 +0,0 @@
|
||||
---
|
||||
title: "Asciidoc and Asciidoctor: Write an e-book with code - Roelof Jan Elsinga"
|
||||
source: https://roelofjanelsinga.com/articles/write-an-e-book-with-code-asciidoc/
|
||||
---
|
||||
|
||||
https://roelofjanelsinga.com/articles/write-an-e-book-with-code-asciidoc/
|
||||
@@ -1,120 +0,0 @@
|
||||
---
|
||||
title: Autocomplete for Java Command Line Applications
|
||||
source: https://picocli.info/autocomplete.html
|
||||
---
|
||||
|
||||
This tutorial uses the [CheckSum example application](https://picocli.info/index.html#CheckSum-application) from the picocli user manual. We created a class `com.myproject.CheckSum` and put it in a jar file, `myproject.jar`.
|
||||
|
||||
Follow these steps to give this application command line autocompletion.
|
||||
|
||||
### 2.1. Create Command
|
||||
|
||||
First, create an executable command that runs the main application class. For this tutorial, the command name is `jchecksum`.
|
||||
|
||||
We use an [alias](https://en.wikipedia.org/wiki/Alias_%28command%29) here to create the command (see [alternatives](#_alternative_ways_to_define_commands)):
|
||||
|
||||
```
|
||||
alias jchecksum='java -cp "picocli-1.0.0.jar;myproject.jar" com.myproject.CheckSum'
|
||||
```
|
||||
|
||||
Let’s test that the command works:
|
||||
|
||||
```
|
||||
$ jchecksum --help
|
||||
Usage: jchecksum [-h] [-a=<algorithm>] <file>
|
||||
Prints the checksum (MD5 by default) of a file to STDOUT.
|
||||
file The file whose checksum to calculate.
|
||||
-a, --algorithm=<algorithm> MD5, SHA-1, SHA-256, ...
|
||||
-h, --help Show this help message and exit.
|
||||
```
|
||||
|
||||
### 2.2. Generate Completion Script
|
||||
|
||||
To generate the completion script, run the `picocli.AutoComplete` class as a java application. Pass it the command name and the fully qualified class name of the annotated command class. (See also [full description](#_completion_script_generation_details) for using `AutoComplete`.)
|
||||
|
||||
```
|
||||
java -cp "picocli-1.0.0.jar;myproject.jar" picocli.AutoComplete -n jchecksum com.myproject.CheckSum
|
||||
```
|
||||
|
||||
This generates a `jchecksum_completion` script in the current directory. To verify:
|
||||
|
||||
```
|
||||
$ ls
|
||||
jchecksum_completion myproject.jar picocli-1.0.0.jar
|
||||
```
|
||||
|
||||
### 2.3. Install Completion Script
|
||||
|
||||
Finally, [source](https://tldp.org/HOWTO/Bash-Prompt-HOWTO/x237.html) the completion script:
|
||||
|
||||
…and you are done. The `jchecksum` command now has autocompletion:
|
||||
|
||||
```
|
||||
$ jchecksum <TAB><TAB>
|
||||
-a --algorithm -h --help
|
||||
```
|
||||
|
||||
### 2.4. Permanent Installation
|
||||
|
||||
The above will last for the duration of your shell session. If you want to make this permanent you need to modify your ~/.bashrc or ~/.zshrc file to add a line that defines the command alias and a line that sources the completion script:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
echo "alias jchecksum='java -cp \"picocli-1.0.0.jar;myproject.jar\" com.myproject.CheckSum'" >> ~/.bashrc
|
||||
echo ". jchecksum_completion" >> ~/.bashrc
|
||||
```
|
||||
|
||||
Make sure to use `>>` (append), using a single `>` would overwrite the file.
|
||||
|
||||
`~/.bashrc` indicates `.bashrc` is in your home directory.
|
||||
|
||||
### 2.5. Distribution
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| | Have a subcommand that generates a completion script. |
|
||||
|
||||
You could generate completion scripts for your commands [during the build](#_generating_completion_scripts_during_the_build) and distribute them with your application, but an alternative is to give your application the ability to generate its own completion script on demand.
|
||||
|
||||
That allows end users to install completion for your application with a single command. For example, if your utility is called `mycommand`, users can install completion for it by running the following command:
|
||||
|
||||
Bash
|
||||
|
||||
```
|
||||
$ source <(mycommand generate-completion)
|
||||
```
|
||||
|
||||
This can be accomplished by registering the built-in `picocli.AutoComplete.GenerateCompletion` class as a subcommand of the top-level command.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
import picocli.AutoComplete.GenerateCompletion;
|
||||
import picocli.CommandLine;
|
||||
import picocli.CommandLine.Command;
|
||||
|
||||
@Command(name = "mycommand", subcommands = GenerateCompletion.class)
|
||||
public class MyApp implements Runnable {
|
||||
|
||||
@Override
|
||||
public void run() { // top-level command business logic here
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
new CommandLine(new MyApp()).execute(args);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
By default, the `generate-completion` command shows up as a subcommand in the usage help message of its parent command. Applications that want the completion subcommand to be hidden in the usage help message, can do the following:
|
||||
|
||||
```
|
||||
public static void main(String... args) {
|
||||
CommandLine cmd = new CommandLine(new MyApp());
|
||||
CommandLine gen = cmd.getSubcommands().get("generate-completion");
|
||||
gen.getCommandSpec().usageMessage().hidden(true);
|
||||
int exitCode = cmd.execute(args);
|
||||
// ...
|
||||
}
|
||||
```
|
||||
@@ -1,13 +0,0 @@
|
||||
---
|
||||
tags:
|
||||
- IT/Tools
|
||||
---
|
||||
|
||||
## HowTo
|
||||
https://www.tecchannel.de/a/grsync-rsync-backups-komfortabel-durchfuehren,2020140
|
||||
|
||||
## Links
|
||||
http://www.opbyte.it/grsync/download.html
|
||||
https://sourceforge.net/projects/grsync-win/
|
||||
|
||||
https://personal-backup.rathlev-home.de/
|
||||
@@ -1,65 +0,0 @@
|
||||
---
|
||||
title: Bash Shortcuts For Maximum Productivity
|
||||
tags:
|
||||
- IT/Tools/Shell/bash
|
||||
- IT/Shell
|
||||
---
|
||||
|
||||
## Bash Shortcuts For Maximum Productivity
|
||||
|
||||
### Command Editing Shortcuts
|
||||
|
||||
| Shortcut | Description |
|
||||
| -------- | ----------- |
|
||||
| Ctrl + a | go to the start of the command line |
|
||||
| Ctrl + e | go to the end of the command line |
|
||||
| Ctrl + k | delete from cursor to the end of the command line |
|
||||
| Ctrl + u | delete from cursor to the start of the command line |
|
||||
| Ctrl + w | delete from cursor to start of word (i.e. delete backwards one word) |
|
||||
| Ctrl + y | paste word or text that was cut using one of the deletion shortcuts (such as the one above) after the cursor |
|
||||
| Ctrl + xx | move between start of command line and current cursor position (and back again) |
|
||||
| Alt + b | move backward one word (or go to start of word the cursor is currently on) |
|
||||
| Alt + f | move forward one word (or go to end of word the cursor is currently on) |
|
||||
| Alt + d | delete to end of word starting at cursor (whole word if cursor is at the beginning of word) |
|
||||
| Alt + c | capitalize to end of word starting at cursor (whole word if cursor is at the beginning of word) |
|
||||
| Alt + u | make uppercase from cursor to end of word |
|
||||
| Alt + l | make lowercase from cursor to end of word |
|
||||
| Alt + t | swap current word with previous |
|
||||
| Ctrl + f | move forward one character |
|
||||
| Ctrl + b | move backward one character |
|
||||
| Ctrl + d | delete character under the cursor |
|
||||
| Ctrl + h | delete character before the cursor |
|
||||
| Ctrl + t | swap character under cursor with the previous one |
|
||||
|
||||
### Command Recall Shortcuts
|
||||
|
||||
| Shortcut | Description |
|
||||
| --------- | ------------- |
|
||||
| Ctrl + r | search the history backwards |
|
||||
| Ctrl + g | escape from history searching mode |
|
||||
| Ctrl + p | previous command in history (i.e. walk back through the command history) |
|
||||
| Ctrl + n | next command in history (i.e. walk forward through the command history) |
|
||||
| Alt + . | use the last word of the previous command |
|
||||
|
||||
### Command Control Shortcuts
|
||||
|
||||
| Shortcut | Description |
|
||||
| -------- | ----------- |
|
||||
| Ctrl + l | clear the screen |
|
||||
| Ctrl + s | stops the output to the screen (for long running verbose command) |
|
||||
| Ctrl + q | allow output to the screen (if previously stopped using command above) |
|
||||
| Ctrl + c | terminate the command |
|
||||
| Ctrl + z | suspend/stop the command |
|
||||
|
||||
### Bash Bang (!) Commands
|
||||
Bash also has some handy features that use the ! (bang) to allow you to do some funky stuff with bash commands.
|
||||
|
||||
| Shortcut | Description |
|
||||
| --------- | ------------- |
|
||||
| `!!` | run last command |
|
||||
| `!blah` | run the most recent command that starts with ‘blah’ (e.g. !ls) |
|
||||
| `!blah:p` | print out the command that !blah would run (also adds it as the latest command in the command history) |
|
||||
| `!$` | the last word of the previous command (same as Alt + .) |
|
||||
| `!$:p` | print out the word that `!$` would substitute |
|
||||
| `!*` | the previous command except for the last word (e.g. if you type ‘find some_file.txt /‘, then !* would give you ‘find some_file.txt‘) |
|
||||
| `!*:p` | print out what `!*` would substitute |
|
||||
@@ -1,250 +0,0 @@
|
||||
---
|
||||
title: Build a CRUD Web App With Python and Flask - Part Three
|
||||
source: https://www.digitalocean.com/community/tutorials/build-a-crud-web-app-with-python-and-flask-part-three
|
||||
---
|
||||
|
||||
This tutorial is out of date and no longer maintained.
|
||||
|
||||
### [Introduction](#introduction)
|
||||
|
||||
This is the last part of a three-part tutorial to build an employee management web app, named Project Dream Team. In [Part Two](https://www.digitalocean.com/community/tutorials/build-a-crud-web-app-with-python-and-flask-part-two) of the tutorial, we built out the CRUD functionality of the app.
|
||||
|
||||
We created forms, views, and templates to list, add, edit and delete departments and roles. By the end of Part Two, we could assign (and re-assign) departments and roles to employees.
|
||||
|
||||
In Part Three, we will cover:
|
||||
|
||||
1. Custom error pages
|
||||
2. Unit tests
|
||||
3. Deployment on PythonAnywhere
|
||||
|
||||
## [Custom Error Pages](#custom-error-pages)
|
||||
|
||||
Web applications make use of HTTP errors to let users know that something has gone wrong. Default error pages are usually quite plain, so we will create our own custom ones for the following common HTTP errors:
|
||||
|
||||
1. 403 Forbidden: this occurs when a user is logged in (authenticated) but does not have sufficient permissions to access the resource. This is the error we have been throwing when non-admins attempt to access an admin view.
|
||||
2. 404 Not Found: this occurs when a user attempts to access a non-existent resource such as an invalid URL, e.g `http://127.0.0.1:5000/nothinghere`.
|
||||
3. 500 Internal Server Error: this is a general error thrown when a more specific error cannot be determined. It means that for some reason, the server cannot process the request.
|
||||
|
||||
We’ll start by writing the views for the custom error pages. In your `app/__init__.py` file, add the following code:
|
||||
|
||||
app/\_\_init\_\_.py
|
||||
|
||||
We make use of Flask’s `@app.errorhandler` decorator to define the error page views, where we pass in the status code as a parameter.
|
||||
|
||||
Next, we’ll create the template files. Create an `app/templates/errors` directory, and in it, create `403.html`, `404.html`, and `500.html`.
|
||||
|
||||
app/templates/errors/403.html
|
||||
|
||||
app/templates/errors/404.html
|
||||
|
||||
app/templates/errors/500.html
|
||||
|
||||
All the templates give a brief description of the error and a button that links to the homepage.
|
||||
|
||||
Run the app and log in as a non-admin user, then attempt to access `http://127.0.0.1:5000/admin/departments`. You should get the following page:
|
||||
|
||||
<img width="748" height="463" src="../_resources/UK4wT1TXRKy92WUKdQqC_Screen_Shot_e3e730a66e604ce58.png"/>
|
||||
|
||||
Now attempt to access this non-existent page: `http://127.0.0.1:5000/nothinghere`. You should see:
|
||||
|
||||
<img width="748" height="462" src="../_resources/gB4WfFWQ9Wvces6B5eby_Screen_Shot_3664c8136d2b4a9b9.png"/>
|
||||
|
||||
To view the internal server error page, we’ll create a temporary route where we’ll use Flask’s `abort()` function to raise a 500 error. In the `app/__init__.py` file, add the following:
|
||||
|
||||
app/\_\_init\_\_.py
|
||||
|
||||
Go to `http://127.0.0.1:5000/500`; you should see the following page:
|
||||
|
||||
<img width="748" height="460" src="../_resources/Ufqg3WlqT8qS5iktOmnc_Screen_Shot_7843d2c46c6441538.png"/>
|
||||
|
||||
Now you can remove the temporary route we just created for the internal server error.
|
||||
|
||||
## [Tests](#tests)
|
||||
|
||||
Now, let’s write some tests for the app. The importance of testing software can’t be overstated. Tests help ensure that your app is working as expected, without the need for you to manually test all of your app’s functionality.
|
||||
|
||||
We’ll begin by creating a test database, and give the database user we created in [Part One](https://www.digitalocean.com/community/tutorials/build-a-crud-web-app-with-python-and-flask-part-one) all privileges on it:
|
||||
|
||||
```
|
||||
mysql> CREATE DATABASE dreamteam_test;
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
mysql> GRANT ALL PRIVILEGES ON dreamteam_test . * TO 'dt_admin'@'localhost';
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
```
|
||||
|
||||
Now we need to edit the `config.py` file to add configurations for testing. Delete the current contents and replace them with the following code:
|
||||
|
||||
config.py
|
||||
|
||||
We have put `DEBUG = True` in the base class, `Config` so that it is the default setting. We override this in the `ProductionConfig` class. In the `TestingConfig` class, we set the `TESTING` configuration variable to `True`.
|
||||
|
||||
We will be writing unit tests. Unit tests are written to test small, individual, and fairly isolated units of code, such as functions. We will make use of [Flask-Testing](https://pythonhosted.org/Flask-Testing/), an extension that provides unit testing utilities for Flask.
|
||||
|
||||
Next, create a `tests.py` file in the root directory of your app. In it, add the following code:
|
||||
|
||||
tests.py
|
||||
|
||||
In the base class above, `TestBase`, we have a `create_app` method, where we pass in the configurations for testing.
|
||||
|
||||
We also have two other methods: `setUp` and `tearDown`. The `setUp` method will be called automatically before every test we run. In it, we create two test users, one admin and one non-admin, and save them to the database. The `tearDown` method will be called automatically after every test. In it, we remove the database session and drop all database tables.
|
||||
|
||||
To run the tests, we will run the `tests.py` file:
|
||||
|
||||
```
|
||||
Output
|
||||
|
||||
----------------------------------------------------------------------
|
||||
Ran 0 tests in 0.000s
|
||||
|
||||
OK
|
||||
```
|
||||
|
||||
The output above lets us know that our test setup is OK. Now let’s write some tests.
|
||||
|
||||
tests.py
|
||||
|
||||
We’ve added three classes: `TestModels`, `TestViews` and `TestErrorPages`.
|
||||
|
||||
The first class has methods to test that each of the models in the app is working as expected. This is done by querying the database to check that the correct number of records exists in each table.
|
||||
|
||||
The second class has methods that test the views in the app to ensure the expected status code is returned. For non-restricted views, such as the homepage and the login page, the `200 OK` code should be returned; this means that everything is OK and the request has succeeded. For restricted views that require authenticated access, a `302 Found` code is returned. This means that the page is redirected to an existing resource, in this case, the login page. We test both that the `302 Found` code is returned and that the page redirects to the login page.
|
||||
|
||||
The third class has methods to ensure that the error pages we created earlier are shown when the respective error occurs.
|
||||
|
||||
Note that each test method begins with `test`. This is deliberate, because `unittest`, the Python unit testing framework, uses the `test` prefix to automatically identify test methods. Also note that we have not written tests for the front-end to ensure users can register and login, and to ensure administrators can create departments and roles and assign them to employees. This can be done using a tool like [Selenium Webdriver](http://www.seleniumhq.org/projects/webdriver/); however, this is outside the scope of this tutorial.
|
||||
|
||||
Run the tests again:
|
||||
|
||||
```
|
||||
Output
|
||||
|
||||
..............
|
||||
----------------------------------------------------------------------
|
||||
Ran 14 tests in 2.313s
|
||||
|
||||
OK
|
||||
```
|
||||
|
||||
Success! The tests are passing.
|
||||
|
||||
## [Deploy!](#deploy)
|
||||
|
||||
Now for the final part of the tutorial: deployment. So far, we’ve been running the app locally. In this stage, we will publish the application on the internet so that other people can use it. We will use [PythonAnywhere](https://www.pythonanywhere.com/), a Platform as a Service (PaaS) that is easy to set up, secure, and scalable, not to mention free for basic accounts!
|
||||
|
||||
### [PythonAnywhere Set-Up](#pythonanywhere-set-up)
|
||||
|
||||
Create a free PythonAnywhere account [here](https://www.pythonanywhere.com/registration/register/beginner/) if you don’t already have one. Be sure to select your username carefully since the app will be accessible at `==your-username==.pythonanywhere.com`.
|
||||
|
||||
Once you’ve signed up, `==your-username==.pythonanywhere.com` should show this page:
|
||||
|
||||
<img width="748" height="376" src="../_resources/K5JRcBqoTcytpmPr4QNP_Screen_Shot_1d4bac826c714f349.png"/>
|
||||
|
||||
We will use git to upload the app to PythonAnywhere. If you’ve been pushing your code to cloud repository management systems like [Bitbucket](https://bitbucket.org/), [GitLab](https://about.gitlab.com/) or [GitHub](https://www.digitalocean.com/community/tutorials/github.com/), that’s great! If not, now’s the time to do it. Remember that we won’t be pushing the `instance` directory, so be sure to include it in your `.gitignore` file, like so:
|
||||
|
||||
.gitignore
|
||||
|
||||
```
|
||||
*.pyc
|
||||
instance/
|
||||
```
|
||||
|
||||
Also, ensure that your `requirements.txt` file is up to date using the `pip freeze` command before pushing your code:
|
||||
|
||||
Now, log in to your PythonAnywhere account. In your dashboard, there’s a `Consoles` tab; use it to start a new Bash console.
|
||||
|
||||
<img width="748" height="190" src="../_resources/DiF4e6kTgK9BI0voIjJY_Screen_Shot_768191532a0a45bd8.png"/>
|
||||
|
||||
In the PythonAnywhere Bash console, clone your repository.
|
||||
|
||||
Next, we will create a virtualenv, then install the dependencies from the `requirements.txt` file. Because PythonAnywhere installs [virtualenvwrapper](https://virtualenvwrapper.readthedocs.io/en/latest/) for all users by default, we can use its commands:
|
||||
|
||||
We’ve created a virtualenv called `dream-team`. The virtualenv is automatically activated. We then entered the project directory and installed the dependencies.
|
||||
|
||||
Now, in the Web tab on your dashboard, create a new web app.
|
||||
|
||||
<img width="748" height="171" src="../_resources/e7V0C5dvR7R6BfDoTwfJ_Screen_Shot_e0e304d2078a4689a.png"/>
|
||||
|
||||
Select the Manual Configuration option (**not** the Flask option), and choose Python 2.7 as your Python version. Once the web app is created, its configurations will be loaded. Scroll down to the Virtualenv section, and enter the name of the virtualenv you just created:
|
||||
|
||||
<img width="748" height="153" src="../_resources/fHiIGtGYTOmhabfn8Ig2_Screen_Shot_1fda64fa1d40418da.png"/>
|
||||
|
||||
### [Database Configuration](#database-configuration)
|
||||
|
||||
Next, we will set up the MySQL production database. In the Databases tab of your PythonAnywhere dashboard, set a new password and then initialize a MySQL server:
|
||||
|
||||
<img width="748" height="343" src="../_resources/twvZCyDpRqOMCZN45k25_Screen_Shot_a51354e3272d4867b.png"/>
|
||||
|
||||
The password above will be your database user password. Next, create a new database if you wish. PythonAnywhere already has a default database that you can use.
|
||||
|
||||
<img width="748" height="196" src="../_resources/GcyKxAJRRB2Rqfny7ys1_database_na_9df284ff50964ad6b.png"/>
|
||||
|
||||
By default, the database user is your username and has all privileges granted on any databases created. Now, we need to migrate the database and populate it with the tables. In a Bash console on PythonAnywhere, we will run the `flask db upgrade` command, since we already have the migrations directory that we created locally. Before running the commands, ensure you are in your virtualenv as well as in the project directory.
|
||||
|
||||
When setting the `SQLALCHEMY_DATABASE_URI` environment variable, remember to replace `==your-username==`, `==your-password==`, `==your-host-address==` and `==your-database-name==` with their correct values. The username, host address and database name can be found in the MySQL settings in the Databases tab on your dashboard. For example, using the information below, my database URI is: `mysql://==projectdreamteam==:==password==@==projectdreamteam.mysql.pythonanywhere-services.com==/==projectdreamteam$dreamteam_db==`
|
||||
|
||||

|
||||
|
||||
### [WSGI File](#wsgi-file)
|
||||
|
||||
Now we will edit the WSGI file, which PythonAnywhere uses to serve the app. Remember that we are not pushing the `instance` directory to version control. We, therefore, need to configure the environment variables for production, which we will do in the WSGI file.
|
||||
|
||||
In the Code section of the Web tab on your dashboard, click on the link to the WSGI configuration file.
|
||||
|
||||
<img width="748" height="173" src="../_resources/gcvgsyaBSLixNO5Vxjie_wsgi_file_1316841568d54b93a12.png"/>
|
||||
|
||||
Delete all the current contents of the file, and replace them with the following:
|
||||
|
||||
In the file above, we tell PythonAnywhere to get the variable `app` from the `run.py` file and serve it as the application. We also set the `FLASK_CONFIG`, `SECRET_KEY`, and `SQLALCHEMY_DATABASE_URI` environment variables. Feel free to alter the secret key. Note that the `path` variable should contain your username and project directory name, so be sure to replace it with the correct values. The same applies to the database URI environment variable.
|
||||
|
||||
We also need to edit our local `app/__init__.py` file to prevent it from loading the `instance/config.py` file in production, as well as to load the configuration variables we’ve set:
|
||||
|
||||
app/\_\_init\_\_.py
|
||||
|
||||
Push your changes to version control, and pull them on the PythonAnywhere Bash console:
|
||||
|
||||
Now let’s try loading the app on PythonAnywhere. First, we need to reload the app on the Web tab in the dashboard:
|
||||
|
||||
<img width="748" height="178" src="../_resources/9uUb5DUvQWWjMSDlK5d5_Screen_Shot_02571ec24a864352a.png"/>
|
||||
|
||||
Now go to your app URL:
|
||||
|
||||
<img width="748" height="464" src="../_resources/ja3sobr0RTO7ivP5YI5A_python_anyw_faac10d9fdd04e49a.png"/>
|
||||
|
||||
Great, it works! Try registering a new user and logging in. This should work just as it did locally.
|
||||
|
||||
<img width="748" height="398" src="../_resources/iHgndWTw6X1VROIUtk9g_register_7eb17d6e5d454355907e.png"/>
|
||||
|
||||
<img width="748" height="284" src="../_resources/OPlsZYIQQSWHQ7dAz9hN_login_b435d51e4b1a48e0b3b670c.png"/>
|
||||
|
||||
<img width="748" height="466" src="../_resources/iqWpZTumRBagdvhY3ms7_dashboard_bb5cfdf3dd2d4b368f4.png"/>
|
||||
|
||||
### [Admin User](#admin-user)
|
||||
|
||||
We will now create an admin user the same way we did locally. Open the Bash console, and run the following commands:
|
||||
|
||||
```
|
||||
Output
|
||||
|
||||
>>> from app.models import Employee
|
||||
>>> from app import db
|
||||
>>> admin = Employee(email="admin@admin.com",username="admin",password="admin2016",is_admin=True)
|
||||
>>> db.session.add(admin)
|
||||
>>> db.session.commit()
|
||||
```
|
||||
|
||||
Now you can log in as an admin user and add departments and roles, and assign them to employees.
|
||||
|
||||
<img width="748" height="259" src="../_resources/c07SFY53Tcum6HpgHnym_admin_login_9b504a76776641b6b.png"/>
|
||||
|
||||
<img width="748" height="466" src="../_resources/zUNwr0kLQtCuYkWBopog_admin_dashb_4425380391f543bab.png"/>
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## [Conclusion](#conclusion)
|
||||
|
||||
Congratulations on successfully deploying your first Flask CRUD web app! From setting up a MySQL database to creating models, blueprints (with forms and views), templates, custom error pages, tests, and finally deploying the app on PythonAnywhere, you now have a strong foundation in web development with Flask. I hope this has been as fun and educational for you as it has for me! I’m looking forward to hearing about your experiences in the comments below.
|
||||
@@ -1,356 +0,0 @@
|
||||
---
|
||||
title: Build a CRUD Web App With Python and Flask - Part One
|
||||
source: https://www.digitalocean.com/community/tutorials/build-a-crud-web-app-with-python-and-flask-part-one
|
||||
---
|
||||
|
||||
This tutorial is out of date and no longer maintained.
|
||||
|
||||
### [Introduction](#introduction)
|
||||
|
||||
In this three-part tutorial, we’ll build a CRUD (Create, Read, Update, Delete) employee management web app using [Flask](http://flask.pocoo.org/), a microframework for Python. I’ve named the app Project Dream Team, and it will have the following features:
|
||||
|
||||
1. Users will be able to register and login as employees
|
||||
2. The administrator will be able to create, update, and delete departments and roles
|
||||
3. The administrator will be able to assign employees to a department and assign them roles
|
||||
4. The administrator will be able to view all employees and their details
|
||||
|
||||
Part One will cover:
|
||||
|
||||
1. Database setup
|
||||
2. Models
|
||||
3. Migration
|
||||
4. Homepage
|
||||
5. Authentication
|
||||
|
||||
Ready? Here we go!
|
||||
|
||||
## [Prerequisites](#prerequisites)
|
||||
|
||||
This tutorial builds on my introductory tutorial, [Getting Started With Flask](https://scotch.io/tutorials/getting-started-with-flask-a-python-microframework), picking up where it left off. It assumes you have, to begin with, the following dependencies installed:
|
||||
|
||||
1. [Python 2.7](https://www.python.org/download/releases/2.7/)
|
||||
2. [Flask](http://flask.pocoo.org/)
|
||||
3. [virtualenv](https://virtualenv.pypa.io/en/stable/) (and, optionally, [virtualenvwrapper](https://virtualenvwrapper.readthedocs.io/en/latest/))
|
||||
|
||||
You should have a virtual environment set up and activated. You should also have the following file and directory structure:
|
||||
|
||||
```
|
||||
├── dream-team
|
||||
├── app
|
||||
│ ├── __init__.py
|
||||
│ ├── templates
|
||||
│ ├── models.py
|
||||
│ └── views.py
|
||||
├── config.py
|
||||
├── requirements.txt
|
||||
└── run.py
|
||||
```
|
||||
|
||||
This project structure groups the similar components of the application together. The `dream-team` directory houses all the project files. The `app` directory is the application package and houses different but interlinked modules of the application. All templates are stored in the `templates` directory, all models are in the `models.py` file, and all routes are in the `views.py` file. The `run.py` file is the application’s entry point, the `config.py` file contains the application configurations, and the `requirements.txt` file contains the software dependencies for the application.
|
||||
|
||||
If you don’t have these set up, please visit the introductory tutorial and catch up!
|
||||
|
||||
## [Database Setup](#database-setup)
|
||||
|
||||
Flask has support for several relational database management systems, including [SQLite](https://sqlite.org/), [MySQL](https://www.mysql.com/), and [PostgreSQL](https://www.postgresql.org/). For this tutorial, we will be using MySQL. It’s popular and therefore has a lot of support, in addition to being scalable, secure, and rich in features.
|
||||
|
||||
We will install the following (remember to activate your virtual environment):
|
||||
|
||||
1. [Flask-SQLAlchemy](http://flask-sqlalchemy.pocoo.org/2.1/): This will allow us to use [SQLAlchemy](http://www.sqlalchemy.org/), a useful tool for SQL use with Python. SQLAlchemy is an Object Relational Mapper (ORM), which means that it connects the objects of an application to tables in a relational database management system. These objects can be stored in the database and accessed without the need to write raw SQL. This is convenient because it simplifies queries that may have been complex if written in raw SQL. Additionally, it reduces the risk of [SQL injection attacks](http://www.w3schools.com/sql/sql_injection.asp) since we are not dealing with the input of raw SQL.
|
||||
|
||||
2. [MySQL-Python](https://pypi.python.org/pypi/MySQL-python/1.2.5): This is a Python interface to MySQL. It will help us connect the MySQL database to the app.
|
||||
|
||||
|
||||
We’ll then create the MySQL database. Ensure you have MySQL installed and running, and then log in as the root user:
|
||||
|
||||
```
|
||||
mysql> CREATE USER 'dt_admin'@'localhost' IDENTIFIED BY 'dt2016';
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
mysql> CREATE DATABASE dreamteam_db;
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
mysql> GRANT ALL PRIVILEGES ON dreamteam_db . * TO 'dt_admin'@'localhost';
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
```
|
||||
|
||||
We have now created a new user `dt_admin` with the password `dt2016`, created a new database `dreamteam_db`, and granted the new user all database privileges.
|
||||
|
||||
Next, let’s edit the `config.py`. Remove any existing code and add the following:
|
||||
|
||||
config.py
|
||||
|
||||
It is good practice to specify configurations for different environments. In the file above, we have specified configurations for development, which we will use while building the app and running it locally, as well as production, which we will use when the app is deployed.
|
||||
|
||||
Some useful configuration variables are:
|
||||
|
||||
1. `TESTING`: setting this to `True` activates the testing mode of Flask extensions. This allows us to use testing properties that could for instance have an increased runtime cost, such as unit test helpers. It should be set to `True` in the configurations for testing. It defaults to `False`.
|
||||
2. `DEBUG`: setting this to `True` activates the debug mode on the app. This allows us to use the Flask debugger in case of an unhandled exception, and also automatically reloads the application when it is updated. It should however always be set to `False` in production. It defaults to `False`.
|
||||
3. `SQLALCHEMY_ECHO`: setting this to `True` helps us with debugging by allowing SQLAlchemy to log errors.
|
||||
|
||||
You can find more Flask configuration variables [here](http://flask.pocoo.org/docs/0.11/config/) and SQLAlchemy configuration variables [here](http://flask-sqlalchemy.pocoo.org/2.1/config/).
|
||||
|
||||
Next, create an `instance` directory in the `dream-team` directory, and then create a `config.py` file inside it. We will put configuration variables here that will not be pushed to version control due to their sensitive nature. In this case, we put the secret key as well as the database URI which contains the database user password.
|
||||
|
||||
instance/config.py
|
||||
|
||||
Now, let’s edit the `app/__init__.py` file. Remove any existing code and add the following:
|
||||
|
||||
app/\_\_init\_\_.py
|
||||
|
||||
We’ve created a function, `create_app` that, given a configuration name, loads the correct configuration from the `config.py` file, as well as the configurations from the `instance/config.py` file. We have also created a `db` object which we will use to interact with the database.
|
||||
|
||||
Next, let’s edit the `run.py` file:
|
||||
|
||||
run.py
|
||||
|
||||
We create the app by running the `create_app` function and passing in the configuration name. We get this from the OS environment variable `FLASK_CONFIG`. Because we are in development, we should set the environment variable to `development`.
|
||||
|
||||
Let’s run the app to ensure everything is working as expected. First, delete the `app/views.py` file as well as the `app/templates` directory as we will not be needing them going forward. Next, add a temporary route to the `app/__init__.py` file as follows:
|
||||
|
||||
app/\_\_init\_\_.py
|
||||
|
||||
Make sure you set the `FLASK_CONFIG` and `FLASK_APP` environment variables before running the app:
|
||||
|
||||
```
|
||||
* Serving Flask app "run"
|
||||
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
<img width="748" height="109" src="../_resources/ZARmTHcvR5WA9FENq2Nn_Screen_Shot_380267898b014e1bb.png"/>
|
||||
|
||||
We can see the “Hello, World” string we set in the route. The app is working well so far.
|
||||
|
||||
## [Models](#models)
|
||||
|
||||
Now to work on the models. Remember that a model is a representation of a database table in code. We’ll need three models: `Employee`, `Department`, and `Role`.
|
||||
|
||||
But first, let’s install [Flask-Login](https://flask-login.readthedocs.io/en/latest/), which will help us with user management and handle logging in, logging out, and user sessions. The `Employee` model will inherit from Flask-Login’s `UserMixin` class which will make it easier for us to make use of its properties and methods.
|
||||
|
||||
To use Flask-Login, we need to create a LoginManager object and initialize it in the `app/__init__.py` file. First, remove the route we added earlier, and then add the following:
|
||||
|
||||
app/\_\_init\_\_.py
|
||||
|
||||
In addition to initializing the LoginManager object, we’ve also added a `login_view` and `login_message` to it. This way, if a user tries to access a page that they are not authorized to, it will redirect to the specified view and display the specified message. We haven’t created the `auth.login` view yet, but we will when we get to authentication.
|
||||
|
||||
Now add the following code to the `app/models.py` file:
|
||||
|
||||
app/models.py
|
||||
|
||||
In the `Employee` model, we make use of some of Werkzeug’s handy security helper methods, `generate_password_hash`, which allows us to hash passwords, and `check_password_hash`, which allows us to ensure the hashed password matches the password. To enhance security, we have a `password` method that ensures that the password can never be accessed; instead, an error will be raised. We also have two foreign key fields, `department_id` and `role_id`, which refer to the ID of the department and the role assigned to the employee.
|
||||
|
||||
Note that we have an `is_admin` field which is set to `False` by default. We will override this when creating the admin user. Just after the `Employee` model, we have a `user_loader` callback, which Flask-Login uses to reload the user object from the user ID stored in the session.
|
||||
|
||||
The `Department` and `Role` models are quite similar. Both have `name` and `description` fields. Additionally, both have a one-to-many relationship with the `Employee` model (one department or role can have many employees). We define this in both models using the `employees` field. `backref` allows us to create a new property on the `Employee` model such that we can use `employee.department` or `employee.role` to get the department or role assigned to that employee. `lazy` defines how the data will be loaded from the database; in this case, it will be loaded dynamically, which is ideal for managing large collections.
|
||||
|
||||
## [Migration](#migration)
|
||||
|
||||
Migrations allow us to manage changes we make to the models and propagate these changes in the database. For example, if later on, we make a change to a field in one of the models, all we will need to do is create and apply a migration, and the database will reflect the change.
|
||||
|
||||
We’ll begin by installing [Flask-Migrate](https://flask-migrate.readthedocs.io/en/latest/), which will handle the database migrations using Alembic, a lightweight database migration tool. Alembic emits `ALTER` statements to a database thus implementing changes made to the models. It also auto-generates minimalistic migration scripts, which may be complex to write.
|
||||
|
||||
We’ll need to edit the `app/__init__.py` file:
|
||||
|
||||
app/\_\_init\_\_.py
|
||||
|
||||
We have created a `migrate` object which will allow us to run migrations using Flask-Migrate. We have also imported the models from the `app` package. Next, we’ll run the following command to create a migration repository:
|
||||
|
||||
This creates a `migrations` directory in the `dream-team` directory:
|
||||
|
||||
```
|
||||
└── migrations
|
||||
├── README
|
||||
├── alembic.ini
|
||||
├── env.py
|
||||
├── script.py.mako
|
||||
└── versions
|
||||
```
|
||||
|
||||
Next, we will create the first migration:
|
||||
|
||||
Finally, we’ll apply the migration:
|
||||
|
||||
We’ve successfully created tables based on the models we wrote! Let’s check the MySQL database to confirm this:
|
||||
|
||||
```
|
||||
mysql> use dreamteam_db;
|
||||
|
||||
mysql> show tables;
|
||||
+------------------------+
|
||||
| Tables_in_dreamteam_db |
|
||||
+------------------------+
|
||||
| alembic_version |
|
||||
| departments |
|
||||
| employees |
|
||||
| roles |
|
||||
+------------------------+
|
||||
4 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
## [Blueprints](#blueprints)
|
||||
|
||||
Blueprints are great for organizing a flask app into components, each with its own views and forms. I find that blueprints make for a cleaner and more organized project structure because each blueprint is a distinct component that addresses a specific functionality of the app. Each blueprint can even have its own custom URL prefix or subdomain. Blueprints are particularly convenient for large applications.
|
||||
|
||||
We’re going to have three blueprints in this app:
|
||||
|
||||
1. Home - this will have the homepage and dashboard views
|
||||
2. Admin - this will have all administrator (department and role) forms and views
|
||||
3. Auth - this will have all authentication (registration and login) forms and views
|
||||
|
||||
Create the relevant files and directories so that your directory structure resembles this:
|
||||
|
||||
```
|
||||
└── dream-team
|
||||
├── app
|
||||
│ ├── __init__.py
|
||||
│ ├── admin
|
||||
│ │ ├── __init__.py
|
||||
│ │ ├── forms.py
|
||||
│ │ └── views.py
|
||||
│ ├── auth
|
||||
│ │ ├── __init__.py
|
||||
│ │ ├── forms.py
|
||||
│ │ └── views.py
|
||||
│ ├── home
|
||||
│ │ ├── __init__.py
|
||||
│ │ └── views.py
|
||||
│ ├── models.py
|
||||
│ ├── static
|
||||
│ └── templates
|
||||
├── config.py
|
||||
├── instance
|
||||
│ └── config.py
|
||||
├── migrations
|
||||
│ ├── README
|
||||
│ ├── alembic.ini
|
||||
│ ├── env.py
|
||||
│ ├── script.py.mako
|
||||
│ └── versions
|
||||
│ └── a1a1d8b30202_.py
|
||||
├── requirements.txt
|
||||
└── run.py
|
||||
```
|
||||
|
||||
I chose not to have `static` and `templates` directories for each blueprint because all the application templates will inherit from the same base template and use the same CSS file. Instead, the `templates` directory will have sub-directories for each blueprint so that blueprint templates can be grouped together.
|
||||
|
||||
In each blueprint’s `__init__.py` file, we need to create a Blueprint object and initialize it with a name. We also need to import the views.
|
||||
|
||||
app/admin/\_\_init\_\_.py
|
||||
|
||||
app/auth/\_\_init\_\_.py
|
||||
|
||||
app/home/\_\_init\_\_.py
|
||||
|
||||
Then, we can register the blueprints on the app in the `app/__init__.py` file, like so:
|
||||
|
||||
app/\_\_init\_\_.py
|
||||
|
||||
We have imported each blueprint object and registered it. For the `admin` blueprint, we have added a URL prefix, `/admin`. This means that all the views for this blueprint will be accessed in the browser with the URL prefix `admin`.
|
||||
|
||||
## [Home Blueprint](#home-blueprint)
|
||||
|
||||
Time to work on fleshing out the blueprints! We’ll start with the `home` blueprint, which will have the homepage as well as the dashboard.
|
||||
|
||||
app/home/views.py
|
||||
|
||||
Each view function has a decorator, `home.route`, which has a URL route as a parameter (remember that `home` is the name of the blueprint as specified in the `app/home/__init__.py` file). Each view handles requests to the specified URL.
|
||||
|
||||
The `homepage` view renders the home template, while the `dashboard` view renders the dashboard template. Note that the `dashboard` view has a `login_required` decorator, meaning that users must be logged in to access it.
|
||||
|
||||
Now to work on the base template, which all other templates will inherit from. Create a `base.html` file in the `app/templates` directory and add the following code:
|
||||
|
||||
app/templates/base.html
|
||||
|
||||
Note that we use `#` for the Register and Login links. We will update this when we are working on the `auth` blueprint.
|
||||
|
||||
Next, create a `home` directory inside the `app/templates` directory. The homepage template, `index.html`, will go inside it:
|
||||
|
||||
app/templates/home/index.html
|
||||
|
||||
Inside the `static` directory, add `css` and `img` directories. Add the following CSS file, `style.css`, to your `static/css` directory (note that you will need a background image, `intro-bg.jpg`, as well as a favicon in your `static/img` directory):
|
||||
|
||||
app/static/css/style.css
|
||||
|
||||
Run the app; you should be able to see the homepage now.
|
||||
|
||||
<img width="748" height="467" src="../_resources/1FIiIIkGR9eQ3PAJrNeu_Screen_Shot_76895f229b65404ea.png"/>
|
||||
|
||||
## [Auth Blueprint](#auth-blueprint)
|
||||
|
||||
For the `auth` blueprint, we’ll begin by creating the registration and login forms. We’ll use [Flask-WTF](https://flask-wtf.readthedocs.io/en/stable/), which will allow us to create forms that are secure (thanks to CSRF protection and reCAPTCHA support).
|
||||
|
||||
Now to write the code for the forms:
|
||||
|
||||
app/auth/forms.py
|
||||
|
||||
Flask-WTF has a number of validators that make writing forms much easier. All the fields in the models have the `DataRequired` validator, which means that users will be required to fill all of them in order to register or log in.
|
||||
|
||||
For the registration form, we require users to fill in their email address, username, first name, and last name. Users will also be required to enter their password twice. We use the `Email` validator to ensure valid email formats are used (e.g., `example@example.com`). We use the `EqualTo` validator to confirm that the `password` and `confirm_password` fields in the `RegistrationForm` match. We also create methods (`validate_email` and `validate_username`) to ensure that the email and username entered have not been used before.
|
||||
|
||||
The `submit` field in both forms will be represented as a button that users will be able to click to register and login respectively.
|
||||
|
||||
With the forms in place, we can write the views:
|
||||
|
||||
app/auth/views.py
|
||||
|
||||
Just like in the `home` blueprint, each view here handles requests to the specified URL. The `register` view creates an instance of the `Employee` model class using the registration form data to populate the fields and then adds it to the database. This essentially registers a new employee.
|
||||
|
||||
The `login` view queries the database to check whether an employee exists with an email address that matches the email provided in the login form data. It then uses the `verify_password` method to check that the password in the database for the employee matches the password provided in the login form data. If both of these are true, it proceeds to log the user in using the `login_user` method provided by Flask-Login.
|
||||
|
||||
The `logout` view has the `login_required` decorator, which means that a user must be logged in to access it. It calls the `logout_user` method provided by Flask-Login to log the user out.
|
||||
|
||||
Note the use of `flash` method, which allows us to use Flask’s [message flashing](http://flask.pocoo.org/docs/0.11/patterns/flashing/) feature. This allows us to communicate feedback to the user, such as informing them of successful registration or unsuccessful login.
|
||||
|
||||
Finally, let’s work on the templates. First, we’ll install [Flask-Bootstrap](https://pythonhosted.org/Flask-Bootstrap/index.html) so we can use its `wtf` and `utils` libraries. The `wtf` library will allow us to quickly generate forms in the templates based on the forms in the `forms.py` file. The `utils` library will allow us to display the flash messages we set earlier to give feedback to the user.
|
||||
|
||||
We need to edit the `app/__init__.py` file to use Flask-Bootstrap:
|
||||
|
||||
app/\_\_init\_\_.py
|
||||
|
||||
We’ve made quite a number of edits to the `app/__init__.py` file. This is the final version of the file and how it should look at this point (note that I have re-arranged the imports and variables in alphabetical order):
|
||||
|
||||
app/\_\_init\_\_.py
|
||||
|
||||
We need two templates for the `auth` blueprint: `register.html` and `login.html`, which we’ll create in an `auth` directory inside the `templates` directory.
|
||||
|
||||
app/templates/auth/register.html
|
||||
|
||||
app/templates/auth/login.html
|
||||
|
||||
The forms are loaded from the `app/auth/views.py` file, where we specified which template files to display for each view. Remember the Register and Login links in the base template? Let’s update them now so we can access the pages from the menus:
|
||||
|
||||
Run the app again and click on the Register and Login menu links. You should see the templates loaded with the appropriate form.
|
||||
|
||||
Try to fill out the registration form; you should be able to register a new employee. After registration, you should be redirected to the login page, where you will see the flash message we configured in the `app/auth/views.py` file, inviting you to login.
|
||||
|
||||
<img width="748" height="407" src="../_resources/YNe42GM3REC5V89JEUQ4_Screen_Shot_834151213325415ab.png"/>
|
||||
|
||||
<img width="748" height="286" src="../_resources/MYG8y2mPRju5r4seFyMw_Screen_Shot_66e0f5d748f94ef09.png"/>
|
||||
|
||||
Logging in should be successful; however you should get a `Template Not Found` error after logging in, because the `dashboard.html` template has not been created yet. Let’s do that now:
|
||||
|
||||
app/templates/home/dashboard.html
|
||||
|
||||
Refresh the page. You’ll notice that the navigation menu still has the register and login links, even though we are already logged in. We’ll need to modify it to show a logout link when a user is already authenticated. We will also include a `Hi, username!` message in the nav bar:
|
||||
|
||||
app/templates/base.html
|
||||
|
||||
Note how we use `if-else` statements in the templates. Also, take note of the `current_user` proxy provided by Flask-Login, which allows us to check whether the user is authenticated and to get the user’s username.
|
||||
|
||||
<img width="748" height="468" src="../_resources/p5AiTJWHSHd9fleVKrxA_Screen_Shot_fc843f9c62304276b.png"/>
|
||||
|
||||
Logging out will take you back to the login page:
|
||||
|
||||
<img width="748" height="291" src="../_resources/fvZWaNdqRiGaWAr4cotK_Screen_Shot_b1f537d5d4f047069.png"/>
|
||||
|
||||
Attempting to access the dashboard page without logging in will redirect you to the login page and display the message we set in the `app/__init__.py` file:
|
||||
|
||||
<img width="748" height="327" src="../_resources/nbibjCDVR82P6XRsLB01_Screen_Shot_059c846478de4da79.png"/>
|
||||
|
||||
Notice that the URL is configured such that once you log in, you will be redirected to the page you initially attempted to access, which in this case is the dashboard.
|
||||
|
||||
## [Conclusion](#conclusion)
|
||||
|
||||
That’s it for Part One! We’ve covered quite a lot: setting up a MySQL database, creating models, migrating the database, and handling registration, login, and logout. Good job for making it this far!
|
||||
|
||||
Watch this space for Part Two, which will cover the CRUD functionality of the app, allowing admin users to add, list, edit, and delete departments and roles, as well as assign them to employees.
|
||||
@@ -1,247 +0,0 @@
|
||||
---
|
||||
title: Build a CRUD Web App With Python and Flask - Part Two
|
||||
source: https://www.digitalocean.com/community/tutorials/build-a-crud-web-app-with-python-and-flask-part-two
|
||||
---
|
||||
|
||||
This tutorial is out of date and no longer maintained.
|
||||
|
||||
### [Introduction](#introduction)
|
||||
|
||||
This is Part Two of a three-part tutorial to build an employee management web app, named Project Dream Team. In [Part One](https://www.digitalocean.com/community/tutorials/build-a-crud-web-app-with-python-and-flask-part-one) of the tutorial, we set up a MySQL database using MySQL-Python and Flask-SQLAlchemy. We created models, migrated the database, and worked on the `home` and `auth` blueprints and templates. By the end of Part One, we had a working app that had a homepage, registration page, login page, and dashboard. We could register a new user, log in, and log out.
|
||||
|
||||
In Part Two, we will work on:
|
||||
|
||||
1. Creating an admin user and admin dashboard
|
||||
2. Creating, listing, editing, and deleting departments
|
||||
3. Creating, listing, editing, and deleting roles
|
||||
4. Assigning departments and roles to employees
|
||||
|
||||
## [Admin User](#admin-user)
|
||||
|
||||
We’ll start by creating an admin user through the command line. Flask provides a handy command, `flask shell`, that allows us to use an interactive Python shell for use with Flask apps.
|
||||
|
||||
```
|
||||
Output
|
||||
|
||||
>>> from app.models import Employee
|
||||
>>> from app import db
|
||||
>>> admin = Employee(email="admin@admin.com",username="admin",password="admin2016",is_admin=True)
|
||||
>>> db.session.add(admin)
|
||||
>>> db.session.commit()
|
||||
```
|
||||
|
||||
We’ve just created a user with a username, `admin`, and a password, `admin2016`. Recall that we set the `is_admin` field to default to `False` in the `Employee` model. To create the admin user above, we override the default value of `is_admin` and set it to `True`.
|
||||
|
||||
## [Admin Dashboard](#admin-dashboard)
|
||||
|
||||
Now that we have an admin user, we need to add a view for an admin dashboard. We also need to ensure that once the admin user logs in, they are redirected to the admin dashboard and not the one for non-admin users. We will do this in the `home` blueprint.
|
||||
|
||||
app/home/views.py
|
||||
|
||||
app/auth/views.py
|
||||
|
||||
Next, we’ll create the admin dashboard template. Create an `admin_dashboard.html` file in the `templates/home` directory, and then add the following code to it:
|
||||
|
||||
app/templates/home/admin_dashboard.html
|
||||
|
||||
Now we need to edit the base template to show a different menu for the admin user.
|
||||
|
||||
app/templates/base.html
|
||||
|
||||
In the menu above, we make use of the `current_user` proxy from Flask-Login to check whether the current user is an admin. If they are, we display the admin menu which will allow them to navigate to the Departments, Roles, and Employees pages. Notice that we use `#` for the links in the admin menu. We will update this after we have created the respective views.
|
||||
|
||||
Now run the app and log in as the admin user that we just created. You should see the admin dashboard:
|
||||
|
||||
<img width="748" height="468" src="../_resources/ax60NlGVQhSYDtpTmGpi_Screen_Shot_637711511e8244e88.png"/>
|
||||
|
||||
Let’s test the error we set in the `home/views.py` file to prevent non-admin users from accessing the admin dashboard. Log out and then log in as a regular user. In your browser’s address bar, manually enter the following URL: `http://127.0.0.1:5000/admin/dashboard`. You should get a `403 Forbidden` error. It looks pretty boring now, but don’t worry, we’ll create custom error pages in Part Three!
|
||||
|
||||
<img width="748" height="132" src="../_resources/e73MdCtRtyGVdvR2ae9L_Screen_Shot_a7a74f4aa3404c119.png"/>
|
||||
|
||||
## [Departments](#departments)
|
||||
|
||||
Now we’ll start working on the `admin` blueprint, which has the bulk of the functionality in the application. We’ll begin by building out CRUD functionality for the departments.
|
||||
|
||||
### [Forms](#forms)
|
||||
|
||||
We’ll start with the `admin/forms.py` file, where we’ll create a form to add and edit departments.
|
||||
|
||||
app/admin/forms.py
|
||||
|
||||
The form is pretty simple and has only two fields, `name` and `department`, both of which are required. We enforce this using the `DataRequired()` validator from WTForms. Note that we will use the same form for adding and editing departments.
|
||||
|
||||
### [Views](#views)
|
||||
|
||||
Now, let’s work on the views:
|
||||
|
||||
app/admin/views.py
|
||||
|
||||
We begin by creating a function, `check_admin`, which throws a `403 Forbidden` error if a non-admin user attempts to access these views. We will call this function in every admin view.
|
||||
|
||||
The `list_departments` view queries the database for all departments and assigns them to the variable `departments`, which we will use to list them in the template.
|
||||
|
||||
The `add_department` view creates a new department object using the form data and adds it to the database. If the department name already exists, an error message is displayed. This view redirects to the `list_departments`. This means that once the admin user creates a new department, they will be redirected to the Departments page.
|
||||
|
||||
The `edit_department` view takes one parameter: `id`. This is the department ID and will be passed to the view in the template. The view queries the database for a department with the ID specified. If the department doesn’t exist, a `404 Not Found` error is thrown. If it does, it is updated with the form data.
|
||||
|
||||
The `delete_department` view is similar to the `edit_department` one, in that it takes a department ID as a parameter and throws an error if the specified department doesn’t exist. If it does, it is deleted from the database.
|
||||
|
||||
Note that we render the same template for adding and editing individual departments: `department.html`. This is why we have the `add_department` variable in the `add_department` view (where it is set to `True`), as well as in the `edit_department` view (where it is set to `False`). We’ll use this variable in the `department.html` template to determine what wording to use for the title and heading.
|
||||
|
||||
### [Templates](#templates)
|
||||
|
||||
Create a `templates/admin` directory, and in it, add a `departments` directory. Inside it, add the `departments.html` and `department.html` files:
|
||||
|
||||
app/templates/admin/departments/departments.html
|
||||
|
||||
We’ve created a table in the template above, where we will display all the departments with their name, description, and the number of employees. Take note of the `count()` function, which we use in this case to get the number of employees. Each department listed will have an edit and delete link. Notice how we pass the `department.id` value to the `edit_department` and `delete_department` views in the respective links.
|
||||
|
||||
If there are no departments, the page will display “No departments have been added”. There is also a button that can be clicked to add a new department.
|
||||
|
||||
Now let’s work on the template for adding and editing departments:
|
||||
|
||||
app/templates/admin/departments/department.html
|
||||
|
||||
Notice that we use the `add_department` variable which we initialized in the `admin/views.py` file, to determine whether the page title will be “Add Department” or “Edit Department”.
|
||||
|
||||
Add the following lines to your `style.css` file:
|
||||
|
||||
app/static/css/style.css
|
||||
|
||||
The `.middle`, `.inner`, and `.outer` classes are to center the content in the middle of the page.
|
||||
|
||||
Lastly, let’s put the correct link to the Departments page in the admin menu:
|
||||
|
||||
Re-start the flask server, and then log back in as the admin user and click on the Departments link. Because we have not added any departments, loading the page will display:
|
||||
|
||||
<img width="748" height="461" src="../_resources/4Z291fMAR4y5ofY8TUdU_Screen_Shot_12dbdb8ce16740ff8.png"/>
|
||||
|
||||
Let’s try adding a department:
|
||||
|
||||
<img width="748" height="464" src="../_resources/y1pX3m44QYFBZ9RZB0eI_Screen_Shot_e911e54c7adb45f6b.png"/>
|
||||
|
||||
<img width="748" height="460" src="../_resources/pdcD9ozbS37vrDP6XkdA_Screen_Shot_2c6c407ea975424b9.png"/>
|
||||
|
||||
It worked! We get the success message we configured in the `add_department` view, and can now see the department displayed.
|
||||
|
||||
Now let’s edit it:
|
||||
|
||||
<img width="748" height="468" src="../_resources/QJxAOzURcCTxUIYrpDCw_Screen_Shot_ac174dc2d01a45188.png"/>
|
||||
|
||||
Notice that the current department name and description are already pre-loaded in the form. Also, take note of the URL, which has the ID of the department we are editing.
|
||||
|
||||
<img width="748" height="462" src="../_resources/IGZlEJBAQuCrNi94kXJA_Screen_Shot_9483ab70156e425fa.png"/>
|
||||
|
||||
<img width="748" height="465" src="../_resources/ZHZuCU3vSY6hqtCiX6o1_Screen_Shot_5546baec374d438b9.png"/>
|
||||
|
||||
Editing the department is successful as well. Clicking the Delete link deletes the department and redirects to the Departments page, where a confirmation message is displayed:
|
||||
|
||||
<img width="748" height="450" src="../_resources/Hu9M9wXQHWfogHm5kj5i_Screen_Shot_48b17b4a69e94adf8.png"/>
|
||||
|
||||
## [Roles](#roles)
|
||||
|
||||
Now to work on the roles. This will be very similar to the departments code because the functionality for roles and departments is exactly the same.
|
||||
|
||||
### [Forms](#forms)
|
||||
|
||||
We’ll start by creating the form to add and edit roles. Add the following code to the `admin/forms.py` file:
|
||||
|
||||
app/admin/forms.py
|
||||
|
||||
### [Views](#views)
|
||||
|
||||
Next, we’ll write the views to add, list, edit, and delete roles. Add the following code to the admin/views.py file:
|
||||
|
||||
app/admin/views.py
|
||||
|
||||
These list, add, edit, and delete views are similar to the ones for departments that we created earlier.
|
||||
|
||||
### [Templates](#templates)
|
||||
|
||||
Create a `roles` directory in the `templates/admin` directory. In it, create the `roles.html` and `role.html` files:
|
||||
|
||||
app/templates/admin/roles/roles.html
|
||||
|
||||
Just like we did for the departments, we have created a table where we will display all the roles with their name, description, and the number of employees. Each role listed will also have an edit and delete link. If there are no roles, a message of the same will be displayed. There is also a button that can be clicked to add a new role.
|
||||
|
||||
app/templates/admin/roles/role.html
|
||||
|
||||
We use the `add_role` variable above the same way we used the `add_department` variable for the `department.html` template.
|
||||
|
||||
Once again, let’s update the admin menu with the correct link:
|
||||
|
||||
app/templates/base.html
|
||||
|
||||
Re-start the server. You should now be able to access the Roles page, and add, edit and delete roles.
|
||||
|
||||
<img width="748" height="461" src="../_resources/AiRt5M8FSfOo2SngPcKu_Screen_Shot_32c8a568cff548f19.png"/>
|
||||
|
||||
<img width="748" height="464" src="../_resources/djvJxYg9R8GEvmPD9E1p_Screen_Shot_8bf7d12f8b0c46a59.png"/>
|
||||
|
||||
<img width="748" height="464" src="../_resources/ifs2IrzMSP2OtIpQexKz_Screen_Shot_c64dc5fb4a8b49a48.png"/>
|
||||
|
||||
<img width="748" height="464" src="../_resources/sbFVZzNhRPuRV91wOekZ_Screen_Shot_65bef1baf293476b9.png"/>
|
||||
|
||||
<img width="748" height="460" src="../_resources/bqJaVpdQ4eyEL8acpUa8_Screen_Shot_c57acee3acf748698.png"/>
|
||||
|
||||
## [Employees](#employees)
|
||||
|
||||
Now to work on listing employees, as well as assigning them departments and roles.
|
||||
|
||||
### [Forms](#forms)
|
||||
|
||||
We’ll need a form to assign each employee a department and role. Add the following to the `admin/forms.py` file:
|
||||
|
||||
app/admin/forms.py
|
||||
|
||||
We have imported a new field type, `QuerySelectField`, which we use for both the department and role fields. This will query the database for all departments and roles. The admin user will select one department and one role using the form on the front-end.
|
||||
|
||||
## [Views](#views)
|
||||
|
||||
Add the following code to the `admin/views.py` file:
|
||||
|
||||
app/admin/views.py
|
||||
|
||||
The `list_employees` view queries the database for all employees and assigns them to the variable `employees`, which we will use to list them in the template.
|
||||
|
||||
The `assign_employee` view takes an employee ID. First, it checks whether the employee is an admin user; if it is, a `403 Forbidden` error is thrown. If not, it updates the `employee.department` and `employee.role` with the selected data from the form, essentially assigning the employee a new department and role.
|
||||
|
||||
## [Templates](#templates)
|
||||
|
||||
Create a `employees` directory in the `templates/admin` directory. In it, create the `employees.html` and `employee.html` files:
|
||||
|
||||
app/templates/admin/employees/employees.html
|
||||
|
||||
The `employees.html` template shows a table of all employees. The table shows their full name, department, and role, or displays a `-` in case no department and role has been assigned. Each employee has an assigned link, which the admin user can click to assign them a department and role.
|
||||
|
||||
Because the admin user is an employee as well, they will be displayed in the table. However, we have formatted the table such that admin users stand out with a green background and white text.
|
||||
|
||||
app/templates/admin/employees/employee.html
|
||||
|
||||
We need to update the admin menu once more:
|
||||
|
||||
app/templates/base.html
|
||||
|
||||
Navigate to the Employees page now. If there are no users other than the admin, this is what you should see:
|
||||
|
||||
<img width="748" height="466" src="../_resources/YOZS9IwfSaCy5UycgIlp_Screen_Shot_edc46ea2afb247709.png"/>
|
||||
|
||||
When there is an employee registered, this is displayed:
|
||||
|
||||
<img width="748" height="464" src="../_resources/TKbhQEo4RRKiNWKvKUTX_Screen_Shot_cd5eeb29228c4a40a.png"/>
|
||||
|
||||
Feel free to add a variety of departments and roles so that you can start assigning them to employees.
|
||||
|
||||
<img width="748" height="469" src="../_resources/rRUY6Q09SoWYO7ynLL5C_Screen_Shot_f3b2be7d30954eb1b.png"/>
|
||||
|
||||
<img width="748" height="376" src="../_resources/IFylw8hMTgGNXcupIaTo_Screen_Shot_ceacdb1329af40638.png"/>
|
||||
|
||||
You can re-assign departments and roles as well.
|
||||
|
||||
<img width="748" height="337" src="../_resources/w8a431SeRFSvTS6JqNLw_Screen_Shot_829ee78040a04035b.png"/>
|
||||
|
||||
## [Conclusion](#conclusion)
|
||||
|
||||
We now have a completely functional CRUD web app! In Part Two of the tutorial, we’ve been able to create an admin user and an admin dashboard, as well as customize the menu for different types of users. We’ve also built out the core functionality of the app, and can now add, list, edit, and delete departments and roles, as well as assign them to employees. We have also taken security into consideration by protecting certain views from unauthorized access.
|
||||
|
||||
In Part Three, we will create custom error pages, write tests, and deploy the app to [PythonAnywhere](https://www.pythonanywhere.com/).
|
||||
@@ -1,896 +0,0 @@
|
||||
---
|
||||
title: Getting Started | Building web applications with Spring Boot and Kotlin
|
||||
source: https://spring.io/guides/tutorials/spring-boot-kotlin/
|
||||
tags:
|
||||
- IT/Development/SpringBoot
|
||||
- IT/Development/Kotlin
|
||||
- IT/Development/Maven
|
||||
---
|
||||
|
||||
This tutorial shows you how to build efficiently a sample blog application by combining the power of [Spring Boot](https://spring.io/projects/spring-boot/) and [Kotlin](https://kotlinlang.org/).
|
||||
|
||||
## Creating a New Project
|
||||
|
||||
First we need to create a Spring Boot application, which can be done in a number of ways.
|
||||
|
||||
### Using the Initializr Website
|
||||
|
||||
Visit [https://start.spring.io](https://start.spring.io/) and choose the Kotlin language. Gradle is the most commonly used build tool in Kotlin, and it provides a Kotlin DSL which is used by default when generating a Kotlin project, so this is the recommended choice. But you can also use Maven if you are more comfortable with it. Notice that you can use https://start.spring.io/#!language=kotlin&type=gradle-project-kotlin to have Kotlin and Gradle selected by default.
|
||||
|
||||
1. Select "Gradle - Kotlin" or "Maven" depending on which build tool you want to use
|
||||
2. Enter the following artifact coordinates: `blog`
|
||||
3. Add the following dependencies:
|
||||
- Spring Web
|
||||
- Mustache
|
||||
- Spring Data JPA
|
||||
- H2 Database
|
||||
- Spring Boot DevTools
|
||||
4. Click "Generate Project".
|
||||
|
||||
The .zip file contains a standard project in the root directory, so you might want to create an empty directory before you unpack it.
|
||||
|
||||
### Using command line
|
||||
|
||||
You can use the Initializr HTTP API [from the command line](https://docs.spring.io/initializr/docs/current/reference/html/#command-line) with, for example, curl on a UN*X like system:
|
||||
|
||||
```shell
|
||||
$ mkdir blog && cd blog
|
||||
$ curl https://start.spring.io/starter.zip -d language=kotlin -d type=gradle-project-kotlin -d dependencies=web,mustache,jpa,h2,devtools -d packageName=com.example.blog -d name=Blog -o blog.zip
|
||||
```
|
||||
|
||||
Add `-d type=gradle-project` if you want to use Gradle.
|
||||
|
||||
### Using IntelliJ IDEA
|
||||
|
||||
Spring Initializr is also integrated in IntelliJ IDEA Ultimate edition and allows you to create and import a new project without having to leave the IDE for the command-line or the web UI.
|
||||
|
||||
To access the wizard, go to File | New | Project, and select Spring Initializr.
|
||||
|
||||
Follow the steps of the wizard to use the following parameters:
|
||||
|
||||
- Artifact: "blog"
|
||||
- Type: "Gradle - Kotlin" or "Maven"
|
||||
- Language: Kotlin
|
||||
- Name: "Blog"
|
||||
- Dependencies: "Spring Web Starter", "Mustache", "Spring Data JPA", "H2 Database" and "Spring Boot DevTools"
|
||||
|
||||
## Understanding the Gradle Build
|
||||
|
||||
If you’re using a Maven Build, you can [skip to the dedicated section](#maven-build).
|
||||
|
||||
### Plugins
|
||||
|
||||
In addition to the obvious [Kotlin Gradle plugin](https://kotlinlang.org/docs/gradle.html), the default configuration declares the [kotlin-spring plugin](https://kotlinlang.org/docs/all-open-plugin.html#spring-support) which automatically opens classes and methods (unlike in Java, the default qualifier is `final` in Kotlin) annotated or meta-annotated with Spring annotations. This is useful to be able to create `@Configuration` or `@Transactional` beans without having to add the `open` qualifier required by CGLIB proxies for example.
|
||||
|
||||
In order to be able to use Kotlin non-nullable properties with JPA, [Kotlin JPA plugin](https://kotlinlang.org/docs/reference/compiler-plugins.html#jpa-support) is also enabled. It generates no-arg constructors for any class annotated with `@Entity`, `@MappedSuperclass` or `@Embeddable`.
|
||||
|
||||
`build.gradle.kts`
|
||||
|
||||
```kotlin
|
||||
import org.jetbrains.kotlin.gradle.tasks.KotlinCompile
|
||||
|
||||
plugins {
|
||||
id("org.springframework.boot") version "3.0.1"
|
||||
id("io.spring.dependency-management") version "1.1.0"
|
||||
kotlin("jvm") version "1.8.0"
|
||||
kotlin("plugin.spring") version "1.8.0"
|
||||
kotlin("plugin.jpa") version "1.8.0"
|
||||
}
|
||||
```
|
||||
|
||||
### Compiler options
|
||||
|
||||
One of Kotlin’s key features is [null-safety](https://kotlinlang.org/docs/null-safety.html) \- which cleanly deals with `null` values at compile time rather than bumping into the famous `NullPointerException` at runtime. This makes applications safer through nullability declarations and expressing "value or no value" semantics without paying the cost of wrappers like `Optional`. Note that Kotlin allows using functional constructs with nullable values; check out this [comprehensive guide to Kotlin null-safety](https://www.baeldung.com/kotlin/null-safety).
|
||||
|
||||
Although Java does not allow one to express null-safety in its type-system, Spring Framework provides null-safety of the whole Spring Framework API via tooling-friendly annotations declared in the `org.springframework.lang` package. By default, types from Java APIs used in Kotlin are recognized as [platform types](https://kotlinlang.org/docs/reference/java-interop.html#null-safety-and-platform-types) for which null-checks are relaxed. [Kotlin support for JSR 305 annotations](https://kotlinlang.org/docs/java-interop.html#jsr-305-support) \+ Spring nullability annotations provide null-safety for the whole Spring Framework API to Kotlin developers, with the advantage of dealing with `null` related issues at compile time.
|
||||
|
||||
This feature can be enabled by adding the `-Xjsr305` compiler flag with the `strict` options.
|
||||
|
||||
`build.gradle.kts`
|
||||
```kotlin
|
||||
tasks.withType<KotlinCompile> {
|
||||
kotlinOptions {
|
||||
freeCompilerArgs += "-Xjsr305=strict"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Dependencies
|
||||
|
||||
2 Kotlin specific libraries are required (the standard library is added automatically with Gradle) for such Spring Boot web application and configured by default:
|
||||
|
||||
- `kotlin-reflect` is Kotlin reflection library
|
||||
- `jackson-module-kotlin` adds support for serialization/deserialization of Kotlin classes and data classes (single constructor classes can be used automatically, and those with secondary constructors or static factories are also supported)
|
||||
|
||||
`build.gradle.kts`
|
||||
```kotlin
|
||||
dependencies {
|
||||
implementation("org.springframework.boot:spring-boot-starter-data-jpa")
|
||||
implementation("org.springframework.boot:spring-boot-starter-mustache")
|
||||
implementation("org.springframework.boot:spring-boot-starter-web")
|
||||
implementation("com.fasterxml.jackson.module:jackson-module-kotlin")
|
||||
implementation("org.jetbrains.kotlin:kotlin-reflect")
|
||||
runtimeOnly("com.h2database:h2")
|
||||
runtimeOnly("org.springframework.boot:spring-boot-devtools")
|
||||
testImplementation("org.springframework.boot:spring-boot-starter-test")
|
||||
}
|
||||
```
|
||||
|
||||
Recent versions of H2 require special configuration to properly escape reserved keywords like `user`.
|
||||
|
||||
`src/main/resources/application.properties`
|
||||
```properties
|
||||
spring.jpa.properties.hibernate.globally_quoted_identifiers=true
|
||||
spring.jpa.properties.hibernate.globally_quoted_identifiers_skip_column_definitions = true
|
||||
```
|
||||
|
||||
Spring Boot Gradle plugin automatically uses the Kotlin version declared via the Kotlin Gradle plugin.
|
||||
|
||||
You can now take a [deeper look at the generated application](#understanding-generated-app).
|
||||
|
||||
## Understanding the Maven Build
|
||||
|
||||
### Plugins
|
||||
|
||||
In addition to the obvious [Kotlin Maven plugin](https://kotlinlang.org/docs/reference/using-maven.html), the default configuration declares the [kotlin-spring plugin](https://kotlinlang.org/docs/reference/compiler-plugins.html#spring-support) which automatically opens classes and methods (unlike in Java, the default qualifier is `final` in Kotlin) annotated or meta-annotated with Spring annotations. This is useful to be able to create `@Configuration` or `@Transactional` beans without having to add the `open` qualifier required by CGLIB proxies for example.
|
||||
|
||||
In order to be able to use Kotlin non-nullable properties with JPA, [Kotlin JPA plugin](https://kotlinlang.org/docs/reference/compiler-plugins.html#jpa-support) is also enabled. It generates no-arg constructors for any class annotated with `@Entity`, `@MappedSuperclass` or `@Embeddable`.
|
||||
|
||||
`pom.xml`
|
||||
```xml
|
||||
<build>
|
||||
<sourceDirectory>${project.basedir}/src/main/kotlin</sourceDirectory>
|
||||
<testSourceDirectory>${project.basedir}/src/test/kotlin</testSourceDirectory>
|
||||
<plugins>
|
||||
<plugin>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-maven-plugin</artifactId>
|
||||
</plugin>
|
||||
<plugin>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<artifactId>kotlin-maven-plugin</artifactId>
|
||||
<configuration>
|
||||
<compilerPlugins>
|
||||
<plugin>jpa</plugin>
|
||||
<plugin>spring</plugin>
|
||||
</compilerPlugins>
|
||||
<args>
|
||||
<arg>-Xjsr305=strict</arg>
|
||||
</args>
|
||||
</configuration>
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<artifactId>kotlin-maven-noarg</artifactId>
|
||||
<version>${kotlin.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<artifactId>kotlin-maven-allopen</artifactId>
|
||||
<version>${kotlin.version}</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
</plugin>
|
||||
</plugins>
|
||||
</build>
|
||||
```
|
||||
|
||||
One of Kotlin’s key features is [null-safety](https://kotlinlang.org/docs/null-safety.html) \- which cleanly deals with `null` values at compile time rather than bumping into the famous `NullPointerException` at runtime. This makes applications safer through nullability declarations and expressing "value or no value" semantics without paying the cost of wrappers like `Optional`. Note that Kotlin allows using functional constructs with nullable values; check out this [comprehensive guide to Kotlin null-safety](https://www.baeldung.com/kotlin-null-safety).
|
||||
|
||||
Although Java does not allow one to express null-safety in its type-system, Spring Framework provides null-safety of the whole Spring Framework API via tooling-friendly annotations declared in the `org.springframework.lang` package. By default, types from Java APIs used in Kotlin are recognized as [platform types](https://kotlinlang.org/docs/reference/java-interop.html#null-safety-and-platform-types) for which null-checks are relaxed. [Kotlin support for JSR 305 annotations](https://kotlinlang.org/docs/reference/java-interop.html#jsr-305-support) \+ Spring nullability annotations provide null-safety for the whole Spring Framework API to Kotlin developers, with the advantage of dealing with `null` related issues at compile time.
|
||||
|
||||
This feature can be enabled by adding the `-Xjsr305` compiler flag with the `strict` options.
|
||||
|
||||
Notice also that Kotlin compiler is configured to generate Java 8 bytecode (Java 6 by default).
|
||||
|
||||
### Dependencies
|
||||
|
||||
3 Kotlin specific libraries are required for such Spring Boot web application and configured by default:
|
||||
|
||||
- `kotlin-stdlib` is the Kotlin standard library
|
||||
- `kotlin-reflect` is Kotlin reflection library
|
||||
- `jackson-module-kotlin` adds support for serialization/deserialization of Kotlin classes and data classes (single constructor classes can be used automatically, and those with secondary constructors or static factories are also supported)
|
||||
|
||||
`pom.xml`
|
||||
```xml
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-data-jpa</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-mustache</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-web</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.fasterxml.jackson.module</groupId>
|
||||
<artifactId>jackson-module-kotlin</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<artifactId>kotlin-reflect</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<artifactId>kotlin-stdlib</artifactId>
|
||||
</dependency>
|
||||
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-devtools</artifactId>
|
||||
<scope>runtime</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.h2database</groupId>
|
||||
<artifactId>h2</artifactId>
|
||||
<scope>runtime</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-test</artifactId>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
```
|
||||
|
||||
## Understanding the generated Application
|
||||
|
||||
`src/main/kotlin/com/example/blog/BlogApplication.kt`
|
||||
```kotlin
|
||||
package com.example.blog
|
||||
|
||||
import org.springframework.boot.autoconfigure.SpringBootApplication
|
||||
import org.springframework.boot.runApplication
|
||||
|
||||
@SpringBootApplication
|
||||
class BlogApplication
|
||||
|
||||
fun main(args: Array<String>) {
|
||||
runApplication<BlogApplication>(*args)
|
||||
}
|
||||
```
|
||||
|
||||
Compared to Java, you can notice the lack of semicolons, the lack of brackets on empty class (you can add some if you need to declare beans via `@Bean` annotation) and the use of `runApplication` top level function. `runApplication<BlogApplication>(*args)` is Kotlin idiomatic alternative to `SpringApplication.run(BlogApplication::class.java, *args)` and can be used to customize the application with following syntax.
|
||||
|
||||
`src/main/kotlin/com/example/blog/BlogApplication.kt`
|
||||
```kotlin
|
||||
fun main(args: Array<String>) {
|
||||
runApplication<BlogApplication>(*args) {
|
||||
setBannerMode(Banner.Mode.OFF)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Writing your first Kotlin controller
|
||||
|
||||
Let’s create a simple controller to display a simple web page.
|
||||
|
||||
`src/main/kotlin/com/example/blog/HtmlController.kt`
|
||||
```kotlin
|
||||
package com.example.blog
|
||||
|
||||
import org.springframework.stereotype.Controller
|
||||
import org.springframework.ui.Model
|
||||
import org.springframework.ui.set
|
||||
import org.springframework.web.bind.annotation.GetMapping
|
||||
|
||||
@Controller
|
||||
class HtmlController {
|
||||
|
||||
@GetMapping("/")
|
||||
fun blog(model: Model): String {
|
||||
model["title"] = "Blog"
|
||||
return "blog"
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Notice that we are using here a [Kotlin extension](https://kotlinlang.org/docs/extensions.html) that allows to add Kotlin functions or operators to existing Spring types. Here we import the `org.springframework.ui.set` extension function in order to be able to write `model["title"] = "Blog"` instead of `model.addAttribute("title", "Blog")`. The [Spring Framework KDoc API](https://docs.spring.io/spring-framework/docs/current/kdoc-api/) lists all the Kotlin extensions provided to enrich the Java API.
|
||||
|
||||
We also need to create the associated Mustache templates.
|
||||
|
||||
`src/main/resources/templates/header.mustache`
|
||||
```html
|
||||
<html>
|
||||
<head>
|
||||
<title>{{title}}</title>
|
||||
</head>
|
||||
<body>
|
||||
```
|
||||
|
||||
`src/main/resources/templates/footer.mustache`
|
||||
|
||||
`src/main/resources/templates/blog.mustache`
|
||||
```html
|
||||
{{> header}} <h1>{{title}}</h1> {{> footer}}
|
||||
```
|
||||
|
||||
Start the web application by running the `main` function of `BlogApplication.kt`, and go to `http://localhost:8080/`, you should see a sober web page with a "Blog" headline.
|
||||
|
||||
## Testing with JUnit 5
|
||||
|
||||
JUnit 5 now used by default in Spring Boot provides various features very handy with Kotlin, including [autowiring of constructor/method parameters](https://docs.spring.io/spring/docs/current/spring-framework-reference/testing.html#testcontext-junit-jupiter-di) which allows to use non-nullable `val` properties and the possibility to use `@BeforeAll`/`@AfterAll` on regular non-static methods.
|
||||
|
||||
### Writing JUnit 5 tests in Kotlin
|
||||
|
||||
For the sake of this example, let’s create an integration test in order to demonstrate various features:
|
||||
|
||||
- We use real sentences between backticks instead of camel-case to provide expressive test function names
|
||||
- JUnit 5 allows to inject constructor and method parameters, which is a good fit with Kotlin read-only and non-nullable properties
|
||||
- This code leverages `getForObject` and `getForEntity` Kotlin extensions (you need to import them)
|
||||
|
||||
`src/test/kotlin/com/example/blog/IntegrationTests.kt`
|
||||
```kotlin
|
||||
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
|
||||
class IntegrationTests(@Autowired val restTemplate: TestRestTemplate) {
|
||||
|
||||
@Test
|
||||
fun `Assert blog page title, content and status code`() {
|
||||
val entity = restTemplate.getForEntity<String>("/")
|
||||
assertThat(entity.statusCode).isEqualTo(HttpStatus.OK)
|
||||
assertThat(entity.body).contains("<h1>Blog</h1>")
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
### Test instance lifecycle
|
||||
|
||||
Sometimes you need to execute a method before or after all tests of a given class. Like Junit 4, JUnit 5 requires by default these methods to be static (which translates to [`companion object`](https://kotlinlang.org/docs/object-declarations.html#companion-objects) in Kotlin, which is quite verbose and not straightforward) because test classes are instantiated one time per test.
|
||||
|
||||
But Junit 5 allows you to change this default behavior and instantiate test classes one time per class. This can be done in [various ways](https://junit.org/junit5/docs/current/user-guide/#writing-tests-test-instance-lifecycle), here we will use a property file to change the default behavior for the whole project:
|
||||
|
||||
`src/test/resources/junit-platform.properties`
|
||||
```properties
|
||||
junit.jupiter.testinstance.lifecycle.default = per_class
|
||||
```
|
||||
|
||||
With this configuration, we can now use `@BeforeAll` and `@AfterAll` annotations on regular methods like shown in updated version of `IntegrationTests` above.
|
||||
|
||||
`src/test/kotlin/com/example/blog/IntegrationTests.kt`
|
||||
```kotlin
|
||||
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
|
||||
class IntegrationTests(@Autowired val restTemplate: TestRestTemplate) {
|
||||
|
||||
@BeforeAll
|
||||
fun setup() {
|
||||
println(">> Setup")
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `Assert blog page title, content and status code`() {
|
||||
println(">> Assert blog page title, content and status code")
|
||||
val entity = restTemplate.getForEntity<String>("/")
|
||||
assertThat(entity.statusCode).isEqualTo(HttpStatus.OK)
|
||||
assertThat(entity.body).contains("<h1>Blog</h1>")
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `Assert article page title, content and status code`() {
|
||||
println(">> TODO")
|
||||
}
|
||||
|
||||
@AfterAll
|
||||
fun teardown() {
|
||||
println(">> Tear down")
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
## Creating your own extensions
|
||||
|
||||
Instead of using util classes with abstract methods like in Java, it is usual in Kotlin to provide such functionalities via Kotlin extensions. Here we are going to add a `format()` function to the existing `LocalDateTime` type in order to generate text with the English date format.
|
||||
|
||||
`src/main/kotlin/com/example/blog/Extensions.kt`
|
||||
```kotlin
|
||||
fun LocalDateTime.format(): String = this.format(englishDateFormatter)
|
||||
|
||||
private val daysLookup = (1..31).associate { it.toLong() to getOrdinal(it) }
|
||||
|
||||
private val englishDateFormatter = DateTimeFormatterBuilder()
|
||||
.appendPattern("yyyy-MM-dd")
|
||||
.appendLiteral(" ")
|
||||
.appendText(ChronoField.DAY_OF_MONTH, daysLookup)
|
||||
.appendLiteral(" ")
|
||||
.appendPattern("yyyy")
|
||||
.toFormatter(Locale.ENGLISH)
|
||||
|
||||
private fun getOrdinal(n: Int) = when {
|
||||
n in 11..13 -> "${n}th"
|
||||
n % 10 == 1 -> "${n}st"
|
||||
n % 10 == 2 -> "${n}nd"
|
||||
n % 10 == 3 -> "${n}rd"
|
||||
else -> "${n}th"
|
||||
}
|
||||
|
||||
fun String.toSlug() = lowercase(Locale.getDefault())
|
||||
.replace("\n", " ")
|
||||
.replace("[^a-z\\d\\s]".toRegex(), " ")
|
||||
.split(" ")
|
||||
.joinToString("-")
|
||||
.replace("-+".toRegex(), "-")
|
||||
```
|
||||
|
||||
We will leverage these extensions in the next section.
|
||||
|
||||
## Persistence with JPA
|
||||
|
||||
In order to make lazy fetching working as expected, entities should be `open` as described in [KT-28525](https://youtrack.jetbrains.com/issue/KT-28525). We are going to use the Kotlin `allopen` plugin for that purpose.
|
||||
|
||||
With Gradle:
|
||||
|
||||
`build.gradle.kts`
|
||||
```kotlin
|
||||
plugins {
|
||||
...
|
||||
kotlin("plugin.allopen") version "1.8.0"
|
||||
}
|
||||
|
||||
allOpen {
|
||||
annotation("jakarta.persistence.Entity")
|
||||
annotation("jakarta.persistence.Embeddable")
|
||||
annotation("jakarta.persistence.MappedSuperclass")
|
||||
}
|
||||
```
|
||||
|
||||
Or with Maven:
|
||||
|
||||
`pom.xml`
|
||||
```xml
|
||||
<plugin>
|
||||
<artifactId>kotlin-maven-plugin</artifactId>
|
||||
<groupId>org.jetbrains.kotlin</groupId>
|
||||
<configuration>
|
||||
...
|
||||
<compilerPlugins>
|
||||
...
|
||||
<plugin>all-open</plugin>
|
||||
</compilerPlugins>
|
||||
<pluginOptions>
|
||||
<option>all-open:annotation=jakarta.persistence.Entity</option>
|
||||
<option>all-open:annotation=jakarta.persistence.Embeddable</option>
|
||||
<option>all-open:annotation=jakarta.persistence.MappedSuperclass</option>
|
||||
</pluginOptions>
|
||||
</configuration>
|
||||
</plugin>
|
||||
```
|
||||
|
||||
Then we create our model by using Kotlin [primary constructor concise syntax](https://kotlinlang.org/docs/reference/classes.html#constructors) which allows to declare at the same time the properties and the constructor parameters.
|
||||
|
||||
`src/main/kotlin/com/example/blog/Entities.kt`
|
||||
```kotlin
|
||||
@Entity
|
||||
class Article(
|
||||
var title: String,
|
||||
var headline: String,
|
||||
var content: String,
|
||||
@ManyToOne var author: User,
|
||||
var slug: String = title.toSlug(),
|
||||
var addedAt: LocalDateTime = LocalDateTime.now(),
|
||||
@Id @GeneratedValue var id: Long? = null)
|
||||
|
||||
@Entity
|
||||
class User(
|
||||
var login: String,
|
||||
var firstname: String,
|
||||
var lastname: String,
|
||||
var description: String? = null,
|
||||
@Id @GeneratedValue var id: Long? = null)
|
||||
```
|
||||
|
||||
Notice that we are using here our `String.toSlug()` extension to provide a default argument to the `slug` parameter of `Article` constructor. Optional parameters with default values are defined at the last position in order to make it possible to omit them when using positional arguments (Kotlin also supports [named arguments](https://kotlinlang.org/docs/reference/functions.html#named-arguments)). Notice that in Kotlin it is not unusual to group concise class declarations in the same file.
|
||||
|
||||
> [!info]
|
||||
> Here we don’t use [`data` classes](https://kotlinlang.org/docs/data-classes.html) with `val` properties because JPA is not designed to work with immutable classes or the methods generated automatically by `data` classes. If you are using other Spring Data flavor, most of them are designed to support such constructs so you should use classes like `data class User(val login: String, …)` when using Spring Data MongoDB, Spring Data JDBC, etc.
|
||||
|
||||
> [!info]
|
||||
> While Spring Data JPA makes it possible to use natural IDs (it could have been the `login` property in `User` class) via [`Persistable`](https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.entity-persistence.saving-entites), it is not a good fit with Kotlin due to [KT-6653](https://youtrack.jetbrains.com/issue/KT-6653), that’s why it is recommended to always use entities with generated IDs in Kotlin.
|
||||
|
||||
We also declare our Spring Data JPA repositories as following.
|
||||
|
||||
`src/main/kotlin/com/example/blog/Repositories.kt`
|
||||
```kotlin
|
||||
interface ArticleRepository : CrudRepository<Article, Long> {
|
||||
fun findBySlug(slug: String): Article?
|
||||
fun findAllByOrderByAddedAtDesc(): Iterable<Article>
|
||||
}
|
||||
|
||||
interface UserRepository : CrudRepository<User, Long> {
|
||||
fun findByLogin(login: String): User?
|
||||
}
|
||||
```
|
||||
|
||||
And we write JPA tests to check whether basic use cases work as expected.
|
||||
|
||||
`src/test/kotlin/com/example/blog/RepositoriesTests.kt`
|
||||
```kotlin
|
||||
@DataJpaTest
|
||||
class RepositoriesTests @Autowired constructor(
|
||||
val entityManager: TestEntityManager,
|
||||
val userRepository: UserRepository,
|
||||
val articleRepository: ArticleRepository) {
|
||||
|
||||
@Test
|
||||
fun `When findByIdOrNull then return Article`() {
|
||||
val johnDoe = User("johnDoe", "John", "Doe")
|
||||
entityManager.persist(johnDoe)
|
||||
val article = Article("Lorem", "Lorem", "dolor sit amet", johnDoe)
|
||||
entityManager.persist(article)
|
||||
entityManager.flush()
|
||||
val found = articleRepository.findByIdOrNull(article.id!!)
|
||||
assertThat(found).isEqualTo(article)
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `When findByLogin then return User`() {
|
||||
val johnDoe = User("johnDoe", "John", "Doe")
|
||||
entityManager.persist(johnDoe)
|
||||
entityManager.flush()
|
||||
val user = userRepository.findByLogin(johnDoe.login)
|
||||
assertThat(user).isEqualTo(johnDoe)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!info]
|
||||
> We use here the `CrudRepository.findByIdOrNull` Kotlin extension provided by default with Spring Data, which is a nullable variant of the `Optional` based `CrudRepository.findById`. Read the great [Null is your friend, not a mistake](https://medium.com/@elizarov/null-is-your-friend-not-a-mistake-b63ff1751dd5) blog post for more details.
|
||||
|
||||
## Implementing the blog engine
|
||||
|
||||
We update the "blog" Mustache templates.
|
||||
|
||||
`src/main/resources/templates/blog.mustache`
|
||||
```html
|
||||
{{> header}} <h1>{{title}}</h1>
|
||||
|
||||
<div class="articles"> {{#articles}} <section>
|
||||
<header class="article-header">
|
||||
<h2 class="article-title"><a href="/article/{{slug}}">{{title}}</a></h2>
|
||||
<div class="article-meta">By <strong>{{author.firstname}}</strong>, on <strong>{{addedAt}}</strong></div>
|
||||
</header>
|
||||
<div class="article-description"> {{headline}} </div>
|
||||
</section> {{/articles}} </div> {{> footer}}
|
||||
```
|
||||
|
||||
And we create an "article" new one.
|
||||
|
||||
`src/main/resources/templates/article.mustache`
|
||||
```hmtl
|
||||
{{> header}} <section class="article">
|
||||
<header class="article-header">
|
||||
<h1 class="article-title">{{article.title}}</h1>
|
||||
<p class="article-meta">By <strong>{{article.author.firstname}}</strong>, on <strong>{{article.addedAt}}</strong></p>
|
||||
</header>
|
||||
|
||||
<div class="article-description"> {{article.headline}}
|
||||
|
||||
{{article.content}} </div>
|
||||
</section> {{> footer}}
|
||||
```
|
||||
|
||||
We update the `HtmlController` in order to render blog and article pages with the formatted date. `ArticleRepository` and `MarkdownConverter` constructor parameters will be automatically autowired since `HtmlController` has a single constructor (implicit `@Autowired`).
|
||||
|
||||
`src/main/kotlin/com/example/blog/HtmlController.kt`
|
||||
```kotlin
|
||||
@Controller
|
||||
class HtmlController(private val repository: ArticleRepository) {
|
||||
|
||||
@GetMapping("/")
|
||||
fun blog(model: Model): String {
|
||||
model["title"] = "Blog"
|
||||
model["articles"] = repository.findAllByOrderByAddedAtDesc().map { it.render() }
|
||||
return "blog"
|
||||
}
|
||||
|
||||
@GetMapping("/article/{slug}")
|
||||
fun article(@PathVariable slug: String, model: Model): String {
|
||||
val article = repository
|
||||
.findBySlug(slug)
|
||||
?.render()
|
||||
?: throw ResponseStatusException(HttpStatus.NOT_FOUND, "This article does not exist")
|
||||
model["title"] = article.title
|
||||
model["article"] = article
|
||||
return "article"
|
||||
}
|
||||
|
||||
fun Article.render() = RenderedArticle(
|
||||
slug,
|
||||
title,
|
||||
headline,
|
||||
content,
|
||||
author,
|
||||
addedAt.format()
|
||||
)
|
||||
|
||||
data class RenderedArticle(
|
||||
val slug: String,
|
||||
val title: String,
|
||||
val headline: String,
|
||||
val content: String,
|
||||
val author: User,
|
||||
val addedAt: String)
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Then, we add data initialization to a new `BlogConfiguration` class.
|
||||
|
||||
`src/main/kotlin/com/example/blog/BlogConfiguration.kt`
|
||||
```kotlin
|
||||
@Configuration
|
||||
class BlogConfiguration {
|
||||
|
||||
@Bean
|
||||
fun databaseInitializer(userRepository: UserRepository,
|
||||
articleRepository: ArticleRepository) = ApplicationRunner {
|
||||
|
||||
val johnDoe = userRepository.save(User("johnDoe", "John", "Doe"))
|
||||
articleRepository.save(Article(
|
||||
title = "Lorem",
|
||||
headline = "Lorem",
|
||||
content = "dolor sit amet",
|
||||
author = johnDoe
|
||||
))
|
||||
articleRepository.save(Article(
|
||||
title = "Ipsum",
|
||||
headline = "Ipsum",
|
||||
content = "dolor sit amet",
|
||||
author = johnDoe
|
||||
))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!info]
|
||||
> Notice the usage of named parameters to make the code more readable.
|
||||
|
||||
And we also update the integration tests accordingly.
|
||||
|
||||
`src/test/kotlin/com/example/blog/IntegrationTests.kt`
|
||||
```kotlin
|
||||
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
|
||||
class IntegrationTests(@Autowired val restTemplate: TestRestTemplate) {
|
||||
|
||||
@BeforeAll
|
||||
fun setup() {
|
||||
println(">> Setup")
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `Assert blog page title, content and status code`() {
|
||||
println(">> Assert blog page title, content and status code")
|
||||
val entity = restTemplate.getForEntity<String>("/")
|
||||
assertThat(entity.statusCode).isEqualTo(HttpStatus.OK)
|
||||
assertThat(entity.body).contains("<h1>Blog</h1>", "Lorem")
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `Assert article page title, content and status code`() {
|
||||
println(">> Assert article page title, content and status code")
|
||||
val title = "Lorem"
|
||||
val entity = restTemplate.getForEntity<String>("/article/${title.toSlug()}")
|
||||
assertThat(entity.statusCode).isEqualTo(HttpStatus.OK)
|
||||
assertThat(entity.body).contains(title, "Lorem", "dolor sit amet")
|
||||
}
|
||||
|
||||
@AfterAll
|
||||
fun teardown() {
|
||||
println(">> Tear down")
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Start (or restart) the web application, and go to `http://localhost:8080/`, you should see the list of articles with clickable links to see a specific article.
|
||||
|
||||
## Exposing HTTP API
|
||||
|
||||
We are now going to implement the HTTP API via `@RestController` annotated controllers.
|
||||
|
||||
`src/main/kotlin/com/example/blog/HttpControllers.kt`
|
||||
```kotlin
|
||||
@RestController
|
||||
@RequestMapping("/api/article")
|
||||
class ArticleController(private val repository: ArticleRepository) {
|
||||
|
||||
@GetMapping("/")
|
||||
fun findAll() = repository.findAllByOrderByAddedAtDesc()
|
||||
|
||||
@GetMapping("/{slug}")
|
||||
fun findOne(@PathVariable slug: String) =
|
||||
repository.findBySlug(slug) ?: throw ResponseStatusException(HttpStatus.NOT_FOUND, "This article does not exist")
|
||||
|
||||
}
|
||||
|
||||
@RestController
|
||||
@RequestMapping("/api/user")
|
||||
class UserController(private val repository: UserRepository) {
|
||||
|
||||
@GetMapping("/")
|
||||
fun findAll() = repository.findAll()
|
||||
|
||||
@GetMapping("/{login}")
|
||||
fun findOne(@PathVariable login: String) =
|
||||
repository.findByLogin(login) ?: throw ResponseStatusException(HttpStatus.NOT_FOUND, "This user does not exist")
|
||||
}
|
||||
```
|
||||
|
||||
For tests, instead of integration tests, we are going to leverage `@WebMvcTest` and [Mockk](https://mockk.io/) which is similar to [Mockito](https://site.mockito.org/) but better suited for Kotlin.
|
||||
|
||||
Since `@MockBean` and `@SpyBean` annotations are specific to Mockito, we are going to leverage [SpringMockK](https://github.com/Ninja-Squad/springmockk) which provides similar `@MockkBean` and `@SpykBean` annotations for Mockk.
|
||||
|
||||
With Gradle:
|
||||
|
||||
`build.gradle.kts`
|
||||
```kotlin
|
||||
testImplementation("org.springframework.boot:spring-boot-starter-test") {
|
||||
exclude(module = "mockito-core")
|
||||
}
|
||||
testImplementation("org.junit.jupiter:junit-jupiter-api")
|
||||
testRuntimeOnly("org.junit.jupiter:junit-jupiter-engine")
|
||||
testImplementation("com.ninja-squad:springmockk:4.0.0")
|
||||
```
|
||||
|
||||
Or with Maven:
|
||||
|
||||
`pom.xml`
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-test</artifactId>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.junit.jupiter</groupId>
|
||||
<artifactId>junit-jupiter-engine</artifactId>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>com.ninja-squad</groupId>
|
||||
<artifactId>springmockk</artifactId>
|
||||
<version>4.0.0</version>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
`src/test/kotlin/com/example/blog/HttpControllersTests.kt`
|
||||
```kotlin
|
||||
@WebMvcTest
|
||||
class HttpControllersTests(@Autowired val mockMvc: MockMvc) {
|
||||
|
||||
@MockkBean
|
||||
lateinit var userRepository: UserRepository
|
||||
|
||||
@MockkBean
|
||||
lateinit var articleRepository: ArticleRepository
|
||||
|
||||
@Test
|
||||
fun `List articles`() {
|
||||
val johnDoe = User("johnDoe", "John", "Doe")
|
||||
val lorem5Article = Article("Lorem", "Lorem", "dolor sit amet", johnDoe)
|
||||
val ipsumArticle = Article("Ipsum", "Ipsum", "dolor sit amet", johnDoe)
|
||||
every { articleRepository.findAllByOrderByAddedAtDesc() } returns listOf(lorem5Article, ipsumArticle)
|
||||
mockMvc.perform(get("/api/article/").accept(MediaType.APPLICATION_JSON))
|
||||
.andExpect(status().isOk)
|
||||
.andExpect(content().contentType(MediaType.APPLICATION_JSON))
|
||||
.andExpect(jsonPath("\$.[0].author.login").value(johnDoe.login))
|
||||
.andExpect(jsonPath("\$.[0].slug").value(lorem5Article.slug))
|
||||
.andExpect(jsonPath("\$.[1].author.login").value(johnDoe.login))
|
||||
.andExpect(jsonPath("\$.[1].slug").value(ipsumArticle.slug))
|
||||
}
|
||||
|
||||
@Test
|
||||
fun `List users`() {
|
||||
val johnDoe = User("johnDoe", "John", "Doe")
|
||||
val janeDoe = User("janeDoe", "Jane", "Doe")
|
||||
every { userRepository.findAll() } returns listOf(johnDoe, janeDoe)
|
||||
mockMvc.perform(get("/api/user/").accept(MediaType.APPLICATION_JSON))
|
||||
.andExpect(status().isOk)
|
||||
.andExpect(content().contentType(MediaType.APPLICATION_JSON))
|
||||
.andExpect(jsonPath("\$.[0].login").value(johnDoe.login))
|
||||
.andExpect(jsonPath("\$.[1].login").value(janeDoe.login))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!hint]
|
||||
> `$` needs to be escaped in strings as it is used for string interpolation.
|
||||
|
||||
## Configuration properties
|
||||
|
||||
In Kotlin, the recommended way to manage your application properties is to use read-only properties.
|
||||
|
||||
`src/main/kotlin/com/example/blog/BlogProperties.kt`
|
||||
```kotlin
|
||||
@ConfigurationProperties("blog")
|
||||
data class BlogProperties(var title: String, val banner: Banner) {
|
||||
data class Banner(val title: String? = null, val content: String)
|
||||
}
|
||||
```
|
||||
|
||||
Then we enable it at `BlogApplication` level.
|
||||
|
||||
`src/main/kotlin/com/example/blog/BlogApplication.kt`
|
||||
```kotlin
|
||||
@SpringBootApplication
|
||||
@EnableConfigurationProperties(BlogProperties::class)
|
||||
class BlogApplication {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
To generate [your own metadata](https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#configuration-metadata-annotation-processor) in order to get these custom properties recognized by your IDE, [kapt should be configured](https://kotlinlang.org/docs/reference/kapt.html) with the `spring-boot-configuration-processor` dependency as following.
|
||||
|
||||
`build.gradle.kts`
|
||||
```kotlin
|
||||
plugins {
|
||||
...
|
||||
kotlin("kapt") version "1.8.0"
|
||||
}
|
||||
|
||||
dependencies {
|
||||
...
|
||||
kapt("org.springframework.boot:spring-boot-configuration-processor")
|
||||
}
|
||||
```
|
||||
|
||||
> [!info]
|
||||
> Note that some features (such as detecting the default value or deprecated items) are not working due to limitations in the model kapt provides. Also annotation processing is not yet supported with Maven due to [KT-18022](https://youtrack.jetbrains.com/issue/KT-18022), see [initializr#438](https://github.com/spring-io/initializr/issues/438) for more details.
|
||||
|
||||
In IntelliJ IDEA:
|
||||
|
||||
- Make sure Spring Boot plugin in enabled in menu File | Settings | Plugins | Spring Boot
|
||||
- Enable annotation processing via menu File | Settings | Build, Execution, Deployment | Compiler | Annotation Processors | Enable annotation processing
|
||||
- Since [Kapt is not yet integrated in IDEA](https://youtrack.jetbrains.com/issue/KT-15040), you need to run manually the command `./gradlew kaptKotlin` to generate the metadata
|
||||
|
||||
Your custom properties should now be recognized when editing `application.properties` (autocomplete, validation, etc.).
|
||||
|
||||
`src/main/resources/application.properties`
|
||||
```properties
|
||||
blog.title=Blog
|
||||
blog.banner.title=Warning
|
||||
blog.banner.content=The blog will be down tomorrow.
|
||||
```
|
||||
|
||||
Edit the template and the controller accordingly.
|
||||
|
||||
`src/main/resources/templates/blog.mustache`
|
||||
```html
|
||||
{{> header}} <div class="articles"> {{#banner.title}} <section>
|
||||
<header class="banner">
|
||||
<h2 class="banner-title">{{banner.title}}</h2>
|
||||
</header>
|
||||
<div class="banner-content"> {{banner.content}} </div>
|
||||
</section> {{/banner.title}} ...
|
||||
|
||||
</div> {{> footer}}
|
||||
```
|
||||
|
||||
`src/main/kotlin/com/example/blog/HtmlController.kt`
|
||||
```kotlin
|
||||
@Controller
|
||||
class HtmlController(private val repository: ArticleRepository,
|
||||
private val properties: BlogProperties) {
|
||||
|
||||
@GetMapping("/")
|
||||
fun blog(model: Model): String {
|
||||
model["title"] = properties.title
|
||||
model["banner"] = properties.banner
|
||||
model["articles"] = repository.findAllByOrderByAddedAtDesc().map { it.render() }
|
||||
return "blog"
|
||||
}
|
||||
|
||||
// ...
|
||||
```
|
||||
|
||||
Restart the web application, refresh `http://localhost:8080/`, you should see the banner on the blog homepage.
|
||||
|
||||
## Conclusion
|
||||
|
||||
We have now finished to build this sample Kotlin blog application. The source code [is available on Github](https://github.com/spring-guides/tut-spring-boot-kotlin). You can also have a look to [Spring Framework](https://docs.spring.io/spring/docs/current/spring-framework-reference/languages.html#kotlin) and [Spring Boot](https://docs.spring.io/spring-boot/docs/current/reference/html/boot-features-kotlin.html) reference documentation if you need more details on specific features.
|
||||
@@ -1,9 +0,0 @@
|
||||
---
|
||||
title: Camel JSON
|
||||
---
|
||||
|
||||
|
||||
https://camel.apache.org/manual/latest/json.html#JSON-UnmarshallingfromjsontoListMaporListpojo
|
||||
https://camel.apache.org/components/latest/dataformats/json-jackson-dataformat.html
|
||||
https://camel.apache.org/components/3.4.x/dataformats/json-gson-dataformat.html
|
||||
https://camel.apache.org/manual/latest/data-format.html
|
||||
-106
@@ -1,106 +0,0 @@
|
||||
---
|
||||
title: "Code Coverage: From Failing the Build To Publishing The Report With Gitlab Pages"
|
||||
source: https://blog.gojekengineering.com/code-coverage-from-failing-the-build-to-publishing-the-report-with-gitlab-pages-a1d9a6a414c0
|
||||
tags:
|
||||
- IT/Development/Gradle
|
||||
- IT/Development/Java
|
||||
- IT/DevOps
|
||||
---
|
||||
|
||||
[Code Coverage: From Failing the Build To Publishing The Report With Gitlab Pages](https://blog.gojekengineering.com/code-coverage-from-failing-the-build-to-publishing-the-report-with-gitlab-pages-a1d9a6a414c0)
|
||||
|
||||
Before going into how gitlab can help us in publishing code coverage reports and making build fail if the coverage is not upto the mark, let’s first go over some of the basic questions.
|
||||
|
||||
## What is Code coverage?
|
||||
|
||||
Code coverage is a technique which tells us that how much of application code has been covered and exercised if we run our test cases. There are many different tools for different languages to measure the code coverage.I will be mainly focusing on Java in this blog.
|
||||
|
||||
## Why Code Coverage Is Important?
|
||||
|
||||
Code coverage gives us insight on how effective our test cases are, what parts of our source code are thoroughly executed, coverage report helps in finding untested part in your codebase. It helps us in increasing and maintaining the quality of code. But having a 100% test coverage doesn’t mean 100% tested because code coverage executed by the two test cases can be the same but input data of 1st test case can find the defect while input of 2nd test case cannot. There are also other metrics like cyclomatic complexity, lines of code, maintainability index and depth of inheritance etc which can also help you in making your code better.I will cover these topics in future blogs.
|
||||
|
||||
## How to generate Code Coverage Report?
|
||||
|
||||
Now that’s just basic understanding of code coverage. Now let’s see how we can generate code coverage reports in java using gradle.
|
||||
|
||||
For generating coverage report in java we will use jacoco , it’s very easy to integrate with your codebase. If you are using gradle, you need to apply the Jacoco plugin in your build.gradle.
|
||||
|
||||
> build.gradle
|
||||
> apply plugin: “jacoco”
|
||||
|
||||
After applying plugin a new task named **jacocoTestReport** is created which is dependent on **test** task. You just need to run **gradle test jacocoTestReport** and your coverage report is available at `***$buildDir***`**/reports/jacoco/test.** By default, HTML report is generated. But what about we want running **test task** to also generate the coverage report. For that you can use **finalisedBy** property provided by gradle. This will finalize **test task** after jacocoTestReport.
|
||||
|
||||
```groovy
|
||||
test {
|
||||
finalizedBy jacocoTestReport
|
||||
}
|
||||
```
|
||||
|
||||
You can also add JacocoReport task in your build.gradle, it can be used to generate code coverage reports in different formats.
|
||||
|
||||
**build.gradle**
|
||||
```groovy
|
||||
jacocoTestReport {
|
||||
reports {
|
||||
xml.enabled false
|
||||
csv.enabled false
|
||||
html.destination "${buildDir}/jacocoHtml"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Now what about we make our build fail if code coverage metrics are not upto the mark. This will help us in preventing untested code to go into production. You can do this by adding **jacocoTestCoverageVerification** task.
|
||||
|
||||
```groovy
|
||||
jacocoTestCoverageVerification {
|
||||
violationRules {
|
||||
rule {
|
||||
limit {
|
||||
minimum = 0.7
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
0.7 states that your tests should cover minimum 70% of your codebase, violating that will fail the build. Now this requirement can be specified for the project as a whole, for individual files, and for particular JaCoCo-specific types of coverage, e.g., lines covered or branches covered. You can read more about it on [gradle docs](https://docs.gradle.org/4.0.2/userguide/jacoco_plugin.html#sec:jacoco_report_violation_rules).
|
||||
|
||||
Since now we have code coverage report , how about we publish it on gitlab pages.
|
||||
|
||||
## How to publish Report to Gitlab Pages
|
||||
|
||||
The configuration of gitlab CI is defined in **.gitlab-ci.yml** file. Let’s see how to write configuration for publishing report to gitlab pages.
|
||||
|
||||
Before publishing we need to first execute test and generates coverage report within a single job in the CI pipeline.
|
||||
|
||||
```yaml
|
||||
test:
|
||||
stage: test
|
||||
script: - ./gradlew test
|
||||
artifacts:
|
||||
paths: - build/reports/jacoco/
|
||||
```
|
||||
|
||||
Everything inside *build/reports/jacoco/* will be stored as artifact.We will use this artifact in our next job.
|
||||
|
||||
Let’s publish the coverage report we generated in our last job on gitlab pages. You need to add **pages job** in **.gitlab-ci.yml.**
|
||||
|
||||
```yml
|
||||
pages:
|
||||
stage: deploy
|
||||
dependencies:
|
||||
- test
|
||||
script:
|
||||
- mkdir public \- mv build/reports/jacoco/test/html/* public
|
||||
artifacts:
|
||||
paths:
|
||||
- public
|
||||
only:
|
||||
- master
|
||||
```
|
||||
|
||||
This job will publish your test coverage report to gitlab pages. Not that you need to use **pages** as job name. Using **dependencies** keyword will tell gitlab to download artifacts stored as a part of **test** job. You also need to move coverage report to **public** directory because this is the directory that **GitLab Pages** expects to find static website in.Using **only** keyword will publish new coverage report only when CI pipeline runs on master branch.
|
||||
|
||||
Once you push your changes in .gitlab-ci.yml to Gitlab for the first time you will see new job in CI pipeline. When **pages:deploy** job is successfull you can access your coverage report using URL [http://group-path.gitlab.io/project-path/index.html.](http://group-path.gitlab.io/project-path/index.html.) The page should look something like:
|
||||
|
||||
If you reach till this point of the blog , then now you will be able to publish your code coverage report to gitlab pages.
|
||||
@@ -1,68 +0,0 @@
|
||||
---
|
||||
title: "Command Line Argument Parsing for Groovy | Jarrod Roberson: Programming Missives"
|
||||
tags:
|
||||
- IT/Development/Groovy
|
||||
---
|
||||
|
||||
Groovy has some wrappers around the apache.commons.cli via their CLIBuilder class. This is a pretty old and crusty library that has some significant limitations. I prefer to use the Java Simple Argument Parser (JSAP) library. Especially since they have added the ability to declare argument definitions in a declarative XML file. This reduces the code footprint in your Groovy or Java program significantly. Normally I am adverse to XML configuration programming but in this case the syntax is very succinct and an appropriate use.
|
||||
|
||||
Here is a partial example of argument declarations for an example program that scans for open ports on a server.
|
||||
```xml
|
||||
<jsap>
|
||||
<parameters>
|
||||
<switch>
|
||||
<id>help</id>
|
||||
<shortFlag>h</shortFlag>
|
||||
<longFlag>help</longFlag>
|
||||
<help>Display this help</help>
|
||||
</switch>
|
||||
<flaggedOption>
|
||||
<id>host</id>
|
||||
<stringParser>
|
||||
<classname>StringStringParser</classname>
|
||||
</stringParser>
|
||||
<required>true</required>
|
||||
<shortFlag>h</shortFlag>
|
||||
<longFlag>host</longFlag>
|
||||
<help>Server to use to scan for open ports</help>
|
||||
</flaggedOption>
|
||||
<unflaggedOption>
|
||||
<id>ports</id>
|
||||
<stringParser>
|
||||
<classname>IntegerStringParser</classname>
|
||||
</stringParser>
|
||||
<greedy>true</greedy>
|
||||
<list>true</list>
|
||||
<listSeparator>,</listSeparator>
|
||||
<help>List of ports to scan on the server</help>
|
||||
</unflaggedOption>
|
||||
</parameters>
|
||||
</jsap>
|
||||
```
|
||||
[jsap.xml](https://gist.github.com/jarrodhroberson/8995420#file-jsap-xml) hosted with ❤ by GitHub
|
||||
|
||||
|
||||
|
||||
Then you can use the following boilerplate code to initialize the parser and use it. Assuming the code is saved in file named “main.groovy” and the configuration file is named “main.jsap” and both are built into a .jar file called main.jar
|
||||
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
|
||||
```groovy
|
||||
JSAP jsap = new JSAP(main.getResource("main.jsap"));
|
||||
JSAPResult config = jsap.parse(args)
|
||||
if (config.getBoolean("help") || !config.success())
|
||||
{
|
||||
println "Usage: java -jar main.jar " + jsap.usage
|
||||
println ""
|
||||
println jsap.help
|
||||
if (!config.success())
|
||||
{
|
||||
for (e in config.getErrorMessageIterator())
|
||||
{
|
||||
println e
|
||||
}
|
||||
}
|
||||
System.exit(0)
|
||||
}
|
||||
```
|
||||
[main.groovy](https://gist.github.com/jarrodhroberson/8995431#file-main-groovy) hosted with ❤ by GitHub
|
||||
|
||||
That is basically all the code you need to easily and powerfully parse command line arguments in Groovy.
|
||||
@@ -1,230 +0,0 @@
|
||||
---
|
||||
title: CompletableFuture in Java with Examples
|
||||
source: https://xperti.io/blogs/completablefuture-in-java/
|
||||
tags:
|
||||
- IT/Development/Java
|
||||
---
|
||||
|
||||
**Inhaltsverzeichnis**
|
||||
|
||||
1. [[#What is CompletableFuture?|What is CompletableFuture?]]
|
||||
1. [[#What is the difference between Future and CompletableFuture in Java?|What is the difference between Future and CompletableFuture in Java?]]
|
||||
1. [[#Future VS CompletableFuture API|Future VS CompletableFuture API]]
|
||||
1. [[#Let’s create a CompletableFuture|Let’s create a CompletableFuture]]
|
||||
1. [[#Let’s create a CompletableFuture#Starting with the basics.|Starting with the basics.]]
|
||||
1. [[#Let’s create a CompletableFuture#Running an asynchronous computation using `runAsync()` method|Running an asynchronous computation using `runAsync()` method]]
|
||||
1. [[#Let’s create a CompletableFuture#Transforming and acting on a CompletableFuture|Transforming and acting on a CompletableFuture]]
|
||||
1. [[#Transforming and acting on a CompletableFuture#`thenApply()`|`thenApply()`]]
|
||||
1. [[#Transforming and acting on a CompletableFuture#`thenAccept()`|`thenAccept()`]]
|
||||
1. [[#Transforming and acting on a CompletableFuture#`thenRun()`|`thenRun()`]]
|
||||
1. [[#Let’s create a CompletableFuture#Combining two CompletableFutures|Combining two CompletableFutures]]
|
||||
1. [[#Conclusion|Conclusion]]
|
||||
|
||||
Java 8 introduced a lot of new features like [Streams API](https://docs.oracle.com/javase/8/docs/api/java/util/stream/Stream.html) and Lambda. One of the prominent additions was CompletableFuture. This article will be discussing CompletableFutureJava and all its methods. We will look at how it works and how you can use it in your Java code using simple examples.
|
||||
|
||||
|
||||
## What is CompletableFuture?
|
||||
|
||||
CompletableFuture is a feature for asynchronous programming using Java. Unlike procedural programming, asynchronous programming is about writing a non-blocking code by running all the tasks on separate threads instead of the main application thread and keep notifying the main thread about the progress, completion status, or if the task fails.
|
||||
|
||||
This way, your main thread does not get blocked while waiting for the completion of a task as it can be executed in parallel. This kind of parallelism can significantly improve the performance of your programs and the time taken for execution.
|
||||
|
||||
## What is the difference between Future and CompletableFuture in Java?
|
||||
|
||||
You would have probably heard about Future API in Java. CompletableFuture is an extension to the Future API which was introduced way back in Java 5. Future API is used as a reference to the results of asynchronous computations from CompletableFutureJava. It provides an isDone() method to confirm whether the computation is done or not, and a get() method to retrieve the result of the computation after it is done.
|
||||
|
||||
## Future VS CompletableFuture API
|
||||
|
||||
Future API was a great step taken towards asynchronous programming in Java but it lacked some very important and crucial features. That is where CompletableFuture comes in as it offers all those features that were limited in Future API.
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| ### <br><br>CompletableFuture API | ### <br><br>Future API |
|
||||
| It can be completed manually. While using a remote-API, if the remote API service gets down, you can complete the Future API manually to retrieve the data. | Future API does not allow manual completion. The program would come to a halt and stop responding if a remote API server gets down. |
|
||||
| It allows a callback function to the API and has it called automatically when the result is available. This way, further actions can be performed on a received result from the API. | Future does not notify of the completion on an API. It just provides a get() method which blocks until the result is available to the main thread. Ultimately, it restricts users from applying any further action on the result. |
|
||||
| You can create an asynchronous workflow with CompletableFuture. It allows chaining multiple APIs, sending ones to result to another. | Future API does not allow chaining multiple future APIs. It needs to be done manually. |
|
||||
| It allows combining multiple futures in CompletableFuture. You can now run multiple APIs in parallel and then it can also be combined with some functions afterward when all of them completes. | Combining multiple futures is possible in Future APIs. You also have to run the functions afterward by yourself if you wish to combine them. |
|
||||
| It also offers exception handling. CompletableFuture, it implements Future and CompletionStage interfaces to provides a huge set of all convenient methods along with a very comprehensive exception handling support. | Future API did not have any exception handling construct. |
|
||||
|
||||
## Let’s create a CompletableFuture
|
||||
|
||||
### Starting with the basics.
|
||||
|
||||
You can create a CompletableFuture by simply using the following non-argument constructor
|
||||
|
||||
```java
|
||||
CompletableFuture<String> completableFuture = new CompletableFuture<String>();
|
||||
```
|
||||
|
||||
This is the most basic CompletableFuture that you can make.
|
||||
|
||||
All the clients who want to get the result of this CompletableFuture can call CompletableFuture.get()method like this,
|
||||
|
||||
```java
|
||||
String result = completableFuture.get();
|
||||
```
|
||||
|
||||
As mentioned before, the get() method blocks until the Future is completed. So, the above-mentioned call will be blocked forever if the Future will never be completed.
|
||||
|
||||
To cater to that, you can use CompletableFuture.complete() method to manually complete a Future,
|
||||
|
||||
```java
|
||||
completableFuture.complete("Result of Future");
|
||||
```
|
||||
|
||||
All the clients waiting for this Future will receive the specified result and the subsequent calls to `completableFuture.complete()` will be ignored.
|
||||
|
||||
### Running an asynchronous computation using `runAsync()` method
|
||||
|
||||
If you wish to run a background task asynchronously and do not want to return anything from that task, you can use CompletableFuture.runAsync() method. It takes a Runnable object and returns CompletableFuture<Void>.
|
||||
|
||||
```java
|
||||
// Run a task asynchronously, specified by a Runnable Object.
|
||||
CompletableFuture<Void> future = CompletableFuture.runAsync(new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
// Simulate a long-running Job
|
||||
try {
|
||||
TimeUnit.SECONDS.sleep(3);
|
||||
} catch (InterruptedException e) {
|
||||
throw new IllegalStateException(e);
|
||||
}
|
||||
System.out.println("this will run in a separate thread from the main thread.");
|
||||
}
|
||||
});
|
||||
// Block and wait for the future to complete
|
||||
future.get()
|
||||
```
|
||||
|
||||
`CompletableFuture.runAsync()` is used for tasks that do not need to return anything but what if you want to return the result from your background task there is a method for it, `CompletableFuture.supplyAsync()`.
|
||||
|
||||
It takes a `Supplier<T>` and will return `CompletableFuture<T>` where `T`is the type of the value obtained by calling the given supplier
|
||||
|
||||
```java
|
||||
// Run a task asynchronously, specified by a Supplier object.
|
||||
CompletableFuture<String> future = CompletableFuture.supplyAsync(new Supplier<String>() {
|
||||
@Override
|
||||
public String get() {
|
||||
try {
|
||||
TimeUnit.SECONDS.sleep(3);
|
||||
} catch (InterruptedException e) {
|
||||
throw new IllegalStateException(e);
|
||||
}
|
||||
return "Result of the asynchronous computation";
|
||||
}
|
||||
});
|
||||
// Block and get the result of the Future
|
||||
String result = future.get();
|
||||
System.out.println(result);
|
||||
```
|
||||
|
||||
A `Supplier<T>` is a simple functional interface that represents a supplier of results. It has a single `get()` method where you can write your background task and return the result.
|
||||
|
||||
### Transforming and acting on a CompletableFuture
|
||||
|
||||
For building asynchronous systems, you need to attach a callback to the CompletableFuture which should automatically get called when the Future completes.
|
||||
|
||||
You can do that using the following methods,
|
||||
|
||||
#### `thenApply()`
|
||||
|
||||
`thenApply()` method is used to process and transform the result of a CompletableFuture as it arrives. It takes a `Function<T,R>` as an argument. `Function<T,R>` is a basic functional interface representing a function that accepts an argument of type T and returns a result of type R. See this example below,
|
||||
|
||||
```java
|
||||
// Creating a CompletableFuture
|
||||
CompletableFuture<String> FirstNameFuture = CompletableFuture.supplyAsync(() -> {
|
||||
try {
|
||||
TimeUnit.SECONDS.sleep(3);
|
||||
} catch (InterruptedException e) {
|
||||
throw new IllegalStateException(e);
|
||||
}
|
||||
return "Shaharyar";
|
||||
});
|
||||
// Attaching a callback to the Future using thenApply()
|
||||
CompletableFuture<String> FirstNameFuture = LastNameFuture.thenApply(firstName -> {
|
||||
return firstName + " Lalani";
|
||||
});
|
||||
// Now, Block and get the result of the future.
|
||||
System.out.println(greetingFuture.get()); // Shaharyar Lalani
|
||||
```
|
||||
|
||||
You can also write a **sequence of transformations** on the CompletableFuture by attaching a several thenApply() callback methods. The result of one thenApply() method will be passed to the next in the series,
|
||||
|
||||
```java
|
||||
CompletableFuture<String> Name = CompletableFuture.supplyAsync(() -> {
|
||||
try {
|
||||
TimeUnit.SECONDS.sleep(3);
|
||||
} catch (InterruptedException e) {
|
||||
throw new IllegalStateException(e);
|
||||
}
|
||||
return "Shaharyar";
|
||||
}).thenApply(firstName -> {
|
||||
return firstName + " Lalani";
|
||||
}).thenApply(fullName -> {
|
||||
return fullname + ", is my Full Name";
|
||||
});
|
||||
System.out.println(Name.get());
|
||||
// Prints, Shaharyar Lalani is my Full Name
|
||||
```
|
||||
|
||||
#### `thenAccept()`
|
||||
|
||||
Now, If you do not want to return anything from your callback function and just want to run a piece of code after the Future is executed, you can use `thenAccept()` and `thenRun()` methods. These methods are consumers and are used as the last callback in the callback chain.
|
||||
|
||||
`CompletableFuture.thenAccept()` takes a `Consumer<T>` as argument and returns `CompletableFuture<Void>`.
|
||||
|
||||
```java
|
||||
// thenAccept() demo
|
||||
CompletableFuture.supplyAsync(() -> {
|
||||
return EventBooking.getpricingDetail(eventId);
|
||||
}).thenAccept(event -> {
|
||||
System.out.println("Got the ticket prices of " +
|
||||
event.getName())
|
||||
});
|
||||
```
|
||||
|
||||
#### `thenRun()`
|
||||
|
||||
While thenAccept() has access to CompletableFuture results, thenRun() does not even have access to the results but it also takes a Runnable and returns CompletableFuture<Void>
|
||||
|
||||
// thenRun() demo
|
||||
CompletableFuture.supplyAsync(() -> {
|
||||
// Running the computation
|
||||
}).thenRun(() -> {
|
||||
// Computation done.
|
||||
});
|
||||
|
||||
### Combining two CompletableFutures
|
||||
|
||||
If you want to fetch the data from a remote API service and from using that data, you want to fetch some related information from another service, you can do that using `thenCompose()` method.
|
||||
|
||||
Consider the following implementations of `getEventDetail()` and `getTicketsAvailable()` methods
|
||||
|
||||
```java
|
||||
CompletableFuture<User> getEventDetail(String eventId) {
|
||||
return CompletableFuture.supplyAsync(() -> {
|
||||
return EventBooking.getpricingDetail(eventId);
|
||||
});
|
||||
}
|
||||
CompletableFuture<Double> getTicketsAvailable(Event event) {
|
||||
return CompletableFuture.supplyAsync(() -> {
|
||||
return EventTickets.getTicketsAvailable(event);
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
Now, you can use `thenCompose()` to get the results from combined Futures
|
||||
|
||||
```java
|
||||
CompletableFuture<CompletableFuture<Double>> result = getEventDetail(eventId).thenCompose(event -> getTicketsAvailable(event));
|
||||
```
|
||||
|
||||
In earlier examples, we used `thenApply()` but in this case, it is returning a CompletableFuture. That is why, the final result in the above case is a nested Completable Future we have used `thenCompose()` method for the final result to be the top-level Future*.*
|
||||
|
||||
Similarly, if you want to combine two independent Futures you can use the thenCompose() method for that.
|
||||
|
||||
See Also: [Understanding Memory Management In Java](https://xperti.io/blogs/understanding-memory-management-in-java/)
|
||||
|
||||
## Conclusion
|
||||
|
||||
In this article, we have explored some of the most basic yet very important concepts of CompletableFutureJava API. These examples were just for starters but you can further explore CompletableFuture and features like how to combine more than two Futures or how to handle exceptions in CompletableFuture.
|
||||
@@ -1,293 +0,0 @@
|
||||
---
|
||||
title: Containerized Python Development - Part 1 - Docker Blog
|
||||
source: https://www.docker.com/blog/containerized-python-development-part-1/
|
||||
tags:
|
||||
- IT/Development/Python
|
||||
- IT/Development/Docker
|
||||
---
|
||||
|
||||
Developing Python projects in local environments can get pretty challenging if more than one project is being developed at the same time. Bootstrapping a project may take time as we need to manage versions, set up dependencies and configurations for it. Before, we used to install all project requirements directly in our local environment and then focus on writing the code. But having several projects in progress in the same environment becomes quickly a problem as we may get into configuration or dependency conflicts. Moreover, when sharing a project with teammates we would need to also coordinate our environments. For this we have to define our project environment in such a way that makes it easily shareable.
|
||||
|
||||
A good way to do this is to create isolated development environments for each project. This can be easily done by using containers and Docker Compose to manage them. We cover this in a [series of blog posts](https://www.docker.com/blog/tag/python-env-series/), each one with a specific focus.
|
||||
|
||||
This first part covers how to containerize a Python service/tool and the best practices for it.
|
||||
|
||||
**_Requirements_**
|
||||
|
||||
To easily exercise what we discuss in this [blog post series](https://www.docker.com/blog/tag/python-env-series/), we need to install a minimal set of tools required to manage containerized environments locally:
|
||||
|
||||
* Windows or macOS: [Install Docker Desktop](https://www.docker.com/get-started)
|
||||
* Linux: Install [Docker](https://docs.docker.com/get-docker/) and then [Docker Compose](https://docs.docker.com/compose/install/)
|
||||
|
||||
## **Containerize a Python service**
|
||||
|
||||
We show how to do this with a simple Flask service such that we can run it standalone without needing to set up other components.
|
||||
|
||||
`
|
||||
|
||||
server.py
|
||||
|
||||
from flask import Flask
|
||||
server = Flask(__name__)
|
||||
|
||||
@server.route("/")
|
||||
def hello():
|
||||
return "Hello World!"
|
||||
|
||||
if __name__ == "__main__":
|
||||
server.run()
|
||||
|
||||
|
||||
|
||||
`
|
||||
|
||||
In order to run this program, we need to make sure we have all the required dependencies installed first. One way to manage dependencies is by using a package installer such as pip. For this we need to create a requirements.txt file and write the dependencies in it. An example of such a file for our simple _server.py_ is the following:
|
||||
|
||||
`
|
||||
|
||||
requirements.txt
|
||||
|
||||
Flask==1.1.1
|
||||
|
||||
`
|
||||
|
||||
We have now the following structure:
|
||||
|
||||
`
|
||||
|
||||
app
|
||||
├─── requirements.txt
|
||||
└─── src
|
||||
└─── server.py
|
||||
|
||||
`
|
||||
|
||||
We create a dedicated directory for the source code to isolate it from other configuration files. We will see later why we do this.
|
||||
|
||||
To execute our Python program, all is left to do is to install a Python interpreter and run it.
|
||||
|
||||
We could run this program locally. But, this goes against the purpose of containerizing our development which is to keep a clean standard development environment that allows us to easily switch between projects with different conflicting requirements.
|
||||
|
||||
Let’s have a look next on how we can easily containerize this Python service.
|
||||
|
||||
### **Dockerfile **
|
||||
|
||||
The way to get our Python code running in a container is to pack it as a Docker image and then run a container based on it. The steps are sketched below.
|
||||
|
||||
<img width="730" height="150" src="../../../_resources/mea72NOjQDBRDziu0e_hlYQInsdtMLkn.png"/>
|
||||
|
||||
To generate a Docker image we need to create a Dockerfile which contains instructions needed to build the image. The Dockerfile is then processed by the Docker builder which generates the Docker image. Then, with a simple _docker run_ command, we create and run a container with the Python service.
|
||||
|
||||
#### **Analysis of a Dockerfile**
|
||||
|
||||
An example of a Dockerfile containing instructions for assembling a Docker image for our _hello world_ Python service is the following:
|
||||
|
||||
`
|
||||
|
||||
Dockerfile
|
||||
|
||||
# set base image (host OS)
|
||||
FROM python:3.8
|
||||
|
||||
# set the working directory in the container
|
||||
WORKDIR /code
|
||||
|
||||
# copy the dependencies file to the working directory
|
||||
COPY requirements.txt .
|
||||
|
||||
# install dependencies
|
||||
RUN pip install -r requirements.txt
|
||||
|
||||
# copy the content of the local src directory to the working directory
|
||||
COPY src/ .
|
||||
|
||||
# command to run on container start
|
||||
CMD [ "python", "./server.py" ]
|
||||
|
||||
|
||||
|
||||
`
|
||||
|
||||
For each instruction or command from the Dockerfile, the Docker builder generates an image layer and stacks it upon the previous ones. Therefore, the Docker image resulting from the process is simply a read-only stack of different layers.
|
||||
|
||||
We can also observe in the output of the build command the Dockerfile instructions being executed as steps.
|
||||
|
||||
`
|
||||
|
||||
$ docker build -t myimage .
|
||||
Sending build context to Docker daemon 6.144kB
|
||||
Step 1/6 : FROM python:3.8
|
||||
3.8.3-alpine: Pulling from library/python
|
||||
…
|
||||
Status: Downloaded newer image for python:3.8.3-alpine
|
||||
---> 8ecf5a48c789
|
||||
Step 2/6 : WORKDIR /code
|
||||
---> Running in 9313cd5d834d
|
||||
Removing intermediate container 9313cd5d834d
|
||||
---> c852f099c2f9
|
||||
Step 3/6 : COPY requirements.txt .
|
||||
---> 2c375052ccd6
|
||||
Step 4/6 : RUN pip install -r requirements.txt
|
||||
---> Running in 3ee13f767d05
|
||||
…
|
||||
Removing intermediate container 3ee13f767d05
|
||||
---> 8dd7f46dddf0
|
||||
Step 5/6 : COPY ./src .
|
||||
---> 6ab2d97e4aa1
|
||||
Step 6/6 : CMD python server.py
|
||||
---> Running in fbbbb21349be
|
||||
Removing intermediate container fbbbb21349be
|
||||
---> 27084556702b
|
||||
Successfully built 70a92e92f3b5
|
||||
Successfully tagged myimage:latest
|
||||
|
||||
`
|
||||
|
||||
Then, we can check the image is in the local image store:
|
||||
|
||||
`
|
||||
|
||||
$ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
myimage latest 70a92e92f3b5 8 seconds ago 991MB
|
||||
|
||||
`
|
||||
|
||||
During development, we may need to rebuild the image for our Python service multiple times and we want this to take as little time as possible. We analyze next some best practices that may help us with this.
|
||||
|
||||
### **Development Best Practices for Dockerfiles**
|
||||
|
||||
We focus now on best practices for speeding up the development cycle. For production-focused ones, this [blog post](https://www.docker.com/blog/speed-up-your-development-flow-with-these-dockerfile-best-practices/) and [the docs](https://docs.docker.com/develop/develop-images/dockerfile_best-practices/) cover them in more details.
|
||||
|
||||
#### **Base Image**
|
||||
|
||||
The first instruction from the Dockerfile specifies the base image on which we add new layers for our application. The choice of the base image is pretty important as the features it ships may impact the quality of the layers built on top of it.
|
||||
|
||||
When possible, we should always use official images which are in general frequently updated and may have less security concerns.
|
||||
|
||||
The choice of a base image can impact the size of the final one. If we prefer size over other considerations, we can use some of the base images of a very small size and low overhead. These images are usually based on the _alpine_ distribution and are tagged accordingly. However, for Python applications, the slim variant of the official Docker Python image works well for most cases (eg. python:3.8-slim).
|
||||
|
||||
#### **Instruction order matters for leveraging build cache**
|
||||
|
||||
When building an image frequently, we definitely want to use the builder cache mechanism to speed up subsequent builds. As mentioned previously, the Dockerfile instructions are executed in the order specified. For each instruction, the builder checks first its cache for an image to reuse. When a change in a layer is detected, that layer and all the ones coming after are being rebuilt.
|
||||
|
||||
For an efficient use of the caching mechanism , we need to place the instructions for layers that change frequently after the ones that incur less changes.
|
||||
|
||||
Let’s check our Dockerfile example to understand how the instruction order impacts caching. The interesting lines are the ones below.
|
||||
|
||||
`
|
||||
|
||||
...
|
||||
# copy the dependencies file to the working directory
|
||||
COPY requirements.txt .
|
||||
|
||||
# install dependencies
|
||||
RUN pip install -r requirements.txt
|
||||
|
||||
# copy the content of the local src directory to the working directory
|
||||
COPY src/ .
|
||||
...
|
||||
|
||||
|
||||
|
||||
`
|
||||
|
||||
During development, our application’s dependencies change less frequently than the Python code. Because of this, we choose to install the dependencies in a layer preceding the code one. Therefore we copy the dependencies file and install them and then we copy the source code. This is the main reason why we isolated the source code to a dedicated directory in our project structure.
|
||||
|
||||
#### **Multi-stage builds **
|
||||
|
||||
Although this may not be really useful during development time, we cover it quickly as it is interesting for shipping the containerized Python application once development is done.
|
||||
|
||||
What we seek in using multi-stage builds is to strip the final application image of all unnecessary files and software packages and to deliver only the files needed to run our Python code. A quick example of a multi-stage Dockerfile for our previous example is the following:
|
||||
|
||||
`
|
||||
|
||||
# first stage
|
||||
FROM python:3.8 AS builder
|
||||
COPY requirements.txt .
|
||||
|
||||
# install dependencies to the local user directory (eg. /root/.local)
|
||||
RUN pip install --user -r requirements.txt
|
||||
|
||||
# second unnamed stage
|
||||
FROM python:3.8-slim
|
||||
WORKDIR /code
|
||||
|
||||
# copy only the dependencies installation from the 1st stage image
|
||||
COPY --from=builder /root/.local/bin /root/.local
|
||||
COPY ./src .
|
||||
|
||||
# update PATH environment variable
|
||||
ENV PATH=/root/.local:$PATH
|
||||
|
||||
CMD [ "python", "./server.py" ]
|
||||
|
||||
|
||||
|
||||
`
|
||||
|
||||
Notice that we have a two stage build where we name only the first one as _builder_. We name a stage by adding an _AS <NAME>_ to the _FROM_ instruction and we use this name in the _COPY_ _i_nstruction where we want to copy only the necessary files to the final image.
|
||||
|
||||
The result of this is a slimmer final image for our application:
|
||||
|
||||
`
|
||||
|
||||
$ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
myimage latest 70a92e92f3b5 2 hours ago 991MB
|
||||
multistage latest e598271edefa 6 minutes ago 197MB
|
||||
…
|
||||
|
||||
`
|
||||
|
||||
In this example we relied on the _pip’s –user_ option to install dependencies to the local user directory and copy that directory to the final image. There are however other solutions available such as virtualenv or building packages as wheels and copy and install them to the final image.
|
||||
|
||||
### **Run the container**
|
||||
|
||||
After writing the Dockerfile and building the image from it, we can run the container with our Python service.
|
||||
|
||||
`
|
||||
|
||||
$ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
myimage latest 70a92e92f3b5 2 hours ago 991MB
|
||||
...
|
||||
|
||||
$ docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
|
||||
$ docker run -d -p 5000:5000 myimage
|
||||
befb1477c1c7fc31e8e8bb8459fe05bcbdee2df417ae1d7c1d37f371b6fbf77f
|
||||
|
||||
|
||||
|
||||
`
|
||||
|
||||
We now containerized our _hello world_ server and we can query the port mapped to localhost.
|
||||
|
||||
`
|
||||
|
||||
$ docker ps
|
||||
CONTAINER ID IMAGE COMMAND PORTS ...
|
||||
befb1477c1c7 myimage "/bin/sh -c 'python ..." 0.0.0.0:5000->5000/tcp ...
|
||||
|
||||
$ curl http://localhost:5000
|
||||
"Hello World!"
|
||||
|
||||
|
||||
|
||||
`
|
||||
|
||||
## **What’s next?**
|
||||
|
||||
This post showed how to containerize a Python service for a better development experience. Containerization not only provides deterministic results easily reproducible on other platforms but also avoids dependency conflicts and enables us to keep a clean standard development environment. A containerized development environment is easy to manage and share with other developers as it can be easily deployed without any change to their standard environment.
|
||||
|
||||
In the next post of [this series](https://www.docker.com/blog/tag/python-env-series/), we will show how to set up a container-based multi-service project where the Python component is connected to other external ones and how to manage the lifecycle of all these project components with Docker Compose.
|
||||
|
||||
### **Resources**
|
||||
|
||||
* Best practices for writing Dockerfiles
|
||||
* [https://docs.docker.com/develop/develop-images/dockerfile_best-practices/](https://docs.docker.com/develop/develop-images/dockerfile_best-practices/)
|
||||
* [https://www.docker.com/blog/speed-up-your-development-flow-with-these-dockerfile-best-practices/](https://www.docker.com/blog/speed-up-your-development-flow-with-these-dockerfile-best-practices/)
|
||||
* Docker Desktop
|
||||
* [https://docs.docker.com/desktop/](https://docs.docker.com/desktop/)
|
||||
@@ -1,317 +0,0 @@
|
||||
---
|
||||
title: Containerized Python Development - Part 2 - Docker Blog
|
||||
source: https://www.docker.com/blog/containerized-python-development-part-2/?utm_campaign=IT+Pro&utm_content=1595433308&utm_medium=social&utm_source=Organic
|
||||
tags:
|
||||
- IT/Development/Python
|
||||
- IT/Development/Docker
|
||||
---
|
||||
|
||||
This is the second part of the [blog post series](https://www.docker.com/blog/tag/python-env-series/) on how to containerize our Python development. [In part 1](https://www.docker.com/blog/containerized-python-development-part-1/), we have already shown how to containerize a Python service and the best practices for it. In this part, we discuss how to set up and wire other components to a containerized Python service. We show a good way to organize project files and data and how to manage the overall project configuration with Docker Compose. We also cover the best practices for writing Compose files for speeding up our containerized development process.
|
||||
|
||||
## **Managing Project Configuration with Docker Compose**
|
||||
|
||||
Let’s take as an example an application for which we separate its functionality in three-tiers following a microservice architecture. This is a pretty common architecture for multi-service applications. Our example application consists of:
|
||||
|
||||
* _a UI tier_ – running on an nginx service
|
||||
* _a logic_ tier – the Python component we focus on
|
||||
* _a data_ tier – we use a mysql database to store some data we need in the logic tier
|
||||
|
||||

|
||||
|
||||
The reason for splitting an application into tiers is that we can easily modify or add new ones without having to rework the entire project.
|
||||
|
||||
A good way to structure the project files is to isolate the file and configurations for each service. We can easily do this by having a dedicated directory per service inside the project one. This is very useful to have a clean view of the components and to easily containerize each service. It also helps in manipulating service specific files without having to worry that we could modify by mistake other service files.
|
||||
|
||||
For our example application, we have the following directories:
|
||||
|
||||
Project
|
||||
├─── web
|
||||
└─── app
|
||||
└─── db
|
||||
|
||||
|
||||
We have already covered how to containerize a Python component in the first part of this blog post series. Same applies for the other project components but we skip the details for them as we can easily access samples implementing the structure we discuss here. The [nginx-flask-mysql](https://github.com/docker/awesome-compose/tree/master/nginx-flask-mysql) example provided by the [awesome-compose](https://github.com/docker/awesome-compose) repository is one of them.
|
||||
|
||||
This is the updated Project structure with the Dockerfile in place. Assume we have a similar setup for the web and db components.
|
||||
|
||||
`
|
||||
|
||||
Project
|
||||
├─── web
|
||||
├─── app
|
||||
│ ├─── Dockerfile
|
||||
│ ├─── requirements.txt
|
||||
│ └─── src
|
||||
│ └─── server.py
|
||||
└─── db
|
||||
|
||||
`
|
||||
|
||||
We could now start the containers manually for all our containerized project components. However, to make them communicate we have to manually handle the network creation and attach the containers to it. This is fairly complicated and it would take precious development time if we need to do it frequently.
|
||||
|
||||
Here is where _Docker Compose_ offers a very easy way of coordinating containers and spinning up and taking down services in our local environment. For this, all we need to do is write a Compose file containing the configuration for our project’s services. Once we have it, we can get the project running with a single command.
|
||||
|
||||
## **Compose file**
|
||||
|
||||
Let’s see what is the structure of the Compose files and how we can manage the project services with it.
|
||||
|
||||
Below is a sample file for our project. As you can see we define a list of services. In the db section we specify the base image directly as we don’t have any particular configuration to apply to it. Meanwhile our web and app service are going to have the image built from their Dockerfiles. According to where we can get the service image we can either set the build or the image field. The build field requires a path with a Dockerfile inside.
|
||||
|
||||
`
|
||||
|
||||
docker-compose.yaml
|
||||
|
||||
version: "3.7"
|
||||
services:
|
||||
db:
|
||||
image: mysql:8.0.19
|
||||
command: '--default-authentication-plugin=mysql_native_password'
|
||||
restart: always
|
||||
environment:
|
||||
- MYSQL_DATABASE=example
|
||||
- MYSQL_ROOT_PASSWORD=password
|
||||
|
||||
app:
|
||||
build: app
|
||||
restart: always
|
||||
|
||||
web:
|
||||
build: web
|
||||
restart: always
|
||||
ports:
|
||||
- 80:80
|
||||
|
||||
|
||||
|
||||
`
|
||||
|
||||
To initialize the database we can pass environment variables with the DB name and password while for our web service we map the container port to the localhost in order to be able to access the web interface of our project.
|
||||
|
||||
Let’s see how to deploy the project with Docker Compose.
|
||||
|
||||
All we need to do now is to place the docker-compose.yaml at the root directory of the project and then issue the command for deployment with docker-compose.
|
||||
|
||||
`
|
||||
|
||||
Project
|
||||
├─── docker-compose.yaml
|
||||
├─── web
|
||||
├─── app
|
||||
└─── db
|
||||
|
||||
`
|
||||
|
||||
_Docker Compose_ is going to take care of pulling the mysql image from Docker Hub and launching the _db_ container while for our _web_ and _app_ service, it builds the images locally and then runs the containers from them. It also takes care of creating a default network and placing all containers in it so that they can reach each other.
|
||||
|
||||

|
||||
|
||||
All this is triggered with only one command.
|
||||
|
||||
``
|
||||
|
||||
$ docker-compose up -d
|
||||
Creating network "project_default" with the default driver
|
||||
Pulling db (mysql:8.0.19)…
|
||||
…
|
||||
Status: Downloaded newer image for mysql:8.0.19
|
||||
Building app
|
||||
Step 1/6 : FROM python:3.8
|
||||
---> 7f5b6ccd03e9
|
||||
Step 2/6 : WORKDIR /code
|
||||
---> Using cache
|
||||
---> c347603a917d
|
||||
Step 3/6 : COPY requirements.txt .
|
||||
---> fa9a504e43ac
|
||||
Step 4/6 : RUN pip install -r requirements.txt
|
||||
---> Running in f0e93a88adb1
|
||||
Collecting Flask==1.1.1
|
||||
…
|
||||
Successfully tagged project_app:latest
|
||||
WARNING: Image for service app was built because it did not already exist. To rebuild this image you must use `docker-compose build` or `docker-compose up --build`.
|
||||
Building web
|
||||
Step 1/3 : FROM nginx:1.13-alpine
|
||||
1.13-alpine: Pulling from library/nginx
|
||||
…
|
||||
Status: Downloaded newer image for nginx:1.13-alpine
|
||||
---> ebe2c7c61055
|
||||
Step 2/3 : COPY nginx.conf /etc/nginx/nginx.conf
|
||||
---> a3b2a7c8853c
|
||||
Step 3/3 : COPY index.html /usr/share/nginx/html/index.html
|
||||
---> 9a0713a65fd6
|
||||
Successfully built 9a0713a65fd6
|
||||
Successfully tagged project_web:latest
|
||||
|
||||
Creating project_web_1 … done
|
||||
Creating project_db_1 … done
|
||||
Creating project_app_1 … done
|
||||
|
||||
|
||||
|
||||
``
|
||||
|
||||
Check the running containers:
|
||||
|
||||
`
|
||||
|
||||
$ docker-compose ps
|
||||
Name Command State Ports
|
||||
-------------------------------------------------------------------------
|
||||
project_app_1 /bin/sh -c python server.py Up
|
||||
project_db_1 docker-entrypoint.sh --def ... Up 3306/tcp, 33060/tcp
|
||||
project_web_1 nginx -g daemon off; Up 0.0.0.0:80->80/tcp
|
||||
|
||||
`
|
||||
|
||||
To stop and remove all project containers run:
|
||||
|
||||
`
|
||||
|
||||
$ docker-compose down
|
||||
Stopping project_db_1 ... done
|
||||
Stopping project_web_1 ... done
|
||||
Stopping project_app_1 ... done
|
||||
Removing project_db_1 ... done
|
||||
Removing project_web_1 ... done
|
||||
Removing project_app_1 ... done
|
||||
Removing network project-default
|
||||
|
||||
`
|
||||
|
||||
To rebuild images we can run a build and then an up command to update the state of the project containers:
|
||||
|
||||
`
|
||||
|
||||
$ docker-compose build
|
||||
$ docker-compose up -d
|
||||
|
||||
`
|
||||
|
||||
As we can see, it is quite easy to manage the lifecycle of the project containers with docker-compose.
|
||||
|
||||
## **Best practices for writing Compose files**
|
||||
|
||||
Let us analyse the Compose file and see how we can optimise it by following best practices for writing Compose files.
|
||||
|
||||
### **Network separation**
|
||||
|
||||
When we have several containers we need to control how to wire them together. We need to keep in mind that, as we do not set any network in the compose file, all our containers will end in the same default network.
|
||||
|
||||
<img width="730" height="305" src="../../../_resources/uyjo2BW7IeNeQSh5Xx7oUYmcMMlqTtLS.png"/>
|
||||
|
||||
This may not be a good thing if we want only our Python service to be able to reach the database. To address this issue, in the compose file we can actually define separate networks for each pair of components. In this case the web component won’t be able to access the DB.
|
||||
|
||||
<img width="730" height="360" src="../../../_resources/cPoEv3XxPg1I6sccKC6nfBLsHjxGWGAw.png"/>
|
||||
|
||||
### **Docker Volumes**
|
||||
|
||||
Every time we take down our containers, we remove them and therefore lose the data we stored in previous sessions. To avoid that and persist DB data between different containers, we can exploit named volumes. For this, we simply define a named volume in the Compose file and specify a mount point for it in the db service as shown below:
|
||||
|
||||
`
|
||||
|
||||
version: "3.7"
|
||||
services:
|
||||
db:
|
||||
image: mysql:8.0.19
|
||||
command: '--default-authentication-plugin=mysql_native_password'
|
||||
restart: always
|
||||
volumes:
|
||||
- db-data:/var/lib/mysql
|
||||
networks:
|
||||
- backend-network
|
||||
environment:
|
||||
- MYSQL_DATABASE=example
|
||||
- MYSQL_ROOT_PASSWORD=password
|
||||
|
||||
app:
|
||||
build: app
|
||||
restart: always
|
||||
networks:
|
||||
- backend-network
|
||||
- frontend-network
|
||||
|
||||
web:
|
||||
build: web
|
||||
restart: always
|
||||
ports:
|
||||
- 80:80
|
||||
networks:
|
||||
- frontend-network
|
||||
volumes:
|
||||
db-data:
|
||||
networks:
|
||||
backend-network:
|
||||
frontend-network:
|
||||
|
||||
|
||||
|
||||
`
|
||||
|
||||
We can explicitly remove the named volumes on docker-compose down if we want.
|
||||
|
||||
### **Docker Secrets**
|
||||
|
||||
As we can observe in the Compose file, we set the `db` password in plain text. To avoid this, we can exploit docker secrets to have the password stored and share it securely with the services that need it. We can define secrets and reference them in services as below. The password is being stored locally in the `project/db/password.txt` file and mounted in the containers under `/run/secrets/<secret-name>`_._
|
||||
|
||||
`
|
||||
|
||||
version: "3.7"
|
||||
services:
|
||||
db:
|
||||
image: mysql:8.0.19
|
||||
command: '--default-authentication-plugin=mysql_native_password'
|
||||
restart: always
|
||||
secrets:
|
||||
- db-password
|
||||
volumes:
|
||||
- db-data:/var/lib/mysql
|
||||
networks:
|
||||
- backend-network
|
||||
environment:
|
||||
- MYSQL_DATABASE=example
|
||||
- MYSQL_ROOT_PASSWORD_FILE=/run/secrets/db-password
|
||||
|
||||
app:
|
||||
build: app
|
||||
restart: always
|
||||
secrets:
|
||||
- db-password
|
||||
networks:
|
||||
- backend-network
|
||||
- frontend-network
|
||||
|
||||
web:
|
||||
build: web
|
||||
restart: always
|
||||
ports:
|
||||
- 80:80
|
||||
networks:
|
||||
- frontend-network
|
||||
volumes:
|
||||
db-data:
|
||||
secrets:
|
||||
db-password:
|
||||
file: db/password.txt
|
||||
networks:
|
||||
backend-network:
|
||||
frontend-network:
|
||||
|
||||
|
||||
|
||||
`
|
||||
|
||||
We have now a well defined Compose file for our project that follows best practices. An example application exercising all the aspects we discussed can be found [here](https://github.com/aiordache/demos/tree/master/dockercon2020-demo).
|
||||
|
||||
## **What’s next?**
|
||||
|
||||
This blog post showed how to set up a container-based multi-service project where a Python service is wired to other services and how to deploy it locally with Docker Compose.
|
||||
|
||||
In the next and final part of [this series](https://www.docker.com/blog/tag/python-env-series/), we show how to update and debug the containerized Python component.
|
||||
|
||||
## **Resources**
|
||||
|
||||
* Project sample
|
||||
* [https://github.com/aiordache/demos/tree/master/dockercon2020-demo](https://github.com/aiordache/demos/tree/master/dockercon2020-demo)
|
||||
* Docker Compose
|
||||
* [https://docs.docker.com/compose/](https://docs.docker.com/compose/)
|
||||
* Project skeleton samples
|
||||
* [https://github.com/docker/awesome-compose](https://github.com/docker/awesome-compose)
|
||||
@@ -1,193 +0,0 @@
|
||||
---
|
||||
title: Containerized Python Development - Part 3 - Docker Blog
|
||||
source: https://www.docker.com/blog/containerized-python-development-part-3/
|
||||
---
|
||||
|
||||
This is the last part in the [series of blog posts](https://www.docker.com/blog/tag/python-env-series/) showing how to set up and optimize a containerized Python development environment. The [first part](https://www.docker.com/blog/containerized-python-development-part-1/) covered how to containerize a Python service and the best development practices for it. The [second part](https://www.docker.com/blog/containerized-python-development-part-2/) showed how to easily set up different components that our Python application needs and how to easily manage the lifecycle of the overall project with Docker Compose.
|
||||
|
||||
In this final part, we review the development cycle of the project and discuss in more details how to apply code updates and debug failures of the containerized Python services. The goal is to analyze how to speed up these recurrent phases of the development process such that we get a similar experience to the local development one.
|
||||
|
||||
## **Applying Code Updates**
|
||||
|
||||
In general, our containerized development cycle consists of writing/updating code, building, running and debugging it.
|
||||
|
||||

|
||||
|
||||
For the building and running phase, as most of the time we actually have to wait, we want these phases to go pretty quick such that we focus on coding and debugging.
|
||||
|
||||
We now analyze how to optimize the build phase during development. The build phase corresponds to image build time when we change the Python source code. The image needs to be rebuilt in order to get the Python code updates in the container before launching it.
|
||||
|
||||
We can however apply code changes without having to build the image. We can do this simply by bind-mounting the local source directory to its path in the container. For this, we update the compose file as follows:
|
||||
|
||||
`
|
||||
|
||||
docker-compose.yaml
|
||||
```yaml
|
||||
app:
|
||||
build: app
|
||||
restart: always
|
||||
volumes:
|
||||
- ./app/src:/code
|
||||
```
|
||||
|
||||
`
|
||||
|
||||
With this, we have direct access to the updated code and therefore we can skip the image build and restart the container to reload the Python process.
|
||||
|
||||

|
||||
|
||||
Furthermore, we can avoid re-starting the container if we run inside it a reloader process that watches for file changes and triggers the restart of the Python process once a change is detected. We need to make sure we have bind-mounted the source code in the Compose file as described previously.
|
||||
|
||||
In our example, we use the Flask framework that, in debugging mode, runs a very convenient module called the reloader. The reloader watches all the source code files and automatically restarts the server when detects that a file has changed. To enable the debug mode we only need to set the debug parameter as below:
|
||||
|
||||
`
|
||||
server.py
|
||||
```python
|
||||
server.run(debug=True, host='0.0.0.0', port=5000)
|
||||
```
|
||||
|
||||
`
|
||||
|
||||
If we check the logs of the _app_ container we see that the flask server is running in debugging mode.
|
||||
|
||||
`
|
||||
|
||||
$ docker-compose logs app
|
||||
Attaching to project_app_1
|
||||
app_1 | * Serving Flask app "server" (lazy loading)
|
||||
app_1 | * Environment: production
|
||||
app_1 | WARNING: This is a development server. Do not use it in a production deployment.
|
||||
app_1 | Use a production WSGI server instead.
|
||||
app_1 | * Debug mode: on
|
||||
app_1 | * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
|
||||
app_1 | * Restarting with stat
|
||||
app_1 | * Debugger is active!
|
||||
app_1 | * Debugger PIN: 315-974-099
|
||||
|
||||
|
||||
`
|
||||
|
||||
Once we update the source code and save, we should see the notification in the logs and reload.
|
||||
|
||||
`
|
||||
|
||||
$ docker-compose logs app
|
||||
Attaching to project_app_1
|
||||
app_1 | * Serving Flask app "server" (lazy loading)
|
||||
...
|
||||
app_1 | * Debugger PIN: 315-974-099
|
||||
app_1 | * Detected change in '/code/server.py', reloading
|
||||
app_1 | * Restarting with stat
|
||||
app_1 | * Debugger is active!
|
||||
app_1 | * Debugger PIN: 315-974-099
|
||||
|
||||
`
|
||||
|
||||
## **Debugging Code**
|
||||
|
||||
We can debug code in mostly two ways.
|
||||
|
||||
First is the old fashioned way of placing print statements all over the code for checking runtime value of objects/variables. Applying this to containerized processes is quite straightforward and we can easily check the output with a _docker-compose logs_ command.
|
||||
|
||||
Second, and the more serious approach is by using a debugger. When we have a containerized process, we need to run a debugger inside the container and then connect to that remote debugger to be able to inspect the instance data.
|
||||
|
||||
We take as an example again our Flask application. When running in debug mode, aside from the reloader module it also includes an interactive debugger. Assume we update the code to raise an exception, the Flask service will return a detailed response with the exception.
|
||||
|
||||

|
||||
|
||||
Another interesting case to exercise is the interactive debugging where we place breakpoints in the code and do a live inspect. For this we need an IDE with Python and remote debugging support. If we choose to rely on Visual Studio Code to show how to debug Python code running in containers we need to do the following to connect to the remote debugger directly from VSCode.
|
||||
|
||||
First, we need to map locally the port we use to connect to the debugger. We can easily do this by adding the port mapping to the Compose file:
|
||||
|
||||
`
|
||||
|
||||
docker-compose.yaml
|
||||
```yaml
|
||||
app:
|
||||
build: app
|
||||
restart: always
|
||||
volumes:
|
||||
- ./app/src:/code
|
||||
ports:
|
||||
- 5678:5678
|
||||
```
|
||||
|
||||
|
||||
`
|
||||
|
||||
Next, we need to import the debugger module in the source code and make it listen on the port we defined in the Compose file. We should not forget to add it to the dependencies file also and rebuild the image for the app service to get the debugger package installed. For this exercise, we choose to use the _ptvsd_ debugger package that VS Code supports.
|
||||
|
||||
`
|
||||
|
||||
server.py
|
||||
```python
|
||||
import ptvsd
|
||||
ptvsd.enable_attach(address=('0.0.0.0', 5678))
|
||||
```
|
||||
|
||||
|
||||
``
|
||||
|
||||
requirements.txt
|
||||
```txt
|
||||
Flask==1.1.1
|
||||
mysql-connector==2.2.9
|
||||
|
||||
ptvsd==4.3.2
|
||||
```
|
||||
|
||||
|
||||
|
||||
`
|
||||
|
||||
We need to remember that for changes we make in the Compose file, we need to run a compose down command to remove the current containers setup and then run a docker-compose up to redeploy with the new configurations in the compose file.
|
||||
|
||||
Finally, we need to create a ‘Remote Attach’ configuration in VS Code to launch the debugging mode.
|
||||
|
||||

|
||||
|
||||
The _launch.json_ for our project should look like:
|
||||
```json
|
||||
{
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Python: Remote Attach",
|
||||
"type": "python",
|
||||
"request": "attach",
|
||||
"port": 5678,
|
||||
"host": "localhost",
|
||||
"pathMappings": [
|
||||
{
|
||||
"localRoot": "${workspaceFolder}/app/src",
|
||||
"remoteRoot": "/code"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
`
|
||||
|
||||
We need to make sure we update the path map locally and in the container.
|
||||
|
||||
Once we do this, we can easily place breakpoints in the IDE, start the debugging mode based on the configuration we created and, finally, trigger the code to reach the breakpoint.
|
||||
|
||||
## **Conclusion**
|
||||
|
||||
This [series of blog posts](https://www.docker.com/blog/tag/python-env-series/) showed how to quickly set up a containerized Python development environment, manage project lifecycle and apply code updates and debug containerized Python services. Putting in practice all we discussed should make the containerized development experience identical to the local one.
|
||||
|
||||
### **Resources**
|
||||
|
||||
* Project sample
|
||||
* [https://github.com/aiordache/demos/tree/master/dockercon2020-demo](https://github.com/aiordache/demos/tree/master/dockercon2020-demo)
|
||||
* Best practices for writing Dockerfiles
|
||||
* [https://docs.docker.com/develop/develop-images/dockerfile_best-practices/](https://docs.docker.com/develop/develop-images/dockerfile_best-practices/)
|
||||
* [https://www.docker.com/blog/speed-up-your-development-flow-with-these-dockerfile-best-practices/](https://www.docker.com/blog/speed-up-your-development-flow-with-these-dockerfile-best-practices/)
|
||||
* Docker Desktop
|
||||
* [https://docs.docker.com/desktop/](https://docs.docker.com/desktop/)
|
||||
* Docker Compose
|
||||
* [https://docs.docker.com/compose/](https://docs.docker.com/compose/)
|
||||
* Project skeleton samples
|
||||
* [https://github.com/docker/awesome-compose](https://github.com/docker/awesome-compose)
|
||||
@@ -1,35 +0,0 @@
|
||||
---
|
||||
title: Conveniently Processing Large XML Files with Java
|
||||
source: https://dzone.com/articles/conveniently-processing-large
|
||||
tags:
|
||||
- IT/Development/Java
|
||||
- IT/Development/XML
|
||||
---
|
||||
|
||||
Join the DZone community and get the full member experience.
|
||||
|
||||
When processing XML data it's usually most convenient to load the whole document using a **DOM** parser and fire some **XPath**-queries against the result. However, since we're building a multi-tenant eCommerce plattform we regularly have to handle large XML files, with file sizes above 1 GB. You certainly don't want to load such a beast into the heap of a production server, since it easily grows up to 3GB+ as DOM representation.
|
||||
|
||||
So what to do? Well, **SAX** to the rescue! Processing a large XML file using a SAX parser still requires constant (low) memory, since it only invokes callback for detected XML tokens. But, on the other hand, parsing complex XML really becomes a mess.
|
||||
|
||||
To resolve this problem we need to have a closer look at our XML input data. Most of the time, at least in our cases, you don't need the whole DOM at once. Say your importing product informations, it sufficient to look at one product at a time. Example:
|
||||
|
||||
When processing Node 1, we don't need access to any attribute of Node 2 or three, respectively when processing Node 2, we don't need access to Node 1 or 3, and so on. So what we want is a partial DOM, in our example for every `<node>`.
|
||||
|
||||
What we've therefore built is a SAX parser, for which you can specify in which XML elements you are interested. Once such an element starts, we record the whole sub-tree. When this completes we notify a handler which then can run XPath expressions against this partial DOM. After that, the DOM is released and the SAX parser continues.
|
||||
|
||||
Here is a shortened example of how you could parse the XML above - one "`<node>`" at a time:
|
||||
|
||||
The full example, along with the implementation is open source (MIT-License) and available here:
|
||||
|
||||
https://github.com/andyHa/scireumOpen/tree/master/src/com/scireum/open/xml
|
||||
|
||||
https://github.com/andyHa/scireumOpen/blob/master/src/examples/ExampleXML.java
|
||||
|
||||
We successfully handle up to five parallel imports of 1GB+ XML files in our production system, without measurable heap growth. (Instead of using a FileInputStream, we use JAVAs ZIP capabilities and directly open and process ZIP versions of the XML file. This shrinks those monsters down to 20-50MB and makes uploads etc. much easier.)
|
||||
|
||||
Topics:
|
||||
|
||||
java, xml, bmecat
|
||||
|
||||
Opinions expressed by DZone contributors are their own.
|
||||
@@ -1,6 +0,0 @@
|
||||
---
|
||||
title: Converting Gradle convention plugins to binary plugins | Harsh Shandilya
|
||||
source: https://msfjarvis.dev/posts/converting-gradle-convention-plugins-to-binary-plugins/
|
||||
---
|
||||
|
||||
https://msfjarvis.dev/posts/converting-gradle-convention-plugins-to-binary-plugins/
|
||||
@@ -1,903 +0,0 @@
|
||||
---
|
||||
title: Create GnuPG key with sub-keys to sign, encrypt, authenticate - Experiencing Technology
|
||||
source: https://blog.tinned-software.net/create-gnupg-key-with-sub-keys-to-sign-encrypt-authenticate/
|
||||
---
|
||||
|
||||
## [Create GnuPG key with sub-keys to sign, encrypt, authenticate](https://blog.tinned-software.net/create-gnupg-key-with-sub-keys-to-sign-encrypt-authenticate/)
|
||||
|
||||
In order to use a GnuPG key on a smartcard or Yubikey, a GnuPG key needs to be created. This post will show you how to create a GnuPG key with sub-keys for signing, encryption and authentication. The authentication key can be used later on to authenticate via ssh as well.
|
||||
|
||||
## Configure GnuPG
|
||||
|
||||
Before the key can be generated, first you need to configure GnuPG. The following settings are suggested before creating the key. The settings contain the documentation from the official GnuPG documentation. Add these settings to the “gpg.conf” file located in the GnuPG home directory. This is either the “~/.gnupg/” or the directory specified in the “–homedir” parameter.
|
||||
|
||||
################################################################################
|
||||
\# GnuPG Options
|
||||
|
||||
\# (OpenPGP-Configuration-Options)
|
||||
\# Assume that command line arguments are given as UTF8 strings.
|
||||
utf8-strings
|
||||
|
||||
\# (OpenPGP-Protocol-Options)
|
||||
\# Set the list of personal digest/cipher/compression preferences. This allows
|
||||
\# the user to safely override the algorithm chosen by the recipient key
|
||||
\# preferences, as GPG will only select an algorithm that is usable by all
|
||||
\# recipients.
|
||||
personal-digest-preferences SHA512 SHA384 SHA256 SHA224
|
||||
personal-cipher-preferences AES256 AES192 AES CAST5 CAMELLIA192 BLOWFISH TWOFISH CAMELLIA128 3DES
|
||||
personal-compress-preferences ZLIB BZIP2 ZIP
|
||||
|
||||
\# Set the list of default preferences to string. This preference list is used
|
||||
\# for new keys and becomes the default for "setpref" in the edit menu.
|
||||
default-preference-list SHA512 SHA384 SHA256 SHA224 AES256 AES192 AES CAST5 ZLIB BZIP2 ZIP Uncompressed
|
||||
|
||||
\# (OpenPGP-Esoteric-Options)
|
||||
\# Use name as the message digest algorithm used when signing a key. Running the
|
||||
\# program with the command --version yields a list of supported algorithms. Be
|
||||
\# aware that if you choose an algorithm that GnuPG supports but other OpenPGP
|
||||
\# implementations do not, then some users will not be able to use the key
|
||||
\# signatures you make, or quite possibly your entire key.
|
||||
\#
|
||||
\# SHA-1 is the only algorithm specified for OpenPGP V4. By changing the
|
||||
\# cert-digest-algo, the OpenPGP V4 specification is not met but with even
|
||||
\# GnuPG 1.4.10 (release 2009) supporting SHA-2 algorithm, this should be safe.
|
||||
\# Source: https://tools.ietf.org/html/rfc4880#section-12.2
|
||||
cert-digest-algo SHA512
|
||||
digest-algo SHA256
|
||||
|
||||
\# Selects how passphrases for symmetric encryption are mangled. 3 (the default)
|
||||
\# iterates the whole process a number of times (see --s2k-count).
|
||||
s2k-mode 3
|
||||
|
||||
\# (OpenPGP-Protocol-Options)
|
||||
\# Use name as the cipher algorithm for symmetric encryption with a passphrase
|
||||
\# if --personal-cipher-preferences and --cipher-algo are not given. The
|
||||
\# default is AES-128.
|
||||
s2k-cipher-algo AES256
|
||||
|
||||
\# (OpenPGP-Protocol-Options)
|
||||
\# Use name as the digest algorithm used to mangle the passphrases for symmetric
|
||||
\# encryption. The default is SHA-1.
|
||||
s2k-digest-algo SHA512
|
||||
|
||||
\# (OpenPGP-Protocol-Options)
|
||||
\# Specify how many times the passphrases mangling for symmetric encryption is
|
||||
\# repeated. This value may range between 1024 and 65011712 inclusive. The
|
||||
\# default is inquired from gpg-agent. Note that not all values in the
|
||||
\# 1024-65011712 range are legal and if an illegal value is selected, GnuPG will
|
||||
\# round up to the nearest legal value. This option is only meaningful if
|
||||
\# --s2k-mode is set to the default of 3.
|
||||
s2k-count 1015808
|
||||
|
||||
################################################################################
|
||||
\# GnuPG View Options
|
||||
|
||||
\# Select how to display key IDs. "long" is the more accurate (but less
|
||||
\# convenient) 16-character key ID. Add an "0x" to include an "0x" at the
|
||||
\# beginning of the key ID.
|
||||
keyid-format 0xlong
|
||||
|
||||
\# List all keys with their fingerprints. This is the same output as --list-keys
|
||||
\# but with the additional output of a line with the fingerprint. If this
|
||||
\# command is given twice, the fingerprints of all secondary keys are listed too.
|
||||
with-fingerprint
|
||||
with-fingerprint
|
||||
|
||||
The “cert-digest-algo” and “digest-algo” also contain a personal explanation why these settings where chosen even if they are supposed to break the OpenPGP specification.
|
||||
|
||||
The last settings in the above example are options influencing the way the keys are shown in the output of GnuPG. It is widely suggested to use the long keyid format to identify the keys. The keyid is a short representation of the fingerprint. The long format takes the last 16 (instead of 8 in the short format) characters from the fingerprint. To be really sure to have the correct key, the fingerprint is the information to use instead of any shortened version of it.
|
||||
|
||||
## Generate a master-key
|
||||
|
||||
With the configuration in place, the master key can be created. The master key will only have the capability “Certify” and is only needed when the key is modified.
|
||||
|
||||
When OpenPGP 2.x is used, the program itself is called “gpg2” in many distributions but also the option to generate the key has changed to “–full-gen-key”. If the option “–gen-key” is used with gpg2, many settings described in this example can not be selected.
|
||||
|
||||
$ gpg --homedir ./gnupg-test --expert --gen-key
|
||||
gpg (GnuPG) 1.4.20; Copyright (C) 2015 Free Software Foundation, Inc.
|
||||
This is free software: you are free to change and redistribute it.
|
||||
There is NO WARRANTY, to the extent permitted by law.
|
||||
|
||||
Please select what kind of key you want:
|
||||
(1) RSA and RSA (default)
|
||||
(2) DSA and Elgamal
|
||||
(3) DSA (sign only)
|
||||
(4) RSA (sign only)
|
||||
(7) DSA (set your own capabilities)
|
||||
(8) RSA (set your own capabilities)
|
||||
Your selection? **8**
|
||||
|
||||
Possible actions for a RSA key: Sign Certify Encrypt Authenticate
|
||||
Current allowed actions: Sign Certify Encrypt
|
||||
|
||||
(S) Toggle the sign capability
|
||||
(E) Toggle the encrypt capability
|
||||
(A) Toggle the authenticate capability
|
||||
(Q) Finished
|
||||
|
||||
Your selection? **S**
|
||||
|
||||
Possible actions for a RSA key: Sign Certify Encrypt Authenticate
|
||||
Current allowed actions: Certify Encrypt
|
||||
|
||||
(S) Toggle the sign capability
|
||||
(E) Toggle the encrypt capability
|
||||
(A) Toggle the authenticate capability
|
||||
(Q) Finished
|
||||
|
||||
Your selection? **E**
|
||||
|
||||
Possible actions for a RSA key: Sign Certify Encrypt Authenticate
|
||||
Current allowed actions: Certify
|
||||
|
||||
(S) Toggle the sign capability
|
||||
(E) Toggle the encrypt capability
|
||||
(A) Toggle the authenticate capability
|
||||
(Q) Finished
|
||||
|
||||
Your selection? **Q**
|
||||
RSA keys may be between 1024 and 4096 bits long.
|
||||
What keysize do you want? (2048) **4096**
|
||||
Requested keysize is 4096 bits
|
||||
Please specify how long the key should be valid.
|
||||
0 = key does not expire
|
||||
<n> = key expires in n days
|
||||
<n>w = key expires in n weeks
|
||||
<n>m = key expires in n months
|
||||
<n>y = key expires in n years
|
||||
Key is valid for? (0) **2y**
|
||||
Key expires at Fri 30 Nov 2018 10:44:14 PM CET
|
||||
Is this correct? (y/N) **Y**
|
||||
|
||||
You need a user ID to identify your key; the software constructs the user ID
|
||||
from the Real Name, Comment and Email Address in this form:
|
||||
"Heinrich Heine (Der Dichter) <heinrichh@duesseldorf.de>"
|
||||
|
||||
Real name: **Alice**
|
||||
Email address: **alice@example.com**
|
||||
Comment:
|
||||
You selected this USER-ID:
|
||||
"Alice <alice@example.com>"
|
||||
|
||||
Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? **O**
|
||||
You need a Passphrase to protect your secret key.
|
||||
|
||||
Enter passphrase: **YourPassword**
|
||||
Repeat passphrase: **YourPassword**
|
||||
|
||||
We need to generate a lot of random bytes. It is a good idea to perform
|
||||
some other action (type on the keyboard, move the mouse, utilize the
|
||||
disks) during the prime generation; this gives the random number
|
||||
generator a better chance to gain enough entropy.
|
||||
.+++++
|
||||
...................+++++
|
||||
gpg: key 0xD93D03C13478D580 marked as ultimately trusted
|
||||
public and secret key created and signed.
|
||||
|
||||
gpg: checking the trustdb
|
||||
gpg: 3 marginal(s) needed, 1 complete(s) needed, PGP trust model
|
||||
gpg: depth: 0 valid: 1 signed: 0 trust: 0-, 0q, 0n, 0m, 0f, 1u
|
||||
gpg: next trustdb check due at 2018-11-30
|
||||
pub 4096R/0xD93D03C13478D580 2016-11-30 \[expires: 2018-11-30\]
|
||||
Key fingerprint = F8C8 1342 2A7F 7A3A 9027 E158 D93D 03C1 3478 D580
|
||||
uid Alice <alice@example.com>
|
||||
|
||||
The above will generate a 4096 bit key which will be used as a master key. The parameter “–homedir ./gnupg-test/” defines the directory used for the keyring to be generated. This is the directory where the previously created gpg.conf file should be located.
|
||||
|
||||
I suggest to use a removable storage like a USB-Stick to store the master-key on. The master key is not used in every day operation and should be stored in a safe place.
|
||||
|
||||
Generating the random data needed for the key generation might take a long time. To speed up the process, use the [rngd(8)](https://linux.die.net/man/8/rngd) to feed random data into the random number pool of the kernel. This can be done by installing the **rng-tools** package.
|
||||
|
||||
\# Debian / Ubuntu
|
||||
$ sudo apt-get install rng-tools
|
||||
|
||||
\# RedHat / CentOS
|
||||
$ yum install rng-tools
|
||||
|
||||
To verify the generated keys, execute the following command.
|
||||
|
||||
$ gpg --homedir ./gnupg-test -K
|
||||
./gnupg-test/secring.gpg
|
||||
\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-
|
||||
sec 4096R/0xD93D03C13478D580 2016-11-30 \[expires: 2018-11-30\]
|
||||
Key fingerprint = F8C8 1342 2A7F 7A3A 9027 E158 D93D 03C1 3478 D580
|
||||
uid Alice <alice@example.com>
|
||||
|
||||
According to the view options in the gpg.conf configuration file, the output shows the long keyid format as well as the fingerprint of each key or subkey.
|
||||
|
||||
## Set key preferences
|
||||
|
||||
To ensure that only strong algorithms are used, set the preferences for the key using the “setpref” command.
|
||||
|
||||
$ gpg --homedir ./gnupg-test --expert --edit-key 0xD93D03C13478D580
|
||||
gpg (GnuPG) 1.4.20; Copyright (C) 2015 Free Software Foundation, Inc.
|
||||
This is free software: you are free to change and redistribute it.
|
||||
There is NO WARRANTY, to the extent permitted by law.
|
||||
|
||||
Secret key is available.
|
||||
|
||||
pub 4096R/0xD93D03C13478D580 created: 2016-11-30 expires: 2018-11-30 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
\[ultimate\] (1). Alice <alice@example.com>
|
||||
|
||||
gpg> **setpref SHA512 SHA384 SHA256 SHA224 AES256 AES192 AES CAST5 ZLIB BZIP2 ZIP Uncompressed**
|
||||
Set preference list to:
|
||||
Cipher: AES256, AES192, AES, CAST5, 3DES
|
||||
Digest: SHA512, SHA384, SHA256, SHA224, SHA1
|
||||
Compression: ZLIB, BZIP2, ZIP, Uncompressed
|
||||
Features: MDC, Keyserver no-modify
|
||||
Really update the preferences? (y/N) **Y**
|
||||
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "Alice <alice@example.com>"
|
||||
4096-bit RSA key, ID 0xD93D03C13478D580, created 2016-11-30
|
||||
|
||||
Enter passphrase: **YourPassword**
|
||||
|
||||
pub 4096R/0xD93D03C13478D580 created: 2016-11-30 expires: 2018-11-30 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
\[ultimate\] (1). Alice <alice@example.com>
|
||||
|
||||
gpg> **save**
|
||||
|
||||
## Generate the sub-keys
|
||||
|
||||
Before starting to generate the different sub-keys, verify the maximum size of keys the smartcard can store. The Yubikey NEO can store keys up to 2048 bits while the Yubikey 4 can store keys up to 4096 bits. Smartcards usually support different sizes as well like 2048, 3072 or 4096 bits.
|
||||
|
||||
To add a subkey, the master-key needs to be opened for editing. The following command will open the key specified (in the following example via key ID) for editing. To be able to create all the different key types, the “–expert” option is used.
|
||||
|
||||
$ gpg --homedir ./gnupg-test --expert --edit-key 0xD93D03C13478D580
|
||||
gpg (GnuPG) 1.4.20; Copyright (C) 2015 Free Software Foundation, Inc.
|
||||
This is free software: you are free to change and redistribute it.
|
||||
There is NO WARRANTY, to the extent permitted by law.
|
||||
|
||||
Secret key is available.
|
||||
|
||||
pub 4096R/0xD93D03C13478D580 created: 2016-11-30 expires: 2018-11-30 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
\[ultimate\] (1). Alice <alice@example.com>
|
||||
|
||||
gpg>
|
||||
|
||||
### Signing sub-key
|
||||
|
||||
With the key opened for editing, the sub-key can be added to it. To start the guided process of creating a sub-key the command is “addkey”.
|
||||
|
||||
After the passphrase is entered, the type of sub-key must be entered. For a signing key, the “(4) RSA (sign only)” is used. The key size should match the size fitting on the smartcard or Yubikey.
|
||||
|
||||
While GnuPG version 1 will ask for the passphrase at the beginning of the “addkey” procedure, version 2 will ask at the end of the creation process for an individual passphrase for the new subkey as well as for the passphrase of the master key.
|
||||
|
||||
gpg> **addkey**
|
||||
Key is protected.
|
||||
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "Alice <alice@example.com>"
|
||||
4096-bit RSA key, ID 0xD93D03C13478D580, created 2016-11-30
|
||||
|
||||
Enter passphrase: **YourPassword**
|
||||
|
||||
Please select what kind of key you want:
|
||||
(3) DSA (sign only)
|
||||
(4) RSA (sign only)
|
||||
(5) Elgamal (encrypt only)
|
||||
(6) RSA (encrypt only)
|
||||
(7) DSA (set your own capabilities)
|
||||
(8) RSA (set your own capabilities)
|
||||
Your selection? **4**
|
||||
RSA keys may be between 1024 and 4096 bits long.
|
||||
What keysize do you want? (2048) **3072**
|
||||
Requested keysize is 3072 bits
|
||||
Please specify how long the key should be valid.
|
||||
0 = key does not expire
|
||||
<n> = key expires in n days
|
||||
<n>w = key expires in n weeks
|
||||
<n>m = key expires in n months
|
||||
<n>y = key expires in n years
|
||||
Key is valid for? (0) **2y**
|
||||
Key expires at Fri 30 Nov 2018 10:44:21 PM CET
|
||||
Is this correct? (y/N) **Y**
|
||||
Really create? (y/N) **Y**
|
||||
We need to generate a lot of random bytes. It is a good idea to perform
|
||||
some other action (type on the keyboard, move the mouse, utilize the
|
||||
disks) during the prime generation; this gives the random number
|
||||
generator a better chance to gain enough entropy.
|
||||
............+++++
|
||||
+++++
|
||||
|
||||
pub 4096R/0xD93D03C13478D580 created: 2016-11-30 expires: 2018-11-30 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
sub 3072R/0x1ED73636975EC6DE created: 2016-11-30 expires: 2018-11-30 usage: S
|
||||
\[ultimate\] (1). Alice <alice@example.com>
|
||||
|
||||
gpg>
|
||||
|
||||
The output above now shows an additional sub-key for signing (“usage: S”). If there is no additional sub-key to be created, the process can be ended by the command “save” to store the modifications to the key.
|
||||
|
||||
gpg> **save**
|
||||
|
||||
### Encryption sub-key
|
||||
|
||||
An encryption key can now be created in the same way as the signing key just by selecting the “RSA (encrypt only)” key type.
|
||||
|
||||
gpg> **addkey**
|
||||
Key is protected.
|
||||
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "Alice <alice@example.com>"
|
||||
4096-bit RSA key, ID 0xD93D03C13478D580, created 2016-11-30
|
||||
|
||||
Enter passphrase: **YourPassword**
|
||||
|
||||
Please select what kind of key you want:
|
||||
(3) DSA (sign only)
|
||||
(4) RSA (sign only)
|
||||
(5) Elgamal (encrypt only)
|
||||
(6) RSA (encrypt only)
|
||||
(7) DSA (set your own capabilities)
|
||||
(8) RSA (set your own capabilities)
|
||||
Your selection? **6**
|
||||
RSA keys may be between 1024 and 4096 bits long.
|
||||
What keysize do you want? (2048) **3072**
|
||||
Requested keysize is 3072 bits
|
||||
Please specify how long the key should be valid.
|
||||
0 = key does not expire
|
||||
<n> = key expires in n days
|
||||
<n>w = key expires in n weeks
|
||||
<n>m = key expires in n months
|
||||
<n>y = key expires in n years
|
||||
Key is valid for? (0) **2y**
|
||||
Key expires at Fri 30 Nov 2018 10:44:23 PM CET
|
||||
Is this correct? (y/N) **Y**
|
||||
Really create? (y/N) **Y**
|
||||
We need to generate a lot of random bytes. It is a good idea to perform
|
||||
some other action (type on the keyboard, move the mouse, utilize the
|
||||
disks) during the prime generation; this gives the random number
|
||||
generator a better chance to gain enough entropy.
|
||||
.......+++++
|
||||
....................+++++
|
||||
|
||||
pub 4096R/0xD93D03C13478D580 created: 2016-11-30 expires: 2018-11-30 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
sub 3072R/0x1ED73636975EC6DE created: 2016-11-30 expires: 2018-11-30 usage: S
|
||||
sub 3072R/0x76737ABEB92745D7 created: 2016-11-30 expires: 2018-11-30 usage: E
|
||||
\[ultimate\] (1). Alice <alice@example.com>
|
||||
|
||||
gpg>
|
||||
|
||||
### Authentication sub-key
|
||||
|
||||
When the GnuPG key should be used for authentication, an additional authentication subkey needs to be created. Such a sub-key can be used to authenticate when connecting via ssh.
|
||||
|
||||
To create such a authentication sub-key, the type “(8) RSA (set your own capabilities)” needs to be selected.
|
||||
|
||||
gpg> **addkey**
|
||||
Key is protected.
|
||||
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "Alice <alice@example.com>"
|
||||
4096-bit RSA key, ID 0xD93D03C13478D580, created 2016-11-30
|
||||
|
||||
Enter passphrase: **YourPassword**
|
||||
|
||||
Please select what kind of key you want:
|
||||
(3) DSA (sign only)
|
||||
(4) RSA (sign only)
|
||||
(5) Elgamal (encrypt only)
|
||||
(6) RSA (encrypt only)
|
||||
(7) DSA (set your own capabilities)
|
||||
(8) RSA (set your own capabilities)
|
||||
Your selection? **8**
|
||||
|
||||
Possible actions for a RSA key: Sign Encrypt Authenticate
|
||||
Current allowed actions: Sign Encrypt
|
||||
|
||||
(S) Toggle the sign capability
|
||||
(E) Toggle the encrypt capability
|
||||
(A) Toggle the authenticate capability
|
||||
(Q) Finished
|
||||
|
||||
Your selection?
|
||||
|
||||
The type (8) allows to set the capability manually. The list above shows the available capabilities. The default assigned capabilities as shown are “Sign” and “Encrypt”.
|
||||
|
||||
Disable the default capabilities by entering the related letter followed by ENTER one capability after the other. The use the toggle “A” to enable authentication capability and proceed with “Q”.
|
||||
|
||||
Your selection? **S**
|
||||
|
||||
Possible actions for a RSA key: Sign Encrypt Authenticate
|
||||
Current allowed actions: Encrypt
|
||||
|
||||
(S) Toggle the sign capability
|
||||
(E) Toggle the encrypt capability
|
||||
(A) Toggle the authenticate capability
|
||||
(Q) Finished
|
||||
|
||||
Your selection? **E**
|
||||
|
||||
Possible actions for a RSA key: Sign Encrypt Authenticate
|
||||
Current allowed actions:
|
||||
|
||||
(S) Toggle the sign capability
|
||||
(E) Toggle the encrypt capability
|
||||
(A) Toggle the authenticate capability
|
||||
(Q) Finished
|
||||
|
||||
Your selection? **A**
|
||||
|
||||
Possible actions for a RSA key: Sign Encrypt Authenticate
|
||||
Current allowed actions: Authenticate
|
||||
|
||||
(S) Toggle the sign capability
|
||||
(E) Toggle the encrypt capability
|
||||
(A) Toggle the authenticate capability
|
||||
(Q) Finished
|
||||
|
||||
Your selection? **Q**
|
||||
RSA keys may be between 1024 and 4096 bits long.
|
||||
What keysize do you want? (2048) **3072**
|
||||
Requested keysize is 3072 bits
|
||||
Please specify how long the key should be valid.
|
||||
0 = key does not expire
|
||||
<n> = key expires in n days
|
||||
<n>w = key expires in n weeks
|
||||
<n>m = key expires in n months
|
||||
<n>y = key expires in n years
|
||||
Key is valid for? (0) **2y**
|
||||
Key expires at Fri 30 Nov 2018 10:44:26 PM CET
|
||||
Is this correct? (y/N) **Y**
|
||||
Really create? (y/N) **Y**
|
||||
We need to generate a lot of random bytes. It is a good idea to perform
|
||||
some other action (type on the keyboard, move the mouse, utilize the
|
||||
disks) during the prime generation; this gives the random number
|
||||
generator a better chance to gain enough entropy.
|
||||
..+++++
|
||||
.....+++++
|
||||
|
||||
pub 4096R/0xD93D03C13478D580 created: 2016-11-30 expires: 2018-11-30 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
sub 3072R/0x1ED73636975EC6DE created: 2016-11-30 expires: 2018-11-30 usage: S
|
||||
sub 3072R/0x76737ABEB92745D7 created: 2016-11-30 expires: 2018-11-30 usage: E
|
||||
sub 3072R/0xE379FB0D81B6925D created: 2016-11-30 expires: 2018-11-30 usage: A
|
||||
\[ultimate\] (1). Alice <alice@example.com>
|
||||
|
||||
gpg> **save**
|
||||
|
||||
As the last output shows, the master key has 4096 bit and the 3 subkeys have a different sizes to fit later on to the smartcard or Yubikey.
|
||||
|
||||
## Add identities
|
||||
|
||||
If necessary, more identities can be added to the GnuPG key. To do so, the key needs to be opened again in edit mode. The “adduid” command is used then to add an additional identity.
|
||||
|
||||
$ gpg --homedir ./gnupg-test --expert --edit-key 0xD93D03C13478D580
|
||||
gpg (GnuPG) 1.4.20; Copyright (C) 2015 Free Software Foundation, Inc.
|
||||
This is free software: you are free to change and redistribute it.
|
||||
There is NO WARRANTY, to the extent permitted by law.
|
||||
|
||||
Secret key is available.
|
||||
|
||||
pub 4096R/0xD93D03C13478D580 created: 2016-11-30 expires: 2018-11-30 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
sub 3072R/0x1ED73636975EC6DE created: 2016-11-30 expires: 2018-11-30 usage: S
|
||||
sub 3072R/0x76737ABEB92745D7 created: 2016-11-30 expires: 2018-11-30 usage: E
|
||||
sub 3072R/0xE379FB0D81B6925D created: 2016-11-30 expires: 2018-11-30 usage: A
|
||||
\[ultimate\] (1). Alice <alice@example.com>
|
||||
|
||||
gpg> **adduid**
|
||||
Real name: **Alice**
|
||||
Email address: **alice@example.org**
|
||||
Comment:
|
||||
You selected this USER-ID:
|
||||
"Alice <alice@example.org>"
|
||||
|
||||
Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? **O**
|
||||
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "Alice <alice@example.com>"
|
||||
4096-bit RSA key, ID 0xD93D03C13478D580, created 2016-11-30
|
||||
|
||||
Enter passphrase: **YourPassword**
|
||||
|
||||
pub 4096R/0xD93D03C13478D580 created: 2016-11-30 expires: 2018-11-30 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
sub 3072R/0x1ED73636975EC6DE created: 2016-11-30 expires: 2018-11-30 usage: S
|
||||
sub 3072R/0x76737ABEB92745D7 created: 2016-11-30 expires: 2018-11-30 usage: E
|
||||
sub 3072R/0xE379FB0D81B6925D created: 2016-11-30 expires: 2018-11-30 usage: A
|
||||
\[ultimate\] (1) Alice <alice@example.com>
|
||||
\[ unknown\] (2). Alice <alice@example.org>
|
||||
|
||||
gpg> **uid 1**
|
||||
|
||||
pub 4096R/0xD93D03C13478D580 created: 2016-11-30 expires: 2018-11-30 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
sub 3072R/0x1ED73636975EC6DE created: 2016-11-30 expires: 2018-11-30 usage: S
|
||||
sub 3072R/0x76737ABEB92745D7 created: 2016-11-30 expires: 2018-11-30 usage: E
|
||||
sub 3072R/0xE379FB0D81B6925D created: 2016-11-30 expires: 2018-11-30 usage: A
|
||||
\[ultimate\] (2)* Alice <alice@example.com>
|
||||
\[ultimate\] (1). Alice <alice@example.org>
|
||||
|
||||
gpg> **primary**
|
||||
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "Alice <alice@example.com>""
|
||||
4096-bit RSA key, ID 0xD93D03C13478D580, created 2016-11-30
|
||||
|
||||
Enter passphrase: **YourPassword**
|
||||
|
||||
pub 4096R/0xD93D03C13478D580 created: 2016-11-30 expires: 2018-11-30 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
sub 3072R/0x1ED73636975EC6DE created: 2016-11-30 expires: 2018-11-30 usage: S
|
||||
sub 3072R/0x76737ABEB92745D7 created: 2016-11-30 expires: 2018-11-30 usage: E
|
||||
sub 3072R/0xE379FB0D81B6925D created: 2016-11-30 expires: 2018-11-30 usage: A
|
||||
\[ultimate\] (2)* Alice <alice@example.com>
|
||||
\[ultimate\] (1) Alice <alice@example.org>
|
||||
|
||||
gpg> **save**
|
||||
|
||||
The last output after adding the identity shows the key with a trust of “unknown” which will change to unlimited after saving the new identity with the “save” command.
|
||||
|
||||
The “.” at the identity marks the primary identity for that key. As shown above, after adding the second identity, the added identity is selected as primary identity. As of this, the primary identity has been manually defined by selecting the primary identity using the “uid” command followed by the “primary” command to set that identity as primary.
|
||||
|
||||
## Export the public and secret keys as backup
|
||||
|
||||
To backup the keys, export them into a file. Exporting the keys is done in two steps, the private keys and the secret keys are exported separately.
|
||||
|
||||
$ gpg --homedir ./gnupg-test --export-secret-keys --armor --output secret-keys.gpg 0xD93D03C13478D580
|
||||
$ gpg --homedir ./gnupg-test --export --armor --output public-keys.gpg 0xD93D03C13478D580
|
||||
|
||||
With the first command, all secret keys (master + subkeys) are exported into one file. The second command will export all public keys (master + subkeys) into another file. Those files can be used to backup the created keys.
|
||||
|
||||
To export only one particular subkey, the subkey ID can be specified with an “!” exclamation mark at the end of the key ID instructs gpg to only export this particular subkey(s).
|
||||
|
||||
$ gpg --homedir ./gnupg-test --export-secret-subkeys --armor --output secret-subkey_sign.gpg 0x1ED73636975EC6DE!
|
||||
|
||||
The above command will export only the signing subkeys secret key. The [gpg man page](https://linux.die.net/man/1/gpg) describes the exclamation mark at the key ID like this.
|
||||
|
||||
When using gpg an exclamation mark (!) may be appended to force using the specified primary or secondary key and not to try and calculate which primary or secondary key to use.
|
||||
|
||||
## Daily use keyring
|
||||
|
||||
For everyday use, you want to “remove” the master secret key from the keyring. This is sometimes refered to as a laptop keyring. Such a keyring can be prepared in multiple ways.
|
||||
|
||||
### Option 1: Removing the secret master key
|
||||
|
||||
By exporting only the secret subkeys, deleting all the secret keys of that key from the keyring (which includes not only the master key but also the subkeys) and then reimporting only the secret subkeys.
|
||||
|
||||
$ gpg --homedir ./gnupg-test --export-secret-subkeys --armor --output secret-subkeys.gpg 0xD93D03C13478D580
|
||||
|
||||
The above command will export all the secret subkeys of the given key ID and stores it in the given output file.
|
||||
|
||||
$ gpg --homedir ./gnupg-test --delete-secret-keys 0xD93D03C13478D580
|
||||
gpg (GnuPG) 1.4.20; Copyright (C) 2015 Free Software Foundation, Inc.
|
||||
This is free software: you are free to change and redistribute it.
|
||||
There is NO WARRANTY, to the extent permitted by law.
|
||||
|
||||
|
||||
sec 4096R/0xD93D03C13478D580 2016-11-30 Alice <alice@example.org>
|
||||
|
||||
Delete this key from the keyring? (y/N) **Y**
|
||||
This is a secret key! - really delete? (y/N) **Y**
|
||||
|
||||
Version 2 of GnuPG will ask for every secret key/subkey to be deleted. At this point, the delete operation for the master key can be accepted but the deletion of the subkeys can be denied. This will result in a error message for the delete operation which indicates that the subkeys where not deleted. This allows to delete the secret master key but keep the subkeys and therefore does not require the reimport of the secret subkeys.
|
||||
|
||||
After the above command is executed, all the secret keys are removed for the created keys. With the following command the exported secret subkeys are reimported back to the keyring.
|
||||
|
||||
$ gpg --homedir ./gnupg-test --import ./gnupg-backup/secret-subkeys.gpg
|
||||
gpg: key 0xD93D03C13478D580: secret key imported
|
||||
gpg: key 0xD93D03C13478D580: "Alice <alice@example.org>" not changed
|
||||
gpg: Total number processed: 1
|
||||
gpg: unchanged: 1
|
||||
gpg: secret keys read: 1
|
||||
gpg: secret keys imported: 1
|
||||
|
||||
### Option 2: Build from backup
|
||||
|
||||
If the keyring you used to create is not the keyring you intend to use for every day use, the backup files created earlier can be used to create the daily use keyring. This is the prefered method if you have created the key not on the computer you are using for everyday tasks or you have created the key on a USB drive or similar.
|
||||
|
||||
$ gpg --homedir ./gnupg-test --export-secret-subkeys --armor --output secret-subkeys.gpg 0xD93D03C13478D580
|
||||
|
||||
As with the first option, an export with only the subkeys has to be created with the command above. Additionally to the following commands, I suggest to also copy the **gpg.conf** used in the keyring to create the key to the daily-use-keyring.
|
||||
|
||||
$ gpg --homedir ~/.gnupg --import gnupg-backup/public-keys.gpg
|
||||
gpg: key 0xD93D03C13478D580: public key "Alice <alice@example.org>" imported
|
||||
gpg: Total number processed: 1
|
||||
gpg: imported: 1 (RSA: 1)
|
||||
|
||||
The above command can be used to import the public key into the keyring you use for everyday use. With the command below, the secret subkeys, without the master secret key, can be imported into the daily use keyring. The “–homedir ~/.gnupg” can be ommited if the keyring is at the default location like in this example.
|
||||
|
||||
$ gpg --homedir ~/.gnupg --import gnupg-backup/secret-subkeys.gpg
|
||||
gpg: key 0xD93D03C13478D580: secret key imported
|
||||
gpg: key 0xD93D03C13478D580: "Alice <alice@example.org>" 1 new signature
|
||||
gpg: Total number processed: 1
|
||||
gpg: new signatures: 1
|
||||
gpg: secret keys read: 1
|
||||
gpg: secret keys imported: 1
|
||||
|
||||
### Check the daily use keyring
|
||||
|
||||
To verify that only the subkeys secret keys have been imported back into the keyring, execute the following command. This command will list all secret keys. The master key is marked with a hash character “#” indicating that the secret key is missing – as expected.
|
||||
|
||||
$ gpg --homedir ./gnupg-test -K
|
||||
./gnupg-test/secring.gpg
|
||||
\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-\-
|
||||
sec# 4096R/0xD93D03C13478D580 2016-11-30 \[expires: 2018-11-30\]
|
||||
Key fingerprint = F8C8 1342 2A7F 7A3A 9027 E158 D93D 03C1 3478 D580
|
||||
uid Alice <alice@example.com>
|
||||
uid Alice <alice@example.org>
|
||||
ssb 3072R/0x1ED73636975EC6DE 2016-11-30
|
||||
Key fingerprint = 292D 3E78 6B2E DBEA 1D10 02C8 1ED7 3636 975E C6DE
|
||||
ssb 3072R/0x76737ABEB92745D7 2016-11-30
|
||||
Key fingerprint = 0C33 42E5 670A B099 8ED7 3E87 7673 7ABE B927 45D7
|
||||
ssb 3072R/0xE379FB0D81B6925D 2016-11-30
|
||||
Key fingerprint = 7357 2158 947D BAFF A89F 4911 E379 FB0D 81B6 925D
|
||||
|
||||
Finally keep a backup of the secret keys, in particular the secret master key, and remove any other temporary export file of the secret subkeys not needed any more. Consider using the [shred(1)](https://linux.die.net/man/1/shred) utility to securely delete those files.
|
||||
|
||||
## Verify the created GnuPG key
|
||||
|
||||
As always, verifying the result is important. Thankfully, there is a tool to assist with that. The hkt (hopenpgp-tools) provide exactly that. The utility does not come pre-installed but can be installed directly from the repository of Ubuntu / LinuxMint. So far it seems hopenpgp-tools is not available as rpm for RHEL or CentOS.
|
||||
|
||||
\# Debian / Ubuntu
|
||||
$ sudo apt-get install hopenpgp-tools
|
||||
|
||||
\# RedHat / CentOS
|
||||
\# ... not available.
|
||||
|
||||
The hopenpgp-tools can be used to check the key for hopenpgp-tools setting. The command below uses the “hkt”, which is part of hopenpgp-tools, to extract the public key from the keyring. As well, a hopenpgp-tools utility called “hokey” performs the check of the key settings. The green sections show where the best practice is fulfilled. If a setting would not be according to the best practice, the utility would mark it red.
|
||||
|
||||
$ hkt export-pubkeys --keyring gnupg-test/pubring.gpg 0xD93D03C13478D580 | hokey lint
|
||||
hokey (hopenpgp-tools) 0.17
|
||||
Copyright (C) 2012-2015 Clint Adams
|
||||
hokey comes with ABSOLUTELY NO WARRANTY. This is free software, and you are welcome to redistribute it under certain conditions.
|
||||
hkt (hopenpgp-tools) 0.17
|
||||
Copyright (C) 2012-2015 Clint Adams
|
||||
hkt comes with ABSOLUTELY NO WARRANTY. This is free software, and you are welcome to redistribute it under certain conditions.
|
||||
|
||||
Key has potential validity: good
|
||||
Key has fingerprint: F8C8 1342 2A7F 7A3A 9027 E158 D93D 03C1 3478 D580
|
||||
Checking to see if key is OpenPGPv4: V4
|
||||
Checking to see if key is RSA or DSA (>= 2048-bit): RSA 4096
|
||||
Checking user-ID- and user-attribute-related items:
|
||||
Alice <alice@example.com>:
|
||||
Self-sig hash algorithms: \[SHA-512\]
|
||||
Preferred hash algorithms: \[SHA-512, SHA-384, SHA-256, SHA-224\]
|
||||
Key expiration times: \[1y11m29d81000s = Fri Nov 30 21:44:14 UTC 2018\]
|
||||
Key usage flags: \[\[certify-keys\]\]
|
||||
Alice <alice@example.org>:
|
||||
Self-sig hash algorithms: \[SHA-512\]
|
||||
Preferred hash algorithms: \[SHA-512, SHA-384, SHA-256, SHA-224\]
|
||||
Key expiration times: \[1y11m29d81000s = Fri Nov 30 21:44:14 UTC 2018\]
|
||||
Key usage flags: \[\[certify-keys\]\]
|
||||
|
||||
Another way of checking the generated GnuPG key is pgpdump. This utility will not interpret the key information and mark any information considered not good practice but will show you the raw key information. On the other hand, way more details about the key itself are revealed.
|
||||
|
||||
The pgpdump utility is also not preinstalled but can be installed directly from the repositories of the distribution. While the “hopenpgp-tools” utility is not available as rpm package, pgpdump is available as rpm for RedHat and CentOS.
|
||||
|
||||
\# Debian / Ubuntu
|
||||
$ sudo apt install pgpdump
|
||||
|
||||
\# RedHat / CentOS
|
||||
$ yum install pgpdump
|
||||
|
||||
The pgpdump utility takes a secret key export as produced from the backup and dumps all of its information in a human readable format. The below command shows grouped information for the master key and the subkeys.
|
||||
|
||||
The first block contains the details about the secret master key. The highlighted area in the first block shows the s2k settings defined in the gpg.conf.
|
||||
|
||||
$ gpg --homedir ./gnupg-test --export-secret-keys --armor 0xD93D03C13478D580 | pgpdump
|
||||
Old: Secret Key Packet(tag 5)(1862 bytes)
|
||||
Ver 4 - new
|
||||
Public key creation time - Wed Nov 30 22:44:14 CET 2016
|
||||
Pub alg - RSA Encrypt or Sign(pub 1)
|
||||
RSA n(4096 bits) - ...
|
||||
RSA e(17 bits) - ...
|
||||
**Sym alg - AES with 256-bit key(sym 9)
|
||||
Iterated and salted string-to-key(s2k 3):
|
||||
Hash alg - SHA512(hash 10)
|
||||
Salt - 12 43 4f 59 74 01 a2 ff
|
||||
Count - 1015808(coded count 159)**
|
||||
IV - 2f d5 54 c1 1f f0 a6 87 a3 af 58 ef 69 47 ec 4f
|
||||
Encrypted RSA d
|
||||
Encrypted RSA p
|
||||
Encrypted RSA q
|
||||
Encrypted RSA u
|
||||
Encrypted SHA1 hash
|
||||
|
||||
The above shows as well that this key is a 4096 bits RSA key. The first block is followed the the identity and its signature. This shows clearly the self signature of the identities from the master key. In the signature the hash algorithm SHA512 as well as the preferred algorithms as defined in the gpg.conf and the key itself can be found.
|
||||
|
||||
Old: User ID Packet(tag 13)(25 bytes)
|
||||
User ID - Alice <alice@example.com>
|
||||
Old: Signature Packet(tag 2)(573 bytes)
|
||||
Ver 4 - new
|
||||
Sig type - Positive certification of a User ID and Public Key packet(0x13).
|
||||
Pub alg - RSA Encrypt or Sign(pub 1)
|
||||
**Hash alg - SHA512(hash 10)**
|
||||
Hashed Sub: signature creation time(sub 2)(4 bytes)
|
||||
Time - Wed Nov 30 22:44:14 CET 2016
|
||||
Hashed Sub: key flags(sub 27)(1 bytes)
|
||||
Flag - This key may be used to certify other keys
|
||||
Hashed Sub: key expiration time(sub 9)(4 bytes)
|
||||
Time - Fri Nov 30 22:44:14 CET 2018
|
||||
**Hashed Sub: preferred symmetric algorithms(sub 11)(4 bytes)
|
||||
Sym alg - AES with 256-bit key(sym 9)
|
||||
Sym alg - AES with 192-bit key(sym 8)
|
||||
Sym alg - AES with 128-bit key(sym 7)
|
||||
Sym alg - CAST5(sym 3)
|
||||
Hashed Sub: preferred hash algorithms(sub 21)(4 bytes)
|
||||
Hash alg - SHA512(hash 10)
|
||||
Hash alg - SHA384(hash 9)
|
||||
Hash alg - SHA256(hash 8)
|
||||
Hash alg - SHA224(hash 11)
|
||||
Hashed Sub: preferred compression algorithms(sub 22)(4 bytes)
|
||||
Comp alg - ZLIB <RFC1950>(comp 2)
|
||||
Comp alg - BZip2(comp 3)
|
||||
Comp alg - ZIP <RFC1951>(comp 1)
|
||||
Comp alg - Uncompressed(comp 0)**
|
||||
Hashed Sub: features(sub 30)(1 bytes)
|
||||
Flag - Modification detection (packets 18 and 19)
|
||||
Hashed Sub: key server preferences(sub 23)(1 bytes)
|
||||
Flag - No-modify
|
||||
Sub: issuer key ID(sub 16)(8 bytes)
|
||||
Key ID - 0xD93D03C13478D580
|
||||
Hash left 2 bytes - b4 17
|
||||
RSA m^d mod n(4096 bits) - ...
|
||||
-\> PKCS-1
|
||||
Old: User ID Packet(tag 13)(25 bytes)
|
||||
User ID - Alice <alice@example.org>
|
||||
Old: Signature Packet(tag 2)(573 bytes)
|
||||
Ver 4 - new
|
||||
Sig type - Positive certification of a User ID and Public Key packet(0x13).
|
||||
Pub alg - RSA Encrypt or Sign(pub 1)
|
||||
**Hash alg - SHA512(hash 10)**
|
||||
Hashed Sub: signature creation time(sub 2)(4 bytes)
|
||||
Time - Wed Nov 30 22:44:28 CET 2016
|
||||
Hashed Sub: key flags(sub 27)(1 bytes)
|
||||
Flag - This key may be used to certify other keys
|
||||
Hashed Sub: key expiration time(sub 9)(4 bytes)
|
||||
Time - Fri Nov 30 22:44:14 CET 2018
|
||||
**Hashed Sub: preferred symmetric algorithms(sub 11)(4 bytes)
|
||||
Sym alg - AES with 256-bit key(sym 9)
|
||||
Sym alg - AES with 192-bit key(sym 8)
|
||||
Sym alg - AES with 128-bit key(sym 7)
|
||||
Sym alg - CAST5(sym 3)
|
||||
Hashed Sub: preferred hash algorithms(sub 21)(4 bytes)
|
||||
Hash alg - SHA512(hash 10)
|
||||
Hash alg - SHA384(hash 9)
|
||||
Hash alg - SHA256(hash 8)
|
||||
Hash alg - SHA224(hash 11)
|
||||
Hashed Sub: preferred compression algorithms(sub 22)(4 bytes)
|
||||
Comp alg - ZLIB <RFC1950>(comp 2)
|
||||
Comp alg - BZip2(comp 3)
|
||||
Comp alg - ZIP <RFC1951>(comp 1)
|
||||
Comp alg - Uncompressed(comp 0)**
|
||||
Hashed Sub: features(sub 30)(1 bytes)
|
||||
Flag - Modification detection (packets 18 and 19)
|
||||
Hashed Sub: key server preferences(sub 23)(1 bytes)
|
||||
Flag - No-modify
|
||||
Sub: issuer key ID(sub 16)(8 bytes)
|
||||
Key ID - 0xD93D03C13478D580
|
||||
Hash left 2 bytes - e5 1a
|
||||
RSA m^d mod n(4096 bits) - ...
|
||||
-\> PKCS-1
|
||||
|
||||
Following the master key and the identities, the secret keys can be found. The first is the signing key with a size of 3072 bits. The signing subkey has two signatures, one from the master key and one signature from itself (self signature). The signature itself can be identified by the “issuer key ID”.
|
||||
|
||||
Old: Secret Subkey Packet(tag 7)(1414 bytes)
|
||||
Ver 4 - new
|
||||
Public key creation time - Wed Nov 30 22:44:21 CET 2016
|
||||
Pub alg - RSA Encrypt or Sign(pub 1)
|
||||
**RSA n(3072 bits) - ...**
|
||||
RSA e(17 bits) - ...
|
||||
**Sym alg - AES with 256-bit key(sym 9)
|
||||
Iterated and salted string-to-key(s2k 3):
|
||||
Hash alg - SHA512(hash 10)
|
||||
Salt - 0f 7d 79 55 7c 4e 99 71
|
||||
Count - 1015808(coded count 159)**
|
||||
IV - f6 1f ba 7c d4 40 28 19 72 c5 12 0f 4f c1 a3 65
|
||||
Encrypted RSA d
|
||||
Encrypted RSA p
|
||||
Encrypted RSA q
|
||||
Encrypted RSA u
|
||||
Encrypted SHA1 hash
|
||||
Old: Signature Packet(tag 2)(964 bytes)
|
||||
Ver 4 - new
|
||||
Sig type - Subkey Binding Signature(0x18).
|
||||
Pub alg - RSA Encrypt or Sign(pub 1)
|
||||
**Hash alg - SHA512(hash 10)**
|
||||
Hashed Sub: signature creation time(sub 2)(4 bytes)
|
||||
Time - Wed Nov 30 22:44:21 CET 2016
|
||||
Hashed Sub: key flags(sub 27)(1 bytes)
|
||||
Flag - This key may be used to sign data
|
||||
Hashed Sub: key expiration time(sub 9)(4 bytes)
|
||||
Time - Fri Nov 30 22:44:21 CET 2018
|
||||
Sub: issuer key ID(sub 16)(8 bytes)
|
||||
**Key ID - 0xD93D03C13478D580**
|
||||
Sub: embedded signature(sub 32)(412 bytes)
|
||||
Ver 4 - new
|
||||
Sig type - Primary Key Binding Signature(0x19).
|
||||
Pub alg - RSA Encrypt or Sign(pub 1)
|
||||
**Hash alg - SHA512(hash 10)**
|
||||
Hashed Sub: signature creation time(sub 2)(4 bytes)
|
||||
Time - Wed Nov 30 22:44:21 CET 2016
|
||||
Sub: issuer key ID(sub 16)(8 bytes)
|
||||
Key ID - 0x1ED73636975EC6DE
|
||||
Hash left 2 bytes - 2c da
|
||||
RSA m^d mod n(3071 bits) - ...
|
||||
-\> PKCS-1
|
||||
Hash left 2 bytes - c0 7e
|
||||
RSA m^d mod n(4095 bits) - ...
|
||||
-\> PKCS-1
|
||||
|
||||
The encryption key as well as the authentication key only show one signature from the master key. As their capabilities do not include signing, they are not signed by them self.
|
||||
|
||||
Old: Secret Subkey Packet(tag 7)(1414 bytes)
|
||||
Ver 4 - new
|
||||
Public key creation time - Wed Nov 30 22:44:23 CET 2016
|
||||
Pub alg - RSA Encrypt or Sign(pub 1)
|
||||
RSA n(3072 bits) - ...
|
||||
RSA e(17 bits) - ...
|
||||
Sym alg - AES with 256-bit key(sym 9)
|
||||
Iterated and salted string-to-key(s2k 3):
|
||||
Hash alg - SHA512(hash 10)
|
||||
Salt - 5c 54 ae 09 9d d2 01 c6
|
||||
Count - 1015808(coded count 159)
|
||||
IV - 6d 44 b1 68 d4 c5 94 41 c0 23 ea 92 bc 50 ce 68
|
||||
Encrypted RSA d
|
||||
Encrypted RSA p
|
||||
Encrypted RSA q
|
||||
Encrypted RSA u
|
||||
Encrypted SHA1 hash
|
||||
Old: Signature Packet(tag 2)(549 bytes)
|
||||
Ver 4 - new
|
||||
Sig type - Subkey Binding Signature(0x18).
|
||||
Pub alg - RSA Encrypt or Sign(pub 1)
|
||||
Hash alg - SHA512(hash 10)
|
||||
Hashed Sub: signature creation time(sub 2)(4 bytes)
|
||||
Time - Wed Nov 30 22:44:23 CET 2016
|
||||
Hashed Sub: key flags(sub 27)(1 bytes)
|
||||
Flag - This key may be used to encrypt communications
|
||||
Flag - This key may be used to encrypt storage
|
||||
Hashed Sub: key expiration time(sub 9)(4 bytes)
|
||||
Time - Fri Nov 30 22:44:23 CET 2018
|
||||
Sub: issuer key ID(sub 16)(8 bytes)
|
||||
Key ID - 0xD93D03C13478D580
|
||||
Hash left 2 bytes - fb 43
|
||||
RSA m^d mod n(4096 bits) - ...
|
||||
-\> PKCS-1
|
||||
Old: Secret Subkey Packet(tag 7)(1414 bytes)
|
||||
Ver 4 - new
|
||||
Public key creation time - Wed Nov 30 22:44:26 CET 2016
|
||||
Pub alg - RSA Encrypt or Sign(pub 1)
|
||||
RSA n(3072 bits) - ...
|
||||
RSA e(17 bits) - ...
|
||||
Sym alg - AES with 256-bit key(sym 9)
|
||||
Iterated and salted string-to-key(s2k 3):
|
||||
Hash alg - SHA512(hash 10)
|
||||
Salt - a5 7a f7 44 d2 b7 3c 2d
|
||||
Count - 1015808(coded count 159)
|
||||
IV - 25 3c aa 37 c9 8e 16 eb 12 b6 7d 04 36 a3 db 92
|
||||
Encrypted RSA d
|
||||
Encrypted RSA p
|
||||
Encrypted RSA q
|
||||
Encrypted RSA u
|
||||
Encrypted SHA1 hash
|
||||
Old: Signature Packet(tag 2)(549 bytes)
|
||||
Ver 4 - new
|
||||
Sig type - Subkey Binding Signature(0x18).
|
||||
Pub alg - RSA Encrypt or Sign(pub 1)
|
||||
Hash alg - SHA512(hash 10)
|
||||
Hashed Sub: signature creation time(sub 2)(4 bytes)
|
||||
Time - Wed Nov 30 22:44:26 CET 2016
|
||||
Hashed Sub: key flags(sub 27)(1 bytes)
|
||||
Flag - This key may be used for authentication
|
||||
Hashed Sub: key expiration time(sub 9)(4 bytes)
|
||||
Time - Fri Nov 30 22:44:26 CET 2018
|
||||
Sub: issuer key ID(sub 16)(8 bytes)
|
||||
Key ID - 0xD93D03C13478D580
|
||||
Hash left 2 bytes - 9d 8b
|
||||
RSA m^d mod n(4095 bits) - ...
|
||||
-\> PKCS-1
|
||||
|
||||
Even if it is not as comfortable to use gpgdump as it is to verify the key with hopenpgp-tools, there are more details that might be of interest. Additionally, for RedHat / CentOS and other rpm based distributions it offers a good alternative to the hopenpgp-tools.
|
||||
|
||||
* * *
|
||||
|
||||
Read more of my posts on my blog at [https://blog.tinned-software.net/](https://blog.tinned-software.net/ "Experiencing Technology").
|
||||
@@ -1,148 +0,0 @@
|
||||
---
|
||||
title: Creating User’s Services With systemd | Baeldung on Linux
|
||||
source: https://www.baeldung.com/linux/systemd-create-user-services
|
||||
tags:
|
||||
- IT/Administration
|
||||
- IT/OS/Linux
|
||||
---
|
||||
|
||||
|
||||
|
||||
## 1\. Overview
|
||||
|
||||
Most Linux distributions use [*systemd*](https://www.baeldung.com/linux/create-remove-systemd-services) as a contemporary service manager. Usually, we need to become *root* to control the services. **However, we can also allow ordinary users to handle services on their own.** This method is often called rootless.
|
||||
|
||||
In this tutorial, we’ll learn to install, manage and control services on a per-user basis.
|
||||
|
||||
## 2\. Creating and Adding a Sample Service
|
||||
|
||||
First, let’s write a simple Bash script *user_service* for the service:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
while true
|
||||
do
|
||||
now=$(date)
|
||||
me=$(whoami)
|
||||
echo "User $me at $now"
|
||||
sleep 10
|
||||
done
|
||||
```
|
||||
|
||||
So, the script prints the date and user name. Then, we need to copy the script to the */usr/local/bin* directory and make sure that the user has executable permission on it.
|
||||
|
||||
Next, let’s prepare the [service’s unit file](https://man7.org/linux/man-pages/man5/systemd.unit.5.html) *user_service.service*:
|
||||
|
||||
```properties
|
||||
[Unit]
|
||||
Description=Script Daemon For Test User Services
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
#User=
|
||||
#Group=
|
||||
ExecStart=/usr/local/bin/user_service
|
||||
Restart=on-failure
|
||||
StandardOutput=file:%h/log_file
|
||||
|
||||
[Install]
|
||||
WantedBy=default.target
|
||||
```
|
||||
|
||||
Since the entries *User* and *Group* are meaningless for user service, we’ve commented them out. Next, we redirect the script’s output to *log_file* with the *StandardOutput* entry. It’s worth noting that the *%h* modifier stands for the user’s home directory.
|
||||
|
||||
**Now, with the [sudo](https://www.baeldung.com/linux/sudo-command) privilege let’s copy the unit file to the */etc/systemd/user* directory.** In this way, *systemd* regards the service as the user’s one. Moreover, the service is available for all users.
|
||||
|
||||
## 3\. The *user* Option
|
||||
|
||||
We can manage services as regular users with the help of the *user* option of [*systemctl*](https://www.baeldung.com/linux/differences-systemctl-service#systemctlcommand). Thus, services can be enabled/disabled, started/stopped, and so on without the sudo privilege.
|
||||
|
||||
So, let’s install the service:
|
||||
|
||||
```bash
|
||||
systemctl --user daemon-reload
|
||||
```
|
||||
|
||||
Afterwards, let’s start it:
|
||||
|
||||
```bash
|
||||
systemctl --user start user_service.service
|
||||
```
|
||||
|
||||
Next, let’s check its status:
|
||||
|
||||
```bash
|
||||
systemctl --user status user_service.service
|
||||
● user_service.service - Script Daemon For Test User Services
|
||||
Loaded: loaded (/etc/xdg/systemd/user/user_service.service; disabled; vendor preset: enable>
|
||||
Active: active (running) since Thu 2023-01-12 19:23:14 CET; 28s ago
|
||||
Main PID: 4935 (user_service)
|
||||
Tasks: 2 (limit: 18982)
|
||||
Memory: 580.0K
|
||||
CPU: 16ms
|
||||
CGroup: /user.slice/user-1000.slice/user@1000.service/app.slice/user_service.service
|
||||
├─4935 /bin/bash /usr/local/bin/user_service
|
||||
└─4972 sleep 10
|
||||
|
||||
sty 12 19:23:14 ubuntu systemd[1511]: Started Script Daemon For Test User Services.
|
||||
```
|
||||
|
||||
Again, we should note that we’ve done that all without the *sudo* command.
|
||||
|
||||
## 4\. Enabling, Disabling, and the Service’s Lifetime[](#enabling-disabling-and-the-services-lifetime)
|
||||
|
||||
Now let’s enable or disable the service with *systemctl*:
|
||||
|
||||
```bash
|
||||
systemctl --user enable user_service.service
|
||||
Created symlink /home/joe/.config/systemd/user/default.target.wants/user_service.service → /etc/xdg/systemd/user/user_service.service.
|
||||
```
|
||||
|
||||
**Thus, once enabled, the service starts automatically after our login.** Then, it’ll be running as long as we have some open sessions. In other words, the service instance is bound to the user, not to the session.
|
||||
|
||||
Finally, let’s disable it:
|
||||
|
||||
```bash
|
||||
systemctl --user disable user_service.service
|
||||
```
|
||||
|
||||
## 5\. Toggling Services of All Users[](#toggling-services-of-all-users)
|
||||
|
||||
With the root privilege, we can enable or disable the service for all users with the *global* option of *systemctl*:
|
||||
|
||||
```bash
|
||||
sudo systemctl --global enable user_service.service
|
||||
Created symlink /etc/systemd/user/default.target.wants/user_service.service → /etc/systemd/user/user_service.service.
|
||||
```
|
||||
|
||||
**Consequently, all users obtain their own running instance of the service immediately after login.**
|
||||
|
||||
## 6\. Extending Service’s Life
|
||||
|
||||
Let’s assume that we intend our service to perform long-running tasks, e.g., calculation. So, we should extend its life beyond the end of the last session. **In that case, we use [*loginctl*](https://man7.org/linux/man-pages/man1/loginctl.1.html) with the *enable-linger* command:**
|
||||
|
||||
```bash
|
||||
$ loginctl enable-linger
|
||||
```
|
||||
|
||||
Now, our services start right after the system boot and run till the shutdown. We should keep in mind that this applies to all our *systemd* services. Finally, we can turn it off with *disable-linger*.
|
||||
|
||||
## 7\. Inspecting Service’s Log
|
||||
|
||||
Now let’s check the service’s log with the [*journalctl*](https://www.baeldung.com/linux/journalctl-check-logs) command. Once again, we’ll use the *user* option:
|
||||
|
||||
```bash
|
||||
$ journalctl --user -u user_service
|
||||
# ...
|
||||
Jan 12 19:50:20 ubuntu systemd[1511]: Stopped Script Daemon For Test User Services.
|
||||
Jan 12 19:50:24 ubuntu systemd[1511]: Started Script Daemon For Test User Services.
|
||||
```
|
||||
|
||||
## 8\. Conclusion
|
||||
|
||||
In this article, we looked at user services managed by *systemd*.
|
||||
|
||||
First, we created a simple service and added it to the *systemd* using the administrator privilege. **Then, we managed the service as a non-sudoer thanks to the *user* option of *systemctl*.**
|
||||
|
||||
Subsequently, we took a look at the lifetime of service and learned how to start the service without login. Finally, we examined the service’s log.
|
||||
@@ -1,336 +0,0 @@
|
||||
---
|
||||
title: Customization of Asciidoctor PDF output
|
||||
source: https://www.wimdeblauwe.com/blog/2019/2019-12-20-customization-of-asciidoctor-pdf-output/
|
||||
tags:
|
||||
- IT/Development/Asciidoctor
|
||||
- IT/Development/Maven
|
||||
- IT/Format/PDF
|
||||
---
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| | This blog post was written for asciidoctor-pdf 1.x. If you are using asciidoctor-pdf 2.x, then be aware that you need to use `pdf-themesdir` and `pdf-theme` in the Maven configuration.<br><br>So replace:<br><br>```<br><attributes><br> <pdf-stylesdir>${project.basedir}/src/main/asciidoc/theme</pdf-stylesdir><br> <pdf-style>pegus-digital</pdf-style><br></attributes><br>```<br><br>with:<br><br>```<br><attributes><br> <pdf-themesdir>${project.basedir}/src/main/asciidoc/theme</pdf-themesdir><br> <pdf-theme>pegus-digital</pdf-theme><br></attributes><br>``` |
|
||||
|
||||
Using [Asciidoc](http://asciidoc.org/) (the markup language) with the [Asciidoctor](https://asciidoctor.org/) toolchain is one of our favorite ways to write documentation. We mainly use it to create API documentation from our REST API backends using [Spring REST Docs](https://spring.io/projects/spring-restdocs).
|
||||
|
||||
Asciidoctor supports a variety of output formats, where HTML and PDF are ones we used the most. While the default PDF output already looks very good, it is always nice to be able customize the output a bit to better align with the project the documentation is created for. This post will explain exactly how to do that.
|
||||
|
||||
To get started, we’ll create a simple Maven project to generate the PDF output. First, create a `pom.xml` file with this contents to configure the asciidoctor-maven-plugin:
|
||||
|
||||
```xml
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
<groupId>digital.pegus.blog.examples</groupId>
|
||||
<artifactId>asciidoctor-custom-pdf</artifactId>
|
||||
<version>0.0.1-SNAPSHOT</version>
|
||||
<name>asciidoctor-custom-pdfemo</name>
|
||||
<description>Demo project that shows how to customize the PDF output of Asciidoctor</description>
|
||||
<properties>
|
||||
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
|
||||
<java.version>11</java.version>
|
||||
<asciidoctor-maven-plugin.version>1.6.0</asciidoctor-maven-plugin.version>
|
||||
</properties>
|
||||
<build>
|
||||
<plugins>
|
||||
<plugin>
|
||||
<groupId>org.asciidoctor</groupId>
|
||||
<artifactId>asciidoctor-maven-plugin</artifactId>
|
||||
<version>${asciidoctor-maven-plugin.version}</version>
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.asciidoctor</groupId>
|
||||
<artifactId>asciidoctorj-pdf</artifactId>
|
||||
<version>1.5.0-beta.5</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
<executions>
|
||||
<execution>
|
||||
<id>generate-docs-pdf</id>
|
||||
<phase>prepare-package</phase>
|
||||
<goals>
|
||||
<goal>process-asciidoc</goal>
|
||||
</goals>
|
||||
<configuration>
|
||||
<backend>pdf</backend>
|
||||
</configuration>
|
||||
</execution>
|
||||
</executions>
|
||||
</plugin>
|
||||
</plugins>
|
||||
</build>
|
||||
</project>
|
||||
```
|
||||
|
||||
Next to that, create a `Documentation.adoc` file in the `src/main/asciidoc` directory as that is the default directory where `asciidoctor-maven-plugin` will look for source files. Fill it up with some content you have, or just add some dummy content.
|
||||
|
||||
Now run `mvn package` and a `Documentation.pdf` should get generated at `target/generated-docs`. In my example, this was my asciidoc source:
|
||||
|
||||
```asciidoc
|
||||
= Example Documentation
|
||||
:icons: font
|
||||
:toc:
|
||||
:toclevels: 3
|
||||
:numbered:
|
||||
|
||||
== This is a chapter in the documentation
|
||||
|
||||
There is some content here
|
||||
|
||||
=== This is a sub-chapter
|
||||
|
||||
Some dummy content
|
||||
|
||||
== This is another chapter
|
||||
```
|
||||
|
||||
Which generated this PDF:
|
||||
|
||||

|
||||
|
||||
This is not too bad, but there are some customizations we would like to apply:
|
||||
|
||||
- Make it more like a book with a title page and a separate table of contents
|
||||
|
||||
- Change the footer to include the name of the current chapter next to the page number
|
||||
|
||||
- Add a header with a logo and the document title
|
||||
|
||||
- Change the font
|
||||
|
||||
|
||||
## Making it a book
|
||||
|
||||
Asciidoctor has the concept of documentation types which can be article, book, inline or manpage. By default, `article` is used, but we want to change this to `book`. There are 2 ways to do this:
|
||||
|
||||
- Add the `:doctype: book` declaration at the start of the document
|
||||
|
||||
- Add `<doctype>book</doctype>` in the `<configuration/>` section of the `asciidoctor-maven-plugin`
|
||||
|
||||
|
||||
Just choose one of the methods, no need to apply both ways. Regenerate the PDF output and you’ll notice that there is now a title page, a TOC starting on a new page, and each chapter also starting on a new page.
|
||||
|
||||
### Maven configuration
|
||||
|
||||
We will first setup a custom theme for the PDF export in order to do our customizations. Start with creating a new configuration file `src/main/asciidoc/theme/pegus-digital-theme.yml`. The name of the config file can be anything you want, but it should end with `-theme`.
|
||||
|
||||
To have the `asciidoctor-maven-plugin` use the theme, we need to configure 2 attributes in the `pom.xml`:
|
||||
|
||||
```xml
|
||||
<configuration>
|
||||
<doctype>book</doctype>
|
||||
<backend>pdf</backend>
|
||||
<attributes>
|
||||
<pdf-stylesdir>${project.basedir}/src/main/asciidoc/theme</pdf-stylesdir>
|
||||
<pdf-style>pegus-digital</pdf-style>
|
||||
</attributes>
|
||||
</configuration>
|
||||
```
|
||||
|
||||
Note that the `<pdf-style>` attribute is using the name of the YAML configuration file *without* the `-theme` part.
|
||||
|
||||
### Theme configuration
|
||||
|
||||
If wanted, the theme file can contain a complete new styling for the PDF export, but in this case, we just want to do some customizations on top of the default theme. To do this, just add the following in the YAML file:
|
||||
|
||||
In order to have our chapter title in the footer, we need to use this YAML configuration:
|
||||
|
||||
```yaml
|
||||
extends: default
|
||||
footer:
|
||||
recto:
|
||||
right:
|
||||
content: '{chapter-title}
|
||||
|
||||
|
|
||||
|
||||
*{page-number}*'
|
||||
```
|
||||
|
||||
This can be explained as follows:
|
||||
|
||||
- `footer`: we want to change the footer here. There is also a `header` key.
|
||||
|
||||
- `recto`: we want to change the so called "recto" pages, which in a book is normally the right page if you have the book open. There is also a `verso` key for the other (left) pages of the book.
|
||||
|
||||
- `right`: the footer is divided in 3 parts, we can add content `left`, `center` or `right`
|
||||
|
||||
- `{chapter-title}` and `{page-number}` are Asciidoc attributes that are available in the content of a footer. See the [Theming Guide](https://github.com/asciidoctor/asciidoctor-pdf/blob/v1.5.0.beta.5/docs/theming-guide.adoc#attribute-references) for other attributes that are available.
|
||||
|
||||
|
||||
Run `mvn package` again and the resulting PDF will have our updated footer:
|
||||
|
||||

|
||||
|
||||
You’ll notice that only page 1 has the footer. Page 2 has just the page number as this is the default. If we want the same on page 2, we need to define the `verso`:
|
||||
|
||||
```yaml
|
||||
extends: default
|
||||
footer:
|
||||
recto:
|
||||
right:
|
||||
content: '{chapter-title}
|
||||
|
||||
|
|
||||
|
||||
*{page-number}*'
|
||||
verso:
|
||||
left:
|
||||
content: '*{page-number}*
|
||||
|
||||
|
|
||||
|
||||
{chapter-title}'
|
||||
```
|
||||
|
||||
Note how we use `left` on the `verso` side and we inverted the order of the content so the page number is always on the "outside":
|
||||
|
||||

|
||||
|
||||
For the header, we want to have our logo in the top left corner and the title of the document in the center. To get started, we put our logo in the `src/main/asciidoc/theme` folder. In our example, it is called `pegus-digital-logo.png`. Add this to the `pegus-digital-theme.yml` file:
|
||||
|
||||
```yaml
|
||||
header:
|
||||
height: $base_line_height_length * 3
|
||||
recto:
|
||||
left:
|
||||
content: image:pegus-digital-logo.png[width=120]
|
||||
center:
|
||||
content: '{document-title}'
|
||||
```
|
||||
|
||||
What we have in the configuration is:
|
||||
|
||||
- `height`: set the height of the header. By default, the header is limited in height and not enough to display the logo.
|
||||
|
||||
- `image` declaration in the `left`/`content` section. We can tweak the size of the image with the `width` declaration on the image.
|
||||
|
||||
- `{document-title}` in the `center` of the header
|
||||
|
||||
|
||||
The resulting PDF looks like this:
|
||||
|
||||

|
||||
|
||||
So we have the content in the header we want, but the styling could be a bit better. We will add a small line beneath the header to offset it from the main content and adjust the page margins so the content is not so close to the header as it is now:
|
||||
|
||||
```yaml
|
||||
page:
|
||||
margin: [0.7in, 0.67in, 0.67in, 0.67in]
|
||||
header:
|
||||
height: $base_line_height_length * 3.5
|
||||
border_color: dddddd
|
||||
border_width: 0.25
|
||||
recto:
|
||||
left:
|
||||
content: image:pegus-digital-logo.png[width=120]
|
||||
center:
|
||||
content: '{document-title}'
|
||||
```
|
||||
|
||||
We are using inches for the margins because the default stylesheet also uses inches, but there are different [measurement units](https://github.com/asciidoctor/asciidoctor-pdf/blob/v1.5.0.beta.5/docs/theming-guide.adoc#measurement-units) that you can use. The resulting PDF:
|
||||
|
||||

|
||||
|
||||
Again, we only have this on the recto pages since we defined it like that. If we want the verso pages to be exactly the same, we can refer to what we have on the recto side in the verso configuration:
|
||||
|
||||
```yaml
|
||||
header:
|
||||
height: $base_line_height_length * 3.5
|
||||
border_color: dddddd
|
||||
border_width: 0.25
|
||||
recto:
|
||||
left:
|
||||
content: image:pegus-digital-logo.png[width=120]
|
||||
center:
|
||||
content: '{document-title}'
|
||||
verso:
|
||||
left:
|
||||
content: $header_recto_left_content
|
||||
center:
|
||||
content: $header_recto_center_content
|
||||
```
|
||||
|
||||
Any key in the YAML configuration can be referenced with `$path_to_the_key`. In our example, it allows us to define the content for the header in 1 place.
|
||||
|
||||
With this, we have our header on the verso side as well:
|
||||
|
||||

|
||||
|
||||
## Custom font
|
||||
|
||||
The Theming Guide goes into great detail on how to use [custom fonts](https://github.com/asciidoctor/asciidoctor-pdf/blob/v1.5.0.beta.5/docs/theming-guide.adoc#custom-fonts) with the PDF export. To be absolutely sure your font will work in all conditions, you need to [prepare the font](https://github.com/asciidoctor/asciidoctor-pdf/blob/v1.5.0.beta.5/docs/theming-guide.adoc#appendix-a-preparing-a-custom-font). However, we just took a font from Google fonts and things just worked.
|
||||
|
||||
For our example, we will use [Open Sans](https://fonts.google.com/specimen/Open+Sans), a modern looking sans serif font. To get started, download the font and copy these 4 variants to `src/main/asciidoc/fonts` while renaming them:
|
||||
|
||||
- `OpenSans-Regular.ttf` → `opensans-normal.ttf`
|
||||
|
||||
- `OpenSans-Italic.ttf` → `opensans-italic.ttf`
|
||||
|
||||
- `OpenSans-Bold.ttf` → `opensans-bold.ttf`
|
||||
|
||||
- `OpenSans-BoldItalic.ttf` → `opensans-bold_italic.ttf`
|
||||
|
||||
|
||||
Configure `pdf-fontsdir` so the Maven plugin knows where to find the fonts:
|
||||
|
||||
```xml
|
||||
<configuration>
|
||||
<doctype>book</doctype>
|
||||
<backend>pdf</backend>
|
||||
<attributes>
|
||||
<pdf-stylesdir>${project.basedir}/src/main/asciidoc/theme</pdf-stylesdir>
|
||||
<pdf-style>pegus-digital</pdf-style>
|
||||
<pdf-fontsdir>${project.basedir}/src/main/asciidoc/fonts</pdf-fontsdir>
|
||||
</attributes>
|
||||
</configuration>
|
||||
```
|
||||
|
||||
Next, configure the fonts in the theme:
|
||||
|
||||
```yaml
|
||||
font:
|
||||
catalog:
|
||||
Noto Serif:
|
||||
normal: GEM_FONTS_DIR/notoserif-regular-subset.ttf
|
||||
bold: GEM_FONTS_DIR/notoserif-bold-subset.ttf
|
||||
italic: GEM_FONTS_DIR/notoserif-italic-subset.ttf
|
||||
bold_italic: GEM_FONTS_DIR/notoserif-bold_italic-subset.ttf
|
||||
# M+ 1mn supports ASCII and the circled numbers used for conums
|
||||
M+ 1mn:
|
||||
normal: GEM_FONTS_DIR/mplus1mn-regular-subset.ttf
|
||||
bold: GEM_FONTS_DIR/mplus1mn-bold-subset.ttf
|
||||
italic: GEM_FONTS_DIR/mplus1mn-italic-subset.ttf
|
||||
bold_italic: GEM_FONTS_DIR/mplus1mn-bold_italic-subset.ttf
|
||||
OpenSans:
|
||||
normal: opensans-normal.ttf
|
||||
italic: opensans-italic.ttf
|
||||
bold: opensans-bold.ttf
|
||||
bold_italic: opensans-bold_italic.ttf
|
||||
```
|
||||
|
||||
*Note that we need to declare the original fonts as well in the font catalog!*
|
||||
|
||||
Finally, use the declared font:
|
||||
|
||||
```yaml
|
||||
base:
|
||||
font_family: OpenSans
|
||||
heading:
|
||||
font-family: OpenSans
|
||||
h2:
|
||||
font-color: '#da3131'
|
||||
literal:
|
||||
font_color: '#da3131'
|
||||
```
|
||||
|
||||
This results in a PDF with the OpenSans font used:
|
||||
|
||||

|
||||
|
||||
We are here using OpenSans for the base content and the headings, but using the same mechanism, you can have different fonts for headings and content.
|
||||
|
||||
## Conclusion
|
||||
|
||||
This post has shown some of the most common customizations for the PDF export of Asciidoc documents so you can have the output branded for your company or customer.
|
||||
@@ -1,351 +0,0 @@
|
||||
---
|
||||
title: Customizing publishing
|
||||
source: https://docs.gradle.org/current/userguide/publishing_customization.html
|
||||
---
|
||||
|
||||
## [](#sec:adding-variants-to-existing-components)[Modifying and adding variants to existing components for publishing](#sec:adding-variants-to-existing-components)
|
||||
|
||||
Gradle’s publication model is based on the notion of *components*, which are defined by plugins. For example, the Java Library plugin defines a `java` component which corresponds to a library, but the Java Platform plugin defines another kind of component, named `javaPlatform`, which is effectively a different kind of software component (a *platform*).
|
||||
|
||||
Sometimes we want to add *more variants* to or modify *existing variants* of an existing component. For example, if you [added a variant of a Java library for a different platform](https://docs.gradle.org/current/userguide/cross_project_publications.html#targeting-different-platforms), you may just want to declare this additional variant on the `java` component itself. In general, declaring additional variants is often the best solution to publish *additional artifacts*.
|
||||
|
||||
To perform such additions or modifications, the `AdhocComponentWithVariants` interface declares two methods called `addVariantsFromConfiguration` and `withVariantsFromConfiguration` which accept two parameters:
|
||||
|
||||
- the [outgoing configuration](https://docs.gradle.org/current/userguide/declaring_dependencies.html#sec:resolvable-consumable-configs) that is used as a variant source
|
||||
|
||||
- a customization action which allows you to *filter* which variants are going to be published
|
||||
|
||||
|
||||
To utilise these methods, you must make sure that the `SoftwareComponent` you work with is itself an `AdhocComponentWithVariants`, which is the case for the components created by the Java plugins (Java, Java Library, Java Platform). Adding a variant is then very simple:
|
||||
|
||||
Example 1. [Adding a variant to an existing software component](#ex-adding-a-variant-to-an-existing-software-component)
|
||||
|
||||
`Kotlin``Groovy`
|
||||
|
||||
InstrumentedJarsPlugin.kt
|
||||
|
||||
```
|
||||
val javaComponent = components.findByName("java")
|
||||
|
||||
as
|
||||
|
||||
AdhocComponentWithVariants javaComponent.addVariantsFromConfiguration(outgoing)
|
||||
|
||||
{
|
||||
|
||||
// dependencies for this variant are considered runtime dependencies mapToMavenScope("runtime")
|
||||
|
||||
// and also optional dependencies, because we don't want them to leak mapToOptional()
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
In other cases, you might want to modify a variant that was added by one of the Java plugins already. For example, if you activate publishing of Javadoc and sources, these become additional variants of the `java` component. If you only want to publish one of them, e.g. only Javadoc but no sources, you can modify the `sources` variant to not being published:
|
||||
|
||||
`Kotlin``Groovy`
|
||||
|
||||
build.gradle.kts
|
||||
|
||||
```
|
||||
java { withJavadocJar() withSourcesJar()
|
||||
|
||||
} val javaComponent = components["java"]
|
||||
|
||||
as
|
||||
|
||||
AdhocComponentWithVariants javaComponent.withVariantsFromConfiguration(configurations["sourcesElements"])
|
||||
|
||||
{ skip()
|
||||
|
||||
} publishing { publications { create<MavenPublication>("mavenJava")
|
||||
|
||||
{
|
||||
|
||||
from(components["java"])
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
## [](#sec:publishing-custom-components)[Creating and publishing custom components](#sec:publishing-custom-components)
|
||||
|
||||
In the [previous example](#sec:adding-variants-to-existing-components), we have demonstrated how to extend or modify an existing component, like the components provided by the Java plugins. But Gradle also allows you to build a custom component (not a Java Library, not a Java Platform, not something supported natively by Gradle).
|
||||
|
||||
To create a custom component, you first need to create an empty *adhoc* component. At the moment, this is only possible via a plugin because you need to get a handle on the [SoftwareComponentFactory](https://docs.gradle.org/current/javadoc/org/gradle/api/component/SoftwareComponentFactory.html) :
|
||||
|
||||
Example 3. [Injecting the software component factory](#ex-injecting-the-software-component-factory)
|
||||
|
||||
`Kotlin``Groovy`
|
||||
|
||||
InstrumentedJarsPlugin.kt
|
||||
|
||||
```
|
||||
class
|
||||
|
||||
InstrumentedJarsPlugin
|
||||
|
||||
@Inject constructor(
|
||||
|
||||
private val softwareComponentFactory:
|
||||
|
||||
SoftwareComponentFactory)
|
||||
|
||||
:
|
||||
|
||||
Plugin<Project>
|
||||
|
||||
{
|
||||
```
|
||||
|
||||
Declaring *what* a custom component publishes is still done via the [AdhocComponentWithVariants](https://docs.gradle.org/current/javadoc/org/gradle/api/component/AdhocComponentWithVariants.html) API. For a custom component, the first step is to create custom outgoing variants, following the instructions in [this chapter](https://docs.gradle.org/current/userguide/cross_project_publications.html#sec:variant-aware-sharing). At this stage, what you should have is variants which can be used in cross-project dependencies, but that we are now going to publish to external repositories.
|
||||
|
||||
Example 4. [Creating a custom, adhoc component](#ex-creating-a-custom-adhoc-component)
|
||||
|
||||
`Kotlin``Groovy`
|
||||
|
||||
InstrumentedJarsPlugin.kt
|
||||
|
||||
```
|
||||
// create an adhoc component val adhocComponent = softwareComponentFactory.adhoc("myAdhocComponent")
|
||||
|
||||
// add it to the list of components that this project declares components.add(adhocComponent)
|
||||
|
||||
// and register a variant for publication adhocComponent.addVariantsFromConfiguration(outgoing)
|
||||
|
||||
{ mapToMavenScope("runtime")
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
First we use the factory to create a new adhoc component. Then we add a variant through the `addVariantsFromConfiguration` method, which is described in more detail in the [previous section](#sec:adding-variants-to-existing-components).
|
||||
|
||||
In simple cases, there’s a one-to-one mapping between a `Configuration` and a variant, in which case you can publish all variants issued from a single `Configuration` because they are effectively the same thing. However, there are cases where a `Configuration` is associated with additional [configuration publications](https://docs.gradle.org/current/javadoc/org/gradle/api/artifacts/ConfigurationPublications.html) that we also call *secondary variants*. Such configurations make sense in the [cross-project publications](https://docs.gradle.org/current/userguide/cross_project_publications.html#cross_project_publications) use case, but not when publishing externally. This is for example the case when between projects you share a *directory of files*, but there’s no way you can publish a *directory* directly on a Maven repository (only packaged things like jars or zips). Look at the [ConfigurationVariantDetails](https://docs.gradle.org/current/javadoc/org/gradle/api/component/ConfigurationVariantDetails.html) class for details about how to skip publication of a particular variant. If `addVariantsFromConfiguration` has already been called for a configuration, further modification of the resulting variants can be performed using `withVariantsFromConfiguration`.
|
||||
|
||||
When publishing an adhoc component like this:
|
||||
|
||||
- Gradle Module Metadata will *exactly* represent the published variants. In particular, all outgoing variants will inherit dependencies, artifacts and attributes of the published configuration.
|
||||
|
||||
- Maven and Ivy metadata files will be generated, but you need to declare how the dependencies are mapped to Maven scopes via the [ConfigurationVariantDetails](https://docs.gradle.org/current/javadoc/org/gradle/api/component/ConfigurationVariantDetails.html) class.
|
||||
|
||||
|
||||
In practice, it means that components created this way can be consumed by Gradle the same way as if they were "local components".
|
||||
|
||||
## [](#sec:publishing_custom_artifacts_to_maven)[Adding custom artifacts to a publication](#sec:publishing_custom_artifacts_to_maven)
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| | Instead of thinking in terms of artifacts, you should embrace the variant aware model of Gradle. It is expected that a single module may need multiple artifacts. However this rarely stops there, if the additional artifacts represent an [optional feature](https://docs.gradle.org/current/userguide/feature_variants.html#feature_variants), they might also have different dependencies and more.<br><br>Gradle, via *Gradle Module Metadata*, supports the publication of *additional variants* which make those artifacts known to the dependency resolution engine. Please refer to the [variant-aware sharing](https://docs.gradle.org/current/userguide/cross_project_publications.html#sec:variant-aware-sharing) section of the documentation to see how to declare such variants and [check out how to publish custom components](#sec:publishing-custom-components).<br><br>If you attach extra artifacts to a publication directly, they are published "out of context". That means, they are not referenced in the metadata at all and can then only be addressed directly through a classifier on a dependency. In contrast to Gradle Module Metadata, Maven pom metadata will not contain information on additional artifacts regardless of whether they are added through a variant or directly, as variants cannot be represented in the pom format. |
|
||||
|
||||
The following section describes how you publish artifacts directly if you are sure that metadata, for example Gradle or POM metadata, is irrelevant for your use case. For example, if your project doesn’t need to be consumed by other projects and the only thing required as result of the publishing are the artifacts themselves.
|
||||
|
||||
In general, there are two options:
|
||||
|
||||
- Create a publication only with artifacts
|
||||
|
||||
- Add artifacts to a publication based on a component with metadata (not recommended, instead [adjust a component](#sec:adding-variants-to-existing-components) or use a [adhoc component publication](#sec:publishing-custom-components) which will both also produce metadata fitting your artifacts)
|
||||
|
||||
|
||||
To create a publication based on artifacts, start by defining a custom artifact and attaching it to a Gradle [configuration](https://docs.gradle.org/current/userguide/dependency_management_terminology.html#sub:terminology_configuration) of your choice. The following sample defines an RPM artifact that is produced by an `rpm` task (not shown) and attaches that artifact to the `archives` configuration:
|
||||
|
||||
Example 5. [Defining a custom artifact for a configuration](#ex-defining-a-custom-artifact-for-a-configuration)
|
||||
|
||||
`Kotlin``Groovy`
|
||||
|
||||
build.gradle.kts
|
||||
|
||||
```
|
||||
val rpmFile = layout.buildDirectory.file("rpms/my-package.rpm") val rpmArtifact = artifacts.add("archives", rpmFile.get().asFile)
|
||||
|
||||
{ type =
|
||||
|
||||
"rpm" builtBy("rpm")
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
The `artifacts.add()` method — from [ArtifactHandler](https://docs.gradle.org/current/dsl/org.gradle.api.artifacts.dsl.ArtifactHandler.html) — returns an artifact object of type [PublishArtifact](https://docs.gradle.org/current/javadoc/org/gradle/api/artifacts/PublishArtifact.html) that can then be used in defining a publication, as shown in the following sample:
|
||||
|
||||
Example 6. [Attaching a custom PublishArtifact to a publication](#ex-attaching-a-custom-publishartifact-to-a-publication)
|
||||
|
||||
`Kotlin``Groovy`
|
||||
|
||||
build.gradle.kts
|
||||
|
||||
```
|
||||
publishing { publications { create<MavenPublication>("maven")
|
||||
|
||||
{ artifact(rpmArtifact)
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
- The `artifact()` method accepts *publish artifacts* as argument — like `rpmArtifact` in the sample — as well as any type of argument accepted by [Project.file(java.lang.Object)](https://docs.gradle.org/current/dsl/org.gradle.api.Project.html#org.gradle.api.Project:file%28java.lang.Object%29), such as a `File` instance, a string file path or a archive task.
|
||||
|
||||
- Publishing plugins support different artifact configuration properties, so always check the plugin documentation for more details. The `classifier` and `extension` properties are supported by both the [Maven Publish Plugin](https://docs.gradle.org/current/userguide/publishing_maven.html#publishing_maven) and the [Ivy Publish Plugin](https://docs.gradle.org/current/userguide/publishing_ivy.html#publishing_ivy).
|
||||
|
||||
- Custom artifacts need to be distinct within a publication, typically via a unique combination of `classifier` and `extension`. See the documentation for the plugin you’re using for the precise requirements.
|
||||
|
||||
- If you use `artifact()` with an archive task, Gradle automatically populates the artifact’s metadata with the `classifier` and `extension` properties from that task.
|
||||
|
||||
|
||||
Now you can publish the RPM.
|
||||
|
||||
If you really want to add an artifact to a publication based on a component, instead of [adjusting the component](#sec:adding-variants-to-existing-components) itself, you can combine the `from components.someComponent` and `artifact someArtifact` notations.
|
||||
|
||||
## [](#sec:publishing_maven:conditional_publishing)[Restricting publications to specific repositories](#sec:publishing_maven:conditional_publishing)
|
||||
|
||||
When you have defined multiple publications or repositories, you often want to control which publications are published to which repositories. For instance, consider the following sample that defines two publications — one that consists of just a binary and another that contains the binary and associated sources — and two repositories — one for internal use and one for external consumers:
|
||||
|
||||
Example 7. [Adding multiple publications and repositories](#ex-adding-multiple-publications-and-repositories)
|
||||
|
||||
`Kotlin``Groovy`
|
||||
|
||||
build.gradle.kts
|
||||
|
||||
```
|
||||
publishing { publications { create<MavenPublication>("binary")
|
||||
|
||||
{
|
||||
|
||||
from(components["java"])
|
||||
|
||||
} create<MavenPublication>("binaryAndSources")
|
||||
|
||||
{
|
||||
|
||||
from(components["java"]) artifact(tasks["sourcesJar"])
|
||||
|
||||
}
|
||||
|
||||
} repositories {
|
||||
|
||||
// change URLs to point to your repos, e.g. http://my.org/repo maven { name =
|
||||
|
||||
"external" url = uri(layout.buildDirectory.dir("repos/external"))
|
||||
|
||||
} maven { name =
|
||||
|
||||
"internal" url = uri(layout.buildDirectory.dir("repos/internal"))
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
The publishing plugins will create tasks that allow you to publish either of the publications to either repository. They also attach those tasks to the `publish` aggregate task. But let’s say you want to restrict the binary-only publication to the external repository and the binary-with-sources publication to the internal one. To do that, you need to make the publishing *conditional*.
|
||||
|
||||
Gradle allows you to skip any task you want based on a condition via the [Task.onlyIf(String, org.gradle.api.specs.Spec)](https://docs.gradle.org/current/dsl/org.gradle.api.Task.html#org.gradle.api.Task:onlyIf%28java.lang.String,org.gradle.api.specs.Spec%29) method. The following sample demonstrates how to implement the constraints we just mentioned:
|
||||
|
||||
`Kotlin``Groovy`
|
||||
|
||||
build.gradle.kts
|
||||
|
||||
```
|
||||
tasks.withType<PublishToMavenRepository>().configureEach { val predicate = provider {
|
||||
|
||||
(repository == publishing.repositories["external"]
|
||||
|
||||
&& publication == publishing.publications["binary"])
|
||||
|
||||
||
|
||||
|
||||
(repository == publishing.repositories["internal"]
|
||||
|
||||
&& publication == publishing.publications["binaryAndSources"])
|
||||
|
||||
} onlyIf("publishing binary to the external repository, or binary and sources to the internal one")
|
||||
|
||||
{ predicate.get()
|
||||
|
||||
}
|
||||
|
||||
} tasks.withType<PublishToMavenLocal>().configureEach { val predicate = provider { publication == publishing.publications["binaryAndSources"]
|
||||
|
||||
} onlyIf("publishing binary and sources")
|
||||
|
||||
{ predicate.get()
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Output of `gradle publish`
|
||||
|
||||
\> gradle publish
|
||||
\> Task :compileJava
|
||||
\> Task :processResources
|
||||
\> Task :classes
|
||||
\> Task :jar
|
||||
\> Task :generateMetadataFileForBinaryAndSourcesPublication
|
||||
\> Task :generatePomFileForBinaryAndSourcesPublication
|
||||
\> Task :sourcesJar
|
||||
\> Task :publishBinaryAndSourcesPublicationToExternalRepository SKIPPED
|
||||
\> Task :publishBinaryAndSourcesPublicationToInternalRepository
|
||||
\> Task :generateMetadataFileForBinaryPublication
|
||||
\> Task :generatePomFileForBinaryPublication
|
||||
\> Task :publishBinaryPublicationToExternalRepository
|
||||
\> Task :publishBinaryPublicationToInternalRepository SKIPPED
|
||||
\> Task :publish
|
||||
|
||||
BUILD SUCCESSFUL in 0s
|
||||
10 actionable tasks: 10 executed
|
||||
|
||||
You may also want to define your own aggregate tasks to help with your workflow. For example, imagine that you have several publications that should be published to the external repository. It could be very useful to publish all of them in one go without publishing the internal ones.
|
||||
|
||||
The following sample demonstrates how you can do this by defining an aggregate task — `publishToExternalRepository` — that depends on all the relevant publish tasks:
|
||||
|
||||
Example 9. [Defining your own shorthand tasks for publishing](#ex-defining-your-own-shorthand-tasks-for-publishing)
|
||||
|
||||
`Kotlin``Groovy`
|
||||
|
||||
build.gradle.kts
|
||||
|
||||
```
|
||||
tasks.register("publishToExternalRepository")
|
||||
|
||||
{
|
||||
|
||||
group
|
||||
|
||||
=
|
||||
|
||||
"publishing" description =
|
||||
|
||||
"Publishes all Maven publications to the external Maven repository." dependsOn(tasks.withType<PublishToMavenRepository>().matching { it.repository == publishing.repositories["external"]
|
||||
|
||||
})
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
## [](#sec:configuring_publishing_tasks)[Configuring publishing tasks](#sec:configuring_publishing_tasks)
|
||||
|
||||
The publishing plugins create their non-aggregate tasks after the project has been evaluated, which means you cannot directly reference them from your build script. If you would like to configure any of these tasks, you should use deferred task configuration. This can be done in a number of ways via the project’s `tasks` collection.
|
||||
|
||||
For example, imagine you want to change where the `generatePomFileForPubNamePublication` tasks write their POM files. You can do this by using the [TaskCollection.withType(java.lang.Class)](https://docs.gradle.org/current/javadoc/org/gradle/api/tasks/TaskCollection.html#withType-java.lang.Class-) method, as demonstrated by this sample:
|
||||
|
||||
`Kotlin``Groovy`
|
||||
|
||||
build.gradle.kts
|
||||
|
||||
```
|
||||
tasks.withType<GenerateMavenPom>().configureEach { val matcher =
|
||||
|
||||
Regex("""generatePomFileFor(\w+)Publication""").matchEntire(name) val publicationName = matcher?.let
|
||||
|
||||
{ it.groupValues[1]
|
||||
|
||||
} destination = layout.buildDirectory.file("poms/${publicationName}-pom.xml").get().asFile }
|
||||
```
|
||||
|
||||
The above sample uses a regular expression to extract the name of the publication from the name of the task. This is so that there is no conflict between the file paths of all the POM files that might be generated. If you only have one publication, then you don’t have to worry about such conflicts since there will only be one POM file.
|
||||
@@ -1,96 +0,0 @@
|
||||
---
|
||||
title: README.md · master · InstitutMaupertuis
|
||||
source: https://gitlab.com/InstitutMaupertuis/mattermost-old-messages/blob/master/README.md
|
||||
tags:
|
||||
- IT/Tools/Gitlab
|
||||
- IT/Tools/Mattermost
|
||||
---
|
||||
|
||||
This guide will help you delete old messages and attachments from your Mattermost Open Source edition server.
|
||||
|
||||
This procedure is very similar to what the [data retention](https://docs.mattermost.com/administration/data-retention.html) option of Mattermost `Enterprise Edition E20` does.
|
||||
|
||||
⚠ Run this at your own risk! I strongly suggest making a backup of your Mattermost directories and MySQL database before running these commands ⚠
|
||||
|
||||
This will be the limit date for the messages to keep (messages before this date will be deleted). Use [https://www.epochconverter.com/](https://www.epochconverter.com/) or Unix commands to generate the timestamp for your date.
|
||||
|
||||
* For example: `1527811200` corresponds to the first of june 2018.
|
||||
* In Mattermost database timestamps are stored with sub seconds accuracy so you need to multiply this timestamp by 1000 for later use.
|
||||
|
||||
In this example we will use `1527811200000`, tweak the commands with your own timestamp.
|
||||
|
||||
## [](#list-old-messages-attachments)List old messages / attachments
|
||||
|
||||
Open the MySQL prompt on your server and issue these queries
|
||||
|
||||
USE mattermost;
|
||||
SELECT * FROM FileInfo WHERE CreateAt < 1527811200000 LIMIT 10;
|
||||
SELECT * FROM Posts WHERE CreateAt < 1527811200000 LIMIT 10;
|
||||
|
||||
You should see information about the files / messages, this only lists 10 results.
|
||||
|
||||
If you get an empty set make sure you have the right timestamp (multiplied by 1000)
|
||||
|
||||
## [](#delete-old-messages-attachments)Delete old messages / attachments
|
||||
|
||||
### [](#mysql-configuration)MySQL configuration
|
||||
|
||||
Edit `/etc/mysql/mysql.conf.d/mysqld.cnf` and add at the end
|
||||
|
||||
secure_file_priv=""
|
||||
|
||||
Restart MySQL
|
||||
|
||||
sudo service mysql restart
|
||||
|
||||
This will allow us to dump the results of a query into a file on the disk.
|
||||
|
||||
### [](#get-a-list-of-the-attachments)Get a list of the attachments
|
||||
|
||||
* Tweak the user and password corresponding to your credentials.
|
||||
* This will create a temporary directory with a file inside containing the path of each attachment that is to be removed
|
||||
|
||||
#!/bin/bash
|
||||
sudo mkdir /tmp/mysqldump/
|
||||
sudo chown -R mysql:mysql /tmp/mysqldump/
|
||||
sudo rm /tmp/mysqldump/*
|
||||
mysql -u user -p'password' -D mattermost -e "SELECT Path FROM FileInfo \
|
||||
WHERE CreateAt < 1527811200000 \
|
||||
INTO OUTFILE '/tmp/mysqldump/uploaded_files.txt' \
|
||||
FIELDS TERMINATED BY ',' \
|
||||
ENCLOSED BY '' \
|
||||
LINES TERMINATED BY '\n';"
|
||||
|
||||
### [](#script-to-delete-the-attachments)Script to delete the attachments
|
||||
|
||||
Create an executable script with the following content, tweak the `/opt/mattermost/data` with your installation directory of Mattermost.
|
||||
|
||||
#!/bin/bash
|
||||
input="/tmp/mysqldump/uploaded_files.txt"
|
||||
while IFS= read -r line
|
||||
do
|
||||
rm "/opt/mattermost/data/$line"
|
||||
done < "$input"
|
||||
|
||||
Run this script as root to delete the attachments files.
|
||||
|
||||
You can now delete the list of files
|
||||
|
||||
sudo rm -Rf /tmp/mysqldump/
|
||||
|
||||
### [](#delete-the-database-entries)Delete the database entries
|
||||
|
||||
This will delete all the messages/attachments in the database
|
||||
|
||||
mysql -u user -p'password' -D mattermost -e "DELETE FROM FileInfo WHERE CreateAt < 1527811200000;"
|
||||
mysql -u user -p'password' -D mattermost -e "DELETE FROM Posts WHERE CreateAt < 1527811200000;"
|
||||
|
||||
### [](#configuration-mysql)Configuration MySQL
|
||||
|
||||
We can now revert the MySQL configuration at `/etc/mysql/mysql.conf.d/mysqld.cnf`, comment
|
||||
|
||||
#secure_file_priv=""
|
||||
|
||||
Restart MySQL
|
||||
|
||||
sudo service mysql restart
|
||||
@@ -1,568 +0,0 @@
|
||||
---
|
||||
title: Deprecated Linux networking commands and their replacements | Doug Vitale Tech Blog
|
||||
source: https://dougvitale.wordpress.com/2011/12/21/deprecated-linux-networking-commands-and-their-replacements/
|
||||
---
|
||||
|
||||
# [Doug Vitale Tech Blog](https://dougvitale.wordpress.com/)
|
||||
|
||||
## Deprecated Linux networking commands and their replacements
|
||||
|
||||
In my [article](https://dougvitale.wordpress.com/2011/12/11/troubleshooting-faulty-network-connectivity-part-2-essential-network-commands/ "Troubleshooting faulty network connectivity, part 2: Essential network commands") detailing the command line utilities available for configuring and troubleshooting network properties on Windows and Linux, I mentioned some Linux tools that, while still included and functional in many Linux distributions, are actually considered [deprecated](http://en.wikipedia.org/wiki/Deprecation "Deprecation on Wikipedia") and therefore should be phased out in favor of more modern replacements.
|
||||
|
||||
Specifically, the deprecated Linux networking commands in question are: **arp**, **ifconfig**, **iptunnel**, **iwconfig**, **nameif**, **netstat**, and **route**. These programs (except **iwconfig**) are included in the [net-tools](http://www.linuxfoundation.org/collaborate/workgroups/networking/net-tools "net-tools on the Linux Foundation") package that has been unmaintained for years. The functionality provided by several of these utilities has been reproduced and improved in the new [iproute2](http://en.wikipedia.org/wiki/Iproute2 "iproute2 on Wikipedia") suite, primarily by using its new **ip** command. The **iproute2** software code is available from [Kernel.org](http://www.kernel.org/pub/linux/utils/net/iproute2/ "Iproute2 on kernel.org"). **Iproute2** documentation is available from [the Linux Foundation](http://www.linuxfoundation.org/collaborate/workgroups/networking/iproute2) and [PolicyRouting.org](http://www.policyrouting.org/iproute2-toc.html "IProute2 utility suite how-to on policyrouting.org").
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| ### **Deprecated command** | ### **Replacement command(s)** |
|
||||
| --- | --- |
|
||||
| **arp** | **ip n** (**ip neighbor)** |
|
||||
| **ifconfig** | **ip a** (**ip addr**), **ip link**, **ip -s** (**ip -stats)** |
|
||||
| **iptunnel** | **ip tunnel** |
|
||||
| **iwconfig** | **iw** |
|
||||
| **nameif** | **ip link**, **ifrename** |
|
||||
| **netstat** | **ss**, **ip route** (for **netstat-r**), **ip -s link** (for **netstat -i**), **ip maddr** (for **netstat-g**) |
|
||||
| **route** | **ip r** (**ip route**) |
|
||||
|
||||
.
|
||||
Now let’s take a closer look at these deprecated commands and their replacements.
|
||||
|
||||
This article will not focus on **iproute2** or the **ip** command in detail; instead it will simply give one-to-one mappings between the deprecated commands and their new counterparts. For replacement commands that are listed as ‘not apparent’, please [contact me](https://dougvitale.wordpress.com/contact/ "Contact") if you know otherwise.
|
||||
|
||||
**Jump to:**
|
||||
|
||||
* [Arp](#arp)
|
||||
* [Ifconfig](#ifconfig)
|
||||
* [Iptunnel](#iptunnel)
|
||||
* [Iwconfig](#iwconfig)
|
||||
* [Nameif](#nameif)
|
||||
* [Netstat](#netstat)
|
||||
* [Route](#route)
|
||||
* [Discussion](#discussion)
|
||||
* [Recommended reading](#recommended)
|
||||
|
||||
Please note that **nslookup** and **dig** are covered separately [here](https://dougvitale.wordpress.com/2011/12/11/troubleshooting-faulty-network-connectivity-part-2-essential-network-commands/#nslookup "Troubleshooting faulty network connectivity, part 2: Essential network commands").
|
||||
|
||||
## Arp
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| ### **Deprecated arp commands** | ### **Replacement** |
|
||||
| --- | --- |
|
||||
| **arp -a \[host\]** or **`--`all \[host\]** <br>. <br>Shows the entries of the specified host name or IP address. If the **\[host\]** parameter is not used, all entries will be displayed. | **ip n** (or **ip neighbor**), or **ip n show** |
|
||||
| **arp -d \[ip_addr\]** or **`--`delete \[ip_addr\]** <br>. <br>Removes the ARP cache entry for the specified host. | **ip n del \[ip_addr\]** (this “invalidates” neighbor entries)** <br>. <br>ip n f \[ip_addr\]** (or **ip n flush \[ip_addr\]**) |
|
||||
| **arp -D** or **`--`use-device** <br>. <br>Uses the hardware address associated with the specified interface. | Not apparent |
|
||||
| **arp -e** <br>. <br>Shows the entries in default (Linux) style. | Not apparent |
|
||||
| **arp -f \[filename\]** or **`--`file \[filename\]** <br>. <br>Similar to the **-s** option, only this time the address info is taken from the file that **\[filename\]** set up. If no **\[filename\]** is specified, _/etc/ethers_ is used as default. | Not apparent |
|
||||
| **arp -H** or **`--`hw-type \[type\]** or **-t \[type\]** <br>. <br>When setting or reading the ARP cache, this optional parameter tells **arp** which class of entries it should check for. The default value of this parameter is **ether** (i.e. hardware code 0x01 for IEEE 802.3 10Mbps Ethernet). | Not apparent |
|
||||
| **arp -i \[int\]** or **`--`device \[int\]** <br>. <br>Selects an interface. When dumping the ARP cache only entries matching the specified interface will be printed. For example, **arp -i eth0 -s 10.21.31.41 A321.ABCF.321A** creates a static ARP entry associating IP address 10.21.31.41 with MAC address A321.ABCF.321A on **eth0**. | **ip n \[add | chg | del | repl\] dev \[name\]** |
|
||||
| **arp -n** or **`--`numeric** <br>. <br>Shows IP addresses instead of trying to determine domain names. | Not apparent |
|
||||
| **arp -s \[ip\_addr\] \[hw\_addr\]** or **`--`set \[ip_addr\]** <br>. <br>Manually creates a static ARP address mapping entry for host **\[ip_addr\]** with the hardware address set to **\[hw_addr\]**. | **ip n add \[ip\_addr\] lladdr \[mac\_address\] dev \[device\] nud \[nud_state\]** (see example below) |
|
||||
| **arp -v** <br>. <br>Uses verbose mode to provide more details. | **ip -s n** (or **ip -stats n**) |
|
||||
|
||||
.
|
||||
Some **ip neighbor** examples are as follows:
|
||||
|
||||
`# ip n del 10.1.2.3 dev eth0`
|
||||
|
||||
Invalidates the ARP cache entry for host 10.1.2.3 on device **eth0**.
|
||||
|
||||
`# ip neighbor show dev eth0`
|
||||
|
||||
Shows the ARP cache for interface **eth0**.
|
||||
|
||||
`# ip n add 10.1.2.3 lladdr 1:2:3:4:5:6 dev eth0 nud perm`
|
||||
|
||||
Adds a “permanent” ARP cache entry for host 10.1.2.3 device **eth0**. The Neighbor Unreachability Detection (**nud**) state can be one of the following:
|
||||
|
||||
* **noarp** – entry is valid. No attempts to validate this entry will be made but it can be removed when its lifetime expires.
|
||||
* **permanent** – entry is valid forever and can be only be removed administratively.
|
||||
* **reachable** – entry is valid until the reachability timeout expires.
|
||||
* **stale** – entry is valid but suspicious.
|
||||
|
||||
## Ifconfig
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| ### **Deprecated ifconfig commands <br>** | ### **Replacement** |
|
||||
| --- | --- |
|
||||
| **ifconfig** <br>. <br>Displays details on all network interfaces. | **ip a** (or **ip addr**) |
|
||||
| **ifconfig \[interface\]** <br>. <br>The name of the interface. This is usually a driver name followed by a unit number; for example, **eth0** for the first Ethernet interface. **Eth0** will usually be a PC’s primary network interface card (NIC). | **ip a show dev \[interface\] <br>** |
|
||||
| **ifconfig \[address_family\]** <br>. <br>To enable the interpretation of differing naming schemes used by various protocols, **\[address_family\]** is used for decoding and displaying all protocol addresses. Currently supported address families include **inet** (TCP/IP, default), **inet6** (IPv6), **ax25** (AMPR Packet Radio), **ddp** (Appletalk Phase 2), **ipx** (Novell IPX) and **netrom** (AMPR Packet radio). | **ip -f \[family\] a**** <br>. <br>\[family\]** can be **inet** (IPv4), **inet6** (IPv6), or **link**. Additionally, **-4** = **-f inet** and **-6** = **-f inet6**. |
|
||||
| **ifconfig \[interface\] add \[address/prefixlength** <br>. <br>Adds an IPv6 address to the **\[interface\]**. | **ip a add \[ip_addr/mask\] dev \[interface\]** |
|
||||
| **ifconfig \[interface\] address \[address\] <br>. <br>**Assigns the specified IP **\[address\]** to the specified **\[interface\].** | **ip a add \[ip_addr/mask\] dev \[interface\]** |
|
||||
| **ifconfig \[interface\] allmulti** or **-allmulti** <br>. <br>Enables or disables all-multicast mode. If selected, all multicast packets on the network will be received by the **\[interface\]** specified. This enables or disables the sending of incoming frames to the kernel’s network layer. | **ip mr iif \[name\]** or **ip mroute iif \[name\]**, where **\[name\]** is the interface on which multicast packets are received. |
|
||||
| **ifconfig \[interface\] arp** or **-arp** <br>. <br>Enables or disables the use of the ARP protocol on this **\[interface\]**. | **ip link set arp on** or **arp off** |
|
||||
| **ifconfig \[interface\] broadcast \[address\]** <br>. <br>Specifies the address to use to use for broadcast transmissions. By default, the broadcast address for a subnet is the IP address with all ones in the host portion of the subnet address (i.e., _a.b.c.255_ for a /24 subnet). | **ip a add broadcast \[ip_address\]** <br>. <br>**ip link set dev \[interface\] broadcast \[mac_address\]** (sets the link layer broadcast address) |
|
||||
| **ifconfig \[interface\] del \[address/prefixlength\]** <br>. <br>Removes an IPv6 address from the **\[interface\]**, such as **eth0**. | **ip a del \[ipv6_addr** or **ipv4_addr\] dev \[interface\]** |
|
||||
| **ifconfig \[interface\] down** <br>. <br>Disables the **\[interface\]**, such as **eth0**. | **ip link set dev \[interface\] down** |
|
||||
| **ifconfig \[interface\] hw \[class\] \[address\]** <br>. <br>Sets the hardware (MAC) address of this **\[interface\]**, if the device driver supports this operation. The keyword _must_ be followed by the name of the hardware **\[class\]** and the printable ASCII equivalent of the hardware address. Hardware classes currently supported include **ether** (Ethernet), **ax25** (AMPR AX.25), **ARCnet** and **netrom** (AMPR NET/ROM). | **ip link set dev \[interface\] address \[mac_addr\]** |
|
||||
| **ifconfig \[interface\] io_addr \[address\]** <br>. <br>Sets the start **\[address\]** in [I/O space](http://www.techterms.com/definition/ioaddress "I/O Address on TechTerms") for this device. | Not apparent; possibly **ethtool**. |
|
||||
| **ifconfig \[interface\] irq \[address\]** <br>. <br>Sets the [interrupt line](http://en.wikipedia.org/wiki/Interrupt_request "IRQ on Wikipedia") used by the network interface. | Not apparent; possibly **ethtool**. |
|
||||
| **ifconfig \[interface\] mem_start \[address\]** <br>. <br>Sets the start address for [shared memory](http://en.wikipedia.org/wiki/Shared_memory "Shared memory on Wikipedia") of the interface. | Not apparent; possibly **ethtool**. |
|
||||
| **ifconfig \[interface\] media \[type\]** <br>. <br>Sets physical port or medium type. Examples of **\[type\]** are **10baseT**, **10base2**, and **AUI**. A **\[type\]** value of **auto** will tell the interface driver to automatically determine the media type (driver support for this command varies). | Not apparent; possibly **ethtool**. |
|
||||
| **ifconfig \[interface\] mtu \[n\]** <br>. <br>Sets the Maximum Transfer Unit ([MTU](http://en.wikipedia.org/wiki/Maximum_transmission_unit "MTU on Wikipedia")) of an interface to **\[n\]**. | **ip link set dev \[interface\] mtu \[n\]** |
|
||||
| **ifconfig \[interface\] multicast** <br>. <br>Sets the [multicast flag](http://en.wikipedia.org/wiki/Multicast_address "Multicast addressing on Wikipedia") on the interface (should not normally be needed as the drivers set the flag correctly themselves). | **ip link set dev \[interface\] multicast on** or **off** |
|
||||
| **ifconfig \[interface\] netmask \[mask_address\]** <br>. <br>Sets the _subnet mask_ (not the IP address) for this **\[interface\]**. This value defaults to the standard Class A, B, or C subnet masks (based on the interface IP address) but can be changed with this command. | Not apparent |
|
||||
| **ifconfig \[interface\] pointopoint** or **-pointopoint** <br>. <br>Enables or disables [point-to-point](http://en.wikipedia.org/wiki/Point-to-point_%28telecommunications%29 "Point-to-point on Wikipedia") mode on this **\[interface\]**. | not apparent; possibly **ipppd \[device\]**. The command **ip a add peer \[address\]** specifies the address of the remote endpoint for point-to-point interfaces. |
|
||||
| **ifconfig \[interface\] promisc** or **-promisc** <br>. <br>Enables or disables [promiscuous mode](http://en.wikipedia.org/wiki/Promiscuous_mode "Promiscuous mode on Wikipedia") on the **\[interface\]**. | **ip link set dev \[interface\] promisc on** or **off** |
|
||||
| **ifconfig \[interface\] txquelen \[n\]** <br>. <br>Sets the [transmit queue length](http://publib.boulder.ibm.com/infocenter/pseries/v5r3/index.jsp?topic=/com.ibm.aix.prftungd/doc/prftungd/transmit_queues.htm "Transmit queue length") on the **\[interface\]**. Smaller values are recommended for connections with high latency (i.e., dial-up modems, ISDN, etc). | **ip link set dev \[interface\] txqueuelen \[n\]** or **txqlen \[n\]** |
|
||||
| **ifconfig \[interface\] tunnel \[address\]** <br>. <br>Creates a Simple Internet Transition (IPv6-in-IPv4) device which tunnels to the IPv4 **\[address\]** provided. | **ip tunnel mode sit** (other possible modes are **ipip** and **gre)**. |
|
||||
| **ifconfig \[interface\] up** <br>. <br>Activates (enables) the **\[interface\]** specified. | **ip link set \[interface\] up** |
|
||||
|
||||
.
|
||||
Some examples illustrating the **ip** command are as follows; using the table above you should be able to figure out what they do.
|
||||
|
||||
`# ip link show dev eth0
|
||||
|
||||
# ip a add 10.11.12.13/8 dev eth0
|
||||
|
||||
# ip link set dev eth0 up
|
||||
|
||||
# ip link set dev eth0 mtu 1500
|
||||
|
||||
# ip link set dev eth0 address 00:70:b7:d6:cd:ef`
|
||||
|
||||
## Iptunnel
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| ### **Deprecated iptunnel commands** | ### **Replacement <br>** |
|
||||
| --- | --- |
|
||||
| **iptunnel \[add | change | del | show\]** | **ip tunnel a** or **add** <br>**ip tunnel chg** or **change** <br>**ip tunnel d** or **del** <br>**ip tunnel ls** or **show** |
|
||||
| **iptunnel add \[name\] \[mode {ipip | gre | sit} \] remote \[remote\_addr\] local \[local\_addr\]** | **ip tunnel add \[name\] \[mode {ipip | gre | sit | isatap | ip6in6 | ipip6 | any }\] remote \[remote\_addr\] local \[local\_addr\]** |
|
||||
| **iptunnel -V** or **`--`version** | not apparent |
|
||||
|
||||
.
|
||||
The syntax between **iptunnel** and **ip tunnel** is very similar as these examples show.
|
||||
|
||||
`# [iptunnel | ip tunnel] add ipip-tunl1 mode ipip remote 83.240.67.86` (_ipip-tunl1_ is the name of the tunnel, 83.240.67.86 is the IP address of the remote endpoint).
|
||||
|
||||
`# [iptunnel | ip tunnel] add ipi-tunl2 mode ipip remote 104.137.4.160 local 104.137.4.150 ttl 1
|
||||
|
||||
# [iptunnel | ip tunnel] add gre-tunl1 mode gre remote 192.168.22.17 local 192.168.10.21 ttl 255`
|
||||
|
||||
**Iptunnel** is covered in more depth [here](http://www.deepspace6.net/docs/iproute2tunnel-en.html).
|
||||
|
||||
## Iwconfig
|
||||
|
||||
**Iwconfig’s** successor, **iw**, is still in development. Official documentation for **iw** is available [here](http://linuxwireless.org/en/users/Documentation/iw) and [here](http://linuxwireless.org/en/users/Documentation/iw/replace-iwconfig).
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| ### **Deprecated iwconfig commands** | ### **Replacement** |
|
||||
| --- | --- |
|
||||
| **iwconfig** <br>. <br>Displays basic details about wireless interfaces, such as supported protocols ([802.11a/b/g/n](http://en.wikipedia.org/wiki/IEEE_802.11 "802.11 on Wikipedia")), Extended Service Set ID ([ESSID](http://en.wikipedia.org/wiki/Service_set_%28802.11_network%29 "Service Set Identifier on Wikipedia")), mode, and access point. To view these details about a particular interface, use **iwconfig \[interface\]** where the interface is the device name, such as **wlan0**. | **iw dev \[interface\] link** |
|
||||
| **iwconfig \[interface\] ap \[address\]** <br>. <br>Forces the wireless adapter to register with the access point given by the **\[address\]**, if possible. This address is the cell identity of the access point (as reported by wireless scanning) which may be different from its MAC address. | Not apparent |
|
||||
| **iwconfig commit** <br>. <br>Some wireless adapters may not apply changes immediately (they may wait to aggregate the changes, or apply them only when the card is brought up via **ifconfig**). This command (when available) forces the adapter to immediately apply all pending changes. | Not apparent |
|
||||
| **iwconfig \[interface\] essid \[name\]** <br>. <br>Connects to the WLAN with the ESSID **\[name\]** provided. With some wireless adapters, you can disable the ESSID checking (ESSID promiscuous) with **off** or **any** (and **on** to re-enable it). | **iw \[interface\] connect \[name\]** |
|
||||
| **iwconfig \[interface\] frag \[num\]** <br>. <br>Sets the maximum fragment size which is always lower than the maximum packet size. This parameter may also control Frame Bursting available on some wireless adapters (the ability to send multiple IP packets together). This mechanism would be enabled if the fragment size is larger than the maximum packet size. Other valid frag parameters to **auto**, **on**, and **off**. | Not apparent |
|
||||
| **iwconfig \[interface\] \[freq | channel\]** <br>. <br>Sets the operating frequency or channel on the wireless device. A value below 1000 indicates a channel number, a value greater than 1000 is a frequency in Hz. You can append the suffix **k**, **M** or **G** to the value (for example, “2.46G” for 2.46 GHz frequency). You may also use **off** or **auto** to let the adapter pick up the best channel (when supported). | **iw dev \[interface\] set freq \[freq\] \[HT20|HT40+|HT40-\]** <br>. <br>**iw dev \[interface\] set channel \[chan\] \[HT20|HT40+|HT40-\]** |
|
||||
| **iwconfig \[interface\] key \[key\] \[mode\] \[on | off\]** <br>. <br>To set the current encryption **\[key\]**, just enter the key in _hex_ digits as XXXX-XXXX-XXXX-XXXX or XXXXXXXX. You can also enter the key as an ASCII string by using the **s:** prefix. **On** and **off** re=enable and disable encryption. The security mode may be **open** or **restricted**, and its meaning depends on the card used. With most cards, in **open** mode no authentication is used and the card may also accept non-encrypted sessions, whereas in **restricted** mode only encrypted sessions are accepted and the card will use authentication if available. | **iw \[interface\] connect \[name\] keys \[key\]** (for WEP) <br>. <br>To connect to an AP with WPA or WPA2 encryption, you must use [wpa_supplicant](http://wireless.kernel.org/en/users/Documentation/wpa_supplicant). |
|
||||
| **iwconfig \[interface\] mode \[mode\]** <br>. <br>Sets the operating mode of the wireless device. The **\[mode\]** can be **Ad-Hoc**, **Auto**, **Managed**, **Master**, **Monitor, Repeater**, or **Secondary**.** <br>. <br>Ad-Hoc**: the network is composed of only one cell and without an access point. <br>**Managed**: the wireless node connects to a network composed of many access points, with roaming. <br>**Master**: the wireless node is the synchronization master, or it acts as an access point. <br>**Monitor**: the wireless node is not associated with any cell and passively monitors all packets on the frequency. <br>**Repeater**: the wireless node forwards packets between other wireless nodes. <br>**Secondary**: the wireless node acts as a backup master/repeater. | Not apparent |
|
||||
| **iwconfig \[interface\] modu \[modulation\]** <br>. <br>Forces the wireless adapter to use a specific set of modulations. Modern adapters support various modulations, such as 802.11b or 802.11g. The list of available modulations depends on the adapter/driver and can be displayed using **iwlist modulation**. Some options are **11g**, **CCK OFDMa**, and **auto**. | Not apparent |
|
||||
| **iwconfig \[interface\] nick \[name\]** <br>. <br>Sets the nick name (or station name). | Not apparent |
|
||||
| **iwconfig \[interface\] nwid \[name\] <br>. <br>**Sets the Network ID for the WLAN. _This parameter is only used for pre-802.11 hardware_ as the 802.11 protocol uses the ESSID and access point address for this function. With some wireless adapters, you can disable the Network ID checking (NWID promiscuous) with **off** (and **on** to re-enable it). | Not apparent |
|
||||
| **iwconfig \[interface\] power \[option\]** <br>**iwconfig \[interface\] power min | max \[secondsu | secondsm\]** <br>**iwconfig \[interface\] power mode \[mode\]** <br>**iwconfig \[interface\] power on | off** <br>. <br>Configures the power management scheme and mode. Valid **\[options\]** are: **period \[value\]** (sets the period between wake ups), **timeout \[value\]** (sets the timeout before going back to sleep), **saving \[value\]** (sets the generic level of power saving). <br>The **min** and **max** modifiers are in seconds by default, but append the suffices **m** or **u** to specify values in milliseconds or microseconds. <br>Valid **\[mode\]** options are: **all** (receive all packets), **unicast** (receive unicast packets only, discard multicast and broadcast) and **multicast** (receive multicast and broadcast only, discard unicast packets). <br>**On** and **off** re-enable or disable power management. | Not apparent; some power commands are: <br>. <br>**iw dev \[interface\] set power_save on** <br>. <br>**iw dev \[interface\] get power_save** |
|
||||
| **iwconfig \[interface\] rate/bit \[rate\]** <br>. <br>Sets the bit rate in bits per second for cards supporting multiple bit rates. The bit-rate is the speed at which bits are transmitted over the medium, the user speed of the link is lower due to medium sharing and various overhead.Suffixes **k**, **M** or **G** can be added to the numeric **\[rate\]** (decimal multiplier : 10^3, 10^6 and 10^9 b/s), or add ‘**0**‘ for enough. The **\[rate\]** can also be **auto** to select automatic bit-rate mode (fallback to lower rate on noisy channels), or **fixed** to revert back to fixed setting. If you specify a bit-rate numeric value and append **auto**, the driver will use all bit-rates lower and equal than this value. | **iw \[interface\] set bitrates legacy-2.4 12 18 24** |
|
||||
| **iwconfig \[interface\] retry \[option\] \[value\]** <br>. <br>To set the maximum number of retries (MAC retransmissions), enter **limit \[value\]**. To set the maximum length of time the MAC should retry, enter **lifetime \[value\]**. By default, this value is in seconds; append the suffices **m** or **u** to specify values in milliseconds or microseconds. You can also add the **short**, **long**, **min** and **max** modifiers. | Not apparent |
|
||||
| **iwconfig \[interface\] rts \[threshold\]** <br>. <br>Sets the size of the smallest packet for which the node sends RTS; a value equal to the maximum packet size disables the mechanism. You may also set the threshold parameter to **auto**, **fixed** or **off**. | Not apparent |
|
||||
| **iwconfig \[interface\] sens \[threshold\]** <br>. <br>Sets the sensitivity threshold (defines how sensitive the wireless adapter is to poor operating conditions such as low signal, signal interference, etc). Modern adapter designs seem to control these thresholds automatically. | Not apparent |
|
||||
| **iwconfig \[interface\] txpower \[value\]** <br>. <br>For adapters supporting multiple transmit powers, this sets the transmit power in dBm. If **W** is the power in Watt, the power in dBm is P = 30 + 10.log(W). If the **\[value\]** is postfixed by **mW**, it will be automatically converted to dBm. In addition, **on** and **off** enable and disable the radio, and **auto** and **fixed** enable and disable power control (if those features are available). | **iw dev \[interface\] set txpower \[auto | fixed | |limit\] \[tx power in mBm\]** <br>. <br>**iw phy \[phyname\] set txpower \[auto | fixed | limit\] \[tx power in mBm\]** |
|
||||
| **iwconfig `--`help** <br>. <br>Displays the iwconfig help message. | **iw help** |
|
||||
| **iwconfig `--`version** <br>. <br>Displays the version of iwconfig installed. | **iw `--`version** |
|
||||
|
||||
.
|
||||
Some examples of the **iw** command syntax are as follows.
|
||||
|
||||
`# iw dev wlan0 link
|
||||
|
||||
# iw wlan0 connect CoffeeShopWLAN
|
||||
|
||||
# iw wlan0 connect HomeWLAN keys 0:abcde d:1:0011223344` (for WEP)
|
||||
|
||||
## Nameif
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| ### **Deprecated nameif commands** | ### **Replacement** |
|
||||
| --- | --- |
|
||||
| **nameif \[name\] \[mac_address\]** <br>. <br>If no name and MAC address are provided, it attempts to read addresses from `/etc/mactab`. Each line of `mactab` should contain an interface name and MAC address (or comments starting with #). | **ip link set dev \[interface\] name \[name\] <br>. <br>ifrename -i \[interface\] -n \[newname\] <br>** |
|
||||
| **nameif -c \[config_file\]** <br>. <br>Reads from **\[config_file\]** instead of `/etc/mactab`. | **ifrename -c \[config_file\]** |
|
||||
| **nameif -s** <br>. <br>Error messages are sent to the syslog. | Not apparent |
|
||||
|
||||
## Netstat
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| ### **Deprecated netstat commands** | ### **Replacement** |
|
||||
| --- | --- |
|
||||
| **netstat -a** or **`--`all** <br>.Shows both listening and non-listening [sockets](http://en.wikipedia.org/wiki/Internet_socket "Sockets on Wikipedia"). | **ss -a** or **`--`all** |
|
||||
| **netstat -A** **\[family\]** or **`--`protocol=\[family\]** <br>. <br>Specifies the address families for which connections are to be shown. **\[family\]** is a comma separated list of address family keywords like **inet**, **unix**, **ipx**, **ax25**, **netrom**, and **ddp**. This has the same effect as using the **`--`inet**, **`--`unix (-x)**, **`--`ipx**, **`--`ax25**, **`--`netrom**, and **`--`ddp** options. | **ss -f \[family\]** or **–family=\[family\]** <br>. <br>Families: **unix**, **inet**, **inet6**, **link**, **netlink**. |
|
||||
| **netstat -c** or **`--`continuous** <br>. <br>Configures **netstat** to refresh the displayed information every second until stopped. | Not apparent |
|
||||
| **netstat -C** <br>. <br>Prints routing information from the route cache. | **ip route list cache** |
|
||||
| **netstat -e** or **`--`extend** <br>. <br>Displays an increased level of detail. Can be entered as twice (as **`--`ee**) for maximum details. | **ss -e** or **`--`extended** |
|
||||
| **netstat -F** <br>. <br>Prints routing information from the forward information database ([FIB](http://en.wikipedia.org/wiki/Forwarding_information_base "Forward Information Database on Wikipedia")). | Not apparent |
|
||||
| **netstat -g** or **`--`groups** <br>. <br>Displays multicast group membership information for IPv4 and IPv6. | **ip maddr**, **ip maddr show \[interface\]** |
|
||||
| **netstat -i** or **`--`interface=\[name\]** <br>. <br>Displays a table of all network interfaces, or the specified **\[name\].** | **ip -s link** |
|
||||
| **netstat -l** or **`--`listening** <br>. <br>Shows only listening sockets (which are omitted by **netstat** be default). | **ss -l** or **`--`listening** |
|
||||
| **netstat -M** or **`--`masquerade** <br>. <br>Displays a list of [masqueraded](http://en.wikipedia.org/wiki/Network_address_translation "NAT on Wikipedia") connections (connections being altered by Network Address Translation). | Not apparent |
|
||||
| **netstat -n** or **`--`numeric** <br>. <br>Show numerical addresses instead of trying to determine symbolic host, port or user names (skips DNS translation). | **ss -n** or **`--`numeric** |
|
||||
| **netstat `--`numeric-hosts** <br>. <br>Shows numerical host addresses but does not affect the resolution of port or user names. | Not apparent |
|
||||
| **netstat `--`numeric ports** <br>. <br>Shows numerical port numbers but does not affect the resolution of host or user names. | Not apparent |
|
||||
| **netstat `--`numeric-users** <br>. <br>Shows numerical user IDs but does not affect the resolution of host or port names. | Not apparent |
|
||||
| **netstat -N** or **`--`symbolic** <br>. <br>Displays the symbolic host, port, or user names instead of numerical representations. **Netstat** does this by default. | **ss -r** or **`--`resolve** |
|
||||
| **netstat -o** or **`--`timers** <br>. <br>Includes information related to networking timers. | **ss -o** or **`--`options** |
|
||||
| **netstat -p** or **`--`program** <br>. <br>Shows the process ID (PID) and name of the program to which each socket belongs. | **ss -p** |
|
||||
| **netstat -r** or **`--`route** <br>. <br>Shows the kernel routing tables. | **ip route**, **ip route show all** |
|
||||
| **netstat -s** or **`--`statistics** <br>. <br>Displays summary statistics for each protocol. | **ss -s** |
|
||||
| **netstat -t** or **`--`tcp** <br>. <br>Filters results to display TCP only. | **ss -t** or **`--`tcp** |
|
||||
| **netstat -T** or **`--`notrim** <br>. <br>Stops trimming long addresses. | Not apparent |
|
||||
| **netstat -u** or **`--`udp** <br>. <br>Filters results to display UDP only. | **ss -u** or **`--`udp** |
|
||||
| **netstat -v** or **`--`verbose** <br>. <br>Produces verbose output. | Not apparent |
|
||||
| **netstat -w** or **`--`raw** <br>. <br>Filter results to display [raw sockets](http://en.wikipedia.org/wiki/Raw_socket "Raw sockets on Wikipedia") only. | **ss-w** or **`--`raw** |
|
||||
| **netstat -Z** or **`--`context** <br>. <br>Prints the [SELinux](http://en.wikipedia.org/wiki/Security-Enhanced_Linux "SELinux on Wikipedia") context if SELinux is enabled. On hosts running SELinux, all processes and files are labeled in a way that represents security-relevant information. This information is called the SELinux context. | Not apparent |
|
||||
|
||||
## Route
|
||||
|
||||
| | |
|
||||
| --- | --- |
|
||||
| ### **Deprecated route commands** | ### **Replacement** |
|
||||
| --- | --- |
|
||||
| **route** <br>. <br>Displays the host’s routing tables. | **ip route** |
|
||||
| **route -A \[family\] \[add\]** or **route `--`\[family\] \[add\]** <br>. <br>Uses the specified address family with **add** or **del**. Valid families are **inet** (DARPA Internet), **inet6** (IPv6), **ax25** (AMPR AX.25), **netrom** (AMPR NET/ROM), **ipx** (Novell IPX), **ddp** (Appletalk DDP), and **x25** (CCITT X.25). | **ip -f \[family\] route** <br>. <br>**\[family\]** can be **inet** (IP), **inet6** (IPv6), or **link**. Additionally, **-4** = **-f inet** and **-6** = **-f inet6**. |
|
||||
| **route -C** or **`--`cache** <br>. <br>Operates on the kernel’s routing cache instead of the forwarding information base ([FIB](http://en.wikipedia.org/wiki/Forwarding_information_base "FIB on Wikipedia")) routing table. | Not apparent; **ip route show cache** dumps the routing cache. |
|
||||
| **route -e** or **-ee** <br>. <br>Uses the **netstat-r** format to display the routing table. **-ee** will generate a very long line with all parameters from the routing table. | **ip route show** |
|
||||
| **route -F** or **`--`fib** <br>. <br>Operates on the kernel’s Forwarding Information Base ([FIB](http://en.wikipedia.org/wiki/Forwarding_information_base "FIB on Wikipedia")) routing table (default behavior). | Not apparent |
|
||||
| **route -h** or **`--`help** <br>. <br>Prints the help message. | **ip route help** |
|
||||
| **route -n** <br>. <br>Shows numerical IP addresses and bypass host name resolution. | Not apparent |
|
||||
| **route -v** or **`--`verbose** <br>. <br>Enables verbose command output. | **ip -s route** |
|
||||
| **route -V** or **`--`version** <br>. <br>Dispays the version of **net-tools** and the **route** command. | **ip -V** |
|
||||
| **route add** or **del** <br>. <br>Adds or delete a route in the routing table. | **ip route \[add | chg | repl | del\] \[ip\_addr\] via \[ip\_addr\]** |
|
||||
| **route \[add** or **del\]** **dev \[interface\]** <br>. <br>Associates a route with a specific device. If **dev \[interface\]** is the last option on the command line, the word dev may be omitted. | **ip route \[add | chg | repl | del\] dev \[interface\]** |
|
||||
| **route \[add** or **del\] \[default\] gw \[gw\]** <br>. <br>Routes packets through the specified gateway IP address. | **ip route add default via \[gw\]** |
|
||||
| **route \[add** or **del\] -host** <br>. <br>Specifies that the target is a host (not a network). | Not apparent |
|
||||
| **route \[add** or **del\] -irtt \[n\]** <br>. <br>Sets the initial round trip time ([IRTT](http://en.wikipedia.org/wiki/Round-trip_delay_time "Round Trip Time on Wikipedia")) for TCP connections over this route to **\[n\]** milliseconds (1-12000). This is typically only used on AX.25 networks. If omitted the [RFC 1122](http://www.rfc-editor.org/info/rfc1122 "RFC 1122") default of 300ms is used. | Not apparent; **ip route \[add | chg | repl | del\] rtt \[number\]** sets the RTT estimate; **rttvar \[number\]** sets the initial RTT variance estimate. |
|
||||
| **route \[add** or **del\] -net** <br>. <br>Specifies that the target is a network (not a host). | Not apparent |
|
||||
| **route \[add** or **del\]** **\[-host** or **-net\] netmask \[mask\]** <br>. <br>Sets the subnet **\[mask\]**. | Not apparent |
|
||||
| **route \[add** or **del\] metric \[n\]** <br>. <br>Sets the metric field in the routing table (used by routing daemons) to the value of **\[n\]**. | **ip route \[add | chg | repl | del\]** **metric \[number\]** or **preference \[number\]** |
|
||||
| **route \[add** or **del\]** **mod, dyn,** or **reinstate** <br>. <br>Install a dynamic or modified route. These flags are for diagnostic purposes, and are generally only set by routing daemons. | Not apparent |
|
||||
| **route \[add** or **del\] mss \[bytes\]** <br>. <br>Sets the TCP Maximum Segment Size ([MSS](http://en.wikipedia.org/wiki/Maximum_segment_size "Maximum segment size on Wikipedia")) for connections over this route to the number of **\[bytes\]** specified. | **ip route \[add | chg | repl | del\] advmss \[number\]** (the MSS to advertise to these destinations when establishing TCP connections). |
|
||||
| **route \[add** or **del\] reject** <br>. <br>Installs a blocking route, which will force a route lookup to fail. This is used to mask out networks before using the default route. This is not intended to provide firewall functionality. | **ip route add prohibit \[network_addr\]** |
|
||||
| **route \[add** or **del\] window \[n\]** <br>. <br>Set the [TCP window size](http://en.wikipedia.org/wiki/TCP_window_scale_option "TCP window scaling on Wikipedia") for connections over this route to the value of **\[n\]** bytes. This is typically only used on AX.25 networks and with drivers unable to handle back-to-back frames. | **ip route \[add | chg | repl | del\] window \[W\]** |
|
||||
|
||||
.
|
||||
Some examples of **ip route** command syntax are as follows.
|
||||
|
||||
`# ip route add 10.23.30.0/24 via 192.168.8.50
|
||||
|
||||
# ip route del 10.28.0.0/16 via 192.168.10.50 dev eth0
|
||||
|
||||
# ip route chg default via 192.168.25.110 dev eth1
|
||||
|
||||
# ip route get [ip_address]` (shows the interface and gateway that would be used to reach a remote host. This command would be especially useful for troubleshooting routing issues on hosts with large routing tables and/or with multiple network interfaces).
|
||||
|
||||
### **Discussion**
|
||||
|
||||
This article and the topic of deprecated Linux networking commands has generated much interesting commentary on [Reddit](http://www.reddit.com/r/linux/comments/nux9v/deprecated_linux_networking_commands_and_their/?sort=confidence "Deprecated Linux network commands on Reddit").
|
||||
|
||||
### **Recommended reading**
|
||||
|
||||
If you found the content of this article helpful and want to expand your knowledge further, please consider buying a relevant book using the links below. Thanks!
|
||||
|
||||
[](http://www.amazon.com/gp/product/143026196X/ref=as_li_ss_il?ie=UTF8&camp=1789&creative=390957&creativeASIN=143026196X&linkCode=as2&tag=douvittecblo-20) [Linux Kernel Networking](http://www.amazon.com/gp/product/143026196X/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=143026196X&linkCode=as2&tag=douvittecblo-20) [](http://www.amazon.com/gp/product/0596002556/ref=as_li_ss_il?ie=UTF8&camp=1789&creative=390957&creativeASIN=0596002556&linkCode=as2&tag=douvittecblo-20)[Linux Network Internals](http://www.amazon.com/gp/product/0596002556/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0596002556&linkCode=as2&tag=douvittecblo-20)
|
||||
|
||||
[](http://www.amazon.com/gp/product/0596102488/ref=as_li_ss_il?ie=UTF8&tag=douvittecblo-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0596102488) [Linux Networking Cookbook](http://www.amazon.com/gp/product/0596102488/ref=as_li_ss_tl?ie=UTF8&tag=douvittecblo-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0596102488) [](http://www.amazon.com/gp/product/0596005482/ref=as_li_ss_tl?ie=UTF8&tag=douvittecblo-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0596005482)[Linux Network Administrator’s Guide](http://www.amazon.com/gp/product/0596005482/ref=as_li_ss_tl?ie=UTF8&tag=douvittecblo-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0596005482)
|
||||
|
||||
[](http://www.amazon.com/gp/product/0596154488/ref=as_li_ss_il?ie=UTF8&tag=douvittecblo-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0596154488) [Linux in a Nutshell, 6th Edition](http://www.amazon.com/gp/product/0596154488/ref=as_li_ss_tl?ie=UTF8&tag=douvittecblo-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0596154488) [](http://www.amazon.com/gp/product/013308504X/ref=as_li_ss_il?ie=UTF8&camp=1789&creative=390957&creativeASIN=013308504X&linkCode=as2&tag=douvittecblo-20)[Practical Guide to Linux Commands](http://www.amazon.com/gp/product/013308504X/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=013308504X&linkCode=as2&tag=douvittecblo-20)
|
||||
|
||||
[](http://www.amazon.com/gp/product/0470147733/ref=as_li_ss_il?ie=UTF8&tag=douvittecblo-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0470147733) [TCP/IP Implementation in Linux](http://www.amazon.com/gp/product/0470147733/ref=as_li_ss_tl?ie=UTF8&tag=douvittecblo-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0470147733)[](http://www.amazon.com/gp/product/0131777203/ref=as_li_ss_il?ie=UTF8&tag=douvittecblo-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0131777203) [Linux Networking Architecture](http://www.amazon.com/gp/product/0131777203/ref=as_li_ss_tl?ie=UTF8&tag=douvittecblo-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0131777203)
|
||||
|
||||
* [The best Linux and Unix books on Amazon](http://astore.amazon.com/douvittecblo-20?_encoding=UTF8&node=3)
|
||||
|
||||
Advertisements
|
||||
|
||||
Report this ad
|
||||
|
||||
Advertisements
|
||||
|
||||
Report this ad
|
||||
|
||||
### Share this on:
|
||||
|
||||
* [Email](https://dougvitale.wordpress.com/2011/12/21/deprecated-linux-networking-commands-and-their-replacements/?share=email&nb=1 "Click to email this to a friend")
|
||||
|
||||
* Share
|
||||
|
||||
* [More](#)
|
||||
|
||||
### Like this:
|
||||
|
||||
Like Loading...
|
||||
|
||||
### _Related_
|
||||
|
||||
[Troubleshooting faulty network connectivity, part 2: Essential network commands](https://dougvitale.wordpress.com/2011/12/11/troubleshooting-faulty-network-connectivity-part-2-essential-network-commands/ "Troubleshooting faulty network connectivity, part 2: Essential network commands
|
||||
|
||||
In my previous article describing the troubleshooting steps for faulty TCP/IP connections, I mentioned several commands such as ping, traceroute, and ipconfig that could assist you in pinpointing problematic network components. These commands and several others like them are commonly referred to as TCP/IP utilities because they are tools that…")In "Computer Networking Techniques and Concepts"
|
||||
|
||||
[Troubleshooting faulty network connectivity, part 1: A step-by-step guide](https://dougvitale.wordpress.com/2011/11/28/troubleshooting-faulty-network-connectivity-part-1/ "Troubleshooting faulty network connectivity, part 1: A step-by-step guide
|
||||
|
||||
(Go to Part 2 of this series). "My computer won't connect to the Internet". "I can't get online; Windows says it only has limited network connectivity". "I'm getting 'page cannot be displayed' errors". "I can't find the file server". If you have worked as a network administrator or help desk…")In "Computer Networking Techniques and Concepts"
|
||||
|
||||
[SSH, the Secure Shell](https://dougvitale.wordpress.com/2012/02/20/ssh-the-secure-shell/ "SSH, the Secure Shell
|
||||
|
||||
SSH is one of the protocols of the TCP/IP protocol suite found at the application layer (Layer 7) of the Open Systems Interconnection (OSI) network model. Officially specified in RFC 4251 (and later, several other RFCs) SSH functions in a way that is similar to telnet but is far more…")In "Computer Networking Techniques and Concepts"
|
||||
|
||||
Written by Doug Vitale
|
||||
|
||||
December 21, 2011 at 4:26 PM
|
||||
|
||||
Posted in [Computer Networking Techniques and Concepts](https://dougvitale.wordpress.com/category/computer-networking-techniques-and-concepts/)
|
||||
|
||||
Tagged with [ip command](https://dougvitale.wordpress.com/tag/ip-command/), [ip link](https://dougvitale.wordpress.com/tag/ip-link/), [ip neighbor](https://dougvitale.wordpress.com/tag/ip-neighbor/), [ip route](https://dougvitale.wordpress.com/tag/ip-route/), [iproute2](https://dougvitale.wordpress.com/tag/iproute2/), [iwconfig](https://dougvitale.wordpress.com/tag/iwconfig/), [linux deprecated](https://dougvitale.wordpress.com/tag/linux-deprecated/)
|
||||
|
||||
« [Troubleshooting faulty network connectivity, part 2: Essential network commands](https://dougvitale.wordpress.com/2011/12/11/troubleshooting-faulty-network-connectivity-part-2-essential-network-commands/)
|
||||
|
||||
[Use SSH in Firefox with FireSSH](https://dougvitale.wordpress.com/2011/12/31/use-ssh-in-firefox-with-firessh/) »
|
||||
|
||||
[](http://astore.amazon.com/douvittecblo-20) [**Amazon bookstore**](http://astore.amazon.com/douvittecblo-20 "Amazon bookstore")
|
||||
|
||||
### Pages
|
||||
|
||||
* [About](https://dougvitale.wordpress.com/about/)
|
||||
* [Contact](https://dougvitale.wordpress.com/contact/)
|
||||
* [Latest IT news and commentary](https://dougvitale.wordpress.com/news/)
|
||||
|
||||
### Site search
|
||||
|
||||
Search for:
|
||||
|
||||
|
||||
[](http://www.google.com/cse/home?cx=009178134032797716717:cwmztgcnbfg)[Site search engine](http://www.google.com/cse/home?cx=009178134032797716717:cwmztgcnbfg)
|
||||
|
||||
### Most popular
|
||||
|
||||
* [Deprecated Linux networking commands and their replacements](https://dougvitale.wordpress.com/2011/12/21/deprecated-linux-networking-commands-and-their-replacements/)
|
||||
* [Send spoofed emails with telnet](https://dougvitale.wordpress.com/2011/12/31/send-spoofed-emails-with-telnet/)
|
||||
* [Layer 3 switches compared to routers](https://dougvitale.wordpress.com/2012/12/01/layer-3-switches-compared-to-routers/)
|
||||
* [Reset Windows passwords with Offline NT Password & Registry Editor](https://dougvitale.wordpress.com/2012/01/05/reset-windows-passwords-with-offline-nt-password-registry-editor/)
|
||||
* [Troubleshooting faulty network connectivity, part 2: Essential network commands](https://dougvitale.wordpress.com/2011/12/11/troubleshooting-faulty-network-connectivity-part-2-essential-network-commands/)
|
||||
* [Microsoft Baseline Security Analyzer](https://dougvitale.wordpress.com/2011/11/18/microsoft-baseline-security-analyzer/)
|
||||
* [Network administration commands for Microsoft Windows and Active Directory](https://dougvitale.wordpress.com/2013/02/07/network-administration-commands-for-microsoft-windows-and-active-directory/)
|
||||
|
||||
### Get networking gear
|
||||
|
||||
[](http://www.amazon.com/b?_encoding=UTF8&camp=1789&creative=9325&linkCode=ur2&node=172504&site-redirect=&tag=douvittecblo-20&linkId=I62YD6RYZXAFAFKK)
|
||||
|
||||
### Categories
|
||||
|
||||
* [Commentary](https://dougvitale.wordpress.com/category/commentary/) (6)
|
||||
* [Computer Networking Techniques and Concepts](https://dougvitale.wordpress.com/category/computer-networking-techniques-and-concepts/) (10)
|
||||
* [Computer Networking Tools](https://dougvitale.wordpress.com/category/computer-networking-tools/) (9)
|
||||
* [Info Security or Ethical Hacking Tools](https://dougvitale.wordpress.com/category/info-security-or-ethical-hacking-tools/) (28)
|
||||
* [Useful Applications](https://dougvitale.wordpress.com/category/useful-applications/) (9)
|
||||
* [Useful Web-Based Tools](https://dougvitale.wordpress.com/category/useful-web-based-tools/) (5)
|
||||
* [Useful Websites](https://dougvitale.wordpress.com/category/useful-websites/) (3)
|
||||
|
||||
### Browse tech books
|
||||
|
||||
[](http://www.amazon.com/b?_encoding=UTF8&camp=1789&creative=9325&linkCode=ur2&node=5&site-redirect=&tag=douvittecblo-20&linkId=AZADNWHFYV5SQXT5)
|
||||
|
||||
### RSS
|
||||
|
||||
[](https://dougvitale.wordpress.com/feed/ "Subscribe to Posts") [RSS - Posts](https://dougvitale.wordpress.com/feed/ "Subscribe to Posts")
|
||||
|
||||
### Follow blog via email
|
||||
|
||||
Enter your email address to follow this blog and receive notifications of new posts by email.
|
||||
|
||||
### Build a custom PC
|
||||
|
||||
[](http://www.amazon.com/b?_encoding=UTF8&camp=1789&creative=9325&linkCode=ur2&node=193870011&site-redirect=&tag=douvittecblo-20&linkId=QS4CWENJX7LEUFUS)
|
||||
|
||||
### ↓ What’s new in Tech ↓
|
||||
|
||||
### [](http://lxer.com/module/newswire/headlines.rdf "Syndicate this content") [LXer Linux News](http://lxer.com/ "Linux and Open Source news headlines")
|
||||
|
||||
* [Tiny i.MX6 UL DIN-rail computer has dual mini-PCIe slots](http://linuxgizmos.com/tiny-i-mx6-ul-din-rail-computer-has-dual-mini-pcie-slots/ "Axiomtek’s compact, rugged “Agent200-FL-DC” DIN-rail computer runs Linux on a low-power i.MX6 UL. Features include 10/100 Ethernet, USB, serial, DIO, optional CAN, and 2x mini-PCIe with a SIM slot. Axiomtek has posted product details for a “coming soon” Agent200-FL-DC DIN-rail computer. Like last year’s similar IFB125 and the IFB122 from 2017, the Agent200-F […]")
|
||||
* [Cops storm Nginx's Moscow offices after a Russian biz claims it owns world's most widely used web server, not F5](https://go.theregister.co.uk/feed/www.theregister.co.uk/2019/12/12/nginx_moscow_office_raided/ "Rambler claims code creator was working for them at the time and so they own tech worth $700m. Nginx's Moscow office was raided today by police after the ownership of the popular web server's source code was disputed.…")
|
||||
* [Seems like Feral Interactive may have a few surprises for Linux in 2020](https://www.gamingonlinux.com/articles/seems-like-feral-interactive-may-have-a-few-surprises-for-linux-in-2020.15589?module=articles_full&title=seems-like-feral-interactive-may-have-a-few-surprises-for-linux-in-2020&aid=15589 "Porting studio Feral Interactive have already given Linux a lot of games and it sounds like more are coming. ")
|
||||
|
||||
### [](https://www.techrepublic.com/rssfeeds/topic/security/ "Syndicate this content") [TechRepublic IT Security](https://www.techrepublic.com/ "Security on TechRepublic")
|
||||
|
||||
* [10 cybersecurity stories in 2019 that make us feel less secure](https://www.techrepublic.com/article/10-cybersecurity-stories-in-2019-that-make-us-feel-less-secure/#ftag=RSS56d97e7 "Jack Wallen runs through 10 of the most important cybersecurity threats, breaches, tools, and news of the year.")
|
||||
* [How to use Firefox's Lockwise password manager](https://www.techrepublic.com/videos/how-to-use-firefoxs-lockwise-password-manager/#ftag=RSS56d97e7 "Mozilla has evolved its Lockbox password tool into a more standard password manager. Jack Wallen shows you how to use the Firefox Lockwise password manager.")
|
||||
* [Organizations moving toward more rigorous security testing to ensure compliance](https://www.techrepublic.com/article/organizations-moving-toward-more-rigorous-security-testing-to-ensure-compliance/#ftag=RSS56d97e7 "More companies are using third-party vendors and crowdsourced testing to meet their security needs, according to a new survey from Synack.")
|
||||
|
||||
### [](https://www.zdnet.com/blog/security/rss.xml "Syndicate this content") [ZDNet Zero Day](https://www.zdnet.com/ "ZDNet | security RSS")
|
||||
|
||||
* [One in every 172 active RSA certificates are vulnerable to attack](https://www.zdnet.com/article/1-in-every-172-active-rsa-certificates-are-vulnerable-to-exploit/#ftag=RSSbaffb68 "Researchers say improper number generation can impact the security of keys used to protect everything from IoT to medical devices.")
|
||||
* [VISA warns of POS malware incidents at gas pumps across North America](https://www.zdnet.com/article/visa-warns-of-pos-malware-incidents-at-gas-pumps-across-north-america/#ftag=RSSbaffb68 "VISA says it's aware of POS malware being deployed on the networks of five North American fuel dispenser merchants.")
|
||||
* [New Orleans hit by ransomware, city employees told to turn off computers](https://www.zdnet.com/article/new-orleans-hit-by-ransomware-city-employees-told-to-turn-off-computers/#ftag=RSSbaffb68 "After Atlanta and Baltimore, another major US city grapples with a ransomware attack.")
|
||||
|
||||
### [](https://www.techrepublic.com/rssfeeds/topic/open-source/ "Syndicate this content") [TechRepublic Open Source](https://www.techrepublic.com/ "Open Source on TechRepublic")
|
||||
|
||||
* [8 data center predictions for 2020](https://www.techrepublic.com/article/8-data-center-predictions-for-2020/#ftag=RSS56d97e7 "Jack Wallen shares his thoughts about data centers and edge computing, Kubernetes, 5G, containers security, and more for the coming year.")
|
||||
* [How to analyze systemd boot performance](https://www.techrepublic.com/videos/how-to-analyze-systemd-boot-performance/#ftag=RSS56d97e7 "Learn how to start troubleshooting systemd-enabled machines with the systemd-analyze tool.")
|
||||
* [8 of the worst open source innovations of the decade](https://www.techrepublic.com/article/8-of-the-worst-open-source-innovations-of-the-decade/#ftag=RSS56d97e7 "Open source innovations aren't all successes. Jack Wallen shares his picks for the biggest open source failures of the 2010s.")
|
||||
|
||||
### [](https://www.zdnet.com/blog/open-source/rss.xml?tag=mantle_skin;content "Syndicate this content") [ZDNet Open Source](https://www.zdnet.com/ "ZDNet | open-source RSS")
|
||||
|
||||
* [How the community can help your business: People Powered](https://www.zdnet.com/article/how-the-community-can-help-your-business-people-powered/#ftag=RSSbaffb68 "Open source took over the world because of community, and community expert Jono Bacon explains how this concept can revolutionize your business in his new book People Powered.")
|
||||
* [Red Hat customers want the hybrid cloud](https://www.zdnet.com/article/red-hat-customers-want-the-hybrid-cloud/#ftag=RSSbaffb68 "Red Hat asked its customers around the globe what they wanted, and while they want the hybrid cloud, Red Hat may not have the experienced staff needed for the transformation from traditional IT to the cloud.")
|
||||
* [Canonical co-sponsors Windows Subsystem for Linux conference](https://www.zdnet.com/article/canonical-co-sponsors-windows-subsystem-for-linux-conference/#ftag=RSSbaffb68 "The year of the Linux desktop on Windows continues to gather steam.")
|
||||
|
||||
### [](http://feeds.feedburner.com/linuxtoday/linux "Syndicate this content") [Linux Today](https://www.linuxtoday.com/)
|
||||
|
||||
* [Linux 5.5 rc2](http://feedproxy.google.com/~r/linuxtoday/linux/~3/5O9bhSzpy3E/linux-5.5-rc2.html "Linus Torvalds: Things look normal - rc2 is usually fairly calm, and so it was this week too.")
|
||||
* [How to Install OpenVPN Server and Client with Easy-RSA 3 on CentOS 8](http://feedproxy.google.com/~r/linuxtoday/linux/~3/muAkRAxkQpg/how-to-install-openvpn-server-and-client-with-easy-rsa-3-on-centos-8-191213092509.html "OpenVPN is an open-source application that allows you to create a secure private network over the public internet.")
|
||||
* [Sysadmins: How many spare cords do you have sitting around?](http://feedproxy.google.com/~r/linuxtoday/linux/~3/oZaN_zcNp1I/sysadmins-how-many-spare-cords-do-you-have-sitting-around-191213063515.html "Do you stockpile cables and other spare parts like they're going out of style?")
|
||||
|
||||
### [](https://www.ehackingnews.com/feeds/posts/default "Syndicate this content") [EHacking News](https://www.ehackingnews.com/)
|
||||
|
||||
* [Rambler claimed the rights to the Nginx web server](https://www.ehackingnews.com/2019/12/rambler-claimed-rights-to-nginx-web.html "Rambler Group claimed a violation of its exclusive copyright on the Nginx web server, which was developed by a former employee of the company Igor Sysoev.Nginx is one of the most successful IT companies created by Russian programmers. Its main product is software, which is necessary for the operation of sites on the Internet. Now about 33% of all sites in th […]")
|
||||
* [New Orleans: Mayor Declares State of Emergency after a Cyberattack](https://www.ehackingnews.com/2019/12/new-orleans-mayor-declares-state-of.html "The city of New Orleans after being hit by a cyberattack, declared a state of emergency wherein the employees and officials were asked to shut down the computers, power down devices by unplugging and take down all servers as a cautionary measure. As a part of the incident, The Nola.gov website was also down.Officials suspect the involvement of ransomware as […]")
|
||||
* [Russian Telegram Accounts Hacked by Intercepting One Time Password (OTP)](https://www.ehackingnews.com/2019/12/russian-telegram-accounts-hacked-by.html "According to a firm Group-IB, in the last few weeks a dozen Russian entrepreneurs saw their Telegram accounts hacked. And what's disturbing is the way these accounts were accessed. The attackers intercepted the codes used to authenticate user and give access.A Telegram App logo in QR code How the attackers gained access?In normal procedure, whenever som […]")
|
||||
|
||||
### [](https://www.networkworld.com/category/security/index.rss "Syndicate this content") [NetworkWorld Security](https://www.networkworld.com)
|
||||
|
||||
* [Blockchain/IoT integration accelerates, hits a 'sweet spot'](https://www.computerworld.com/article/3489503/blockchainiot-integration-accelerates-hits-a-sweet-spot-for-the-two-technologies.html#tk.rss_security "IoT and blockchain may be a natural fit, but it will still take five to 10 years before kinks are worked out and the two technologies can reach their full potential, according to Gartner.")
|
||||
* [What’s hot for Cisco in 2020](https://www.networkworld.com/article/3487831/what-s-hot-for-cisco-in-2020.html#tk.rss_security "As the industry gets ready to gear up for 2020 things have been a little disquieting in networking land.That’s because some key players – Arista and Juniper in particular – have been reporting business slowdowns as new deals have been smaller than expected and cloud providers haven’t been as free-spending as in the past.[Get regularly scheduled insights by […]")
|
||||
* [The VPN is dying, long live zero trust](https://www.networkworld.com/article/3487720/the-vpn-is-dying-long-live-zero-trust.html#tk.rss_security "The venerable VPN, which has for decades provided remote workers with a secure tunnel into the enterprise network, is facing extinction as enterprises migrate to a more agile, granular security framework called zero trust, which is better adapted to today’s world of digital business.VPNs are part of a security strategy based on the notion of a network perime […]")
|
||||
|
||||
### [](https://www.networkworld.com/category/lan-wan/index.rss "Syndicate this content") NetworkWorld LAN & WAN
|
||||
|
||||
* An error has occurred; the feed is probably down. Try again later.
|
||||
|
||||
### [](https://www.zdnet.com/blog/networking/rss.xml "Syndicate this content") [ZDNet Networking](https://www.zdnet.com/ "ZDNet | networking RSS")
|
||||
|
||||
* [Twitter proposes open social network standard](https://www.zdnet.com/article/twitter-proposes-open-social-network-standard/#ftag=RSSbaffb68 "Twitter CEO Jack Dorsey wants to replace Twitter's existing social networking platform with one based on an open, decentralized standard.")
|
||||
* [At long last, WireGuard VPN is on its way into Linux](https://www.zdnet.com/article/at-long-last-wireguard-vpn-is-on-its-way-into-linux/#ftag=RSSbaffb68 "For years, developers have been working on this new take on the virtual private network, and now it's finally ready to go.")
|
||||
* [FBI warns about snoopy smart TVs spying on you](https://www.zdnet.com/article/fbi-warns-about-snoopy-smart-tvs-spying-on-you/#ftag=RSSbaffb68 "An FBI branch office warns smart TV users that they can be gateways for hackers to come into your home. Meanwhile, the smart TV OEMs are already spying on you.")
|
||||
|
||||
### [](https://www.darkreading.com/rss_simple.asp "Syndicate this content") [Dark Reading](https://www.darkreading.com "Dark Reading: Connecting the Information and Security Community")
|
||||
|
||||
* [Visa Warns of Targeted PoS Attacks on Gas Station Merchants](https://www.darkreading.com/attacks-breaches/visa-warns-of-targeted-pos-attacks-on-gas-station-merchants/d/d-id/1336619 "At least two North American chains have been hit in sophisticated new campaigns for stealing payment card data.")
|
||||
* ['Motivating People Who Want the Struggle': Expert Advice on InfoSec Leadership](https://www.darkreading.com/edge/theedge/motivating-people-who-want-the-struggle-expert-advice-on-infosec-leadership/b/d-id/1336615 "Industry veteran and former Intel security chief Malcolm Harkins pinpoints three essential elements for leaders to connect with their employees and drive business objectives.")
|
||||
* [Fortinet Buys CyberSponse for SOAR Capabilities](https://www.darkreading.com/threat-intelligence/fortinet-buys-cybersponse-for-soar-capabilities/d/d-id/1336616 "It plans to integrate CyberSponse's SOAR platform into the Fortinet Security Fabric.")
|
||||
|
||||
### [](http://www.windowsnetworking.com/articles-tutorials/feed.rss "Syndicate this content") Windows Networking
|
||||
|
||||
* An error has occurred; the feed is probably down. Try again later.
|
||||
|
||||
### [](http://www.windowsecurity.com/articles-tutorials/feed.rss "Syndicate this content") Windows Security
|
||||
|
||||
* An error has occurred; the feed is probably down. Try again later.
|
||||
|
||||
### [](http://www.infosecisland.com/rss.html "Syndicate this content") [InfoSec Island](https://www.infosecisland.com "Adrift in Threats? Come Ashore!")
|
||||
|
||||
* [University of Arizona Researchers Going on Offense and Defense in Battle Against Hackers](https://www.infosecisland.com/blogview/25232-University-of-Arizona-Researchers-Going-on-Offense-and-Defense-in-Battle-Against-Hackers.html "University of Arizona-led teams will be more proactive in the battle against cyberthreats thanks to nearly $1.5 million in grants from the National Science Foundation.")
|
||||
* [Securing the Internet of Things (IoT) in Today's Connected Society](https://www.infosecisland.com/blogview/25231-Securing-the-Internet-of-Things-IoT-in-Todays-Connected-Society.html "The rush to adoption has highlighted serious deficiencies in both the security design of Internet of Things (IoT) devices and their implementation.")
|
||||
* [What Is Next Generation SIEM? 8 Things to Look For](https://www.infosecisland.com/blogview/25230-What-Is-Next-Generation-SIEM-8-Things-to-Look-For.html "Effective next generation SIEM should provide better protection and equally important, if not more, a much more effective, next gen user experience.")
|
||||
|
||||
### [](http://feeds.feedburner.com/securityweek "Syndicate this content") [SecurityWeek](https://www.securityweek.com "Latest IT Security News and Expert Insights Via RSS Feed")
|
||||
|
||||
* [Schneider Electric Patches Vulnerabilities in Modicon, EcoStruxure Products](http://feedproxy.google.com/~r/Securityweek/~3/NO-fk8ug6-Q/schneider-electric-patches-vulnerabilities-modicon-ecostruxure-products "Schneider Electric last week informed customers that patches have been made available for vulnerabilities in some Modicon controllers and several EcoStruxure products. read more ")
|
||||
* [Cyberattack on New Orleans City Computers Called 'Minimal'](http://feedproxy.google.com/~r/Securityweek/~3/StbP5TdyROs/cyberattack-new-orleans-city-computers-called-minimal "Officials announced Saturday that no data was held for ransom and that a recovery operation is getting underway after a cyberattack a day earlier triggered a shutdown of city government computers in New Orleans. read more ")
|
||||
* [Iran Says It's Defused 2nd Cyberattack in Less Than a Week](http://feedproxy.google.com/~r/Securityweek/~3/hG_x5HRH1oI/iran-says-its-defused-2nd-cyberattack-less-week "Iran's telecommunications minister announced on Sunday that the country has defused a second cyberattack in less than a week, this time “aimed at spying on government intelligence." read more ")
|
||||
|
||||
### [](http://feeds.feedburner.com/isc2Blog?format=xml "Syndicate this content") [(ISC)² Blog](https://blog.isc2.org/isc2_blog/ "Voice of the Certified Cybersecurity Professional")
|
||||
|
||||
* [Job Satisfaction Is High Among Cybersecurity Workers](http://feedproxy.google.com/~r/isc2Blog/~3/t6dJDUhSNWE/job-satisfaction-is-high-among-cybersecurity-workers.html "Cybersecurity professionals face plenty of challenges in their work – there’s always something new to learn, cyber attackers are relentless and security teams are usually short-staffed. Still, nearly two-thirds of cybersecurity professionals (66%) say they are satisfied with their jobs. But that number jumps to 72% among cybersecurity workers whose employers […]")
|
||||
* [Cyber Threats to Healthcare on the Rise](http://feedproxy.google.com/~r/isc2Blog/~3/-ZQqI-qz2js/cyber-threats-to-healthcare-on-the-rise.html "Hospitals are set up to fight infections, but not necessarily the kind that has been plaguing healthcare institutions lately – malware. A new report estimates that cyber threats against healthcare targets increased 60% since January, surpassing the total number of threats identified in all of 2018. The most common threat targeting the healthcare industry is […]")
|
||||
* [Enter to Win a Nintendo Switch While Taking FREE Professional Development Courses](http://feedproxy.google.com/~r/isc2Blog/~3/knWKtfKMmGY/enter-to-win-a-nintendo-switch-while-taking-free-professional-development-courses.html "(ISC)² members and associates have an exclusive opportunity to win a Nintendo Switch while earning CPEs. This participation-based contest is running until the end of December – just in time for the holidays. Fifteen winners will be chosen. Steps to complete in order to be entered to win: Members and associates must fill out a registration form for December e […]")
|
||||
|
||||
### [](https://blogs.cisco.com/security/feed "Syndicate this content") [Cisco Security Blog](https://blogs.cisco.com)
|
||||
|
||||
* [Threat Roundup for December 6 to December 13](https://blogs.cisco.com/security/talos/threat-roundup-1206-1213 "Today, Talos is publishing a glimpse into the most prevalent threats we’ve observed between Dec 6 and Dec 13. As with previous roundups, this post isn’t meant to be an in-depth analysis. Instead, this post will summarize the threats we’ve observed by highlighting key behavioral characteristics, indicators of compromise, and discussing how our customers are [ […]")
|
||||
* [A Look Back at the Major Cyber Threats of 2019](https://blogs.cisco.com/security/a-look-back-at-the-major-cyber-threats-of-2019 "Use the latest Cisco cybersecurity report to understand the current cyber threat landscape, and test how your organization would perform against these attacks. The post A Look Back at the Major Cyber Threats of 2019 appeared first on Cisco Blogs. ")
|
||||
* [Talos Vulnerability Discovery Year in Review – 2019](https://blogs.cisco.com/security/talos/talos-vulnerability-discovery-2019 "Introduction Cisco Talos’ Systems Security Research Team investigates software, operating system, IOT and ICS vulnerabilities in order to discover them before malicious threat actors do. We provide this information to the affected vendors so that they can create patches and protect their customers as soon as possible. We strive to improve the security of our […]")
|
||||
|
||||
### [](https://msrc-blog.microsoft.com/feed/ "Syndicate this content") [Microsoft Security Response Center](https://msrc-blog.microsoft.com)
|
||||
|
||||
* [December 2019 security updates are available](https://msrc-blog.microsoft.com/2019/12/10/december-2019-security-updates-are-available/ "We have released the December security updates to provide additional protections against malicious attackers. As a best practice, we encourage customers to turn on automatic updates. More information about this month’s security updates can be found in the Security Update Guide. As a reminder, Windows 7 and Windows Server 2008 R2 will be out of … December 201 […]")
|
||||
* [Customer Guidance for the Dopplepaymer Ransomware](https://msrc-blog.microsoft.com/2019/11/20/customer-guidance-for-the-dopplepaymer-ransomware/ "Microsoft has been investigating recent attacks by malicious actors using the Dopplepaymer ransomware. There is misleading information circulating about Microsoft Teams, along with references to RDP (BlueKeep), as ways in which this malware spreads. Our security research teams have investigated and found no evidence to support these claims. In our investigat […]")
|
||||
* [BlueHat Seattle videos are online!](https://msrc-blog.microsoft.com/2019/11/13/bluehat-seattle-videos-are-online/ "Were you unable to attend BlueHat Seattle, or wanted to see a session again? We have good news. If you have been waiting for the videos from BlueHat Seattle last month, the wait is over. All videos which the presenter authorized to be recorded are now online and available to anyone. We are also happy … BlueHat Seattle videos are online! Read More »")
|
||||
|
||||
### [](https://www.theregister.co.uk/security/headlines.atom "Syndicate this content") [The Register – Security](https://www.theregister.co.uk/security/)
|
||||
|
||||
* [VMware warning, OpenBSD gimme-root hole again, telco hit with GDPR fine, Ring camera hijackings, and more](https://go.theregister.co.uk/feed/www.theregister.co.uk/2019/12/16/roundup_dec13/ "Your quick summary of infosec news beyond everything else we've reported Roundup Here's your Register security roundup of infosec news about stuff that's unfit for production but fit for print.…")
|
||||
* [Valuable personal info leaks from Facebook – not Zuck selling it, unencrypted hard drives of staff data stolen](https://go.theregister.co.uk/feed/www.theregister.co.uk/2019/12/13/facebook_data_loss/ "Car smash-and-grab ends with loss of payroll details for 20,000 employees Facebook has lost a copy of the personal details of 29,000 of its employees after hard drives containing unencrypted payroll information were stolen from an employee's car.…")
|
||||
* [Ever wonder how hackers could possibly pwn power plants? Here are 54 Siemens bugs that could explain things](https://go.theregister.co.uk/feed/www.theregister.co.uk/2019/12/13/siemens_security_advisory/ "Arbitrary code execution in a controller, what could go wrong? Siemens industrial control systems designed specifically for energy plant gear are riddled with dozens of security vulnerabilities that are, luckily enough, tricky to exploit from the outside.… ")
|
||||
|
||||
### [](https://www.internetsociety.org/feed/ "Syndicate this content") [Internet Society](https://www.internetsociety.org "Working for an Internet that is open, globally connected, and secure.")
|
||||
|
||||
* [Celebrating a Successful Chapterthon 2019!](https://www.internetsociety.org/blog/2019/12/celebrating-a-successful-2019-chapterthon/ "We are incredibly inspired by the collaborative projects brought to life by our Chapters for the 2019 Chapterthon, the global contest in which Internet Society Chapters develop a project within a set timeline and budget to achieve a common goal for the development of the Internet. This year’s theme was “Connecting the Unconnected” – because every last person […]")
|
||||
* [Claudio Jeker Honored by Internet Security Research Group with Radiant Award](https://www.internetsociety.org/blog/2019/12/claudio-jeker-honored-by-internet-security-research-group-with-radiant-award/ "This week another Radiant Award has been awarded by the Internet Security Research Group, the folks behind Let’s Encrypt. The award puts the limelight on the heroes who make the Internet more secure and trustworthy each day. The newest Radiant Award winner is Claudio Jeker, who receives the prize for his work of a BGP4 […] The post Claudio Jeker Honored by I […]")
|
||||
* [The Week in Internet News: Australian Lawmakers Push for ‘Fix’ to Encryption Law](https://www.internetsociety.org/blog/2019/12/the-week-in-internet-news-australian-lawmakers-push-for-fix-to-encryption-law/ "An encryption fix: The Australian Labor Party says it will push for changes to an encryption law, passed in late 2018, that requires tech comp anies to give law enforcement agencies access to encrypted communications, ZDNet reports. Labor Party lawmakers have raised concerns about the law’s effect on the country’s tech industry, but it appears […] The post T […]")
|
||||
|
||||
### [](https://www.cio.com/category/security/index.rss "Syndicate this content") [CIO.com Security](https://www.cio.com)
|
||||
|
||||
* [The big task for CIOs in 2020: Bringing security and IT operations together](https://www.cio.com/article/3487798/the-big-task-for-cios-in-2020-bringing-security-and-it-operations-together.html#tk.rss_security "The first step in bridging the gap starts with understanding the problem. IT and security operations have worked in silos for decades so one might think “If it ain’t broke, don’t fix it.” But it is, in fact, broken, and there is little awareness of the impact caused by the fragmentation.According to a recent study conducted by Forrester on behalf of endpoi […]")
|
||||
* [IDG Contributor Network: What is the California Consumer Privacy Act of 2018? Influencers in the know break down the details](https://www.cio.com/article/3482361/what-is-the-california-consumer-privacy-act-of-2018.html#tk.rss_security "It was only a matter of time before US created their own version of the EU’S General Data Protection Regulation (GDPR). However, unlike the EU who addresses digital privacy protection on a national level, the US is handling online privacy on the state level. California has led the charge with the California Consumer Privacy Act (CCPA) that was passed into la […]")
|
||||
* [IT certifications and training center](https://www.idginsiderpro.com/article/3482642/welcome-to-insider-pros-certifications-and-training-center.html#tk.rss_security "Certifications show that you’re committed to your job, have specific skills and are willing to up your game. Check out our online training courses and guides to top certifications -- all part of your Insider Pro subscription.")
|
||||
|
||||
### [](http://feeds.feedburner.com/InformationSecurityBuzz "Syndicate this content") [Information Security Buzz](https://www.informationsecuritybuzz.com "Experts Comments on Information Security News")
|
||||
|
||||
* [Mozilla To Force All Add-On Devs To Use 2FA To Prevent Supply-Chain Attacks – Comments](http://feedproxy.google.com/~r/InformationSecurityBuzz/~3/sNpbmI6WYGo/ "Mozilla announced last week that all developers of Firefox add-ons must enable a two-factor authentication (2FA) solution for their account. As of early 2020, #Firefox extension #developers will be required to have #2FA enabled on #Mozilla Add-Ons portal to help prevent cybercrooks from taking control of legitimate add-ons and their users. Good #security mov […]")
|
||||
* [Security Expert re: New Legislation Passes To Help Protect The Nation’s Grid Against Cyber Attacks](http://feedproxy.google.com/~r/InformationSecurityBuzz/~3/qG4atpjVRKc/ "Legislation to protect the nation’s electric grid against cyber attacks was added to the final version of the National Defense Authorization Act (NDAA), which passed the House Wednesday by a vote of 3777 to 48. The program’s recommendations would require a national strategy, crafted by federal agencies and the energy industry, and a 2-year pilot program … […]")
|
||||
* [Comments On FBI Advise For Holiday Shopping](http://feedproxy.google.com/~r/InformationSecurityBuzz/~3/RzJLPKPqEAI/ "The FBI has issued advise to keep consumers safe during the online holiday shopping season. Some of the advise includes making sure the online company has a physical address and working phone number, be wary of special offers and more. The ISBuzz Post: This Post Comments On FBI Advise For Holiday Shopping appeared first on Information Security Buzz. ")
|
||||
|
||||
### [](https://insights.sei.cmu.edu/cert/rss.xml "Syndicate this content") [CERT Blogs](https://insights.sei.cmu.edu/cert/ "CERT is Anticipating and Solving the Nation’s Cybersecurity Challenges.")
|
||||
|
||||
* [Prioritizing Vulnerability Response with a Stakeholder-Specific Vulnerability Categorization](https://insights.sei.cmu.edu/cert/2019/12/prioritizing-vulnerability-response-with-a-stakeholder-specific-vulnerability-categorization.html "By Allen Householder. We've just released a follow-up paper in our research agenda about prioritizing actions during vulnerability management, Prioritizing Vulnerability Response: A Stakeholder-Specific Vulnerability Categorization.")
|
||||
* [Machine Learning in Cybersecurity](https://insights.sei.cmu.edu/cert/2019/12/machine-learning-in-cybersecurity.html "By Jonathan Spring. We recently published a report that outlines relevant questions that decision makers who want to use artificial intelligence (AI) or machine learning (ML) tools as solutions in cybersecurity should ask of machine-learning practitioners to adequately prepare for implementing them. My coauthors are Joshua Fallon, April Galyardt, Angela Horn […]")
|
||||
* [VPN - A Gateway for Vulnerabilities](https://insights.sei.cmu.edu/cert/2019/11/vpn---a-gateway-for-vulnerabilities.html "By Vijay Sarvepalli. Virtual Private Networks (VPNs) are the backbone of today's businesses providing a wide range of entities from remote employees to business partners and sometimes even to customers, with the ability to connect to sensitive corporate information securely. Long gone are the days of buying a leased line or a dedicated physical network […]")
|
||||
|
||||
### [](https://cmu-sei-podcasts.libsyn.com/rss "Syndicate this content") [CERT’S Security for Business Leaders (MP3)](https://www.sei.cmu.edu/publications/podcasts/index.cfm "The SEI Podcast Series presents conversations in software engineering, cybersecurity, and future technologies.")
|
||||
|
||||
* [Machine Learning in Cybersecurity: 7 Questions for Decision Makers](http://cmu-sei-podcasts.seimedia.libsynpro.com/machine-learning-in-cybersecurity-7-questions-for-decision-makers "April Galyardt, Angela Horneman, and Jonathan Spring discuss seven key questions that managers and decision makers should ask about machine learning to effectively solve cybersecurity problems.")
|
||||
* [Women in Software and Cybersecurity: Kristi Roth](http://cmu-sei-podcasts.seimedia.libsynpro.com/women-in-software-and-cybersecurity-kristi-roth "In this SEI Podcast, Kristi Roth, a summer 2019 intern in the Software Solutions Division at the Software Engineering Institute, discusses the path that led from a childhood spent calculating math problems in her head to a high school Introduction to Programming class to Penn State University where she is a senior computer science major.")
|
||||
* [Human Factors in Software Engineering](http://cmu-sei-podcasts.seimedia.libsynpro.com/human-factors-in-software-engineering "Solving the technical aspects isn’t enough to build reliable, enduring, resilient software and systems. Human decision making, behavioral factors, and cultural factors influence software engineering, acquisition, and cybersecurity. In this podcast roundtable, Andrew Mellinger, Suzanne Miller, and Hasan Yasar discuss the human factors that impact software eng […]")
|
||||
|
||||
### [](https://www.scmagazine.com/pages/rss.aspx?mp=true "Syndicate this content") SC Magazine
|
||||
|
||||
* An error has occurred; the feed is probably down. Try again later.
|
||||
|
||||
|
||||
[](http://astore.amazon.com/douvittecblo-20) [**Amazon bookstore**](http://astore.amazon.com/douvittecblo-20 "Amazon bookstore")
|
||||
|
||||
Advertisements
|
||||
|
||||
Report this ad
|
||||
|
||||
[Create a free website or blog at WordPress.com.](https://wordpress.com/?ref=footer_website)
|
||||
|
||||
Post to
|
||||
|
||||
[Cancel](#)
|
||||
|
||||
Privacy & Cookies: This site uses cookies. By continuing to use this website, you agree to their use.
|
||||
To find out more, including how to control cookies, see here: [Cookie Policy](https://automattic.com/cookies)
|
||||
|
||||
* Follow
|
||||
|
||||
* * [ Doug Vitale Tech Blog](http://dougvitale.wordpress.com)
|
||||
* [Customize](https://dougvitale.wordpress.com/wp-admin/customize.php?url=https%3A%2F%2Fdougvitale.wordpress.com%2F2011%2F12%2F21%2Fdeprecated-linux-networking-commands-and-their-replacements%2F)
|
||||
* Follow
|
||||
* [Sign up](https://wordpress.com/start/)
|
||||
* [Log in](https://wordpress.com/log-in?redirect_to=https%3A%2F%2Fdougvitale.wordpress.com%2F2011%2F12%2F21%2Fdeprecated-linux-networking-commands-and-their-replacements%2F&signup_flow=account)
|
||||
* [Copy shortlink](https://wp.me/pNKAH-8W)
|
||||
* [Report this content](http://en.wordpress.com/abuse/)
|
||||
* [Manage subscriptions](https://subscribe.wordpress.com/)
|
||||
* Collapse this bar
|
||||
|
||||
|
||||
%d bloggers like this:
|
||||
|
||||
Send to Email Address Your Name Your Email Address
|
||||
|
||||
[Cancel](#cancel)
|
||||
|
||||
Post was not sent - check your email addresses!
|
||||
|
||||
Email check failed, please try again
|
||||
|
||||
Sorry, your blog cannot share posts by email.
|
||||
|
||||

|
||||
@@ -1,166 +0,0 @@
|
||||
---
|
||||
title: Desing Patterns in Golang - Factory Method
|
||||
source: http://blog.ralch.com/tutorial/design-patterns/golang-factory-method/
|
||||
---
|
||||
[[Go MOC]]
|
||||
|
||||
[Desing Patterns in Golang: Factory Method](http://blog.ralch.com/tutorial/design-patterns/golang-factory-method/)
|
||||
Sun, Jan 31, 2016
|
||||
|
||||
#### Introduction
|
||||
|
||||
The `Factory Method` pattern is a design pattern used to define a runtime interface for creating an object. It’s called a factory because it creates various types of objects without necessarily knowing what kind of object it creates or how to create it.
|
||||
|
||||
#### Purpose
|
||||
|
||||
* Allows the sub-classes to choose the type of objects to create at runtime
|
||||
* It provides a simple way of extending the family of objects with minor changes in application code.
|
||||
* Promotes the loose-coupling by eliminating the need to bind application-specific structs into the code
|
||||
|
||||
#### Design Pattern Diagram
|
||||
|
||||
The structs and objects participating in this pattern are: product, concreate product, creator and concrete creator. The Creator contains one method to produce one type of product related to its type.
|
||||
|
||||

|
||||
|
||||
* `Product` defines the interface of objects the factory method creates
|
||||
* `ConcreteProduct` implements the Product interface
|
||||
* `Creator` declares the factory method, which returns an object of type Product
|
||||
* `ConcreteCreator` overrides the factory method to return an instance of a Concrete Product
|
||||
|
||||
#### Implementation
|
||||
|
||||
The Factory Method defines an interface for creating objects, but lets subclasses decide which classes to instantiate. In these example, we will adopt the pattern to create document object model of Scalable Vector Graphics.
|
||||
|
||||
The SVG format can contains multiple elements. In this example, we will illustrate only some of the shape elements. In the context of `Factory Method` design pattern, they are our product.
|
||||
|
||||
Every shape implements the `Shape` interface, which expose a `Draw` function that generates the required XML element:
|
||||
|
||||
```go
|
||||
type Shape interface {
|
||||
Draw(io.Writer) error
|
||||
}
|
||||
```
|
||||
|
||||
In the following code snippets, we will illustrate two implementations of `Shape` interface `Circle` and `Ractangle`:
|
||||
|
||||
```go
|
||||
type Circle struct {
|
||||
Location Point
|
||||
Radius float64
|
||||
}
|
||||
|
||||
func (c *Circle) Draw(w io.Writer) error {
|
||||
_, err := fmt.Fprintf(w, `<circle cx="%f" cy="%f" r="%f"/>`, c.Location.X, c.Location.Y, c.Radius)
|
||||
return err
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
```go
|
||||
type Rectangle struct {
|
||||
Location Point
|
||||
Size Size
|
||||
}
|
||||
|
||||
func (rect *Rectangle) Draw(w io.Writer) error {
|
||||
_, err := fmt.Fprintf(w, `<rect x="%f" y="%f" width="%f" height="%f"/>`, rect.Location.X, rect.Location.Y, rect.Size.Width, rect.Size.Height)
|
||||
return err
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Every of them has a function that is responsible for their instantiation based on the provided `Viewport`. The `Viewport` is an argument which keeps an information about the location and the size of the view port.
|
||||
|
||||
```go
|
||||
type ShapeFactory interface {
|
||||
Create(viewport Viewport) Shape
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The `CircleFactory` creates a `Circle` instance that has radius, which fits the viewport:
|
||||
|
||||
```go
|
||||
type CircleFactory struct{}
|
||||
|
||||
func (factory *CircleFactory) Create(viewport Viewport) Shape {
|
||||
return &Circle{
|
||||
Location: viewport.Location,
|
||||
Radius: math.Min(viewport.Size.Width, viewport.Size.Height),
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The `RectangleFactory` produces a rectangle that fits the viewport:
|
||||
|
||||
```go
|
||||
type RactangleFactory struct{}
|
||||
|
||||
func (factory *RactangleFactory) Create(viewport Viewport) Shape {
|
||||
return &Rectangle{
|
||||
Location: viewport.Location,
|
||||
Size: viewport.Size,
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The main object `Document` has a `Draw` function, which composes a different shapes created by provided factories. The `Document` can be instaciated with different set of factories. This allow to customize and change the document’s content:
|
||||
|
||||
```go
|
||||
type Document struct {
|
||||
ShapeFactories []ShapeFactory
|
||||
}
|
||||
|
||||
func (doc *Document) Draw(w io.Writer) error {
|
||||
viewport := Viewport{
|
||||
Location: Point{
|
||||
X: 0,
|
||||
Y: 0,
|
||||
},
|
||||
Size: Size{
|
||||
Width: 640,
|
||||
Height: 480,
|
||||
},
|
||||
}
|
||||
if _, err := fmt.Fprintf(w, `<svg height="%f" width="%f">`, viewport.Size.Height, viewport.Size.Width); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
for _, factory := range doc.ShapeFactories {
|
||||
shape := factory.Create(viewport)
|
||||
if err := shape.Draw(w); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
|
||||
_, err := fmt.Fprint(w, `</svg>`)
|
||||
return err
|
||||
}
|
||||
```
|
||||
|
||||
We should instaciate the `Document` struct with the available factories in the following way:
|
||||
|
||||
```go
|
||||
doc := &svg.Document{
|
||||
ShapeFactories: []svg.ShapeFactory{
|
||||
&svg.CircleFactory{},
|
||||
&svg.RactangleFactory{},
|
||||
},
|
||||
}
|
||||
|
||||
doc.Draw(os.Stdout)
|
||||
```
|
||||
|
||||
You can get the full source code from [github](https://github.com/svett/golang-design-patterns/tree/master/creational-patterns/factory-method).
|
||||
|
||||
Important aspects when we implement the Factory Method design pattern are:
|
||||
|
||||
* Designing the arguments of the factory method
|
||||
* Considering an internal object pool that will allow object cache and reuse instead of created from scratch
|
||||
|
||||
#### Verdict
|
||||
|
||||
The Factory Method is one of the most used design patterns. It makes a design more customizable and only a little more complicated. Other design patterns require new structs, whereas Factory Method only requires a new operation. The Factory Method is similar to Abstract Factory but without the emphasis on families.
|
||||
@@ -1,52 +0,0 @@
|
||||
---
|
||||
title: "Die Praxis-Lösung: Nie mehr Fehler durch zu lange Pfade bei Windows 10"
|
||||
source: https://www.computerwissen.de/windows/windows-troubleshooting/fehlermeldung/die-praxis-loesung-nie-mehr-fehler-durch-zu-lange-pfade-bei-windows-10/
|
||||
tags:
|
||||
- IT/OS/Windows
|
||||
---
|
||||
|
||||

|
||||
Die Praxis-Lösung: Nie mehr Fehler durch zu lange Pfade bei Windows 10
|
||||
© sdecoret - Adobe Stock
|
||||
|
||||
Erfahren Sie, wie Sie die Längenbegrenzung bei Pfaden aufheben
|
||||
|
||||
<img width="42" height="42" src="../_resources/csm_computerwissen-logo_a75d2114_6143768825d24332b.png"/>](https://www.computerwissen.de/unsere-experten/redaktion-computerwissen/)
|
||||
|
||||
Veröffentlicht am 17.12.2018 |
|
||||
|
||||
Zuletzt aktualisiert am 30.11.2020
|
||||
|
||||
Vergeben Sie bei Windows 10 einen Datei- oder Ordnernamen, haben Sie dafür bis zu 256 Zeichen zur Verfügung. Da können Sie einen halben Roman als Dateinamen schreiben.
|
||||
|
||||
Doch in der Praxis führen lange Dateinamen ebenso wie ordentlich verzweigte Ordner schnell zu einem Fehler. Ein Pfad darf nämlich maximal 260 Zeichen lang sein, also nur vier Zeichen länger als ein Dateiname.
|
||||
|
||||
Solange Sie eine Datei mit einem 256 Zeichen langen Dateinamen im Hauptverzeichnis eines Laufwerks abspeichern, tritt kein Fehler auf. Der Pfad der Festplatte ist zum Beispiel bei „C:\\“ nur drei Zeichen lang.
|
||||
|
||||
Doch wehe, wenn Sie die Datei im Pfad **C:\\BENUTZER\\MICHAEL-ALEXANDER BEISECKER\\DOKUMENTE\\BRIEFE** ablegen. Dann meckert Windows, denn der Pfad hat schon allein 55 Zeichen. Zusammen mit einem Dateinamen von 256 Zeichen sind es dann insgesamt 311 Zeichen oder anders ausgedrückt 51 Zeichen zu viel.
|
||||
|
||||
Schalten Sie die Längenbegrenzung für die Pfade ab. Dazu führen Sie eine Änderung in der Registrierungsdatenbank von Windows durch:
|
||||
|
||||
**1.** Öffnen Sie mit Tastenkombination "**WINDOWS+R**" das **AUSFÜHREN**\-Fenster.
|
||||
|
||||
**2.** Geben Sie **regedit** gefolgt von der **Eingabetaste** ein und bestätigen Sie mit einem Klick auf **JA**, dass der Registrierungseditor ausgeführt werden soll.
|
||||
|
||||
**3.** Blättern Sie bis zum Pfad **HKEY \_CURRENT\_USER\\SOFTWARE\\ MICROSOFT\\WINDOWS\\CURRENTVERSION\\GROUP POLICY OBJECTS\\**
|
||||
|
||||
**4\.** Klicken Sie auf den Zweig in geschweiften Klammern, bei dem am Ende **MACHINE** steht. Ein Beispiel: **{952C039A-B277-4F7E-9E87- 7E391F0BBE06}MACHINE\\** Die Angabe in den geschweiften Klammern weicht dabei in Ihrem Fall ab.
|
||||
|
||||
**5.** Klicken Sie auf **SYSTEM**. Ist **SYSTEM** nicht vorhanden, legen Sie es mit **NEU – SCHLÜSSEL** und dem Namen **SYSTEM** an und klicken dann darauf.
|
||||
|
||||
**6\.** Klicken Sie innerhalb von **SYSTEM** auf **CURRENTCONTROLSET**. Ist **CURRENTCONTROLSET** nicht vorhanden, legen Sie es wie bei **SYSTEM** zuerst mit **NEU** und **SCHLÜSSEL** an.
|
||||
|
||||
**7\.** Klicken Sie innerhalb von **CURRENTCONTROLSET** auf **POLICIES**. Ist **POLICIES** nicht vorhanden, legen Sie es mit **NEU** und **SCHLÜSSEL** an.
|
||||
|
||||
**8\.** Klicken Sie ins rechte Fenster und legen Sie dort mit **NEU** und **DWORD-WERT** (32 BIT) den Wert **LONGPATHS-ENABLED** an, was übersetzt so viel wie „lange Pfade aktiviert“ bedeutet.
|
||||
|
||||
**9\.** Klicken Sie auf **LONGPATHS-ENABLED** und ändern Sie den Wert von **0** auf **1**. Das bedeutet, Pfade können nun länger als 260 Zeichen sein.
|
||||
|
||||
Die Änderung wird nach dem nächsten Windows-Start aktiv.
|
||||
|
||||
**Meine Empfehlung:** Sie können die Einstellung jederzeit wieder rückgängig machen. Ändern Sie den Wert von **LONGPATHS-ENABLED** einfach wieder von **1** in **0.** Haben Sie Fragen zu den Registry-Änderungen oder treten nicht behebbare Fehler im Zusammenhang mit Datei- und Pfadnamen auf, helfe ich Ihnen über den Computerwissen Club:
|
||||
|
||||
[club.computerwissen.de](https://club.computerwissen.de/)
|
||||
@@ -1,390 +0,0 @@
|
||||
---
|
||||
title: Documentation as Code mit Asciidoctor
|
||||
source: https://www.heise.de/hintergrund/Documentation-as-Code-mit-Asciidoctor-4642013.html?seite=all
|
||||
tags:
|
||||
- IT/Development/Asciidoctor
|
||||
---
|
||||
|
||||
1. Documentation as Code mit Asciidoctor
|
||||
- [Git versus Microsoft Word](#nav__git_versus__0 " Git versus Microsoft Word")
|
||||
- [Wer steckt dahinter?](#nav_wer_steckt__1 "Wer steckt dahinter?")
|
||||
- [Willkommen im Projekt](#nav_willkommen_im__2 "Willkommen im Projekt")
|
||||
- [Die Entwicklerdokumentation](#nav_die__3 "Die Entwicklerdokumentation")
|
||||
- [Fachliche Dokumentation](#nav_fachliche__4 "Fachliche Dokumentation")
|
||||
- [IT-Architekturdokumentation](#nav_it_architekturdo__5 "IT-Architekturdokumentation")
|
||||
- [API-Dokumentation mit Beispielen](#nav_api_dokumentatio__6 "API-Dokumentation mit Beispielen")
|
||||
- [Arbeitsalltag mit Docs as Code](#nav_arbeitsalltag__7 "Arbeitsalltag mit Docs as Code")
|
||||
- [Refactoring und Strukturierungen](#nav_refactoring_und__8 "Refactoring und Strukturierungen")
|
||||
- [Ausliefern von Dokumenten](#nav_ausliefern_von__9 "Ausliefern von Dokumenten")
|
||||
- [Publizieren als HTML](#nav_publizieren_als__10 "Publizieren als HTML")
|
||||
- [Publizieren als PDF](#nav_publizieren_als__11 "Publizieren als PDF")
|
||||
- [Fazit](#nav_fazit_12 "Fazit")
|
||||
|
||||
Bei Documentation as Code sind Dokumente Teil von Code-Reviews, und der Continuous-Integration-Server erzeugt nicht nur lauffähige Software, sondern auch die dazu passenden Dokumente als druckfertige PDF- oder Online-Dokumentation. Dieser Artikel stellt Beispiele hierfür vor. Im Fokus steht das Asciidoctor-Projekt, um das in den letzten Jahren ein Ökosystem mit verschiedenen Werkzeugen entstanden ist.
|
||||
|
||||
### Git versus Microsoft Word
|
||||
|
||||
Wer mit Office-Dateiformaten wie Microsoft Word arbeitet, kann seine Dokumente lokal bearbeiten, drucken und per E-Mail oder Dateiablage mit anderen Autoren teilen. Je nach Infrastruktur lassen sich Dokumente gemeinsam via SharePoint oder OneDrive bearbeiten. Spätestens, wenn verschiedene bearbeitete Dokumentenversionen über Organisationsgrenzen zusammenzuführen sind, wird es schwierig. Eine Alternative dazu sind Wikis, in denen die Autoren gemeinsam an Dokumenten arbeiten. Hakelig ist meist das Aufbereiten der Inhalte zu druckfertigen Dokumenten mit ansprechendem Layout. Beide Ansätze kommen an ihre Grenzen, wenn Entwickler verschiedene Versionen der Dokumente zum Beispiel für unterschiedliche Software-Releases parallel pflegen sollen.
|
||||
|
||||
Versionskontrollsysteme wie Git punkten auf der anderen Seite mit einer komfortablen Unterstützung für Release-Branches: Änderungen lassen sich zwischen diesen mit Merges und Cherry-Picks übernehmen. Für jede Zeile und jedes Zeichen können sie zurückverfolgen, wer die Änderung wann und – einen entsprechenden Commit-Kommentar vorausgesetzt – aus welchem Grund durchgeführt hat. Das klappt aber nur, wenn es sich bei den Dateien um Textdateien wie Quellcode handelt. Bei Office-Formaten, die eine binäre Struktur haben, versagen diese Funktionen.
|
||||
|
||||
Nutzt ein Team Dokumentationsformate, die nicht auf binären Strukturen basieren, kann es von einer Versionsverwaltung in Git profitieren. Dann umfassen Code-Reviews nicht nur Änderungen am Programmcode, sondern auch die an der Dokumentation. Einfache Textdateien als Dokumentation sind allerdings keine Lösung, wenn Teams eine hochwertige und gut strukturierte Dokumentation erstellen sollen. Im mathematisch-wissenschaftlichen Bereich ist LaTeX der Platzhirsch: Damit lassen sich sowohl HTML- als auch PDF-Dateien erzeugen. Im Publishing-Bereich gibt es zudem Formate wie DocBook und DITA.
|
||||
|
||||
Um Neueinsteigern schnelle Erfolge bei der Dokumentation zu ermöglichen, sind verschiedene Ökosysteme entstanden. Beispiele dafür sind Markdown, AsciiDoc und reStructuredText. Diese Formate sind alle in ihrem Quellformat in einem Texteditor direkt les- und bearbeitbar. Über Konverter lassen sie sich in hochwertige HTML- und PDF-Ausgaben umwandeln, die Auszeichnungen für Überschriften, Querverweise und Inhaltsverzeichnisse bieten.
|
||||
|
||||
Der Wechsel auf ein solches Format verändert die Arbeitsweise mit Dokumenten im Team:
|
||||
|
||||
- Die Trennung von Inhalt und Formatierung wird gefördert: Inhalte in den Quelldateien werden erst im Build-Server mit Stylesheets und Formatvorlagen zusammengeführt.
|
||||
- Inhalte lassen sich an unterschiedlichen Stellen wiederverwenden, verschieden komponieren und so für verschiedene Empfänger aufbereiten.
|
||||
- Entwickler bearbeiten Dokumente in ihrer Entwicklungsumgebung, sodass die Hürde sinkt, Dokumentation zu schreiben.
|
||||
- Fachanwender erhalten in ihren Dokumenten einen Verweis zur Versionsverwaltung und können Änderungen direkt über die Weboberfläche vornehmen. Je nach Berechtigung und Team-Workflow wird die Änderung direkt übernommen oder erzeugt einen Pull-Request, den eine zweite Person begutachtet.
|
||||
|
||||
Im weiteren Verlauf des Artikels geht es um das Format AsciiDoc. Im Vergleich zu Markdown bietet es eine große Ausdrucksstärke, die alle Elemente umfasst, die für das Erstellen eines Buchs notwendig sind – inklusive mathematischem Formelsatz, Tabellen, Fußnoten und Textauszeichnungen. Gleichzeitig ist es einfach genug, um auch für gelegentliche Nutzer erlernbar zu sein.
|
||||
|
||||
### Wer steckt dahinter?
|
||||
|
||||
AsciiDoc als Sprache und Implementierung startete vor über 15 Jahren mit Stuart Rackham als Maintainer. Der offizielle Nachfolger ist das [Asciidoctor-Projekt](https://asciidoctor.org/) mit dem Project Lead Dan Allan und einer Ruby-Implementierung, die auch für JavaScript- und Java-Umgebungen verfügbar ist.
|
||||
|
||||
Die Website des Asciidoctor-Projekts bietet verschiedene Einstiegspunkte: Eine [Syntax Quick Reference](https://asciidoctor.org/docs/asciidoc-syntax-quick-reference/) für den Kurzeinstieg in die Syntax, einen [Writer's Guide](https://asciidoctor.org/docs/asciidoc-writers-guide/), der Einsteigern die Konzepte vorstellt, und ein [User Manual](https://asciidoctor.org/docs/user-manual/), das alle Details rund um Sprache, Installation von Konvertern sowie Tipps und Kniffe enthält.
|
||||
|
||||
Die eigentliche Asciidoctor-Implementierung konvertiert als Ruby-Kommandozeilenprogramm Quelldateien im AsciiDoc-Format in HTML, PDF, DocBook und andere Formate. Damit eignet sie sich für den Einsatz auf Continuous-Integration-Servern. Verpackt als Plug-in für Gradle, Maven oder npm ist sie Teil von Build-Skripten und benötigt keine zusätzliche Installation von Werkzeugen außerhalb des Build-Tools, da sie die Java- beziehungsweise JavaScript-Runtime des Build-Prozesses nutzt.
|
||||
|
||||
Beim Bearbeiten der Quelldateien finden Entwickler für ihre jeweilige IDE [Plug-ins, die sowohl Syntax-Highlighting als auch Live-Preview unterstützen](https://asciidoctor.org/docs/editing-asciidoc-with-live-preview/).
|
||||
|
||||
### Willkommen im Projekt
|
||||
|
||||
Wenn Entwickler in einem neuen Projekt starten, benötigen sie ein paar Eckdaten: Wie heißt das Projekt? Worum geht es? Wo finde ich weitere Informationen? Im AsciiDoc-Format sieht es wie folgt aus:
|
||||
|
||||
```markdown
|
||||
= Ultimatives App-Projekt
|
||||
|
||||
Mit diesem Projekt machen wir unsere Kundinnen und Kunden glücklich!
|
||||
|
||||
== Was uns einzigartig macht
|
||||
|
||||
- Funktionen, die niemand anderes hat.
|
||||
- Durchdachte Interaktion für alle und Nutzerinnen und Nutzer.
|
||||
- ...
|
||||
|
||||
== So startest du als Entwickler
|
||||
|
||||
Starte die Anwendung im Entwicklungsmodus mit folgenden zwei Kommandos:
|
||||
|
||||
npm install
|
||||
npm run dev
|
||||
|
||||
== Mehr Informationen
|
||||
|
||||
In unserem https://github.com/dummy[GitHub-Repository] findest du unsere Ticket-Verwaltung.
|
||||
```
|
||||
|
||||
Am Anfang steht der Titel, den ein Gleichheitszeichen (=) einleitet. Zwei Gleichheitszeichen leiten die Überschriften der ersten Ebene ein. Aufzählungen starten mit einem Spiegelstrich. Kommandos auf der Kommandozeile sind etwas eingerückt. Ein Link mit URL und als dargestellter Text steht im letzten Abschnitt.
|
||||
|
||||
Dieser Text könnte auch eins zu eins in einer Begrüßungs-E-Mail an neue Entwickler stehen. Als Konvention hat es sich jedoch etabliert, dass ein solcher Text in einer Datei *README.adoc* im Wurzelverzeichnis eines Quellcode-Repositorys steht. *.adoc* ist dabei die übliche Dateiendung für AsciiDoc-Dateien. Versionsverwaltungen wie GitHub oder GitLab erkennen *README* als die Datei, die sie auf der Startseite eines Repositorys automatisch anzeigen. Dabei zeigen sie nicht die Textversion an, sondern formatieren sie ähnlich wie unten dargestellt mit hervorgehobenen Überschriften, Aufzählungen und Links.
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/example-readme-preview-716c78a96159d959.png)
|
||||
Ausgabe des README als HTML (Abb. 1)
|
||||
|
||||
### Die Entwicklerdokumentation
|
||||
|
||||
Wenn Entwickler in einem neuen Projekt anfangen, ist ein *README.adoc* ein erster guter Start. Danach benötigen sie weitere Informationen mit Codebeispielen. Bei der Navigation in einem solchen Dokument hilft ein Inhaltsverzeichnis. Querverweise im Dokument erleichtern selektives, nichtlineares Lesen im Dokument. Hier ein Beispiel aus einem Entwicklungshandbuch. Das Attribut `toc` zu Beginn des Dokuments generiert ein automatisches Inhaltsverzeichnis:
|
||||
|
||||
```asciidoc
|
||||
= Entwicklungshandbuch
|
||||
Vorname Nachname <autor@asciidoctor.org>
|
||||
1.0, 31.10.2019: Halloween Release
|
||||
:toc-title: Inhaltsverzeichnis
|
||||
:toc:
|
||||
:icons: font
|
||||
|
||||
// Bitte den Abschnitten IDs geben, um sie später referenzieren zu können!
|
||||
[[sec:code-conventions]]
|
||||
== Code-Konventionen
|
||||
|
||||
Hier eine kurze Einführung in unsere Code-Konventionen.
|
||||
|
||||
.Beispielcode
|
||||
[source,java]
|
||||
----
|
||||
/**
|
||||
* Beschreibung, warum diese Methode existiert. <1>
|
||||
*/
|
||||
public int calculatePowerOfTwo(int num) {
|
||||
return num * num; // <2>
|
||||
}
|
||||
----
|
||||
<1> Wir dokumentieren unsere Methoden, es sei denn, es sind einfache Getter- und Setter.
|
||||
<2> Du kannst den Wert direkt zurückgeben, ohne ihn vorher in eine Zwischenvariable zu schreiben.
|
||||
|
||||
[[sec:code-review]]
|
||||
== Code-Review
|
||||
|
||||
. Prüfe die <<sec:code-conventions>>!
|
||||
. Gibt es Kommentare, die das "`Warum`" beschreiben?
|
||||
. Gibt es einen Test, der neue Code-Teile abdeckt?
|
||||
|
||||
NOTE: Code-Reviews sind unsere erste Verteidigungslinie gegen Bugs in Produktion!
|
||||
```
|
||||
|
||||
Im Listing des Handbuchs ist der annotierte Quellcode sichtbar. Die einzelnen Nummern im Quellcode verweisen auf kurze Hinweise darunter. Ein Hinweis ist mit `NOTE:` hervorgehoben.
|
||||
|
||||
In eine HTML-Datei konvertiert wird der annotierte Quellcode wie abgebildet dargestellt. Die hervorgehobenen Hinweise stellt die HTML-Ausgabe als Icons dar, da das Attribut `icons` auf den Wert `font` gesetzt wurde. Der Quellcode wird durch Syntax-Highlighting lesbarer.
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/example-devdocs-preview-5e28e2e9a9bfdfc6.png)
|
||||
Ausgabe der Entwicklerdokumentation als HTML (Abb. 2)
|
||||
|
||||
Das vorherige Beispiel enthielt Quellcode, der als Auszug aus einer Datei in das Dokument hineinkopiert wurde. Das kann dazu führen, dass der Quellcode in der Originaldatei angepasst wird, in der Dokumentation jedoch nicht oder nur unvollständig. Dadurch wäre das Codebeispiel veraltet und kompiliert vielleicht nicht mehr. Besser ist es, die Zeilen zu referenzieren statt sie zu kopieren. Hier ein Beispiel zunächst des Quellcodes mit zusätzlichen `tags`-Kommentaren, dann eingebunden in ein Dokument:
|
||||
|
||||
```asciidoc
|
||||
public class Calculator {
|
||||
// tag::mymethod[]
|
||||
public int calculatePowerOfTwo(int num) {
|
||||
return num * num; // <2>
|
||||
}
|
||||
// end::mymethod[]
|
||||
}
|
||||
|
||||
[source,java,indent=0]
|
||||
----
|
||||
include::Calculator.java[tag=mymethod]
|
||||
----
|
||||
<2> Du kannst den Wert direkt zurückgeben...
|
||||
```
|
||||
|
||||
Damit kompilieren die Codebeispiele und sind wie jeder andere Code durch Unit-Tests testbar. Die zusätzliche Option `indent=0` passt die Einrückung an und entfernt die führenden Leerzeichen des ausgeschnittenen Codebeispiels. Das ermöglicht Entwicklungshandbücher von hoher Qualität.
|
||||
|
||||
### Fachliche Dokumentation
|
||||
|
||||
Für eine fachliche Dokumentation braucht es aber mehr als Quellcode und Referenzen. Hier sind Tabellen und Diagramme gefragt, die Inhalte strukturieren und übersichtlicher darstellen können als ein langer Text. Eine einfache Tabelle sieht im Quellcode wie folgt aus:
|
||||
|
||||
```markdown
|
||||
|===
|
||||
|Thema |Text |Mehr...
|
||||
|
||||
|Ein Thema
|
||||
|Text
|
||||
|Noch mehr Text
|
||||
|
||||
|Zweites Thema
|
||||
|Text Nr. 2
|
||||
|Ganz viel Text
|
||||
|===
|
||||
```
|
||||
|
||||
Als HTML-Ausgabe stellt es sich wie folgt dar:
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/abb3-067ddda24b50a64c.png)
|
||||
Darstellung einer Tabelle (Abb. 3)
|
||||
|
||||
Mit zusätzlichen Attributen erlaubt AsciiDoc Textausrichtung und horizontal und vertikal zusammengefasste Zellen. Für mathematisch-wissenschaftliche Darstellungen bietet es Formeln im LaTeX- und AsciiMath-Format. Aus folgendem Text wird mit [MathJax](https://www.mathjax.org/) in der Ausgabe eine gesetzte Formel.
|
||||
|
||||
```asciidoc
|
||||
stem:[sqrt(4) = 2]
|
||||
|
||||
Eine Matrix: stem:[[[a,b\],[c,d\]\](https://www.heise.de/hintergrund/(n),(k))].
|
||||
|
||||
latexmath:[C = \alpha + \beta Y^{\gamma} + \epsilon]
|
||||
```
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/abb4-94dd414d9500f058.png)
|
||||
Darstellung der Formeln in der Ausgabe (Abb. 4)
|
||||
|
||||
UML-Diagramme wie ein Ablaufdiagramm lassen sich über [PlantUML](https://plantuml.com/) als Text beschreiben und als Grafik ausgeben:
|
||||
|
||||
```asciidoc
|
||||
@startuml
|
||||
|Akteur A|
|
||||
start
|
||||
:Schritt 1;
|
||||
|#AntiqueWhite|Akteur B|
|
||||
' Dies ist ein Kommentar im
|
||||
' Quellcode des Diagramms
|
||||
:Schritt 2;
|
||||
:Schritt 3;
|
||||
|Akteur A|
|
||||
:Schritt 4;
|
||||
|Akteur B|
|
||||
:Schritt 5;
|
||||
stop
|
||||
@enduml
|
||||
```
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/abb5-7b5bfc5742569b0d.png)
|
||||
Ablaufdiagramm in der Ausgabe (Abb. 5)
|
||||
|
||||
Auch für diese Diagramme ist in der Versionshistorie nachvollziehbar, wer sie wann und als Teil von welcher Aufgabe warum geändert hat.
|
||||
|
||||
### IT-Architekturdokumentation
|
||||
|
||||
Alle Elemente, die die fachliche Dokumentation nutzt, eignen sich auch für eine IT-Architekturdokumentation: Sie benötigt ebenso Tabellen, Diagramme, Querverweise et cetera. Um nicht bei jedem neuen Projekt von vorne zu beginnen, gibt es frei verfügbare Vorlagen. [Eine solche Vorlage findet sich unter arc42.de](https://arc42.de/). Sie ist in AsciiDoc geschrieben und unterstützt Projekte durch eine erprobte Dokumentationsstruktur. Projekte können sie im Projektverlauf nach und nach füllen. Erklärende Kommentare helfen beim Schreiben der Kapitel, sodass sich auch Einsteiger im Bereich Architekturdokumentation zurechtfinden.
|
||||
|
||||
Das arc42-Projekt zeigt außerdem, wie Dokumentations-Pipelines funktionieren: Die Vorlage wird im AsciiDoc-Format gepflegt. Daraus erstellt ein automatischer Build-Prozess verschiedene Zielformate: unter anderem Word, Markdown, HTML und reStructuredText.
|
||||
|
||||
### API-Dokumentation mit Beispielen
|
||||
|
||||
Neben aufgeschriebenen Texten gibt es in Projekten immer wieder automatisch erzeugte Inhalte. Das sind zum Beispiel technische Datenmodelle, die man aus dem Datenbankschema erzeugt, oder Listen von Fehler-Codes und -beschreibungen, die Entwickler im Programm als Konstanten hinterlegt haben und aus denen Handbücher generiert werden. Hier hilft eine [einfache Template-Sprache wie Freemarker](https://freemarker.apache.org/), um Dokumentationsteile automatisiert zu erstellen.
|
||||
|
||||
Das [Konzept von Spring REST Docs](https://docs.spring.io/spring-restdocs/docs/current/reference/html5/) geht noch etwas weiter: Es nutzt für die Dokumentation von REST-Schnittstellen Beispielanfragen und -antworten, die in automatisierten Testfällen aufgezeichnet werden. Diese ergänzt man um zusätzlichen erklärenden Text. Das Ergebnis ist eine Dokumentation, die mit konkreten Beispielen zeigt, wie die Schnittstelle genutzt werden soll. Im Vergleich zu einer Schnittstellendokumentation im OpenAPI-Format, die nur Methoden und Felder zeigt (Syntax und ggf. etwas Semantik), ist das ein deutlicher Zugewinn von Verwendung und Bedeutung (Pragmatik): Die verschiedenen Aufrufe und Felder werden in einen Kontext gesetzt im Ablauf gezeigt.
|
||||
|
||||
Neben dem vorgestellten AsciiDoc-`include`-Makro bringt Spring REST Docs ein zusätzliches `operation`-Makro mit, das aufgezeichnete Elemente (Snippets) einbindet. Hier ein Auszug aus einem [offiziellen Beispiel des Spring-REST-Docs-Projekts](https://github.com/spring-projects/spring-restdocs/tree/master/samples/rest-notes-spring-hateoas):
|
||||
|
||||
```asciidoc
|
||||
=== Listing notes
|
||||
|
||||
A `GET` request will list all of the service's notes.
|
||||
|
||||
operation::notes-list-example[snippets='response-fields,curl-request,http-response']
|
||||
```
|
||||
|
||||
Ein Test zeichnet die Antworten auf und prüft, ob die erwarteten Felder in der Antwort enthalten sind:
|
||||
|
||||
```java
|
||||
@Test
|
||||
public void notesListExample() throws Exception {
|
||||
|
||||
/* .... */
|
||||
|
||||
this.mockMvc.perform(get("/notes"))
|
||||
.andExpect(status().isOk())
|
||||
.andDo(document("notes-list-example",
|
||||
responseFields(
|
||||
subsectionWithPath("_embedded.notes").description("An array of [Note](#note) resources"),
|
||||
subsectionWithPath("_links").description("Links to other resources"))));
|
||||
}
|
||||
```
|
||||
|
||||
Das `operation`-Makro fügt in der Ausgabe die Beschreibung der Antwortfelder, den Aufruf als `curl`-Befehl und die HTTP-Antwort im JSON-Format ein:
|
||||
|
||||
[](https://www.heise.de/imgs/18/2/8/2/7/9/0/3/abb6-263275e61056170a.png)
|
||||
Ausgabe der API-Dokumentation als HTML (Abb. 6)
|
||||
|
||||
Analog zur Entwicklerdokumentation, die per `include` getestete Codebeispiele anzeigt, entsteht hier eine Schnittstellendokumentation mit getesteten Beispielen.
|
||||
|
||||
### Arbeitsalltag mit Docs as Code
|
||||
|
||||
Die AsciiDoc-Dokumente sind zunächst einfache Textdateien. Bei der Bearbeitung hilft eine Entwicklungsumgebung mit entsprechenden Plug-ins. Bei der Übersicht hilft Strukturierung in handliche Dokumententeile.
|
||||
|
||||
Während sich das erste *README.adoc* noch intuitiv in jedem Texteditor bearbeiten lässt, zeigt die Entwicklungsdokumentation mehr Funktionen. Eine passende Überstützung im Editor erlaubt eine komfortable Bearbeitung der Dateien, zum Beispiel durch Syntax-Highlighting, Navigation zu Includes und Referenzen und Livevorschau bei Änderungen. Entsprechende Plug-ins gibt es etwa für [Eclipse](https://marketplace.eclipse.org/content/asciidoctor-editor), [IntelliJ IDEA](https://github.com/asciidoctor/asciidoctor-intellij-plugin), [Atom](https://atom.io/packages/asciidoc-assistant) und [Visual Studio Code](https://marketplace.visualstudio.com/items?itemName=joaompinto.asciidoctor-vscode).
|
||||
|
||||
Der Autor dieses Artikels ist Maintainer des Plug-ins für IntelliJ IDEA. Es bietet eine Strukturansicht des Dokuments für einen Überblick über die Kapitelstruktur und zur Navigation. Die bekannten Tastaturkürzel funktionieren, um zum Beispiel zu einer Referenz zu springen oder Referenzen über Dateigrenzen umzubenennen. Mit der für IntelliJ IDEA verfügbaren Rechtschreib- und [Grammatikprüfung Grazie](https://plugins.jetbrains.com/plugin/12175-grazie/) zieht die IDE mit Office-Paketen gleich.
|
||||
|
||||
[Mit AsciidoctorFX gibt es außerdem einen Standalone-Editor](https://asciidocfx.com/), der einen großen Funktionsumfang für Vorschau und Plug-ins umfasst. Auf der Website des Editors sind einige Bücher verlinkt, die mit ihm in AsciiDoc geschrieben wurden.
|
||||
|
||||
### Refactoring und Strukturierungen
|
||||
|
||||
Wächst ein Dokument im Umfang, stellen sich die Fragen nach mehr Struktur und die Aufteilung in kleinere, handhabbare Dateien. Wem beim Wort "Master-Dokument" kalte Schauer bei der Erinnerung an vergangene Office-Abenteuer den Rücken herunterlaufen, sei beruhigt: Mit der gleichen `include::[]`-Syntax wie oben bei den eingebundenen Quellcodes lassen sich auch Dokumententeile nachvollziehbar und zuverlässig einbinden. Asciidoctor unterstützt mehrere `include`-Stufen, sodass das Master-Dokument die Kapitel und diese die Unterkapitel einbinden. Verschiedene Master-Dokumente können Kapitel und Unterkapitel unterschiedlich einbinden oder sortieren, sodass ein für den jeweiligen Empfängerkreis maßgeschneidertes Dokument entsteht.
|
||||
|
||||
Selbstdefinierte Attribute erlauben konsistente Textbausteine, Namen oder URLs, die sich dann in allen Kapiteln referenzieren lassen. Zeilen- und Blockkommentare geben Autoren Bearbeitungshinweise und erlauben es, Inhalte vorübergehend auszukommentieren.
|
||||
|
||||
```asciidoc
|
||||
= Hauptdokument
|
||||
|
||||
// selbstdefinierte Attribute für dieses Dokument
|
||||
:homepage: https://my.home.page
|
||||
|
||||
== Willkommen
|
||||
|
||||
Mehr Informationen finden Sie auf unserer {homepage}[Homepage]!
|
||||
|
||||
include::kapitel_ueberblick.adoc[]
|
||||
|
||||
include::kapitel_basisfunktionen.adoc[]
|
||||
|
||||
////
|
||||
Dieses Kapitel ist noch in Arbeit...
|
||||
include::kapitel_03.adoc[]
|
||||
////
|
||||
|
||||
////
|
||||
Dieses Kapitel nur ausgeben, wenn "premiumkunde" als Attribut gesetzt wurde,
|
||||
z. B. über die Kommandozeile wie hier
|
||||
asciidoctor -a premiumkunde dokument.adoc
|
||||
////
|
||||
ifdef::premiumkunde[]
|
||||
include::kapitel_premiumfunktionen.adoc[]
|
||||
endif::[]
|
||||
```
|
||||
|
||||
`ifdef` blendet abhängig von Attributen Teile des Dokuments ein und aus. Die Attribute lassen sich auf der Kommandozeile setzen oder im Build-Prozess zum Beispiel im Gradle- oder Maven-Plug-in für Asciidoctor übergeben.
|
||||
|
||||
### Ausliefern von Dokumenten
|
||||
|
||||
Ist ein erster Entwurf der Dokumente fertig, ist es an der Zeit, sie den Lesern zu präsentieren. Im Browser ist die Dokumentation einfach zugänglich und sie lässt sich als Teil in eine bestehende Website integrieren. Als PDF kann man die Dokumentation als einzelne versionierte Datei zum Beispiel als Handbuch einer Softwarelieferung mitgeben. [Für Präsentationen gibt es eine Integration in reveal.js](https://asciidoctor.org/docs/asciidoctor-revealjs/).
|
||||
|
||||
Die Inhalte der Präsentation schreiben Autoren in AsciiDoc, das Styling erfolgt über Themes ergänzt um individuelles CSS. [Die Präsentation der Folien übernimmt das JavaScript-Paket reveal.js](https://revealjs.com/#/).
|
||||
|
||||
Ein Continuous-Integration-Server erstellt diese Dokumente automatisch nach jeder Änderung an den Quellen; alle Schritte sind über wenige Kommandos automatisierbar. Wer verschiedene Quellen für seine Dokumentationspipeline anbinden möchte und verschiedene Formate und Systeme mit Dokumentation versorgen möchte, [dem sei das Projekt docToolchain ans Herz gelegt](https://doctoolchain.github.io/docToolchain/). Hier finden sich Anleitungen und Skripte, um viele wiederkehrende Aufgaben zu automatisieren. Damit lassen sich Quellen wie Sparx Enterprise Architect anbinden und Ergebnisse etwa nach Confluence publizieren.
|
||||
|
||||
### Publizieren als HTML
|
||||
|
||||
Meist ist ein einzelnes Dokument oder ein Master-Dokument in eine HTML-Datei zu wandeln. Am einfachsten gelingt das über die Kommandozeile, nachdem Ruby beziehungsweise JRuby und dasAsciidoctor Gem installiert sind:
|
||||
|
||||
```shell
|
||||
gem install asciidoctor
|
||||
```
|
||||
|
||||
In JavaScript-Umgebungen wird die Kommandozeilenversion für [Asciidoctor für Node.js](https://github.com/asciidoctor/asciidoctor-cli.js/) wie folgt installiert:
|
||||
|
||||
```shell
|
||||
npm i -g asciidoctor
|
||||
```
|
||||
|
||||
Ein einzelnes Dokument wird dann wie folgt konvertiert:
|
||||
|
||||
```shell
|
||||
asciidoctor document.adoc
|
||||
```
|
||||
|
||||
Das Ergebnis ist eine Datei *document.html*, die sich auf einem Webserver publizieren und im Browser anzeigen lässt. Wer keine Ruby- oder Node.js-Umgebung installieren möchte, kann die Konvertierung beispielsweise über einen Maven- oder Gradle-Build anstoßen.
|
||||
|
||||
Sollen Inhalte zur Laufzeit aufbereitet werden, bietet Asciidoctor APIs in Ruby, Java und JavaScript an. Hier ein JavaScript-Beispiel, das [zunächst ein alternatives Backend "Semantic-HTML für Asciidoctor" lädt und anschließend AsciiDoc in HTML konvertiert](https://github.com/jirutka/asciidoctor-html5s):
|
||||
|
||||
```js
|
||||
const asciidoctor = require("asciidoctor")(),
|
||||
asciidoctorHtml5s = require("asciidoctor-html5s")
|
||||
|
||||
// Register the HTML5s converter and supporting extension.
|
||||
asciidoctorHtml5s.register()
|
||||
|
||||
// default option
|
||||
const defaultOptions = {
|
||||
sourceHighlighter: "highlightjs",
|
||||
backend: "html5s"
|
||||
}
|
||||
|
||||
module.exports = function(content) {
|
||||
this.cacheable && this.cacheable()
|
||||
var params = loaderUtils.getOptions(this)
|
||||
var options = Object.assign({}, defaultOptions, params)
|
||||
var html = asciidoctor.convert(content, options)
|
||||
return "<section>" + html + "</section>"
|
||||
}
|
||||
```
|
||||
|
||||
Damit lassen sich Inhalte für Websites im AsciiDoc-Format verwalten und zur Build- oder Laufzeit in HTML wandeln und anzeigen. Die Inhalte können auf diese Weise vom Layout getrennt und an verschiedenen Stellen wiederverwendet werden.
|
||||
|
||||
Für Dokumentations-Websites integriert sich Asciidoctor in statische Website-Generatoren wie [Jekyll](https://github.com/asciidoctor/jekyll-asciidoc) oder [JBake](https://jbake.org/). Für große Projekte bietet sich [Antora](https://antora.org/) an, das Informationen aus mehreren Repositories und Branches zusammenführen und publizieren kann. Die Open-Source-Projekte [Couchbase](https://docs.couchbase.com/home/index.html) und [Fedora](https://docs.fedoraproject.org/en-US/fedora/f31/) nutzen beide Antora, um Dokumentation ihrer Releases auf einer Website darzustellen. Auf jeder Seite findet sich ein Edit-Button, der es Lesern ermöglicht, die Inhalte der Seite im AsciiDoc-Format im Browser zu bearbeiten.
|
||||
|
||||
### Publizieren als PDF
|
||||
|
||||
Um ein AsciiDoc-Dokument in ein PDF zu wandeln, stehen Nutzern verschiedene Implementierungen zur Verfügung:
|
||||
|
||||
1. Asciidoctor DocBook erzeugt auf Wunsch das DocBook-5.0-Format, aus dem sich über eine LaTeX- oder XSLT-FO-Verarbeitungskette druckfertige Dokumente erzeugen lassen.
|
||||
2. [Asciidoctor PDF Ruby](https://asciidoctor.org/docs/asciidoctor-pdf/) basiert auf Ruby und Prawn und läuft in jeder Ruby-, JRuby- und Java-Umgebung. Hierfür stehen auch Gradle- und Maven-Plug-ins zur Automatisierung zur Verfügung.
|
||||
3. [Asciidoctor PDF JavaScript](https://github.com/Mogztter/asciidoctor-pdf.js) basiert auf JavaScript und Puppeteer, das einen reduzierten Chrome-Browser (Chromium) für die PDF-Erstellung fernsteuert. Der Build lässt sich über npm oder yarn automatisieren, die auch Puppetteer und Chromium installieren.
|
||||
4. [Asciidoctor Latex](https://github.com/asciidoctor/asciidoctor-latex) ist eine Asciidoctor-Erweiterung, mit der man AsciiDoc-Dokumente ohne den Umweg über DocBook mit LaTeX in druckfertige Dokumente und PDFs wandelt.
|
||||
|
||||
Die populärste Implementierung ist die Asciidoctor-PDF-Ruby-Implementierung, da sie PDFs ohne zusätzliche Werkzeuge erstellen kann. Sie liegt derzeit als Release-Candiate-Version vor und unterstützt den kompletten AsciiDoc-Sprachumfang zur Formatierung von Text, Bildern und Tabellen. Über 900 Tests stellen sicher, dass es im Alltag keine Überraschungen gibt. Die Layouts sind parametrisierbar, sodass sich individuelle Schriftarten, Seitenformate und Abstände nutzen lassen. Die aus AsciiDoc generierten PDF können Anwender mit Seiten aus bestehenden PDFs ergänzen.
|
||||
|
||||
Die Implementierung mit dem größten Potenzial für ein individuelles PDF-Layout ist die JavaScript-Implementierung. Sie liegt derzeit als Alpha-Version vor. Während Prawn nur eingeschränktes Styling zulässt, stehen Designern hier die kompletten Möglichkeiten von CSS offen. Im Standardlayout sehen die Dokumente ähnlich wie die der Ruby-Implementierung aus; über Stylesheets lässt sich das Layout anpassen oder komplett individuell gestalten. Beispiele auf der Projektseite zeigen individuelle Layouts für Bücher, Cheatsheets, Briefe und Präsentationen.
|
||||
|
||||
### Fazit
|
||||
|
||||
Mit AsciiDoc nutzen Autoren aus der Softwareentwicklung bekannte Werkzeugen wie Git und IDEs und Methoden wie Code-Reviews, Refactorings, Includes und Continuous Integration. Es entstehen Websites und Handbücher mit Codebeispielen, die kompilieren, und API-Beschreibungen mit zur aktuellen Version passenden Beispielen. AsciiDoc als Sprache und Asciidoctor als Implementierung versetzen Teams in die Lage, Softwaresysteme und ihre Dokumentation aus einem Guss zu erstellen, kontinuierlich weiterzuentwickeln und automatisiert zu publizieren.
|
||||
|
||||
Die Syntax von AsciiDoc erschließt sich beim Lesen von Dokumenten. Für ein erstes *README.adoc* reichen ein paar wenige Syntaxelemente. Für größere und komplexere Dokumente stellt es alle wichtigen Elemente wie Tabellen, Diagramme und Formeln zur Verfügung, die ansprechende und ausdrucksstarke Websites und Bücher benötigen. Bei der Umsetzung hilft die ausführliche Dokumentation auf der Asciidoctor-Website.
|
||||
|
||||
Alles zusammen gute Voraussetzungen, um in Projekten Documentation as Code mit Asciidoctor zuerst auszuprobieren und dann durchgängig zu implementieren.
|
||||
|
||||
*Alexander Schwartz*
|
||||
*arbeitet als Principal IT Consultant bei der msg. Im Laufe der Zeit hatte er mit verschiedensten Server- und Webtechnologien zu tun. Auf Konferenzen und bei User Groups spricht er über seine Erfahrungen, [in seinem Blog schreibt er zu Themen rund um die IT](https://www.ahus1.de/).*
|
||||
-83
@@ -1,83 +0,0 @@
|
||||
---
|
||||
title: "Dokumentationen als Code: So verwandeln Sie AsciiDoc in PDF, DOCX, Confluence und EPUB"
|
||||
source: https://entwickler.de/software-architektur/dokumentationen-als-code-so-verwandeln-sie-asciidoc-in-pdf-docx-confluence-und-epub/
|
||||
tags:
|
||||
- IT/Development/Asciidoctor
|
||||
- IT/Development/Gradle
|
||||
---
|
||||
|
||||
In der [letzten Folge dieser Kolumne](https://entwickler.de/%22https://jaxenter.de/documentation-modularisierung-63743/%22) haben wir gezeigt, wie Sie Ihre AsciiDoc-Dokumente modular aufbauen können. In der dritten Folge der Kolumne erklären wir am Beispiel der Formate PDF, DOCX, Confluence und EPUB, wie sich verschiedene Ausgabeformate aus Ihrem AsciiDoc-Input erzeugen lassen.
|
||||
|
||||
AsciiDoc-Dokumente lassen sich sehr einfach in viele unterschiedliche Ausgabeformate umwandeln. Am Beispiel HTML5 haben Sie das in Folge eins und zwei der Kolumne schon gesehen. Aber wie lassen sich andere Formate erzeugen?
|
||||
|
||||
Die Dokumentation des Asciidoctor-Plug-ins für Gradle gibt erste Hinweise \[1\]: Mithilfe von Attributen lassen sich verschiedene Backends für verschiedene Ausgabeformate definieren. Im Gepäck hat Asciidoctor dabei verschiedene HTML-Varianten (HTML5 und XHTML), DocBook in zwei Versionen (4.5 und 5.0) und manpages \[2\]. Wer weitere Formate erzeugen möchte, muss etwas tiefer in die Trickkiste greifen.
|
||||
|
||||
## Plug-ins helfen weiter
|
||||
|
||||
Für PDF gibt es verschiedene Alternativen von DocBook-Konvertierung mittels Apache FOP über PDF-Druck der HTML-Ausgabe mit PhantomJS bis hin zum Asciidoctor-PDF-Plug-in in der Alphaversion. Alle Ansätze funktionieren und liefern Resultate unterschiedlicher Qualität. Wir haben mit dem Asciidoctor-PDF-Plug-in die besten Ergebnisse erzielt (Abb. 1), und es sieht ganz danach aus, als würde es bald ein fertiges Release geben.
|
||||
|
||||
[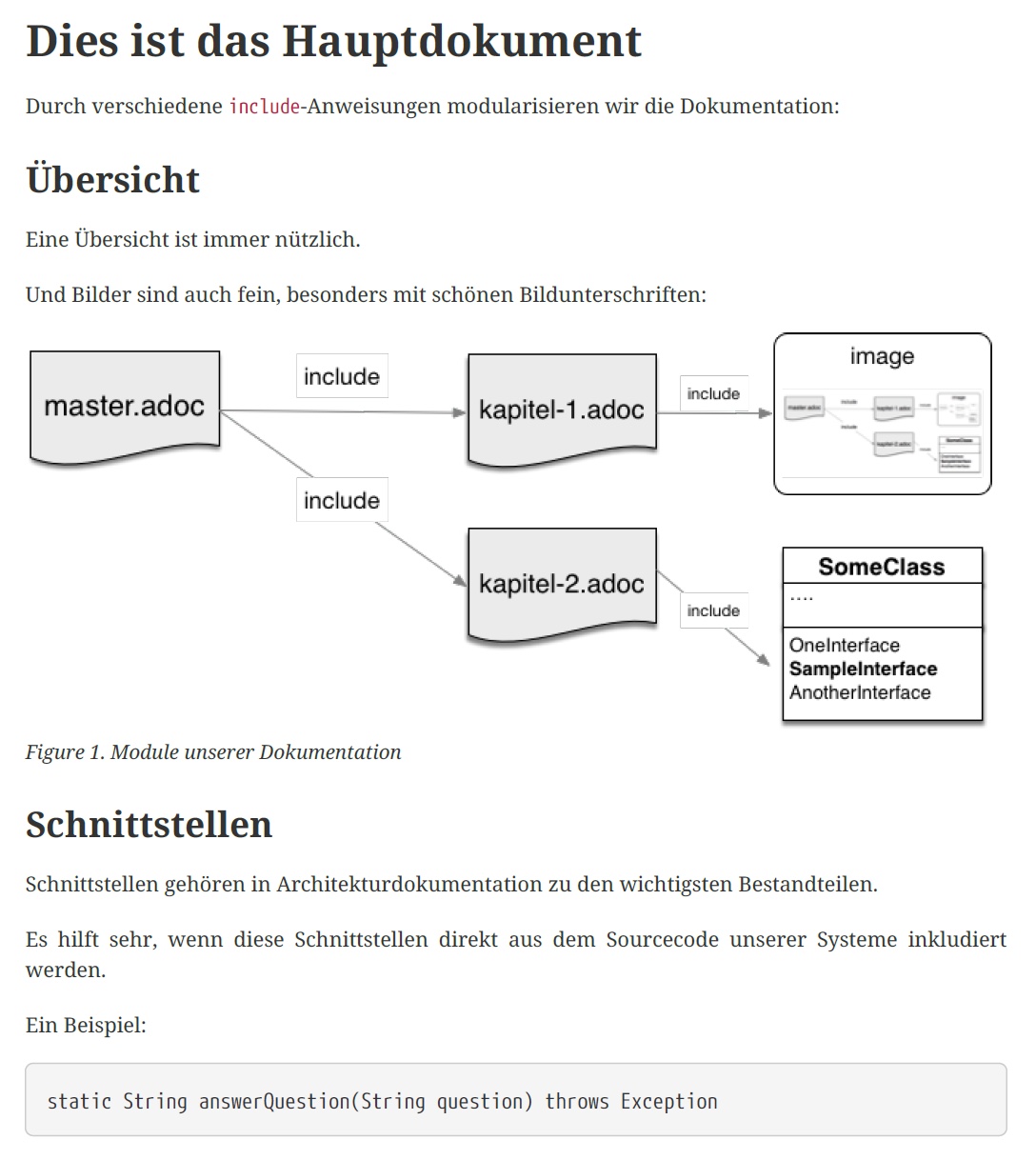](https://jaxenter.de/wp-content/uploads/2017/12/mueller_starke_dac_1.jpg)
|
||||
|
||||
Abb. 1: PDF-Ausgabe des modularisierten Dokuments
|
||||
|
||||
Listing 1 zeigt unser Build-Skript, mit dem sich jetzt neben HTML auch PDF generieren lassen.
|
||||
|
||||
**Listing 1: „build.gradle“ (Auszug)**
|
||||
|
||||
```groovy
|
||||
import org.asciidoctor.gradle.AsciidoctorTask
|
||||
...
|
||||
dependencies {
|
||||
asciidoctor 'org.asciidoctor:asciidoctorj-pdf:1.5.0-alpha.15'
|
||||
}
|
||||
…
|
||||
tasks.withType(AsciidoctorTask) { docTask ->
|
||||
attributes \
|
||||
'source-highlighter': 'coderay',
|
||||
'imagesdir': 'images',
|
||||
'toc': 'left', 'icons': 'font'
|
||||
}
|
||||
...
|
||||
task generatePDF (type: AsciidoctorTask) {
|
||||
attributes \
|
||||
'pdf-stylesdir': 'pdfTheme',
|
||||
'pdf-style': 'custom'
|
||||
|
||||
backends = ['pdf']
|
||||
}
|
||||
```
|
||||
|
||||
Listing 1 zeigt auch die Flexibilität von Gradle – über *tasks.withType(AsciidoctorTask)* werden generelle Einstellungen für Asciidoctor vorgenommen. Anschließend lassen sich für verschiedene Anwendungsfälle mit *task generatePDF (type: AsciidoctorTask)* unterschiedliche Gradle-Build-Tasks erstellen, die dann die fallspezifische Konfiguration setzen. Der Bau der unterschiedlichen Ausgabeformate lässt sich so sauber trennen.
|
||||
|
||||
## Pandoc – das Schweizer Taschenmesser zur Konvertierung
|
||||
|
||||
Reichen HTML und PDF dem Entwickler nicht aus, weil z. B. DOCX der Unternehmensstandard ist oder die umfangreiche Dokumentation sich leichter auf einem E-Book-Reader liest, so lohnt sich ein Blick auf Pandoc \[3\]. Pandoc kann Dokumente aus einer Vielzahl von Ausgangsformaten in fast beliebige Zielformate konvertieren. Praktisch verlustfrei funktioniert das unter anderem mit dem DocBook-Format. AsciiDoc liefert perfektes DocBook – was Pandoc dann zur weiteren Verarbeitung nutzen kann. Listing 2 zeigt den Aufruf von Pandoc zur Konvertierung nach DOCX mittels Gradle-Exec-Task. Genauso gut funktioniert die Konvertierung in das beliebte EPUB-Format.
|
||||
|
||||
**Listing 2: Gradle-Exec-Task**
|
||||
|
||||
```groovy
|
||||
task convertToDocx ( type: Exec) {
|
||||
workingDir 'build/asciidoc/docbook'
|
||||
executable = "pandoc"
|
||||
new File('build/asciidoc/docx/').mkdirs()
|
||||
args = ['-r','docbook',
|
||||
'-t','docx',
|
||||
'-o','../docx/master.docx',
|
||||
'master.xml']
|
||||
}
|
||||
```
|
||||
|
||||
## Jetzt wird’s Groovy!
|
||||
|
||||
Sie wollen noch mehr? Über die HTML-5- und DocBook-Ausgabe \[4\] liegt Ihre Dokumentation in zwei strukturierten Formaten vor, die sich leicht noch weiter verarbeiten lassen. In Gradle steht dem Entwickler zudem Groovy als Skriptsprache, die für die einfache Bearbeitung von XML-Dateien bekannt ist, zur Verfügung.
|
||||
|
||||
Mit diesem Werkzeugkasten lässt sich die Dokumentation auch in einem Wiki veröffentlichen. Das oft verwendete Confluence von Atlassian speichert seine Seiten beispielsweise in einem XHTML-Dialekt und verfügt über ein REST-API. Das Open-Source-Projekt docToolchain \[5\] hat dies als Gradle-Task implementiert, wobei das generierte HTML-Dokument entsprechend der Überschriftenebenen in Seiten und Unterseiten zerlegt wird, um so eine einem Wiki entsprechende Strukturierung zu erreichen (Abb. 2).
|
||||
|
||||
Den vollständigen Code zur Konvertierung eines kleinen Beispiels in HTML, PDF und DOCX finden Sie in unserem Code-Repository \[6\].
|
||||
|
||||
[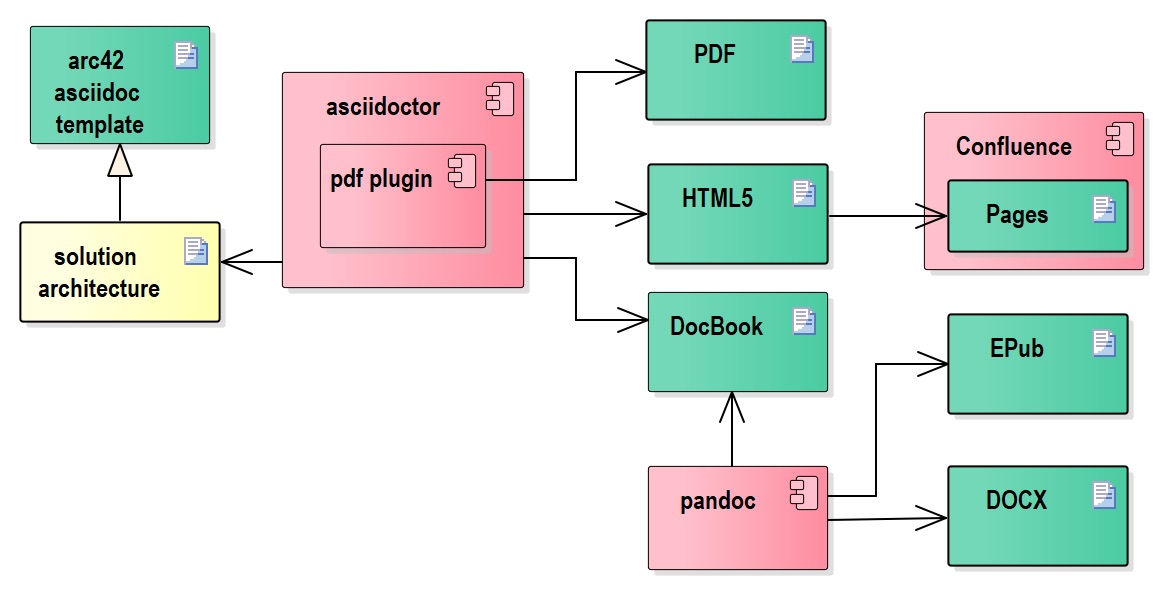](https://jaxenter.de/wp-content/uploads/2017/12/mueller_starke_dac_2.jpg)
|
||||
Abb. 2: Schematische Darstellung der Formatkonvertierungen
|
||||
|
||||
## Fazit
|
||||
|
||||
Das Potenzial, das in der Behandlung von Dokumentation wie Code schlummert, ist riesig. So wird die Dokumentation nicht nur zusammen mit dem Code verwaltet, die Modularisierung der Dokumente vereinfacht auch die Zusammenarbeit zwischen den verschiedenen Eigentümern der Dokumentation. Nutzt der Entwickler dann noch die eigenen Programmierkenntnisse – wie im Beispiel der Konvertierung nach Confluence gezeigt – so erhält er ein mächtiges Werkzeug, von dem wir in den nächsten Folgen noch ausgiebig Gebrauch machen werden. Im nächsten Teil dieser Kolumne betrachten wir AsciiDoc selbst etwas genauer und stellen Ihnen diejenigen Konstrukte vor, die Sie für die Architekturdokumentation und andere technische Dokumente am häufigsten benötigen werden. Bis dahin: Enjoy docs-as-code …
|
||||
@@ -1,8 +0,0 @@
|
||||
---
|
||||
{}
|
||||
---
|
||||
|
||||
Download von Youtube mit `yt-dlp` und Umwandlung ins MP3-Format
|
||||
```shell
|
||||
yt-dlp -x --audio-format mp3 <LINK>
|
||||
```
|
||||
@@ -1,8 +0,0 @@
|
||||
---
|
||||
title: Eclipse JDT Java Code Formatter von der Kommandozeile aufrufen
|
||||
---
|
||||
|
||||
```shel
|
||||
D:\eclipse\3.2m6\eclipse>eclipse -nosplash -application org.eclipse.jdt.core.JavaCodeFormatter -config .\configuration\.settings\org.eclipse.ui.ide.prefs c:/projects/tutorials.de/workspace/de.tutorials.training/src
|
||||
```
|
||||
|
||||
@@ -1,197 +0,0 @@
|
||||
---
|
||||
title: Edit the Yaml Front Matter of multiple Markdown files
|
||||
source: https://roneo.org/en/hugo-edit-yaml-files-from-the-cli-with-yq/
|
||||
tags:
|
||||
- IT/Development/Markdown
|
||||
- IT/Development/Yaml
|
||||
- IT/Shell
|
||||
---
|
||||
|
||||
Content files in Hugo are written in [Markdown](https://roneo.org/markdown/), and look like this:
|
||||
|
||||
```
|
||||
---
|
||||
title:
|
||||
|
||||
hello
|
||||
tags:
|
||||
|
||||
fruits
|
||||
---
|
||||
|
||||
Here is an article about **fruits**
|
||||
```
|
||||
|
||||
When you switch to a new theme or migrate content, you need to edit the Front Matter of multiple files.
|
||||
|
||||
We can make use of [Yq, a standalone executable](https://github.com/mikefarah/yq) providing batch Front Matter edition from the terminal.
|
||||
YAML, JSON and XML are supported, and [binaries are available](https://github.com/mikefarah/yq/releases/latest) for Linux, Mac, FreeBSD and Windows.
|
||||
|
||||
As an example, here is how to bulk edit `tags:` from every Markdown files:
|
||||
|
||||
```bash
|
||||
find -name "*.md" -exec yq '.tags = "food"' -i {} \;
|
||||
```
|
||||
|
||||
Basic examples are missing in the [offical documentation](https://mikefarah.gitbook.io/yq/), so here is a memo.
|
||||
|
||||
## First, let’s read the files
|
||||
|
||||
Here is how to extract the `title:` variable from `example.md`
|
||||
|
||||
```bash
|
||||
yq '.title' example.md
|
||||
```
|
||||
|
||||
Get `title:` from multiple files:
|
||||
|
||||
```bash
|
||||
yq '.title' fruits.md example.md
|
||||
```
|
||||
|
||||
(**Hint**: Separator `---` can be removed with `--no-doc`)
|
||||
|
||||
Get every `.md` files and show `title`
|
||||
|
||||
```bash
|
||||
find -name "*.md" -exec yq '.title' {} \;
|
||||
```
|
||||
|
||||
## Now let’s *update* our files
|
||||
|
||||
### Starting gently with a single file
|
||||
|
||||
Let’s imagine that we want to modify the `tags` variable.
|
||||
|
||||
Run a test
|
||||
|
||||
```bash
|
||||
yq '.tags = "food"' example.md
|
||||
```
|
||||
|
||||
Write the file with `-i`
|
||||
|
||||
```bash
|
||||
yq '.tags = "food"' example.md -i
|
||||
```
|
||||
|
||||
**Note**: special characters must be escaped:
|
||||
|
||||
```bash
|
||||
yq '.title = "This is a \"special\" update"' example.md -i
|
||||
```
|
||||
|
||||
See [the documentation](https://mikefarah.gitbook.io/yq/usage/tips-and-tricks#special-characters-in-strings) for advanced guidance on special characters.
|
||||
|
||||
### Batch modifications
|
||||
|
||||
Preview the modifications with a test run:
|
||||
|
||||
```bash
|
||||
find -name "*.md" -exec yq '.tags = "food"' {} \;
|
||||
```
|
||||
|
||||
Add `-i` to apply
|
||||
|
||||
```bash
|
||||
find -name "*.md" -exec yq '.tags = "food"' -i {} \;
|
||||
```
|
||||
|
||||
### Solving the error “bad file mapping values are not allowed”
|
||||
|
||||
You may get messages like “**Error: bad file .. mapping values are not allowed in this context**”
|
||||
|
||||
In such situation, use `--front-matter="process"` like this:
|
||||
|
||||
```bash
|
||||
find -name "*.md" -exec yq --front-matter="process" '.tags = "food"' -i {} \;
|
||||
```
|
||||
|
||||
**Note**: this will also fix/change the indentation of your Front Matter.
|
||||
|
||||
## Other nice features
|
||||
|
||||
`yq` also provides the following features:
|
||||
|
||||
### Convert YAML file to JSON
|
||||
|
||||
```bash
|
||||
yq config.yml -o json
|
||||
```
|
||||
|
||||
### Convert YAML file to XML
|
||||
|
||||
```bash
|
||||
yq config.yml -o xml
|
||||
```
|
||||
|
||||
### Create a new file with custom content
|
||||
|
||||
```bash
|
||||
yq -n '.title="A new post"' > new.yml
|
||||
```
|
||||
|
||||
**Note**: Front matter separator `---` are not added to new files.
|
||||
|
||||
### Combine multiple Yaml files into one
|
||||
|
||||
```bash
|
||||
yq '.' folder/*.yml
|
||||
```
|
||||
|
||||
### Use conditionals with if / else
|
||||
|
||||
See [this hidden corner of the doc](https://mikefarah.gitbook.io/yq/usage/tips-and-tricks#logic-without-if-elif-else)
|
||||
|
||||
## The complete man page
|
||||
|
||||
```bash
|
||||
$ yq --help
|
||||
|
||||
yq is a portable command-line YAML processor (https://github.com/mikefarah/yq/)
|
||||
See https://mikefarah.gitbook.io/yq/ for detailed documentation and examples.
|
||||
|
||||
Usage:
|
||||
yq [flags] yq [command]
|
||||
|
||||
Examples:
|
||||
|
||||
# yq defaults to 'eval' command if no command is specified. See "yq eval --help" for more examples.
|
||||
|
||||
# read the "stuff" node from "myfile.yml"
|
||||
yq '.stuff' < myfile.yml
|
||||
|
||||
# update myfile.yml in place
|
||||
yq -i '.stuff = "foo"' myfile.yml
|
||||
|
||||
# print contents of sample.json as idiomatic YAML
|
||||
yq -P sample.json
|
||||
|
||||
Available Commands:
|
||||
completion Generate the autocompletion script for the specified shell eval (default) Apply the expression to each document in each yaml file in sequence eval-all Loads _all_ yaml documents of _all_ yaml files and runs expression once help Help about any command shell-completion Generate completion script
|
||||
|
||||
Flags:
|
||||
-C, --colors force print with colors -e, --exit-status set exit status if there are no matches or null or false is returned --expression string forcibly set the expression argument. Useful when yq argument detection thinks your expression is a file. --from-file string Load expression from specified file. -f, --front-matter string (extract|process) first input as yaml front-matter. Extract will pull out the yaml content, process will run the expression against the yaml content, leaving the remaining data intact --header-preprocess Slurp any header comments and separators before processing expression. (default true) -h, --help help for yq -I, --indent int sets indent level for output (default 2) -i, --inplace update the file inplace of first file given. -p, --input-format string [yaml|y|props|p|xml|x] parse format for input. Note that json is a subset of yaml. (default "yaml") -M, --no-colors force print with no colors -N, --no-doc Don't print document separators (---) -n, --null-input Don't read input, simply evaluate the expression given. Useful for creating docs from scratch. -o, --output-format string [yaml|y|json|j|props|p|xml|x] output format type. (default "yaml") -P, --prettyPrint pretty print, shorthand for '... style = ""' -s, --split-exp string print each result (or doc) into a file named (exp). [exp] argument must return a string. You can use $index in the expression as the result counter. --split-exp-file string Use a file to specify the split-exp expression. -r, --unwrapScalar unwrap scalar, print the value with no quotes, colors or comments (default true) -v, --verbose verbose mode -V, --version Print version information and quit --xml-attribute-prefix string prefix for xml attributes (default "+") --xml-content-name string name for xml content (if no attribute name is present). (default "+content") --xml-keep-namespace enables keeping namespace after parsing attributes (default true) --xml-raw-token enables using RawToken method instead Token. Commonly disables namespace translations. See https://pkg.go.dev/encoding/xml#Decoder.RawToken for details. (default true) --xml-strict-mode enables strict parsing of XML. See https://pkg.go.dev/encoding/xml for more details.
|
||||
|
||||
Use "yq [command] --help" for more information about a command.
|
||||
```
|
||||
|
||||
## Further reading
|
||||
|
||||
- [Official documentation](https://mikefarah.gitbook.io/yq/usage/front-matter)
|
||||
- [Handle Dates](https://mikefarah.gitbook.io/yq/operators/datetime)
|
||||
- [Navigate structured Yaml files](https://mikefarah.gitbook.io/yq/operators/traverse-read)
|
||||
- [Advanced usage](https://mikefarah.gitbook.io/yq/operators/load#replace-all-nodes-with-referenced-file)
|
||||
- [Introduction to Yaml](https://learnxinyminutes.com/docs/yaml/)
|
||||
|
||||
- https://github.com/tomwright/dasel
|
||||
- https://github.com/pandastrike/yaml-cli
|
||||
- Written in Python:
|
||||
- https://kislyuk.github.io/yq
|
||||
- [Batch Edit Yaml Front Matter with Python](https://karlredman.github.io/EditFrontMatter/)
|
||||
- NPM based editors
|
||||
- https://chrisdmacrae.github.io/front-matter-manipulator (unmaintained)
|
||||
- https://github.com/hilja/file-batcher (unmaintained)
|
||||
- https://github.com/dworthen/js-yaml-front-matter (unmaintained)
|
||||
- Jinja: https://karlredman.github.io/EditFrontMatter/
|
||||
- A collection: [Frontmatter Tools](https://www.sametbh.com/docs/64-programming/static-site-generators/hugo/frontmatter-tools/)
|
||||
@@ -1,158 +0,0 @@
|
||||
---
|
||||
title: Factory Method · Software adventures and thoughts
|
||||
source: http://blog.ralch.com/tutorial/design-patterns/golang-factory-method/
|
||||
tags:
|
||||
- IT/Development/Go
|
||||
---
|
||||
|
||||
#### Introduction
|
||||
|
||||
The `Factory Method` pattern is a design pattern used to define a runtime interface for creating an object. It’s called a factory because it creates various types of objects without necessarily knowing what kind of object it creates or how to create it.
|
||||
|
||||
#### Purpose
|
||||
|
||||
* Allows the sub-classes to choose the type of objects to create at runtime
|
||||
* It provides a simple way of extending the family of objects with minor changes in application code.
|
||||
* Promotes the loose-coupling by eliminating the need to bind application-specific structs into the code
|
||||
|
||||
#### Design Pattern Diagram
|
||||
|
||||
The structs and objects participating in this pattern are: product, concreate product, creator and concrete creator. The Creator contains one method to produce one type of product related to its type.
|
||||
|
||||
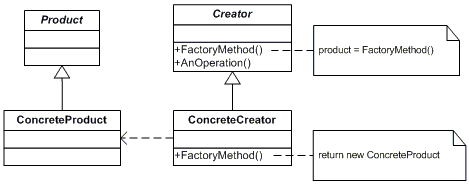
|
||||
|
||||
* `Product` defines the interface of objects the factory method creates
|
||||
* `ConcreteProduct` implements the Product interface
|
||||
* `Creator` declares the factory method, which returns an object of type Product
|
||||
* `ConcreteCreator` overrides the factory method to return an instance of a Concrete Product
|
||||
|
||||
#### Implementation
|
||||
|
||||
The Factory Method defines an interface for creating objects, but lets subclasses decide which classes to instantiate. In these example, we will adopt the pattern to create document object model of Scalable Vector Graphics.
|
||||
|
||||
The SVG format can contains multiple elements. In this example, we will illustrate only some of the shape elements. In the context of `Factory Method` design pattern, they are our product.
|
||||
|
||||
Every shape implements the `Shape` interface, which expose a `Draw` function that generates the required XML element:
|
||||
|
||||
```go
|
||||
type Shape interface {
|
||||
Draw(io.Writer) error
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
In the following code snippets, we will illustrate two implementations of `Shape` interface `Circle` and `Ractangle`:
|
||||
|
||||
```go
|
||||
type Circle struct {
|
||||
Location Point
|
||||
Radius float64
|
||||
}
|
||||
|
||||
func (c *Circle) Draw(w io.Writer) error {
|
||||
_, err := fmt.Fprintf(w, `<circle cx="%f" cy="%f" r="%f"/>`, c.Location.X, c.Location.Y, c.Radius)
|
||||
return err
|
||||
}
|
||||
|
||||
type Rectangle struct {
|
||||
Location Point
|
||||
Size Size
|
||||
}
|
||||
|
||||
func (rect *Rectangle) Draw(w io.Writer) error {
|
||||
_, err := fmt.Fprintf(w, `<rect x="%f" y="%f" width="%f" height="%f"/>`, rect.Location.X, rect.Location.Y, rect.Size.Width, rect.Size.Height)
|
||||
return err
|
||||
}
|
||||
```
|
||||
|
||||
Every of them has a function that is responsible for their instantiation based on the provided `Viewport`. The `Viewport` is an argument which keeps an information about the location and the size of the view port.
|
||||
|
||||
```go
|
||||
type ShapeFactory interface {
|
||||
Create(viewport Viewport) Shape
|
||||
}
|
||||
```
|
||||
|
||||
The `CircleFactory` creates a `Circle` instance that has radius, which fits the viewport:
|
||||
|
||||
```go
|
||||
type CircleFactory struct{}
|
||||
|
||||
func (factory *CircleFactory) Create(viewport Viewport) Shape {
|
||||
return &Circle{
|
||||
Location: viewport.Location,
|
||||
Radius: math.Min(viewport.Size.Width, viewport.Size.Height),
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The `RectangleFactory` produces a rectangle that fits the viewport:
|
||||
|
||||
```go
|
||||
type RactangleFactory struct{}
|
||||
|
||||
func (factory *RactangleFactory) Create(viewport Viewport) Shape {
|
||||
return &Rectangle{
|
||||
Location: viewport.Location,
|
||||
Size: viewport.Size,
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The main object `Document` has a `Draw` function, which composes a different shapes created by provided factories. The `Document` can be instaciated with different set of factories. This allow to customize and change the document’s content:
|
||||
|
||||
```go
|
||||
type Document struct {
|
||||
ShapeFactories []ShapeFactory
|
||||
}
|
||||
|
||||
func (doc *Document) Draw(w io.Writer) error {
|
||||
viewport := Viewport{
|
||||
Location: Point{
|
||||
X: 0,
|
||||
Y: 0,
|
||||
},
|
||||
Size: Size{
|
||||
Width: 640,
|
||||
Height: 480,
|
||||
},
|
||||
}
|
||||
if _, err := fmt.Fprintf(w, `<svg height="%f" width="%f">`, viewport.Size.Height, viewport.Size.Width); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
for _, factory := range doc.ShapeFactories {
|
||||
shape := factory.Create(viewport)
|
||||
if err := shape.Draw(w); err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
|
||||
_, err := fmt.Fprint(w, `</svg>`)
|
||||
return err
|
||||
}
|
||||
```
|
||||
|
||||
We should instaciate the `Document` struct with the available factories in the following way:
|
||||
|
||||
```go
|
||||
doc := &svg.Document{
|
||||
ShapeFactories: []svg.ShapeFactory{
|
||||
&svg.CircleFactory{},
|
||||
&svg.RactangleFactory{},
|
||||
},
|
||||
}
|
||||
|
||||
doc.Draw(os.Stdout)
|
||||
```
|
||||
|
||||
You can get the full source code from [github](https://github.com/svett/golang-design-patterns/tree/master/creational-patterns/factory-method).
|
||||
|
||||
Important aspects when we implement the Factory Method design pattern are:
|
||||
|
||||
* Designing the arguments of the factory method
|
||||
* Considering an internal object pool that will allow object cache and reuse instead of created from scratch
|
||||
|
||||
#### Verdict
|
||||
|
||||
The Factory Method is one of the most used design patterns. It makes a design more customizable and only a little more complicated. Other design patterns require new structs, whereas Factory Method only requires a new operation. The Factory Method is similar to Abstract Factory but without the emphasis on families.
|
||||
@@ -1,102 +0,0 @@
|
||||
---
|
||||
title: Fun Commands You Can Use | GitGuys - GitGuys
|
||||
tags:
|
||||
- IT/Development/Git
|
||||
---
|
||||
|
||||
|
||||
Git Remotes: Fun Commands You Can Use
|
||||
Commands discussed in this section:
|
||||
|
||||
git branch
|
||||
git remote
|
||||
git ls-remote
|
||||
git fetch
|
||||
git pull
|
||||
|
||||
List remote-tracking branches
|
||||
|
||||
$ git branch -r
|
||||
origin/HEAD -> origin/master
|
||||
origin/master
|
||||
origin/test
|
||||
qa/master
|
||||
qa/test
|
||||
|
||||
List all branches:
|
||||
|
||||
$ git branch -a
|
||||
* master
|
||||
remotes/origin/HEAD -> origin/master
|
||||
remotes/origin/master
|
||||
remotes/origin/test
|
||||
|
||||
List only local, working branches:
|
||||
|
||||
$ git branch
|
||||
* master
|
||||
|
||||
Show basic information about the default remote
|
||||
|
||||
$ git remote -v
|
||||
origin file:///home/gitadmin/project1.git (fetch)
|
||||
origin file:///home/gitadmin/project1.git (push)
|
||||
|
||||
Show a lot about a remote
|
||||
|
||||
$ git remote show origin
|
||||
* remote origin
|
||||
Fetch URL: file:///home/gitadmin/project1.git
|
||||
Push URL: file:///home/gitadmin/project1.git
|
||||
HEAD branch: master
|
||||
Remote branches:
|
||||
master tracked
|
||||
test tracked
|
||||
Local branch configured for 'git pull':
|
||||
master merges with remote master
|
||||
Local ref configured for 'git push':
|
||||
master pushes to master (up to date)
|
||||
|
||||
Dig around remote repositories
|
||||
|
||||
Show the references in a remote repository and their hash:
|
||||
|
||||
$ git ls-remote origin
|
||||
8dc59a3c60b5dd12605d0a647b4921b5410b820f HEAD
|
||||
8dc59a3c60b5dd12605d0a647b4921b5410b820f refs/heads/master
|
||||
a402bc61da05d2c9dc6dc6307dcffe12a1fb8045 refs/heads/test
|
||||
|
||||
$ git ls-remote git://git.debian.org/collab-maint/usplash.git
|
||||
ee17d863ceab06e408e8b051244b7202ae4075f7 HEAD
|
||||
ee17d863ceab06e408e8b051244b7202ae4075f7 refs/heads/master
|
||||
f0847d378161de510b49654746f551482240901f refs/heads/upstream
|
||||
7f5b189dc1c67bb5ff33ca2d4f616336baa8fb4c refs/tags/0.5.19-1
|
||||
...
|
||||
|
||||
The first example, refers to a remote repository named origin and the second above specifies the completely URL of the remote repository.
|
||||
Add a remote repository
|
||||
|
||||
$ git remote add qa git://qaserver/round1
|
||||
$ git fetch qa
|
||||
From git://qaserver/round1
|
||||
* [new branch] master -> qa/master
|
||||
* [new branch] test -> qa/test
|
||||
|
||||
Add a tracking branch
|
||||
|
||||
$ git branch --track test origin/test
|
||||
Branch test set up to track remote branch test from origin.
|
||||
$ git checkout test
|
||||
$ git pull
|
||||
...
|
||||
|
||||
Next: [The .git directory](http://www.gitguys.com/topics/the-git-directory)
|
||||
Previous: [Git and Remotes: The config file – Branch Section](http://www.gitguys.com/topics/the-configuration-file-branch-section)
|
||||
|
||||
Related:
|
||||
[Git and Remote Repositories](http://www.gitguys.com/topics/git-and-remote-repositories)
|
||||
[Git Remotes Example: Creating a shared repository and users sharing the repository](http://www.gitguys.com/topics/creating-a-shared-repository-users-sharing-the-repository)
|
||||
[Adding and Removing Remote Branches](http://www.gitguys.com/topics/adding-and-removing-remote-branches)
|
||||
[Git Remotes Behind The Scenes: “Tracking Branches” and “Remote-Tracking Branches”](http://www.gitguys.com/topics/tracking-branches-and-remote-tracking-branches)
|
||||
[Git Remotes Up Close: The Configuration File – “remote” section](http://www.gitguys.com/topics/the-configuration-file-remote-section)
|
||||
[Git Remotes Up Close: The Configuration File – “branch” section](http://www.gitguys.com/topics/the-configuration-file-branch-section)
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,242 +0,0 @@
|
||||
---
|
||||
title: "Git Tip of the Week: Git Notes"
|
||||
tags:
|
||||
- IT
|
||||
- IT/Development/Git
|
||||
---
|
||||
|
||||
|
||||
Git Tip of the Week: Git Notes
|
||||
|
||||
Nov 8th, 2011
|
||||
2011, git, gtotw
|
||||
|
||||
|
||||
This week’s [Git Tip of the Week](http://alblue.bandlem.com/Tag/gtotw/) is about git notes. You can subscribe to the feed if you want to receive new instalments automatically.
|
||||
|
||||
|
||||
|
||||
|
||||
At a recent talk for the London Java Community (recorded video is available via the link), I presented Git and Gerrit (based on the successful screencasts I have done previously). One of the things I demonstrated was the use of git notes, so I thought writing about them and explaining what they are made sense.
|
||||
|
||||
|
||||
When files are committed into a Git repository, they are addressed by a hash of the contents. The same is true of trees and commits. One of the benefits of this structure is that the objects cannot be modified after they have been committed (since doing so would change that hash).
|
||||
|
||||
|
||||
However, sometimes it is desirable to be able to add metadata to a commit after it has already been committed. There are three ways of doing this:
|
||||
|
||||
|
||||
Amend the commit message to add in the additional metadata, accepting this will change the branch.
|
||||
Create a merge node with a more detailed commit, and push that (so that the previous commit is retained and can be fast forwarded).
|
||||
Add additional metadata in the form of git notes.
|
||||
|
||||
|
||||
Of these three options, only the last one will not change the current branch.
|
||||
|
||||
|
||||
Git Notes
|
||||
|
||||
|
||||
Git Notes are, in effect, a separate ‘branch’ of the repository (stored at .git/refs/notes). They don’t show up in the git branch command (that lists .git/refs/heads by default). However, although you could check it out and manually update it, there is a command provided which helps you do that; git notes.
|
||||
|
||||
|
||||
none
|
||||
|
||||
|
||||
|
||||
(master) $ git log --oneline
|
||||
056ca11 More Stuff Again
|
||||
9defb31 MoreStuff
|
||||
0c7ff4f Additional
|
||||
19b6cdf Initial
|
||||
(master) $ git notes show
|
||||
(master) $ git notes add -m "ToDo: Fix stuff"
|
||||
(master) $ git notes show
|
||||
ToDo: Fix stuff
|
||||
(master) $ git log
|
||||
(master) $ git log
|
||||
commit 056ca11c01b47e2bfe1e51178b65c80bbdeef7b0
|
||||
…
|
||||
|
||||
More Stuff Again
|
||||
|
||||
Notes:
|
||||
ToDo: Fix stuff
|
||||
|
||||
|
||||
When you look at the output of git log, it checks to see if there is an associated note, and if so, prints it out as if it were an appendix to the commit. Furthermore, the notes are mutable and can be updated over time:
|
||||
|
||||
|
||||
none
|
||||
|
||||
|
||||
|
||||
(master) $ git notes add --force -m "ToDone: Fixed stuff"
|
||||
Overwriting existing notes for object 056ca11c01b47e2bfe1e51178b65c80bbdeef7b0
|
||||
(master) $ git notes show
|
||||
ToDone: Fixed stuff
|
||||
|
||||
|
||||
The advantage of the notes is that they can be updated without changing the commit message (and therefore the hash) of the item that they are referring to. Of course, this can be used for good as well as bad; but bear in mind the mutability if you need to depend on the notes’ contents.
|
||||
|
||||
|
||||
Gits all the way down …
|
||||
|
||||
|
||||
Actually, a better title might have been “objects all the way down”, but I liked this one better.
|
||||
|
||||
|
||||
Since Git is a content addressable database, the notes themselves are git objects. You can even view the history of the branch using git log and even check it out. But how are the notes stored?
|
||||
|
||||
|
||||
none
|
||||
|
||||
|
||||
|
||||
(master) $ git log --oneline notes/commits
|
||||
d6ac2b2 Notes added by 'git notes add'
|
||||
5eb0ee5 Notes added by 'git notes add'
|
||||
(master) $ git checkout notes/commits
|
||||
Note: checking out 'notes/commits'.
|
||||
|
||||
You are in 'detached HEAD' state. You can look around, make experimental
|
||||
…
|
||||
HEAD is now at d6ac2b2... Notes added by 'git notes add'
|
||||
((d6ac2b2...)) $ ls
|
||||
056ca11c01b47e2bfe1e51178b65c80bbdeef7b0
|
||||
((d6ac2b2...)) $ cat 056ca11c01b47e2bfe1e51178b65c80bbdeef7b0
|
||||
ToDone: Fixed stuff
|
||||
|
||||
|
||||
The branch contains a list of notes, with file names referenced by the commit (or other object) ID that they correspond to. We can make a change here and update our notes:
|
||||
|
||||
|
||||
none
|
||||
|
||||
|
||||
|
||||
((d6ac2b2...)) $ echo Note: Git notes are just objects >> 056ca11c01b47e2bfe1e51178b65c80bbdeef7b0
|
||||
((d6ac2b2...)) $ git commit -a -m "Note added by me"
|
||||
[detached HEAD 89e6afa] Note added by me
|
||||
1 files changed, 1 insertions(+), 0 deletions(-)
|
||||
((89e6afa...)) $ git checkout master
|
||||
Warning: you are leaving 1 commit behind, not connected to
|
||||
any of your branches:
|
||||
|
||||
89e6afa Note added by me
|
||||
…
|
||||
(master) $ git log HEAD^..HEAD
|
||||
commit 056ca11c01b47e2bfe1e51178b65c80bbdeef7b0
|
||||
…
|
||||
More Stuff Again
|
||||
|
||||
Notes:
|
||||
ToDone: Fixed stuff
|
||||
|
||||
|
||||
So, we added a new commit and then switched back to master; but as the warning message told us, this has left the commit behind. We really need to update the refs/notes/comits reference if we want to see the new values:
|
||||
|
||||
|
||||
none
|
||||
|
||||
|
||||
|
||||
(master) $ git update-ref refs/notes/commits 89e6afa
|
||||
(master) $ git log HEAD^..HEAD
|
||||
commit 056ca11c01b47e2bfe1e51178b65c80bbdeef7b0
|
||||
…
|
||||
More Stuff Again
|
||||
|
||||
Notes:
|
||||
ToDone: Fixed stuff
|
||||
Note: Git notes are just objects
|
||||
|
||||
|
||||
Here, the git update-ref is assigning the content of refs/notes/commits the value 89e6afa… (although it’s resolving it to a full 40 character hash and checking that it exists first).
|
||||
|
||||
|
||||
Conventions
|
||||
|
||||
|
||||
Just a quick note on conventions; since the notes file is essentially on its own branch, the content doesn’t get merged with merges between branches. If you wanted to merge git notes, then following the Key: Value on separate lines is the way to achieve git note merging nirvana. The merging options for git notes allow for appending of notes (i.e. similar to cat noteV1 noteV2) or sorting and uniquifying the data (i.e. cat noteV1 noteV2 | sort | uniq).
|
||||
|
||||
|
||||
However, the notes don’t have to be textual, nor do they have to be something which is mergeable. They don’t even need to be on the notes/commits ref; you can create notes based on any reference.
|
||||
|
||||
|
||||
In fact, this is how Gerrit works (which I’ve written about before). Gerrit stores its review information in the Git repository under notes/review. Ordinarily, this doesn’t show up (the git log only shows notes in the notes/commits refspace), but you can make it do so if you want:
|
||||
|
||||
|
||||
none
|
||||
|
||||
|
||||
|
||||
(BARE:master) $ git show refs/notes/review
|
||||
commit bb7cba258eaaf4851b20b66c7ef56775f0cb4367
|
||||
…
|
||||
Update notes for submitted changes
|
||||
|
||||
* Goodbye world
|
||||
|
||||
diff --git a/f7f38314247063271631cfddf560ea99214cd438 b/…
|
||||
@@ -0,0 +1,7 @@
|
||||
+Code-Review+2: Alex Blewitt
|
||||
+Verified+1: Jenkins
|
||||
+Submitted-by: Alex Blewitt
|
||||
+Submitted-at: Thu, 20 Oct 2011 20:11:16 +0100
|
||||
+Reviewed-on: http://localhost:9080/7
|
||||
+Project: SkillsMatter
|
||||
+Branch: refs/heads/master
|
||||
(BARE:master) $ git log HEAD^..HEAD
|
||||
commit f7f38314247063271631cfddf560ea99214cd438
|
||||
…
|
||||
Goodbye world
|
||||
|
||||
Change-Id: I692f8de08938f22da9d6e26005ba44c95a1479d7
|
||||
(BARE:master) $ git log --show-notes=* HEAD^..HEAD
|
||||
commit f7f38314247063271631cfddf560ea99214cd438
|
||||
…
|
||||
Goodbye world
|
||||
|
||||
Change-Id: I692f8de08938f22da9d6e26005ba44c95a1479d7
|
||||
|
||||
Notes (review):
|
||||
Code-Review+2: Alex Blewitt
|
||||
Verified+1: Jenkins
|
||||
Submitted-by: Alex Blewitt
|
||||
Submitted-at: Thu, 20 Oct 2011 20:11:16 +0100
|
||||
Reviewed-on: http://localhost:9080/7
|
||||
Project: SkillsMatter
|
||||
Branch: refs/heads/master
|
||||
|
||||
|
||||
In this case, I reviewed the commit (with a +2 from me, and a +1 from Jenkins) and it’s stored in the Git repository, along with everything else. Normally, it’s not received by the user when pulling or cloning; but it is a permanent record on the repository (and will be visible if you e.g. do a git clone --mirror). However, if you want to fetch the notes as well you can do so:
|
||||
|
||||
|
||||
none
|
||||
|
||||
|
||||
|
||||
[remote "origin"]
|
||||
fetch = +refs/notes/*:refs/notes/*
|
||||
fetch = +refs/heads/*:refs/remotes/origin/*
|
||||
url = ssh://localhost:29418/SkillsMatter.git
|
||||
push = refs/heads/master:refs/for/master
|
||||
|
||||
|
||||
The fetch refspec in bold allows me to pull any/all reviews from the repository and make them available in my local clone.
|
||||
|
||||
|
||||
Exercise for the reader …
|
||||
|
||||
|
||||
Since the Git notes can contain any blob, and it’s not cloned by default (unless you specifically review it), you can create a distribution and check it into a repository. Instead of storing it in refs/notes/commit, store it in refs/notes/dist and have the binary generated from your compile system export it as a Git Note pointing to the tag. That way, if you want to check out the pre-built bundle for a given tag, you can use refs/notes/dist to point to the tag you want and extract the full binary.
|
||||
|
||||
|
||||
Of course, you don’t really need to use git notes to store any blob in the repository in any case; there’s no reason why you couldn’t have a refs/dists tree, with one file per tag.
|
||||
|
||||
|
||||
Git notes demonstrates the fact that Git is not just a source code control system, like Hg or Bzr. Instead, it’s a content-addressable file-system, which just happens to be able to represent trees and files (blobs) in an easy way. As a result, Git will always be capable of being extended with functionality like Gerrit and git notes, because it is not limited to what it can store in a repository – yet, the cloning of the repository can still be efficient since the data you pull from a clone is only the reachable objects from a specific commit. As a result, review notes (and/or binary distributions) need never be part of a cloned repository, even if it is persisted and available in the same Git back-end.
|
||||
|
||||
|
||||
|
||||
@@ -1,190 +0,0 @@
|
||||
---
|
||||
title: Git Tools - Signing Your Work
|
||||
tags:
|
||||
- IT/Development/Git
|
||||
- IT/Sicherheit
|
||||
- IT/Tools/GPG
|
||||
---
|
||||
|
||||
## Git Tools - Signing Your Work
|
||||
|
||||
### Signing Your Work
|
||||
|
||||
Git is cryptographically secure, but it’s not foolproof. If you’re taking work from others on the internet and want to verify that commits are actually from a trusted source, Git has a few ways to sign and verify work using GPG.
|
||||
|
||||
#### GPG Introduction
|
||||
|
||||
First of all, if you want to sign anything you need to get GPG configured and your personal key installed.
|
||||
|
||||
```shell
|
||||
$ gpg --list-keys
|
||||
/Users/schacon/.gnupg/pubring.gpg
|
||||
---------------------------------
|
||||
pub 2048R/0A46826A 2014-06-04
|
||||
uid Scott Chacon (Git signing key) <schacon@gmail.com>
|
||||
sub 2048R/874529A9 2014-06-04
|
||||
```
|
||||
|
||||
If you don’t have a key installed, you can generate one with gpg --gen-key.
|
||||
|
||||
```shell
|
||||
gpg --gen-key
|
||||
```
|
||||
|
||||
Once you have a private key to sign with, you can configure Git to use it for signing things by setting the user.signingkey config setting.
|
||||
|
||||
```shell
|
||||
git config --global user.signingkey 0A46826A
|
||||
```
|
||||
|
||||
Now Git will use your key by default to sign tags and commits if you want.
|
||||
|
||||
### Signing Tags
|
||||
|
||||
If you have a GPG private key setup, you can now use it to sign new tags. All you have to do is use -s instead of -a:
|
||||
|
||||
```shell
|
||||
$ git tag -s v1.5 -m 'my signed 1.5 tag'
|
||||
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "Ben Straub <ben@straub.cc>"
|
||||
2048-bit RSA key, ID 800430EB, created 2014-05-04
|
||||
```
|
||||
|
||||
If you run git show on that tag, you can see your GPG signature attached to it:
|
||||
|
||||
```shell
|
||||
$ git show v1.5
|
||||
tag v1.5
|
||||
Tagger: Ben Straub <ben@straub.cc>
|
||||
Date: Sat May 3 20:29:41 2014 -0700
|
||||
|
||||
my signed 1.5 tag
|
||||
-----BEGIN PGP SIGNATURE-----
|
||||
Version: GnuPG v1
|
||||
|
||||
iQEcBAABAgAGBQJTZbQlAAoJEF0+sviABDDrZbQH/09PfE51KPVPlanr6q1v4/Ut
|
||||
LQxfojUWiLQdg2ESJItkcuweYg+kc3HCyFejeDIBw9dpXt00rY26p05qrpnG+85b
|
||||
hM1/PswpPLuBSr+oCIDj5GMC2r2iEKsfv2fJbNW8iWAXVLoWZRF8B0MfqX/YTMbm
|
||||
ecorc4iXzQu7tupRihslbNkfvfciMnSDeSvzCpWAHl7h8Wj6hhqePmLm9lAYqnKp
|
||||
8S5B/1SSQuEAjRZgI4IexpZoeKGVDptPHxLLS38fozsyi0QyDyzEgJxcJQVMXxVi
|
||||
RUysgqjcpT8+iQM1PblGfHR4XAhuOqN5Fx06PSaFZhqvWFezJ28/CLyX5q+oIVk=
|
||||
=EFTF
|
||||
-----END PGP SIGNATURE-----
|
||||
|
||||
commit ca82a6dff817ec66f44342007202690a93763949
|
||||
Author: Scott Chacon <schacon@gee-mail.com>
|
||||
Date: Mon Mar 17 21:52:11 2008 -0700
|
||||
|
||||
changed the version number
|
||||
```
|
||||
|
||||
### Verifying Tags
|
||||
|
||||
To verify a signed tag, you use git tag -v [tag-name]. This command uses GPG to verify the signature. You need the signer’s public key in your keyring for this to work properly:
|
||||
|
||||
```shell
|
||||
$ git tag -v v1.4.2.1
|
||||
object 883653babd8ee7ea23e6a5c392bb739348b1eb61
|
||||
type commit
|
||||
tag v1.4.2.1
|
||||
tagger Junio C Hamano <junkio@cox.net> 1158138501 -0700
|
||||
|
||||
GIT 1.4.2.1
|
||||
|
||||
Minor fixes since 1.4.2, including git-mv and git-http with alternates.
|
||||
gpg: Signature made Wed Sep 13 02:08:25 2006 PDT using DSA key ID F3119B9A
|
||||
gpg: Good signature from "Junio C Hamano <junkio@cox.net>"
|
||||
gpg: aka "[jpeg image of size 1513]"
|
||||
Primary key fingerprint: 3565 2A26 2040 E066 C9A7 4A7D C0C6 D9A4 F311 9B9A
|
||||
```
|
||||
|
||||
If you don’t have the signer’s public key, you get something like this instead:
|
||||
|
||||
```shell
|
||||
gpg: Signature made Wed Sep 13 02:08:25 2006 PDT using DSA key ID F3119B9A
|
||||
gpg: Can't check signature: public key not found
|
||||
error: could not verify the tag 'v1.4.2.1'
|
||||
```
|
||||
|
||||
### Signing Commits
|
||||
|
||||
In more recent versions of Git (v1.7.9 and above), you can now also sign individual commits. If you’re interested in signing commits directly instead of just the tags, all you need to do is add a -S to your git commit command.
|
||||
|
||||
```shell
|
||||
$ git commit -a -S -m 'signed commit'
|
||||
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "Scott Chacon (Git signing key) <schacon@gmail.com>"
|
||||
2048-bit RSA key, ID 0A46826A, created 2014-06-04
|
||||
|
||||
[master 5c3386c] signed commit
|
||||
4 files changed, 4 insertions(+), 24 deletions(-)
|
||||
rewrite Rakefile (100%)
|
||||
create mode 100644 lib/git.rb
|
||||
```
|
||||
|
||||
To see and verify these signatures, there is also a --show-signature option to git log.
|
||||
|
||||
```shell
|
||||
$ git log --show-signature -1
|
||||
commit 5c3386cf54bba0a33a32da706aa52bc0155503c2
|
||||
gpg: Signature made Wed Jun 4 19:49:17 2014 PDT using RSA key ID 0A46826A
|
||||
gpg: Good signature from "Scott Chacon (Git signing key) <schacon@gmail.com>"
|
||||
Author: Scott Chacon <schacon@gmail.com>
|
||||
Date: Wed Jun 4 19:49:17 2014 -0700
|
||||
|
||||
signed commit
|
||||
```
|
||||
|
||||
Additionally, you can configure git log to check any signatures it finds and list them in it’s output with the %G? format.
|
||||
|
||||
```shell
|
||||
$ git log --pretty="format:%h %G? %aN %s"
|
||||
|
||||
5c3386c G Scott Chacon signed commit
|
||||
ca82a6d N Scott Chacon changed the version number
|
||||
085bb3b N Scott Chacon removed unnecessary test code
|
||||
a11bef0 N Scott Chacon first commit
|
||||
```
|
||||
|
||||
Here we can see that only the latest commit is signed and valid and the previous commits are not.
|
||||
|
||||
In Git 1.8.3 and later, “git merge” and “git pull” can be told to inspect and reject when merging a commit that does not carry a trusted GPG signature with the --verify-signatures command.
|
||||
|
||||
If you use this option when merging a branch and it contains commits that are not signed and valid, the merge will not work.
|
||||
|
||||
```shell
|
||||
$ git merge --verify-signatures non-verify
|
||||
fatal: Commit ab06180 does not have a GPG signature.
|
||||
```
|
||||
|
||||
If the merge contains only valid signed commits, the merge command will show you all the signatures it has checked and then move forward with the merge.
|
||||
|
||||
```shell
|
||||
$ git merge --verify-signatures signed-branch
|
||||
Commit 13ad65e has a good GPG signature by Scott Chacon (Git signing key) <schacon@gmail.com>
|
||||
Updating 5c3386c..13ad65e
|
||||
Fast-forward
|
||||
README | 2 ++
|
||||
1 file changed, 2 insertions(+)
|
||||
```
|
||||
|
||||
You can also use the -S option with the git merge command itself to sign the resulting merge commit itself. The following example both verifies that every commit in the branch to be merged is signed and furthermore signs the resulting merge commit.
|
||||
|
||||
```shell
|
||||
$ git merge --verify-signatures -S signed-branch
|
||||
Commit 13ad65e has a good GPG signature by Scott Chacon (Git signing key) <schacon@gmail.com>
|
||||
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "Scott Chacon (Git signing key) <schacon@gmail.com>"
|
||||
2048-bit RSA key, ID 0A46826A, created 2014-06-04
|
||||
|
||||
Merge made by the 'recursive' strategy.
|
||||
README | 2 ++
|
||||
1 file changed, 2 insertions(+)
|
||||
```
|
||||
|
||||
### Everyone Must Sign
|
||||
|
||||
Signing tags and commits is great, but if you decide to use this in your normal workflow, you’ll have to make sure that everyone on your team understands how to do so. If you don’t, you’ll end up spending a lot of time helping people figure out how to rewrite their commits with signed versions. Make sure you understand GPG and the benefits of signing things before adopting this as part of your standard workflow.
|
||||
@@ -1,178 +0,0 @@
|
||||
---
|
||||
title: Git notes
|
||||
tags:
|
||||
- IT
|
||||
- IT/Development/Git
|
||||
---
|
||||
|
||||
|
||||
Note to Self
|
||||
|
||||
One of the cool things about Git is that it has strong cryptographic integrity. If you change any bit in the commit data or any of the files it keeps, all the checksums change, including the commit SHA and every commit SHA since that one. However, that means that in order to amend the commit in any way, for instance to add some comments on something or even sign off on a commit, you have to change the SHA of the commit itself.
|
||||
|
||||
Wouldn't it be nice if you could add data to a commit without changing its SHA? If only there existed an external mechanism to attach data to a commit without modifying the commit message itself. Happy day! It turns out there exists just such a feature in newer versions of Git! As we can see from the Git 1.6.6 release notes where this new functionality was first introduced:
|
||||
|
||||
* "git notes" command to annotate existing commits.
|
||||
|
||||
Need any more be said? Well, maybe. How do you use it? What does it do? How can it be useful? I'm not sure I can answer all of these questions, but let's give it a try. First of all, how does one use it?
|
||||
|
||||
Well, to add a note to a specific commit, you only need to run git notes add [commit], like this:
|
||||
|
||||
$ git notes add HEAD
|
||||
|
||||
This will open up your editor to write your commit message. You can also use the -m option to provide the note right on the command line:
|
||||
|
||||
$ git notes add -m 'I approve - Scott' master~1
|
||||
|
||||
That will add a note to the first parent on the last commit on the master branch. Now, how to view these notes? The easiest way is with the git log command.
|
||||
|
||||
$ git log master
|
||||
commit 0385bcc3bc66d1b1ec07346c237061574335c3b8
|
||||
Author: Ryan Tomayko <rtomayko@gmail.com>
|
||||
Date: Tue Jun 22 20:09:32 2010 -0700
|
||||
|
||||
yield to run block right before accepting connections
|
||||
|
||||
commit 06ca03a20bb01203e2d6b8996e365f46cb6d59bd
|
||||
Author: Ryan Tomayko <rtomayko@gmail.com>
|
||||
Date: Wed May 12 06:47:15 2010 -0700
|
||||
|
||||
no need to delete these header names now
|
||||
|
||||
Notes:
|
||||
I approve - Scott
|
||||
|
||||
You can see the notes appended automatically in the log output. You can only have one note per commit in a namespace though (I will explain namespaces in the next section), so if you want to add a note to that commit, you have to instead edit the existing one. You can either do this by running:
|
||||
|
||||
$ git notes edit master~1
|
||||
|
||||
Which will open a text editor with the existing note so you can edit it:
|
||||
|
||||
I approve - Scott
|
||||
|
||||
```
|
||||
#
|
||||
# Write/edit the notes for the following object:
|
||||
#
|
||||
# commit 06ca03a20bb01203e2d6b8996e365f46cb6d59bd
|
||||
# Author: Ryan Tomayko <rtomayko@gmail.com>
|
||||
# Date: Wed May 12 06:47:15 2010 -0700
|
||||
#
|
||||
# no need to delete these header names now
|
||||
#
|
||||
# kidgloves.rb | 2 --
|
||||
# 1 files changed, 0 insertions(+), 2 deletions(-)
|
||||
~
|
||||
~
|
||||
~
|
||||
".git/NOTES_EDITMSG" 13L, 338C
|
||||
```
|
||||
|
||||
Sort of weird, but it works. If you just want to add something to the end of an existing note, you can run git notes append SHA, but only in newer versions of Git (I think 1.7.1 and above).
|
||||
Notes Namespaces
|
||||
|
||||
Since you can only have one note per commit, Git allows you to have multiple namespaces for your notes. The default namespace is called 'commits', but you can change that. Let's say we're using the 'commits' notes namespace to store general comments but we want to also store bugzilla information for our commits. We can also have a 'bugzilla' namespace. Here is how we would add a bug number to a commit under the bugzilla namespace:
|
||||
|
||||
$ git notes --ref=bugzilla add -m 'bug #15' 0385bcc3
|
||||
|
||||
However, now you have to tell Git to specifically look in that namespace:
|
||||
|
||||
$ git log --show-notes=bugzilla
|
||||
commit 0385bcc3bc66d1b1ec07346c237061574335c3b8
|
||||
Author: Ryan Tomayko <rtomayko@gmail.com>
|
||||
Date: Tue Jun 22 20:09:32 2010 -0700
|
||||
|
||||
yield to run block right before accepting connections
|
||||
|
||||
Notes (bugzilla):
|
||||
bug #15
|
||||
|
||||
commit 06ca03a20bb01203e2d6b8996e365f46cb6d59bd
|
||||
Author: Ryan Tomayko <rtomayko@gmail.com>
|
||||
Date: Wed May 12 06:47:15 2010 -0700
|
||||
|
||||
no need to delete these header names now
|
||||
|
||||
Notes:
|
||||
I approve - Scott
|
||||
|
||||
Notice that it also will show your normal notes. You can actually have it show notes from all your namespaces by running git log --show-notes=* - if you have a lot of them, you may want to just alias that. Here is what your log output might look like if you have a number of notes namespaces:
|
||||
|
||||
$ git log -1 --show-notes=*
|
||||
commit 0385bcc3bc66d1b1ec07346c237061574335c3b8
|
||||
Author: Ryan Tomayko <rtomayko@gmail.com>
|
||||
Date: Tue Jun 22 20:09:32 2010 -0700
|
||||
|
||||
yield to run block right before accepting connections
|
||||
|
||||
Notes:
|
||||
I approve of this, too - Scott
|
||||
|
||||
Notes (bugzilla):
|
||||
bug #15
|
||||
|
||||
Notes (build):
|
||||
build successful (8/13/10)
|
||||
|
||||
You can also switch the current namespace you're using so that the default for writing and showing notes is not 'commits' but, say, 'bugzilla' instead. If you export the variable GIT_NOTES_REF to point to something different, then the --ref and --show-notes options are not neccesary. For example:
|
||||
|
||||
$ export GIT_NOTES_REF=refs/notes/bugzilla
|
||||
|
||||
That will set your default to 'bugzilla' instead. It has to start with the 'refs/notes/' though.
|
||||
Sharing Notes
|
||||
|
||||
Now, here is where the general usability of this really breaks down. I am hoping that this will be improved in the future and I put off writing this post because of my concern with this phase of the process, but I figured it has interesting enough functionality as-is that someone might want to play with it.
|
||||
|
||||
So, the notes (as you may have noticed in the previous section) are stored as references, just like branches and tags. This means you can push them to a server. However, Git has a bit of magic built in to expand a branch name like 'master' to what it really is, which is 'refs/heads/master'. Unfortunately, Git has no such magic built in for notes. So, to push your notes to a server, you cannot simply run something like git push origin bugzilla. Git will do this:
|
||||
|
||||
$ git push origin bugzilla
|
||||
error: src refspec bugzilla does not match any.
|
||||
error: failed to push some refs to 'git@github.com:schacon/kidgloves.git'
|
||||
|
||||
However, you can push anything under 'refs/' to a server, you just need to be more explicit about it. If you run this it will work fine:
|
||||
|
||||
$ git push origin refs/notes/bugzilla
|
||||
Counting objects: 3, done.
|
||||
Delta compression using up to 2 threads.
|
||||
Compressing objects: 100% (2/2), done.
|
||||
Writing objects: 100% (3/3), 263 bytes, done.
|
||||
Total 3 (delta 0), reused 0 (delta 0)
|
||||
To git@github.com:schacon/kidgloves.git
|
||||
* [new branch] refs/notes/bugzilla -> refs/notes/bugzilla
|
||||
|
||||
In fact, you may want to just make that git push origin refs/notes/* which will push all your notes. This is what Git does normally for something like tags. When you run git push origin --tags it basically expands to git push origin refs/tags/*.
|
||||
Getting Notes
|
||||
|
||||
Unfortunately, getting notes is even more difficult. Not only is there no git fetch --notes or something, you have to specify both sides of the refspec (as far as I can tell).
|
||||
|
||||
$ git fetch origin refs/notes/*:refs/notes/*
|
||||
remote: Counting objects: 12, done.
|
||||
remote: Compressing objects: 100% (8/8), done.
|
||||
remote: Total 12 (delta 0), reused 0 (delta 0)
|
||||
Unpacking objects: 100% (12/12), done.
|
||||
From github.com:schacon/kidgloves
|
||||
* [new branch] refs/notes/bugzilla -> refs/notes/bugzilla
|
||||
|
||||
That is basically the only way to get them into your repository from the server. Yay. If you want to, you can setup your Git config file to automatically pull them down though. If you look at your .git/config file you should have a section that looks like this:
|
||||
|
||||
[remote "origin"]
|
||||
fetch = +refs/heads/*:refs/remotes/origin/*
|
||||
url = git@github.com:schacon/kidgloves.git
|
||||
|
||||
The 'fetch' line is the refspec of what Git will try to do if you run just git fetch origin. It contains the magic formula of what Git will fetch and store local references to. For instance, in this case it will take every branch on the server and give you a local branch under 'remotes/origin/' so you can reference the 'master' branch on the server as 'remotes/origin/master' or just 'origin/master' (it will look under 'remotes' when it's trying to figure out what you're doing). If you change that line to fetch = +refs/heads/*:refs/remotes/manamana/* then even though your remote is named 'origin', the master branch from your 'origin' server will be under 'manamana/master'.
|
||||
|
||||
Anyhow, you can use this to make your notes fetching easier. If you add multiple fetch lines, it will do them all. So in addition to the current fetch line, you can add a line that looks like this:
|
||||
|
||||
fetch = +refs/notes/*:refs/notes/*
|
||||
|
||||
Which says also get all the notes references on the server and store them as though they were local notes. Or you can namespace them if you want, but that can cause issues when you try to push them back again.
|
||||
Collaborating on Notes
|
||||
|
||||
Now, this is where the main problem is. Merging notes is super difficult. This means that if you pull down someone's notes, you edit any note in a namespace locally and the other developer edits any note in that same namespace, you're going to have a hard time getting them back in sync. When the second person tries to push their notes it will look like a non-fast-forward just like a normal branch update, but unline a normal branch you can't just run git pull and then try again. You have to check out your notes ref as if it were a normal branch, which will look ridiculously confusing and then do the merge and then switch back. It is do-able, but probably not something you really want to do.
|
||||
|
||||
Because of this, it's probably best to namespace your notes or better just have an automated process create them (like build statuses or bugzilla artifacts). If only one entity is updating your notes, you won't have merge issues. However, if you want to use them to comment on commits within a team, it is going to be a bit painful.
|
||||
|
||||
So far, I've heard of people using them to have their ticketing system attach metadata automatically or have a system attach associated mailing list emails to commits they concern. Other people just use them entirely locally without pushing them anywhere to store reminders for themselves and whatnot.
|
||||
Probably a good start, but the ambitious among you may come up with something else interesting to do. Let me know!
|
||||
|
||||
|
||||
@@ -1,100 +0,0 @@
|
||||
---
|
||||
title: Git team workflows
|
||||
source: https://www.atlassian.com/blog/git/git-team-workflows-merge-or-rebase
|
||||
tags:
|
||||
- IT/Development/Git
|
||||
---
|
||||
|
||||
Published October 28, 2013 in [Git](https://www.atlassian.com/blog/git)
|
||||
|
||||
Published October 28, 2013 in [Git](https://www.atlassian.com/blog/git)
|
||||
|
||||
The question is simple: In a software team using [git](http://atlassian.com/git) and [feature branching](https://www.atlassian.com/git/workflows#!workflow-feature-branch), what’s the best way to incorporate finished work back to your main line of development? It’s one of those recurring debates where both sides have strong opinions, and mindful conversation can sometimes be hard (for other examples of heated debate see: [The Internet](http://en.wikipedia.org/wiki/Internet)).
|
||||
|
||||
Should you adopt a rebase policy where the repository history is kept flat and clean? Or a merge policy, which gives you traceability at the expense of readability and clarity (going so far as forbidding [fast-forward](https://www.atlassian.com/git/tutorial/git-branches#!merge) merges)?
|
||||
|
||||
## A debate exists
|
||||
|
||||
The topic is a bit controversial; maybe not as much as classic holy wars between vim and Emacs, or between Linux and BSD, but the two camps are vocal.
|
||||
|
||||
My empirical pulse on all-things-git – scientific, I know! – is that the **always merge** approach has a slightly bigger mind share. But the **always rebase** field is also pretty vocal online. For examples see:
|
||||
|
||||
- [A rebase-based workflow](http://unethicalblogger.com/2010/04/02/a-rebase-based-workflow.html)
|
||||
- [A Rebase Workflow for Git](http://randyfay.com/content/rebase-workflow-git)
|
||||
- [A Simple Git Rebase Workflow, Explained](http://mettadore.com/analysis/a-simple-git-rebase-workflow-explained/)
|
||||
- [A Git Workflow for Agile Teams](http://reinh.com/blog/2009/03/02/a-git-workflow-for-agile-teams.html)
|
||||
|
||||
To be honest, the split in two camps – always rebase vs. always merge – can be confusing, because **rebase as local cleanup** is a different thing than **rebase as team policy**.
|
||||
|
||||
## Aside: **Rebase as cleanup** is awesome in the coding lifecycle
|
||||
|
||||
**Rebase as team policy** is a different thing than **rebase as cleanup**. **Rebase as cleanup** is a healthy part of the coding lifecycle of the git practitioner. Let me detail some example scenarios that show when rebasing is reasonable and effective (and when it’s not):
|
||||
|
||||
- **You’re developing locally.** You have not shared your work with anyone else. At this point, you should prefer rebasing over merging to keep history tidy. If you’ve got your personal fork of the repository and that is not shared with other developers, you’re safe to rebase even after you’ve pushed to your fork.
|
||||
- **Your code is ready for review.** You create a pull request, others are reviewing your work and are potentially fetching it into their fork for local review. At this point you should not rebase your work. You should create ‘rework’ commits and update your feature branch. This helps with traceability in the pull request, and prevents the accidental history breakage.
|
||||
- **Review is done and ready to be integrated into the target branch.** Congratulations! You’re about to delete your feature branch. Given that other developers won’t be fetch-merging in these changes from this point on, this is your chance to sanitize history. At this point you can rewrite history and fold the original commits and those pesky ‘pr rework’ and ‘merge’ commits into a small set of focussed commits. Creating an explicit merge for these commits is optional, but has value. It records when the feature graduated to master.
|
||||
|
||||
With this aside clear we can now talk about **policies**. I’ll try to keep a balanced view on the argument, and will mention how the problem is dealt with inside Atlassian.
|
||||
|
||||
## **Rebase team policy**: definition, pros, and cons
|
||||
|
||||
It’s obviously hard to generalize since every team is different, but we have to start from somewhere. Consider this policy as a possible example: When a feature branch’s development is complete, rebase/[squash](http://git-scm.com/book/en/Git-Tools-Rewriting-History) all the work down to the minimum number of meaningful commits and **avoid creating a merge commit** – either making sure the changes [fast-forward](https://www.atlassian.com/git/tutorial/git-branches#!merge) (or simply [cherry-pick](https://www.kernel.org/pub/software/scm/git/docs/git-cherry-pick.html) those commits into the target branch).
|
||||
|
||||
While the work is still in progress and a feature branch needs to be brought up to date with the upstream target branch, use rebase – as opposed to pull or merge – not to pollute the history with spurious merges.
|
||||
|
||||
### Pros:
|
||||
|
||||
- Code history remains flat and readable. Clean, clear commit messages are as much part of the documentation of your code base as code comments, comments on your issue tracker etc. For this reason, it’s important not to pollute history with 31 single-line commits that partially cancel each other out for a single feature or bug fix. Going back through history to figure out when a bug or feature was introduced, and why it was done, is going to be tough in a situation like this.
|
||||
- Manipulating a single commit is easy (e.g. reverting them).
|
||||
|
||||
### Cons:
|
||||
|
||||
- Squashing the feature down to a handful of commits can hide context, unless you keep around the historical branch with the entire development history.
|
||||
- Rebasing doesn’t play well with [pull requests](https://www.atlassian.com/software/stash/overview/pull-requests), because you can’t see what minor changes someone made if they rebased (incidentally, the consensus inside the [Stash](http://www.atlassian.com/software/stash/overview) development team is to never rebase during a pull request).
|
||||
- Rebasing can be dangerous! Rewriting history of shared branches is prone to team work breakage. This can be mitigated by doing the rebase/squash on a copy of the feature branch, but rebase carries the implication that competence and carefulness must be employed.
|
||||
- It’s more work: Using rebase to keep your feature branch updated requires that you resolve similar conflicts again and again. Yes, you can [reuse recorded resolutions (rerere)](https://www.kernel.org/pub/software/scm/git/docs/git-rerere.html) sometimes, but merges win here: Just solve the conflicts one time, and you’re set.
|
||||
- Another side effect of rebasing with remote branches is that you need to *force push* at some point. The biggest problem we’ve seen at Atlassian is that people force push – which is fine – but haven’t set git push.default. This results in updates to all branches having the same name, both locally and remotely, and that is **dreadful** to deal with.
|
||||
|
||||
**NOTE: When history is rewritten in a shared branch touched by multiple developers breakage happens**.
|
||||
|
||||
## **Merge team policy**: definitions, pros, and cons
|
||||
|
||||
**Always Merge**-based policies instead flow like this: When a feature branch is complete merge it to your target branch (master or develop or next).
|
||||
|
||||
Make sure the merge is explicit with –no-ff, which forces git to record a merge commit in all cases, even if the changes could be replayed automatically on top of the target branch.
|
||||
|
||||
### Pros:
|
||||
|
||||
- Traceability: This helps keeping information about the historical existence of a feature branch and groups together all commits part of the feature.
|
||||
|
||||
### Cons:
|
||||
|
||||
- History can become intensely polluted by lots of merge commits, and visual charts of your repository can have rainbow branch lines that don’t add too much information, if not outright obfuscate what’s happening. (Now to be fair, confusion is easily solved by knowing how to navigate your history; The trick here is to use, for example, git log –first-parent to make sense of what happened.)
|
||||
|
||||
[](http://atlassianblog.wpengine.com/wp-content/uploads/merge-trees-1-600x183.png)
|
||||
|
||||
- Debugging using git bisect can become much harder due to the merge commits.
|
||||
|
||||
## Decisions, decisions, decisions: What do you value most?
|
||||
|
||||
So what’s best? What do the experts recommend?
|
||||
|
||||
If you and your team are not familiar with, or don’t understand the intricacies of rebase, then you probably shouldn’t use it. In this context, **always merge** is the safest option.
|
||||
|
||||
If you and your team are familiar with both options, then the main decision revolves around this: **Do you value more a clean, linear history? Or the traceability of your branches?** In the first case go for a **rebase** policy, in the later go for a **merge** one.
|
||||
|
||||
Note that a rebase policy comes with small contraindications and takes more effort.
|
||||
|
||||
### At Atlassian
|
||||
|
||||
The policy inside Atlassian’s [Stash](http://www.atlassian.com/software/stash/overview) team is always to merge feature branches, and require that branches are merged through a [pull request](https://www.atlassian.com/software/stash/overview/pull-requests) for quality and code review. But the team is not too strict around fast-forward.
|
||||
|
||||
### Conclusions and acknowledgements
|
||||
|
||||
This article is the result of the [confluence](https://www.atlassian.com/software/confluence) of insightful exchanges (pun intended!) with the [Stash](http://www.atlassian.com/software/stash/overview) team on the topic.
|
||||
|
||||
This piece hopefully dispels the doubts on this, and allows you to adopt an approach that works for your team. Follow me [@durdn](http://twitter.com/durdn) for more git awesomeness.
|
||||
|
||||
> Anyone can be good, but awesome takes teamwork.
|
||||
>
|
||||
> Find tools to help your team work better together in our [Git Essentials](https://www.atlassian.com/solutions/git-essentials/?utm_source=Atlassian&utm_medium=blog&utm_campaign=git-together) solution.
|
||||
@@ -1,232 +0,0 @@
|
||||
---
|
||||
title: Git-flow-Workflow | Atlassian Git Tutorial
|
||||
source: https://www.atlassian.com/de/git/tutorials/comparing-workflows/gitflow-workflow
|
||||
tags:
|
||||
- IT/Development/Git
|
||||
- IT/Tools/Gitflow
|
||||
---
|
||||
|
||||
## [Git-flow-Workflow | Atlassian Git Tutorial](https://www.atlassian.com/de/git/tutorials/comparing-workflows/gitflow-workflow)
|
||||
|
||||
Gitflow ist ein veralteter Git-Workflow der einst eine disruptive und neuartige Strategie für die Verwaltung von Git-Branches darstellte. An die Stelle von Gitflow sind mittlerweile [Trunk-basierte](https://www.atlassian.com/de/continuous-delivery/continuous-integration/trunk-based-development) Workflows getreten, die in der modernen kontinuierlichen Softwareentwicklung und im [DevOps](https://www.atlassian.com/de/devops/what-is-devops)-Bereich zum Einsatz kommen. Hinzu kommt, dass sich Gitflow nur schwierig in [CI/CD](https://www.atlassian.com/de/continuous-delivery)-Prozesse integrieren lässt. Dieser Artikel zu Gitflow dient lediglich der historischen Einordnung.
|
||||
|
||||
## Was ist Gitflow?
|
||||
|
||||
Gitflow ist ein alternatives Git-Branching-Modell, das Feature-Branches und mehrere primäre Branches verwendet. Er wurde erstmals von [Vincent Driessen auf nvie](http://nvie.com/posts/a-successful-git-branching-model/) veröffentlicht und bekannt gemacht. Gitflow verfügt im Gegensatz zur Trunk-basierten Entwicklung über mehr und langlebigere Branches sowie größere Commits. Unter diesem Modell erstellen Entwickler einen Feature-Branch und verzögern den Merge mit dem Haupt-Trunk-Branch, bis das Feature vollständig ist. Diese langlebigen Feature-Branches erfordern mehr Zusammenarbeit bei Merges und haben ein höheres Risiko, vom Trunk-Branch abzuweichen. Außerdem können sie womöglich konfliktbehaftete Updates einführen.
|
||||
|
||||
Gitflow kann für Projekte genutzt werden, die einen geplanten Release-Zyklus haben, sowie für die [DevOps-Best-Practices](https://www.atlassian.com/de/devops/what-is-devops/devops-best-practices) der [Continuous Delivery](https://www.atlassian.com/de/continuous-delivery). Dieser Workflow fügt keine neuen Konzepte oder Befehle hinzu, die über das für den [Feature-Branch-Workflow](https://www.atlassian.com/de/git/tutorials/comparing-workflows/feature-branch-workflow) Erforderliche hinausgehen. Stattdessen weist er verschiedenen Branches äußerst spezifische Rollen zu und definiert, wie und wann diese interagieren sollen. Zusätzlich zu `Feature`-Branches verwendet er einzelne Branches zum Vorbereiten, Verwalten und Aufzeichnen von Releases. Natürlich kannst du auch alle Vorteile des Feature-Branch-Workflows nutzen: Pull-Anfragen, isolierte Experimente und eine effizientere Zusammenarbeit.
|
||||
|
||||
## Erste Schritte
|
||||
|
||||
Git-flow ist nur eine abstrakte Vorstellung eines Git-Workflows. Dabei wird lediglich vorgegeben, welche Art von Branches einzurichten und wie sie zu mergen sind. Welchen Zweck die Branches erfüllen, sehen wir später. Die Git-flow-Tools sind echte Befehlszeilentools, die eine Installation voraussetzen. Der Installationsprozess für Git-flow ist ganz einfach. Git-flow-Pakete sind für mehrere Betriebssysteme verfügbar. Auf OS X-Systemen führst du einfach `brew install git-flow` aus. Unter Windows musst du [Git-flow herunterladen und installieren](https://git-scm.com/download/win). Nach der Installation kannst du Git-flow mit dem Befehl `git flow init` in deinem Projekt nutzen. Git-flow ist eine Art Umhüllung für Git. Der Befehl `git flow init` ist eine Erweiterung des Standardbefehls `[git init](https://www.atlassian.com/de/git/tutorials/setting-up-a-repository/git-init)`. In deinem Repository ändert sich dabei nichts, außer dass jetzt Branches für dich erstellt werden können.
|
||||
|
||||
## Wie es funktioniert
|
||||
|
||||

|
||||
|
||||
### Develop- und Haupt-Branches
|
||||
|
||||
Statt eines einzelnen `main`-Branch sieht dieser Workflow zwei Branches vor, um den Verlauf des Projekts aufzuzeichnen. Der `main`-Branch enthält den offiziellen Release-Verlauf und der `develop`-Branch dient als Integrations-Branch für Features. Es ist zudem üblich, alle Commits im `main`-Branch mit einer Versionsnummer zu taggen.
|
||||
|
||||
Der erste Schritt ist, den obligatorischen `main`\- mit einem `develop`-Branch zu ergänzen. Entwickler können das ganz einfach tun, indem sie einen leeren `develop`-Branch lokal erstellen und ihn zum Server pushen:
|
||||
|
||||
```shell
|
||||
git branch develop
|
||||
git push -u origin develop
|
||||
```
|
||||
|
||||
Dieser Branch wird den kompletten Versionsverlauf des Projekts enthalten, während der `main`-Branch eine verkürzte Version enthält. Andere Entwickler sollten das zentrale Repository nun klonen und einen Tracking-Branch für den `develop`-Branch erstellen.
|
||||
|
||||
Wenn du die Git-flow-Erweiterungsbibliothek verwendest, wird beim Ausführen von `git flow init` in einem bestehenden Repository der `develop` Branch erstellt:
|
||||
|
||||
```shell
|
||||
$ git flow init
|
||||
|
||||
Initialized empty Git repository in ~/project/.git/
|
||||
No branches exist yet. Base branches must be created now.
|
||||
Branch name for production releases: [main]
|
||||
Branch name for "next release" development: [develop]
|
||||
|
||||
How to name your supporting branch prefixes?
|
||||
Feature branches? [feature/]
|
||||
Release branches? [release/]
|
||||
Hotfix branches? [hotfix/]
|
||||
Support branches? [support/]
|
||||
Version tag prefix? []
|
||||
|
||||
$ git branch
|
||||
* develop
|
||||
main
|
||||
|
||||
|
||||
```
|
||||
|
||||
## Feature Branches
|
||||
|
||||
Jedes neue Feature sollte sich auf seinem eigenen Branch befinden, der zu Sicherungs-/Zusammenarbeitszwecken [zum zentralen Repository gepusht werden kann](https://www.atlassian.com/de/git/tutorials/syncing/git-push). Doch anstatt Branches auf Basis des `main`-Branch zu erstellen, nutzen `feature`-Branches den `develop`-Branch als übergeordneten Branch. Wenn ein Feature fertig ist, wird es [zurück in den develop-Branch gemergt](https://www.atlassian.com/de/git/tutorials/using-branches/git-merge). Features sollten niemals direkt mit dem `main`-Branch interagieren.
|
||||
|
||||

|
||||
|
||||
Beachte, dass die Kombination von `Feature` Branches mit dem `develop`-Branch eigentlich dem Feature Branch Workflow entspricht. Doch der Git-flow-Workflow geht darüber hinaus.
|
||||
|
||||
`feature`-Branches werden für gewöhnlich auf Basis des aktuellsten `develop`-Branches erstellt.
|
||||
|
||||
### Einen Feature Branch erstellen
|
||||
|
||||
Ohne die Git-flow-Erweiterungen:
|
||||
|
||||
```
|
||||
git checkout develop
|
||||
git checkout -b feature_branch
|
||||
```
|
||||
|
||||
Mit der Git-flow-Erweiterung:
|
||||
|
||||
```
|
||||
git flow feature start feature_branch
|
||||
```
|
||||
|
||||
Setze deine Arbeit fort und nutze Git wie gewohnt.
|
||||
|
||||
### Einen Feature Branch abschließen
|
||||
|
||||
Wenn die Entwicklungsarbeiten am Feature abgeschlossen sind, muss als nächstes der `feature_branch` in den `develop` Branch gemergt werden.
|
||||
|
||||
Ohne die Git-flow-Erweiterungen:
|
||||
|
||||
```shell
|
||||
git checkout develop
|
||||
git merge feature_branch
|
||||
```
|
||||
|
||||
Mit der Git-flow-Erweiterung:
|
||||
|
||||
```shell
|
||||
git flow feature finish feature_branch
|
||||
```
|
||||
|
||||
## Release-Branches
|
||||
|
||||

|
||||
|
||||
Wenn der `develop`-Branch genügend Features für ein Release enthält (oder ein festgelegter Release-Termin ansteht), wird vom `develop`-Branch ein `release`-Branch geforkt. Damit beginnt der neue Release-Zyklus. In diesem Branch sollten ab diesem Punkt keine neuen Features mehr hinzugefügt werden, sondern nur Bugfixes und ähnliche Release-orientierte Änderungen. Ist er zur Auslieferung bereit, wird der `release`-Branch in den `main`-Branch gemergt und mit einer Versionsnummer getaggt. Zusätzlich sollte er zurück in den `develop`-Branch gemergt werden, der sich seit Initiierung des Release weiterentwickelt haben könnte.
|
||||
|
||||
Werden Releases in dedizierten Branches vorbereitet, ist paralleles Arbeiten möglich: Eines eurer Teams kann dem aktuellen Release den letzten Schliff geben, während ein anderes Team sich weiter um die Features des nächsten Release kümmert. Außerdem lassen sich auf diese Weise klar abgegrenzte Entwicklungsphasen definieren. Wenn ihr euch entscheidet, in einer Woche an Version 4.0 zu arbeiten, kann die Struktur eures Repositorys diese Entscheidung abbilden.
|
||||
|
||||
Das Erstellen von `release` Branches ist ebenfalls ein unkomplizierter Branching-Vorgang. Wie die `feature` Branches basieren `release` branches auf dem `develop` Branch. Ein neuer `release` Branch kann mit den folgenden Methoden erstellt werden.
|
||||
|
||||
Ohne die Git-flow-Erweiterungen:
|
||||
|
||||
```shell
|
||||
git checkout develop
|
||||
git checkout -b release/0.1.0
|
||||
```
|
||||
|
||||
Mit der Git-flow-Erweiterung:
|
||||
|
||||
```shell
|
||||
$ git flow release start 0.1.0
|
||||
Switched to a new branch 'release/0.1.0'
|
||||
```
|
||||
|
||||
Ist der Release bereit zur Auslieferung, wird er in den `main`-Branch und den `develop`-Branch gemergt. Anschließend wird der `release`-Branch gelöscht. Es ist wichtig, zurück in den `develop`-Branch zu mergen, da der `release`-Branch eventuell kritische Updates enthalten kann, auf die neue Features Zugriff haben müssen. Wenn deine Organisation Code-Reviews nutzt, ist hier ein sehr guter Zeitpunkt für einen Pull-Request.
|
||||
|
||||
Du beendest einen `release` Branch mit den folgenden Methoden:
|
||||
|
||||
Ohne die Git-flow-Erweiterungen:
|
||||
|
||||
```shell
|
||||
git checkout main
|
||||
git merge release/0.1.0
|
||||
```
|
||||
|
||||
Mit der Git-flow-Erweiterung:
|
||||
|
||||
```shell
|
||||
git flow release finish '0.1.0'
|
||||
```
|
||||
|
||||
## Hotfix Branches
|
||||
|
||||

|
||||
|
||||
Maintenance- bzw. `hotfix`-Branches eignen sich für schnelle Patches von Produktions-Releases. `hotfix`-Branches sind `release`-Branches und `feature`-Branches sehr ähnlich, basieren jedoch auf dem `main`\- statt auf dem `develop`-Branch. Dies ist der einzige Branch, der direkt vom `main`-Branch geforkt werden sollte. Sobald der Fix abgeschlossen wurde, sollte er sowohl in den `main`\- als auch in den `develop`-Branch (oder den aktuellen `release`-Branch) gemergt werden; der `main`-Branch sollte außerdem mit einer aktualisierten Versionsnummer getaggt werden.
|
||||
|
||||
Durch eine solche dedizierte Entwicklungslinie für Bugfixes kann ein Team Probleme beheben, ohne den Rest des Workflows zu unterbrechen oder auf den nächsten Release-Zyklus warten zu müssen. Maintenance-Branches sind sozusagen Ad-hoc-`release`-Branches, die direkt mit dem `main`-Branch interagieren. Einen `hotfix`-Branch kannst du mithilfe folgender Methoden erstellen:
|
||||
|
||||
Ohne die Git-flow-Erweiterungen:
|
||||
|
||||
```shell
|
||||
git checkout main
|
||||
git checkout -b hotfix_branch
|
||||
```
|
||||
|
||||
Mit der Git-flow-Erweiterung:
|
||||
|
||||
```shell
|
||||
$ git flow hotfix start hotfix_branch
|
||||
```
|
||||
|
||||
Ähnlich wie beim Abschluss eines `release`-Branch wird ein `hotfix`-Branch sowohl in den `main`\- als auch in den `develop`-Branch gemergt.
|
||||
|
||||
```shell
|
||||
git checkout main
|
||||
git merge hotfix_branch
|
||||
git checkout develop
|
||||
git merge hotfix_branch
|
||||
git branch -D hotfix_branch
|
||||
```
|
||||
|
||||
```shell
|
||||
$ git flow hotfix finish hotfix_branch
|
||||
```
|
||||
|
||||
## Beispiel
|
||||
|
||||
Im Folgenden siehst du ein vollständiges Beispiel für einen Feature-Branch-Workflow. Nehmen wir an, wir haben ein Repository mit einem `main`-Branch eingerichtet.
|
||||
|
||||
```shell
|
||||
git checkout main
|
||||
git checkout -b develop
|
||||
git checkout -b feature_branch
|
||||
# work happens on feature branch
|
||||
git checkout develop
|
||||
git merge feature_branch
|
||||
git checkout main
|
||||
git merge develop
|
||||
git branch -d feature_branch
|
||||
```
|
||||
|
||||
Zusätzlich zum `feature` Workflow und `release` Workflow sieht ein `hotfix`-Beispiel folgendermaßen aus:
|
||||
|
||||
```shell
|
||||
git checkout main
|
||||
git checkout -b hotfix_branch
|
||||
# work is done commits are added to the hotfix_branch
|
||||
git checkout develop
|
||||
git merge hotfix_branch
|
||||
git checkout main
|
||||
git merge hotfix_branch
|
||||
```
|
||||
|
||||
## Zusammenfassung
|
||||
|
||||
Wir haben hier den Git-flow-Workflow besprochen. Git-flow ist eine der vielen Varianten des [Git-Workflows](https://www.atlassian.com/de/git/tutorials/comparing-workflows), die du dir mit deinem Team zunutze machen kannst.
|
||||
|
||||
Wichtige Punkte zum Git-flow:
|
||||
|
||||
- Der Workflow eignet sich hervorragend für release-basierte Software-Workflows.
|
||||
- Gitflow bietet einen eigenen Kanal für Hotfixes bis zur Produktion.
|
||||
|
||||
|
||||
Der allgemeine Git-flow-Ablauf sieht so aus:
|
||||
|
||||
1. Ein `develop`-Branch wird auf Basis des `main`-Branch erstellt.
|
||||
2. Ein `release` Branch wird vom `develop` Branch erstellt.
|
||||
3. Ein `feature` Branch wird ebenfalls vom `develop` Branch erstellt.
|
||||
4. Wenn ein `feature` fertig ist, wird es in den `develop`-Branch gemergt.
|
||||
5. Ist der `release`-Branch abgeschlossen, wird er in den `develop`-Branch und den `main`-Branch gemergt.
|
||||
6. Taucht ein Problem im `main`-Branch auf, wird ein `hotfix`-Branch auf Basis des `main`-Branch erstellt.
|
||||
7. Sobald der `hotfix` abgeschlossen ist, wird er in den `develop`-Branch und den `main`-Branch gemergt.
|
||||
|
||||
Fahre nun fort mit dem [Forking-Workflow](https://www.atlassian.com/de/git/tutorials/comparing-workflows/forking-workflow) oder sieh dir unseren [Workflow-Vergleich](https://www.atlassian.com/de/git/tutorials/comparing-workflows) an.
|
||||
@@ -1,230 +0,0 @@
|
||||
---
|
||||
title: Git-flow-Workflow | Atlassian Git Tutorial
|
||||
tags:
|
||||
- IT/Development/Git
|
||||
- IT/Workflow
|
||||
- IT/Tools/Gitflow
|
||||
source: https://www.atlassian.com/de/git/tutorials/comparing-workflows/gitflow-workflow
|
||||
---
|
||||
|
||||
Gitflow ist ein veralteter Git-Workflow der einst eine disruptive und neuartige Strategie für die Verwaltung von Git-Branches darstellte. An die Stelle von Gitflow sind mittlerweile [Trunk-basierte](https://www.atlassian.com/de/continuous-delivery/continuous-integration/trunk-based-development) Workflows getreten, die in der modernen kontinuierlichen Softwareentwicklung und im [DevOps](https://www.atlassian.com/de/devops/what-is-devops)-Bereich zum Einsatz kommen. Hinzu kommt, dass sich Gitflow nur schwierig in [CI/CD](https://www.atlassian.com/de/continuous-delivery)-Prozesse integrieren lässt. Dieser Artikel zu Gitflow dient lediglich der historischen Einordnung.
|
||||
|
||||
## Was ist Gitflow?
|
||||
|
||||
Gitflow ist ein alternatives Git-Branching-Modell, das Feature-Branches und mehrere primäre Branches verwendet. Er wurde erstmals von [Vincent Driessen auf nvie](http://nvie.com/posts/a-successful-git-branching-model/) veröffentlicht und bekannt gemacht. Gitflow verfügt im Gegensatz zur Trunk-basierten Entwicklung über mehr und langlebigere Branches sowie größere Commits. Unter diesem Modell erstellen Entwickler einen Feature-Branch und verzögern den Merge mit dem Haupt-Trunk-Branch, bis das Feature vollständig ist. Diese langlebigen Feature-Branches erfordern mehr Zusammenarbeit bei Merges und haben ein höheres Risiko, vom Trunk-Branch abzuweichen. Außerdem können sie womöglich konfliktbehaftete Updates einführen.
|
||||
|
||||
Gitflow kann für Projekte genutzt werden, die einen geplanten Release-Zyklus haben, sowie für die [DevOps-Best-Practices](https://www.atlassian.com/de/devops/what-is-devops/devops-best-practices) der [Continuous Delivery](https://www.atlassian.com/de/continuous-delivery). Dieser Workflow fügt keine neuen Konzepte oder Befehle hinzu, die über das für den [Feature-Branch-Workflow](https://www.atlassian.com/de/git/tutorials/comparing-workflows/feature-branch-workflow) Erforderliche hinausgehen. Stattdessen weist er verschiedenen Branches äußerst spezifische Rollen zu und definiert, wie und wann diese interagieren sollen. Zusätzlich zu `Feature`-Branches verwendet er einzelne Branches zum Vorbereiten, Verwalten und Aufzeichnen von Releases. Natürlich kannst du auch alle Vorteile des Feature-Branch-Workflows nutzen: Pull-Anfragen, isolierte Experimente und eine effizientere Zusammenarbeit.
|
||||
|
||||
## Erste Schritte
|
||||
|
||||
Git-flow ist nur eine abstrakte Vorstellung eines Git-Workflows. Dabei wird lediglich vorgegeben, welche Art von Branches einzurichten und wie sie zu mergen sind. Welchen Zweck die Branches erfüllen, sehen wir später. Die Git-flow-Tools sind echte Befehlszeilentools, die eine Installation voraussetzen. Der Installationsprozess für Git-flow ist ganz einfach. Git-flow-Pakete sind für mehrere Betriebssysteme verfügbar. Auf OS X-Systemen führst du einfach `brew install git-flow` aus. Unter Windows musst du [Git-flow herunterladen und installieren](https://git-scm.com/download/win). Nach der Installation kannst du Git-flow mit dem Befehl `git flow init` in deinem Projekt nutzen. Git-flow ist eine Art Umhüllung für Git. Der Befehl `git flow init` ist eine Erweiterung des Standardbefehls `git init`. In deinem Repository ändert sich dabei nichts, außer dass jetzt Branches für dich erstellt werden können.
|
||||
|
||||
## Wie es funktioniert
|
||||
|
||||

|
||||
|
||||
### Develop- und Haupt-Branches
|
||||
|
||||
Statt eines einzelnen `main`-Branch sieht dieser Workflow zwei Branches vor, um den Verlauf des Projekts aufzuzeichnen. Der `main`-Branch enthält den offiziellen Release-Verlauf und der `develop`-Branch dient als Integrations-Branch für Features. Es ist zudem üblich, alle Commits im `main`-Branch mit einer Versionsnummer zu taggen.
|
||||
|
||||
Der erste Schritt ist, den obligatorischen `main`\- mit einem `develop`-Branch zu ergänzen. Entwickler können das ganz einfach tun, indem sie einen leeren `develop`-Branch lokal erstellen und ihn zum Server pushen:
|
||||
|
||||
```
|
||||
git branch develop
|
||||
git push -u origin develop
|
||||
```
|
||||
|
||||
Dieser Branch wird den kompletten Versionsverlauf des Projekts enthalten, während der `main`-Branch eine verkürzte Version enthält. Andere Entwickler sollten das zentrale Repository nun klonen und einen Tracking-Branch für den `develop`-Branch erstellen.
|
||||
|
||||
Wenn du die Git-flow-Erweiterungsbibliothek verwendest, wird beim Ausführen von `git flow init` in einem bestehenden Repository der `develop` Branch erstellt:
|
||||
|
||||
```
|
||||
$ git flow init
|
||||
|
||||
Initialized empty Git repository in ~/project/.git/
|
||||
No branches exist yet. Base branches must be created now.
|
||||
Branch name for production releases: [main]
|
||||
Branch name for "next release" development: [develop]
|
||||
|
||||
How to name your supporting branch prefixes?
|
||||
Feature branches? [feature/]
|
||||
Release branches? [release/]
|
||||
Hotfix branches? [hotfix/]
|
||||
Support branches? [support/]
|
||||
Version tag prefix? []
|
||||
|
||||
|
||||
$ git branch
|
||||
* develop
|
||||
main
|
||||
```
|
||||
|
||||
## Feature Branches
|
||||
|
||||
Jedes neue Feature sollte sich auf seinem eigenen Branch befinden, der zu Sicherungs-/Zusammenarbeitszwecken [zum zentralen Repository gepusht werden kann](https://www.atlassian.com/de/git/tutorials/syncing/git-push). Doch anstatt Branches auf Basis des `main`-Branch zu erstellen, nutzen `feature`-Branches den `develop`-Branch als übergeordneten Branch. Wenn ein Feature fertig ist, wird es [zurück in den develop-Branch gemergt](https://www.atlassian.com/de/git/tutorials/using-branches/git-merge). Features sollten niemals direkt mit dem `main`-Branch interagieren.
|
||||
|
||||

|
||||
|
||||
Beachte, dass die Kombination von `Feature` Branches mit dem `develop`-Branch eigentlich dem Feature Branch Workflow entspricht. Doch der Git-flow-Workflow geht darüber hinaus.
|
||||
|
||||
`feature`-Branches werden für gewöhnlich auf Basis des aktuellsten `develop`-Branches erstellt.
|
||||
|
||||
### Einen Feature Branch erstellen
|
||||
|
||||
Ohne die Git-flow-Erweiterungen:
|
||||
|
||||
```
|
||||
git checkout develop
|
||||
git checkout -b feature_branch
|
||||
```
|
||||
|
||||
Mit der Git-flow-Erweiterung:
|
||||
|
||||
```
|
||||
git flow feature start feature_branch
|
||||
```
|
||||
|
||||
Setze deine Arbeit fort und nutze Git wie gewohnt.
|
||||
|
||||
### Einen Feature Branch abschließen
|
||||
|
||||
Wenn die Entwicklungsarbeiten am Feature abgeschlossen sind, muss als nächstes der `feature_branch` in den `develop` Branch gemergt werden.
|
||||
|
||||
Ohne die Git-flow-Erweiterungen:
|
||||
|
||||
```
|
||||
git checkout develop
|
||||
git merge feature_branch
|
||||
```
|
||||
|
||||
Mit der Git-flow-Erweiterung:
|
||||
|
||||
```
|
||||
git flow feature finish feature_branch
|
||||
```
|
||||
|
||||
## Release-Branches
|
||||
|
||||

|
||||
|
||||
Wenn der `develop`-Branch genügend Features für ein Release enthält (oder ein festgelegter Release-Termin ansteht), wird vom `develop`-Branch ein `release`-Branch geforkt. Damit beginnt der neue Release-Zyklus. In diesem Branch sollten ab diesem Punkt keine neuen Features mehr hinzugefügt werden, sondern nur Bugfixes und ähnliche Release-orientierte Änderungen. Ist er zur Auslieferung bereit, wird der `release`-Branch in den `main`-Branch gemergt und mit einer Versionsnummer getaggt. Zusätzlich sollte er zurück in den `develop`-Branch gemergt werden, der sich seit Initiierung des Release weiterentwickelt haben könnte.
|
||||
|
||||
Werden Releases in dedizierten Branches vorbereitet, ist paralleles Arbeiten möglich: Eines eurer Teams kann dem aktuellen Release den letzten Schliff geben, während ein anderes Team sich weiter um die Features des nächsten Release kümmert. Außerdem lassen sich auf diese Weise klar abgegrenzte Entwicklungsphasen definieren. Wenn ihr euch entscheidet, in einer Woche an Version 4.0 zu arbeiten, kann die Struktur eures Repositorys diese Entscheidung abbilden.
|
||||
|
||||
Das Erstellen von `release` Branches ist ebenfalls ein unkomplizierter Branching-Vorgang. Wie die `feature` Branches basieren `release` branches auf dem `develop` Branch. Ein neuer `release` Branch kann mit den folgenden Methoden erstellt werden.
|
||||
|
||||
Ohne die Git-flow-Erweiterungen:
|
||||
|
||||
```
|
||||
git checkout develop
|
||||
git checkout -b release/0.1.0
|
||||
```
|
||||
|
||||
Mit der Git-flow-Erweiterung:
|
||||
|
||||
```
|
||||
$ git flow release start 0.1.0
|
||||
Switched to a new branch 'release/0.1.0'
|
||||
```
|
||||
|
||||
Ist der Release bereit zur Auslieferung, wird er in den `main`-Branch und den `develop`-Branch gemergt. Anschließend wird der `release`-Branch gelöscht. Es ist wichtig, zurück in den `develop`-Branch zu mergen, da der `release`-Branch eventuell kritische Updates enthalten kann, auf die neue Features Zugriff haben müssen. Wenn deine Organisation Code-Reviews nutzt, ist hier ein sehr guter Zeitpunkt für einen Pull-Request.
|
||||
|
||||
Du beendest einen `release` Branch mit den folgenden Methoden:
|
||||
|
||||
Ohne die Git-flow-Erweiterungen:
|
||||
|
||||
```
|
||||
git checkout main
|
||||
git merge release/0.1.0
|
||||
```
|
||||
|
||||
Mit der Git-flow-Erweiterung:
|
||||
|
||||
```
|
||||
git flow release finish '0.1.0'
|
||||
```
|
||||
|
||||
## Hotfix Branches
|
||||
|
||||

|
||||
|
||||
Maintenance- bzw. `hotfix`-Branches eignen sich für schnelle Patches von Produktions-Releases. `hotfix`-Branches sind `release`-Branches und `feature`-Branches sehr ähnlich, basieren jedoch auf dem `main`\- statt auf dem `develop`-Branch. Dies ist der einzige Branch, der direkt vom `main`-Branch geforkt werden sollte. Sobald der Fix abgeschlossen wurde, sollte er sowohl in den `main`\- als auch in den `develop`-Branch (oder den aktuellen `release`-Branch) gemergt werden; der `main`-Branch sollte außerdem mit einer aktualisierten Versionsnummer getaggt werden.
|
||||
|
||||
Durch eine solche dedizierte Entwicklungslinie für Bugfixes kann ein Team Probleme beheben, ohne den Rest des Workflows zu unterbrechen oder auf den nächsten Release-Zyklus warten zu müssen. Maintenance-Branches sind sozusagen Ad-hoc-`release`-Branches, die direkt mit dem `main`-Branch interagieren. Einen `hotfix`-Branch kannst du mithilfe folgender Methoden erstellen:
|
||||
|
||||
Ohne die Git-flow-Erweiterungen:
|
||||
|
||||
```
|
||||
git checkout main
|
||||
git checkout -b hotfix_branch
|
||||
```
|
||||
|
||||
Mit der Git-flow-Erweiterung:
|
||||
|
||||
```
|
||||
$ git flow hotfix start hotfix_branch
|
||||
```
|
||||
|
||||
Ähnlich wie beim Abschluss eines `release`-Branch wird ein `hotfix`-Branch sowohl in den `main`\- als auch in den `develop`-Branch gemergt.
|
||||
|
||||
```
|
||||
git checkout main
|
||||
git merge hotfix_branch
|
||||
git checkout develop
|
||||
git merge hotfix_branch
|
||||
git branch -D hotfix_branch
|
||||
```
|
||||
|
||||
```
|
||||
$ git flow hotfix finish hotfix_branch
|
||||
```
|
||||
|
||||
## Beispiel
|
||||
|
||||
Im Folgenden siehst du ein vollständiges Beispiel für einen Feature-Branch-Workflow. Nehmen wir an, wir haben ein Repository mit einem `main`-Branch eingerichtet.
|
||||
|
||||
```
|
||||
git checkout main
|
||||
git checkout -b develop
|
||||
git checkout -b feature_branch
|
||||
# work happens on feature branch
|
||||
git checkout develop
|
||||
git merge feature_branch
|
||||
git checkout main
|
||||
git merge develop
|
||||
git branch -d feature_branch
|
||||
```
|
||||
|
||||
Zusätzlich zum `feature` Workflow und `release` Workflow sieht ein `hotfix`-Beispiel folgendermaßen aus:
|
||||
|
||||
```
|
||||
git checkout main
|
||||
git checkout -b hotfix_branch
|
||||
# work is done commits are added to the hotfix_branch
|
||||
git checkout develop
|
||||
git merge hotfix_branch
|
||||
git checkout main
|
||||
git merge hotfix_branch
|
||||
```
|
||||
|
||||
## Zusammenfassung
|
||||
|
||||
Wir haben hier den Git-flow-Workflow besprochen. Git-flow ist eine der vielen Varianten des [Git-Workflows](https://www.atlassian.com/de/git/tutorials/comparing-workflows), die du dir mit deinem Team zunutze machen kannst.
|
||||
|
||||
Wichtige Punkte zum Git-flow:
|
||||
|
||||
- Der Workflow eignet sich hervorragend für release-basierte Software-Workflows.
|
||||
- Gitflow bietet einen eigenen Kanal für Hotfixes bis zur Produktion.
|
||||
|
||||
|
||||
Der allgemeine Git-flow-Ablauf sieht so aus:
|
||||
|
||||
1. Ein `develop`-Branch wird auf Basis des `main`-Branch erstellt.
|
||||
2. Ein `release` Branch wird vom `develop` Branch erstellt.
|
||||
3. Ein `feature` Branch wird ebenfalls vom `develop` Branch erstellt.
|
||||
4. Wenn ein `feature` fertig ist, wird es in den `develop`-Branch gemergt.
|
||||
5. Ist der `release`-Branch abgeschlossen, wird er in den `develop`-Branch und den `main`-Branch gemergt.
|
||||
6. Taucht ein Problem im `main`-Branch auf, wird ein `hotfix`-Branch auf Basis des `main`-Branch erstellt.
|
||||
7. Sobald der `hotfix` abgeschlossen ist, wird er in den `develop`-Branch und den `main`-Branch gemergt.
|
||||
|
||||
Fahre nun fort mit dem [Forking-Workflow](https://www.atlassian.com/de/git/tutorials/comparing-workflows/forking-workflow) oder sieh dir unseren [Workflow-Vergleich](https://www.atlassian.com/de/git/tutorials/comparing-workflows) an.
|
||||
@@ -1,202 +0,0 @@
|
||||
---
|
||||
title: "GitHub - shayne/wsl2-hacks: Useful snippets / tools for using WSL2 as a development environment"
|
||||
source: https://github.com/shayne/wsl2-hacks
|
||||
---
|
||||
|
||||
## [wsl2-hacks - Updated for Ubuntu 20.04 / 20.10](https://github.com/shayne/wsl2-hacks)
|
||||
|
||||
## Useful snippets / tools for using WSL2 as a development environment Updated based on issue #7 guidance from '@scotte' and '@JohnTasto'
|
||||
|
||||
**Auto-start/services** (`systemd` and `snap` support)
|
||||
|
||||
I've done a few methods that have had various levels of success. My goal was to make it feel seamless for my workflow and have commands work as expected. What's below is the current version of the setup I use. It allows me to use the MS Terminal as well as VSCode's Remote WSL plugin.
|
||||
|
||||
With this setup your shells will be able to run `systemctl` commands, have auto-starting services, as well as be able to run [snaps](https://tutorials.ubuntu.com/tutorial/basic-snap-usage).
|
||||
|
||||
1. Install deps
|
||||
|
||||
$ sudo apt update
|
||||
$ sudo apt install dbus policykit-1 daemonize
|
||||
|
||||
2. Create a fake-`bash`
|
||||
|
||||
This fake shell will intercept calls to `wsl.exe bash ...` and forward them to a real bash running in the right environment for `systemd`. If this sounds like a hack-- well, it is. However, I've tested various workflows and use this daily. That being said, your mileage may vary.
|
||||
|
||||
```
|
||||
$ sudo touch /usr/local/bin/wsl2hack
|
||||
$ sudo chmod +x /usr/local/bin/wsl2hack
|
||||
$ sudo editor /usr/local/bin/wsl2hack
|
||||
```
|
||||
|
||||
Add the following, be sure to replace `<YOURUSER>` with your WSL2 Linux username
|
||||
|
||||
#!/bin/bash
|
||||
# your WSL2 username
|
||||
UNAME="<YOURUSER>"
|
||||
|
||||
UUID=$(id -u "${UNAME}")
|
||||
UGID=$(id -g "${UNAME}")
|
||||
UHOME=$(getent passwd "${UNAME}" | cut -d: -f6)
|
||||
USHELL=$(getent passwd "${UNAME}" | cut -d: -f7)
|
||||
|
||||
if \[\[ -p /dev/stdin || "${BASH_ARGC}" > 0 && "${BASH_ARGV\[1\]}" != "-c" \]\]; then
|
||||
USHELL=/bin/bash
|
||||
fi
|
||||
|
||||
if \[\[ "${PWD}" = "/root" \]\]; then
|
||||
cd "${UHOME}"
|
||||
fi
|
||||
|
||||
# get pid of systemd
|
||||
SYSTEMD_PID=$(pgrep -xo systemd)
|
||||
|
||||
# if we're already in the systemd environment
|
||||
if \[\[ "${SYSTEMD_PID}" -eq "1" \]\]; then
|
||||
exec "${USHELL}" "$@"
|
||||
fi
|
||||
|
||||
if \[\[ -z ${SYSTEMD_PID} \]\]; then
|
||||
# start systemd
|
||||
/usr/bin/daemonize -l "${HOME}/.systemd.lock" /usr/bin/unshare -fp --mount-proc /lib/systemd/systemd --system-unit=basic.target
|
||||
|
||||
# wait for systemd to start
|
||||
retries=50
|
||||
while \[\[ -z ${SYSTEMD_PID} && $retries -ge 0 \]\]; do
|
||||
(( retries-- ))
|
||||
sleep .1
|
||||
SYSTEMD_PID=$(pgrep -xo systemd)
|
||||
done
|
||||
|
||||
if \[\[ $retries -lt 0 \]\]; then
|
||||
>&2 echo "Systemd timed out; aborting."
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
# export WSL variables
|
||||
export WINPATH="$(echo "$PATH"|grep -o ':/mnt/c.*$'|sed 's!^:!!')"
|
||||
RUNOPTS=""
|
||||
RUNOPTS="$RUNOPTS -l"
|
||||
RUNOPTS="$RUNOPTS -w WINPATH"
|
||||
RUNOPTS="$RUNOPTS -w WSL_INTEROP"
|
||||
RUNOPTS="$RUNOPTS -w WSL\_DISTRO\_NAME"
|
||||
|
||||
# enter systemd namespace
|
||||
exec /usr/bin/nsenter -t "${SYSTEMD_PID}" -m -p --wd="${PWD}" /sbin/runuser $RUNOPTS -s "${USHELL}" "${UNAME}" \-\- "${@}"
|
||||
|
||||
3. Set the fake-`bash` as our `root` user's shell
|
||||
|
||||
We need `root` level permission to get `systemd` setup and enter the environment. The way I went about solving this is to have WSL2 default to the `root` user and when `wsl.exe` is executed the fake-`bash` will do the right thing.
|
||||
|
||||
The next step in getting this working is to change the default shell for our `root` user.
|
||||
|
||||
Edit the `/etc/passwd` file:
|
||||
|
||||
`$ vipw`
|
||||
|
||||
`$ vipw -s`
|
||||
|
||||
Find the line starting with `root:`, it should be the first line. Add a line:
|
||||
|
||||
`rootwsl:x:0:0:root:/root:/usr/local/bin/wsl2hack`
|
||||
|
||||
*Never replace `/usr/bin/bash` as it is an actual binary in Ubuntu 20.04/20.10*
|
||||
|
||||
Save and close this file.
|
||||
|
||||
Make sure to update the primary passwd file *and* the shadow passwd file.
|
||||
|
||||
4. Exit out of / close the WSL2 shell
|
||||
|
||||
The next step is to shutdown WSL2 and to change the default user to `root`.
|
||||
|
||||
In a PowerShell terminal run:
|
||||
|
||||
```
|
||||
> wsl --shutdown
|
||||
> ubuntu2004.exe config --default-user root
|
||||
```
|
||||
|
||||
5. Re-open WSL2
|
||||
|
||||
Everything should be in place. Fire up WSL via the MS Terminal or just `wsl.exe`. You should be logged in as your normal user and `systemd` should be running
|
||||
|
||||
You can test by running the following in WSL2:
|
||||
|
||||
$ systemctl is-active dbus
|
||||
active
|
||||
|
||||
6. Create `/etc/rc.local` (optional)
|
||||
|
||||
If you want to run certain commands when the WSL2 VM starts up, this is a useful file that's automatically ran by systemd.
|
||||
|
||||
$ sudo touch /etc/rc.local
|
||||
$ sudo chmod +x /etc/rc.local
|
||||
$ sudo editor /etc/rc.local
|
||||
|
||||
Add the following:
|
||||
|
||||
#!/bin/sh -e
|
||||
|
||||
# your commands here...
|
||||
|
||||
exit 0
|
||||
|
||||
|
||||
`/etc/rc.local` is only run on "boot", so only when you first access WSL2 (or it's shutdown due to inactivity/no-processes). To test you can shutdown WSL via PowerShell/CMD `wsl --shutdown` then start it back up with `wsl`.
|
||||
|
||||
* * *
|
||||
|
||||
**Access localhost ports from Windows**
|
||||
|
||||
**NOTE: No longer needed as of build 18945**
|
||||
|
||||
Many development servers default to binding to `127.0.0.1` or `localhost`. It can be cumbersome and frustrating to get it to bind to `0.0.0.0` to make it accessible via Windows using the IP of the WSL2 VM.
|
||||
|
||||
> Take a look at https://github.com/shayne/go-wsl2-host to have `wsl.local` automatically resolve to the WSL2 VM
|
||||
|
||||
To make these dev servers / ports accessible you can run the following commands, or add them to the `/etc/rc.local` if you have `systemd` running:
|
||||
|
||||
# /etc/rc.local runs as root by default
|
||||
# if you run these yourself add 'sudo' to the beginning of each command
|
||||
|
||||
$ sysctl -w net.ipv4.conf.all.route_localnet=1
|
||||
$ iptables -t nat -I PREROUTING -p tcp -j DNAT --to-destination 127.0.0.1
|
||||
|
||||
* * *
|
||||
|
||||
**Increase `max_user_watches`**
|
||||
|
||||
If devtools are watching for file changes, the default is too low.
|
||||
|
||||
```
|
||||
# /etc/rc.local runs as root by default
|
||||
# if you run these yourself add 'sudo' to the beginning of each command
|
||||
|
||||
sysctl -w fs.inotify.max_user_watches=524288
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
**Open MS Terminal to home directory by default**
|
||||
|
||||
Open your MS Terminal configuration Ctrl+,
|
||||
|
||||
Find the `"commandLine":...` config for the WSL profile.
|
||||
|
||||
Change to something like:
|
||||
|
||||
"commandline": "wsl.exe ~ -d Ubuntu-18.04",
|
||||
|
||||
**Copy current IP of WSL2 into Windows clipboard** (optionally with port 3000 here):
|
||||
|
||||
```
|
||||
hostname -I | awk '{print $1}' | awk '{printf "%s:3000", $0}' | clip.exe
|
||||
```
|
||||
|
||||
Alternatively, put it in a file, for example `copy_ip.sh`, make it executable with `chmod +x copy_ip.sh` and you can get the IP any time with `./copy_ip.sh`:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
hostname -I | awk '{print $1}' | awk '{printf "%s:3000", $0}' | clip.exe
|
||||
```
|
||||
@@ -1,6 +0,0 @@
|
||||
---
|
||||
title: "GitHub - vishwanatharondekar/gitlab-cli: Create a merge request from command line in gitlab"
|
||||
source: https://github.com/vishwanatharondekar/gitlab-cli
|
||||
---
|
||||
|
||||
https://github.com/vishwanatharondekar/gitlab-cli
|
||||
@@ -1,159 +0,0 @@
|
||||
---
|
||||
title: GitHub Flow – Scott Chacon
|
||||
author: Scott Chacon
|
||||
tags:
|
||||
- IT/Development/Git
|
||||
- IT/Tools/GitHub
|
||||
- IT/Workflow
|
||||
source: https://scottchacon.com/2011/08/31/github-flow.html
|
||||
---
|
||||
|
||||
## Issues with git-flow
|
||||
|
||||
I travel all over the place teaching Git to people and nearly every class and workshop I’ve done recently has asked me what I think about [git-flow](http://nvie.com/posts/a-successful-git-branching-model/). I always answer that I think that it’s great - it has taken a system (Git) that has a million possible workflows and documented a well tested, flexible workflow that works for lots of developers in a fairly straightforward manner. It has become something of a standard so that developers can move between projects or companies and be familiar with this standardized workflow.
|
||||
|
||||
However, it does have its issues. I have heard a number of opinions from people along the lines of not liking that new feature branches are started off of `develop` rather than `master`, or the way it handles hotfixes, but those are fairly minor.
|
||||
|
||||
One of the bigger issues for me is that it’s more complicated than I think most developers and development teams actually require. It’s complicated enough that a big [helper script](https://github.com/nvie/gitflow) was developed to help enforce the flow. Though this is cool, the issue is that it cannot be enforced in a Git GUI, only on the command line, so the only people who have to learn the complex workflow really well, because they have to do all the steps manually, are the same people who aren’t comfortable with the system enough to use it from the command line. This can be a huge problem.
|
||||
|
||||
Both of these issues can be solved easily just by having a much more simplified process. At GitHub, we do not use git-flow. We use, and always have used, a much simpler Git workflow.
|
||||
|
||||
Its simplicity gives it a number of advantages. One is that it’s easy for people to understand, which means they can pick it up quickly and they rarely if ever mess it up or have to undo steps they did wrong. Another is that we don’t need a wrapper script to help enforce it or follow it, so using GUIs and such are not a problem.
|
||||
|
||||
## GitHub Flow
|
||||
|
||||
So, why don’t we use git-flow at GitHub? Well, the main issue is that we deploy all the time. The git-flow process is designed largely around the “release”. We don’t really have “releases” because we deploy to production every day - often several times a day. We can do so through our chat room robot, which is the same place our CI results are displayed. We try to make the process of testing and shipping as simple as possible so that every employee feels comfortable doing it.
|
||||
|
||||
There are a number of advantages to deploying so regularly. If you deploy every few hours, it’s almost impossible to introduce large numbers of big bugs. Little issues can be introduced, but then they can be fixed and redeployed very quickly. Normally you would have to do a ‘hotfix’ or something outside of the normal process, but it’s simply part of our normal process - there is no difference in the GitHub flow between a hotfix and a very small feature.
|
||||
|
||||
Another advantage of deploying all the time is the ability to quickly address issues of all kinds. We can respond to security issues that are brought to our attention or implement small but interesting feature requests incredibly quickly, yet we can use the exact same process to address those changes as we do to handle normal or even large feature development. It’s all the same process and it’s all very simple.
|
||||
|
||||
### How We Do It
|
||||
|
||||
So, what is GitHub Flow?
|
||||
|
||||
- Anything in the `master` branch is deployable
|
||||
- To work on something new, create a descriptively named branch off of `master` (ie: `new-oauth2-scopes`)
|
||||
- Commit to that branch locally and regularly push your work to the same named branch on the server
|
||||
- When you need feedback or help, or you think the branch is ready for merging, open a [pull request](http://help.github.com/send-pull-requests/)
|
||||
- After someone else has reviewed and signed off on the feature, you can merge it into master
|
||||
- Once it is merged and pushed to ‘master’, you can and *should* deploy immediately
|
||||
|
||||
That is the entire flow. It is very simple, very effective and works for fairly large teams - GitHub is 35 employees now, maybe 15-20 of whom work on the same project (github.com) at the same time. I think that most development teams - groups that work on the same logical code at the same time which could produce conflicts - are around this size or smaller. Especially those that are progressive enough to be doing rapid and consistent deployments.
|
||||
|
||||
So, let’s look at each of these steps in turn.
|
||||
|
||||
#### #1 - anything in the master branch is deployable
|
||||
|
||||
This is basically the only hard *rule* of the system. There is only one branch that has any specific and consistent meaning and we named it `master`. To us, this means that it has been deployed or at the worst will be deployed within hours. It’s incredibly rare that this gets rewound (the branch is moved back to an older commit to revert work) - if there is an issue, commits will be reverted or new commits will be introduced that fixes the issue, but the branch itself is almost never rolled back.
|
||||
|
||||
The `master` branch is stable and it is always, always safe to deploy from it or create new branches off of it. If you push something to master that is not tested or breaks the build, you break the social contract of the development team and you normally feel pretty bad about it. Every branch we push has tests run on it and reported into the chat room, so if you haven’t run them locally, you can simply push to a topic branch (even a branch with a single commit) on the server and wait for [Jenkins](http://jenkins-ci.org/) to tell you if it passes everything.
|
||||
|
||||
You could have a `deployed` branch that is updated only when you deploy, but we don’t do that. We simply expose the currently deployed SHA through the webapp itself and `curl` it if we need a comparison made.
|
||||
|
||||
#### #2 - create descriptive branches off of master
|
||||
|
||||
When you want to start work on anything, you create a descriptively named branch off of the stable `master` branch. Some examples in the GitHub codebase right now would be `user-content-cache-key`, `submodules-init-task` or `redis2-transition`. This has several advantages - one is that when you fetch, you can see the topics that everyone else has been working on. Another is that if you abandon a branch for a while and go back to it later, it’s fairly easy to remember what it was.
|
||||
|
||||
This is nice because when we go to the GitHub branch list page we can easily see what branches have been worked on recently and roughly how much work they have on them.
|
||||
|
||||

|
||||
|
||||
It’s almost like a list of upcoming features with current rough status. This page is awesome if you’re not using it - it only shows you branches that have unique work on them relative to your currently selected branch and it sorts them so that the ones most recently worked on are at the top. If I get really curious, I can click on the ‘Compare’ button to see what the actual unified diff and commit list is that is unique to that branch.
|
||||
|
||||
So, as of this writing, we have 44 branches in our repository with unmerged work in them, but I can also see that only about 9 or 10 of them have been pushed to in the last week.
|
||||
|
||||
#### #3 - push to named branches constantly
|
||||
|
||||
Another big difference from git-flow is that we push to named branches on the server constantly. Since the only thing we really have to worry about is `master` from a deployment standpoint, pushing to the server doesn’t mess anyone up or confuse things - everything that is not `master` is simply something being worked on.
|
||||
|
||||
It also make sure that our work is always backed up in case of laptop loss or hard drive failure. More importantly, it puts everyone in constant communication. A simple ‘git fetch’ will basically give you a TODO list of what every is currently working on.
|
||||
|
||||
```
|
||||
$ git fetch
|
||||
remote: Counting objects: 3032, done.
|
||||
remote: Compressing objects: 100% (947/947), done.
|
||||
remote: Total 2672 (delta 1993), reused 2328 (delta 1689)
|
||||
Receiving objects: 100% (2672/2672), 16.45 MiB | 1.04 MiB/s, done.
|
||||
Resolving deltas: 100% (1993/1993), completed with 213 local objects.
|
||||
From github.com:github/github
|
||||
* [new branch] charlock-linguist -> origin/charlock-linguist
|
||||
* [new branch] enterprise-non-config -> origin/enterprise-non-config
|
||||
* [new branch] fi-signup -> origin/fi-signup
|
||||
2647a42..4d6d2c2 git-http-server -> origin/git-http-server
|
||||
* [new branch] knyle-style-commits -> origin/knyle-style-commits
|
||||
157d2b0..d33e00d master -> origin/master
|
||||
* [new branch] menu-behavior-act-i -> origin/menu-behavior-act-i
|
||||
ea1c5e2..dfd315a no-inline-js-config -> origin/no-inline-js-config
|
||||
* [new branch] svg-tests -> origin/svg-tests
|
||||
87bb870..9da23f3 view-modes -> origin/view-modes
|
||||
* [new branch] wild-renaming -> origin/wild-renaming
|
||||
```
|
||||
|
||||
It also lets everyone see, by looking at the GitHub Branch List page, what everyone else is working on so they can inspect them and see if they want to help with something.
|
||||
|
||||
#### #4 - open a pull request at any time
|
||||
|
||||
GitHub has an amazing code review system called [Pull Requests](http://help.github.com/send-pull-requests/) that I fear not enough people know about. Many people use it for open source work - fork a project, update the project, send a pull request to the maintainer. However, it can also easily be used as an internal code review system, which is what we do.
|
||||
|
||||
Actually, we use it more as a branch conversation view more than a pull request. You can send pull requests from one branch to another in a single project (public or private) in GitHub, so you can use them to say “I need help or review on this” in addition to “Please merge this in”.
|
||||
|
||||

|
||||
|
||||
Here you can see Josh cc’ing Brian for review and Brian coming in with some advice on one of the lines of code. Further down we can see Josh acknowledging Brian’s concerns and pushing more code to address them.
|
||||
|
||||

|
||||
|
||||
Finally you can see that we’re still in the trial phase - this is not a deployment ready branch yet, we use the Pull Requests to review the code long before we actually want to merge it into `master` for deployment.
|
||||
|
||||
If you are stuck in the progress of your feature or branch and need help or advice, or if you are a developer and need a designer to review your work (or vice versa), or even if you have little or no code but some screenshot comps or general ideas, you open a pull request. You can cc people in the GitHub system by adding in a @username, so if you want the review or feedback of specific people, you simply cc them in the PR message (as you saw Josh do above).
|
||||
|
||||
This is cool because the Pull Request feature let’s you comment on individual lines in the unified diff, on single commits or on the pull request itself and pulls everything inline to a single conversation view. It also let you continue to push to the branch, so if someone comments that you forgot to do something or there is a bug in the code, you can fix it and push to the branch, GitHub will show the new commits in the conversation view and you can keep iterating on a branch like that.
|
||||
|
||||
If the branch has been open for too long and you feel it’s getting out of sync with the master branch, you can merge master into your topic branch and keep going. You can easily see in the pull request discussion or commit list when the branch was last brought up to date with the ‘master’.
|
||||
|
||||

|
||||
|
||||
When everything is really and truly done on the branch and you feel it’s ready to deploy, you can move on to the next step.
|
||||
|
||||
#### #5 - merge only after pull request review
|
||||
|
||||
We don’t simply do work directly on `master` or work on a topic branch and merge it in when we think it’s done - we try to get signoff from someone else in the company. This is generally a +1 or emoji or “:shipit:” comment, but we try to get someone else to look at it.
|
||||
|
||||

|
||||
|
||||
Once we get that, and the branch passes CI, we can merge it into master for deployment, which will automatically close the Pull Request when we push it.
|
||||
|
||||
#### #6 - deploy immediately after review
|
||||
|
||||
Finally, your work is done and merged into the `master` branch. This means that even if you don’t deploy it now, people will base new work off of it and the next deploy, which will likely happen in a few hours, will push it out. So since you really don’t want someone else to push something that you wrote that breaks things, people tend to make sure that it really is stable when it’s merged and people also tend to push their own changes.
|
||||
|
||||
Our campfire bot, hubot, can do deployments for any of the employees, so a simple:
|
||||
|
||||
```
|
||||
hubot depoy github to production
|
||||
```
|
||||
|
||||
will deploy the code and zero-downtime restart all the necessary processes. You can see how common this is at GitHub:
|
||||
|
||||

|
||||
|
||||
You can see 6 different people (including a support guy and a designer) deploying about 24 times in one day.
|
||||
|
||||
I have done this for branches with one commit containing a one line change. The process is simple, straightforward, scalable and powerful. You can do it with feature branches with 50 commits on them that took 2 weeks, or 1 commit that took 10 minutes. It is such a simple and frictionless process that you are not annoyed that you have to do it even for 1 commit, which means people rarely try to skip or bypass the process unless the change is so small or insignificant that it just doesn’t matter.
|
||||
|
||||
This is an incredibly simple and powerful process. I think most people would agree that GitHub has a very stable platform, that issues are addressed quickly if they ever come up at all, and that new features are introduced at a rapid pace. There is no compromise of quality or stability so that we can get more speed or simplicity or less process.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Git itself is fairly complex to understand, making the workflow that you use with it more complex than necessary is simply adding more mental overhead to everybody’s day. I would always advocate using the simplest possible system that will work for your team and doing so until it doesn’t work anymore and then adding complexity only as absolutely needed.
|
||||
|
||||
For teams that have to do formal releases on a longer term interval (a few weeks to a few months between releases), and be able to do hot-fixes and maintenance branches and other things that arise from shipping so infrequently, [git-flow](http://nvie.com/posts/a-successful-git-branching-model/) makes sense and I would highly advocate it’s use.
|
||||
|
||||
For teams that have set up a culture of shipping, who push to production every day, who are constantly testing and deploying, I would advocate picking something simpler like GitHub Flow.
|
||||
|
||||
### Discussion, links, and tweets
|
||||
|
||||
[](https://twitter.com/chacon)
|
||||
|
||||
I'm a developer at GitHub. [Follow me on Twitter](https://twitter.com/chacon); you'll enjoy my tweets. I take care to carefully craft each one. Or at least aim to make you giggle. Or offended. One of those two— I haven't decided which yet.
|
||||
@@ -1,26 +0,0 @@
|
||||
---
|
||||
title: Gitlab get repo urls
|
||||
tags:
|
||||
- IT/Development/REST
|
||||
- IT/Tools/Gitlab
|
||||
- IT/Tools/Shell
|
||||
---
|
||||
|
||||
```bash
|
||||
curl --header "Private-Token: bFcsw1ebNhoFgKysksU1" https://gitlab.thpeetz.de/api/v4/projects/ | jq '.[] | { id: .id, url: .http_url_to_repo }'
|
||||
curl --header "Private-Token: aJVkcL2a6dDSVhJYzqEn" https://gitlab.thpeetz.de/api/v4/projects\?per_page=100 | jq '.[] | .http_url_to_repo'
|
||||
|
||||
for projectid in $(curl --header "Private-Token: aJVkcL2a6dDSVhJYzqEn" https://gitlab.thpeetz.de/api/v4/projects\?per_page\=100 | jq '.[] | .id')
|
||||
do curl --header "Private-Token: aJVkcL2a6dDSVhJYzqEn" https://gitlab.thpeetz.de/api/v4/projects/$projectid/hooks | jq
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
## Links
|
||||
|
||||
- https://docs.gitlab.com/ee/api/index.html
|
||||
- https://docs.gitlab.com/ee/api/projects.html
|
||||
- https://docs.gitlab.com/ee/user/project/settings/project\_access\_tokens.html
|
||||
- https://docs.gitlab.com/ee/api/remote_mirrors.html
|
||||
|
||||
|
||||
@@ -1,52 +0,0 @@
|
||||
---
|
||||
title: Gmail · Wiki · Mutt Project / mutt
|
||||
source: https://gitlab.com/muttmua/mutt/wikis/UseCases/Gmail
|
||||
---
|
||||
|
||||
[Gmail](https://gitlab.com/muttmua/mutt/wikis/UseCases/Gmail)
|
||||
|
||||
## <a id="user-content-userstorygmailoverimap"></a>[](#userstorygmailoverimap)!UserStory/GMailOverIMAP
|
||||
|
||||
This is a quick guide to setting up mutt to work with GMail's IMAP interface.
|
||||
|
||||
### <a id="user-content-essentials-configuration-options"></a>[](#essentials-configuration-options)Essentials: configuration options
|
||||
|
||||
set imap_user = 'yourusername@gmail.com'
|
||||
set imap_pass = 'yourpassword'
|
||||
|
||||
set folder = imaps://imap.gmail.com/
|
||||
set spoolfile = +INBOX
|
||||
set record = "+[Gmail]/Sent Mail"
|
||||
set postponed = "+[Gmail]/Drafts"
|
||||
|
||||
If you want to use GMail SMTP server, set record to an empty string as it handles saving the sent mail anyway.
|
||||
|
||||
set smtp_url = 'smtps://yourusername@smtp.gmail.com'
|
||||
set smtp_pass = 'yourpassword'
|
||||
set record=""
|
||||
|
||||
You can also set the mbox:
|
||||
|
||||
set mbox="imaps://imap.gmail.com/[Gmail]/All Mail"
|
||||
|
||||
...which means that when you exit mutt, it will prompt you to archive your read messages.
|
||||
|
||||
If you are using the [trash_folder patch](http://cedricduval.free.fr/mutt/patches/#trash)
|
||||
|
||||
set trash="imaps://imap.gmail.com/[Gmail]/Trash"
|
||||
|
||||
### <a id="user-content-navigation-quirks"></a>[](#navigation-quirks)Navigation quirks
|
||||
|
||||
You can change folders using the change-folder command, but you'll need to hit **<space>** to view the files instead of just changing folders.
|
||||
|
||||
### <a id="user-content-web-keyboard-shortcut-macros"></a>[](#web-keyboard-shortcut-macros)Web keyboard shortcut macros
|
||||
|
||||
bind editor <space> noop
|
||||
macro index,pager y "<save-message>=[Gmail]/All Mail<enter><enter>" "Archive"
|
||||
macro index,pager d "<save-message>=[Gmail]/Trash<enter><enter>" "Trash"
|
||||
macro index gi "<change-folder>=INBOX<enter>" "Go to inbox"
|
||||
macro index ga "<change-folder>=[Gmail]/All Mail<enter>" "Go to all mail"
|
||||
macro index gs "<change-folder>=[Gmail]/Starred<enter>" "Go to starred messages"
|
||||
macro index gd "<change-folder>=[Gmail]/Drafts<enter>" "Go to drafts"
|
||||
|
||||
You need the "noop" `bind` so that the line editor accepts IMAP folders with spaces in their names. The gi, ga, gs and gd shortcuts help get around the "navigation quirks" mentioned above too.
|
||||
@@ -1,46 +0,0 @@
|
||||
---
|
||||
title: Gradle Goodness
|
||||
source: https://blog.mrhaki.com/2022/12/gradle-goodness-set-project-version-in.html
|
||||
tags:
|
||||
- IT/Development/Gradle
|
||||
---
|
||||
### [Gradle Goodness: Set Project Version In Version Catalog](https://blog.mrhaki.com/2022/12/gradle-goodness-set-project-version-in.html)
|
||||
|
||||
The version catalog in Gradle is very useful to have one place in our project to define our project and plugin dependencies with their versions. But we can also use it to define our project version and then refer to that version from the version catalog in our build script file. That way the version catalog is our one place to look for everything related to a version. In the version catalog we have a `versions` section and there we can define a key with a version value. The name of the key could be our project or application name for example. We can use type safe accessors generated by Gradle in our build script to refer to that version.
|
||||
|
||||
In the following example build script written with Kotlin we see how we can refer to the version from the version catalog:
|
||||
|
||||
```kotlin
|
||||
description = "Sample project for Gradle version catalog"
|
||||
version = libs.versions.app.version.get()
|
||||
tasks {
|
||||
register("projectVersion") {
|
||||
doLast {
|
||||
println("Project version: " + version)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
And the version catalog is defined in the following file:
|
||||
|
||||
```properties
|
||||
[versions]
|
||||
app-version = "2.0.1"
|
||||
```
|
||||
|
||||
When we run the task `projectVersion` we see our project version in the output:
|
||||
|
||||
```shell
|
||||
$ gradle projectVersion
|
||||
Task :projectVersion
|
||||
|
||||
Project version: 2.0.1
|
||||
|
||||
BUILD SUCCESSFUL in 831ms
|
||||
|
||||
1 actionable task: 1 executed
|
||||
$
|
||||
```
|
||||
|
||||
Written with Gradle 7.6.
|
||||
@@ -1,44 +0,0 @@
|
||||
---
|
||||
title: Gradle Goodness
|
||||
source: https://blog.jdriven.com/2021/02/gradle-goodness-setting-plugin-version-from-property-in-plugins-section/
|
||||
tags:
|
||||
- IT/Development/Gradle
|
||||
---
|
||||
|
||||
The `plugins` section in our Gradle build files can be used to define Gradle plugins we want to use. Gradle can optimize the build process if we use `plugins {…}` in our build scripts, so it is a good idea to use it. But there is a restriction if we want to define a version for a plugin inside the `plugins` section: the version is a fixed string value. We cannot use a property to set the version inside the `plugins` section. We can overcome this by using a `pluginsManagement` section in a settings file in the root of our project. Inside the `pluginsManagement` section we can use properties to set the version of a plugin we want to use. Once it is defined inside `pluginsManagement` we can use it in our project build script without having the specify the version. This allows us to have one place where all plugin versions are defined. We can even use a `gradle.properties` file in our project with all plugin versions and use that in `pluginsManagement`.
|
||||
|
||||
In the following settings file we use `pluginsManagement` to use a project property `springBootPluginVersion` to set the version to use for the Spring Boot Gradle plugin.
|
||||
|
||||
```kotlin
|
||||
// File: settings.gradle.kts
|
||||
pluginManagement {
|
||||
val springBootPluginVersion: String by settings // use project property with version
|
||||
plugins {
|
||||
id("org.springframework.boot") version "${springBootPluginVersion}"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Next in our project build file we can simply reference the id of the Spring Boot Gradle plugin without the version. The version is already resolved in our settings file:
|
||||
|
||||
```kotlin
|
||||
// File: build.gradle.kts
|
||||
plugins {
|
||||
java
|
||||
application
|
||||
id("org.springframework.boot") // no version here: it is set in settings.gradle.kts
|
||||
}
|
||||
|
||||
application {
|
||||
mainClass.set("com.mrhaki.sample.App")
|
||||
}
|
||||
```
|
||||
|
||||
Finally we can add a `gradle.properties` file with the project property (or specify it on the command line or environment variable):
|
||||
|
||||
```properties
|
||||
# File: gradle.properties
|
||||
springBootPluginVersion=2.4.2
|
||||
```
|
||||
|
||||
Written with Gradle 6.8.2.
|
||||
@@ -1,89 +0,0 @@
|
||||
---
|
||||
title: Gradle Goodness - Shared Configuration With Conventions Plugin
|
||||
source: https://blog.jdriven.com/2021/02/gradle-goodness-shared-configuration-with-conventions-plugin/
|
||||
tags:
|
||||
- IT/Development/Gradle
|
||||
- IT/Development/Kotlin
|
||||
- IT/Development/Groovy
|
||||
---
|
||||
|
||||
When we have a multi-module project in Gradle we sometimes want to have dependencies, task configuration and other settings shared between the multiple modules. We can use the `subprojects` or `allprojects` blocks, but the downside is that it is not clear from the build script of the subproject where the configuration comes from. We must remember it is set from another build script, but there is no reference in the subproject to that connection. It is better to use a plugin with shared configuration and use that plugin in the subprojects. We call this a conventions plugin. This way it is explicitly visible in a subproject that the shared settings come from a plugin. Also it allows Gradle to optimize the build configuration.
|
||||
|
||||
The easiest way to implement the shared configuration in a plugin is using a so-called precompiled script plugin. This type of plugin can be written as a build script using the Groovy or Kotlin DSL with a filename ending with `.gradle` or `.gradle.kts`. The name of the plugin is the first part of the filename before `.gradle` or `.gradle.kts`. In our subproject we can add the plugin to our build script to apply the shared configuration. For a multi-module project we can create such a plugin in the `buildSrc` directory. For a Groovy plugin we place the file in `src/main/groovy`, for a Kotlin plugin we place it in `src/main/kotlin`.
|
||||
|
||||
In the following example we write a script plugin using the Kotlin DSL to apply the `java-library` plugin to a project, set some common dependencies used by all projects, configure the `Test` tasks and set the Java toolchain. First we create a `build.gradle.kts` file in the `buildSrc` directory in the root of our multi-module project and apply the `kotlin-dsl` plugin:
|
||||
|
||||
```kotlin
|
||||
// File: buildSrc/build.gradle.kts
|
||||
plugins {
|
||||
`kotlin-dsl`
|
||||
}
|
||||
|
||||
repositories.mavenCentral()
|
||||
```
|
||||
|
||||
Next we create the conventions plugin with our shared configuration:
|
||||
|
||||
```kotlin
|
||||
// File: buildSrc/src/main/kotlin/java-project-conventions.gradle.kts
|
||||
plugins {
|
||||
`java-library`
|
||||
}
|
||||
|
||||
group = "mrhaki.sample"
|
||||
version = "1.0"
|
||||
|
||||
repositories {
|
||||
mavenCentral()
|
||||
}
|
||||
|
||||
dependencies {
|
||||
val log4jVersion: String by extra("2.14.0")
|
||||
val junitVersion: String by extra("5.3.1")
|
||||
val assertjVersion: String by extra("3.19.0")
|
||||
|
||||
// Logging
|
||||
implementation("org.apache.logging.log4j:log4j-api:${log4jVersion}")
|
||||
implementation("org.apache.logging.log4j:log4j-core:${log4jVersion}")
|
||||
|
||||
// Testing
|
||||
testImplementation("org.junit.jupiter:junit-jupiter-api:${junitVersion}")
|
||||
testRuntimeOnly("org.junit.jupiter:junit-jupiter-engine:${junitVersion}")
|
||||
testImplementation("org.assertj:assertj-core:${assertjVersion}")
|
||||
}
|
||||
|
||||
java {
|
||||
toolchain {
|
||||
languageVersion.set(JavaLanguageVersion.of(15))
|
||||
}
|
||||
}
|
||||
|
||||
tasks.withType<Test> {
|
||||
useJUnitPlatform()
|
||||
}
|
||||
```
|
||||
|
||||
The id of our new plugin is `java-project-conventions` and we can use it in our build script for a subproject as:
|
||||
|
||||
```kotlin
|
||||
// File: rest-api/build.gradle.kts
|
||||
plugins {
|
||||
id("java-project-conventions") // apply shared config
|
||||
application // apply the Gradle application plugin
|
||||
}
|
||||
|
||||
dependencies {
|
||||
val vertxVersion: String by extra("4.0.2")
|
||||
|
||||
implementation(project(":domain")) // project dependency
|
||||
implementation("io.vertx:vertx-core:${vertxVersion}")
|
||||
}
|
||||
|
||||
application {
|
||||
mainClass.set("com.mrhaki.web.Api")
|
||||
}
|
||||
```
|
||||
|
||||
The `rest-api` project will have all the configuration and tasks from `java-library` plugin as configured in the `java-project-conventions` plugin, so we can build it as a Java project.
|
||||
|
||||
Written with Gradle 6.8.2.
|
||||
@@ -1,143 +0,0 @@
|
||||
---
|
||||
title: Groovy - ConfigSlurper
|
||||
tags:
|
||||
- IT/Development/Groovy
|
||||
---
|
||||
|
||||
# ConfigSlurper
|
||||
|
||||
ConfigSlurper is a utility class within Groovy for writing properties file like scripts for performing configuration. Unlike regular Java properties files ConfigSlurper scripts support native Java types and are structured like a tree.
|
||||
|
||||
Below is an example of how you could configure Log4j with a ConfigSlurper script:
|
||||
|
||||
```groovy
|
||||
log4j.appender.stdout = "org.apache.log4j.ConsoleAppender"
|
||||
log4j.appender."stdout.layout"="org.apache.log4j.PatternLayout"
|
||||
log4j.rootLogger="error,stdout"
|
||||
log4j.logger.org.springframework="info,stdout"
|
||||
log4j.additivity.org.springframework=false
|
||||
```
|
||||
|
||||
To load this into a readable config you can do:
|
||||
|
||||
```groovy
|
||||
def config = new ConfigSlurper().parse(new File('myconfig.groovy').toURL())
|
||||
|
||||
assert "info,stdout" == config.log4j.logger.org.springframework
|
||||
assert false == config.log4j.additivity.org.springframework
|
||||
```
|
||||
|
||||
As you can see from the example above you can navigate the config using dot notation and the return values are Java types like strings and booleans.
|
||||
|
||||
You can also use scoping in config scripts to avoid repeating yourself. So the above config could also be written as:
|
||||
|
||||
```groovy
|
||||
log4j {
|
||||
appender.stdout = "org.apache.log4j.ConsoleAppender"
|
||||
appender."stdout.layout"="org.apache.log4j.PatternLayout"
|
||||
rootLogger="error,stdout"
|
||||
logger {
|
||||
org.springframework="info,stdout"
|
||||
}
|
||||
additivity {
|
||||
org.springframework=false
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Converting to and from Java properties files
|
||||
|
||||
You can convert ConfigSlurper configs to and from Java properties files. For example:
|
||||
|
||||
```groovy
|
||||
java.util.Properties props = // load from somewhere
|
||||
|
||||
def config = new ConfigSlurper().parse(props)
|
||||
|
||||
props = config.toProperties()
|
||||
```
|
||||
|
||||
## Merging configurations
|
||||
|
||||
You can merge config objects so if you have multiple config files and want to create one central config object you can do:
|
||||
|
||||
```groovy
|
||||
def config1 = new ConfigSlurper().parse(..)
|
||||
def config2 = new ConfigSlurper().parse(..)
|
||||
|
||||
config1 = config1.merge(config2)
|
||||
```
|
||||
|
||||
## Serializing a configuration to disk
|
||||
|
||||
You can serialize a config object to disk. Each config object implements the groovy.lang.Writable interface that allows you to write out the config to any java.io.Writer:
|
||||
|
||||
```groovy
|
||||
def config = new ConfigSlurper().parse(..)
|
||||
|
||||
new File("..").withWriter { writer ->
|
||||
config.writeTo(writer)
|
||||
}
|
||||
```
|
||||
|
||||
## Special "environments" Configuration
|
||||
|
||||
The ConfigSlurper class has a special constructor other than the default constructor that takes an "environment" parameter. This special constructor works in concert with a property setting called environments. This allows a default setting to exist in the property file that can be superceded by a setting in the appropriate environments closure. This allows multiple related configurations to be stored in the same file.
|
||||
|
||||
Given this groovy property file:
|
||||
**Sample.groovy**
|
||||
|
||||
```groovy
|
||||
sample {
|
||||
foo = "default_foo"
|
||||
bar = "default_bar"
|
||||
}
|
||||
|
||||
environments {
|
||||
development {
|
||||
sample {
|
||||
foo = "dev_foo"
|
||||
}
|
||||
}
|
||||
test {
|
||||
sample {
|
||||
bar = "test_bar"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Here is the demo code that exercises this configuration:
|
||||
|
||||
```groovy
|
||||
def config = new ConfigSlurper("development").parse(new File('Sample.groovy').toURL())
|
||||
|
||||
assert config.sample.foo == "dev_foo"
|
||||
assert config.sample.bar == "default_bar"
|
||||
|
||||
config = new ConfigSlurper("test").parse(new File('Sample.groovy').toURL())
|
||||
|
||||
assert config.sample.foo == "default_foo"
|
||||
assert config.sample.bar == "test_bar"
|
||||
```
|
||||
|
||||
Note: the environments closure is not directly parsable. Without using the special environment constructor the closure is ignored.
|
||||
|
||||
The value of the environment constructor is also available in the configuration file, allowing you to build the configuration like this:
|
||||
|
||||
```groovy
|
||||
switch (environment) {
|
||||
case 'development':
|
||||
baseUrl = "devServer/"
|
||||
break
|
||||
case 'test':
|
||||
baseUrl = "testServer/"
|
||||
break
|
||||
default:
|
||||
baseUrl = "localhost/"
|
||||
}
|
||||
```
|
||||
|
||||
# Further information
|
||||
|
||||
[Using Groovy ConfigSlurper to Configure Spring Beans](http://jroller.com/page/0xcafebabe?entry=using_groovy_configslurper_to_configure)
|
||||
@@ -1,118 +0,0 @@
|
||||
---
|
||||
title: Groovy - Reading XML using Groovy's XmlSlurper
|
||||
tags:
|
||||
- IT/Development/Groovy
|
||||
---
|
||||
|
||||
This example assumes the following class is already on your CLASSPATH:
|
||||
|
||||
XmlExamples.groovy
|
||||
```groovy
|
||||
class XmlExamples {
|
||||
static def CAR_RECORDS = '''
|
||||
<records>
|
||||
<car name='HSV Maloo' make='Holden' year='2006'>
|
||||
<country>Australia</country>
|
||||
<record type='speed'>Production Pickup Truck with speed of 271kph</record>
|
||||
</car>
|
||||
<car name='P50' make='Peel' year='1962'>
|
||||
<country>Isle of Man</country>
|
||||
<record type='size'>Smallest Street-Legal Car at 99cm wide and 59 kg in weight</record>
|
||||
</car>
|
||||
<car name='Royale' make='Bugatti' year='1931'>
|
||||
<country>France</country>
|
||||
<record type='price'>Most Valuable Car at $15 million</record>
|
||||
</car>
|
||||
</records>
|
||||
'''
|
||||
}
|
||||
```
|
||||
Here is an example of using XmlSlurper:
|
||||
```groovy
|
||||
def records = new XmlSlurper().parseText(XmlExamples.CAR_RECORDS)
|
||||
def allRecords = records.car
|
||||
assert 3 == allRecords.size()
|
||||
def allNodes = records.depthFirst().collect{ it }
|
||||
assert 10 == allNodes.size()
|
||||
def firstRecord = records.car[0]
|
||||
assert 'car' == firstRecord.name()
|
||||
assert 'Holden' == firstRecord.@make.text()
|
||||
assert 'Australia' == firstRecord.country.text()
|
||||
def carsWith_e_InMake = records.car.findAll{ it.@make.text().contains('e') }
|
||||
assert carsWith_e_InMake.size() == 2// alternative way to find cars with 'e' in makeassert 2 == records.car.findAll{ it.@make =~ '.*e.*' }.size()
|
||||
// makes of cars that have an 's' followed by an 'a' in the countryassert ['Holden', 'Peel'] == records.car.findAll{ it.country =~ '.*s.*a.*' }.@make.collect{ it.text() }
|
||||
def expectedRecordTypes = ['speed', 'size', 'price']
|
||||
assert expectedRecordTypes == records.depthFirst().grep{ it.@type != '' }.'@type'*.text()
|
||||
assert expectedRecordTypes == records.'**'.grep{ it.@type != '' }.'@type'*.text()
|
||||
def countryOne = records.car[1].country
|
||||
assert 'Peel' == countryOne.parent().@make.text()
|
||||
assert 'Peel' == countryOne.'..'.@make.text()
|
||||
// names of cars with records sorted by yeardef sortedNames = records.car.list().sort{ it.@year.toInteger() }.'@name'*.text()
|
||||
assert ['Royale', 'P50', 'HSV Maloo'] == sortedNames
|
||||
assert ['Australia', 'Isle of Man'] == records.'**'.grep{ it.@type =~ 's.*' }*.parent().country*.text()
|
||||
assert 'co-re-co-re-co-re' == records.car.children().collect{ it.name()[0..1] }.join('-')
|
||||
assert 'co-re-co-re-co-re' == records.car.'*'.collect{ it.name()[0..1] }.join('-')
|
||||
```
|
||||
Notes:
|
||||
|
||||
- If your elements contain characters such as dashes, you can enclose the element name in double quotes. Meaning for:
|
||||
|
||||
```xml
|
||||
<foo>
|
||||
<foo-bar>test</foo-bar>
|
||||
</foo>
|
||||
```
|
||||
|
||||
You do the following:
|
||||
|
||||
```groovy
|
||||
def foo = new XmlSlurper().parseText(FOO_XML)
|
||||
assert "test" == foo."foo-bar".text()
|
||||
```
|
||||
|
||||
You can also parse XML documents using namespaces:
|
||||
|
||||
```groovy
|
||||
def wsdl = '''
|
||||
<definitions name="AgencyManagementService"
|
||||
xmlns:ns1="http://www.example.org/NS1"
|
||||
xmlns:ns2="http://www.example.org/NS2">
|
||||
<ns1:message name="SomeRequest">
|
||||
<ns1:part name="parameters" element="SomeReq" />
|
||||
</ns1:message>
|
||||
<ns2:message name="SomeRequest">
|
||||
<ns2:part name="parameters" element="SomeReq" />
|
||||
</ns2:message>
|
||||
</definitions>
|
||||
'''
|
||||
|
||||
def xml = new XmlSlurper().parseText(wsdl).declareNamespace(ns1: 'http://www.example.org/NS1', ns2: 'http://www.example.org/NS2')
|
||||
println xml.'ns1:message'.'ns1:part'.size()
|
||||
println xml.'ns2:message'.'ns2:part'.size()
|
||||
```
|
||||
|
||||
XmlSlurper has a declareNamespace method which takes a Map of prefix to URI mappings. You declare the namespaces and just use the prefixes in the GPath expression.
|
||||
|
||||
```groovy
|
||||
new XmlSlurper().parseText(blog).declareNamespace(dc: "http://purl.org/dc/elements/1.1/").channel.item.findAll { item ->
|
||||
d.any{entry -> item."dc:date".text() =~ entry.key} && a.any{entry -> item.tags.text() =~ entry
|
||||
}
|
||||
```
|
||||
|
||||
Some remarks:
|
||||
|
||||
- name or "*:name" matches an element named "name" irrespective of the namespace it's in (i.e. this is the default mode of operation)
|
||||
- ":name" matches an element named "name" only id the element is not in a namespace
|
||||
- "prefix:name" matches an element names "name" only if it is in the namespace identified by the prefix "prefix" (and the prefix to namespace mapping was defined by a previous call to declareNamespace)
|
||||
|
||||
You can generate namespaced elements in StreamingMarkupBuilder very easily:
|
||||
|
||||
```groovy
|
||||
System.out << new StreamingMarkupBuilder().bind {
|
||||
mkp.declareNamespace(dc: "http://purl.org/dc/elements/1.1/")
|
||||
|
||||
root {
|
||||
dc.date()
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -1,96 +0,0 @@
|
||||
---
|
||||
title: Groovy - Updating XML with XmlSlurper
|
||||
tags:
|
||||
- IT/Development/Groovy
|
||||
---
|
||||
|
||||
# Updating XML with XmlSlurper
|
||||
|
||||
Here is an example of updating XML using XmlSlurper:
|
||||
|
||||
```groovy
|
||||
// require(groupId:'xmlunit', artifactId:'xmlunit', version:'1.1')import org.custommonkey.xmlunit.Diff
|
||||
import org.custommonkey.xmlunit.XMLUnit
|
||||
import groovy.xml.StreamingMarkupBuilder
|
||||
|
||||
def input = '''
|
||||
<shopping>
|
||||
<category type="groceries">
|
||||
<item>Chocolate</item>
|
||||
<item>Coffee</item>
|
||||
</category>
|
||||
<category type="supplies">
|
||||
<item>Paper</item>
|
||||
<item quantity="4">Pens</item>
|
||||
</category>
|
||||
<category type="present">
|
||||
<item when="Aug 10">Kathryn's Birthday</item>
|
||||
</category>
|
||||
</shopping>
|
||||
'''
|
||||
|
||||
def expectedResult = '''
|
||||
<shopping>
|
||||
<category type="groceries">
|
||||
</category>
|
||||
<category type="supplies">
|
||||
<item>Iced Tea</item>
|
||||
<item quantity="6" when="Urgent">Pens</item>
|
||||
</category>
|
||||
<category type="present">
|
||||
<item>Mum's Birthday</item>
|
||||
<item when="Oct 15">Monica's Birthday</item>
|
||||
</category>
|
||||
<category>
|
||||
<item>Wine</item>
|
||||
</category>
|
||||
</shopping>
|
||||
'''
|
||||
|
||||
def root = new XmlSlurper().parseText(input)
|
||||
|
||||
// modify groceries: quality items pleasedef groceries = root.category.find{ it.@type == 'groceries' }
|
||||
(0..<groceries.item.size()).each {
|
||||
groceries.item[it] = 'Luxury ' + groceries.item[it]
|
||||
}
|
||||
|
||||
// modify supplies: we need extra pensdef pens = root.category.find{ it.@type == 'supplies' }.item.findAll{ it.text() == 'Pens' }
|
||||
pens.each { p ->
|
||||
p.@quantity = (p.@quantity.toInteger() + 2).toString()
|
||||
p.@when = 'Urgent'
|
||||
}
|
||||
|
||||
// modify presents: August has come and gonedef presents = root.category.find{ it.@type == 'present' }
|
||||
presents.replaceNode{ node ->
|
||||
category(type:'present'){
|
||||
item("Mum's Birthday")
|
||||
item("Monica's Birthday", when:'Oct 15')
|
||||
}
|
||||
}
|
||||
|
||||
// append child at the end of shopping
|
||||
root.appendNode {
|
||||
category {
|
||||
item("Wine")
|
||||
}
|
||||
}
|
||||
|
||||
// delete all occurrences of a specific element inside a specific parent
|
||||
root.category[0].item.replaceNode {}
|
||||
|
||||
// update the text of a specific element
|
||||
root.category[1].item[0] = "Iced Tea"
|
||||
|
||||
// check the whole document using XmlUnitdef outputBuilder = new StreamingMarkupBuilder()
|
||||
String result = outputBuilder.bind{ mkp.yield root }
|
||||
|
||||
XMLUnit.setIgnoreWhitespace(true)
|
||||
def xmlDiff = new Diff(result, expectedResult)
|
||||
assert xmlDiff.similar()
|
||||
|
||||
// check the when attributes (can't do before now due to delayed setting)def resultRoot = new XmlSlurper().parseText(result)
|
||||
def removeNulls(list) { list.grep{it} }
|
||||
assert removeNulls(resultRoot.'*'.item.@when) == [ "Urgent", "Oct 15" ]
|
||||
```
|
||||
|
||||
|
||||
@@ -1,116 +0,0 @@
|
||||
---
|
||||
title: Groovy - Using Enums
|
||||
tags:
|
||||
- IT/Development/Groovy
|
||||
---
|
||||
|
||||
Some examples (inspired by the Java Enum Tutorial):
|
||||
|
||||
```groovy
|
||||
enum Day {
|
||||
SUNDAY, MONDAY, TUESDAY, WEDNESDAY,
|
||||
THURSDAY, FRIDAY, SATURDAY
|
||||
}
|
||||
|
||||
def tellItLikeItIs(Day day) {
|
||||
switch (day) {
|
||||
case Day.MONDAY:
|
||||
println "Mondays are bad."
|
||||
break
|
||||
case Day.FRIDAY:
|
||||
println "Fridays are better."
|
||||
break
|
||||
case Day.SATURDAY:
|
||||
case Day.SUNDAY:
|
||||
println "Weekends are best."
|
||||
break
|
||||
default:
|
||||
println "Midweek days are so-so."
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
tellItLikeItIs(Day.MONDAY) // => Mondays are bad.
|
||||
tellItLikeItIs(Day.WEDNESDAY) // => Midweek days are so-so.
|
||||
tellItLikeItIs(Day.FRIDAY) // => Fridays are better.
|
||||
tellItLikeItIs(Day.SATURDAY) // => Weekends are best.
|
||||
```
|
||||
|
||||
Or with a bit of refactoring, you could write the switch like this:
|
||||
|
||||
```groovy
|
||||
def today = Day.SATURDAY
|
||||
switch (today) {
|
||||
// Saturday or Sunday
|
||||
case [ Day.SATURDAY, Day.SUNDAY ]:
|
||||
println "Weekends are cool"
|
||||
break
|
||||
// a day between Monday and Friday
|
||||
case Day.MONDAY..Day.FRIDAY:
|
||||
println "Boring work day"
|
||||
break
|
||||
default:
|
||||
println "Are you sure this is a valid day?"
|
||||
}
|
||||
```
|
||||
|
||||
Here is a coin example:
|
||||
|
||||
```groovy
|
||||
enum Coin {
|
||||
penny(1), nickel(5), dime(10), quarter(25)
|
||||
Coin(int value) { this.value = value }
|
||||
private final int value
|
||||
public int value() { return value }
|
||||
}
|
||||
|
||||
assert Coin.values().size() == 4
|
||||
|
||||
def pocketMoney = 2 * Coin.quarter.value() + 5 * Coin.dime.value()
|
||||
assert pocketMoney == 100
|
||||
|
||||
// another way to do abovedef coins = [ Coin.quarter ] * 2 + [ Coin.dime ] * 5
|
||||
println coins // => [ quarter, quarter, dime, dime, dime, dime, dime ]
|
||||
println coins.sum{ it.value() } // => 100
|
||||
```
|
||||
|
||||
Here is a planet example:
|
||||
|
||||
```groovy
|
||||
enum Planet {
|
||||
MERCURY(3.303e+23, 2.4397e6),
|
||||
VENUS(4.869e+24, 6.0518e6),
|
||||
EARTH(5.976e+24, 6.37814e6),
|
||||
MARS(6.421e+23, 3.3972e6),
|
||||
JUPITER(1.9e+27, 7.1492e7),
|
||||
SATURN(5.688e+26, 6.0268e7),
|
||||
URANUS(8.686e+25, 2.5559e7),
|
||||
NEPTUNE(1.024e+26, 2.4746e7)
|
||||
private final double mass // in kilograms
|
||||
private final double radius // in metres
|
||||
Planet(double mass, double radius) {
|
||||
this.mass = mass
|
||||
this.radius = radius
|
||||
}
|
||||
private double mass() { return mass }
|
||||
private double radius() { return radius }
|
||||
// universal gravitational constant (m3 kg-1 s-2)
|
||||
public static final double G = 6.67300E-11
|
||||
double surfaceGravity() { return G * mass / (radius * radius) }
|
||||
double surfaceWeight(double otherMass) { return otherMass * surfaceGravity() }
|
||||
}
|
||||
|
||||
double earthWeight = 75.0 // kgdouble mass = earthWeight/Planet.EARTH.surfaceGravity()
|
||||
for (p in Planet.values()) {
|
||||
printf("Your weight on %s is %f%n", p, p.surfaceWeight(mass))
|
||||
}
|
||||
|
||||
// =>// Your weight on MERCURY is 28.331821// Your weight on VENUS is 67.874932// Your weight on EARTH is 75.000000// Your weight on MARS is 28.405289// Your weight on JUPITER is 189.791814// Your weight on SATURN is 79.951165// Your weight on URANUS is 67.884540// Your weight on NEPTUNE is 85.374605
|
||||
```
|
||||
|
||||
Note: there are currently issues with using Groovy enums in conjunction with GroovyShell. Best bet would be to check Jira if you are having problems, e.g. http://jira.codehaus.org/browse/GROOVY-2135
|
||||
|
||||
|
||||
Evernote hilft dir, nichts zu vergessen und alles mühelos zu ordnen und zu organisieren. Evernote herunterladen.
|
||||
|
||||
|
||||
@@ -1,455 +0,0 @@
|
||||
---
|
||||
title: Groovy - Using MarkupBuilder for Agile XML creation
|
||||
tags:
|
||||
- IT/Development/Groovy
|
||||
---
|
||||
|
||||
Two principles of Agile development are DRY (don't repeat yourself) and merciless refactoring. Thanks to excellent IDE support it isn't too hard to apply these principles to coding Java and Groovy but it's a bit harder with XML.
|
||||
|
||||
The good news is that Groovy's Builder notation can help. Whether you are trying to refactor your Ant build file(s) or manage a family of related XML files (e.g. XML request and response files for testing Web Services) you will find that you can make great advances in managing your XML files using builder patterns.
|
||||
|
||||
|
||||
Scenario: Consider we have a program to track the sales of copies of [GINA](http://groovy.canoo.com/gina) (smile) . Books leave a warehouse in trucks. Trucks contain big boxes which are sent off to various countries. The big boxes contain smaller boxes which travel to different states and cities around the world. These boxes may also contain smaller boxes as required. Eventually some of the boxes contain just books. Either GINA or some potential upcoming Groovy titles. Suppose the delivery system produces XML files containing the items in each truck. We are responsible for writing the system which does some fancy reporting.
|
||||
|
||||
|
||||
If we are a vigilant tester, we will have a family of test files which allow us to test the many possible kinds of XML files we need to deal with. Instead of having to manage a directory full of files which would be hard to maintain if the delivery system changed, we decide to use Groovy to generate the XML files we need. Here is our first attempt:
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
xml.truck(id:'ABC123') {
|
||||
box(country:'Australia') {
|
||||
box(country:'Australia', state:'QLD') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for VBA Macro writers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW') {
|
||||
box(country:'Australia', state:'NSW', city:'Sydney') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for COBOL Programmers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW', suburb:'Albury') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for Fortran Programmers')
|
||||
}
|
||||
}
|
||||
}
|
||||
box(country:'USA') {
|
||||
box(country:'USA', state:'CA') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for Ruby programmers')
|
||||
}
|
||||
}
|
||||
box(country:'Germany') {
|
||||
box(country:'Germany', city:'Berlin') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for PHP Programmers')
|
||||
}
|
||||
}
|
||||
box(country:'UK') {
|
||||
box(country:'UK', city:'London') {
|
||||
book(title:'Groovy in Action', author:'Dierk K??nig et al')
|
||||
book(title:'Groovy for Haskel Programmers')
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
There is quite a lot of replication in this file. Lets refactor out two helper methods standardBook1 and standardBook2 to remove some of the duplication. We now have something like this:
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
// standard bookdef standardBook1(builder) { builder.book(title:'Groovy in Action', author:'Dierk K??nig et al') }
|
||||
// other standard booksdef standardBook2(builder, audience) { builder.book(title:"Groovy for ${audience}") }
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
xml.truck(id:'ABC123') {
|
||||
box(country:'Australia') {
|
||||
box(country:'Australia', state:'QLD') {
|
||||
standardBook1(xml)
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'VBA Macro writers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW') {
|
||||
box(country:'Australia', state:'NSW', city:'Sydney') {
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'COBOL Programmers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW', suburb:'Albury') {
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'Fortran Programmers')
|
||||
}
|
||||
}
|
||||
}
|
||||
box(country:'USA') {
|
||||
box(country:'USA', state:'CA') {
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'Ruby Programmers')
|
||||
}
|
||||
}
|
||||
box(country:'Germany') {
|
||||
box(country:'Germany', city:'Berlin') {
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'PHP Programmers')
|
||||
}
|
||||
}
|
||||
box(country:'UK') {
|
||||
box(country:'UK', city:'London') {
|
||||
standardBook1(xml)
|
||||
standardBook2(xml, 'Haskel Programmers')
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
Next, let's refactor out a few more methods to end up with the following:
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
// define standard book and version allowing multiple copiesdef standardBook1(builder) { builder.book(title:'Groovy in Action', author:'Dierk K??nig et al') }
|
||||
def standardBook1(builder, copies) { (0..<copies).each{ standardBook1(builder) } }
|
||||
// another standard bookdef standardBook2(builder, audience) { builder.book(title:"Groovy for ${audience}") }
|
||||
// define standard boxdef standardBox1(builder, args) {
|
||||
def other = args.findAll{it.key != 'audience'}
|
||||
builder.box(other) { standardBook1(builder); standardBook2(builder, args['audience']) }
|
||||
}
|
||||
// define standard country boxdef standardBox2(builder, args) {
|
||||
builder.box(country:args['country']) {
|
||||
if (args.containsKey('language')) {
|
||||
args.put('audience', args['language'] + ' programmers')
|
||||
args.remove('language')
|
||||
}
|
||||
standardBox1(builder, args)
|
||||
} }
|
||||
|
||||
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
xml.truck(id:'ABC123') {
|
||||
box(country:'Australia') {
|
||||
box(country:'Australia', state:'QLD') {
|
||||
standardBook1(xml, 2)
|
||||
standardBook2(xml, 'VBA Macro writers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW') {
|
||||
[Sydney:'COBOL', Albury:'Fortran'].each{ city, language ->
|
||||
standardBox1(xml, [country:'Australia', state:'NSW',
|
||||
city:"${city}", audience:"${language} Programmers"])
|
||||
} } }
|
||||
standardBox2(xml, [country:'USA', state:'CA', language:'Ruby'])
|
||||
standardBox2(xml, [country:'Germany', city:'Berlin', language:'PHP'])
|
||||
standardBox2(xml, [country:'UK', city:'London', language:'Haskel'])
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
This is better. If the format of our XML changes, we will minimise the changes required in our builder code. Similarly, if we need to produce multiple XML files, we can add some for loops, closures or if statements to generate all the files from one or a small number of source files.
|
||||
|
||||
We could extract out some of our code into a helper method and the code would become:
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
def standard = new StandardBookDefinitions(xml)
|
||||
xml.truck(id:'ABC123') {
|
||||
box(country:'Australia') {
|
||||
box(country:'Australia', state:'QLD') {
|
||||
standard.book1(2)
|
||||
standard.book2('VBA Macro writers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW') {
|
||||
[Sydney:'COBOL', Albury:'Fortran'].each{ city, language ->
|
||||
standard.box1(country:'Australia', state:'NSW',
|
||||
city:"${city}", audience:"${language} Programmers")
|
||||
} } }
|
||||
standard.box2(country:'USA', state:'CA', language:'Ruby')
|
||||
standard.box2(country:'Germany', city:'Berlin', language:'PHP')
|
||||
standard.box2(country:'UK', city:'London', language:'Haskel')
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
So far we have just produced the one XML file. It would make sense to use similar techniques to produce all the XML files we need. We can take this in several directions at this point including using GStrings, using database contents to help generate the content or making use of templates.
|
||||
|
||||
We won't look at any of these, instead we will just augment the previous example just a little more.
|
||||
|
||||
First we will slightly expand our helper class. Here is the result:
|
||||
StandardBookDefinitions.groovy
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
class StandardBookDefinitions {
|
||||
private def builder
|
||||
StandardBookDefinitions(builder) {
|
||||
this.builder = builder
|
||||
}
|
||||
def removeKey(args, key) { return args.findAll{it.key != key} }
|
||||
// define standard book and version allowing multiple copies
|
||||
def book1() { builder.book(title:'Groovy in Action', author:'Dierk K??nig et al') }
|
||||
def book1(copies) { (0..<copies).each{ book1() } }
|
||||
// another standard book
|
||||
def book2(audience) { builder.book(title:"Groovy for ${audience}") }
|
||||
// define standard box
|
||||
def box1(args) {
|
||||
def other = removeKey(args, 'audience')
|
||||
builder.box(other) { book1(); book2(args['audience']) }
|
||||
}
|
||||
// define standard country box
|
||||
def box2(args) {
|
||||
builder.box(country:args['country']) {
|
||||
if (args.containsKey('language')) {
|
||||
args.put('audience', args['language'] + ' programmers')
|
||||
args.remove('language')
|
||||
}
|
||||
box1(args)
|
||||
} }
|
||||
// define deep box
|
||||
def box3(args) {
|
||||
def depth = args['depth']
|
||||
def other = removeKey(args, 'depth')
|
||||
if (depth > 1) {
|
||||
builder.box(other) {
|
||||
other.put('depth', depth - 1)
|
||||
box3(other)
|
||||
}
|
||||
} else {
|
||||
box2(other)
|
||||
} }
|
||||
// define deep box
|
||||
def box4(args) {
|
||||
builder.box(country:'South Africa'){
|
||||
(0..<args['number']).each{ book1() }
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
And now we will use this helper class to generate a family of related XML files. For illustrative purposes, we will just print out the generated files rather than actually store the files.
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
def writer = new StringWriter()
|
||||
xml = new MarkupBuilder(writer)
|
||||
standard = new StandardBookDefinitions(xml)
|
||||
def shortCountry = 'UK'def longCountry = 'The United Kingdom of Great Britain and Northern Ireland'def shortState = 'CA'def longState = 'The State of Rhode Island and Providence Plantations'def countryForState = 'USA'
|
||||
|
||||
def generateWorldOrEuropeXml(world) {
|
||||
xml.truck(id:'ABC123') {
|
||||
if (world) {
|
||||
box(country:'Australia') {
|
||||
box(country:'Australia', state:'QLD') {
|
||||
standard.book1(2)
|
||||
standard.book2('VBA Macro writers')
|
||||
}
|
||||
box(country:'Australia', state:'NSW') {
|
||||
[Sydney:'COBOL', Albury:'Fortran'].each{ city, language ->
|
||||
standard.box1(country:'Australia', state:'NSW',
|
||||
city:"${city}", audience:"${language} Programmers")
|
||||
} } }
|
||||
standard.box2(country:'USA', state:'CA', language:'Ruby')
|
||||
}
|
||||
standard.box2(country:'Germany', city:'Berlin', language:'PHP')
|
||||
standard.box2(country:'UK', city:'London', language:'Haskel')
|
||||
}
|
||||
}
|
||||
|
||||
def generateSpecialSizeXml(depth, number) {
|
||||
xml.truck(id:'DEF123') {
|
||||
standard.box3(country:'UK', city:'London', language:'Haskel', depth:depth)
|
||||
standard.box4(country:'UK', city:'London', language:'Haskel', number:number)
|
||||
box(country:'UK') {} // empty box
|
||||
}
|
||||
}
|
||||
|
||||
def generateSpecialNamesXml(country, state) {
|
||||
xml.truck(id:'GHI123') {
|
||||
if (state) {
|
||||
box(country:country, state:state){ standard.book1() }
|
||||
} else {
|
||||
box(country:country){ standard.book1() }
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
generateWorldOrEuropeXml(true)
|
||||
generateWorldOrEuropeXml(false)
|
||||
generateSpecialSizeXml(10, 10)
|
||||
generateSpecialNamesXml(shortCountry, '')
|
||||
generateSpecialNamesXml(longCountry, '')
|
||||
generateSpecialNamesXml(countryForState, shortState)
|
||||
generateSpecialNamesXml(countryForState, longState)
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
This will be much more maintainable over time than a directory full of hand-crafted XML files.
|
||||
|
||||
Here is what will be produced:
|
||||
|
||||
```xml
|
||||
<truck id='ABC123'>
|
||||
<box country='Australia'>
|
||||
<box state='QLD' country='Australia'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for VBA Macro writers' />
|
||||
</box>
|
||||
<box state='NSW' country='Australia'>
|
||||
<box city='Albury' state='NSW' country='Australia'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for Fortran Programmers' />
|
||||
</box>
|
||||
<box city='Sydney' state='NSW' country='Australia'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for COBOL Programmers' />
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
<box country='USA'>
|
||||
<box state='CA' country='USA'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for Ruby programmers' />
|
||||
</box>
|
||||
</box>
|
||||
<box country='Germany'>
|
||||
<box city='Berlin' country='Germany'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for PHP programmers' />
|
||||
</box>
|
||||
</box>
|
||||
<box country='UK'>
|
||||
<box city='London' country='UK'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for Haskel programmers' />
|
||||
</box>
|
||||
</box>
|
||||
</truck>
|
||||
<truck id='ABC123'>
|
||||
<box country='Germany'>
|
||||
<box city='Berlin' country='Germany'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for PHP programmers' />
|
||||
</box>
|
||||
</box>
|
||||
<box country='UK'>
|
||||
<box city='London' country='UK'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for Haskel programmers' />
|
||||
</box>
|
||||
</box>
|
||||
</truck>
|
||||
<truck id='DEF123'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box language='Haskel' city='London' country='UK'>
|
||||
<box country='UK'>
|
||||
<box city='London' country='UK'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
<book title='Groovy for Haskel programmers' />
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
</box>
|
||||
<box country='South Africa'>
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
<book title='Groovy in Action' author='Dierk König et al' />
|
||||
</box>
|
||||
<box country='UK' />
|
||||
</truck>
|
||||
<truck id='GHI123'>
|
||||
<box country='UK'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
</box>
|
||||
</truck>
|
||||
<truck id='GHI123'>
|
||||
<box country='The United Kingdom of Great Britain and Northern Ireland'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
</box>
|
||||
</truck>
|
||||
<truck id='GHI123'>
|
||||
<box state='CA' country='USA'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
</box>
|
||||
</truck>
|
||||
<truck id='GHI123'>
|
||||
<box state='The State of Rhode Island and Providence Plantations' country='USA'>
|
||||
<book title='Groovy in Action' author='Dierk K??nig et al' />
|
||||
</box>
|
||||
</truck>
|
||||
```
|
||||
|
||||
Things to be careful about when using markup builders is not to overlap variables you currently have in scope. The following is a good example
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
def book = "MyBook"
|
||||
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
xml.shelf() {
|
||||
book(name:"Fight Club") {
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
|
||||
When run this will actually get the error
|
||||
|
||||
```
|
||||
aught: groovy.lang.MissingMethodException: No signature of method: java.lang.String.call() is applicable for argument types: (java.util.LinkedHashMap, HelloWorld$_run_closure1_closure2) values: {["name":"Fight Club"],
|
||||
```
|
||||
|
||||
This is because we have a variable above called book, then we are trying to create an element called book using the markup. Markups will always honor for variables/method names in scope first before assuming something should be interpreted as markup. But wait, we want a variable called book AND we want to create an xml element called book! No problem, use delegate variable.
|
||||
|
||||
```groovy
|
||||
import groovy.xml.MarkupBuilder
|
||||
|
||||
def book = "MyBook"
|
||||
|
||||
def writer = new StringWriter()
|
||||
def xml = new MarkupBuilder(writer)
|
||||
xml.shelf() {
|
||||
delegate.book(name:"Fight Club") {
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
println writer.toString()
|
||||
```
|
||||
@@ -1,54 +0,0 @@
|
||||
---
|
||||
title: Groovy Goodness - Working with Lines in Strings
|
||||
tags:
|
||||
- IT/Development/Groovy
|
||||
---
|
||||
|
||||
In Groovy we can create multiline strings, which contain line separators. But we can also read text from an file containing line separators. The Groovy String GDK contains method to work with strings that contain line separators. We can loop through the string line by line, or we can do split on each line. We can even convert the line separators to the platform specific line separators with the denormalize() method or linefeeds with the normalize() method.
|
||||
|
||||
```groovy
|
||||
def multiline = '''\
|
||||
Groovy is closely related to Java,
|
||||
so it is quite easy to make a transition.
|
||||
'''
|
||||
|
||||
// eachLine takes a closure with one argument, that
|
||||
// contains the complete line.
|
||||
multiline.eachLine {
|
||||
if (it =~ /Groovy/) {
|
||||
println it // Output: Groovy is closely related to Java,
|
||||
}
|
||||
}
|
||||
|
||||
// or eachLine has a closure with two argument, the current line
|
||||
// and the line count.
|
||||
multiline.eachLine { line, count ->
|
||||
if (count == 0) {
|
||||
println "line $count: $line" // Output: line 0: Groovy is closely related to Java,
|
||||
}
|
||||
}
|
||||
|
||||
def platformLinefeeds = multiline.denormalize()
|
||||
def linefeeds = multiline.normalize()
|
||||
|
||||
// Read all lines and convert to list.
|
||||
def list = multiline.readLines()
|
||||
assert list instanceof ArrayList
|
||||
assert 2 == list.size()
|
||||
assert 'Groovy is closely related to Java,' == list[0]
|
||||
|
||||
def records = """\
|
||||
mrhaki\tGroovy
|
||||
hubert\tJava
|
||||
"""
|
||||
|
||||
// splitEachLine will split each line with the specified
|
||||
// separator. The closure has one argument, the list of
|
||||
// elements separated by the separator.
|
||||
records.splitEachLine('\t') { items ->
|
||||
println items[0] + " likes " + items[1]
|
||||
}
|
||||
// Output:
|
||||
// mrhaki likes Groovy
|
||||
// hubert likes Java
|
||||
```
|
||||
@@ -1,18 +0,0 @@
|
||||
---
|
||||
title: "Groovy Goodness: Use GrabResolver for Custom Repositories - Messages from mrhaki"
|
||||
tags:
|
||||
- IT/Development/Groovy
|
||||
---
|
||||
|
||||
## Groovy Goodness: Use GrabResolver for Custom Repositories
|
||||
|
||||
In Groovy we can use the @Grab annotation to define dependencies and automatically download them from public repositories. But maybe we have created our own package and we want to use it in our Groovy script. Our own package is deployed to a customer Maven 2 compatible repository with the url http://customserver/repo, so it is not available to the general public. We can use @GrabResolver to add this repository as a source to look for dependencies in our script. In the following sample code we assume the module groovy-samples, version 1.0 is deployed in the repository accessible via http://customserver/repo:
|
||||
|
||||
```groovy
|
||||
@GrabResolver(name='custom', root='http://customserver/repo', m2Compatible='true')
|
||||
@Grab('com.mrhaki:groovy-samples:1.0')
|
||||
import com.mrhaki.groovy.Sample
|
||||
|
||||
def s = new Sample()
|
||||
s.justToShowGrabResolver() // Just a sample
|
||||
```
|
||||
@@ -1,364 +0,0 @@
|
||||
---
|
||||
title: Guide To CompletableFuture | Baeldung
|
||||
source: https://www.baeldung.com/java-completablefuture
|
||||
tags:
|
||||
- IT/Development/Java
|
||||
---
|
||||
|
||||
**Inhaltsverzeichnis**
|
||||
|
||||
1. [[#Introduction|Introduction]]
|
||||
1. [[#Asynchronous Computation in Java|Asynchronous Computation in Java]]
|
||||
1. [[#Using *CompletableFuture* as a Simple *Future*|Using *CompletableFuture* as a Simple *Future*]]
|
||||
1. [[#*CompletableFuture* with Encapsulated Computation Logic|*CompletableFuture* with Encapsulated Computation Logic]]
|
||||
1. [[#Processing Results of Asynchronous Computations|Processing Results of Asynchronous Computations]]
|
||||
1. [[#Combining Futures|Combining Futures]]
|
||||
1. [[#Difference Between *thenApply()* and *thenCompose()*|Difference Between *thenApply()* and *thenCompose()*]]
|
||||
1. [[#Difference Between *thenApply()* and *thenCompose()*#*thenApply()*|*thenApply()*]]
|
||||
1. [[#Difference Between *thenApply()* and *thenCompose()*#*thenCompose()*|*thenCompose()*]]
|
||||
1. [[#Running Multiple *Futures* in Parallel|Running Multiple *Futures* in Parallel]]
|
||||
1. [[#Handling Errors|Handling Errors]]
|
||||
1. [[#Async Methods|Async Methods]]
|
||||
1. [[#JDK 9 *CompletableFuture* API|JDK 9 *CompletableFuture* API]]
|
||||
1. [[#Conclusion|Conclusion]]
|
||||
|
||||
## Introduction
|
||||
|
||||
This tutorial is a guide to the functionality and use cases of the *CompletableFuture* class that was introduced as a Java 8 Concurrency API improvement.
|
||||
|
||||
## Asynchronous Computation in Java
|
||||
|
||||
Asynchronous computation is difficult to reason about. Usually, we want to think of any computation as a series of steps, but in the case of asynchronous computation, **actions represented as callbacks tend to be either scattered across the code or deeply nested inside each other**. Things get even worse when we need to handle errors that might occur during one of the steps.
|
||||
|
||||
The *Future* interface was added in Java 5 to serve as a result of an asynchronous computation, but it did not have any methods to combine these computations or handle possible errors.
|
||||
|
||||
**Java 8 introduced the *CompletableFuture* class.** Along with the *Future* interface, it also implemented the *CompletionStage* interface. This interface defines the contract for an asynchronous computation step that we can combine with other steps.
|
||||
|
||||
*CompletableFuture* is at the same time, a building block and a framework, with **about 50 different methods for composing, combining, and executing asynchronous computation steps and handling errors**.
|
||||
|
||||
Such a large API can be overwhelming, but these mostly fall into several clear and distinct use cases.
|
||||
|
||||
## Using *CompletableFuture* as a Simple *Future*
|
||||
|
||||
First, the *CompletableFuture* class implements the *Future* interface so that we can **use it as a *Future* implementation but with additional completion logic**.
|
||||
|
||||
For example, we can create an instance of this class with a no-arg constructor to represent some future result, hand it out to the consumers, and complete it at some time in the future using the *complete* method. The consumers may use the *get* method to block the current thread until this result is provided.
|
||||
|
||||
In the example below, we have a method that creates a *CompletableFuture* instance, then spins off some computation in another thread and returns the *Future* immediately.
|
||||
|
||||
When the computation is done, the method completes the *Future* by providing the result to the *complete* method:
|
||||
|
||||
```java
|
||||
public Future<String> calculateAsync() throws InterruptedException {
|
||||
CompletableFuture<String> completableFuture = new CompletableFuture<>();
|
||||
|
||||
Executors.newCachedThreadPool().submit(() -> {
|
||||
Thread.sleep(500);
|
||||
completableFuture.complete("Hello");
|
||||
return null;
|
||||
});
|
||||
|
||||
return completableFuture;
|
||||
}
|
||||
```
|
||||
|
||||
To spin off the computation, we use the *Executor* API. This method of creating and completing a *CompletableFuture* can be used with any concurrency mechanism or API, including raw threads.
|
||||
|
||||
Notice that **the *calculateAsync* method returns a *Future* instance**.
|
||||
|
||||
We simply call the method, receive the *Future* instance, and call the *get* method on it when we're ready to block for the result.
|
||||
|
||||
Also, observe that the *get* method throws some checked exceptions, namely *ExecutionException* (encapsulating an exception that occurred during a computation) and *InterruptedException* (an exception signifying that a thread was interrupted either before or during an activity):
|
||||
|
||||
```java
|
||||
Future<String> completableFuture = calculateAsync();
|
||||
|
||||
// ...
|
||||
|
||||
String result = completableFuture.get();
|
||||
assertEquals("Hello", result);
|
||||
```
|
||||
|
||||
**If we already know the result of a computation**, we can use the static *completedFuture* method with an argument that represents the result of this computation. Consequently, the *get* method of the *Future* will never block, immediately returning this result instead:
|
||||
|
||||
```java
|
||||
Future<String> completableFuture =
|
||||
CompletableFuture.completedFuture("Hello");
|
||||
|
||||
// ...
|
||||
|
||||
String result = completableFuture.get();
|
||||
assertEquals("Hello", result);
|
||||
```
|
||||
|
||||
As an alternative scenario, we may want to [**cancel the execution of a *Future***](https://www.baeldung.com/java-future#2-canceling-a-future-with-cancel).
|
||||
|
||||
## *CompletableFuture* with Encapsulated Computation Logic
|
||||
|
||||
The code above allows us to pick any mechanism of concurrent execution, but what if we want to skip this boilerplate and execute some code asynchronously?
|
||||
|
||||
Static methods *runAsync* and *supplyAsync* allow us to create a *CompletableFuture* instance out of *Runnable* and *Supplier* functional types correspondingly.
|
||||
|
||||
*Runnable* and *Supplier* are functional interfaces that allow passing their instances as lambda expressions thanks to the new Java 8 feature.
|
||||
|
||||
The *Runnable* interface is the same old interface used in threads and does not allow to return a value.
|
||||
|
||||
The *Supplier* interface is a generic functional interface with a single method that has no arguments and returns a value of a parameterized type.
|
||||
|
||||
This allows us to **provide an instance of the *Supplier* as a lambda expression that does the calculation and returns the result**. It is as simple as:
|
||||
|
||||
```java
|
||||
CompletableFuture<String> future
|
||||
= CompletableFuture.supplyAsync(() -> "Hello");
|
||||
|
||||
// ...
|
||||
|
||||
assertEquals("Hello", future.get());
|
||||
```
|
||||
|
||||
## Processing Results of Asynchronous Computations
|
||||
|
||||
The most generic way to process the result of a computation is to feed it to a function. The *thenApply* method does exactly that; it accepts a *Function* instance, uses it to process the result, and returns a *Future* that holds a value returned by a function:
|
||||
|
||||
```java
|
||||
CompletableFuture<String> completableFuture
|
||||
= CompletableFuture.supplyAsync(() -> "Hello");
|
||||
|
||||
CompletableFuture<String> future = completableFuture
|
||||
.thenApply(s -> s + " World");
|
||||
|
||||
assertEquals("Hello World", future.get());
|
||||
```
|
||||
|
||||
If we don't need to return a value down the *Future* chain, we can use an instance of the *Consumer* functional interface. Its single method takes a parameter and returns *void*.
|
||||
|
||||
There's a method for this use case in the *CompletableFuture.* The *thenAccept* method receives a *Consumer* and passes it the result of the computation. Then the final *future.get()* call returns an instance of the *Void* type:
|
||||
|
||||
```java
|
||||
CompletableFuture<String> completableFuture
|
||||
= CompletableFuture.supplyAsync(() -> "Hello");
|
||||
|
||||
CompletableFuture<Void> future = completableFuture
|
||||
.thenAccept(s -> System.out.println("Computation returned: " + s));
|
||||
|
||||
future.get();
|
||||
```
|
||||
|
||||
Finally, if we neither need the value of the computation nor want to return some value at the end of the chain, then we can pass a *Runnable* lambda to the *thenRun* method. In the following example, we simply print a line in the console after calling the *future.get():*
|
||||
|
||||
```java
|
||||
CompletableFuture<String> completableFuture
|
||||
= CompletableFuture.supplyAsync(() -> "Hello");
|
||||
|
||||
CompletableFuture<Void> future = completableFuture
|
||||
.thenRun(() -> System.out.println("Computation finished."));
|
||||
|
||||
future.get();
|
||||
```
|
||||
|
||||
## Combining Futures
|
||||
|
||||
The best part of the *CompletableFuture* API is the **ability to combine *CompletableFuture* instances in a chain of computation steps**.
|
||||
|
||||
The result of this chaining is itself a *CompletableFuture* that allows further chaining and combining. This approach is ubiquitous in functional languages and is often referred to as a monadic design pattern.
|
||||
|
||||
**In the following example, we use the *thenCompose* method to chain two *Futures* sequentially.**
|
||||
|
||||
Notice that this method takes a function that returns a *CompletableFuture* instance. The argument of this function is the result of the previous computation step. This allows us to use this value inside the next *CompletableFuture*‘s lambda:
|
||||
|
||||
```java
|
||||
CompletableFuture<String> completableFuture
|
||||
= CompletableFuture.supplyAsync(() -> "Hello")
|
||||
.thenCompose(s -> CompletableFuture.supplyAsync(() -> s + " World"));
|
||||
|
||||
assertEquals("Hello World", completableFuture.get());
|
||||
```
|
||||
|
||||
The *thenCompose* method, together with *thenApply,* implements the basic building blocks of the monadic pattern. They closely relate to the *map* and *flatMap* methods of *Stream* and *Optional* classes, also available in Java 8.
|
||||
|
||||
Both methods receive a function and apply it to the computation result, but the *thenCompose* (*flatMap*) method **receives a function that returns another object of the same type**. This functional structure allows composing the instances of these classes as building blocks.
|
||||
|
||||
If we want to execute two independent *Futures* and do something with their results, we can use the *thenCombine* method that accepts a *Future* and a *Function* with two arguments to process both results:
|
||||
|
||||
```java
|
||||
CompletableFuture<String> completableFuture
|
||||
= CompletableFuture.supplyAsync(() -> "Hello")
|
||||
.thenCombine(CompletableFuture.supplyAsync(
|
||||
() -> " World"), (s1, s2) -> s1 + s2));
|
||||
|
||||
assertEquals("Hello World", completableFuture.get());
|
||||
```
|
||||
|
||||
A simpler case is when we want to do something with two *Futures*‘ results but don't need to pass any resulting value down a *Future* chain. The *thenAcceptBoth* method is there to help:
|
||||
|
||||
```java
|
||||
CompletableFuture future = CompletableFuture.supplyAsync(() -> "Hello")
|
||||
.thenAcceptBoth(CompletableFuture.supplyAsync(() -> " World"),
|
||||
(s1, s2) -> System.out.println(s1 + s2));
|
||||
```
|
||||
|
||||
## Difference Between *thenApply()* and *thenCompose()*
|
||||
|
||||
In our previous sections, we've shown examples regarding *thenApply()* and *thenCompose()*. Both APIs help chain different *CompletableFuture* calls, but the usage of these two functions are different.
|
||||
|
||||
### *thenApply()*
|
||||
|
||||
**We can use this method to work with the result of the previous call.** However, a key point to remember is that the return type will be combined of all calls.
|
||||
|
||||
So this method is useful when we want to transform the result of a *CompletableFuture *call:
|
||||
|
||||
```java
|
||||
CompletableFuture<Integer> finalResult = compute().thenApply(s-> s + 1);
|
||||
```
|
||||
|
||||
### *thenCompose()*
|
||||
|
||||
The *thenCompose()* is similar to *thenApply()* in that both return a new CompletionStage. However, ***thenCompose()* uses the previous stage as the argument**. It will flatten and return a *Future* with the result directly, rather than a nested future as we observed in *thenApply():*
|
||||
|
||||
```java
|
||||
CompletableFuture<Integer> computeAnother(Integer i){
|
||||
return CompletableFuture.supplyAsync(() -> 10 + i);
|
||||
}
|
||||
CompletableFuture<Integer> finalResult = compute().thenCompose(this::computeAnother);
|
||||
```
|
||||
|
||||
So if the idea is to chain *CompletableFuture* methods, then it’s better to use *thenCompose()*.
|
||||
|
||||
Also, note that the difference between these two methods is analogous to [the difference between *map()* and *flatMap()*](https://www.baeldung.com/java-difference-map-and-flatmap)*.*
|
||||
|
||||
## Running Multiple *Futures* in Parallel
|
||||
|
||||
When we need to execute multiple *Futures* in parallel, we usually want to wait for all of them to execute and then process their combined results.
|
||||
|
||||
The *CompletableFuture.allOf* static method allows to wait for the completion of all of the *Futures* provided as a var-arg:
|
||||
|
||||
```java
|
||||
CompletableFuture<String> future1
|
||||
= CompletableFuture.supplyAsync(() -> "Hello");
|
||||
CompletableFuture<String> future2
|
||||
= CompletableFuture.supplyAsync(() -> "Beautiful");
|
||||
CompletableFuture<String> future3
|
||||
= CompletableFuture.supplyAsync(() -> "World");
|
||||
|
||||
CompletableFuture<Void> combinedFuture
|
||||
= CompletableFuture.allOf(future1, future2, future3);
|
||||
|
||||
// ...
|
||||
|
||||
combinedFuture.get();
|
||||
|
||||
assertTrue(future1.isDone());
|
||||
assertTrue(future2.isDone());
|
||||
assertTrue(future3.isDone());
|
||||
```
|
||||
|
||||
Notice that the return type of the *CompletableFuture.allOf()* is a *CompletableFuture<Void>*. The limitation of this method is that it does not return the combined results of all *Futures*. Instead, we have to get results from *Futures* manually. Fortunately, *CompletableFuture.join()* method and Java 8 Streams API makes it simple:
|
||||
|
||||
```java
|
||||
String combined = Stream.of(future1, future2, future3)
|
||||
.map(CompletableFuture::join)
|
||||
.collect(Collectors.joining(" "));
|
||||
|
||||
assertEquals("Hello Beautiful World", combined);
|
||||
```
|
||||
|
||||
The *CompletableFuture.join()* method is similar to the *get* method, but it throws an unchecked exception in case the *Future* does not complete normally. This makes it possible to use it as a method reference in the *Stream.map()* method.
|
||||
|
||||
## Handling Errors
|
||||
|
||||
For error handling in a chain of asynchronous computation steps, we have to adapt the *throw/catch* idiom in a similar fashion.
|
||||
|
||||
Instead of catching an exception in a syntactic block, the *CompletableFuture* class allows us to handle it in a special *handle* method. This method receives two parameters: a result of a computation (if it finished successfully) and the exception thrown (if some computation step did not complete normally).
|
||||
|
||||
In the following example, we use the *handle* method to provide a default value when the asynchronous computation of a greeting was finished with an error because no name was provided:
|
||||
|
||||
```java
|
||||
String name = null;
|
||||
|
||||
// ...
|
||||
|
||||
CompletableFuture<String> completableFuture
|
||||
= CompletableFuture.supplyAsync(() -> {
|
||||
if (name == null) {
|
||||
throw new RuntimeException("Computation error!");
|
||||
}
|
||||
return "Hello, " + name;
|
||||
}).handle((s, t) -> s != null ? s : "Hello, Stranger!");
|
||||
|
||||
assertEquals("Hello, Stranger!", completableFuture.get());
|
||||
```
|
||||
|
||||
As an alternative scenario, suppose we want to manually complete the *Future* with a value, as in the first example, but also have the ability to complete it with an exception. The *completeExceptionally* method is intended for just that. The *completableFuture.get()* method in the following example throws an *ExecutionException* with a *RuntimeException* as its cause:
|
||||
|
||||
```java
|
||||
CompletableFuture<String> completableFuture = new CompletableFuture<>();
|
||||
|
||||
// ...
|
||||
|
||||
completableFuture.completeExceptionally(
|
||||
new RuntimeException("Calculation failed!"));
|
||||
|
||||
// ...
|
||||
|
||||
completableFuture.get(); // ExecutionException
|
||||
```
|
||||
|
||||
In the example above, we could have handled the exception with the *handle* method asynchronously, but with the *get* method, we can use the more typical approach of synchronous exception processing.
|
||||
|
||||
## Async Methods
|
||||
|
||||
Most methods of the fluent API in the *CompletableFuture* class have two additional variants with the *Async* postfix. These methods are usually intended for **running a corresponding execution step in another thread**.
|
||||
|
||||
The methods without the *Async* postfix run the next execution stage using a calling thread. In contrast, the *Async* method without the *Executor* argument runs a step using the common *fork/join* pool implementation of *Executor* that is accessed with the *ForkJoinPool.commonPool()*, as long as [parallelism > 1](https://www.baeldung.com/java-when-to-use-parallel-stream#2-common-thread-pool). Finally, the *Async* method with an *Executor* argument runs a step using the passed *Executor*.
|
||||
|
||||
Here's a modified example that processes the result of a computation with a *Function* instance. The only visible difference is the *thenApplyAsync* method, but under the hood, the application of a function is wrapped into a *ForkJoinTask* instance (for more information on the *fork/join* framework, see the article [“Guide to the Fork/Join Framework in Java”](https://www.baeldung.com/java-fork-join)). This allows us to parallelize our computation even more and use system resources more efficiently:
|
||||
|
||||
```java
|
||||
CompletableFuture<String> completableFuture
|
||||
= CompletableFuture.supplyAsync(() -> "Hello");
|
||||
|
||||
CompletableFuture<String> future = completableFuture
|
||||
.thenApplyAsync(s -> s + " World");
|
||||
|
||||
assertEquals("Hello World", future.get());
|
||||
```
|
||||
|
||||
## JDK 9 *CompletableFuture* API
|
||||
|
||||
Java 9 enhances the *CompletableFuture* API with the following changes:
|
||||
|
||||
- New factory methods added
|
||||
- Support for delays and timeouts
|
||||
- Improved support for subclassing
|
||||
|
||||
and new instance APIs:
|
||||
|
||||
- *Executor defaultExecutor()*
|
||||
- *CompletableFuture<U> newIncompleteFuture()*
|
||||
- *CompletableFuture<T> copy()*
|
||||
- *CompletionStage<T> minimalCompletionStage()*
|
||||
- *CompletableFuture<T> completeAsync(Supplier<? extends T> supplier, Executor executor)*
|
||||
- *CompletableFuture<T> completeAsync(Supplier<? extends T> supplier)*
|
||||
- *CompletableFuture<T> orTimeout(long timeout, TimeUnit unit)*
|
||||
- *CompletableFuture<T> completeOnTimeout(T value, long timeout, TimeUnit unit)*
|
||||
|
||||
We also now have a few static utility methods:
|
||||
|
||||
- *Executor delayedExecutor(long delay, TimeUnit unit, Executor executor)*
|
||||
- *Executor delayedExecutor(long delay, TimeUnit unit)*
|
||||
- *<U> CompletionStage<U> completedStage(U value)*
|
||||
- *<U> CompletionStage<U> failedStage(Throwable ex)*
|
||||
- *<U> CompletableFuture<U> failedFuture(Throwable ex)*
|
||||
|
||||
Finally, to address timeout, Java 9 has introduced two more new functions:
|
||||
|
||||
- *orTimeout()*
|
||||
- *completeOnTimeout()*
|
||||
|
||||
Here's the detailed article for further reading: [Java 9 CompletableFuture API Improvements](https://www.baeldung.com/java-9-completablefuture).
|
||||
|
||||
## Conclusion
|
||||
|
||||
In this article, we've described the methods and typical use cases of the *CompletableFuture* class.
|
||||
|
||||
The source code for the article is available [over on GitHub](https://github.com/eugenp/tutorials/tree/master/core-java-modules/core-java-concurrency-simple).
|
||||
@@ -1,54 +0,0 @@
|
||||
---
|
||||
title: How to Check Your Laptop's Battery Health in Windows 10
|
||||
source: https://uk.pcmag.com/batteries-power/132133/how-to-check-your-laptops-battery-health-in-windows-10
|
||||
tags:
|
||||
- IT/OS/Windows
|
||||
---
|
||||
|
||||
# [How to Check Your Laptop's Battery Health in Windows 10](https://uk.pcmag.com/batteries-power/132133/how-to-check-your-laptops-battery-health-in-windows-10)
|
||||
|
||||
Batteries power our favorite electronic devices, but they're not meant to last forever. The good news is that [Windows 10](https://uk.pcmag.com/windows0-2/69981/microsoft-windows-10) laptops have a Battery Report feature that breaks down whether your battery is still kicking or is on its last legs. With a few simple commands, you can generate an HTML file with battery usage data, capacity history, and life estimates. If it needs to be replaced, this report will tell you, long before it has a chance to fail.
|
||||
|
||||
* * *
|
||||
|
||||
## Generate Battery Report in PowerShell
|
||||
|
||||
The Battery Report is generated via Windows PowerShell, a built-in command line tool you may have never used before. The easiest way to access it is to right-click on the Start icon and select **Windows PowerShell (Admin)** from the menu that appears. A pop-up window may ask for permission to make changes to your device; say yes.
|
||||
|
||||

|
||||
|
||||
The blue PowerShell command window will appear, allowing you to enter commands to automate certain tasks within Windows 10. Type or paste **powercfg /batteryreport /output "C:\\battery-report.html"** into the window and press Enter to run the command.
|
||||
|
||||

|
||||
|
||||
PowerShell will then tell you the name of the generated battery life report HTML file and where it has been saved on your computer. In this case, it is called battery-report.html and it has been saved to the C drive. You can now safely close PowerShell.
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
## View the Battery Report
|
||||
|
||||
Open Windows File Explorer and access the C drive. There you should find the battery life report saved as an HTML file. Double-click the file to open it in your preferred web browser.
|
||||
|
||||

|
||||
|
||||
The report will outline the health of your laptop battery, how well it has been doing, and how much longer it might last. At the top of the Battery Report, you will see basic information about your computer, followed by the battery's specs.
|
||||
|
||||

|
||||
|
||||
In the **Recent usage** section, take note of each time the laptop ran on battery power or was attached to AC power. Every drain over the last three days is tracked in the **Battery usage** section. You can also get a full history of the battery's usage under the **Usage history **section.
|
||||
|
||||

|
||||
|
||||
The **Battery capacity history** section shows how the capacity has changed over time. On the right is Design Capacity, or how much the battery was designed to handle. On the left, you can see the current full-charge capacity of your laptop's battery, which will likely decline over time the more you use your device.
|
||||
|
||||

|
||||
|
||||
This leads us to the **Battery life estimates **section. On the right, you'll see how long it should last based on design capacity; on the left, you'll see how long it's actually lasting. A current, final battery-life estimation is at the bottom of the report. In this case, my PC would last 6:02:03 at design capacity, but will currently hold out for 4:52:44.
|
||||
|
||||

|
||||
|
||||
If you don't like what your battery report has to say, [these easy tips](https://uk.pcmag.com/laptops/116734/how-to-increase-your-laptop-battery-life) can help you squeeze longer battery life out of your current laptop.
|
||||
|
||||
* * *
|
||||
@@ -1,166 +0,0 @@
|
||||
---
|
||||
title: How to Install and Use Veracrypt on Ubuntu 20.04
|
||||
source: https://linuxhint.com/how-to-install-and-use-veracrypt-on-ubuntu-20-04/
|
||||
---
|
||||
|
||||
If you do not want others to have access to your data, then encryption is essential. When you encrypt your sensitive data, unauthorized persons cannot easily get to it. This how-to guide focuses on the installation and basic usage of Veracrypt disk encryption software on Ubuntu Linux. Veracrypt is an open-source software and it is free.
|
||||
|
||||
As seen on the official downloads page (link: https://www.veracrypt.fr/en/Downloads.html), two options are available for using Veracrypt on Ubuntu Linux, namely: GUI and console. GUI means graphical-based and console means text-based(command-line.)
|
||||
|
||||
## Install Veracrypt: GUI
|
||||
|
||||
Run the following command in the Ubuntu terminal to download the Veracrypt GUI installer package.
|
||||
|
||||
### MY LATEST VIDEOS
|
||||
|
||||
How to pick the best CPU and GPU for a laptop in 2021
|
||||
|
||||
How to pick the best CPU and GPU for a laptop in 2021
|
||||
|
||||
0 seconds of 17 minutes, 46 secondsVolume 0%
|
||||
|
||||
[<img width="380" height="214" src="../../_resources/_width_400_height_225_url__2F_2F_b48c46da80684bd08.jpg"/>](https://eb2.3lift.com/pass?tl_clickthrough=true&redir=https%3A%2F%2Fr1-euc1.zemanta.com%2Frp2%2Fb1_triplelift%2F4705773%2F55697709%2FKCGLJNFFXXRIWAXPTUIHZUVAURDYOEHYG7AKBQYKWUALHZTYTXQRS3NAXRCTRPEVACZZXL4IJF7ZRRVFGULKKODBHQY7NZB2T67EDSNQOEMQVISG7NXS55T2GAPIS2RT6JWWXIM4EPCCARDFEENLXOGTMDFAPSIGCFZEZKAY55QLEQZAPC5ZVK5X2KTRATVUVSVOD27C36FF7RMEUTKSFCAXR4JTMXKY64KFTHSVURVSGDAYE36DDMIKTM253G3RXOT3JDDV3WQGF5NCTXWMG6ZFAVXIQ6QEUG55TZXDQIKYAFL5S6DTJIATLRHFCGYXZTIMHRPEBCZNGNY4W7UECJP5QEESDJRIWIO4RKPGPTAQ7IJGQE6KT5ANSMYN6T6QE35XYDSN7KUHUTMGHGQOL6PWECDAURQAGT5JCFNRODFNH4NT6J3ZS3WZH4JOR7KLTBCFWA5VNAJRICJFWJG7HGSDDGSDA7BYPJVXU63B7VNTT3UMCRXKSGI5WXOQPNTDJA3GKO4JFCTFF7KTZCYHWGPCW4PCYFC5B5HPTXSGH25OICELTBU5XVCWWWDPYNAFCCU5AKDSGQQNYZ4KLVPMAGUU4P2SA3D3VMAOO2XXTVOMN4ICVKV532LGO4TDJ2I275V6JZGTJETYA%2F%3Fcnsnt%3DCPUKG3MPUKG4jADABBDECBCsAP_AAH_AAAAAHyIF5C5URSFD4GJsIJIUIAEXwFAAAGAgDgQBA4AACBCAEAwEkAAAEAAAIAAAAAAAIAIAAAAACAkAAAAAQIAAIQAAAAQAIAAAIAIACAAAEAAAAAgAAoAAEAAAAAAAAAAAgAAAAAYAQAAAAAAAAAAAAAAAAAAAAAAAAAAAQAAAQPkQLyFyoikKGwMDQQSQoQAIugKAAAMBAHAACBgAAECEAIBgJIAAAAAAAQAAAAAAAQAQAAAAAABIAAAAAgQAAQgAAAAgAQAAAQAQAEAAAIAAAABAABQAAIAAAAAAAAAABAAAAAAwAgAAAAAAAAAAAAAAAAAAAAAAAAAAAgAAAgAA.YAAAAAAAA4AA&ss=12&bc=0.173&pr=0.12961&adid=55697709&brid=322294&bmid=2460&biid=2460&aid=35430398746445421280660&bcud=173&sid=63937&ts=1644432261&cb=30716)
|
||||
|
||||

|
||||
|
||||
$ sudo wget https://launchpad.net/veracrypt/trunk/1.24-update7/+download/veracrypt-1.24-Update7-Ubuntu-20.04-amd64.deb
|
||||
|
||||
Now, you may install the downloaded package as follows.
|
||||
|
||||
$ sudo apt-get install ./veracrypt-1.24-Update7-Ubuntu-20.04-amd64.deb
|
||||
|
||||
Enter **y** to continue with the installation if prompted. After a successful installation, you can launch Veracrypt from the Applications menu > Accessories > Veracrypt.
|
||||
|
||||
## Install Veracrypt: Console
|
||||
|
||||
Run the following command in the Ubuntu terminal to download the Veracrypt console installer package.
|
||||
|
||||
$ sudo wget https://launchpad.net/veracrypt/trunk/1.24-update7/+download/veracrypt-console-1.24-Update7-Ubuntu-20.04-amd64.deb
|
||||
|
||||
You may now proceed to install the downloaded package. Run the command below.
|
||||
|
||||
$ dpkg -i ./veracrypt-console-1.24-Update7-Ubuntu-20.04-amd64.deb
|
||||
|
||||
When the installation completes successfully, you may begin to use Veracrypt in the Ubuntu terminal. To see usage info, run the following command.
|
||||
|
||||
## Encrypt Your Sensitive Data
|
||||
|
||||
Let us imagine that you have a folder named folder1 on your Ubuntu desktop which contains sensitive documents. We are going to create an encrypted volume via the GUI and the console to serve as a personal vault for storing such sensitive documents.
|
||||
|
||||
## GUI Method:
|
||||
|
||||
### Create an encrypted volume
|
||||
|
||||
1\. Launch Veracrypt from the **Applications** menu > **Accessories** \> **Veracrypt** 2. Click **Create** 3. In the Veracrypt volume creation wizard, choose **Create an encrypted file container** 4. Click **Next** **<img width="760" height="474" src="../../_resources/word-image-485_5483a595b6ca4a1ab89f8ecdeeb2e146.png"/>****Figure 1:** Create an encrypted file container 5. On the Volume Type page, choose the first option labeled **Standard Veracrypt volume** 6. Click **Next** 7. Under Volume Location, click **Select File** 8. Choose your desired location on the left and then enter a name for the encrypted file container at the top
|
||||
|
||||

|
||||
|
||||
**Figure 2:** Name your new encrypted file container 9. Click **Save** at the bottom of the window 10. Back to the Volume Location page, click **Next** 11. Under Encryption Options, leave the default selections: AES and SHA-512, and click **Next** 12. Under Volume Size, enter the desired volume size. Click the drop-down menu to switch between Gigabytes, Megabytes and Kilobytes
|
||||
|
||||

|
||||
|
||||
**Figure 3:** Specify the size of the encrypted file container 13. Click **Next** 14. Under Volume Password, enter an encryption password 15. Click **Next** 16. Under Format Options, you may choose Linux Ext3 from the drop-down menu
|
||||
|
||||

|
||||
|
||||
**Figure 4:** Choose filesystem type for the encrypted volume 17. Click **Next** 18. Under Cross-Platform Support, let us go with the default selection 19. Click **Next** and then click **OK** when prompted 20. Under Volume Format, begin to move your mouse randomly for at least 1 minute
|
||||
|
||||
****
|
||||
|
||||
**Figure 5:** Move your mouse randomly 21. When you are done, click **Format** 22. When prompted, enter your Linux user password and click **OK** 23. Wait for a message indicating that your Veracrypt volume was successfully created 24. Click **OK** 25. Click **Exit**
|
||||
|
||||
### Mount the encrypted volume
|
||||
|
||||
1. Back to the main VeraCrypt window, click any free slot in the list 2. Click **Select File** 3. Choose the encrypted file container which you created earlier 4. Click **Open** at the bottom of the Window 5. Click **Mount** ******Figure 6:** Mount encrypted volume 6. When prompted, enter your encryption password and click **OK** 7. You should now see a new device icon on your desktop The mounted device will also be listed under **Devices** when you open File Manager by accessing your home directory for instance. Figure 7 below shows the default mount directory path.
|
||||
|
||||

|
||||
|
||||
**Figure 7:** Encrypted volume mount directory path You may now proceed to move your sensitive folder into your personal vault. 
|
||||
|
||||
**Figure 8:** Mounted volume listed under devices
|
||||
|
||||
### Dismount the encrypted volume
|
||||
|
||||
1. To dismount the encrypted volume, make sure that the appropriate slot is selected in the main Veracrypt window 2. Click **Dismount** 3. The slot entry should now be blank 4. Also, you should no longer see the encrypted volume on your desktop or listed under **Devices** ****
|
||||
|
||||
**Figure 9:** Dismount encrypted volume
|
||||
|
||||
## Console Method:
|
||||
|
||||
### Create an encrypted volume
|
||||
|
||||
Run the command below in the Ubuntu terminal to begin creating your encrypted volume.
|
||||
|
||||
When prompted to choose a volume type, enter **1** for a Normal volume
|
||||
|
||||
Volume type: 1) Normal 2) Hidden Select \[1\]: **1**
|
||||
|
||||
Next, you would be prompted to enter volume path and volume size. In the example below, the encrypted volume is called personal_vault and will be created in my home directory. The size of the personal vault will be 2 Gigabytes.
|
||||
|
||||
Enter volume path: **/home/shola/personal_vault** Enter volume size (sizeK/size\[M\]/sizeG): **2G**
|
||||
|
||||
For encryption algorithm and hash algorithm, the default AES and SHA-512 values are recommended. Enter **1** in both cases.
|
||||
|
||||
Encryption Algorithm: 1) AES 2) Serpent 3) Twofish 4) Camellia 5) Kuznyechik 6) AES(Twofish) 7) AES(Twofish(Serpent)) 8) Camellia(Kuznyechik) 9) Camellia(Serpent) 10) Kuznyechik(AES) 11) Kuznyechik(Serpent(Camellia)) 12) Kuznyechik(Twofish) 13) Serpent(AES) 14) Serpent(Twofish(AES)) 15) Twofish(Serpent) Select \[1\]: **1** Hash algorithm: 1) SHA-512 2) Whirlpool 3) SHA-256 4) Streebog Select \[1\]: **1**
|
||||
|
||||
For filesystem, Linux Ext3 would suffice. You may enter **4** to choose that.
|
||||
|
||||
[<img width="380" height="214" src="../../_resources/_width_400_height_225_url__2F_2F_1fa44ddeafe641ad9.jpg"/>](https://eb2.3lift.com/pass?tl_clickthrough=true&redir=https%3A%2F%2Fr1-euc1.zemanta.com%2Frp2%2Fb1_triplelift%2F16449741%2F67264830%2FFMLINY4JU7AKE3FMYLWAVWVDZDFGJWPW2GXGSAZ7NYEYHIVJBYKLLSLYKW725R2KV3G4EW2SQKKDBQ7HLCRUB2RLXRUOCDS5CY3JRWXOW72HJCOBO2Y7KNK3LKEVOX4SMGNDTEMYXBYACRWBRTFMZSSKHRVVLPHJPKIJTV27CVTXZTTTT234F6CBURDZNI352DVUZ2ERCP774A6G4A4JCUIR5LKB67LC6OY4E4HHDA2444BPYQO5XHWZ6VOXHRXFVTSXQGWVUHJ4F3VZ65Y6FZJZ2ODFHJ3NMUHSTH4P6XQUKIQX2LEFYI26DGYEVKJ2AMTRC7JLE2IBINALXVWGFUHG3RIB5HFCPOJEB2LOA3W35OEZVW2XNH5INRCRFTA5WX7N4AJQHKC27SKYNH7ABJQJPJ3QG7RI4FBBWF2FFUYYZ5UVYBWIU6WSUTF6KJNMRIGPT6MO4M2ZS56XNQWSUESZRSNLKMFU7DP3APRWSNYIRG6CACNHTYTCVCRM3K7EUBCBEE4DYFH6AQ3S454OZFBSADXFWHWL5A4G5V3IA55IREKEO4NGDIBCDLI6CPAZH3747RANP4X5XG5PWBXE6ILODA6XLZIQQUHKA7GE4LWHJN7GW7LOAURCDQFM53V7OBAWBARPTDMRL7CMSVQXC74MPJFIWKSXSSQ7W7XDVLYB65OMBWCQ%2F%3Fcnsnt%3DCPUKG3MPUKG4jADABBDECBCsAP_AAH_AAAAAHyIF5C5URSFD4GJsIJIUIAEXwFAAAGAgDgQBA4AACBCAEAwEkAAAEAAAIAAAAAAAIAIAAAAACAkAAAAAQIAAIQAAAAQAIAAAIAIACAAAEAAAAAgAAoAAEAAAAAAAAAAAgAAAAAYAQAAAAAAAAAAAAAAAAAAAAAAAAAAAQAAAQPkQLyFyoikKGwMDQQSQoQAIugKAAAMBAHAACBgAAECEAIBgJIAAAAAAAQAAAAAAAQAQAAAAAABIAAAAAgQAAQgAAAAgAQAAAQAQAEAAAIAAAABAABQAAIAAAAAAAAAABAAAAAAwAgAAAAAAAAAAAAAAAAAAAAAAAAAAAgAAAgAA.YAAAAAAAA4AA&ss=12&bc=0.209&pr=0.155532&adid=67264830&brid=569145&bmid=2460&biid=2460&aid=11335674744328348274350&bcud=209&sid=146385&ts=1644432132&cb=50589)
|
||||
|
||||

|
||||
|
||||
Filesystem: 1) None 2) FAT 3) Linux Ext2 4) Linux Ext3 5) Linux Ext4 6) NTFS 7) exFAT 8) Btrfs Select \[2\]: **4**
|
||||
|
||||
Now, it is time to choose a strong encryption password. You will get a warning if your chosen password is determined to be weak. **Note:** Using a short password is NOT recommended.
|
||||
|
||||
Enter password: WARNING: Short passwords are easy to crack using brute force techniques! We recommend choosing a password consisting of 20 or more characters. Are you sure you want to use a short password? (y=Yes/n=No) \[No\]: **y** Re-enter password:
|
||||
|
||||
When you are prompted to enter PIM, press the enter key on your keyboard to accept the default value. Do the same when you are prompted to enter the keyfile path. PIM is a number that specifies how many times your password is hashed. A keyfile is used alongside a password, such that any volume that uses the keyfile cannot be mounted if the correct keyfile is not provided. As we are focusing on basic usage here, the default values would suffice.
|
||||
|
||||
Enter PIM: Enter keyfile path \[none\]:
|
||||
|
||||
Finally, you would need to randomly type on the keyboard for at least 1 minute and quite fast too. This is supposed to make the encryption stronger. Avoid the enter key while you type. Press Enter only when you are done typing and then wait for the encrypted volume to be created.
|
||||
|
||||
Please type at least 320 randomly chosen characters and then press Enter: Done: 100% Speed: 33 MiB/s Left: 0 s The VeraCrypt volume has been successfully created.
|
||||
|
||||
### Mount the encrypted volume
|
||||
|
||||
To access the content of the encrypted volume, you need to first mount it. The default mount directory is /media/veracrypt1 but you can create yours if you wish. For example, the following command will create a mount directory under /mnt.
|
||||
|
||||
[<img width="380" height="214" src="../../_resources/_width_400_height_225_url__2F_2F_1fa44ddeafe641ad9.jpg"/>](https://eb2.3lift.com/pass?tl_clickthrough=true&redir=https%3A%2F%2Fr1-euc1.zemanta.com%2Frp2%2Fb1_triplelift%2F16449741%2F67264849%2FFMLINY4JU7AKFE6SNBKM6N72DD5JV3BIJB5B2PJAOULRHIVAITXMPXV7JU2GQY4SJMDZIXFWZTYD36Z2NF4H3W5M6PXPGKN2PXNZSMEKBGHPA54RF3HI56O27R6ENGVPUFAPEOHGRXDZ5IFL2J4SW5C5V525DNQIO3TCQCFUC2J5LYSQRTLHKE7B4R2D3456QYDZGLKZD3JRHQ3RP4GYUZTUSEQ7LWEOZVB5KYO2KWY6W2C4Q2L6RNPVHKH5AXMEZ5O22B2JBEHDQUCYEAIRHAWRWPIA22GYE3ROVKGGSCKWVY5ESN3O2ZRZ3R6IOPR7GILUVCR2VN3TUKSH2T4YDQGAOUIYQAXDUYE3VHRXAI56QZFZKJT3OKHTPJCBPTEWCOKZZUICUST2LHSP4AODYX2HFI4AGR4FO7K2NXML3YGFECNF4RPTD5DD6FQBPHDUPT66M4IW7STJ2BLJAEZWFUNZYESG3OYNH4SM5PGCUNWGBXDXGIBWFE4WRSO5G25MYPI4OBHVXO3WPVHZXWA7QYXAK6ZRODTHODCZEF5Z35YP6TCXOEXFRYHXEZUUBIV3UC77KW2CKRR2XBNYOEC3XWHWODXEUV67YXTXULIJWQWC4UEIRA5JA4H6UMSQTYK63KQGMZHIHTNZJZZSEV3IYCPZLQ%2F%3Fcnsnt%3DCPUKG3MPUKG4jADABBDECBCsAP_AAH_AAAAAHyIF5C5URSFD4GJsIJIUIAEXwFAAAGAgDgQBA4AACBCAEAwEkAAAEAAAIAAAAAAAIAIAAAAACAkAAAAAQIAAIQAAAAQAIAAAIAIACAAAEAAAAAgAAoAAEAAAAAAAAAAAgAAAAAYAQAAAAAAAAAAAAAAAAAAAAAAAAAAAQAAAQPkQLyFyoikKGwMDQQSQoQAIugKAAAMBAHAACBgAAECEAIBgJIAAAAAAAQAAAAAAAQAQAAAAAABIAAAAAgQAAQgAAAAgAQAAAQAQAEAAAIAAAABAABQAAIAAAAAAAAAABAAAAAAwAgAAAAAAAAAAAAAAAAAAAAAAAAAAAgAAAgAA.YAAAAAAAA4AA&ss=12&bc=0.153&pr=0.114655&adid=67264849&brid=569145&bmid=2460&biid=2460&aid=32984611738689614205690&bcud=153&sid=146385&ts=1644432132&cb=51131)
|
||||
|
||||

|
||||
|
||||
$ sudo mkdir /mnt/personal_vault
|
||||
|
||||
The next command below will begin mounting the encrypted volume.
|
||||
|
||||
$ veracrypt --mount /home/shola/personal_vault
|
||||
|
||||
When you are prompted, either press the enter key to use the default mount directory or type your own mount directory path. You would be prompted to enter your encryption password next. For PIM, keyfile and protect hidden volume prompts, hit the enter key to use the default values.
|
||||
|
||||
Enter mount directory \[default\]: **/mnt/personal_vault** Enter password for /home/shola/personal\_vault: Enter PIM for /home/shola/personal\_vault: Enter keyfile \[none\]: Protect hidden volume (if any)? (y=Yes/n=No) \[No\]:
|
||||
|
||||
Run the following command to list mounted volumes.
|
||||
|
||||
1: /home/shola/personal\_vault /dev/mapper/veracrypt1 /mnt/personal\_vault
|
||||
|
||||
You may now move your sensitive folder to your personal vault as follows.
|
||||
|
||||
$ sudo mv /home/shola/folder1 /mnt/personal_vault
|
||||
|
||||
To list the contents of your personal vault, run:
|
||||
|
||||
$ ls -l /mnt/personal_vault
|
||||
|
||||
### Dismount the encrypted volume
|
||||
|
||||
The following command will dismount the encrypted volume.
|
||||
|
||||
$ veracrypt --dismount /mnt/personal_vault
|
||||
|
||||
If you run **veracrypt –list** again, you should get a message indicating that no volume is mounted.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Veracrypt has some very advanced capabilities but we only covered the basics in this article. Feel free to share your experiences with us in the comments section.
|
||||
@@ -1,52 +0,0 @@
|
||||
---
|
||||
title: How to Shrink a WSL2 Virtual Disk – Stephen Rees-Carter
|
||||
source: https://stephenreescarter.net/how-to-shrink-a-wsl2-virtual-disk/
|
||||
tags:
|
||||
- IT/OS/Windows/WSL
|
||||
- IT/OS/Windows
|
||||
---
|
||||
|
||||
I’m a huge fan of [Windows Subsystem for Linux](https://docs.microsoft.com/en-us/windows/wsl/about) (WSL), especially [WSL2](https://docs.microsoft.com/en-us/windows/wsl/wsl2-index) which uses a virtualisation layer to bring increased performance and compatibility to WSL. However, one of the few downsides of WSL2 is that it uses a virtual disk (VHDX) to store the filesystem. This means you can end up in a situation where your virtual disk is taking up 100GB, but WSL2 only needs 15GB… which is exactly what happened to me today!
|
||||
|
||||
Long story short, I saved a backup in the wrong directory, and my WSL2 disk expanded to use up all available space on my drive. I went looking for a way to shrink a WSL2 virtual disk, and after a few false starts, found a method which worked for me. Hopefully it’ll help you out too!
|
||||
|
||||
## Before you begin
|
||||
|
||||
Before shrinking a WSL2 virtual disk, you need to ensure that WSL2 is not running.
|
||||
|
||||
You can check if it’s running with the command ‘`wsl.exe --list --verbose`‘ in PowerShell:
|
||||
|
||||
It should stop when it’s idle, or you can encourage it to stop with the ‘`wsl.exe --terminate`‘ command:
|
||||
|
||||
**I also highly recommend you take a backup of your WSL2 installation.**
|
||||
|
||||
These instructions worked for me, but you could have a different environment that may result in corrupted data. So please, take a backup first!
|
||||
|
||||
## Use `diskpart` to Shrink a WSL2 Virtual Disk
|
||||
|
||||
I discovered you can use the ‘`diskpart`‘ tool to compact a VHDX. This allows you to shrink a WSL2 virtual disk file, reclaiming disk space. It appeared to work for me without any data corruption, taking the file size down from 100GB to 15GB. Your results may vary though.
|
||||
|
||||
You can launch the `diskpart` tool in PowerShell:
|
||||
|
||||
It will open up a new window:
|
||||
|
||||
<img width="1200" height="554" src="../_resources/image_9c74eb2d2933442aa241accf3c5fe694.png"/>
|
||||
|
||||
Once that has opened, you need to specify the path to your VHDX file.
|
||||
|
||||
If you don’t know this path, you can find by first locating the package directory for your WSL2 instance, which lives in: `C:\Users\valorin\AppData\Local\Packages\`. Look for the vendor name, such as `WhitewaterFoundryLtd.Co` for **Pengwin**, `CanonicalGroupLimited` for **Ubuntu**, or `TheDebianProject` for **Debian**. Once you’ve identified the folder, you’ll find the VHDX in the `LocalState` subdirectory.
|
||||
|
||||
For me, this path is:
|
||||
`C:\Users\valorin\AppData\Local\Packages\WhitewaterFoundryLtd.Co.16571368D6CFF_kd...\LocalState\ext4.vhdx`
|
||||
|
||||
With the full path to the VHDX, you can select it within `diskpart`:
|
||||
|
||||
Once it’s selected, you can ask `diskpart` to compact it:
|
||||
|
||||
Once that has finished, you can close `diskpart`.
|
||||
|
||||
If you check your VHDX now, you should see it has reduced in size. It depends how much empty space was being used by WSL2 as to how big a space reduction there will be. In my case, it was quite significant:
|
||||
|
||||
I hope you found this useful. ?
|
||||
|
||||
Please let me know if you have an alternate way to shrink a WSL2 virtual disk – especially if it’s safer than this approach.
|
||||
@@ -1,137 +0,0 @@
|
||||
---
|
||||
title: How to String Split Example in Java - Tutorial
|
||||
source: https://javarevisited.blogspot.com/2011/09/how-to-string-split-example-in-java.html
|
||||
tags:
|
||||
- IT/Development/Java
|
||||
---
|
||||
|
||||
## [How to String Split Example in Java - Tutorial](https://javarevisited.blogspot.com/2011/09/how-to-string-split-example-in-java.html#axzz76j8BSDc2)
|
||||
|
||||
**Java String Split Example**
|
||||
|
||||
I don't know how many times I needed to Split a String in Java. Splitting a delimited String is a very common operation given various data sources e.g CSV file which contains input string in the form of large [String separated by the comma](http://javarevisited.blogspot.sg/2012/08/convert-collection-to-string-in-java.html). Splitting is necessary and Java API has great support for it. Java provides two convenience methods to **split strings** first within the java.lang.String class itself: split (regex) and other in **java.util.StringTokenizer**. Both are capable of splitting the string by any delimiter provided to them. Since [String is final in Java](http://javarevisited.blogspot.sg/2010/10/why-string-is-immutable-in-java.html) every split-ed String is a new [String in Java](http://javarevisited.blogspot.sg/2011/07/string-vs-stringbuffer-vs-stringbuilder.html).
|
||||
<a id="more"></a>
|
||||
|
||||
[](http://javarevisited.blogspot.com/2011/07/javalangunsupportedclassversionerror.html)In this article we will see *how to split a string in Java* both by using String’s split() method and StringTokenizer. If you have any doubt on anything related to split string please let me know and I will try to help.
|
||||
|
||||
Since String is one of the most common Class in Java and we always need to do something with String; I have created a lot of how to do with String examples e.g.
|
||||
|
||||
- [How to replace String in Java](http://javarevisited.blogspot.sg/2011/12/java-string-replace-example-tutorial.html),
|
||||
- [convert String to Date in Java](http://javarevisited.blogspot.sg/2011/09/convert-date-to-string-simpledateformat.html) or,
|
||||
- [convert String to Integer in Java](http://javarevisited.blogspot.sg/2011/08/convert-string-to-integer-to-string.html).
|
||||
|
||||
If you feel enthusiastic about String and you can also learn some bits from those post.
|
||||
|
||||
If you like to read interview articles about String in Java you can see :
|
||||
|
||||
### String Split Example Java
|
||||
|
||||
Let's see an example of *splitting the string in Java* by using the split() method of java.lang.String class:
|
||||
|
||||
**//split string example in Java**
|
||||
String assetClasses = "Gold:Stocks:Fixed Income:Commodity:Interest Rates";
|
||||
String\[\] splits = asseltClasses.split(":");
|
||||
|
||||
System.out.println("splits.size: " + splits.length);
|
||||
|
||||
for(String asset: splits){
|
||||
System.out.println(asset);
|
||||
}
|
||||
|
||||
OutPut
|
||||
splits.size: 5
|
||||
Gold
|
||||
Stocks
|
||||
Fixed Income
|
||||
Commodity
|
||||
Interest Rates
|
||||
|
||||
In above example, we have provided delimiter or separator as “:” to split function which expects a [regular expression](http://javarevisited.blogspot.sg/2012/08/how-to-format-string-in-java-printf.html) and used to split the string. When you pass a character as a regular expression than regex engine will only match that character, provided it's not a special character e.g. dot(.), star(*), question mark(?) etc.
|
||||
|
||||
You can use the same logic to [split a comma separated String in Java](http://javarevisited.blogspot.com/2015/12/how-to-split-comma-separated-string-in-java-example.html) or any other delimiter except the dot(.) and pipe(|) which requires special handling and described in the next paragraph or more detailed in [this](http://java67.blogspot.com/2013/03/how-to-split-string-in-java-regular-expression.html) article.
|
||||
|
||||
Now let see another *example of split using StringTokenizer*
|
||||
|
||||
**// String split example using StringTokenizer**
|
||||
StringTokenizer stringtokenizer = new StringTokenizer(asseltClasses, ":");
|
||||
while (stringtokenizer.hasMoreElements()) {
|
||||
System.out.println(stringtokenizer.nextToken());
|
||||
}
|
||||
|
||||
OutPut
|
||||
Gold
|
||||
Stocks
|
||||
Fixed Income
|
||||
Commodity
|
||||
Interest Rates
|
||||
|
||||
You can further see [this post](http://javarevisited.blogspot.com/2014/02/stringtokenizer-example-in-java-multiple-delimiters.html) to learn more about StringTokenizer. It's a legacy class, so I don't advise you to use it while writing new code, but if you are one of those developers, who is maintaining legacy code, it's imperative for you to know more about StringTokenizer.
|
||||
|
||||
You can also take a look at [Core Java Volume 1 - Fundamentals](https://javarevisited.blogspot.com/2017/02/top-5-core-java-books-for-beginners.html) by Cay S. Horstmann, the most reputed author in the Java programming world. I have read this book twice and can say it's one of the best in the market to learn subtle details of Java.
|
||||
|
||||
[](https://medium.com/javarevisited/5-best-core-java-books-for-beginners-20e3f723e3a)
|
||||
|
||||
## How to Split Strings in Java – 2 Examples
|
||||
|
||||
[<img width="200" height="168" src="../../../_resources/7_0e917ab397c8431994ffe179f1407d1c.jpg"/>](https://4.bp.blogspot.com/-SU3ogbJsBAk/TeJPfpAcPoI/AAAAAAAAALc/qwzYEjCLXQI/s1600/7.jpg)My personal favorite is String.split () because it’s defined in String class itself and its capability to handle regular expression which gives you immense power to [split the string](http://javarevisited.blogspot.sg/2012/03/how-to-compare-two-string-in-java.html) on any delimiter you ever need. Though it’s worth to remember following points about split method in Java
|
||||
|
||||
1) Some special characters need to be escaped while using them as delimiters or separators e.g. ***"." and "|".*** Both dot and pipe are special characters on a regular expression and that's why they need to be escaped. It becomes really tricky to split String on the dot if you don't know this details and often face the issue described in [this](http://javarevisited.blogspot.com/2016/02/2-ways-to-split-string-with-dot-in-java-using-regular-expression.html) article.
|
||||
|
||||
**//string split on special character “|”**
|
||||
String assetTrading = "Gold Trading|Stocks Trading
|
||||
|Fixed Income Trading|Commodity Trading|FX trading";
|
||||
|
||||
String\[\] splits = assetTrading.split("\\\|");
|
||||
// two \\\ is required because "\\" itself require escaping
|
||||
|
||||
for(String trading: splits){
|
||||
System.out.println(trading);
|
||||
}
|
||||
|
||||
Output:
|
||||
Gold Trading
|
||||
Stocks Trading
|
||||
Fixed Income Trading
|
||||
Commodity Trading
|
||||
FX trading
|
||||
|
||||
**// split string on “.”**
|
||||
String smartPhones = "Apple IPhone.HTC Evo3D.Nokia N9.LG
|
||||
Optimus.Sony Xperia.Samsung Charge";
|
||||
|
||||
String\[\] smartPhonesSplits = smartPhones.split("\\\.");
|
||||
|
||||
for(String smartPhone: smartPhonesSplits){
|
||||
System.out.println(smartPhone);
|
||||
}
|
||||
|
||||
|
||||
OutPut:
|
||||
Apple IPhone
|
||||
HTC Evo3D
|
||||
Nokia N9
|
||||
LG Optimus
|
||||
Sony Xperia
|
||||
Samsung Charge
|
||||
|
||||
2) You can control a number of splitting by using [overloaded](http://javarevisited.blogspot.sg/2011/12/method-overloading-vs-method-overriding.html) version split (regex, limit). If you give a limit of 2 it will only create two strings. For example, in the following example, we could have a total of 4 splits but if we just wanted to create 2, to achieve that we have used a **limit**. You can further see these [core Java courses](https://javarevisited.blogspot.com/2020/04/top-10-advanced-core-java-courses-for-experienced-developers.html) to learn more about the advanced splitting of String in Java.
|
||||
|
||||
**//string split example with limit**
|
||||
|
||||
String places = "London.Switzerland.Europe.Australia";
|
||||
String\[\] placeSplits = places.split("\\\.",2);
|
||||
|
||||
System.out.println("placeSplits.size: " + placeSplits.length );
|
||||
|
||||
for(String contents: placeSplits){
|
||||
System.out.println(contents);
|
||||
}
|
||||
|
||||
Output:
|
||||
placeSplits.size: 2
|
||||
London
|
||||
Switzerland.Europe.Australia
|
||||
|
||||
To conclude the topic StringTokenizer is the old way of tokenizing string and with the introduction of the split since JDK 1.4 its usage is discouraged. No matter what kind of project you work you often need to *split a string in Java* so better get familiar with these APIs.
|
||||
|
||||
**Related Java tutorials**
|
||||
@@ -1,334 +0,0 @@
|
||||
---
|
||||
title: How to Write a Git Commit Message
|
||||
tags:
|
||||
- IT/Development/Git
|
||||
---
|
||||
|
||||
|
||||
How to Write a Git Commit Message
|
||||
31 Aug 2014
|
||||
Introduction | The Seven Rules | Tips
|
||||
|
||||
Introduction: Why good commit messages matter
|
||||
|
||||
If you browse the log of any random git repository you will probably find its commit messages are more or less a mess. For example, take a look at these gems from my early days committing to Spring:
|
||||
|
||||
$ git log --oneline -5 --author cbeams --before "Fri Mar 26 2009"
|
||||
|
||||
e5f4b49 Re-adding ConfigurationPostProcessorTests after its brief removal in r814. @Ignore-ing the testCglibClassesAreLoadedJustInTimeForEnhancement() method as it turns out this was one of the culprits in the recent build breakage. The classloader hacking causes subtle downstream effects, breaking unrelated tests. The test method is still useful, but should only be run on a manual basis to ensure CGLIB is not prematurely classloaded, and should not be run as part of the automated build.
|
||||
2db0f12 fixed two build-breaking issues: + reverted ClassMetadataReadingVisitor to revision 794 + eliminated ConfigurationPostProcessorTests until further investigation determines why it causes downstream tests to fail (such as the seemingly unrelated ClassPathXmlApplicationContextTests)
|
||||
147709f Tweaks to package-info.java files
|
||||
22b25e0 Consolidated Util and MutableAnnotationUtils classes into existing AsmUtils
|
||||
7f96f57 polishing
|
||||
|
||||
Yikes. Compare that with these more recent commits from the same repository:
|
||||
|
||||
$ git log --oneline -5 --author pwebb --before "Sat Aug 30 2014"
|
||||
|
||||
5ba3db6 Fix failing CompositePropertySourceTests
|
||||
84564a0 Rework @PropertySource early parsing logic
|
||||
e142fd1 Add tests for ImportSelector meta-data
|
||||
887815f Update docbook dependency and generate epub
|
||||
ac8326d Polish mockito usage
|
||||
|
||||
Which would you rather read?
|
||||
|
||||
The former varies wildly in length and form; the latter is concise and consistent. The former is what happens by default; the latter never happens by accident.
|
||||
|
||||
While many repositories' logs look like the former, there are exceptions. The Linux kernel and git itself are great examples. Look at Spring Boot, or any repository managed by Tim Pope.
|
||||
|
||||
The contributors to these repositories know that a well-crafted git commit message is the best way to communicate context about a change to fellow developers (and indeed to their future selves). A diff will tell you what changed, but only the commit message can properly tell you why. Peter Hutterer makes this point well:
|
||||
|
||||
Re-establishing the context of a piece of code is wasteful. We can't avoid it completely, so our efforts should go to reducing it [as much] as possible. Commit messages can do exactly that and as a result, a commit message shows whether a developer is a good collaborator.
|
||||
|
||||
If you haven't given much thought to what makes a great git commit message, it may be the case that you haven't spent much time using git log and related tools. There is a vicious cycle here: because the commit history is unstructured and inconsistent, one doesn't spend much time using or taking care of it. And because it doesn't get used or taken care of it, it remains unstructured and inconsistent.
|
||||
|
||||
But a well-cared for log is a beautiful and useful thing. git blame, revert, rebase, log, shortlog and other subcommands come to life. Reviewing others' commits and pull requests becomes something worth doing, and suddenly can be done independently. Understanding why something happpened months or years ago becomes not only possible but efficient.
|
||||
|
||||
A project's long-term success rests (among other things) on its maintainability, and a maintainer has few tools more powerful than his project's log. It's worth taking the time to learn how to care for one properly. What may be a hassle at first soon becomes habit, and eventually a source of pride and productivity for all involved.
|
||||
|
||||
In this post, I am addressing just the most basic element of keeping a healthy commit history: how to write an individual commit message. There are other important practices like commit squashing that I am not addressing here. Perhaps I'll do that in a subsequent post.
|
||||
|
||||
Most programming languages have well-established conventions as to what constitutes idiomatic style, i.e. naming and formatting and so on. There are variations on these conventions, of course, but most developers agree that picking one and sticking to it is far better than the chaos that ensues when everybody does their own thing.
|
||||
|
||||
A team's approach to its commit log should be no different. In order to create a useful revision history, teams should first agree on a commit message convention that defines at least the following three things:
|
||||
|
||||
Style. Markup syntax, wrap margins, grammar, capitalization, punctuation. Spell these things out, remove the guesswork, and make it all as simple as possible. The end result will be a remarkably consistent log that's not only a pleasure to read but that actually does get read on a regular basis.
|
||||
|
||||
Content. What kind of information should the body of the commit message (if any) contain? What should it not contain?
|
||||
|
||||
Metadata. How should issue tracking IDs, pull request numbers, etc. be referenced?
|
||||
|
||||
Fortunately, there are well-established conventions as to what makes an idiomatic git commit message. Indeed, many of them are assumed in the way certain git commands function. There's nothing you need to re-invent. Just follow the seven rules below and you're on your way to committing like a pro.
|
||||
|
||||
The seven rules of a great git commit message
|
||||
|
||||
Keep in mind: This has all been said before.
|
||||
|
||||
Separate subject from body with a blank line
|
||||
Limit the subject line to 50 characters
|
||||
Capitalize the subject line
|
||||
Do not end the subject line with a period
|
||||
Use the imperative mood in the subject line
|
||||
Wrap the body at 72 characters
|
||||
Use the body to explain what and why vs. how
|
||||
|
||||
For example:
|
||||
|
||||
Summarize changes in around 50 characters or less
|
||||
|
||||
More detailed explanatory text, if necessary. Wrap it to about 72
|
||||
characters or so. In some contexts, the first line is treated as the
|
||||
subject of the commit and the rest of the text as the body. The
|
||||
blank line separating the summary from the body is critical (unless
|
||||
you omit the body entirely); various tools like `log`, `shortlog`
|
||||
and `rebase` can get confused if you run the two together.
|
||||
|
||||
Explain the problem that this commit is solving. Focus on why you
|
||||
are making this change as opposed to how (the code explains that).
|
||||
Are there side effects or other unintuitive consequenses of this
|
||||
change? Here's the place to explain them.
|
||||
|
||||
Further paragraphs come after blank lines.
|
||||
|
||||
- Bullet points are okay, too
|
||||
|
||||
- Typically a hyphen or asterisk is used for the bullet, preceded
|
||||
by a single space, with blank lines in between, but conventions
|
||||
vary here
|
||||
|
||||
If you use an issue tracker, put references to them at the bottom,
|
||||
like this:
|
||||
|
||||
Resolves: #123
|
||||
See also: #456, #789
|
||||
|
||||
1. Separate subject from body with a blank line
|
||||
|
||||
From the git commit manpage:
|
||||
|
||||
Though not required, it's a good idea to begin the commit message with a single short (less than 50 character) line summarizing the change, followed by a blank line and then a more thorough description. The text up to the first blank line in a commit message is treated as the commit title, and that title is used throughout Git. For example, git-format-patch(1) turns a commit into email, and it uses the title on the Subject line and the rest of the commit in the body.
|
||||
|
||||
Firstly, not every commit requires both a subject and a body. Sometimes a single line is fine, especially when the change is so simple that no further context is necessary. For example:
|
||||
|
||||
Fix typo in introduction to user guide
|
||||
|
||||
Nothing more need be said; if the reader wonders what the typo was, she can simply take a look at the change itself, i.e. use git show or git diff or git log -p.
|
||||
|
||||
If you're committing something like this at the command line, it's easy to use the -m switch to git commit:
|
||||
|
||||
$ git commit -m"Fix typo in introduction to user guide"
|
||||
|
||||
However, when a commit merits a bit of explanation and context, you need to write a body. For example:
|
||||
|
||||
Derezz the master control program
|
||||
|
||||
MCP turned out to be evil and had become intent on world domination.
|
||||
This commit throws Tron's disc into MCP (causing its deresolution)
|
||||
and turns it back into a chess game.
|
||||
|
||||
This is not so easy to commit this with the -m switch. You really need a proper editor. If you do not already have an editor set up for use with git at the command line, read this section of Pro Git.
|
||||
|
||||
In any case, the separation of subject from body pays off when browsing the log. Here's the full log entry:
|
||||
|
||||
$ git log
|
||||
commit 42e769bdf4894310333942ffc5a15151222a87be
|
||||
Author: Kevin Flynn <kevin@flynnsarcade.com>
|
||||
Date: Fri Jan 01 00:00:00 1982 -0200
|
||||
|
||||
Derezz the master control program
|
||||
|
||||
MCP turned out to be evil and had become intent on world domination.
|
||||
This commit throws Tron's disc into MCP (causing its deresolution)
|
||||
and turns it back into a chess game.
|
||||
|
||||
And now git log --oneline, which prints out just the subject line:
|
||||
|
||||
$ git log --oneline
|
||||
42e769 Derezz the master control program
|
||||
|
||||
Or, git shortlog, which groups commits by user, again showing just the subject line for concision:
|
||||
|
||||
$ git shortlog
|
||||
Kevin Flynn (1):
|
||||
Derezz the master control program
|
||||
|
||||
Alan Bradley (1):
|
||||
Introduce security program "Tron"
|
||||
|
||||
Ed Dillinger (3):
|
||||
Rename chess program to "MCP"
|
||||
Modify chess program
|
||||
Upgrade chess program
|
||||
|
||||
Walter Gibbs (1):
|
||||
Introduce protoype chess program
|
||||
|
||||
There are a number of other contexts in git where the distinction between subject line and body kicks in—but none of them work properly without the blank line in between.
|
||||
|
||||
2. Limit the subject line to 50 characters
|
||||
|
||||
50 characters is not a hard limit, just a rule of thumb. Keeping subject lines at this length ensures that they are readable, and forces the author to think for a moment about the most concise way to explain what's going on.
|
||||
|
||||
Tip: If you're having a hard time summarizing, you might be committing too many changes at once. Strive for atomic commits (a topic for a separate post).
|
||||
|
||||
GitHub's UI is fully aware of these conventions. It will warn you if you go past the 50 character limit:
|
||||
|
||||
gh1
|
||||
|
||||
And will truncate any subject line longer than 69 characters with an ellipsis:
|
||||
|
||||
gh2
|
||||
|
||||
So shoot for 50 characters, but consider 69 the hard limit.
|
||||
|
||||
3. Capitalize the subject line
|
||||
|
||||
This is as simple as it sounds. Begin all subject lines with a capital letter.
|
||||
|
||||
For example:
|
||||
|
||||
Accelerate to 88 miles per hour
|
||||
|
||||
Instead of:
|
||||
|
||||
accelerate to 88 miles per hour
|
||||
|
||||
4. Do not end the subject line with a period
|
||||
|
||||
Trailing punctuation is unnecessary in subject lines. Besides, space is precious when you're trying to keep them to 50 chars or less.
|
||||
|
||||
Example:
|
||||
|
||||
Open the pod bay doors
|
||||
|
||||
Instead of:
|
||||
|
||||
Open the pod bay doors.
|
||||
|
||||
5. Use the imperative mood in the subject line
|
||||
|
||||
Imperative mood just means "spoken or written as if giving a command or instruction". A few examples:
|
||||
|
||||
Clean your room
|
||||
Close the door
|
||||
Take out the trash
|
||||
|
||||
Each of the seven rules you're reading about right now are written in the imperative ("Wrap the body at 72 characters", etc).
|
||||
|
||||
The imperative can sound a little rude; that's why we don't often use it. But it's perfect for git commit subject lines. One reason for this is that git itself uses the imperative whenever it creates a commit on your behalf.
|
||||
|
||||
For example, the default message created when using git merge reads:
|
||||
|
||||
Merge branch 'myfeature'
|
||||
|
||||
And when using git revert:
|
||||
|
||||
Revert "Add the thing with the stuff"
|
||||
|
||||
This reverts commit cc87791524aedd593cff5a74532befe7ab69ce9d.
|
||||
|
||||
Or when clicking the "Merge" button on a GitHub pull request:
|
||||
|
||||
Merge pull request #123 from someuser/somebranch
|
||||
|
||||
So when you write your commit messages in the imperative, you're following git's own built-in conventions. For example:
|
||||
|
||||
Refactor subsystem X for readability
|
||||
Update getting started documentation
|
||||
Remove deprecated methods
|
||||
Release version 1.0.0
|
||||
|
||||
Writing this way can be a little awkward at first. We're more used to speaking in the indicative mood, which is all about reporting facts. That's why commit messages often end up reading like this:
|
||||
|
||||
Fixed bug with Y
|
||||
Changing behavior of X
|
||||
|
||||
And sometimes commit messages get written as a description of their contents:
|
||||
|
||||
More fixes for broken stuff
|
||||
Sweet new API methods
|
||||
|
||||
To remove any confusion, here's a simple rule to get it right every time.
|
||||
|
||||
A properly formed git commit subject line should always be able to complete the following sentence:
|
||||
|
||||
If applied, this commit will your subject line here
|
||||
|
||||
For example:
|
||||
|
||||
If applied, this commit will refactor subsystem X for readability
|
||||
If applied, this commit will update getting started documentation
|
||||
If applied, this commit will remove deprecated methods
|
||||
If applied, this commit will release version 1.0.0
|
||||
If applied, this commit will merge pull request #123 from user/branch
|
||||
|
||||
Notice how this doesn't work for the other non-imperative forms:
|
||||
|
||||
If applied, this commit will fixed bug with Y
|
||||
If applied, this commit will changing behavior of X
|
||||
If applied, this commit will more fixes for broken stuff
|
||||
If applied, this commit will sweet new API methods
|
||||
|
||||
Remember: Use of the imperative is important only in the subject line. You can relax this restriction when you're writing the body.
|
||||
|
||||
6. Wrap the body at 72 characters
|
||||
|
||||
Git never wraps text automatically. When you write the body of a commit message, you must mind its right margin, and wrap text manually.
|
||||
|
||||
The recommendation is to do this at 72 characters, so that git has plenty of room to indent text while still keeping everything under 80 characters overall.
|
||||
|
||||
A good text editor can help here. It's easy to configure Vim, for example, to wrap text at 72 characters when you're writing a git commit. Traditionally, however, IDEs have been terrible at providing smart support for text wrapping in commit messages (although in recent versions, IntelliJ IDEA has finally gotten better about this).
|
||||
|
||||
7. Use the body to explain what and why vs. how
|
||||
|
||||
This commit from Bitcoin Core is a great example of explaining what changed and why:
|
||||
|
||||
commit eb0b56b19017ab5c16c745e6da39c53126924ed6
|
||||
Author: Pieter Wuille <pieter.wuille@gmail.com>
|
||||
Date: Fri Aug 1 22:57:55 2014 +0200
|
||||
|
||||
Simplify serialize.h's exception handling
|
||||
|
||||
Remove the 'state' and 'exceptmask' from serialize.h's stream
|
||||
implementations, as well as related methods.
|
||||
|
||||
As exceptmask always included 'failbit', and setstate was always
|
||||
called with bits = failbit, all it did was immediately raise an
|
||||
exception. Get rid of those variables, and replace the setstate
|
||||
with direct exception throwing (which also removes some dead
|
||||
code).
|
||||
|
||||
As a result, good() is never reached after a failure (there are
|
||||
only 2 calls, one of which is in tests), and can just be replaced
|
||||
by !eof().
|
||||
|
||||
fail(), clear(n) and exceptions() are just never called. Delete
|
||||
them.
|
||||
|
||||
Take a look at the full diff and just think how much time the author is saving fellow and future committers by taking the time to provide this context here and now. If he didn't, it would probably be lost forever.
|
||||
|
||||
In most cases, you can leave out details about how a change has been made. Code is generally self-explanatory in this regard (and if the code is so complex that it needs to be explained in prose, that's what source comments are for). Just focus on making clear the reasons you made the change in the first place—the way things worked before the change (and what was wrong with that), the way they work now, and why you decided to solve it the way you did.
|
||||
|
||||
The future maintainer that thanks you may be yourself!
|
||||
|
||||
Tips
|
||||
Learn to love the command line. Leave the IDE behind.
|
||||
|
||||
For as many reasons as there are git subcommands, it's wise to embrace the command line. Git is insanely powerful; IDEs are too, but each in different ways. I use an IDE every day (IntelliJ IDEA) and have used others extensively (Eclipse), but I have never seen IDE integration for git that could begin to match the ease and power of the command line (once you know it).
|
||||
|
||||
Certain git-related IDE functions are invaluable, like calling git rm when you delete a file, and doing the right stuff with git when you rename one. Where everything falls apart is when you start trying to commit, merge, rebase, or do sophisticated history analysis through the IDE.
|
||||
|
||||
When it comes to wielding the full power of git, it's command-line all the way.
|
||||
|
||||
Remember that whether you use Bash or Z shell, there are tab completion scripts that take much of the pain out of remembering the subcommands and switches.
|
||||
Read Pro Git
|
||||
|
||||
The [Pro Git](http://git-scm.com/book) book is available online for free, and it's fantastic. Take advantage!
|
||||
[Disqus]
|
||||
home | subscribe | more...
|
||||
|
||||
|
||||
Evernote hilft dir, nichts zu vergessen und alles mühelos zu ordnen und zu organisieren. Evernote herunterladen.
|
||||
|
||||
|
||||
@@ -1,373 +0,0 @@
|
||||
---
|
||||
title: titles - How to customize my titlepage? - TeX
|
||||
source: https://tex.stackexchange.com/questions/209993/how-to-customize-my-titlepage
|
||||
tags:
|
||||
- IT/Development/LaTeX
|
||||
---
|
||||
|
||||
[The titlepage is one of the first pages of a book or thesis. This page contains only the title in a fashion similar to the rest of the text within the book.](http://en.wikipedia.org/wiki/Title_page)
|
||||
|
||||
That is what Wikipedia tells us, now we have a perspective to follow, the titlepage should match the appearance of the rest of the book or thesis. Let us look at the standard scrbook titlepage.
|
||||
|
||||
```latex
|
||||
\documentclass{scrbook}
|
||||
\usepackage[utf8]{inputenc}
|
||||
\usepackage[T1]{fontenc}
|
||||
\usepackage[english,french]{babel}
|
||||
\makeatletter
|
||||
\newcommand{\fakechap}[1]{{\noindent\normalfont\sectfont\nobreak\size@chapter{}#1\par}\chapterheadendvskip\noindent\ignorespaces}
|
||||
\makeatother
|
||||
\subject{Doctoral thesis}
|
||||
\title{On ducks and their love for dissertations}
|
||||
\subtitle{A fiction story telling the truth}
|
||||
\author{domi}
|
||||
\publishers{Published by the publisher\\ at a secret location}
|
||||
%\extratitle{Stories of ducks}
|
||||
\uppertitleback{\vspace{3cm}I want to thank Scrooge MacDuck for his financial Support}
|
||||
\date{}
|
||||
\usepackage{blindtext}
|
||||
\begin{document}
|
||||
\frontmatter
|
||||
\maketitle
|
||||
|
||||
\tableofcontents
|
||||
\addchap{Résumé}
|
||||
Résumé de la thèse en français\dots
|
||||
\blindtext
|
||||
\vfill
|
||||
|
||||
\selectlanguage{english}
|
||||
\fakechap{Summary}
|
||||
Résumé de la thèse en anglais\dots
|
||||
\blindtext
|
||||
\vfill
|
||||
|
||||
\selectlanguage{french}
|
||||
\end{document}}
|
||||
```
|
||||
|
||||

|
||||
|
||||
Command `\maketitle` places the predefined elements on the first page. If you want, you can change the font using the usual `\addtokomafont`-mechanism.
|
||||
|
||||
There are more elements available, e.g. `\publishers`, `\titlehead` and `\extratitle`. Additional elements are only typeset if they have been define by the user with some argument. In other words, no space is reserved just in case.
|
||||
|
||||
Book classes do not provide an `abstract` environment as it is usual for books to have a whole chapter to sum up the contents. I defined a `\fakechap` command to have both on the same page and look alike. To be honest, it is a bit of a hack, a chapter should be of its own. Please note the difference in using `\addchap`. If you are interested, you can find out more at [How to use unnumbered chapters with KOMA-script?](https://tex.stackexchange.com/questions/193767/how-to-use-unnumbered-chapters-with-koma-script/193799#193799).
|
||||
|
||||
What happens if we are using `\extratitle` to the above MWE?
|
||||
An additional pair of pages has been generated in the very beginning. Seems to be a strange location for a title. This is a fact of history, as books didn't have a hard cover a while back. This extra title protected the book from dirt. It is also called a _bastard title_.
|
||||
|
||||
Default option for book classes is the start of new chapters on odd (right hand) pages. That means for us, we get a blank page between title and the first chapter. If we set `\uppertitleback` we can place a thanks note, or something else. You can even use spaces if you need to customize a little bit.
|
||||
|
||||
But who decided where the elements set with `\title`, `\author` and co are placed? It is the author of the class. In the case of KOMA-script it was Markus Kohm. That brings us to our next question:
|
||||
|
||||
Relatively simple, as LaTeX is a macro language to place boxes. It is like having a huge lego set and put pieces together until satisfied with the solution.
|
||||
|
||||
As we now want to do the titlepage with our own hands, we don't call `\maketitle` that would do the default stuff. Since we don't use `\maketitle` we don't need to set the fields for it. No need for `\title{this is the title}` et al. _If you are using `\maketitle` together with the `titlepage`-environment, you are doing something wrong._
|
||||
|
||||
```latex
|
||||
\documentclass{report}
|
||||
\usepackage{blindtext}
|
||||
\begin{document}
|
||||
\begin{titlepage}
|
||||
Dixie dancing ducks
|
||||
|
||||
A story of love, hate and fame
|
||||
\end{titlepage}
|
||||
\chapter{Summary}
|
||||
\blindtext
|
||||
\end{document}
|
||||
```
|
||||
|
||||

|
||||
|
||||
Not very pleasing to the eye. We forgot to use the right pieces to modify it. Some tweaks lead us to this:
|
||||
|
||||
```latex
|
||||
\documentclass{report}
|
||||
\usepackage{blindtext}
|
||||
%\usepackage{showframe}
|
||||
\begin{document}
|
||||
\begin{titlepage}
|
||||
\vspace*{9em}{\centering\Huge\usefont{T1}{qzc}{m}{it}
|
||||
Dixie dancing ducks\par}
|
||||
\vspace{1em}
|
||||
{\hfill\itshape A story of love, hate and fame}
|
||||
\clearpage
|
||||
\vspace*{\fill}\hfill \parbox{.4\textwidth}{
|
||||
\raggedleft
|
||||
\scriptsize Delilah was a sad duck with a dream, being a
|
||||
Dixie dancer some day. She wasn't the best looking duck
|
||||
in town but she never cared about superficial things.
|
||||
Practicing a lot she finally became a professional Dixie
|
||||
dancer. She even fell in love. Will Delilah overcome the
|
||||
infamy and hate of her \emph{new gained friends}?
|
||||
}
|
||||
\end{titlepage}
|
||||
\chapter{Summary}
|
||||
\blindtext
|
||||
\end{document}
|
||||
```
|
||||
|
||||

|
||||
|
||||
Looks much better, but the page number is screwed. Using a KOMA-class can save the day.
|
||||
|
||||
* * *
|
||||
|
||||
Now an example that might be used as a cover for a thesis. Using the `addmargin`-environment, we can get some asynchronity for the titlepage. Package `mwe` gives us some dummy pictures, we could use the universities logo instead.
|
||||
|
||||
> 
|
||||
|
||||
```latex
|
||||
\documentclass{scrreprt}
|
||||
\usepackage{graphicx}
|
||||
\begin{document}
|
||||
\begin{titlepage}
|
||||
\begin{addmargin}[4cm]{-1cm}
|
||||
\centering
|
||||
\hfill\includegraphics[width=2cm]{example-image-1x1}\par
|
||||
\vspace{4\baselineskip}
|
||||
{\Huge Peter Piper picked a peck\\ of pickled peppers\par}
|
||||
\vspace{4\baselineskip}
|
||||
by\par
|
||||
{\Large\textsc{Crazy Capybara}\par}
|
||||
\vfill
|
||||
in order to get a fancy degree at\par
|
||||
{\em The university of applied dice rolling}
|
||||
\end{addmargin}
|
||||
\end{titlepage}
|
||||
\end{document}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
A titlepage for a scientific article is also possible. If the journal provides no template, there is mostly no use in bothering to implement their style, they will happily do it for you.
|
||||
|
||||
This will be just an example, if you are really working on a titlepage for a journal, take the solid approach as mentioned later on. Al this manual fixing up should not been done twice to get the same output.
|
||||
|
||||
```latex
|
||||
\documentclass[twoside,ngerman]{article}
|
||||
\usepackage{blindtext}
|
||||
\usepackage{babel}
|
||||
\usepackage{hyperref}
|
||||
|
||||
\begin{document}
|
||||
\twocolumn[%
|
||||
\centering
|
||||
\begin{minipage}{.75\textwidth}
|
||||
\begin{center}
|
||||
{\large
|
||||
Pendulum\par}
|
||||
presents\par
|
||||
{\Large The sonic recreation of \\the end of the world\par}
|
||||
\end{center}
|
||||
\vspace{\baselineskip}
|
||||
\setlength{\parskip}{\smallskipamount}
|
||||
Ladies and gentlemen, We understand that you Have come tonight
|
||||
To bear witness to the sound Of drum And Bass.
|
||||
|
||||
We regret to announce That this is not the case, As instead We
|
||||
come tonight to bring you The sonic recreation of the end of
|
||||
the world.
|
||||
|
||||
Ladies and gentlemen, Prepare To \dots\par
|
||||
\rule{7em}{.4pt}\par
|
||||
Rob Swire, Gareth McGrillen, and Paul
|
||||
Harding;\par \href{mailto:someone@gmail.com}{Mail the
|
||||
authors}
|
||||
\end{minipage}
|
||||
\vspace{2\baselineskip}
|
||||
]
|
||||
\section{Hold Your Colour}
|
||||
\blindtext
|
||||
|
||||
\blindtext
|
||||
\end{document}
|
||||
```
|
||||
|
||||

|
||||
|
||||
A collection of different titlepages that can lead to your very own customized titlepage can be found at [Titlepage](http://ctan.org/pkg/titlepages). I'll also try to collect some [titlepages on github](https://github.com/johannesbottcher/titlepages).
|
||||
|
||||
The natural approach to use the rock solid KOMA-interface is impossible, as the author of `classicthesis` decided to implement things in _another_ way. We would have to put the commands inside the definition, which feels like rape to me, so no example for this. We are back at putting lego pieces together
|
||||
|
||||
```latex
|
||||
\documentclass[12pt,a4paper,footinclude=true,twoside,headinclude=true,headings=optiontoheadandtoc]{scrbook}
|
||||
%\usepackage{geometry}
|
||||
%\geometry{marginparsep=8pt,left=3.5cm,right=3.5cm,top=3cm,bottom=3cm}
|
||||
\usepackage[parts,pdfspacing,dottedtoc]{classicthesis}
|
||||
\usepackage[utf8]{inputenc}
|
||||
\makeatletter
|
||||
\newcommand{\fakechap}[1]{{\noindent\normalfont\sectfont\nobreak\size@chapter{}#1\par}\chapterheadendvskip\noindent\ignorespaces}
|
||||
\makeatother
|
||||
\usepackage{blindtext}
|
||||
\begin{document}
|
||||
\frontmatter
|
||||
\begin{titlepage}
|
||||
\vspace*{7em}
|
||||
\begin{center}
|
||||
{\Large \spacedallcaps{is it really worth the trouble?}
|
||||
\bigbreak}
|
||||
An assessment of spent time adjusting badly
|
||||
implemented \LaTeX{} templates \\[2em]
|
||||
{\scriptsize \spacedlowsmallcaps{The author}}
|
||||
\end{center}
|
||||
\end{titlepage}
|
||||
|
||||
\tableofcontents
|
||||
\addchap{Résumé}
|
||||
Résumé de la thèse en français\dots
|
||||
\blindtext[13]
|
||||
\vfill
|
||||
|
||||
\fakechap{Summary}
|
||||
No, simple as that.
|
||||
\blindtext
|
||||
\vfill
|
||||
\end{document}}
|
||||
```
|
||||
|
||||

|
||||
|
||||
The titlepage looks ok, but---having an up to date TeX installation---we get a huge warning and looking at the next page we are shocked. Our predefined _fakechap_ doesn't match. `classicthesis` loads package `titlesec` which is incompatible with KOMA. `titlesec` adds features to the LaTeX standard classes, `memoir` has its own way of customizing things, `KOMA` as well. Some functionality is broken.
|
||||
|
||||
For advanced users
|
||||
|
||||
If the layout of the titlepage is fixed by some rules or guidelines of a corporate design, we need to make sure the user doesn't change the appearance. We use the same concept of defining a titlepage, but hide it in a package file (or possibly a class file). Just like the standard classes, we define a set of macros for the user (`author`, `title`, `degree` etc.). The user can input his or her data in the document with no need to care about what is going on in the background and can just call `\maketitle`. A very basic and non-advanced example:
|
||||
|
||||
```latex
|
||||
\begin{filecontents}{domititlepage.sty}
|
||||
\ProvidesPackage{domititlepage}[2014/11/03 titlepages domi style]
|
||||
%There is absolutely no warranty for this demo package
|
||||
% https://tex.stackexchange.com/questions/209993/how-to-add-a-flyleaf-code/210280#210280
|
||||
\RequirePackage{etoolbox}
|
||||
\ifundef{\KOMAClassName}{
|
||||
\@ifclassloaded{memoir}{\PackageWarningNoLine{domititlepage}{Using
|
||||
memoir. Memoir has its own mechanism of
|
||||
generating stuff. Not loading
|
||||
`scrextend'. Aborting now}
|
||||
\endinput
|
||||
}{
|
||||
\typeout{You seem to be using a standard class.
|
||||
Using package `scrextend' for nice
|
||||
features}
|
||||
\RequirePackage[extendedfeature=title]{scrextend}
|
||||
}
|
||||
\typeout{non-KOMA branch}
|
||||
}{
|
||||
\typeout{Using a KOMA class, no need to load package scrextend}
|
||||
}
|
||||
\newcommand{\@supervisor}{}
|
||||
\newcommand{\supervisor}[1]{\gdef\@supervisor{#1}}
|
||||
\newkomafont{supervisor}{\normalfont\normalsize}
|
||||
\newcommand{\@degree}{}
|
||||
\newcommand{\degree}[1]{\gdef\@degree{#1}}
|
||||
\newkomafont{degree}{\normalfont\normalsize}
|
||||
\newcommand*{\@thanksnote}{}
|
||||
\newcommand*{\thanksnote}[1]{\gdef\@thanksnote{#1}}
|
||||
\newkomafont{thanksnote}{\small\itshape}
|
||||
\newcommand{\@@thanksnote}{\begin{minipage}{\linewidth}
|
||||
\usekomafont{thanksnote}\@thanksnote\par\end{minipage}\par}
|
||||
\renewcommand{\maketitle}{%
|
||||
\begin{titlepage}
|
||||
\setlength{\parindent}{\z@}
|
||||
\setlength{\parskip}{\z@}
|
||||
\typeout{Typesetting the titlepage}
|
||||
\vspace{-1em}
|
||||
\begin{minipage}[t]{\textwidth}
|
||||
\centering
|
||||
University for theoretical and applied animal dance in Duckburg\par
|
||||
\end{minipage}\par
|
||||
\vspace{7em}
|
||||
{\LARGE\centering\usefont{T1}{qcs}{b}{n} \@title\par}
|
||||
\vspace{5em}
|
||||
{\usekomafont{author}\centering \@author\par}
|
||||
\vspace{2em}
|
||||
\ifx\@degree\@empty \else
|
||||
{\centering\usekomafont{degree}\@degree\par}
|
||||
\fi
|
||||
\next@tpage
|
||||
\ifx\@thanksnote\@empty\hbox{} \else
|
||||
{\@@thanksnote}
|
||||
\fi
|
||||
\vfill
|
||||
\begin{minipage}{10em}
|
||||
\raggedright
|
||||
\usefont{T1}{qcr}{m}{n}
|
||||
No animals were harmed
|
||||
during the production of
|
||||
this printed work\par
|
||||
\end{minipage}
|
||||
\end{titlepage}%
|
||||
}
|
||||
\end{filecontents}
|
||||
\documentclass{scrbook}
|
||||
\usepackage{domititlepage}
|
||||
\usepackage{blindtext}
|
||||
\author{Paulo Lee Peterson}
|
||||
\title{Polka loving Platypus}
|
||||
%\degree{Master of Stuff}
|
||||
%\thanksnote{Thanks to Daisy for her support}
|
||||
|
||||
\begin{document}
|
||||
\maketitle
|
||||
\chapter{Introduction to Polka dancing}
|
||||
\blindtext
|
||||
\end{document}
|
||||
```
|
||||
|
||||
The above uses a little trick to save us time, it writes the contents of the first environment (filecontents) to a new file (called `domititlepage.sty`), which gives us a solid LaTeX-package the user can load in the preamble.
|
||||
|
||||
The heading of this section said something about a solid method, right before the example, i said it is non-advanced. What is going on? We are defining some simple to remember commands like `author` and `degree`. As the appearance of the titlepage is given and therefore fixed, it doesn't matter in which order the user types in its data, our `\maketitle` command takes care of typesetting everything where it is supposed to be according to the guidelines. A few things a kept variable. There is an easy to use interface to set the font of some elements provided by KOMA-scripts font selection features. The user can decide whether he wants to give a thanksnote or leave that out. The package handles this.
|
||||
|
||||
Almost all code is hidden from the user, who might be intimidated, hence the user cannot change anything without a bit of effort. This seems to be quite solid, so why is it non advanced? The above is a syntax/language mix-up of `TeX`, `LaTe2eX` and maybe a bit of LaTeX3 in the future. This is quite bad style.
|
||||
|
||||

|
||||
|
||||
The author of KOMA-script started a project called `titlepage` a few years back collecting different titlepages, defining different languages and hence making the titlepages rock solid. The zip folder can be downloaded at the [KOMA-project website](http://www.komascript.de/titlepage).
|
||||
|
||||
Package `titlepage` provides a new interface for `\maketitle` making it possible to give the relevant information in a quite handy _key-value-syntax_. Not all styles (loaded by `\TitlePageStyle{<style>}`) support all possible fields.
|
||||
|
||||
The thing is though, in order to get the titlepage of your university available with the `titlepage` package, you need to get in contact with the author of KOMA-script.
|
||||
|
||||
```latex
|
||||
%% Copyright (c) 2011 by Markus Kohm <komascript(at)gmx.info>
|
||||
\documentclass[a4paper,pagesize]{scrbook}
|
||||
\usepackage[utf8]{inputenc}
|
||||
\usepackage[ngerman]{babel}
|
||||
\usepackage[T1]{fontenc}
|
||||
\usepackage{lmodern}
|
||||
\usepackage[demo]{graphicx}% remove option demo if you have the logo
|
||||
\usepackage{xcolor}
|
||||
\usepackage{titlepage}
|
||||
\begin{document}
|
||||
\TitlePageStyle{KIT}
|
||||
\maketitle[%
|
||||
mainlogo={\textcolor{red}{%
|
||||
\includegraphics[width=40mm,height=18.5mm]{KITLogo_RGB}}},%
|
||||
% You may additionally change titlehead. Original definition of titlehead
|
||||
% is:
|
||||
titlehead={\usetitleelement{mainlogo}\hspace*{\fill}},%
|
||||
title=\textcolor{red}{Titel der Arbeit\\im Stil \texttt{KIT}},%
|
||||
subject=\textcolor{red}{Klassifizierung der Arbeit},%
|
||||
author=\textcolor{red}{Markus~Kohm},%
|
||||
faculty=\textcolor{red}{Fakultät für Informatik},%
|
||||
chair=\textcolor{red}{%
|
||||
Institute for Program Structures\\and Data Organization (IPA)},%
|
||||
advisor={\textcolor{red}{Titel Vorname Nachname}\and
|
||||
\textcolor{red}{Titel Vorname Nachname}},%
|
||||
referee={\textcolor{red}{Titel Vorname Nachname}\and
|
||||
\textcolor{red}{Titel Vorname Nachname}},%
|
||||
duration=\textcolor{red}{XX. Monat 20XX -- XX. Monat 20XX},%
|
||||
university=\textcolor{red}{\KITlongname},%
|
||||
homepage=\textcolor{red}{\KITurl}%
|
||||
]
|
||||
\end{document}
|
||||
```
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
[The Wikibook page on Title Creation](https://en.wikibooks.org/wiki/LaTeX/Title_Creation), you can find some more examples linked there
|
||||
@@ -1,342 +0,0 @@
|
||||
---
|
||||
title: How to use interfaces in Go
|
||||
tags:
|
||||
- IT/Development/Go
|
||||
source: https://jordanorelli.com/post/32665860244/how-to-use-interfaces-in-go
|
||||
---
|
||||
|
||||
[How to use interfaces in Go](https://jordanorelli.com/post/32665860244/how-to-use-interfaces-in-go)
|
||||
|
||||
Before I started programming Go, I was doing most of my work with Python. As a Python programmer, I found that learning to use interfaces in Go was extremely difficult. That is, the basics were easy, and I knew how to use the interfaces in the standard library, but it took some practice before I knew how to design my own interfaces. In this post, I’ll discuss Go’s type system in an effort to explain how to use interfaces effectively.
|
||||
|
||||
### Introduction to interfaces
|
||||
|
||||
So what _is_ an interface? An interface is two things: it is a set of methods, but it is also a type. Let’s focus on the method set aspect of interfaces first.
|
||||
|
||||
Typically, we’re introduced to interfaces with some contrived example. Let’s go with the contrived example of writing some application where you’re defining Animal datatypes, because that’s a totally realistic situation that happens all the time. The `Animal` type will be an interface, and we’ll define an `Animal` as being _anything that can speak_. This is a core concept in Go’s type system; instead of designing our abstractions in terms of what kind of data our types can hold, we design our abstractions in terms of what actions our types can execute.
|
||||
|
||||
We start by defining our `Animal` interface:
|
||||
|
||||
```go
|
||||
type Animal interface {
|
||||
Speak() string
|
||||
}
|
||||
```
|
||||
|
||||
pretty simple: we define an `Animal` as being any type that has a method named `Speak`. The `Speak` method takes no arguments and returns a string. Any type that defines this method is said to _satisfy _the `Animal` interface. There is no `implements` keyword in Go; whether or not a type satisfies an interface is determined automatically. Let’s create a couple of types that satisfy this interface:
|
||||
|
||||
```java
|
||||
type Dog struct {
|
||||
}
|
||||
|
||||
func (d Dog) Speak() string {
|
||||
return "Woof!"
|
||||
}
|
||||
|
||||
type Cat struct {
|
||||
}
|
||||
|
||||
func (c Cat) Speak() string {
|
||||
return "Meow!"
|
||||
}
|
||||
|
||||
type Llama struct {
|
||||
}
|
||||
|
||||
func (l Llama) Speak() string {
|
||||
return "?????"
|
||||
}
|
||||
|
||||
type JavaProgrammer struct {
|
||||
}
|
||||
|
||||
func (j JavaProgrammer) Speak() string {
|
||||
return "Design patterns!"
|
||||
}
|
||||
```
|
||||
|
||||
We now have four different types of animals: A dog, a cat, a llama, and a Java programmer. In our `main()` function, we can create a slice of Animals, and put one of each type into that slice, and see what each animal says. Let’s do that now:
|
||||
|
||||
```java
|
||||
func main() {
|
||||
animals := \[\]Animal{Dog{}, Cat{}, Llama{}, JavaProgrammer{}}
|
||||
for _, animal := range animals {
|
||||
fmt.Println(animal.Speak())
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You can view and run this example here:[http://play.golang.org/p/yGTd4MtgD5](https://t.umblr.com/redirect?z=http%3A%2F%2Fplay.golang.org%2Fp%2FyGTd4MtgD5&t=NzMyYTM0N2MxNWU5MGEzZTJjMzk1Mzc0Nzg3YTkxMDhiZTk0MmUzMCxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://play.golang.org/p/yGTd4MtgD5")
|
||||
|
||||
Great, now you know how to use interfaces, and I don’t need to talk about them any more, right? Well, no, not really. Let’s look at a few things that aren’t very obvious to the budding gopher.
|
||||
|
||||
### The `interface{}` type
|
||||
|
||||
The `interface{}` type, _the empty interface_, is the source of much confusion. The `interface{}` type is the interface that has no methods. Since there is no `implements` keyword, all types implement at least zero methods, and satisfying an interface is done automatically, _all types satisfy the empty interface_. That means that if you write a function that takes an `interface{}` value as a parameter, you can supply that function with any value. So, this function:
|
||||
|
||||
```go
|
||||
func DoSomething(v interface{}) {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
will accept any parameter whatsoever.
|
||||
|
||||
Here’s where it gets confusing: inside of the `DoSomething` function, what is `v`’s type? Beginner gophers are led to believe that “`v` is of any type”, but that is wrong. `v` is not of _any_ type; it is of `interface{}` type. Wait, what? When passing a value into the `DoSomething` function, the Go runtime will perform a type conversion (if necessary), and convert the value to an `interface{}` value. All values have exactly one type at runtime, and `v`’s one static type is `interface{}`.
|
||||
|
||||
This should leave you wondering: ok, so if a conversion is taking place, what is _actually _being passed into a function that takes an `interface{}` value (or, what is actually stored in an `[]Animal` slice)? An interface value is constructed of two words of data; one word is used to point to a method table for the value’s underlying type, and the other word is used to point to the actual data being held by that value. I don’t want to bleat on about this endlessly. If you understand that an interface value is two words wide and it contains a pointer to the underlying data, that’s typically enough to avoid common pitfalls. If you are curious to learn more about the implementation of interfaces, I think[Russ Cox’s description of interfaces](https://t.umblr.com/redirect?z=http%3A%2F%2Fresearch.swtch.com%2Finterfaces&t=YTNhMjY1ZmM2NmJhMDcwYjAwNzY0MTYzYzBhMDA1MjRjZmIxZTYzMyxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "Russ Cox's description of interfaces") is very, very helpful.
|
||||
|
||||
In our previous example, when we constructed a slice of `Animal` values, we did not have to say something onerous like `Animal(Dog{})` to put a value of type `Dog` into the slice of `Animal` values, because the conversion was handled for us automatically. Within the `animals` slice, each element is of `Animal` type, but our different values have different underlying types.
|
||||
|
||||
So… why does this matter? Well, understanding how interfaces are represented in memory makes some potentially confusing things very obvious. For example, the question “[can I convert a \[\]T to an \[\]interface{}](https://t.umblr.com/redirect?z=http%3A%2F%2Fgolang.org%2Fdoc%2Fgo_faq.html%23convert_slice_of_interface&t=ODBjMjNmYWYwNDk1ODMxMjgxM2NmYTg5ZDE2MWFiYWRmZWYyMGU1YyxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://golang.org/doc/go_faq.html#convert_slice_of_interface")” is easy to answer once you understand how interfaces are represented in memory. Here’s an example of some broken code that is representative of a common misunderstanding of the `interface{}` type:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
)
|
||||
|
||||
func PrintAll(vals \[\]interface{}) {
|
||||
for _, val := range vals {
|
||||
fmt.Println(val)
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
names := \[\]string{"stanley", "david", "oscar"}
|
||||
PrintAll(names)
|
||||
}
|
||||
```
|
||||
Run it here:[http://play.golang.org/p/4DuBoi2hJU](https://t.umblr.com/redirect?z=http%3A%2F%2Fplay.golang.org%2Fp%2F4DuBoi2hJU&t=NzgzYzFmYWQyNTRhYTgyNWJjZTQ3MTMxMjcxMzIyOTA2MmQ0NDQyYixoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://play.golang.org/p/4DuBoi2hJU")
|
||||
|
||||
By running this, you can see that we encounter the following error: `cannot use names (type []string) as type []interface {} in function argument.` If we want to actually make that work, we would have to convert the `[]string` to an `[]interface{}`:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
)
|
||||
|
||||
func PrintAll(vals []interface{}) {
|
||||
for _, val := range vals {
|
||||
fmt.Println(val)
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
names := []string{"stanley", "david", "oscar"}
|
||||
vals := make([]interface{}, len(names))
|
||||
for i, v := range names {
|
||||
vals[i] = v
|
||||
}
|
||||
PrintAll(vals)
|
||||
}
|
||||
```
|
||||
Run it here:[http://play.golang.org/p/Dhg1YS6BJS](https://t.umblr.com/redirect?z=http%3A%2F%2Fplay.golang.org%2Fp%2FDhg1YS6BJS&t=M2UyNmU2N2YzOGMyMjBiYTUxNDAwYmY5YjI3MzgyZDliOGNmZTE5ZSxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://play.golang.org/p/Dhg1YS6BJS")
|
||||
|
||||
That’s pretty ugly, but _c'est la vie_. Not everything is perfect. (in reality, this doesn’t come up very often, because `[]interface{}` turns out to be less useful than you would initially expect)
|
||||
|
||||
### Pointers and interfaces
|
||||
|
||||
Another subtlety of interfaces is that an interface definition does not prescribe whether an implementor should implement the interface using a pointer receiver or a value receiver. When you are given an interface value, there’s no guarantee whether the underlying type is or isn’t a pointer. In our previous example, we defined all of our methods on value receivers, and we put the associated values into the `Animal` slice. Let’s change this and make the `Cat`’s `Speak()` method take a pointer receiver:
|
||||
|
||||
```go
|
||||
func (c *Cat) Speak() string {
|
||||
return "Meow!"
|
||||
}
|
||||
```
|
||||
If you change that one signature, and you try to run the same program exactly as-is ([http://play.golang.org/p/TvR758rfre](https://t.umblr.com/redirect?z=http%3A%2F%2Fplay.golang.org%2Fp%2FTvR758rfre&t=ZTlkMjZkMTk0ZGQ4NDQ3NDM0MjA2M2I0NTYxNzBjYWZmZDVhNWMyYSxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://play.golang.org/p/TvR758rfre")), you will see the following error:
|
||||
|
||||
prog.go:40: cannot use Cat literal (type Cat) as type Animal in array element:
|
||||
Cat does not implement Animal (Speak method requires pointer receiver)
|
||||
|
||||
This error message is a bit confusing at first, to be honest. What it’s saying is not that the interface `Animal` demands that you define your method as a pointer receiver, but that you have tried to convert a `Cat` struct into an `Animal` interface value, but only `*Cat` satisfies that interface. You can fix this bug by passing in a `*Cat` pointer to the `Animal` slice instead of a `Cat` value, by using `new(Cat)` instead of `Cat{}` (you could also say `&Cat{}`, I simply prefer the look of `new(Cat)`):
|
||||
|
||||
```go
|
||||
animals := []Animal{Dog{}, new(Cat), Llama{}, JavaProgrammer{}}
|
||||
```
|
||||
now our program works again:[http://play.golang.org/p/x5VwyExxBM](https://t.umblr.com/redirect?z=http%3A%2F%2Fplay.golang.org%2Fp%2Fx5VwyExxBM&t=MDRmYTE5MTEyYmNhZjM1YWFlMWFiNTAxMWFmZWQyYjE1NTI1YTcxMCxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://play.golang.org/p/x5VwyExxBM")
|
||||
|
||||
Let’s go in the opposite direction: let’s pass in a `*Dog` pointer instead of a `Dog` value, but this time we _won’t_ change the definition of the `Dog` type’s `Speak` method:
|
||||
|
||||
```go
|
||||
animals := []Animal{new(Dog), new(Cat), Llama{}, JavaProgrammer{}}
|
||||
```
|
||||
This also works ([http://play.golang.org/p/UZ618qbPkj](https://t.umblr.com/redirect?z=http%3A%2F%2Fplay.golang.org%2Fp%2FUZ618qbPkj&t=NmZlOTE1YzVkNDVhZGNjYTFiNTI1NmY2NGQ4YmNlOTYwZDZkNGUzYyxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://play.golang.org/p/UZ618qbPkj")), but recognize a subtle difference: we didn’t need to change the type of the receiver of the `Speak` method. This works because a pointer type can access the methods of its associated value type, but not vice versa. That is, a `*Dog` value can utilize the `Speak` method defined on `Dog`, but as we saw earlier, a `Cat` value cannot access the `Speak` method defined on `*Cat`.
|
||||
|
||||
That may sound cryptic, but it makes sense when you remember the following: everything in Go is passed by value. Every time you call a function, the data you’re passing into it is copied. In the case of a method with a value receiver, the value is copied when calling the method. This is slightly more obvious when you understand that a method of the following signature:
|
||||
|
||||
```go
|
||||
func (t T)MyMethod(s string) {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
is a function of type `func(T, string)`; method receivers are passed into the function by value just like any other parameter.
|
||||
|
||||
Any changes to the receiver made inside of a method defined on a value type (e.g., `func (d Dog) Speak() { ... }`) will not be seen by the caller because the caller is scoping a completely separate `Dog` value. Since everything is passed by value, it should be obvious why a `*Cat` method is not usable by a `Cat` value; any one `Cat` value may have any number of `*Cat` pointers that point to it. If we try to call a `*Cat` method by using a `Cat` value, we never had a `*Cat` pointer to begin with. Conversely, if we have a method on the `Dog` type, and we have a `*Dog` pointer, we know exactly which `Dog` value to use when calling this method, because the `*Dog` pointer points to exactly one `Dog` value; the Go runtime will dereference the pointer to its associated `Dog` value any time it is necessary. That is, given a `*Dog` value `d `and a method `Speak` on the `Dog` type, we can just say `d.Speak()`; we don’t need to say something like `d->Speak()` as we might do in other languages.
|
||||
|
||||
### The real world: getting a proper timestamp out of the Twitter API
|
||||
|
||||
The Twitter API represents timestamps using a string of the following format:
|
||||
|
||||
"Thu May 31 00:00:01 +0000 2012"
|
||||
|
||||
of course, timestamps can be represented in any number of ways in a JSON document, because timestamps aren’t a part of the JSON spec. For the sake of brevity, I won’t put in the entire JSON representation of a tweet, but let’s take a look at how the `created_at` field would be handled by encoding/json:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"fmt"
|
||||
"reflect"
|
||||
)
|
||||
|
||||
// start with a string representation of our JSON data
|
||||
var input = `
|
||||
{
|
||||
"created_at": "Thu May 31 00:00:01 +0000 2012"
|
||||
}
|
||||
`
|
||||
|
||||
func main() {
|
||||
// our target will be of type map[string]interface{}, which is a
|
||||
// pretty generic type that will give us a hashtable whose keys
|
||||
// are strings, and whose values are of type interface{}
|
||||
var val map[string]interface{}
|
||||
|
||||
if err := json.Unmarshal([]byte(input), &val); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
fmt.Println(val)
|
||||
for k, v := range val {
|
||||
fmt.Println(k, reflect.TypeOf(v))
|
||||
}
|
||||
}
|
||||
```
|
||||
run it here:[http://play.golang.org/p/VJAyqO3hTF](https://t.umblr.com/redirect?z=http%3A%2F%2Fplay.golang.org%2Fp%2FVJAyqO3hTF&t=OWY4MGU1MWIwMWI0N2U5MjdhZmRiYTUzY2Q1ZWY5N2YwYTk5MzAyNCxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://play.golang.org/p/VJAyqO3hTF")
|
||||
|
||||
Running this application, we see that we arrive at the following output:
|
||||
|
||||
map\[created_at:Thu May 31 00:00:01 +0000 2012\]
|
||||
created_at string
|
||||
|
||||
We can see that we’ve retrieved the key properly, but having a timestamp in a string format like that isn’t very useful. If we want to compare timestamps to see which is earlier, or see how much time has passed since the given value and the current time, using a plain string won’t be very helpful.
|
||||
|
||||
Let’s naively try to unmarshal this to a `time.Time` value, which is the standard library representation of time, and see what kind of error we get. Make the following change:
|
||||
|
||||
```go
|
||||
var val map[string]time.Time
|
||||
|
||||
if err := json.Unmarshal([]byte(input), &val); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
```
|
||||
running this, we will encounter the following error:
|
||||
|
||||
parsing time ""Thu May 31 00:00:01 +0000 2012"" as ""2006-01-02T15:04:05Z07:00"":
|
||||
|
||||
cannot parse "Thu May 31 00:00:01 +0000 2012"" as "2006"
|
||||
|
||||
that somewhat confusing error message comes from the way that Go handles the conversion of `time.Time` values to and from strings. In a nutshell, what it means is that the string representation we gave it does not match the standard time formatting (because Twitter’s API was originally written in Ruby, and the default format for Ruby is not the same as the default format for Go). We’ll need to define our own type in order to unmarshal this value correctly. The `encoding/json` package looks to see if values passed to `json.Unmarshal` satisfy the `json.Unmarshaler` interface, which looks like this:
|
||||
|
||||
```go
|
||||
type Unmarshaler interface {
|
||||
UnmarshalJSON([]byte) error
|
||||
}
|
||||
```
|
||||
this is referenced in the documentation here:[http://golang.org/pkg/encoding/json/#Unmarshaler](https://t.umblr.com/redirect?z=http%3A%2F%2Fgolang.org%2Fpkg%2Fencoding%2Fjson%2F%23Unmarshaler&t=Zjk0MGE2M2FiNDE4NDY2M2E1ZDAyYWFjNmZiZmFjZjM5MzE3ODNlNyxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://golang.org/pkg/encoding/json/#Unmarshaler")
|
||||
|
||||
So what we need is a `time.Time` value with an `UnmarshalJSON([]byte) error` method:
|
||||
|
||||
```go
|
||||
type Timestamp time.Time
|
||||
|
||||
func (t *Timestamp) UnmarshalJSON(b []byte) error {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
By implementing this method we satisfy the `json.Unmarshaler` interface, causing `json.Unmarshal` to call our custom unmarshalling code when seeing a `Timestamp` value. For this case, we use a pointer method, because we want the caller to the see the changes made to the receiver. In order to set the value that a pointer points to, we dereference the pointer manually using the * operator. Inside of the `UnmarshalJSON` method, `t` represents a pointer to a `Timestamp` value. By saying `*t`, we dereference the pointer `t` and we are able to access the value that `t` points to. Remember: everything is pass-by-value in Go. That means that inside of the `UnmarshalJSON` method, the pointer `t` is not the same pointer as the pointer in its calling context; it is a copy. If you were to assign `t` to another value directly, you would just be reassigning a function-local pointer; the change would not be seen by the caller. However, the pointer inside of the method call points to the same data as the pointer in its calling scope; by dereferencing the pointer, we make our change visible to the caller.
|
||||
|
||||
We can make use of the `time.Parse` method, which has the signature `func(layout, value string) (Time, error)`. That is, it takes two strings: the first string is a layout string that describes how we are formatting our timestamps, and the second is the value we wish to parse. It returns a `time.Time` value, as well as an error (in case we failed to parse the timestamp for some reason). You can read more about the semantics of the layout strings in [the time package documentation](https://t.umblr.com/redirect?z=http%3A%2F%2Fgolang.org%2Fpkg%2Ftime%2F&t=MjBjODdjZjg0YzVhYTJjMTk1NjM0OTE0NGFhODY2Y2U1MmU3ZDIwOSxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "the time package"), but in this example we won’t need to figure out the layout string manually because this layout string already exists in the standard library as the value `time.RubyDate`. So in effect, we can resolve the string “Thu May 31 00:00:01 +0000 2012” to a `time.Time` value by invoking the function `time.Parse(time.RubyDate, "Thu May 31 00:00:01 +0000 2012")`. The value we will receive is of type `time.Time`. In our example, we’re interested in values of the type `Timestamp`. We can convert the `time.Time` value to a `Timestamp` value by saying `Timestamp(v)`, where `v` is our `time.Time` value. Ultimately, our `UnmarshalJSON` function winds up looking like this:
|
||||
|
||||
```go
|
||||
func (t *Timestamp) UnmarshalJSON(b []byte) error {
|
||||
v, err := time.Parse(time.RubyDate, string(b[1:len(b)-1]))
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
*t = Timestamp(v)
|
||||
return nil
|
||||
}
|
||||
```
|
||||
|
||||
we take a subslice of the incoming byte slice because the incoming byte slice is the raw data of the JSON element and contains the quotation marks surrounding the string value; we want to chop those off before passing the string value into `time.Parse`.
|
||||
|
||||
Source for the entire timestamp example can be seen (and executed) here:[http://play.golang.org/p/QpiFsJi-nZ](https://t.umblr.com/redirect?z=http%3A%2F%2Fplay.golang.org%2Fp%2FQpiFsJi-nZ&t=ZmJhOGY0ODc1NmVhYmUwNjI2YTEwMjFmM2QzYTI1ZWFjMGI5ZDhlMixoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://play.golang.org/p/QpiFsJi-nZ")
|
||||
|
||||
### Real-world interfaces: getting an object out of an http request
|
||||
|
||||
Let’s wrap up by seeing how we might design an interfaces to solve a common web development problem: we wish to parse the body of an HTTP request into some object data. At first, this is not a very obvious interface to define. We might try to say that we’re going to get a resource from an HTTP request like this:
|
||||
|
||||
```go
|
||||
GetEntity(*http.Request) (interface{}, error)
|
||||
```
|
||||
|
||||
because an `interface{}` can have any underlying type, so we can just parse our request and return whatever we want. This turns out to be a pretty bad strategy, the reason being that we wind up sticking too much logic into the `GetEntity` function, the `GetEntity` function now needs to be modified for every new type, and we’ll need to use a type assertion to do anything useful with that returned `interface{}` value. In practice, functions that return `interface{}` values tend to be quite annoying, and as a rule of thumb you can just remember that it’s typically better to take in an `interface{}` value as a parameter than it is to return an `interface{}` value. ([Postel’s Law](https://t.umblr.com/redirect?z=http%3A%2F%2Fen.wikipedia.org%2Fwiki%2FRobustness_Principle&t=ZGYxODRiYjhjOWQwNzA5MjgzYTA0ZjRjN2QxNzZiZmJhYzFkNGFjNyxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://en.wikipedia.org/wiki/Robustness_Principle"), applied to interfaces)
|
||||
|
||||
We might also be tempted to write some type-specific function like this:
|
||||
```go
|
||||
GetUser(*http.Request) (User, error)
|
||||
```
|
||||
This also turns out to be pretty inflexible, because now we have different functions for every type, but no sane way to generalize them. Instead, what we really want to do is something more like this:
|
||||
|
||||
```go
|
||||
type Entity interface {
|
||||
UnmarshalHTTP(*http.Request) error
|
||||
}
|
||||
|
||||
func GetEntity(r *http.Request, v Entity) error {
|
||||
return v.UnmarshalHTTP(r)
|
||||
}
|
||||
```
|
||||
|
||||
Where the `GetEntity` function takes an interface value that is guaranteed to have an `UnmarshalHTTP` method. To make use of this, we would define on our `User` object some method that allows the `User` to describe how it would get itself out of an HTTP request:
|
||||
|
||||
```go
|
||||
func (u \*User) UnmarshalHTTP(r \*http.Request) error {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
in your application code, you would declare a var of `User` type, and then pass a pointer to this function into `GetEntity`:
|
||||
|
||||
```go
|
||||
var u User
|
||||
if err := GetEntity(req, &u); err != nil {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
That’s very similar to how you would unpack JSON data. This type of thing works consistently and safely because the statement `var u User` will automatically [zero](https://t.umblr.com/redirect?z=http%3A%2F%2Fgolang.org%2Fref%2Fspec%23The_zero_value&t=NzkwOTU0ODhiOTAyOThhYjg1Njg3ZDE5MGUzYjg5MDQyMzJlZmY3OCxoZmZyTU04Sg%3D%3D&b=t%3AWvVgq8ST2uhqerqL8LopZw&p=https%3A%2F%2Fjordanorelli.com%2Fpost%2F32665860244%2Fhow-to-use-interfaces-in-go&m=1 "http://golang.org/ref/spec#The_zero_value") the `User` struct. Go is not like some other languages in that declaration and initialization occur separately, and that by declaring a value without initializing it you can create a subtle pitfall wherein you might access a section of junk data; when declaring the value, the runtime will zero the appropriate memory space to hold that value. Even if our UnmarshalHTTP method fails to utilize some fields, those fields will contain valid zero data instead of junk.
|
||||
|
||||
That should seem weird to you if you’re a Python programmer, because it’s basically inside-out of what we typically do in Python. The reason that this form becomes so handy is that now we can define an arbitrary number of types, each of which is responsible for its own unpacking from an http request. It is now up to the entity definitions to decide how they may be represented. Then, we can build around the `Entity` type to create things like generic HTTP handlers.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
I hope, after reading this, that you feel more comfortable using interfaces in Go. Remember the following:
|
||||
|
||||
* create abstractions by considering the functionality that is common between datatypes, instead of the fields that are common between datatypes
|
||||
* an `interface{}` value is not of any type; it is of `interface{}` type
|
||||
* interfaces are two words wide; schematically they look like `(type, value)`
|
||||
* it is better to accept an `interface{}` value than it is to return an `interface{}` value
|
||||
* a pointer type may call the methods of its associated value type, but not vice versa
|
||||
* everything is pass by value, even the receiver of a method
|
||||
* an interface value isn’t strictly a pointer or not a pointer, it’s just an interface
|
||||
* if you need to completely overwrite a value inside of a method, use the `*` operator to manually dereference a pointer
|
||||
|
||||
Ok, I think that sums up everything about interfaces that I personally found confusing. Happy coding :)
|
||||
|
||||
[8:07 am • 1 October 2012 • 125 notes](https://jordanorelli.com/post/32665860244/how-to-use-interfaces-in-go)
|
||||
@@ -1,51 +0,0 @@
|
||||
---
|
||||
title: "IT DevOps: One Size Does Not Fit All"
|
||||
tags:
|
||||
- IT/DevOps
|
||||
- IT
|
||||
source: https://devops.com/devops-one-size-not-fit/
|
||||
---
|
||||
|
||||
## [IT DevOps: One Size Does Not Fit All](https://devops.com/devops-one-size-not-fit/)
|
||||
|
||||
As absurd as this may seem, some in IT may be longing for the good old days of the mainframe. After all, the hulking machine, with its dumb terminals and thousands of punch cards, gave IT complete control. No citizen developers or business analysts allowed.
|
||||
|
||||
Things got more complicated with distributed desktop computing and its different operating systems and requirements. Server-based web apps simplified things once again, but now mobile has made development more complex than ever. Instead of just updating the server, you also now have to update each mobile device—creating apps that work on each and getting changes out to the entire mobile population.
|
||||
|
||||
What’s IT to do? Applied properly, DevOps can help.
|
||||
|
||||
## The Evolution of DevOps
|
||||
|
||||
Coming on the heels of agile development—a term first coined in 2001—is DevOps, which was first popularized in Belgium in 2009. Today, 15 years into agile development and six years into DevOps, it is becoming clear that these intertwined terms are quite broad, encompassing attitude and approach, platforms, tools and solutions. Agile development, with its Scrum meetings and quick turnaround cycles, did speed development but made deployment more difficult, because many organizations just couldn’t support fast cycle deployment.
|
||||
|
||||
DevOps, with its platforms, tools and practices emphasizing collaboration between IT and development, targets application delivery with continuous testing, ongoing feature development and ongoing maintenance to deliver apps faster. While the intention is well and good, the DevOps process must be task-specific to succeed.
|
||||
|
||||
Today’s development environments can be broken down into three categories: low-code, deployment-centric apps and, in a class by itself, mobile. Delivering apps in these three environments involves a broad range of skills and tools. Therefore, the approach and degree to which DevOps is utilized must vary as well—from virtually no DevOps in low-code environments to extended DevOps in mobile.
|
||||
|
||||
## Low-Code = Zero Ops
|
||||
|
||||
In cloud-based, application performance-as-a-service (aPaaS), low-code environments, DevOps can take a back seat. With the vendor managing, maintaining and controlling the deployment environment, the citizen developer or business analyst is empowered to work on GUI development and other features and functions with little involvement from IT or development. In these environments, power users can easily push out low-code apps. A strong DevOps presence here is not necessary because the separate environments typically required to propagate apps does not exist. The business analyst simply makes the changes and pushes them through to production.
|
||||
|
||||
Here, IT is best utilized as gatekeepers, getting involved only when needed. We characterize these environments as ***zero ops**—*the less DevOps the better. This leaves business users, IT and development free to focus on their strategic areas and core competencies, funneling resources appropriately and enhancing productivity across the board.
|
||||
|
||||
## Deployment-Centric = Controlled Ops
|
||||
|
||||
High-transaction, highly scalable, business-critical global apps fall into the deployment-centric category. The goal of DevOps in these code-intensive environments is to free developers from deployment issues, enabling them to focus on their key competency of writing code. Well-executed DevOps can effectively move apps from development to deployment, enabling tight collaboration between development and IT. In this environment, a well-managed DevOps process can make it easy for the DevOps team to deploy the apps and to manage the deployment moving forward, scaling apps automatically with rules that scale automatically based on usage.
|
||||
|
||||
That is why we characterize DevOps in these environments as ***controlled ops***, a collaboration tightly controlled by development and IT.
|
||||
|
||||
## Mobile = Extended Ops
|
||||
|
||||
From development to deployment, maintenance, monitoring and analysis, mobile has introduced new levels of complexity to application delivery. Developers have iOS, Windows and Android to deal with, not to mention multiple versions within those environments. Then there is the development environment itself—web, native or hybrid. Compounding it further are the devices—countless phones and tablets. And deployment options—public app stores, private app stores, file-sharing services. Finally, the end user is engaging the device in ways never before imagined, placing the need to build responsive and compelling user experiences front and center.
|
||||
|
||||
This environment calls for ***extended ops***—a highly collaborative environment where development, deployment, maintenance, support and business stakeholders are all integral to an app’s success. In mobile, everyone needs to have a place at the DevOps table, as mobile apps are literally iterative apps—constantly on the move, morphing and changing, driven primarily by end-user feedback. The ability to make seamless updates and user-driven changes at record speed can spell an app’s success or failure. The collaboration, platforms and tools DevOps offers in this environment have never been so critical, as business users now must be involved in the design and development of the app and in analyzing how the app is used, which will dictate changes moving forward. Successful, extended ops welcomes business users, but does not involve them in the DevOps process itself—that’s for IT and development.
|
||||
|
||||
## In Summary
|
||||
|
||||
DevOps can have an impact on the entire application delivery cycle. From improving deployment frequency—which can lead to faster time-to-market—to shortening lead times for new releases with lower failure rates, the goal of DevOps is to maximize the predictability, efficiency, security and maintainability of the simplest mobile app to the most complex transactional system. The key to successful DevOps is applying the right level of collaboration and employing the right tools to ensure that DevOps improves quality and productivity rather than hinders it.
|
||||
|
||||
## About the Author/Mark Troester
|
||||
|
||||

|
||||
Mark Troester is the Vice President of Solutions Marketing at Progress Software. Mark has extensive experience in bringing application development and data integration products to market. Mark previously led product marketing efforts at Sonatype, SAS and Progress DataDirect. Before moving into marketing, Mark worked as a developer and developer manager for start-ups and enterprises alike.
|
||||
[LinkedIn](https://www.linkedin.com/in/marktroester) [Google+](https://plus.google.com/104069072019379366992/posts)
|
||||
@@ -1,57 +0,0 @@
|
||||
---
|
||||
title: Improve Your Git Commits in Two Easy Steps
|
||||
source: https://blogs.vmware.com/opensource/2021/04/14/improve-your-git-commits-in-two-easy-steps/
|
||||
tags:
|
||||
- IT/Development/Git
|
||||
---
|
||||
|
||||
## [Improve Your Git Commits in Two Easy Steps](https://blogs.vmware.com/opensource/2021/04/14/improve-your-git-commits-in-two-easy-steps/)
|
||||
|
||||
In any successful open-source project, quality git commits are essential. Yes, your code should be technically sound, well-tested and functional, but breaking up your changes into readable chunks and writing informative commit messages are equally as important as the actual code being committed to the project. Well-structured and well-written git commits ensure your code is maintainable, approachable and can be easily debugged. Whether you’re a seasoned veteran or brand new to an open-source community, writing quality git commits is an essential step towards getting your changes merged. Excellent commits have two attributes:
|
||||
|
||||
1. Each commit only does one thing
|
||||
2. Each commit message is its own self-contained story
|
||||
|
||||
I spoke on this topic recently at OpenSource101. The recording of my presentation is below.
|
||||
|
||||
[Improve Your Git Commits in Two Easy Steps – Rose Judge – VMware – Open Source 101](https://www.youtube.com/watch?v=6gWSEKESYJw)
|
||||
|
||||
## Each commit does only one thing
|
||||
|
||||
At a high level, think of your commit like a recipe. If you had ingredients and were told to use them to make a cake, where would you start? First, you would probably look for a recipe that tells you how to make it. Now imagine all the directions for the recipe are crammed into one big paragraph instead of separated into steps – it would be pretty hard to follow along, right? The same is true for your git commits. Think of your pull request, which is the sum of all your commits, as the recipe. Each commit in that pull request should be one step of the recipe that tells you how to make the cake.
|
||||
|
||||
Separating your commits into smaller chunks makes your changelog easier to navigate if there’s ever a regression in your code. Your commits are essentially a list of steps that you can trace to find where the problem was introduced. If all your past changes are represented as one big change, it’s going to be difficult to narrow down where exactly the error occurred. But, if your changes are separated into smaller commits that each only do one thing, it will be much easier to isolate the commit that broke the build. Once you find that commit, reverting a smaller patch that only does one thing will be much easier than if that patch contained many changes.
|
||||
|
||||
As you start to break up your commits to only do one thing, consider what each change is doing. Isolate your non-functional changes into their own commits (i.e., changes where no code is changing). Next, dissect your functional changes into their own commits. For example, if you are creating a new function ‘foo’ while also renaming another function ‘bar,’ each of those individual changes can be their own commits. If you are doing any code cleanup, those changes can also be their own commits. Finally, no commit should break the build. This means that at each commit the code should compile.
|
||||
|
||||
## Each commit message is its own self-contained story
|
||||
|
||||
Once you’ve broken up your changes so each commit only does one thing, it’s time to write a commit message for each change. Your commit message title should contain a summary of *what* changed. The body of the commit message will be your explanation as to *why* and in what *context* the changes are being made.
|
||||
|
||||
In general, keep the reviewer in mind when you are writing your commit message. Assume they are not familiar with the code you’re changing and have no context about why the change is being made. Summarize any relevant information in the body – this may include information about how you arrived at your proposed solution, why the fix is necessary, notes on performance improvements, error messages the commit is addressing, bug references or links to relevant discussions. If you provide outside URLs in your commit message, it’s important that enough context exists in the commit message itself that the reviewer doesn’t have to click on the link to understand the changes. Think of any URL you provide as supportive evidence in addition to your summary of the relevant information.
|
||||
|
||||
A good commit message boils down to a good story. It has a beginning, middle and end with all relevant details self-contained and clearly summarized. A self-contained commit message will explain any assumptions being made in the explanation and reference future or past commits in context so the reviewer can easily comprehend the changes being proposed. The more detail and clarity you provide as to why you are making the change, the faster the reviewer(s) will be able to provide feedback and ultimately, merge your change.
|
||||
|
||||
## The power of good commits
|
||||
|
||||
Well-organized commits and thoroughly explained commit messages add numerous benefits to a project:
|
||||
|
||||
- *Makes future debugging and code cleanup easier*
|
||||
|
||||
If you encounter a regression in the future and you need to figure out which change caused the problem, working with smaller commits that only do one thing makes it easier to find the exact change where the issue was introduced and revert it, if necessary.
|
||||
|
||||
- *Protection when a contributor leaves a project*
|
||||
|
||||
Good commits are an easy insurance policy to protect against attrition in a project. If anyone contributing to your project suddenly leaves the community, good commits will make it possible for the project to continue even when an author of a patch set is not around to answer questions.
|
||||
|
||||
- *Enables time zone collaboration*
|
||||
|
||||
Good commits enable the development process to continue even while contributors in differing time zones sleep. If someone has a question about a particular commit, they can read the commit message and get all the context they need instead of waiting to ask the author directly.
|
||||
|
||||
- *Makes your project approachable for new contributors*
|
||||
|
||||
Think of your commit messages in the same way you think of documentation for your project – if your commits are detailed and organized, new contributors will get up and come running to contribute to your project sooner.
|
||||
|
||||
Writing good commits is a skill that will take time to master – but practice is the only way to improve. So start practicing today. If you’re the maintainer of a project, add your projects git commit requirements to the Contributing Guide. If you’re a contributor working on a project with no commit requirements, consider opening an issue (or better yet, a pull request!) to add these requirements to the project documentation.
|
||||
|
||||
When you’re writing and opening pull requests for a project, lead by example and write the commit messages that you would want to read. Break up your commits in such a way that if you had to debug your code a year from now it would be a pleasant experience. By that same token, hold others accountable for their commits. Whether you are a maintainer or a contributor, encourage others to break up their commits to only do one thing and write informative commit messages for them. Holding others accountable for their work creates a culture of continuous improvement and makes your project, as well as the engineers who work on it, better. Then, enjoy a slice of cake!
|
||||
@@ -1,369 +0,0 @@
|
||||
---
|
||||
title: Improving Performance with Java's CompletableFuture
|
||||
source: https://reflectoring.io/java-completablefuture/
|
||||
tags:
|
||||
- IT/Development/Java
|
||||
---
|
||||
|
||||
**Inhaltsverzeichnis**
|
||||
|
||||
1. [[#What Is a `Future`?|What Is a `Future`?]]
|
||||
1. [[#`CompletableFuture` vs. `Future`|`CompletableFuture` vs. `Future`]]
|
||||
1. [[#`CompletableFuture` vs. `Future`#Defining a Timeout|Defining a Timeout]]
|
||||
1. [[#`CompletableFuture` vs. `Future`#Combining Asynchronous Operations|Combining Asynchronous Operations]]
|
||||
1. [[#`CompletableFuture` vs. `Future`#Reacting to Completion Without Blocking the Thread|Reacting to Completion Without Blocking the Thread]]
|
||||
1. [[#Performance Gains with `CompletableFuture`|Performance Gains with `CompletableFuture`]]
|
||||
1. [[#Performance Gains with `CompletableFuture`#Synchronous Implementation|Synchronous Implementation]]
|
||||
1. [[#Performance Gains with `CompletableFuture`#Parallel Stream Implementation|Parallel Stream Implementation]]
|
||||
1. [[#Performance Gains with `CompletableFuture`#Increasing Performance Using `CompletableFuture`|Increasing Performance Using `CompletableFuture`]]
|
||||
1. [[#Conclusion|Conclusion]]
|
||||
|
||||
|
||||
In this article, we will learn how to use `CompletableFuture` to increase the performance of our application. We’ll start with looking at the `Future` interface and its limitations and then will discuss how we can instead use the `CompletableFuture` class to overcome these limitations.
|
||||
|
||||
We will do this by building a simple application that tries to categorize a list of bank `Transaction`s using a remote service. Let’s begin our journey!
|
||||
|
||||
## What Is a `Future`?
|
||||
|
||||
**`Future` is a Java interface that was introduced in Java 5 to represent a value that will be available in the future**. The advantages of using a `Future` are enormous because we could do some very intensive computation asynchronously without blocking the current thread that in the meantime can do some other useful job.
|
||||
|
||||
We can think of it as going to the restaurant. During the time that the chef is preparing our dinner, we can do other things, like talking to friends or drinking a glass of wine and once the chef has finished the preparation, we can finally eat. Another advantage is that using the `Future` interface is much more developer-friendly than working directly with threads.
|
||||
|
||||
## `CompletableFuture` vs. `Future`
|
||||
|
||||
In this section we will look at some limitations of the `Future` interface and how we can solve these by using the `CompletableFuture` class.
|
||||
|
||||
### Defining a Timeout
|
||||
|
||||
The `Future` interface provides only the `get()` method to retrieve the result of the computation, but **if the computation takes too long we don’t have any way to complete it by returning a value that we can assign**.
|
||||
|
||||
To understand better, let’s look at some code:
|
||||
|
||||
```java
|
||||
class Demo {
|
||||
|
||||
public static void main(String[] args) throws ExecutionException, InterruptedException {
|
||||
ExecutorService executor = Executors.newSingleThreadExecutor();
|
||||
Future<String> stringFuture = executor.submit(() -> neverEndingComputation());
|
||||
System.out.println("The result is: " + stringFuture.get());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We have created an instance of `ExecutorService` that we will use to submit a task that never ends - we call it `neverEndingComputation()`.
|
||||
|
||||
After that we want to print the value of the `stringFuture` variable on the console by invoking the `get()` method. This method waits if necessary for the computation to complete, and then retrieves its result. But because we are calling `neverEndingComputation()` that never ends, the result will never be printed on the console, and we don’t have any way to complete it manually by passing a value.
|
||||
|
||||
Now let’s see how to overcome this limitation by using the class `CompletableFuture`. We will use the same scenario, but in this case, we will provide our value by using the method `complete()` of the `CompletableFuture` class.
|
||||
|
||||
```java
|
||||
class Demo {
|
||||
|
||||
public static void main(String[] args) {
|
||||
CompletableFuture<String> stringCompletableFuture = CompletableFuture.supplyAsync(() -> neverEndingComputation());
|
||||
stringCompletableFuture.complete("Completed");
|
||||
System.out.println("Is the stringCompletableFuture done ? " + stringCompletableFuture.isDone());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Here we are creating a `CompletableFuture` of type `String` by calling the method `supplyAsync()` which takes a `Supplier` as an argument.
|
||||
|
||||
In the end, we are testing if `stringCompletableFuture` really has a value by using the method `isDone()` which returns `true` if completed in any fashion: normally, exceptionally, or via cancellation. The output of the `main()` method is:
|
||||
|
||||
```java
|
||||
Is the stringCompletableFuture done ? true
|
||||
```
|
||||
|
||||
### Combining Asynchronous Operations
|
||||
|
||||
Let’s imagine that we need to call two remote APIs, `firstApiCall()` and `secondApiCall()`. The result of the first API will be the input for the second API. By using the `Future` interface there is no way to combine these two operations asynchronously:
|
||||
|
||||
```java
|
||||
class Demo {
|
||||
public static void main(String[] args) throws ExecutionException, InterruptedException {
|
||||
ExecutorService executor = Executors.newSingleThreadExecutor();
|
||||
Future<String> firstApiCallResult = executor.submit(
|
||||
() -> firstApiCall(someValue)
|
||||
);
|
||||
|
||||
String stringResult = firstApiCallResult.get();
|
||||
Future<String> secondApiCallResult = executor.submit(
|
||||
() -> secondApiCall(stringResult)
|
||||
);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
In the code example above, we call the first API by submitting a task on the `ExecutorService` that returns a `Future`. We need to pass this value to the second API, but the only way to retrieve the value is by using the `get()` of the `Future` method that we have discussed earlier, and by using it we block the main thread. Now we have to wait until the first API returns the result before doing anything else.
|
||||
|
||||
By using the `CompletableFuture` class we don’t need to block the main thread anymore, but we can asynchronously combine more operations:
|
||||
|
||||
```java
|
||||
class Demo {
|
||||
public static void main(String[] args) {
|
||||
|
||||
var finalResult = CompletableFuture.supplyAsync(
|
||||
() -> firstApiCall(someValue)
|
||||
)
|
||||
.thenApply(firstApiResult -> secondApiCall(firstApiResult));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We are using the method `supplyAsync()` of the `CompletableFuture` class which returns a new `CompletableFuture` that is asynchronously completed by a task running in the `ForkJoinPool.commonPool()` with the value obtained by calling the given `Supplier`. After that we are taking the result of the `firstApiCall()` and using the method `thenApply()`, we pass it to the other API invoking `secondApiCall()`.
|
||||
|
||||
### Reacting to Completion Without Blocking the Thread
|
||||
|
||||
Using the `Future` interface we don’t have a way to react to the completion of an operation asynchronously. The only way to get the value is by using the `get()` method which blocks the thread until the result is returned:
|
||||
|
||||
```java
|
||||
class Demo {
|
||||
|
||||
public static void main(String[] args) throws ExecutionException, InterruptedException {
|
||||
ExecutorService executor = Executors.newSingleThreadExecutor();
|
||||
Future<String> stringFuture = executor.submit(() -> "hello future");
|
||||
String uppercase = stringFuture.get().toUpperCase();
|
||||
System.out.println("The result is: " + uppercase);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The code above creates a `Future` by returning a `String` value. Then we transform it to uppercase by firstly calling the `get()` method and right after the `toUpperCase()` method of the `String` class.
|
||||
|
||||
Using `CompletableFuture` we can now create a pipeline of asynchronous operations. Let’s see a simple example of how to do it:
|
||||
|
||||
```java
|
||||
class Demo {
|
||||
public static void main(String[] args) {
|
||||
|
||||
CompletableFuture.supplyAsync(() -> "hello completable future")
|
||||
.thenApply(String::toUpperCase)
|
||||
.thenAccept(System.out::println);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
In the example above we can notice how simple is to create such a pipeline. First, we are calling the `supplyAsync()` method which takes a `Supplier` and returns a new `CompletableFuture`. Then we are then transforming the result to an uppercase string by calling `thenApply()` method. In the end, we just print the value on the console using `thenAccept()` that takes a `Consumer` as the argument.
|
||||
|
||||
If we step back for a moment, we realize that working with `CompletableFuture` is very similar to Java Streams.
|
||||
|
||||
## Performance Gains with `CompletableFuture`
|
||||
|
||||
In this section we will build a simple application that takes a list of bank transactions and calls an external service to categorize each transaction based on the description. We will simulate the call of the external service by using a method that adds some delay before returning the category of the transaction. In the next sections we will incrementally change the implementation of our client application to improve the performance by using CompletableFuture.
|
||||
|
||||
### Synchronous Implementation
|
||||
|
||||
Let’s start implementing our categorization service that declares a method called `categorizeTransaction` :
|
||||
|
||||
```java
|
||||
public class CategorizationService {
|
||||
|
||||
public static Category categorizeTransaction(Transaction transaction) {
|
||||
delay();
|
||||
return new Category("Category_" + transaction.getId());
|
||||
}
|
||||
|
||||
public static void delay() {
|
||||
try {
|
||||
Thread.sleep(1000L);
|
||||
} catch (InterruptedException e) {
|
||||
throw new RuntimeException(e);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
public class Category {
|
||||
private final String category;
|
||||
|
||||
public Category(String category) {
|
||||
this.category = category;
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString() {
|
||||
return "Category{" +
|
||||
"category='" + category + '\'' +
|
||||
'}';
|
||||
}
|
||||
}
|
||||
|
||||
public class Transaction {
|
||||
private String id;
|
||||
private String description;
|
||||
|
||||
public Transaction(String id, String description) {
|
||||
this.id = id;
|
||||
this.description = description;
|
||||
}
|
||||
|
||||
public String getId() {
|
||||
return id;
|
||||
}
|
||||
|
||||
public void setId(String id) {
|
||||
this.id = id;
|
||||
}
|
||||
|
||||
public String getDescription() {
|
||||
return description;
|
||||
}
|
||||
|
||||
public void setDescription(String description) {
|
||||
this.description = description;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
In the code above we have a class called `Transaction` that has an `id` and a `description` field.
|
||||
|
||||
We will pass an instance of this class to the static method `categorizeTransaction(Transaction transaction)` of our `CategorizationService` which will return an instance of the class `Category`.
|
||||
|
||||
Before returning the result, the `categorizeTransaction()` method waits for one second and then returns a `Category` object that has field of type `String` called `description`. The `description` field will be just the concatenation of the String `"Category_"` with the `id` field from the `Transaction` class.
|
||||
|
||||
To test this implementation we will build a client application that tries to categorize three transactions, as follows :
|
||||
|
||||
```java
|
||||
public class Demo {
|
||||
|
||||
public static void main(String[] args) {
|
||||
long start = System.currentTimeMillis();
|
||||
var categories = Stream.of(
|
||||
new Transaction("1", "description 1"),
|
||||
new Transaction("2", "description 2"),
|
||||
new Transaction("3", "description 3"))
|
||||
.map(CategorizationService::categorizeTransaction)
|
||||
.collect(Collectors.toList());
|
||||
long end = System.currentTimeMillis();
|
||||
|
||||
System.out.printf("The operation took %s ms%n", end - start);
|
||||
System.out.println("Categories are: " + categories);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
After running the code, it prints on the console the total time taken to categorize the three transactions, and on my machine it is saying :
|
||||
|
||||
```java
|
||||
The operation took 3039 ms
|
||||
Categories are: [Category{category='Category_1'},
|
||||
Category{category='Category_2'},
|
||||
Category{category='Category_3'}]
|
||||
```
|
||||
|
||||
The program takes 3 seconds to complete because we are categorizing each transaction in sequence and the time needed to categorize one transaction is one second. In the next section, we will try to refactor our client application using a parallel stream.
|
||||
|
||||
### Parallel Stream Implementation
|
||||
|
||||
Using a parallel stream, our client application will look like this:
|
||||
|
||||
```java
|
||||
public class Demo {
|
||||
|
||||
public static void main(String[] args) {
|
||||
long start = System.currentTimeMillis();
|
||||
var categories = Stream.of(
|
||||
new Transaction("1", "description 1"),
|
||||
new Transaction("2", "description 2"),
|
||||
new Transaction("3", "description 3"))
|
||||
.parallel()
|
||||
.map(CategorizationService::categorizeTransaction)
|
||||
.collect(Collectors.toList());
|
||||
long end = System.currentTimeMillis();
|
||||
|
||||
System.out.printf("The operation took %s ms%n", end - start);
|
||||
System.out.println("Categories are: " + categories);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
It’s almost identical to before, apart from that here we are using the `parallel()` method to parallelize the computation. If we run this program now, it will print the following output:
|
||||
|
||||
```java
|
||||
The operation took 1037 ms
|
||||
Categories are: [Category{category='Category_1'},
|
||||
Category{category='Category_2'},
|
||||
Category{category='Category_3'}]
|
||||
```
|
||||
|
||||
The difference is huge! Now our application runs almost three times faster, but this is not the whole story.
|
||||
|
||||
This solution can scale until we reach the limit of the number of processors. After that the performance doesn’t change because internally the parallel stream uses a Thread pool that has a fixed number of threads that is equal to `Runtime.getRuntime().availableProcessors()`.
|
||||
|
||||
In my machine, I have 8 processors, so if we run the code above with ten transactions it should take at least 2 seconds:
|
||||
|
||||
```java
|
||||
The operation took 2030 ms
|
||||
Categories are: [Category{category='Category_1'},
|
||||
Category{category='Category_2'},
|
||||
Category{category='Category_3'},
|
||||
Category{category='Category_4'},
|
||||
Category{category='Category_5'},
|
||||
Category{category='Category_6'},
|
||||
Category{category='Category_7'},
|
||||
Category{category='Category_8'},
|
||||
Category{category='Category_9'},
|
||||
Category{category='Category_10'}]
|
||||
```
|
||||
|
||||
We see that the operation took 2030 ms, as predicted. Can we do something to increase the performance of our application even more? YES!
|
||||
|
||||
### Increasing Performance Using `CompletableFuture`
|
||||
|
||||
Now will refactor our client application to take advantage of `CompletableFuture`:
|
||||
|
||||
```java
|
||||
public class Demo {
|
||||
|
||||
public static void main(String[] args) {
|
||||
Executor executor = Executors.newFixedThreadPool(10);
|
||||
long start = System.currentTimeMillis();
|
||||
var futureCategories = Stream.of(
|
||||
new Transaction("1", "description 1"),
|
||||
new Transaction("2", "description 2"),
|
||||
new Transaction("3", "description 3"),
|
||||
new Transaction("4", "description 4"),
|
||||
new Transaction("5", "description 5"),
|
||||
new Transaction("6", "description 6"),
|
||||
new Transaction("7", "description 7"),
|
||||
new Transaction("8", "description 8"),
|
||||
new Transaction("9", "description 9"),
|
||||
new Transaction("10", "description 10")
|
||||
)
|
||||
.map(transaction -> CompletableFuture.supplyAsync(
|
||||
() -> CategorizationService.categorizeTransaction(transaction), executor)
|
||||
)
|
||||
.collect(toList());
|
||||
|
||||
var categories = futureCategories.stream()
|
||||
.map(CompletableFuture::join)
|
||||
.collect(toList());
|
||||
long end = System.currentTimeMillis();
|
||||
|
||||
System.out.printf("The operation took %s ms%n", end - start);
|
||||
System.out.println("Categories are: " + categories);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Our client application is trying to call the categorization service by using the method `supplyAsync()` that takes as arguments a `Supplier` and an `Executor`. Here we can now pass a custom `Executor` with a pool of ten threads to make the computation finish even faster than before.
|
||||
|
||||
With 10 threads, we expect that the operation should take around one second. Indeed, the output confirms the expected result :
|
||||
|
||||
```java
|
||||
The operation took 1040 ms
|
||||
Categories are: [Category{category='Category_1'},
|
||||
Category{category='Category_2'},
|
||||
Category{category='Category_3'},
|
||||
Category{category='Category_4'},
|
||||
Category{category='Category_5'},
|
||||
Category{category='Category_6'},
|
||||
Category{category='Category_7'},
|
||||
Category{category='Category_8'},
|
||||
Category{category='Category_9'},
|
||||
Category{category='Category_10'}]
|
||||
```
|
||||
|
||||
## Conclusion
|
||||
|
||||
In this article, we learned how to use the `Future` interface in Java and its limitations. We learned how to overcome these limitations by using the `CompletableFuture` class. After that, we analyzed a demo application, and step by step using the potential offered by `CompletableFuture` we refactored it for better performance.
|
||||
@@ -1,10 +0,0 @@
|
||||
---
|
||||
title: Installation oh-my-zsh
|
||||
---
|
||||
|
||||
Installation oh-my-zsh
|
||||
|
||||
```shell
|
||||
curl -Lo install.sh https://raw.githubusercontent.com/robbyrussell/oh-my-zsh/master/tools/install.sh
|
||||
sh install.sh
|
||||
```
|
||||
@@ -1,13 +0,0 @@
|
||||
---
|
||||
{}
|
||||
---
|
||||
|
||||
Script zum Installieren
|
||||
```shell
|
||||
type -p curl >/dev/null || (sudo apt update && sudo apt install curl -y)
|
||||
curl -fsSL https://cli.github.com/packages/githubcli-archive-keyring.gpg | sudo dd of=/usr/share/keyrings/githubcli-archive-keyring.gpg \
|
||||
&& sudo chmod go+r /usr/share/keyrings/githubcli-archive-keyring.gpg \
|
||||
&& echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/githubcli-archive-keyring.gpg] https://cli.github.com/packages stable main" | sudo tee /etc/apt/sources.list.d/github-cli.list > /dev/null \
|
||||
&& sudo apt update \
|
||||
&& sudo apt install gh -y
|
||||
```
|
||||
@@ -1,84 +0,0 @@
|
||||
---
|
||||
title: Integrate git diffs with word docx files
|
||||
source: https://github.com/vigente/gerardus/wiki/Integrate-git-diffs-with-word-docx-files
|
||||
---
|
||||
|
||||
# [Integrate git diffs with word docx files](https://github.com/vigente/gerardus/wiki/Integrate-git-diffs-with-word-docx-files)
|
||||
|
||||
This section was inspired by Martin Fenner's ["Using Microsoft Word with git"](http://blog.martinfenner.org/2014/08/25/using-microsoft-word-with-git/).
|
||||
|
||||
To configure git diff:
|
||||
|
||||
1. [**Install pandoc**](http://pandoc.org/installing.html).
|
||||
2. Tell git how to handle diffs of .docx files.
|
||||
1. Create or edit file ~/.gitconfig (linux, Mac) or "c:\\Documents and Settings\\user.gitconfig" (Windows) to add
|
||||
|
||||
```gitconfig
|
||||
[diff "pandoc"]
|
||||
textconv=pandoc --to=markdown
|
||||
prompt = false
|
||||
[alias]
|
||||
wdiff = diff --word-diff=color --unified=1
|
||||
```
|
||||
|
||||
2. In your paper directory, create or edit file .gitattributes (linux, Windows and Mac) to add
|
||||
|
||||
```shell
|
||||
*.docx diff=pandoc
|
||||
```
|
||||
|
||||
3. You can commit .gitattributes so that it stays with your paper for use in other computers, but you'll need to edit ~/.gitconfig in every new computer you want to use.
|
||||
|
||||
|
||||
Now you can see a pretty coloured diff with the changes you have made to your .docx file since the last commit
|
||||
|
||||
```shell
|
||||
git wdiff file.docx
|
||||
```
|
||||
|
||||
To see all changes over time
|
||||
|
||||
```shell
|
||||
git log -p --word-diff=color file.docx
|
||||
```
|
||||
|
||||
## Automatically when running `git commit`.
|
||||
|
||||
This is only going to work from linux/Mac or Windows running git from a bash shell.
|
||||
|
||||
1. [**Install pandoc**](http://pandoc.org/installing.html). Pandoc is a program to convert between different file formats. It's going to allow us to convert Word files (.docx) to Markdown (.md).
|
||||
|
||||
2. **Set up git hooks to enable automatic generation and tracking of Markdown copies of .docx files.**
|
||||
|
||||
Copy these hook files to your git project's `.git/hooks` directory and rename them, or soft-link to them with `ln -s`, and make them executable (`chmod u+x *.sh`):
|
||||
|
||||
- [pre-commit-git-diff-docx.sh](https://github.com/vigente/gerardus/blob/master/shell-script/pre-commit-git-diff-docx.sh) -\> .git/hooks/pre-commit
|
||||
- [post-commit-git-diff-docx.sh](https://github.com/vigente/gerardus/blob/master/shell-script/post-commit-git-diff-docx.sh) -\> .git/hooks/post-commit
|
||||
|
||||
Now every time you run `git commit`, the pre-commit hook will automatically run before you see the window to enter the log message. The hook is a script that makes a copy in Markdown format (.md) of every .docx file you are committing. The post-commit hook then amends the commit adding the .md files.
|
||||
|
||||
|
||||
## Manually by creating a Markdown copy of the .docx file.
|
||||
|
||||
This works in linux, Mac and Windows.
|
||||
|
||||
1. [**Install pandoc**](http://pandoc.org/installing.html).
|
||||
|
||||
2. **Edit your Word document** as needed.
|
||||
|
||||
3. **Run pandoc** from the linux or Windows command line. This will create a Markdown version of your file (without Figures, but with equations in latex format)
|
||||
|
||||
```shell
|
||||
pandoc -s file.docx -t markdown -o file.md
|
||||
|
||||
```
|
||||
|
||||
4. **Update the ChangeLog**
|
||||
|
||||
5. **Commit both files with git**
|
||||
|
||||
```shell
|
||||
git add file.docx file.md
|
||||
git commit
|
||||
|
||||
```
|
||||
@@ -1,904 +0,0 @@
|
||||
---
|
||||
title: Interfaces and Composition for Effective Unit Testing in Golang
|
||||
source: https://nathanleclaire.com/blog/2015/10/10/interfaces-and-composition-for-effective-unit-testing-in-golang/
|
||||
tags:
|
||||
- IT/Development/Go
|
||||
- IT/Testautomatisierung
|
||||
---
|
||||
|
||||
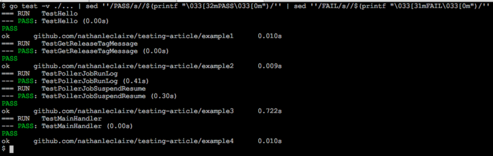
|
||||
|
||||
Go programs, when properly implemented, are fairly simple to test programatically. Go unit tests offer:
|
||||
|
||||
* Increased enforcement of behavior expectations beyond the compiler (providing critical assurance around rapidly changing code paths)
|
||||
* Fast execution speed (many popular modules’ tests can execute completely in seconds)
|
||||
* Easy integration into CI pipelines (`go test` is built right in)
|
||||
* Programmatic race condition detection through the `-race` flag
|
||||
|
||||
Consequently, they are by far one of the best ways to ensure code quality and prevent regressions. Tragically, however, unit testing seems to often be one of the most neglected aspects of any given Go project. It is often slept on until the effort required to implement it properly is Herculean.
|
||||
|
||||
This tendency seems at least partly due to a lack of quality resources explaining how to properly structure a Go program to be tested, and examples of doing so. This is a guide attempting to provide both and to increase the general quality of programs available in the Go community.
|
||||
|
||||
Don’t let the compiler lull you into a false sense of security: you’ll be glad you began testing sooner rather than later.
|
||||
|
||||
### Overview
|
||||
|
||||
In this article I will walk you through:
|
||||
|
||||
1. Concepts for ensuring testability
|
||||
2. Four concrete examples to learn how to test effectively in Go
|
||||
|
||||
By the end, you should be armed with the knowledge you need in order to go forth and test.
|
||||
|
||||
### Concepts
|
||||
|
||||
If you do not structure and test your program properly from the start, it will be astronomically more difficult to test down the road. This is a fairly universal axiom of programming but seems particularly true of Go testing due to its opinionated nature.
|
||||
|
||||
The three most important concepts to be able to use fluidly in order to test Go programs effectively are:
|
||||
|
||||
1. Using interfaces in your Go code
|
||||
2. Constructing higher-level interfaces through composition (embedding)
|
||||
3. Becoming familiar with `go test` and the [`testing`](https://golang.org/pkg/testing/) module
|
||||
|
||||
Let’s take a look at each one and why it is important.
|
||||
|
||||
## Using interfaces
|
||||
|
||||
You may be familiar with the use of interfaces from working through the Go walkthrough or from the official documentation. What you may not be familiar with is why interfaces are so important and why you should begin using your own interfaces as soon as possible.
|
||||
|
||||
For those who are unfamiliar with interfaces, I highly recommend you [read the official documentation](https://golang.org/doc/effective_go.html#interfaces) to understand how they work (I also have an [article on interfaces](https://nathanleclaire.com/blog/2015/03/09/youre-not-using-this-enough-part-one-go-interfaces/)).
|
||||
|
||||
Long story short:
|
||||
|
||||
1. Interfaces let you define a set of methods a type (often `struct`) must define to be considered an implementation of that interface.
|
||||
2. When any given type implements all the methods of that interface, the Go compiler automatically knows that it is allowed to be used as that type.
|
||||
|
||||
This is used to great effect in the Go standard library so that, for instance, the same interface in `database/sql` can be used to write functionality that can interact with a variety of different databases using the same code.
|
||||
|
||||
Fledgling Go programmers may be familiar with writing unit tests in other languages such as Java, Python, or PHP, and using “stubs” or “mocks” to fake out the results of a method call and explore the various code paths you want to exercise in a fine-grained way. What many don’t seem to realize, however, is that interfaces can and should be used for this same type of operation in Go.
|
||||
|
||||
Due to being built into the language and supported in a huge way by the standard library, interfaces offer the test author in Go a vast amount of power and flexibility when used the correct way. One can wrap operations which are outside of the scope of a given test in an interface, and selectively re-implement them for the relevant tests. This allows the author to control every aspect of the program’s behavior within the test suite.
|
||||
|
||||
## Using composition
|
||||
|
||||
Interfaces are great for increased flexibility and control, but they are not enough on their own. Consider, for instance, the case where we have a `struct` which exposes a large set of methods to external consumers but also relies on these methods internally for some operations. We cannot wrap the whole object in an interface to control the methods it relies on, since this would require implementing the method we are trying to test.
|
||||
|
||||
Consequently, it becomes critical to compose larger interfaces from smaller ones through embedding to enable control of the methods which we _do_ want to change while still being able to test the ones we don’t want to change. This is a bit easier to see in an actual example, so I will eschew further abstract discussion until later in the article.
|
||||
|
||||
## `go test` and `testing`
|
||||
|
||||
This may seem obvious, but at least skimming the documentation for the `go test` command and the `testing` package and familiarizing yourself with how each works will make you much more effective at unit testing. The tools and library can seem a bit quirky if you are not familiar with them or with Go tooling in general (though they are very nice once acclimated).
|
||||
|
||||
It might be tempting to reach for a 3rd party package which promises to help with testing, but I highly encourage you to avoid doing so until you have a handle on the basics and are absolutely certain that the dependency will bring you more benefit than headaches.
|
||||
|
||||
Please, please, read the docs, but the basic knowledge you need to get started is:
|
||||
|
||||
* For any given file `foo.go`, the test is placed in a file in the same directory called `foo_test.go`.
|
||||
* `go test .` runs the unit tests in the current directory. `go test ./...` will run the tests in the current directory and every directory underneath it. `go test foo_test.go` not work because the file under test is not included.
|
||||
* The `-v` flag for `go test` is useful because it prints out verbose output (the result of each individual test).
|
||||
* Tests are functions which accept a `testing.T` struct pointer as an argument and are idiomatically called `TestFoo`, where `Foo` is the name of the function being tested.
|
||||
* You usually do not assert that conditions you expect are true like you may be accustomed to; rather, you fail the test by calling `t.Fatal` if you encounter conditions which are different than you expect.
|
||||
* Displaying output in tests may not work [how you expect](https://stackoverflow.com/questions/23205419/how-do-you-print-in-a-go-test-using-the-testing-package) – use the `t.Log` and/or `t.Logf` methods if you need to print information in a test.
|
||||
|
||||
### Examples
|
||||
|
||||
Enough discussion of fundamentals; let’s write some tests.
|
||||
|
||||
If you are curious to check out the source code in its final form for the following examples, they are organized in separate directories at [https://github.com/nathanleclaire/testing-article](https://github.com/nathanleclaire/testing-article).
|
||||
|
||||
## Example #1: Hello, Testing!
|
||||
|
||||
I’m assuming that you have Go installed and configured for these exercises.
|
||||
|
||||
Make a new Go package in your `GOPATH`, e.g. I would execute:
|
||||
|
||||
$ mkdir -p ~/go/src/github.com/nathanleclaire/testing-article
|
||||
$ cd ~/go/src/github.com/nathanleclaire/testing-article
|
||||
|
||||
Create a file `hello.go`:
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
)
|
||||
|
||||
func hello() string {
|
||||
return "Hello, Testing!"
|
||||
}
|
||||
|
||||
func main() {
|
||||
fmt.Println(hello())
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Now let’s write a test for `hello.go`.
|
||||
|
||||
Make a file `hello_test.go` in the same directory:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"testing"
|
||||
)
|
||||
|
||||
func TestHello(t *testing.T) {
|
||||
expectedStr := "Hello, Testing!"
|
||||
result := hello()
|
||||
if result != expectedStr {
|
||||
t.Fatalf("Expected %s, got %s", expectedStr, result)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Hopefully this test should be pretty self-explanatory. We inject an instance of `*testing.T` to the test, and this is used to control the test flow and output. We set what our expectations for the function call are in one variable, and then check it against what the function actually returns.
|
||||
|
||||
To run the test:
|
||||
|
||||
$ go test -v
|
||||
=== RUN TestHello
|
||||
\-\-\- PASS: TestHello (0.00s)
|
||||
PASS
|
||||
ok github.com/nathanleclaire/testing-article 0.006s
|
||||
|
||||
Great, now let’s try something more complex.
|
||||
|
||||
## Example #2: Using an interface to mock results
|
||||
|
||||
Let’s say that as part of a program we wanted to get some data from the GitHub API. In this case, let’s say we wanted to query the git tag which the latest release of a given repo corresponds to.
|
||||
|
||||
We _could_ write some code like the following to do so:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"fmt"
|
||||
"io/ioutil"
|
||||
"log"
|
||||
"net/http"
|
||||
)
|
||||
|
||||
type ReleasesInfo struct {
|
||||
Id uint `json:"id"`
|
||||
TagName string `json:"tag_name"`
|
||||
}
|
||||
|
||||
// Function to actually query the GitHub API for the release information.
|
||||
func getLatestReleaseTag(repo string) (string, error) {
|
||||
apiUrl := fmt.Sprintf("https://api.github.com/repos/%s/releases", repo)
|
||||
response, err := http.Get(apiUrl)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
defer response.Body.Close()
|
||||
|
||||
body, err := ioutil.ReadAll(response.Body)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
releases := []ReleasesInfo{}
|
||||
|
||||
if err := json.Unmarshal(body, &releases); err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
tag := releases[0].TagName
|
||||
|
||||
return tag, nil
|
||||
}
|
||||
|
||||
// Function to get the message to display to the end user.
|
||||
func getReleaseTagMessage(repo string) (string, error) {
|
||||
tag, err := getLatestReleaseTag(repo)
|
||||
if err != nil {
|
||||
return "", fmt.Errorf("Error querying GitHub API: %s", err)
|
||||
}
|
||||
|
||||
return fmt.Sprintf("The latest release is %s", tag), nil
|
||||
}
|
||||
|
||||
func main() {
|
||||
msg, err := getReleaseTagMessage("docker/machine")
|
||||
if err != nil {
|
||||
fmt.Fprintln(os.Stderr, msg)
|
||||
}
|
||||
|
||||
fmt.Println(msg)
|
||||
}
|
||||
```
|
||||
|
||||
And, in fact, this is commonly how one will see Go programs structured in the wild.
|
||||
|
||||
But it is not very testable. If we were to test the `getLatestReleaseTag` function directly, our test would fail if the GitHub API went down or if GitHub decided to rate limit us (which is likely if running the test frequently such as in CI environments). Additionally, we’d have to update the test every time that the latest release tag changed. Yuck.
|
||||
|
||||
What to do? We can re-define the way that this is implemented to be a lot more testable. If we query the GitHub API through an `interface` instead of directly through a function call, then we can actually control the result of what will be returned through our test.
|
||||
|
||||
Let’s redefine the program a bit to have an interface, `ReleaseInfoer`, of which one implementation can be `GithubReleaseInfoer`. `ReleaseInfoer` only has one method, `GetLatestReleaseTag`, which is similar in nature to our function above (it accepts a repository name as an argument and returns a `string` and/or `error` for the result).
|
||||
|
||||
The `interface` definition looks like:
|
||||
|
||||
```go
|
||||
type ReleaseInfoer interface {
|
||||
GetLatestReleaseTag(string) (string, error)
|
||||
}
|
||||
```
|
||||
|
||||
Then, we can update our above bare function call to be a method on a `GithubReleaseInfoer` struct instead:
|
||||
|
||||
```go
|
||||
type GithubReleaseInfoer struct {}
|
||||
|
||||
// Function to actually query the GitHub API for the release information.
|
||||
func (gh GithubReleaseInfoer) GetLatestReleaseTag(repo string) (string, error) {
|
||||
// ... same code as above
|
||||
}
|
||||
```
|
||||
|
||||
And, consequently, update the `getReleaseTagMessage` and `main` functions like so:
|
||||
|
||||
```go
|
||||
// Function to get the message to display to the end user.
|
||||
func getReleaseTagMessage(ri ReleaseInfoer, repo string) (string, error) {
|
||||
tag, err := ri.GetLatestReleaseTag(repo)
|
||||
if err != nil {
|
||||
return "", fmt.Errorf("Error query GitHub API: %s", err)
|
||||
}
|
||||
return fmt.Sprintf("The latest release is %s", tag), nil
|
||||
}
|
||||
|
||||
func main() {
|
||||
gh := GithubReleaseInfoer{}
|
||||
msg, err := getReleaseTagMessage(gh, "docker/machine")
|
||||
if err != nil {
|
||||
fmt.Fprintln(os.Stderr, err)
|
||||
os.Exit(1)
|
||||
}
|
||||
|
||||
fmt.Println(msg)
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Why bother? Well, now we can actually test the `getReleaseTagMessage` function by defining a new struct that fulfills the `ReleaseInfoer` interface with a method which we control completely. That way, at test time, we can ensure that the behavior of the method which we depend on is exactly as we expect.
|
||||
|
||||
We could define a `FakeReleaseInfoer` struct which behaves however we want. We simply define what to return in the parameters of the struct.
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import "testing"
|
||||
|
||||
type FakeReleaseInfoer struct {
|
||||
Tag string
|
||||
Err error
|
||||
}
|
||||
|
||||
func (f FakeReleaseInfoer) GetLatestReleaseTag(repo string) (string, error) {
|
||||
if f.Err != nil {
|
||||
return "", f.Err
|
||||
}
|
||||
|
||||
return f.Tag, nil
|
||||
}
|
||||
|
||||
func TestGetReleaseTagMessage(t *testing.T) {
|
||||
f := FakeReleaseInfoer{
|
||||
Tag: "v0.1.0",
|
||||
Err: nil,
|
||||
}
|
||||
|
||||
expectedMsg := "The latest release is v0.1.0"
|
||||
msg, err := getReleaseTagMessage(f, "dev/null")
|
||||
if err != nil {
|
||||
t.Fatalf("Expected err to be nil but it was %s", err)
|
||||
}
|
||||
|
||||
if expectedMsg != msg {
|
||||
t.Fatalf("Expected %s but got %s", expectedMsg, msg)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You can see above that the `FakeReleaseInfoer` struct was set to return `"v0.1.0"` and the returned error was set to nil.
|
||||
|
||||
That’s great for this case, but notice we’re not testing our error return. It would be preferable to cover this case as well.
|
||||
|
||||
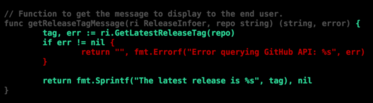
|
||||
|
||||
Is there any way to express the various paths and return possibilities for this function concisely in our unit tests? Certainly. We can test a wide variety of cases in one function with an anonymous struct slice (thanks to [Andrew Gerrand’s talk](https://talks.golang.org/2012/10things.slide#3) and [David Cheney’s article on test tables](http://dave.cheney.net/2013/06/09/writing-table-driven-tests-in-go) for this idea).
|
||||
|
||||
```go
|
||||
func TestGetReleaseTagMessage(t *testing.T) {
|
||||
cases := []struct {
|
||||
f FakeReleaseInfoer
|
||||
repo string
|
||||
expectedMsg string
|
||||
expectedErr error
|
||||
}{
|
||||
{
|
||||
f: FakeReleaseInfoer{
|
||||
Tag: "v0.1.0",
|
||||
Err: nil,
|
||||
},
|
||||
repo: "doesnt/matter",
|
||||
expectedMsg: "The latest release is v0.1.0",
|
||||
expectedErr: nil,
|
||||
},
|
||||
{
|
||||
f: FakeReleaseInfoer{
|
||||
Tag: "v0.1.0",
|
||||
Err: errors.New("TCP timeout"),
|
||||
},
|
||||
repo: "doesnt/foo",
|
||||
expectedMsg: "",
|
||||
expectedErr: errors.New("Error querying GitHub API: TCP timeout"),
|
||||
},
|
||||
}
|
||||
|
||||
for _, c := range cases {
|
||||
msg, err := getReleaseTagMessage(c.f, c.repo)
|
||||
if !reflect.DeepEqual(err, c.expectedErr) {
|
||||
t.Errorf("Expected err to be %q but it was %q", c.expectedErr, err)
|
||||
}
|
||||
|
||||
if c.expectedMsg != msg {
|
||||
t.Errorf("Expected %q but got %q", c.expectedMsg, msg)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Note the use of `reflect.DeepEqual` there. It’s a [useful method](https://golang.org/pkg/reflect/#DeepEqual) from the standard library which will check if two structs are equal by value. It’s used to check error equality here, but it also could be used to compare the contents of two `struct`s. Just `==` alone won’t work for equality for this due to the use of `errors.New` (I tried using the `Error` method but that doesn’t work with `nil` value errors, so if anyone has better ideas please mention it in the comments).
|
||||
|
||||
Something to take note of is that this technique can be used to gain more control over 3rd party libraries in tests. For instance, [Sam Alba’s Golang Docker client](https://github.com/samalba/dockerclient) will give you a `type DockerClient struct` to interact with, which is not easily mock-able for tests. But you could create a `type DockerClient interface` in your own module which specifies the methods you are using on `dockerclient.DockerClient` as the things to implement, use that in your code instead, and then create your own version of that interface for testing.
|
||||
|
||||
Aside from the benefits to testability which I’m focusing on here, using interfaces can potentially be a huge boon for future extensibility of your program. If you have structured every component which interacts with the GitHub API as working through an interface, for instance, you won’t need to change your program’s architecture at all to add support for another source code hosting platform. You could simply implement a `BitbucketReleaseInfoer` and use that wherever you want to wrap the Bitbucket API instead of GitHub. Granted, this type of wrapper abstraction won’t work for every use case, but it can be used powerfully to mock out external and internal dependencies.
|
||||
|
||||
## Example #3: Using composition to test a large struct
|
||||
|
||||
The above example illustrates an introductory concept which can be very useful, but sometimes we might want to mock out parts of one `struct` which depend on each other and test each piece separately.
|
||||
|
||||
If you find yourself with an `interface` or `struct` which is starting to get larger in terms of the number of methods exposed, it might be a good candidate for breaking into several smaller `interfaces` and [embedding](https://golang.org/doc/effective_go.html#embedding) them. For instance, let’s suppose that we have a `Job` interface which exposes a `Log` method both internally and externally to the structure. Any `interface` can be passed to this method with a variable number of arguments. It also provides supported for `Run`ing, `Suspend`ing, and `Resume`ing jobs.
|
||||
|
||||
```Go
|
||||
type Job interface {
|
||||
Log(...interface{})
|
||||
Suspend() error
|
||||
Resume() error
|
||||
Run() error
|
||||
}
|
||||
```
|
||||
|
||||
If we are working on developing a `struct` which implements this `interface`, we may want to use the `Log` method inside of the `Suspend` and `Resume` methods to keep track of what has happened. Therefore, faking out the whole interface like in the previous example won’t work. How do we test the whole structure while mocking out only part of the interface?
|
||||
|
||||
We can do so by defining several smaller interfaces and using composition. Consider an implementation of a `Job`, `PollerJob`, which can be used for questionable homebrew system monitoring software. My first crack at coding it was this:
|
||||
|
||||
```Go
|
||||
package main
|
||||
|
||||
import (
|
||||
"log"
|
||||
"net/http"
|
||||
"time"
|
||||
)
|
||||
|
||||
type Job interface {
|
||||
Log(...interface{})
|
||||
Suspend() error
|
||||
Resume() error
|
||||
Run() error
|
||||
}
|
||||
|
||||
type PollerJob struct {
|
||||
suspend chan bool
|
||||
resume chan bool
|
||||
resourceUrl string
|
||||
inMemLog string
|
||||
}
|
||||
|
||||
func NewPollerJob(resourceUrl string) PollerJob {
|
||||
return PollerJob{
|
||||
resourceUrl: resourceUrl,
|
||||
suspend: make(chan bool),
|
||||
resume: make(chan bool),
|
||||
}
|
||||
}
|
||||
|
||||
func (p PollerJob) Log(args ...interface{}) {
|
||||
log.Println(args...)
|
||||
}
|
||||
|
||||
func (p PollerJob) Suspend() error {
|
||||
p.suspend <- true
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p PollerJob) PollServer() error {
|
||||
resp, err := http.Get(p.resourceUrl)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
p.Log(p.resourceUrl, "--", resp.Status)
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p PollerJob) Run() error {
|
||||
for {
|
||||
select {
|
||||
case <-p.suspend:
|
||||
<-p.resume
|
||||
default:
|
||||
if err := p.PollServer(); err != nil {
|
||||
p.Log("Error trying to get resource: ", err)
|
||||
}
|
||||
time.Sleep(1 * time.Second)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (p PollerJob) Resume() error {
|
||||
p.resume <- true
|
||||
return nil
|
||||
}
|
||||
|
||||
func main() {
|
||||
p := NewPollerJob("https://nathanleclaire.com")
|
||||
go p.Run()
|
||||
time.Sleep(5 * time.Second)
|
||||
|
||||
p.Log("Suspending monitoring of server for 5 seconds...")
|
||||
p.Suspend()
|
||||
time.Sleep(5 * time.Second)
|
||||
|
||||
p.Log("Resuming job...")
|
||||
p.Resume()
|
||||
|
||||
// Wait for a bit before exiting
|
||||
time.Sleep(5 * time.Second)
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
The output of the above program, when run, looks like:
|
||||
|
||||
$ go run -race job.go
|
||||
2015/10/11 20:37:59 https://nathanleclaire.com -- 200 OK
|
||||
2015/10/11 20:38:01 https://nathanleclaire.com -- 200 OK
|
||||
2015/10/11 20:38:02 https://nathanleclaire.com -- 200 OK
|
||||
2015/10/11 20:38:03 https://nathanleclaire.com -- 200 OK
|
||||
2015/10/11 20:38:04 https://nathanleclaire.com -- 200 OK
|
||||
2015/10/11 20:38:04 Suspending monitoring of server for 5 seconds...
|
||||
2015/10/11 20:38:10 Resuming job...
|
||||
2015/10/11 20:38:10 https://nathanleclaire.com -- 200 OK
|
||||
2015/10/11 20:38:11 https://nathanleclaire.com -- 200 OK
|
||||
2015/10/11 20:38:12 https://nathanleclaire.com -- 200 OK
|
||||
2015/10/11 20:38:14 https://nathanleclaire.com -- 200 OK
|
||||
2015/10/11 20:38:15 https://nathanleclaire.com -- 200 OK
|
||||
2015/10/11 20:38:16 https://nathanleclaire.com -- 200 OK
|
||||
|
||||
If we want to test the various complex interactions at play here, how do we do so? With everything in one structure, it seems to be daunting to test each component of the program in isolation and without using external resources.
|
||||
|
||||
The solution is to break the higher-level `Job` interface into several other interfaces and embed them all into the `PollerJob` struct, allowing us to mock out each piece in isolation when we do testing.
|
||||
|
||||
We can break the `Job` interface into a few different interfaces like so:
|
||||
|
||||
type Logger interface {
|
||||
Log(...interface{})
|
||||
}
|
||||
|
||||
type SuspendResumer interface {
|
||||
Suspend() error
|
||||
Resume() error
|
||||
}
|
||||
|
||||
type Job interface {
|
||||
Logger
|
||||
SuspendResumer
|
||||
Run() error
|
||||
}
|
||||
|
||||
|
||||
You can see that there is an interface `SuspendResumer` for handling suspend/resume functionality, and an interface `Log` whose only purpose is to manage the `Log` method. Additionally, we will create a `PollServer` interface for controlling the status calls to the server we are polling:
|
||||
|
||||
type ServerPoller interface {
|
||||
PollServer() (string, error)
|
||||
}
|
||||
|
||||
|
||||
With all of these component interfaces in place, we can begin re-constructing our `PollerJob` implementation of the `Job` interface. By embedding `Logger` and `ServerPoller` (both interfaces) and a pointer to a `PollSuspendResumer` struct, we ensure that the compiler is satisfied for the definition of `PollerJob` as a `Job`. We provide a `NewPollerJob` function which will provide an instance of the struct with all of the components set up and initialized properly. Notice that we use our own implementation of the components such as `Logger` in the struct literal that this function returns.
|
||||
|
||||
```go
|
||||
type PollerLogger struct{}
|
||||
|
||||
type URLServerPoller struct {
|
||||
resourceUrl string
|
||||
}
|
||||
|
||||
type PollSuspendResumer struct {
|
||||
SuspendCh chan bool
|
||||
ResumeCh chan bool
|
||||
}
|
||||
|
||||
type PollerJob struct {
|
||||
WaitDuration time.Duration
|
||||
ServerPoller
|
||||
Logger
|
||||
*PollSuspendResumer
|
||||
}
|
||||
|
||||
func NewPollerJob(resourceUrl string, waitDuration time.Duration) PollerJob {
|
||||
return PollerJob{
|
||||
WaitDuration: waitDuration,
|
||||
Logger: &PollerLogger{},
|
||||
ServerPoller: &URLServerPoller{
|
||||
resourceUrl: resourceUrl,
|
||||
},
|
||||
PollSuspendResumer: &PollSuspendResumer{
|
||||
SuspendCh: make(chan bool),
|
||||
ResumeCh: make(chan bool),
|
||||
},
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The rest of the code defines the methods on the relevant structs, and is available in full \[on GitHub here\]().
|
||||
|
||||
This provides us with the flexibility that we need to actually fake out each component of the `PollerJob` struct in isolation when we do testing. Each “mock” component can be re-used and/or re-worked to be more flexible where needed, allowing us to cover a wide range of possible outcomes from the components which we depend on.
|
||||
|
||||
We can now test `Run` in isolation, and without talking to any actual servers. We simply control what the `ServerPoller` returns and verify that what was written to the `Logger` was as we expect by re-implementing those interfaces. Consequently the test file for `PollerJob` looks similar to this.
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
"testing"
|
||||
"time"
|
||||
)
|
||||
|
||||
type ReadableLogger interface {
|
||||
Logger
|
||||
Read() string
|
||||
}
|
||||
|
||||
type MessageReader struct {
|
||||
Msg string
|
||||
}
|
||||
|
||||
func (mr *MessageReader) Read() string {
|
||||
return mr.Msg
|
||||
}
|
||||
|
||||
type LastEntryLogger struct {
|
||||
*MessageReader
|
||||
}
|
||||
|
||||
func (lel *LastEntryLogger) Log(args ...interface{}) {
|
||||
lel.Msg = fmt.Sprint(args...)
|
||||
}
|
||||
|
||||
type DiscardFirstWriteLogger struct {
|
||||
*MessageReader
|
||||
writtenBefore bool
|
||||
}
|
||||
|
||||
func (dfwl *DiscardFirstWriteLogger) Log(args ...interface{}) {
|
||||
if dfwl.writtenBefore {
|
||||
dfwl.Msg = fmt.Sprint(args...)
|
||||
}
|
||||
dfwl.writtenBefore = true
|
||||
}
|
||||
|
||||
type FakeServerPoller struct {
|
||||
result string
|
||||
err error
|
||||
}
|
||||
|
||||
func (fsp FakeServerPoller) PollServer() (string, error) {
|
||||
return fsp.result, fsp.err
|
||||
}
|
||||
|
||||
func TestPollerJobRunLog(t *testing.T) {
|
||||
waitBeforeReading := 100 * time.Millisecond
|
||||
shortInterval := 20 * time.Millisecond
|
||||
longInterval := 200 * time.Millisecond
|
||||
|
||||
testCases := []struct {
|
||||
p PollerJob
|
||||
logger ReadableLogger
|
||||
sp ServerPoller
|
||||
expectedMsg string
|
||||
}{
|
||||
{
|
||||
p: NewPollerJob("madeup.website", shortInterval),
|
||||
logger: &LastEntryLogger{&MessageReader{}},
|
||||
sp: FakeServerPoller{"200 OK", nil},
|
||||
expectedMsg: "200 OK",
|
||||
},
|
||||
{
|
||||
p: NewPollerJob("down.website", shortInterval),
|
||||
logger: &LastEntryLogger{&MessageReader{}},
|
||||
sp: FakeServerPoller{"500 SERVER ERROR", nil},
|
||||
expectedMsg: "500 SERVER ERROR",
|
||||
},
|
||||
{
|
||||
p: NewPollerJob("error.website", shortInterval),
|
||||
logger: &LastEntryLogger{&MessageReader{}},
|
||||
sp: FakeServerPoller{"", errors.New("DNS probe failed")},
|
||||
expectedMsg: "Error trying to get state: DNS probe failed",
|
||||
},
|
||||
{
|
||||
p: NewPollerJob("some.website", longInterval),
|
||||
// Discard first write since we want to verify that no
|
||||
// additional logs get made after the first one (time
|
||||
// out)
|
||||
logger: &DiscardFirstWriteLogger{MessageReader: &MessageReader{}},
|
||||
sp: FakeServerPoller{"200 OK", nil},
|
||||
expectedMsg: "",
|
||||
},
|
||||
}
|
||||
|
||||
for _, c := range testCases {
|
||||
c.p.Logger = c.logger
|
||||
c.p.ServerPoller = c.sp
|
||||
go c.p.Run()
|
||||
|
||||
time.Sleep(waitBeforeReading)
|
||||
|
||||
if c.logger.Read() != c.expectedMsg {
|
||||
t.Errorf("Expected message did not align with what was written:\n\texpected: %q\n\tactual: %q", c.expectedMsg, c.logger.Read())
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Note the creative flexibility that making our own `ReadableLogger` interface for testing, and being able to implement `Logger` in a variety of ways, provides us. `Suspend` and `Resume` functionality can likewise be tested meticulously by controlling the `ServerPoller` interface component of `JobPoller`.
|
||||
|
||||
```go
|
||||
func TestPollerJobSuspendResume(t *testing.T) {
|
||||
p := NewPollerJob("foobar.com", 20*time.Millisecond)
|
||||
waitBeforeReading := 100 * time.Millisecond
|
||||
expectedLogLine := "200 OK"
|
||||
normalServerPoller := &FakeServerPoller{expectedLogLine, nil}
|
||||
|
||||
logger := &LastEntryLogger{&MessageReader{}}
|
||||
p.Logger = logger
|
||||
p.ServerPoller = normalServerPoller
|
||||
|
||||
// First start the job / polling
|
||||
go p.Run()
|
||||
|
||||
time.Sleep(waitBeforeReading)
|
||||
|
||||
if logger.Read() != expectedLogLine {
|
||||
t.Errorf("Line read from logger does not match what was expected:\n\texpected: %q\n\tactual: %q", expectedLogLine, logger.Read())
|
||||
}
|
||||
|
||||
// Then suspend the job
|
||||
if err := p.Suspend(); err != nil {
|
||||
t.Errorf("Expected suspend error to be nil but got %q", err)
|
||||
}
|
||||
|
||||
// Fake the log line to detect if poller is still running
|
||||
newExpectedLogLine := "500 Internal Server Error"
|
||||
logger.MessageReader.Msg = newExpectedLogLine
|
||||
|
||||
// Give it a second to poll if it's going to poll
|
||||
time.Sleep(waitBeforeReading)
|
||||
|
||||
// If this log writes, we know we are polling the server when we're not
|
||||
// supposed to (job should be suspended).
|
||||
if logger.Read() != newExpectedLogLine {
|
||||
t.Errorf("Line read from logger does not match what was expected:\n\texpected: %q\n\tactual: %q", newExpectedLogLine, logger.Read())
|
||||
}
|
||||
|
||||
if err := p.Resume(); err != nil {
|
||||
t.Errorf("Expected resume error to be nil but got %q", err)
|
||||
}
|
||||
|
||||
// Give it a second to poll if it's going to poll
|
||||
time.Sleep(waitBeforeReading)
|
||||
|
||||
if logger.Read() != expectedLogLine {
|
||||
t.Errorf("Line read from logger does not match what was expected:\n\texpected: %q\n\tactual: %q", expectedLogLine, logger.Read())
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
It certainly might seem like a lot of boilerplate to test a small file, but it will scale well as the size of the code base grows. Mocking out dependent bits in this fashion makes it easier to specify what behavior should be like in error cases or to control flow in the case of tricky concurrency issues.
|
||||
|
||||
Due to the practical and creative enhancements that interfaces offer to testability, it is preferred to wrap external dependencies in one and then combine them to create higher-order interfaces wherever possible. As you can hopefully see, even small one-method interfaces are useful to combine into bigger pieces of functionality.
|
||||
|
||||
## Example #4: Using and faking standard library functionality
|
||||
|
||||
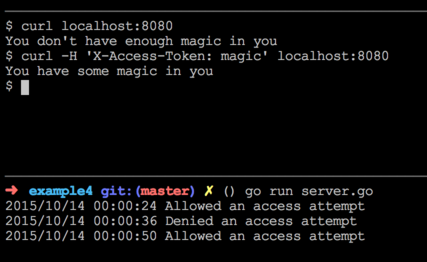
|
||||
|
||||
The concepts illustrated above are useful for your own programs, but you will also notice that many of the constructs in the Go standard library can be managed in your unit tests in a similar fashion (and indeed they _are_ frequently used in such a manner in the tests for the standard library itself).
|
||||
|
||||
Let’s take a look at testing an example HTTP server. It might be tempting to actually start up the HTTP server in a goroutine and send it the requests that you expect it to be able to handle directly (e.g. with `http.Get`). But that is far more like an integration test than a proper unit test. Let’s take a look at a little HTTP server and discuss how to approach testing it.
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"log"
|
||||
"net/http"
|
||||
)
|
||||
|
||||
func mainHandler(w http.ResponseWriter, r *http.Request) {
|
||||
token := r.Header.Get("X-Access-Token")
|
||||
if token == "magic" {
|
||||
fmt.Fprintf(w, "You have some magic in you\n")
|
||||
log.Println("Allowed an access attempt")
|
||||
} else {
|
||||
http.Error(w, "You don't have enough magic in you", http.StatusForbidden)
|
||||
log.Println("Denied an access attempt")
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
http.HandleFunc("/", mainHandler)
|
||||
log.Fatal(http.ListenAndServe(":8080", nil))
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
The above HTTP server listens on `:8080/` for requests, and checks if they have a `X-Access-Token` header set. If the token matches our `"magic"` value, we allow the users access and return a HTTP 200 OK status code. Otherwise, we reject the request with a HTTP 403 Access Forbidden status code. This is a crude imitation of how some API servers handle authorization. How can we test it?
|
||||
|
||||
As you can see, the `mainHandler` function accepts two arguments: a `http.ResponseWriter` (note that it is an `interface`, which you can verify by reading the source of `http` or the documentation) and a `http.Request` struct pointer. To test the handler, we could make our own implementation of the [`http.ResponseWriter` interface](https://golang.org/pkg/net/http/#ResponseWriter) which we could also read from later, but fortunately the Go authors have already provided a `httptest` package with a [`ResponseRecorder` struct](https://golang.org/pkg/net/http/httptest/#ResponseRecorder) which is meant to help with exactly this issue. Having such a module to provide common testing functionality where needed is a useful and not uncommon pattern.
|
||||
|
||||
Given that, we can also create a hand-crafted `http.Request` struct by calling `NewRequest` with the expected parameters. We simply have to call `Header.Set` on the `Request` to set the desired header. We specify in the `NewRequest` method that it should be `GET` method and not contain any information in the request body, though we could also test `POST` requests and so on if we wanted to by creating structures for those instead.
|
||||
|
||||
The initial test looks like this:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"net/http"
|
||||
"net/http/httptest"
|
||||
"testing"
|
||||
)
|
||||
|
||||
func TestMainHandler(t *testing.T) {
|
||||
rootRequest, err := http.NewRequest("GET", "/", nil)
|
||||
if err != nil {
|
||||
t.Fatal("Root request error: %s", err)
|
||||
}
|
||||
|
||||
cases := []struct {
|
||||
w *httptest.ResponseRecorder
|
||||
r *http.Request
|
||||
accessTokenHeader string
|
||||
expectedResponseCode int
|
||||
expectedResponseBody []byte
|
||||
}{
|
||||
{
|
||||
w: httptest.NewRecorder(),
|
||||
r: rootRequest,
|
||||
accessTokenHeader: "magic",
|
||||
expectedResponseCode: http.StatusOK,
|
||||
expectedResponseBody: []byte("You have some magic in you\n"),
|
||||
},
|
||||
{
|
||||
w: httptest.NewRecorder(),
|
||||
r: rootRequest,
|
||||
accessTokenHeader: "",
|
||||
expectedResponseCode: http.StatusForbidden,
|
||||
expectedResponseBody: []byte("You don't have enough magic in you\n"),
|
||||
},
|
||||
}
|
||||
|
||||
for _, c := range cases {
|
||||
c.r.Header.Set("X-Access-Token", c.accessTokenHeader)
|
||||
|
||||
mainHandler(c.w, c.r)
|
||||
|
||||
if c.expectedResponseCode != c.w.Code {
|
||||
t.Errorf("Status Code didn't match:\n\t%q\n\t%q", c.expectedResponseCode, c.w.Code)
|
||||
}
|
||||
|
||||
if !bytes.Equal(c.expectedResponseBody, c.w.Body.Bytes()) {
|
||||
t.Errorf("Body didn't match:\n\t%q\n\t%q", string(c.expectedResponseBody), c.w.Body.String())
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
However, there is one glaring omission of testing functionality we can account for. We do not check that what was written to the `log` is what we expected at all. How can we do so?
|
||||
|
||||
Well, if we examine the source for the standard library’s `log` package, we can see that the `log.Println` method directly wraps an instance of the `Logger` struct which internally calls the `Write` method on a `Writer` interface (in the case of the `std` struct which is written to if you invoke `log.*` directly, that `Writer` is `os.Stdout`). Hm, I wonder if there’s any way we could set that interface to whatever we want so we can verify that what was written is what we expected?
|
||||
|
||||
Naturally, there is a way to do so. We can invoke the `log.SetOutput` method to specify our own custom writer for logging to. In order to pass something in which we can read from later, we create the `Writer` to pass in using [`io.Pipe`](https://golang.org/pkg/io/#Pipe). This will provide us with a `Reader` that we can use to `Read` the subsequent `Write` calls made in the `Logger`. We wrap the given `PipeReader` in a `bufio.Reader` so that we can easily read line-by-line using a call to `bufio.Reader`’s `ReadString` method.
|
||||
|
||||
Note that in `PipeWriter`’s [documentation](https://golang.org/pkg/io/#PipeWriter.Write) it says:
|
||||
|
||||
> Write implements the standard Write interface: it writes data to the pipe, blocking until readers have consumed all the data or the read end is closed.
|
||||
|
||||
Therefore, we have to concurrently read from the `PipeReader` as the `mainHandler` function is writing to it, so we run that bit of the test in its own goroutine. In my original version I got this wrong and discovered my error by using `go test`’s `-timeout` flag, which will panic any given test if it stalls for longer than the specified interval.
|
||||
|
||||
Put together, it all looks like this:
|
||||
|
||||
```go
|
||||
func TestMainHandler(t *testing.T) {
|
||||
rootRequest, err := http.NewRequest("GET", "/", nil)
|
||||
if err != nil {
|
||||
t.Fatal("Root request error: %s", err)
|
||||
}
|
||||
|
||||
cases := []struct {
|
||||
w *httptest.ResponseRecorder
|
||||
r *http.Request
|
||||
accessTokenHeader string
|
||||
expectedResponseCode int
|
||||
expectedResponseBody []byte
|
||||
expectedLogs []string
|
||||
}{
|
||||
{
|
||||
w: httptest.NewRecorder(),
|
||||
r: rootRequest,
|
||||
accessTokenHeader: "magic",
|
||||
expectedResponseCode: http.StatusOK,
|
||||
expectedResponseBody: []byte("You have some magic in you\n"),
|
||||
expectedLogs: []string{
|
||||
"Allowed an access attempt\n",
|
||||
},
|
||||
},
|
||||
{
|
||||
w: httptest.NewRecorder(),
|
||||
r: rootRequest,
|
||||
accessTokenHeader: "",
|
||||
expectedResponseCode: http.StatusForbidden,
|
||||
expectedResponseBody: []byte("You don't have enough magic in you\n"),
|
||||
expectedLogs: []string{
|
||||
"Denied an access attempt\n",
|
||||
},
|
||||
},
|
||||
}
|
||||
|
||||
for _, c := range cases {
|
||||
logReader, logWriter := io.Pipe()
|
||||
bufLogReader := bufio.NewReader(logReader)
|
||||
log.SetOutput(logWriter)
|
||||
|
||||
c.r.Header.Set("X-Access-Token", c.accessTokenHeader)
|
||||
|
||||
go func() {
|
||||
for _, expectedLine := range c.expectedLogs {
|
||||
msg, err := bufLogReader.ReadString('\n')
|
||||
if err != nil {
|
||||
t.Errorf("Expected to be able to read from log but got error: %s", err)
|
||||
}
|
||||
if !strings.HasSuffix(msg, expectedLine) {
|
||||
t.Errorf("Log line didn't match suffix:\n\t%q\n\t%q", expectedLine, msg)
|
||||
}
|
||||
}
|
||||
}()
|
||||
|
||||
mainHandler(c.w, c.r)
|
||||
|
||||
if c.expectedResponseCode != c.w.Code {
|
||||
t.Errorf("Status Code didn't match:\n\t%q\n\t%q", c.expectedResponseCode, c.w.Code)
|
||||
}
|
||||
|
||||
if !bytes.Equal(c.expectedResponseBody, c.w.Body.Bytes()) {
|
||||
t.Errorf("Body didn't match:\n\t%q\n\t%q", string(c.expectedResponseBody), c.w.Body.String())
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
I hope that this example illustrates clearly the value of having well-architected interfaces in the Go standard library as well as in your own code, and how reading the source code of modules upon which you are relying (including the Go standard library, which is meticulously documented) can make your understanding of the code you are working with better as well as ease testing.
|
||||
@@ -1,365 +0,0 @@
|
||||
---
|
||||
title: Introduction to Git workflows | GitLab
|
||||
tags:
|
||||
- IT/Development/Git
|
||||
- IT/Workflow
|
||||
- IT/Tools/Gitlab
|
||||
- IT/Tools/GitHub
|
||||
source: https://docs.gitlab.com/ee/topics/gitlab_flow.html
|
||||
---
|
||||
|
||||
With Git, you can use a variety of branching strategies and workflows. Having a structured workflow for collaboration in complex projects is crucial for several reasons:
|
||||
|
||||
- **Code organization**:
|
||||
Keep the codebase organized, prevent overlapping work, and ensure focused efforts towards a common goal.
|
||||
- **Version control**:
|
||||
Allow simultaneous work on different features without conflicts, maintaining code stability.
|
||||
- **Code quality**:
|
||||
A code review and approval process helps maintain high code quality and adherence to coding standards.
|
||||
- **Traceability and accountability**:
|
||||
Enable tracking of changes and their authors, simplifying issue identification and responsibility assignment.
|
||||
- **Easier onboarding**:
|
||||
Help new team members quickly grasp the development process, and start contributing effectively.
|
||||
- **Time and resource management**:
|
||||
Enable better planning, resource allocation, and meeting deadlines, ensuring an efficient development process.
|
||||
- **CI/CD**:
|
||||
Incorporate automated testing and deployment processes, streamlining the release cycle and delivering high-quality software consistently.
|
||||
|
||||
A structured workflow promotes organization, efficiency, and code quality, leading to a more successful and streamlined development process.
|
||||
|
||||
Because the default workflow is not specifically defined, many organizations end up with workflows that are too complicated, not clearly defined, or not integrated with their issue tracking systems.
|
||||
|
||||
Your organization can use GitLab with any workflow you choose.
|
||||
|
||||
## Workflow types[](#workflow-types "Permalink")
|
||||
|
||||
Here are some of the most common Git workflows.
|
||||
|
||||
### Centralized workflow[](#centralized-workflow "Permalink")
|
||||
|
||||
Best suited for small teams transitioning from a centralized version control system like SVN. All team members work on a single branch, usually `main`, and push their changes directly to the central repository.
|
||||
|
||||
### Feature branch workflow[](#feature-branch-workflow "Permalink")
|
||||
|
||||
Developers create separate branches for each feature or bugfix, keeping the ‘main’ branch stable. When a feature is complete, the developer submits a pull request or merge request to integrate the changes back into the `main` branch after a code review.
|
||||
|
||||
### Forking workflow[](#forking-workflow "Permalink")
|
||||
|
||||
Commonly used in open-source projects, this workflow allows external contributors to work without direct access to the main repository. Developers create a fork (a personal copy) of the main repository, make changes in their fork, and then submit a pull request or merge request to have their changes integrated into the main repository.
|
||||
|
||||
### Git flow workflow[](#git-flow-workflow "Permalink")
|
||||
|
||||
This workflow is best for projects with a structured release cycle. It introduces two long-lived branches: `main` for production-ready code and `develop` for integrating features. Additional branches like `feature`, `release`, and `hotfix` are used for specific purposes, ensuring a strict and organized development process.
|
||||
|
||||
### GitLab/GitHub flow[](#gitlabgithub-flow "Permalink")
|
||||
|
||||
A simplified workflow primarily used for web development and continuous deployment. It combines aspects of the Feature branch workflow and the Git flow workflow. Developers create feature branches from `main`, and after the changes are complete, they are merged back into the `main` branch, which is then immediately deployed.
|
||||
|
||||
Each of these Git workflows has its advantages and is suited to different project types and team structures. Below the most popular workflows are reviewed in more details.
|
||||
|
||||
## Git workflow[](#git-workflow "Permalink")
|
||||
|
||||
Most version control systems have only one step: committing from the working copy to a shared server.
|
||||
|
||||
When you convert to Git, you have to get used to the fact that it takes three steps to share a commit with colleagues.
|
||||
|
||||
In Git, you add files from the working copy to the staging area. After that, you commit them to your local repository. The third step is pushing to a shared remote repository.
|
||||
|
||||
Git workflow
|
||||
|
||||
git add
|
||||
|
||||
git commit
|
||||
|
||||
git push
|
||||
|
||||
Index
|
||||
|
||||
Working copy
|
||||
|
||||
Local repository
|
||||
|
||||
Remote repository
|
||||
|
||||
After getting used to these three steps, the next challenge is the branching model.
|
||||
|
||||
Because many organizations new to Git have no conventions for how to work with it, their repositories can quickly become messy. The biggest problem is that many long-running branches emerge that all contain part of the changes. People have a hard time figuring out which branch has the latest code, or which branch to deploy to production. Frequently, the reaction to this problem is to adopt a standardized pattern such as [Git flow](https://nvie.com/posts/a-successful-git-branching-model/) and [GitHub flow](https://scottchacon.com/2011/08/31/github-flow.html).
|
||||
|
||||
We think there is still room for improvement, and so we’ve proposed a set of practices called the GitLab Flow.
|
||||
|
||||
For a video introduction of this workflow in GitLab, see [GitLab Flow](https://youtu.be/InKNIvky2KE).
|
||||
|
||||
## Problems with the Git flow[](#problems-with-the-git-flow "Permalink")
|
||||
|
||||
Git flow was one of the first proposals to use Git branches, and it has received a lot of attention. It suggests a `main` branch and a separate `develop` branch, with supporting branches for features, releases, and hotfixes. The development happens on the `develop` branch, moves to a release branch, and is finally merged into the `main` branch.
|
||||
|
||||
Git flow is a well-defined standard, but its complexity introduces two problems. The first problem is that developers must use the `develop` branch and not `main`. `main` is reserved for code that is released to production. It is a convention to call your default branch `main` and to mostly branch from and merge to this. Because most tools automatically use the `main` branch as the default, it is annoying to have to switch to another branch.
|
||||
|
||||
The second problem of Git flow is the complexity introduced by the hotfix and release branches. These branches can be a good idea for some organizations but are overkill for the vast majority of them. Nowadays, most organizations practice continuous delivery, which means that your default branch can be deployed. Continuous delivery removes the need for hotfix and release branches, including all the ceremony they introduce. An example of this ceremony is the merging back of release branches. Though specialized tools do exist to solve this, they require documentation and add complexity. Frequently, developers make mistakes such as merging changes only into `main` and not into the `develop` branch. The reason for these errors is that Git flow is too complicated for most use cases. For example, many projects do releases but don’t need to do hotfixes.
|
||||
|
||||
[](https://docs.gitlab.com/ee/topics/img/gitlab_flow_gitdashflow.png)
|
||||
|
||||
## GitHub flow as a simpler alternative[](#github-flow-as-a-simpler-alternative "Permalink")
|
||||
|
||||
In reaction to Git flow, GitHub created a simpler alternative. [GitHub flow](https://docs.github.com/en/get-started/quickstart/github-flow) has only feature branches and a `main` branch:
|
||||
|
||||
Feature branches in GitHub Flow
|
||||
|
||||
add navigation
|
||||
|
||||
add feature
|
||||
|
||||
main branch
|
||||
|
||||
main branch
|
||||
|
||||
nav branch
|
||||
|
||||
main branch
|
||||
|
||||
feature-branch
|
||||
|
||||
main branch
|
||||
|
||||
This flow is clean and straightforward, and many organizations have adopted it with great success. Atlassian recommends [a similar strategy](https://www.atlassian.com/blog/git/simple-git-workflow-is-simple), although they rebase feature branches. Merging everything into the `main` branch and frequently deploying means you minimize the amount of unreleased code. This approach is in line with lean and continuous delivery best practices. However, this flow still leaves a lot of questions unanswered regarding deployments, environments, releases, and integrations with issues.
|
||||
|
||||
## Introduction to GitLab Flow[all tiers](https://about.gitlab.com/pricing/?glm_source=docs.gitlab.com&glm_content=badges-docs)[](#introduction-to-gitlab-flow "Permalink")
|
||||
|
||||
However, if you are looking for guidance on best practices, you can use the GitLab Flow. This workflow combines [feature-driven development](https://en.wikipedia.org/wiki/Feature-driven_development) and [feature branches](https://martinfowler.com/bliki/FeatureBranch.html) with issue tracking.
|
||||
|
||||
While this workflow used at GitLab, you can choose whichever workflow suits your organization best.
|
||||
|
||||
With GitLab flow, we offer additional guidance for these questions.
|
||||
|
||||
## Production branch with GitLab flow[](#production-branch-with-gitlab-flow "Permalink")
|
||||
|
||||
GitHub flow assumes you can deploy to production every time you merge a feature branch. While this is possible in some cases, such as SaaS applications, there are some cases where this is not possible, such as:
|
||||
|
||||
- You don’t control the timing of a release. For example, an iOS application that is released when it passes App Store validation.
|
||||
- You have deployment windows - for example, workdays from 10 AM to 4 PM when the operations team is at full capacity - but you also merge code at other times.
|
||||
|
||||
In these cases, you can create a production branch that reflects the deployed code. You can deploy a new version by merging `main` into the `production` branch. While not shown in the graph below, the work on the `main` branch works just like in GitHub flow: with feature branches being merged into `main`.
|
||||
|
||||
Production branch in GitLab Flow
|
||||
|
||||
deployment
|
||||
|
||||
development
|
||||
|
||||
main branch
|
||||
|
||||
main branch
|
||||
|
||||
main branch
|
||||
|
||||
production
|
||||
|
||||
production
|
||||
|
||||
main branch
|
||||
|
||||
main branch
|
||||
|
||||
If you need to know what code is in production, you can check out the production branch to see. The approximate time of deployment is visible as the merge commit in the version control system. This time is pretty accurate if you automatically deploy your production branch. If you need a more exact time, you can have your deployment script create a tag on each deployment. This flow prevents the overhead of releasing, tagging, and merging that happens with Git flow.
|
||||
|
||||
## Environment branches with GitLab flow[](#environment-branches-with-gitlab-flow "Permalink")
|
||||
|
||||
It might be a good idea to have an environment that is automatically updated to the `staging` branch. Only, in this case, the name of this environment might differ from the branch name. Suppose you have a staging environment, a pre-production environment, and a production environment:
|
||||
|
||||
Environment branches in GitLab Flow
|
||||
|
||||
deploy to
|
||||
pre-prod
|
||||
|
||||
deploy to
|
||||
pre-prod
|
||||
|
||||
production
|
||||
deployment
|
||||
|
||||
staging
|
||||
|
||||
staging
|
||||
|
||||
staging
|
||||
|
||||
staging
|
||||
|
||||
pre-prod
|
||||
|
||||
pre-prod
|
||||
|
||||
pre-prod
|
||||
|
||||
pre-prod
|
||||
|
||||
production
|
||||
|
||||
production
|
||||
|
||||
production
|
||||
|
||||
In this case, deploy the `staging` branch to your staging environment. To deploy to pre-production, create a merge request from the `staging` branch to the `pre-prod` branch. Go live by merging the `pre-prod` branch into the `production` branch. This workflow, where commits only flow downstream, ensures that everything is tested in all environments. If you need to cherry-pick a commit with a hotfix, it is common to develop it on a feature branch and merge it into `production` with a merge request. In this case, do not delete the feature branch yet. If `production` passes automatic testing, you then merge the feature branch into the other branches. If this is not possible because more manual testing is required, you can send merge requests from the feature branch to the downstream branches.
|
||||
|
||||
## Release branches with GitLab flow[](#release-branches-with-gitlab-flow "Permalink")
|
||||
|
||||
You should work with release branches only if you need to release software to the outside world. In this case, each branch contains a minor version, such as `2.3-stable` or `2.4-stable`:
|
||||
|
||||
cherry-pick
|
||||
|
||||
main
|
||||
|
||||
main
|
||||
|
||||
main
|
||||
|
||||
main
|
||||
|
||||
main
|
||||
|
||||
2.3-stable
|
||||
|
||||
2.3-stable
|
||||
|
||||
2.4-stable
|
||||
|
||||
Create stable branches using `main` as a starting point, and branch as late as possible. By doing this, you minimize the length of time during which you have to apply bug fixes to multiple branches. After announcing a release branch, only add serious bug fixes to the branch. If possible, first merge these bug fixes into `main`, and then cherry-pick them into the release branch. If you start by merging into the release branch, you might forget to cherry-pick them into `main`, and then you’d encounter the same bug in subsequent releases. Merging into `main` and then cherry-picking into release is called an “upstream first” policy, which is also practiced by [Google](https://www.chromium.org/chromium-os/chromiumos-design-docs/upstream-first/) and [Red Hat](https://www.redhat.com/en/blog/a-community-for-using-openstack-with-red-hat-rdo). Every time you include a bug fix in a release branch, increase the patch version (to comply with [Semantic Versioning](https://semver.org/)) by setting a new tag. Some projects also have a stable branch that points to the same commit as the latest released branch. In this flow, it is not common to have a production branch (or Git flow `main` branch).
|
||||
|
||||
## Merge/pull requests with GitLab flow[](#mergepull-requests-with-gitlab-flow "Permalink")
|
||||
|
||||
[](https://docs.gitlab.com/ee/topics/img/gitlab_flow_mr_inline_comments.png)
|
||||
|
||||
Merge or pull requests are created in a Git management application. They ask an assigned person to merge two branches. Tools such as GitHub and Bitbucket choose the name “pull request”, because the first manual action is to pull the feature branch. Tools such as GitLab and others choose the name “merge request”, because the final action is to merge the feature branch. This article refers to them as merge requests.
|
||||
|
||||
If you work on a feature branch for more than a few hours, share the intermediate result with the rest of your team. To do this, create a merge request without assigning it to anyone. Instead, mention people in the description or a comment, for example, “/cc [@mark](https://gitlab.com/mark) [@susan](https://gitlab.com/susan).” This indicates that the merge request is not ready to be merged yet, but feedback is welcome. Your team members can comment on the merge request in general or on specific lines with line comments. The merge request serves as a code review tool, and no separate code review tools should be needed. If the review reveals shortcomings, anyone can commit and push a fix. Usually, the person to do this is the creator of the merge request. The diff in the merge request automatically updates when new commits are pushed to the branch.
|
||||
|
||||
When you are ready for your feature branch to be merged, assign the merge request to the person who knows most about the codebase you are changing. Also, mention any other people from whom you would like feedback. After the assigned person feels comfortable with the result, they can merge the branch. If the assigned person does not feel comfortable, they can request more changes or close the merge request without merging.
|
||||
|
||||
In GitLab, it is common to protect the long-lived branches, such as the `main` branch, so [most developers can’t modify them](https://docs.gitlab.com/ee/user/permissions.html). So, if you want to merge into a protected branch, assign your merge request to someone with the Maintainer role.
|
||||
|
||||
After you merge a feature branch, you should remove it from the source control software. In GitLab, you can do this when merging. Removing finished branches ensures that the list of branches shows only work in progress. It also ensures that if someone reopens the issue, they can use the same branch name without causing problems.
|
||||
|
||||
[](https://docs.gitlab.com/ee/topics/img/gitlab_flow_remove_checkbox.png)
|
||||
|
||||
## Issue tracking with GitLab flow[](#issue-tracking-with-gitlab-flow "Permalink")
|
||||
|
||||
GitLab flow is a way to make the relation between the code and the issue tracker more transparent.
|
||||
|
||||
Any significant change to the code should start with an issue that describes the goal. Having a reason for every code change helps to inform the rest of the team and to keep the scope of a feature branch small. In GitLab, each change to the codebase starts with an issue in the issue tracking system. If there is no issue yet, create the issue if the change requires more than an hour’s work. In many organizations, raising an issue is part of the development process because they are used in sprint planning. The issue title should describe the desired state of the system. For example, the issue title `As an administrator, I want to remove users without receiving an error` is better than “Administrators can’t remove users.”
|
||||
|
||||
When you are ready to code, create a branch for the issue from the `main` branch. This branch is the place for any work related to this change.
|
||||
|
||||
When you are done or want to discuss the code, open a merge request. A merge request is an online place to discuss the change and review the code.
|
||||
|
||||
If you open the merge request but do not assign it to anyone, it is a [draft merge request](https://docs.gitlab.com/ee/user/project/merge_requests/drafts.html). Drafts are used to discuss the proposed implementation but are not ready for inclusion in the `main` branch yet. Start the title of the merge request with `[Draft]`, `Draft:` or `(Draft)` to prevent it from being merged before it’s ready.
|
||||
|
||||
When you think the code is ready, assign the merge request to a reviewer. The reviewer can merge the changes when they think the code is ready for inclusion in the `main` branch. When they press the merge button, GitLab merges the code and creates a merge commit that makes this event visible later on. Merge requests always create a merge commit, even when the branch could be merged without one. This merge strategy is called “no fast-forward” in Git. After the merge, delete the feature branch, because it is no longer needed. In GitLab, this deletion is an option when merging.
|
||||
|
||||
Suppose that a branch is merged but a problem occurs and the issue is reopened. In this case, it is no problem to reuse the same branch name, because the first branch was deleted when it was merged. At any time, there is at most one branch for every issue. It is possible that one feature branch solves more than one issue.
|
||||
|
||||
## Linking and closing issues from merge requests[](#linking-and-closing-issues-from-merge-requests "Permalink")
|
||||
|
||||
Link to issues by mentioning them in commit messages or the description of a merge request, for example, “Fixes #16” or “Duck typing is preferred. See #12.” GitLab then creates links to the mentioned issues and creates comments in the issues linking back to the merge request.
|
||||
|
||||
To automatically close linked issues, mention them with the words “fixes” or “closes,” for example, “fixes #14” or “closes #67.” GitLab closes these issues when the code is merged into the default branch.
|
||||
|
||||
If you have an issue that spans across multiple repositories, create an issue for each repository and link all issues to a parent issue.
|
||||
|
||||
## Squashing commits with rebase[](#squashing-commits-with-rebase "Permalink")
|
||||
|
||||
With Git, you can use an interactive rebase (`rebase -i`) to squash multiple commits into one or reorder them. This feature helps you replace a couple of small commits with a single commit, or if you want to make the order more logical:
|
||||
|
||||
```
|
||||
pick c6ee4d3 add a new file to the repo
|
||||
pick c3c130b change readme
|
||||
|
||||
# Rebase 168afa0..c3c130b onto 168afa0
|
||||
#
|
||||
# Commands:
|
||||
# p, pick = use commit
|
||||
# r, reword = use commit, but edit the commit message
|
||||
# e, edit = use commit, but stop for amending
|
||||
# s, squash = use commit, but meld into previous commit
|
||||
# f, fixup = like "squash", but discard this commit's log message
|
||||
# x, exec = run command (the rest of the line) using shell
|
||||
#
|
||||
# These lines can be re-ordered; they are executed from top to bottom.
|
||||
#
|
||||
# If you remove a line here THAT COMMIT WILL BE LOST.
|
||||
#
|
||||
# However, if you remove everything, the rebase will be aborted.
|
||||
#
|
||||
# Note that empty commits are commented out
|
||||
~
|
||||
~
|
||||
~
|
||||
"~/demo/gitlab-ce/.git/rebase-merge/git-rebase-todo" 20L, 673C
|
||||
```
|
||||
|
||||
However, you should avoid rebasing commits you have pushed to a remote server if you have other active contributors in the same branch. Because rebasing creates new commits for all your changes, it can cause confusion because the same change would have multiple identifiers. It would cause merge errors for anyone working on the same branch because their history would not match with yours. It can be really troublesome for the author or other contributors. Also, if someone has already reviewed your code, rebasing makes it hard to tell what changed after the last review.
|
||||
|
||||
You should never rebase commits authored by other people unless you’ve agreed otherwise. Not only does this rewrite history, but it also loses authorship information. Rebasing prevents the other authors from being attributed and sharing part of the [`git blame`](https://git-scm.com/docs/git-blame).
|
||||
|
||||
If a merge involves many commits, it may seem more difficult to undo. You might consider solving this by squashing all the changes into one commit just before merging by using the GitLab [Squash-and-Merge](https://docs.gitlab.com/ee/user/project/merge_requests/squash_and_merge.html) feature. Fortunately, you can undo a merge with all its commits. The way to do this is by reverting the merge commit. Preserving this ability to revert a merge is a good reason to always use the “no fast-forward” (`--no-ff`) strategy when you merge manually.
|
||||
|
||||
## Reducing merge commits in feature branches[](#reducing-merge-commits-in-feature-branches "Permalink")
|
||||
|
||||
Having lots of merge commits can make your repository history messy. Therefore, you should try to avoid merge commits in feature branches. Often, people avoid merge commits by just using rebase to reorder their commits after the commits on the `main` branch. Using rebase prevents a merge commit when merging `main` into your feature branch, and it creates a neat linear history. However, as discussed in [the section about rebasing](#squashing-commits-with-rebase), you should avoid rebasing commits in a feature branch that you’re sharing with others.
|
||||
|
||||
Rebasing could create more work, as every time you rebase, you may need to resolve the same conflicts. Sometimes you can reuse recorded resolutions (`rerere`), but merging is better, because you only have to resolve conflicts once. Atlassian has [a more thorough explanation of the tradeoffs between merging and rebasing](https://www.atlassian.com/blog/git/git-team-workflows-merge-or-rebase) on their blog.
|
||||
|
||||
A good way to prevent creating many merge commits is to not frequently merge `main` into the feature branch. Three reasons to merge in `main`:
|
||||
|
||||
1. Utilizing new code.
|
||||
2. Resolving merge conflicts.
|
||||
3. Updating long-running branches.
|
||||
|
||||
If you need to use some code that was introduced in `main` after you created the feature branch, you can often solve this by just cherry-picking a commit.
|
||||
|
||||
If your feature branch has a merge conflict, creating a merge commit is a standard way of solving this.
|
||||
|
||||
The last reason for creating merge commits is to keep long-running feature branches up-to-date with the latest state of the project. The solution here is to keep your feature branches short-lived. Most feature branches should take less than one day of work. If your feature branches often take more than a day of work, try to split your features into smaller units of work.
|
||||
|
||||
If you need to keep a feature branch open for more than a day, there are a few strategies to keep it up-to-date. One option is to use continuous integration (CI) to merge in `main` at the start of the day. Another option is to only merge in from well-defined points in time, for example, a tagged release. You could also use [feature toggles](https://martinfowler.com/bliki/FeatureToggle.html) to hide incomplete features so you can still merge back into `main` every day.
|
||||
|
||||
In conclusion, you should try to prevent merge commits, but not eliminate them. Your codebase should be clean, but your history should represent what actually happened. Developing software happens in small, messy steps, and it is OK to have your history reflect this. You can use tools to view the network graphs of commits and understand the messy history that created your code. If you rebase code, the history is incorrect, and there is no way for tools to remedy this because they can’t deal with changing commit identifiers.
|
||||
|
||||
## Commit often and push frequently[](#commit-often-and-push-frequently "Permalink")
|
||||
|
||||
Another way to make your development work easier is to commit often. Every time you have a working set of tests and code, you should make a commit. Splitting up work into individual commits provides context for developers looking at your code later. Smaller commits make it clear how a feature was developed. They help you roll back to a specific good point in time, or to revert one code change without reverting several unrelated changes.
|
||||
|
||||
Committing often also helps you share your work, which is important so that everyone is aware of what you are working on. You should push your feature branch frequently, even when it is not yet ready for review. By sharing your work in a feature branch or [a merge request](#mergepull-requests-with-gitlab-flow), you prevent your team members from duplicating work. Sharing your work before it’s complete also allows for discussion and feedback about the changes. This feedback can help improve the code before it gets to review.
|
||||
|
||||
## How to write a good commit message[](#how-to-write-a-good-commit-message "Permalink")
|
||||
|
||||
A commit message should reflect your intention, not just the contents of the commit. You can see the changes in a commit, so the commit message should explain why you made those changes:
|
||||
|
||||
```
|
||||
# This commit message doesn't give enough information
|
||||
git commit -m 'Improve XML generation'
|
||||
|
||||
# These commit messages clearly state the intent of the commit
|
||||
git commit -m 'Properly escape special characters in XML generation'
|
||||
```
|
||||
|
||||
An example of a good commit message is: “Combine templates to reduce duplicate code in the user views.” The words “change,” “improve,” “fix,” and “refactor” don’t add much information to a commit message. For more information, see Tim Pope’s excellent [note about formatting commit messages](https://tbaggery.com/2008/04/19/a-note-about-git-commit-messages.html).
|
||||
|
||||
To add more context to a commit message, consider adding information regarding the origin of the change. For example, the URL of a GitLab issue, or a Jira issue number, containing more information for users who need in-depth context about the change.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
Properly escape special characters in XML generation.
|
||||
|
||||
Issue: gitlab.com/gitlab-org/gitlab/-/issues/1
|
||||
```
|
||||
|
||||
## Testing before merging[](#testing-before-merging "Permalink")
|
||||
|
||||
In old workflows, the continuous integration (CI) server commonly ran tests on the `main` branch only. Developers had to ensure their code did not break the `main` branch. When using GitLab flow, developers create their branches from this `main` branch, so it is essential that it never breaks. Therefore, each merge request must be tested before it is accepted. CI software like Travis CI and GitLab CI/CD show the build results right in the merge request itself to simplify the process.
|
||||
|
||||
There is one drawback to testing merge requests: the CI server only tests the feature branch itself, not the merged result. Ideally, the server could also test the `main` branch after each change. However, retesting on every commit to `main` is computationally expensive and means you are more frequently waiting for test results. Because feature branches should be short-lived, testing just the branch is an acceptable risk. If new commits in `main` cause merge conflicts with the feature branch, merge `main` back into the branch to make the CI server re-run the tests. As said before, if you often have feature branches that last for more than a few days, you should make your issues smaller.
|
||||
|
||||
## Working with feature branches[](#working-with-feature-branches "Permalink")
|
||||
|
||||
When creating a feature branch, always branch from an up-to-date `main`. If you know before you start that your work depends on another branch, you can also branch from there. If you need to merge in another branch after starting, explain the reason in the merge commit. If you have not pushed your commits to a shared location yet, you can also incorporate changes by rebasing on `main` or another feature branch. Do not merge from upstream again if your code can work and merge cleanly without doing so. Merging only when needed prevents creating merge commits in your feature branch that later end up littering the `main` history.
|
||||
@@ -1,20 +0,0 @@
|
||||
---
|
||||
tags:
|
||||
- IT/Format/VOB
|
||||
- IT/Format/VRO
|
||||
- IT/Format/MP4
|
||||
---
|
||||
|
||||
## Dateiformat VRO
|
||||
|
||||
Verwendet von dem inzwischen entsorgten DVD-Rekorder.
|
||||
|
||||
## Konvertierung
|
||||
|
||||
```shell
|
||||
ffmpeg -i /path/to/VR_MOVIE.VRO -vcodec libx264 Video.mp4
|
||||
```
|
||||
|
||||
```shell
|
||||
ffmpeg -i "concat:VTS_01_1.VOB|VTS_02_1.VOB|VTS_03_1.VOB" -vcodec libx264 Video.mp4
|
||||
```
|
||||
@@ -1,15 +0,0 @@
|
||||
---
|
||||
tags:
|
||||
- IT/Format/WMA
|
||||
- IT/Format/MP3
|
||||
---
|
||||
|
||||
## Dateiformat WMA
|
||||
|
||||
*W*indows *M*edia *A*udio
|
||||
|
||||
## Konvertierung
|
||||
|
||||
```shell
|
||||
ffmpeg -i Song.wma -acodec mibmp3lame -ab 192k Song.mp3
|
||||
```
|
||||
@@ -1,362 +0,0 @@
|
||||
---
|
||||
title: Laying out roles, inventories and playbooks – Random stuff
|
||||
source: https://leucos.github.io/ansible-files-layout
|
||||
tags:
|
||||
- IT/Development/Ansible
|
||||
---
|
||||
_(revised 20181110 per @theenglishway suggestions)_
|
||||
|
||||
I have been writing playbooks for quite a while now. Along the way, I went through various stages, and used different ways to layout Ansible files. I guess that after going down this trial and error path, I finally came up with something I will stick to.
|
||||
|
||||
I am not saying that this is the be-all and end-all of Ansible files layout but may be it will fast forward you to a saner file layout, and you’ll be able to move on from there. This post will probably help you if you are new to Ansible, trying to figure out what to put and where. I hope it will prove usefull if you have some Ansible experience too.
|
||||
|
||||
## Some terminology
|
||||
|
||||
In this post, I will mostly talk about 3 things: roles, inventories and playbooks. Other items do exist (plays, tasks, …) but those 3 elements shape the big picture of the layout.
|
||||
|
||||
### Roles
|
||||
|
||||
A role is a collection of tasks and templates (among other things, but those are the most common) focused on one very specific goal. For instance, you can have a role that installs nginx, another that deploys ssh keys for admins, etc…
|
||||
|
||||
Nginx role will install and configure nginx. Nothing else. It won’t create DNS entries, trim logs, add a ftp server or anything. It just installs nginx. Period.
|
||||
|
||||
### Inventories
|
||||
|
||||
An inventory is a list of hosts, eventually assembled into groups, on which you will run ansible playbooks. Ansible automatically puts all defined hosts in the aptly named group `all`.
|
||||
|
||||
For instance, you could have hosts `www1` and `www2`, assembled in group `webservers`, and later reference the group or individual hosts, depending on your needs.
|
||||
|
||||
Inventories can also come with variables applied to hosts or groups (including `all`).
|
||||
|
||||
Inventories can be dynamic. If the inventory file is executable, Ansible will run it and use its output as the inventory (note that, in this case, the format is not the same as static inventory).
|
||||
|
||||
You can of course have multiple inventories, segregated from each other. We will take advantage from this later on.
|
||||
|
||||
### Playbooks
|
||||
|
||||
The last piece of the puzzle is the playbook. The playbook is the pivot between and inventory and roles. This is where you basically tell Ansible: _please install roles foo, bar and baz on machines alice, bob and charlie_.
|
||||
|
||||
## Role layout
|
||||
|
||||
Role layout is pretty well documented at Ansible website. A role contains several directories. All directories are optional besides `tasks`. For each directory, the entry point is `main.yml`. Thus, the only compulsory file in a role is `tasks/main.yml`.
|
||||
|
||||
ansible-foobar/
|
||||
├── defaults
|
||||
│ └── main.yml
|
||||
├── files
|
||||
├── handlers
|
||||
│ └── main.yml
|
||||
├── meta
|
||||
│ └── main.yml
|
||||
├── tasks
|
||||
│ ├── check_vars.yml
|
||||
│ ├── foobar.yml
|
||||
│ └── main.yml
|
||||
└── templates
|
||||
└── foobar.conf.j2
|
||||
|
||||
|
||||
Let’s cover briefly the layout an see the function of each file and directory.
|
||||
|
||||
### `defaults/main.yml`
|
||||
|
||||
This directory contains defaults for variables used in roles. I encourage you to define every variable used in your role, for several reasons:
|
||||
|
||||
* this file will be a nice and always up to date reference list of settings configuration in your roles
|
||||
* having configured variables will prevent your role failing in an uncontrolled way (more on this later).
|
||||
|
||||
If some of these variables are used in templates to generate config files, I highly encourage you to use your target OS defaults. The principle of least surprise should apply here.
|
||||
|
||||
Best practices assumes that you are using _pseudo-namespacing_ for your role’s variables (e.g. for role `foobar`, all variables should begin with `foobar_`) to avoid collisions with other roles.
|
||||
|
||||
### `files/`
|
||||
|
||||
This directory holds files that do not require Jinja interpolation, and can be copied as-is on the remote nodes.
|
||||
|
||||
### `handlers/main.yml`
|
||||
|
||||
This is where you define handlers that get notified by tasks. Handlers are just standard tasks. You can use `include` in this file if you want to separate handlers (for different OSes versions for instances), but try to keep the file number as low as possible so you don’t end up hunting down stuff everywhere.
|
||||
|
||||
If your handler restarts any service, you have to make sure that the service config file is valid before attempting to restart it. Some daemons allow this (e.g. nginx, haproxy, apache). If your service does not, provide some fallback mechanism. You don’t want your playbook to screw up your running system because you typoed a configuration variable. See the `validate` option in the [template module](http://docs.ansible.com/template_module.html).
|
||||
|
||||
Note that handlers are just standard tasks.
|
||||
|
||||
### `meta/main.yml`
|
||||
|
||||
This metadata has (AFAIK) only two variables:
|
||||
|
||||
* `galaxy_info`: meta information for galaxy about your role. You just don’t need this if you don intend to push your role to Galaxy. For details on the format, see TODO: find ref
|
||||
* `dependencies`: what roles this role depends on.
|
||||
|
||||
The latter is of utmost importance, and setting it right deserves a blog post on it’s own. Until then, the rule of thumb to remember is to **only include compulsory role dependencies for the target host**.
|
||||
|
||||
This means that adding `nginx` dependency in a `php-fpm` role sounds perfectly reasonable[1](#fn:1). However, adding a `mysql` dependency to your web application role is not, because `mysql` can be deployed on another server.
|
||||
|
||||
**A note 3 years later**: I do not use dependencies anymore. I had issues regarding role’s defaults variables behavior. Also, the playbook is the main focus area when building infrastructure code. Having explicit dependencies in the playbook is the way to go. No weird or hard to track magic.
|
||||
|
||||
### `tasks/main.yml`
|
||||
|
||||
This file is the tasks entry point. However, it should be mostly empty. Why ? Because you want to use Ansible tags. Tags are a great way to limit task execution for an Ansible run, where only tagged tasks are run.
|
||||
|
||||
For instance, in a playbook that deploys your application, you could choose to run only tasks regarding nginx.
|
||||
|
||||
The problem is that tagging every task in `main.yml` would be cumbersome, error prone, and clutter the code unnecessarily.
|
||||
|
||||
The best way to tag all your tasks is to include your real task file from `tasks/main.yml` and tag the whole file:
|
||||
|
||||
- import_tasks: foobar.yml
|
||||
tags:
|
||||
- foobar
|
||||
|
||||
Here, I name the real task file `foobar.yml` with the same name as the role (quite handy with `find` or `locate`; no need to guess which `main.yml` you are looking for) and apply the tag `foobar` to all tasks in the role.
|
||||
|
||||
You can repeat this if you have a big list of tasks and want to split them in several files. You could, for instance, separate configuration and installation matters, and add another specific tag for each of them:
|
||||
|
||||
- import_tasks: foobar-install.yml
|
||||
tags:
|
||||
- foobar
|
||||
- foobar:install
|
||||
|
||||
- import_tasks: foobar-config.yml
|
||||
tags:
|
||||
- foobar
|
||||
- foobar:config
|
||||
|
||||
Here I added two tags to the installation part (`foobar` and `foobar:install`), and two for the configuration part (`foobar` and `foobar:config`).
|
||||
|
||||
Note that the `:` between, for instance, `foobar` and `config` has no meaning. Ansible treats tags as dumb strings. It is just a personnal convention (Redis like) for refining tags.
|
||||
|
||||
With this setup, you could run only the configuration part of your role by issuing:
|
||||
|
||||
`ansible-playbook playbook.yml -t foobar:config`
|
||||
|
||||
The `-t` and `-l` combination is a very powerful weapon to target a specific host with a precise change (think of this as pointing to a matrix cell targetting host (i.e. row) and tag (i.e. column)).
|
||||
|
||||
#### A word of caution
|
||||
|
||||
Do not overdo tags: most of the time, this is YAGNI (You Ain’t Gonna Need It). Create a tag if you’re gonna need it. It can be hard to mentally predict what will happen if you do too much. Beware of the `never` tag, that will skip tasks **unless** you explicitely use another tag.
|
||||
|
||||
For instance:
|
||||
|
||||
- import_tasks: foobar-uninstall.yml
|
||||
tags
|
||||
- never
|
||||
- foobar
|
||||
|
||||
will execute tasks in `foobar-uninstall.yml` if tag `foobar` is specified at the command line.
|
||||
|
||||
### `tasks/check_vars.yml`
|
||||
|
||||
I use this file to ensure that required variables are defined.
|
||||
|
||||
#
|
||||
# Checking that required variables are set
|
||||
#
|
||||
- name: Checking that required variables are set
|
||||
fail: msg="{{ item }} is not defined"
|
||||
when: item not in vars
|
||||
loop:
|
||||
- foobar_database
|
||||
- foobar_deploy_user
|
||||
|
||||
Then, include this file in `tasks/main.yml`:
|
||||
|
||||
- import_tasks: check_vars.yml
|
||||
tags:
|
||||
- foobar
|
||||
- foobar:check
|
||||
- check
|
||||
|
||||
- import_tasks: foobar.yml
|
||||
tags:
|
||||
- foobar
|
||||
|
||||
### `templates/*`
|
||||
|
||||
This is the place where templates (i.e. files with interpolated variables goes). While this is not necessary, I often reference them using a relative path like so:
|
||||
|
||||
- name: Template foo
|
||||
template:
|
||||
src: ../templates/foo.conf.j2
|
||||
dest: /some/place/in/the/node/filesystem/foo.conf
|
||||
|
||||
The goal of using relative path is to be able to hit `gf` in Vim and open the file directly. You can get rid of that and just use `src: foo.conf.j2`. It is just a readability/convenience tradeoff.
|
||||
|
||||
The file name I use is the **intended filename at the destination**, appended with `.j2` so it is clear that it is a Jinja2 template, and easier to search (`find` or `locate`).
|
||||
|
||||
Some folks like to replicate the destination hierarchy (e.g. `src: etc/sysconfig /network-scripts/ifcfg-ethx.cfg.j2`). This is a matter of taste, but personaly I don’t see the point of having those deep hierarchies in the role if the naming is correct.
|
||||
|
||||
### `vars/main.yml`
|
||||
|
||||
It is sometimes difficult to grok the difference between `vars/main.yml` and `defaults/main.yml`. After all, they both contain variable assignements.
|
||||
|
||||
I do not always use a `vars/main.yml`, but when I do, I put “constants like” variables in it. These are variables that are not intended to be overriden.
|
||||
|
||||
For instance the github repository for a particular piece of code (e.g. your web application) will certainly go there. However, the version you want to deploy won’t.
|
||||
|
||||
All in all, it is just a mechanism to take those values out of tasks files readability and role life cycle.
|
||||
|
||||
## Inventories and playbook layout
|
||||
|
||||
A playbook glues together roles and inventories. Thus playbooks depend on roles and inventories. But while you have mechanisms to list roles requirements in a playbook, you don’t have any for inventories.
|
||||
|
||||
Since the playbook can not live without the targeted inventories I include my inventories in my playbooks.
|
||||
|
||||
playbook-foobar/
|
||||
├── ansible.cfg
|
||||
├── requirements.txt
|
||||
├── roles/
|
||||
│ └── requirements.yml
|
||||
├── inventories
|
||||
│ ├── development
|
||||
│ | ├── group_vars
|
||||
│ | │ └── all
|
||||
│ | └── hosts
|
||||
│ ├── integration
|
||||
│ | ├── group_vars
|
||||
│ | │ └── all
|
||||
│ | └── hosts
|
||||
│ └── production
|
||||
│ ├── group_vars
|
||||
│ │ └── all
|
||||
│ └── hosts
|
||||
├── site.yml
|
||||
└── playbooks
|
||||
├── 10_database.yml
|
||||
└── 20_stuff.yml
|
||||
|
||||
|
||||
### `ansible.cfg`, `roles/` and `roles/requirements.yml`
|
||||
|
||||
This file controles ansible behaviour. You can have one in `/etc/ansible` or as a personal dotfile (`~/.ansible.cfg`). Adding an `ansible.cfg` file in the playbook root will ensure that the required settings for the playbook to run are really there. The precedence order for Ansible config files is[2](#fn:2):
|
||||
|
||||
1. `ANSIBLE_CONFIG` (an environment variable pointing to a file)
|
||||
2. `ansible.cfg` (in the current directory)
|
||||
3. `.ansible.cfg` (in the home directory)
|
||||
4. `/etc/ansible/ansible.cfg`
|
||||
|
||||
Ansible will use the first config file found.
|
||||
|
||||
In this config file, I always set at least two options:
|
||||
|
||||
hostfile = ./inventories/dev
|
||||
roles_path = ./roles:/some/path/to/roles/repos
|
||||
|
||||
The first one (`hostfile`) sets which inventory Ansible will use. More explanations will come below.
|
||||
|
||||
The second one set the path where Ansible will look for roles. I typically set two directories here (separated by `:`, like shell’s `PATH`):
|
||||
|
||||
* the first directory will be used by ansible galaxy to install imported roles. I set it to `./roles` but the name doesn’t matter. Don’t forget to add the directory content (except `requirements.yml`) in your playbook’s `.gitignore` like so:
|
||||
|
||||
!/roles
|
||||
/roles/*
|
||||
!/roles/requirements.yml
|
||||
|
||||
|
||||
* sometimes I add a second directory that points to my roles developmenent directory path
|
||||
|
||||
The advantages for this setup are two fold: first, you have a dedicated path, ignored by your SCM, where you will download roles. The roles will be searched there first. Secondly, if a role is not found, it will be searched in your role development directory. This let you hack on your roles while writing a playbook. You don’t need to go through a _commit/push/install_ cycle when you are coding your roles for this playbook.
|
||||
|
||||
Roles dependencies for your playbook are listed in `requirements.yml` and can be installed with `ansible-galaxy install -r requirements.yml`:
|
||||
|
||||
# Role on galaxy
|
||||
- you.rolename
|
||||
# Public role on github
|
||||
- name: role-public
|
||||
src: https://github.com/erasme/role-public.git
|
||||
# Private role on github
|
||||
- name: role-private
|
||||
src: git+ssh://git@github.com/you/role-private.git
|
||||
|
||||
### `inventories/`
|
||||
|
||||
This directory holds all inventories you want to apply your playbook too. The most common pattern is to use per-environment inventories: one for `development`, one for `integration`, another for `production`, etc…
|
||||
|
||||
Of course, the `hostfile` variable in `ansible.cfg` should point to `development` to avoid accidentaly messing with production. Executing the playbook on non-development inventories will force you tu use the `-i`, which is a good safety measure.
|
||||
|
||||
While you can define variables in groups (in `group_vars`) and hosts (`host_vars`), you should stuff as much variables as possible in `group_vars/all`. The rationale is that it is much easier to find a variable when a single file is involved. Variables scattered in a dozen of files are _not_ manageable.
|
||||
|
||||
And when you’ll want to create an additional inventory (e.g. create `production` from `development`), it will be much easier to change a single file and set the variables to proper values than to do the same in several files.
|
||||
|
||||
Note that `group_vars/all` can be a directory containing several files. I usually split variables in a clear text file (`group_vars/all/all`) and a ciphered one (`group_vars/all_secret`) using the transparent vaulting techniques described in [this post](https://leucos.github.io/articles/transparent-vault-revisited/).
|
||||
|
||||
**Note 3 years later**: now ansible allow you to vault a single variable in an inventory. Use it !
|
||||
|
||||
Here is a handy bash alias that crypts text selected with a mouse:
|
||||
|
||||
`alias vault_clip_crypt='echo Passing $(xclip -rmlastnl -o) to ansible-vault && echo -n "$(xclip -rmlastnl -o)" | ansible-vault encrypt_string'`
|
||||
|
||||
### `site.yml` and `playbooks/`
|
||||
|
||||
This directory contains the playbooks themselves. I always create a “master” playbook called `site.yml` in the playbook root directory, which includes all other playbooks located in `playbooks/`.
|
||||
|
||||
I prefix playbooks with a number (Basic style) so I get a sense of the order playbook will be executed just by looking at `playbooks/` content.
|
||||
|
||||
For instance:
|
||||
|
||||
#!/usr/bin/env ansible-playbook
|
||||
|
||||
- import_playbook: playbooks/10_database.yml
|
||||
- import_playbook: playbooks/20_stuff.yml
|
||||
|
||||
The rationale is to be able to use `ansible-pull` easily if needed (`ansible- pull`, by default, tries to execute a playbook called`site.yml`). The other point is to split playbook in related parts.
|
||||
|
||||
For instance, you could have a playbook the takes care of setting up the database, another that will set the OS level stuff (e.g. ssh keys, firewalling, …), another one that takes care of deploying your web application, etc… When needed, You can use all the playbooks at once with `site.yml`, or just focus on a specific problem running the appropriate playbook (no need to run the ssh-key setup if you’re just deploying the latest version of your web application).
|
||||
|
||||
The shebang line at the top of the file (`#!/usr/bin/env ansible-playbook`) will make the playbook directly executable (adjust `ansible-playbook` path and `chmod +x` the playbook file). You can still pass additional `ansible-playbook` parameters if required.
|
||||
|
||||
### `requirements.txt`
|
||||
|
||||
This file contains the result of a `pip freeze`. I now only use `pip` under `virtualenv` to install ansible and required modules. It makes it really easy to switch ansible (and even python) version between projects.
|
||||
|
||||
So when someone needs to work on this project, the workflow is simple:
|
||||
|
||||
git clone http://github.com/some/playbook-repos
|
||||
cd playbook-repos
|
||||
mkvirtualenv playbook-repos --no-site-packages
|
||||
pip install -r requirements.txt
|
||||
ansible-galaxy install -r roles/requirements.yml
|
||||
|
||||
|
||||
and you’re good to go.
|
||||
|
||||
## Layout Antipatterns
|
||||
|
||||
When I started using Ansible, I cumulated several antipatterns at the same time: trying to emcompass all my infrastructure in a single inventory containing per-host fine grained variables, used in a single playbook, without using any role.
|
||||
|
||||
While this sounds feasible, it is doomed to failure unless you manage a very small infrastructure. Let’s zoom in briefly on each mistake.
|
||||
|
||||
### Trying to encompass all your infrastructure in one playbook
|
||||
|
||||
Is is tempting to aim for a one-liner that will magically deploy all your infrastructure in one shot. This gives you some bragging rights at your next meetup, and feels like the ultimate sysadmin masterpiece.
|
||||
|
||||
However, it has many drawbacks:
|
||||
|
||||
* it will be slow: do you really want to run a playbook over dozens of more tasks or roles, just to change an entry in `/etc/hosts` ? Yes, there are workaround for this, but it will require some command line magic, a lot of thinking.
|
||||
|
||||
* it mixes bananas and apples: you should strive for separation of concerns in your playbooks if you want be able to read them (and, as a consequence, maintain them).
|
||||
|
||||
|
||||
As a consequence, your infrastructure code will be unnecessary hard to test and maintain.
|
||||
|
||||
### Per-host fine grained variables
|
||||
|
||||
This is a corolary of the previous antipattern: when you try to encompass your whole infrastructure, you start to think, inheritance, variables overriding and refining.
|
||||
|
||||
And while doing this, you add considerable complexity to your inventories. It is very hard to track down variables definitions when you overrides them in `group_vars/some_group`, `group_vars/all`, `hosts_vars/machine`, role defaults, …
|
||||
|
||||
Now this can get even worse when you use the `hash_behavior: merge` Ansible configuration setting: it introduces more confusion, and makes your Ansible work potentially unshareable with people using `hash_behaviour: replace`. Since I am [guilty](https://github.com/ansible/ansible/commit/e28e538c6ed7520ecef305c776eb6036aff42d06) on this one, it is time to make some apologies. Sorry folks. Michael DeHaan did not like it, and he was right.
|
||||
|
||||
### Single playbook
|
||||
|
||||
A single playbook relates to the first Sin again, but also applies to more focused playbooks where you only deploy one thing. Splitting your playbooks between various logically related roles will fasten your deployments. Again, why running ssh key distribution, storage cluster deployment, web stack, middlewares and application when you just change the color of a button in your web app ?
|
||||
|
||||
Split your playbook in related parts that reflects your stack architecture. They will be faster and easier to use.
|
||||
|
||||
### No roles (tasks only)
|
||||
|
||||
Well, this is obvious. Even if you don’t want to share, make roles and strive for code reuse. Reused code will save you time of course, but it is also battle tested since it is used more frequently.
|
||||
|
||||
Tasks-only playbook can be used for a quick hit and run, solving a transient problem that doesn’t offer any code reuse opportunities.
|
||||
|
||||
I also try to avoid tasks along roles in playbooks: this hurts the abstraction level you manage to build using roles. When thinking in terms of roles, you don’t need to think about the nitty gritty details of the roles when reading your playbooks. If your roles are thouroughly tested, you can read your infrastructure in seconds. Add tasks to the mix, and you loose this superpower.
|
||||
@@ -1,129 +0,0 @@
|
||||
---
|
||||
title: Linux on Windows
|
||||
source: https://dev.to/darksmile92/linux-on-windows-wsl-with-desktop-environment-via-rdp-522g
|
||||
tags:
|
||||
- IT/OS/Linux
|
||||
- IT/OS/Windows
|
||||
---
|
||||
|
||||
## [Linux on Windows: WSL with Desktop Environment via RDP](https://dev.to/darksmile92/linux-on-windows-wsl-with-desktop-environment-via-rdp-522g)
|
||||
|
||||

|
||||
|
||||
WSL (Windows Subsystem for Linux) is very common these days especially with the new that Windows will ship a [Linux kernel](https://github.com/microsoft/WSL2-Linux-Kernel) with [WSL 2.0](https://docs.microsoft.com/de-de/windows/wsl/wsl2-about)!
|
||||
|
||||
Installing a Linux distro as WSL is easy via the Microsoft App Store and there are plenty of tutorials out there for it.
|
||||
|
||||
Most of the resources cover the access via Shell, Terminal, Hyperterminal or other console based tools to the WSL.
|
||||
Running GUI software is possible and there are resources describing how to archieve this via VcXsrv (see chapter in [this post](https://dev.to/darksmile92/run-gui-app-in-linux-docker-container-on-windows-host-4kde#install-vcxsrv-and-configure-it) of mine).
|
||||
|
||||
But what if you:
|
||||
|
||||
## <a id="want-to-haveaccess-a-desktop-environment-on-wsl"></a>[](#want-to-haveaccess-a-desktop-environment-on-wsl)Want to have/access a Desktop environment on WSL?
|
||||
|
||||
You can use any Desktop Environment you want, I will be using [Xfce](https://www.xfce.org/) in this example because it is lightweight.
|
||||
|
||||
Here is the quick rundown of all commands and steps, explained in the sections below. One is for Kali Linux, the other is for the Debian based distros (Debian, Ubuntu, ...).
|
||||
|
||||
For Kali:
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt -y upgrade
|
||||
sudo apt -y install kali-desktop-xfce
|
||||
sudo apt-get install xrdp
|
||||
sudo cp /etc/xrdp/xrdp.ini /etc/xrdp/xrdp.ini.bak
|
||||
sudo sed -i 's/3389/3390/g' /etc/xrdp/xrdp.ini
|
||||
sudo sed -i 's/max_bpp=32/#max_bpp=32\nmax_bpp=128/g' /etc/xrdp/xrdp.ini
|
||||
sudo sed -i 's/xserverbpp=24/#xserverbpp=24\nxserverbpp=128/g' /etc/xrdp/xrdp.ini
|
||||
sudo /etc/init.d/xrdp start
|
||||
```
|
||||
|
||||
Enter fullscreen mode Exit fullscreen mode
|
||||
|
||||
For other debian based distros:
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt -y upgrade
|
||||
sudo apt -y install xfce4
|
||||
sudo apt-get install xrdp
|
||||
sudo cp /etc/xrdp/xrdp.ini /etc/xrdp/xrdp.ini.bak
|
||||
sudo sed -i 's/3389/3390/g' /etc/xrdp/xrdp.ini
|
||||
sudo sed -i 's/max_bpp=32/#max_bpp=32\nmax_bpp=128/g' /etc/xrdp/xrdp.ini
|
||||
sudo sed -i 's/xserverbpp=24/#xserverbpp=24\nxserverbpp=128/g' /etc/xrdp/xrdp.ini
|
||||
sudo /etc/init.d/xrdp start
|
||||
```
|
||||
|
||||
Enter fullscreen mode Exit fullscreen mode
|
||||
|
||||
And then connect via RDP `localhost:3390` to your desktop.
|
||||
|
||||
[](https://res.cloudinary.com/practicaldev/image/fetch/s--Zuom5SHX--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws.com/i/ho6kk30r5w1azj1pgvfv.png)
|
||||
|
||||
[](https://res.cloudinary.com/practicaldev/image/fetch/s--IfG4_oat--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws.com/i/nuteksr5x3tbmewsic7s.png)
|
||||
|
||||
### <a id="detailed-steps"></a>[](#detailed-steps)Detailed steps
|
||||
|
||||
#### <a id="updating-the-system-and-installing-xfce4"></a>[](#updating-the-system-and-installing-xfce4)Updating the system and installing Xfce4
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt -y upgrade
|
||||
```
|
||||
|
||||
Enter fullscreen mode Exit fullscreen mode
|
||||
|
||||
```
|
||||
sudo apt -y install kali-desktop-xfce
|
||||
```
|
||||
|
||||
Enter fullscreen mode Exit fullscreen mode
|
||||
|
||||
```
|
||||
sudo apt -y install xfce4
|
||||
```
|
||||
|
||||
Enter fullscreen mode Exit fullscreen mode
|
||||
|
||||
The first command updates the source list and the packages. Always important, I will not explain this.
|
||||
The `sudo apt -y install kali-desktop-xfce` installs a Kali Linux specific version of Xfce4 and `sudo apt -y install xfce4` will install the Xfce4 package for debian based distros.
|
||||
|
||||
#### <a id="installing-xrdp"></a>[](#installing-xrdp)Installing Xrdp
|
||||
|
||||
```
|
||||
sudo apt-get install xrdp
|
||||
```
|
||||
|
||||
Enter fullscreen mode Exit fullscreen mode
|
||||
|
||||
[Xrdp](http://www.xrdp.org/) is an open source remote desktop solution and also very lightweight and easy to configure. This command will install the package and setup the default configuration with port 3389.
|
||||
|
||||
#### <a id="configuring-xrdp"></a>[](#configuring-xrdp)Configuring Xrdp
|
||||
|
||||
```
|
||||
sudo cp /etc/xrdp/xrdp.ini /etc/xrdp/xrdp.ini.bak
|
||||
sudo sed -i 's/3389/3390/g' /etc/xrdp/xrdp.ini
|
||||
sudo sed -i 's/max_bpp=32/#max_bpp=32\nmax_bpp=128/g' /etc/xrdp/xrdp.ini
|
||||
sudo sed -i 's/xserverbpp=24/#xserverbpp=24\nxserverbpp=128/g' /etc/xrdp/xrdp.ini
|
||||
sudo /etc/init.d/xrdp start
|
||||
```
|
||||
|
||||
Enter fullscreen mode Exit fullscreen mode
|
||||
|
||||
Copy the config file as backup before the changes, change the port from 3389 to 3390 and for quality reasons increase the bpp from 24 to 128. You can play with those settings but since this is a local connection, the speed should not be worse with those settings.
|
||||
And finally restarting the xrdp service to apply the changes.
|
||||
|
||||
Now you can connect via `localhost:3390` and the credentials of your WSL account via RDP! 💪
|
||||
|
||||
[<img width="678" height="382" src="../../_resources/3qds38rrmzc6kaya8mym_c536d7d3c9654773b4ad923186f56.png"/>](https://res.cloudinary.com/practicaldev/image/fetch/s--oBRJbOXY--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws.com/i/3qds38rrmzc6kaya8mym.png)
|
||||
|
||||
###### <a id="why-the-port-change-from-3389-to-3390"></a>[](#why-the-port-change-from-3389-to-3390)Why the port change from 3389 to 3390?
|
||||
|
||||
Two reasons: security and sometimes port 3389 is used by a process on wsl and you get the message
|
||||
|
||||
> `Your computer could not connect to another console session on the remote computer because you already have a console session in progress.`
|
||||
|
||||
#### <a id="benefits-of-rdp-here"></a>[](#benefits-of-rdp-here)Benefits of RDP here
|
||||
|
||||
Even though you can run GUI software via XServer in a window, sometimes it is more convenient to have the full desktop environment accessible.
|
||||
Also you can restore a previously disconnected session easily and do not have to close the console (let processes running for example).
|
||||
|
||||
Let me know your thoughts on this topic!
|
||||
@@ -1,17 +0,0 @@
|
||||
---
|
||||
title: Löschen von Diensten unter Windows 10
|
||||
tags:
|
||||
- IT/Development/Powershell
|
||||
- IT/OS/Windows
|
||||
---
|
||||
|
||||
Auflisten der Dienste aus der Powershell:
|
||||
```powershell
|
||||
Get-WmiObject win32_service | Select Name, Displayname, State, Startmode | Sort Name
|
||||
```
|
||||
|
||||
Entfernen der Dienste:
|
||||
Aufruf der Konsole als Administrator
|
||||
```powershell
|
||||
sc delete <SERVICENAME>
|
||||
```
|
||||
@@ -1,10 +0,0 @@
|
||||
---
|
||||
title: Mac tips
|
||||
---
|
||||
|
||||
http://docs.brew.sh/Installation.html
|
||||
https://support.office.com/en-us/article/Keyboard-shortcuts-for-Outlook-for-Mac-07ae68c8-b7af-4010-b225-324c04ac7335
|
||||
[Mac keyboard shortcuts - Apple Support](https://support.apple.com/en-us/HT201236)
|
||||
[MacBook All-in-One For Dummies Cheat Sheet - dummies](http://www.dummies.com/computers/macs/macbook/macbook-all-in-one-for-dummies-cheat-sheet/)
|
||||
[Dan Rodney's List of Mac Keyboard Shortcuts & Keystrokes](https://www.danrodney.com/mac/)
|
||||
[Top 10 Mac keyboard shortcuts everyone should know](https://www.cultofmac.com/317935/top-10-mac-keyboard-shortcuts/)
|
||||
@@ -1,6 +0,0 @@
|
||||
---
|
||||
title: Managing your profile README - GitHub Docs
|
||||
source: https://docs.github.com/en/account-and-profile/setting-up-and-managing-your-github-profile/customizing-your-profile/managing-your-profile-readme
|
||||
---
|
||||
|
||||
https://docs.github.com/en/account-and-profile/setting-up-and-managing-your-github-profile/customizing-your-profile/managing-your-profile-readme
|
||||
-97
@@ -1,97 +0,0 @@
|
||||
---
|
||||
title: "Modulare Dokumentationen: Wie man sie baut und warum sie die Teamarbeit erleichtern"
|
||||
source: https://entwickler.de/software-architektur/modulare-dokumentationen-wie-man-sie-baut-und-warum-sie-die-teamarbeit-erleichtern/
|
||||
tags:
|
||||
- IT/Development/Asciidoctor
|
||||
- IT/Dokumentation
|
||||
---
|
||||
|
||||
In der letzten Ausgabe haben wir gezeigt, wie Sie mithilfe von AsciiDoc schnell zu ordentlich gestalteten Dokumenten kommen können. In der zweiten Folge unserer Kolumne möchten wir Ihnen Strukturierung und Modularisierung von Dokumentation vorstellen, einerseits zur Erleichterung von Teamarbeit, andererseits zur Verwendung einzelner Dokuteile für verschiedene Zielgruppen.
|
||||
|
||||
Im Gegensatz zu anderen Markup-Sprachen verfügt AsciiDoc über ein mächtiges Konzept zur Modularisierung: den Befehl *include::path\[attributes\]*. Damit können Sie Ihre Dokumentation auf mehrere Dateien aufteilen. Das erleichtert die Teamarbeit und verbessert die Übersichtlichkeit. Beispielsweise kann ein Masterdokument Verweise auf Unterdokumente erhalten (Listing 1). Darin inkludieren wir zwei AsciiDoc-Dateien (*kapitel-1.adoc* und *kapitel-2.adoc*).
|
||||
|
||||
**Listing 1: „master.adoc“**
|
||||
|
||||
```
|
||||
:source-highlighter: coderay
|
||||
:imagesdir: images
|
||||
|
||||
== Dies ist das Hauptdokument
|
||||
|
||||
Durch verschiedene `include`-Anweisungen modularisieren wir die Dokumentation:
|
||||
|
||||
include::kapitel/kapitel-1.adoc[leveloffset=+1]
|
||||
|
||||
include::kapitel/kapitel-2.adoc[leveloffset=+1]
|
||||
```
|
||||
|
||||
**Listing 2: „kapitel1.adoc“**
|
||||
|
||||
```
|
||||
== Kapitel 1: Übersicht
|
||||
|
||||
Eine Übersicht ist immer nützlich...
|
||||
|
||||
.Module unserer Dokumentation
|
||||
image::uebersicht.png[]
|
||||
```
|
||||
|
||||
**Listing 3: „kapitel2.adoc“**
|
||||
|
||||
```
|
||||
== Kapitel 2: Schnittstellen
|
||||
|
||||
include::{sourcedir}SampleInterface.java[tag=signatur]
|
||||
```
|
||||
|
||||
Wie üblich übersetzen wir unsere Dokumente mit Gradle:
|
||||
|
||||
```
|
||||
> cd folge-2
|
||||
> gradle asciidoctor
|
||||
```
|
||||
|
||||
Der AsciiDoc-Prozessor erzeugt im Verzeichnis *build/asciidoc/html5/* das passende HTML (**Abb. 1**). Dabei wurde einerseits das HTML-Dokument erzeugt und zusätzlich noch das referenzierte Diagramm in das *build*-Verzeichnis kopiert. Hierzu nutzen wir wieder eine Standardeinstellung des Asciidoctor-Plug-ins für Gradle: alle Dateien aus dem *images*-Verzeichnis werden automatisch in das *build*-Verzeichnis kopiert. Es bietet sich an, die Teile der Dokumentation wie im Beispiel mit dem eigentlichen Inhalt in Unterverzeichnisse zu legen. Dadurch ist das strukturierende Masterdokument sauber vom eigentlichen Inhalt getrennt. Auch das im AsciiDoc-Format vorliegende [arc42-Template](https://github.com/arc42/arc42-template) ist in dieser Struktur aufgebaut.
|
||||
|
||||
[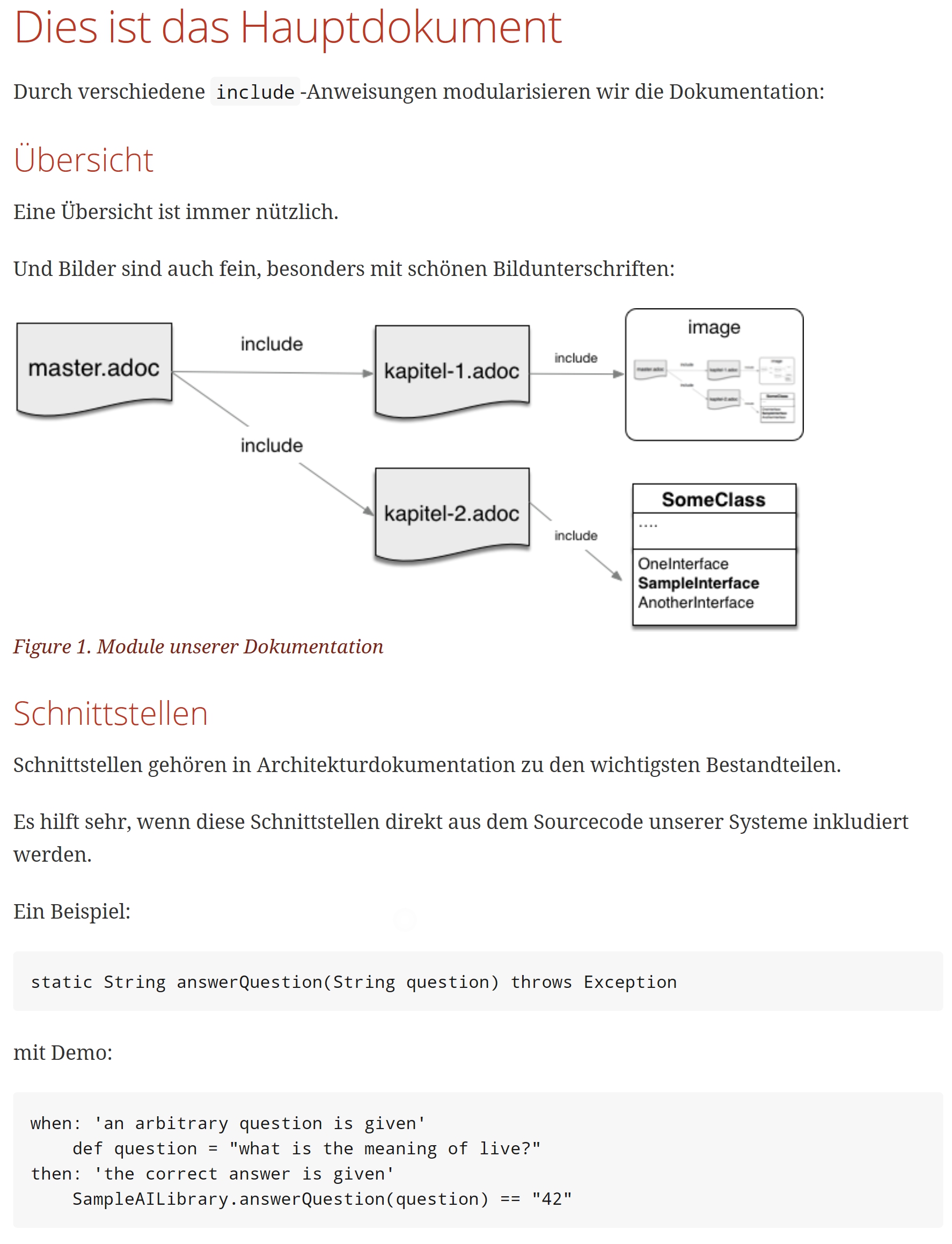](https://jaxenter.de/wp-content/uploads/2017/11/mueller_starke_hhgdac_1.jpg)
|
||||
|
||||
Abb.1: HTML-Ausgabe des modularisierten Dokuments
|
||||
|
||||
**Listing 4: „SampleAILibrary.java“**
|
||||
|
||||
```
|
||||
package demo;
|
||||
|
||||
class SampleAILibrary {
|
||||
|
||||
// beantwortet alle Fragen
|
||||
|
||||
// tag::signatur[]
|
||||
static String answerQuestion(String question) throws Exception
|
||||
//end::signatur[] {
|
||||
if (question==null) {
|
||||
//...
|
||||
```
|
||||
|
||||
## Sourcecode einbinden
|
||||
|
||||
AsciiDoc kann auch andere Dateiformate einbinden, z. B. Sourcecode (Listing 3), wobei wir auch einzelne Fragmente aus den Sourcen in die Dokumentation einbinden können. Dazu können Sie im Sourcecode Kommentare mit einer einfachen Tag-Syntax verwenden (Listing 4). Markus Schlichting schlägt vor, den [inkludierten Code immer in einen automatisierten Test einzubetten](https://www.mynethome.de/content/Markus-Schlichting-Lebendige-Dokumentation-mit-AsciiDoctor.pdf). Dadurch können Sie die Erstellung aktueller Dokumentation vom Testergebnis des referenzierten Codes abhängig machen und stellen sicher, dass alle Beispiele in der Dokumentation stimmen. Cool, oder? Führt man den Gedanken weiter, lassen sich über die Tests auch Antworten von REST-Services erzeugen, die dann in die aktuelle Dokumentation einfließen.
|
||||
|
||||
Ein Hinweis: Der Pfad zu Bildern wird immer über das Attribut *imagesdir* relativ zum Hauptdokument aufgelöst, wohingegen der Pfad zu Dokumenten `include::` relativ zum aktuell eingebetteten Dokument aufgelöst wird. Das ist bei verschachtelten Dokumenten praktisch, nicht aber bei der Referenzierung von Sourcecode. Hier bietet es sich an, im Build-File ein *sourcedir*-Attribut mit dem entsprechenden absoluten Pfad zu setzen und dann wie in Listing 3 zu referenzieren.
|
||||
|
||||
## Stakeholderspezifische Dokumentation
|
||||
|
||||
Unterschiedliche Projektteilnehmer benötigen oft nur einen spezifischen Teil der Dokumentation. Allerdings gibt es Überschneidungen, z. B. eine kurze Einführung in das Projekt. Solche stakeholderspezifischen Dokumente lassen sich nun leicht generieren. Man erzeugt einfach weitere Masterdokumente, bindet jedoch unterschiedlichen Inhalt ein oder ändert die Reihenfolge von Kapiteln. Dabei kann es passieren, dass ein Kapitel, das in der Hauptdokumentation auf erster Ebene erscheint, in einem anderen Dokument in der Gliederung auf zweiter oder dritter Ebene ist. Dann müssen wir Überschriftenebenen korrigieren. AsciiDoc bietet dafür eine elegante und einfache Lösung an: Über das Attribut *levelOffset* der *include*-Anweisung lassen sich die Überschriftenebenen korrigieren.
|
||||
|
||||
Damit Sie nicht ständig überlegen müssen, mit welcher Überschriftebene ein Unterdokument beginnt, können Sie jedes Unterdokument einheitlich mit Überschriftenebene 1 beginnen und eine entsprechende Korrektur beim Einbinden in andere Dokumente vornehmen (Listing 1). Auf diese Weise funktioniert Modularisierung auch in großem Stil: Das [VENOM-Beispiel](https://github.com/aim42/venom-example) (**Abb. 2**) zeigt das: Zwei Hauptdokumente (Architektur- und Businessdokumentation, insgesamt deutlich über hundert Druckseiten) werden aus mehr als zwanzig einzelnen Teilen über *include*-Statements verwaltet.
|
||||
|
||||
[](https://jaxenter.de/wp-content/uploads/2017/11/mueller_starke_hhgdac_2.jpg)
|
||||
|
||||
Abb. 2: Übersicht der modularen VENOM-Dokumentation
|
||||
|
||||
**Tipp: Bildverweise in Unterdokumenten**
|
||||
Über *:imagesDir::<verzeichnis> *teilt man asciidoctorj mit, wo die zu referenzierenden Bilder liegen. Das Verzeichnis wird relativ im Hauptdokument angegeben. Wird ein Unterdokument im Editor geöffnet, kennt dieser nicht den korrekten Verzeichnispfad und hat keine Chance, die Bilder anzuzeigen. Es sei denn, man hilft ihm mit folgender Anweisung: *ifndef::imagesdir\[:imagesdir: ../images\]*. Die Generierung über das Hauptdokument wird dadurch nicht geändert. Ein Editor kann somit aber auch die Bilder in Unterdokumenten anzeigen.
|
||||
|
||||
## Fazit
|
||||
|
||||
Modularisierung der Dokumente vereinfacht die Zusammenarbeit im Team und ermöglicht das Wiederverwenden einzelner Fragmente in verschiedenen Kontexten. Sie können das Erstellen der Dokumentation vom Ergebnis automatisierter Tests einzelner Codefragmenten abhängig machen und damit die Aktualität Ihrer Dokumentation verbessern. Die Sourcen unseres leicht gewachsenen Beispiels liegen wieder in unserem [GitHub-Repo](https://github.com/arc42/HHGDAC). Mit dem Docs-as-Code-Ansatz geht es aber noch weiter. In der nächsten Folge zeigen wir, wie Sie unterschiedliche Ausgabeformate erzeugen können (HTML, PDF, docx, Confluence) und welche Vor- und Nachteile sich dabei ergeben. Bis dahin: Happy Docu-Coding!
|
||||
@@ -1,6 +0,0 @@
|
||||
---
|
||||
title: Multiple accounts with Mutt E-Mail Client (gmail example) · GitHub
|
||||
source: https://gist.github.com/miguelmota/9456162
|
||||
---
|
||||
|
||||
https://gist.github.com/miguelmota/9456162
|
||||
@@ -1,6 +0,0 @@
|
||||
---
|
||||
title: Mutt - ArchWiki
|
||||
source: https://wiki.archlinux.org/title/Mutt
|
||||
---
|
||||
|
||||
https://wiki.archlinux.org/title/Mutt
|
||||
@@ -1,58 +0,0 @@
|
||||
---
|
||||
title: Optional Parameters in Go?
|
||||
source: https://stackoverflow.com/questions/2032149/optional-parameters-in-go
|
||||
tags:
|
||||
- IT/Development/Go
|
||||
---
|
||||
|
||||
For arbitrary, potentially large number of optional parameters, a nice idiom is to use **Functional options**.
|
||||
|
||||
For your type `Foobar`, first write only one constructor:
|
||||
|
||||
```go
|
||||
func NewFoobar(options ...func(*Foobar) error) (*Foobar, error){
|
||||
fb := &Foobar{}
|
||||
// ... (write initializations with default values)...
|
||||
for _, op := range options{
|
||||
err := op(fb)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
}
|
||||
return fb, nil
|
||||
}
|
||||
```
|
||||
|
||||
where each option is a function which mutates the Foobar. Then provide convenient ways for your user to use or create standard options, for example :
|
||||
|
||||
```go
|
||||
func OptionReadonlyFlag(fb *Foobar) error {
|
||||
fb.mutable = false
|
||||
return nil
|
||||
}
|
||||
|
||||
func OptionTemperature(t Celsius) func(*Foobar) error {
|
||||
return func(fb *Foobar) error {
|
||||
fb.temperature = t
|
||||
return nil
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
[Playground](http://play.golang.org/p/3HB9KJ7m2D)
|
||||
|
||||
For conciseness, you may give a name to the type of the options ([Playground](http://play.golang.org/p/il93GYGtFL)) :
|
||||
|
||||
```go
|
||||
type OptionFoobar func(*Foobar) error
|
||||
```
|
||||
|
||||
If you need mandatory parameters, add them as first arguments of the constructor before the variadic `options`.
|
||||
|
||||
The main benefits of the _Functional options_ idiom are :
|
||||
|
||||
* your API can grow over time without breaking existing code, because the constuctor signature stays the same when new options are needed.
|
||||
* it enables the default use case to be its simplest: no arguments at all!
|
||||
* it provides fine control over the initialization of complex values.
|
||||
|
||||
This technique was coined by [Rob Pike](https://commandcenter.blogspot.fr/2014/01/self-referential-functions-and-design.html) and also demonstrated by [Dave Cheney](https://dave.cheney.net/2014/10/17/functional-options-for-friendly-apis).
|
||||
@@ -1,6 +0,0 @@
|
||||
---
|
||||
title: Page Category Keys | Asciidoctor Docs
|
||||
source: https://docs.asciidoctor.org/pdf-converter/latest/theme/page/
|
||||
---
|
||||
|
||||
https://docs.asciidoctor.org/pdf-converter/latest/theme/page/
|
||||
@@ -1,32 +0,0 @@
|
||||
---
|
||||
title: Parsen der Argumente in einem Shell-Skript
|
||||
latitude: 50.7912
|
||||
longitude: 6.06267
|
||||
altitude: 0
|
||||
tags:
|
||||
- IT/Shell
|
||||
---
|
||||
|
||||
Parsen der Argumente in einem Shell-Skript
|
||||
|
||||
```shell
|
||||
while [ "$#" -gt 0 ]
|
||||
do
|
||||
case "$1" in
|
||||
-option1)
|
||||
echo "option 1"
|
||||
;;
|
||||
-option2)
|
||||
echo "option 2"
|
||||
if [ -n "$2" ] && [ "$2" == `echo "$2" | sed 's/-//'` ]; then
|
||||
OPTION2 = $2
|
||||
shift
|
||||
fi
|
||||
;;
|
||||
*)
|
||||
OPTS = "$OPTS '$1'"
|
||||
;;
|
||||
ecase
|
||||
shift
|
||||
done
|
||||
```
|
||||
@@ -1,139 +0,0 @@
|
||||
---
|
||||
title: Perl Einzeiler
|
||||
tags:
|
||||
- IT/Development/Perl
|
||||
---
|
||||
|
||||
# Hilfreiche Perl-Einzeiler für Unix und Windows
|
||||
Michael Schilli
|
||||
|
||||
## Aufmacher
|
||||
|
||||
Statt unleserliche Wunderwerke zu erzeugen - wie im regelmäßig stattfindenden Obfuscated Perl Contest - kann man mit Perl-Einzeilern auch flott Alltagsprogrammierjobs erledigen. Es folgt eine Sammlung der wichtigsten, die man immer im Handgepäck haben sollte.
|
||||
|
||||
Perl-Skripts müssen nicht in einer Datei stehen. Der Interpreter verarbeitet auch mit der Option -e hereingereichte Strings. Um zum Beispiel 61 000 DM Jahresgehalt mal schnell durch 12 zu teilen, reicht die Eingabe
|
||||
```shell
|
||||
perl -l -e 'print 61000 / 12'
|
||||
```
|
||||
|
||||
und Perl rechnet fließkommagenau 5083.33333333333 aus. Zu beachten ist bei solchen Aufrufen von der Kommandozeile, daß der auszuführende Code in Unix-Shells in einfachen Anführungszeichen steht (sonst expandiert die Shell Sonderzeichen wie * und $), der Command-Interpreter unter Windows 95 und NT jedoch doppelte Anführungszeichen verlangt. Die vorangestellte Option -l dient hier nur dazu, hinter das Ergebnis ein Newline-Zeichen einzufügen.
|
||||
grep, awk und sed in einem
|
||||
|
||||
Perls Stärke ist zweifellos die Manipulation von Texten, und so steht mit -n eine Option zur Verfügung, mit der sich auf der Kommandozeile angegebene (oder durch die Standardeingabe hereinkommende) Dateien bearbeiten lassen:
|
||||
```shell
|
||||
perl -n -e 'print $_ if /mschilli/' /etc/passwd
|
||||
cat /etc/passwd | perl -n -e "print $_ if /mschilli/"
|
||||
```
|
||||
|
||||
Beide Befehle sehen nach, ob in der Unix-Paßwortdatei irgendwo der String 'mschilli' vorkommt, und geben passende Zeilen aus. Intern wickelt der Perl-Interpreter bei gesetzter Option -n nämlich eine while-Schleife um den angegebenen Kommandostring, die entweder auf der Kommandozeile angegebene Dateien oder den Datenstrom der Standardeingabe zeilenweise abarbeitet:
|
||||
```perl
|
||||
while (<>) {
|
||||
print $_ if /mschilli/;
|
||||
}
|
||||
```
|
||||
|
||||
Da die Paßwortdatei bekanntlich Einträge vom Format
|
||||
|
||||
`mschilli:8KYD6mggn4tsI:501:100:Michael Schilli:/home/mschilli:/bin/bash`
|
||||
|
||||
enthält, wäre es angebracht, die durch Doppelpunkte getrennten Einzelfelder gesondert zu untersuchen. Bei gesetzter Option -a zerlegt Perl die Felder der hereinkommenden Zeilen in die Elemente eines Array mit dem Spezialnamen @F, wobei es den in der -F-Option gesetzten Feldtrenner benutzt, oder, falls diese fehlt, an Leerzeichen oder Tabulatoren trennt. Die Benutzerkürzel, also die ersten Felder der Paßwortdateieinträge spuckt somit die Konstruktion
|
||||
```shell
|
||||
perl -l -a -F: -n -e 'print $F[0]' /etc/passwd
|
||||
```
|
||||
|
||||
aus. Daraus läßt sich eine hilfreiche Anwendung ableiten: Das dritte Feld des Paßworteintrags enthält die im System eindeutige Benutzernummer. Möchte der Administrator einen Account für einen neuen Benutzer einrichten, sucht er - falls er, wie alle 'echten' Sysadmins, ohne GUI-Schnickschnack arbeitet - nach der nächsten, noch unbenutzten Nummer. Da Perl wie der gute alte awk ein END-Konstrukt bietet, dessen Inhalt der Interpreter nach der impliziten -n-Schleife ausführt, findet folgendes Konstrukt die gesuchte Nummer:
|
||||
```shell
|
||||
perl -l -n -a -F: -e '$high = $F[2] if $F[2] > $high;
|
||||
END {print $high+1}' /etc/passwd
|
||||
```
|
||||
|
||||
Zeile für Zeile durchsucht dieses Skript die Paßwortdatei und setzt $high gleich der aktuellen Benutzernummer im dritten Feld, falls diese größer als der bislang gespeicherte Wert ist. So steht am Ende der Datei die höchste vergebene Benutzernummer in $high. Anschließend kommt der Code im END-Konstrukt zur Ausführung und gibt eine um eins größere Zahl aus.
|
||||
|
||||
## Dateien automatisch editieren
|
||||
|
||||
Damit Perl bei solchen impliziten Schleifen die jeweils bearbeitete Zeile automatisch ausgibt, muß statt -n die Option -p stehen. Dies hilft beim Suchen und Ersetzen von Textstücken:
|
||||
```shell
|
||||
perl -p -e 's/a/b/g' datei
|
||||
```
|
||||
|
||||
ersetzt in datei alle 'a' durch 'b' und gibt den modifizierten Inhalt auf der Standardausgabe aus. Um den Inhalt der Datei selbst zu verändern, muß die -i-Option (für in-place-edit) herhalten: Der Aufruf
|
||||
```shell
|
||||
perl -p -i.bak -e 's/a/b/g' datei
|
||||
```
|
||||
|
||||
sichert zunächst für alle Fälle datei nach datei.bak und führt anschließend die Zeichenersetzung in datei selbst durch. Das obige Kommando funktioniert auch für mehrere Dateien gleichzeitig:
|
||||
```shell
|
||||
perl -p -i.bak -e 's/\bprintf\b/myprintf/g' *.c
|
||||
```
|
||||
|
||||
ersetzt unter Unix, wo die Shell *.c zu einer Reihe von Dateinamen expandiert, in allen C-Dateien im gegenwärtigen Verzeichnis sämtliche Aufrufe von printf (Wortgrenzen links und rechts) durch eine neue Funktion myprintf und sichert gleichzeitig die alten Dateien nach *.c.bak. Kommt ein Kurzskript nicht mit dem Funktionsumfang der Standard-Perl-Bibliothek aus, sondern benötigt Zusatzmodule, veranlaßt die Option -M den Interpreter, die angegebenen Module einzubinden. Somit steht Einzeilern die Welt offen: Das praktische Modul LWP::Simple aus der Programmsammlung libwww beispielweise gewährt einfachen Zugriff auf das World Wide Web:
|
||||
```shell
|
||||
perl -MLWP::Simple -e 'getprint("http://www.aol.com")'
|
||||
```
|
||||
|
||||
holt den Inhalt der Web-Seite http://www.aol.com vom Netz und gibt ihn auf der Standardausgabe aus. Zu beachten ist jedoch, daß LWP::Simple nur einfache Web-Zugriffe beherrscht, Redirects sind nicht im Funktionsumfang enthalten. Verweist ein angegebener URL statt auf eine Datei auf ein Verzeichnis auf dem Zielrechner, vollführen moderne Browser einen Redirect, aus <A HREF="http://www.aol.com/">http://www.aol.com/netfind</A> wird so flugs <A HREF="http://www.aol.com/netfind/">http://www.aol.com/netfind/</A>, und nur der zweite URL ist für LWP::Simple geeignet.
|
||||
|
||||
Um den Inhalt einer Web-Seite nicht nur auszugeben, sondern gleich wegzuschreiben, hilft das Konstrukt
|
||||
```shell
|
||||
perl -MLWP::Simple -e 'getstore("http://www.aol.com", "aol.html")'
|
||||
```
|
||||
|
||||
Es speichert die geholte Information gleich in der Datei aol.html auf der lokalen Festplatte. Schon kein richtiger Einzeiler mehr, aber dennoch ganz praktisch ist
|
||||
```shell
|
||||
cat aol.html | \
|
||||
perl -MHTML::TreeBuilder -e \
|
||||
'print map {"$_->[0]\n" }\
|
||||
@{HTML::TreeBuilder->new->parse_file(\*STDIN)->\
|
||||
extract_links}'
|
||||
```
|
||||
|
||||
Es extrahiert alle Hyperlinks aus dem per cat weitergereichten HTML-Dokument. Wie? Nun, das ist etwas komplizierter: Das erzeugte Objekt vom Typ HTML::TreeBuilder ruft seine parse_file-Methode mit einer Glob-Referenz des Standardeingabedeskriptors (\*STDIN) auf. Dadurch erstellt es ein HTML::Parser-Objekt, dessen Methode extract_links eine Referenz auf ein Array zurückgibt. Dieses besteht wiederum aus Array-Referenzen, die als erstes Element den Linknamen enthalten. Die Funktion map nimmt einen Codeblock und eine Liste entgegen, ruft für jedes Element der Liste den Codeblock auf (wobei der Wert des aktuell bearbeiteten Elements in der Spezialvariablen $_ liegt) und setzt dessen Rückgabewert in die Ergebnisliste ein. Nachdem das Skript also die von extract_links gelieferte Array-Referenz mit dem Konstrukt @{...} in ein Array verwandelt hat, steht im Codeblock mit $_ eine Referenz auf das Unter-Array zur Verfügung. $_->[0] extrahiert dessen erstes Element.
|
||||
|
||||
## Kopieren und Verschieben à la Unix
|
||||
|
||||
File::Copy schließlich erlaubt das Verschieben und Kopieren von Dateien im Unix-Look&Feel: Die Funktionen move und copy nehmen als zweiten Parameter auch ein Verzeichnis, in das sie die als ersten Parameter spezifizierte Datei verschieben beziehungsweise kopieren. Windows-Benutzer werden folgendes zu schätzen wissen:
|
||||
```shell
|
||||
perl -MFile::Copy -e 'for(<*.c>) {copy $_, "/backups"}'
|
||||
```
|
||||
|
||||
kopiert alle *.c-Dateien im gegenwärtigen Verzeichnis ins Verzeichnis /backups, falls dieses existiert. Die for-Schleife iteriert mit dem File-Globbing-Konstrukt über alle *.c-Dateien und setzt für den Schleifenrumpf $_ auf die aktuelle Datei. Da die Windows-Version des Perl-Interpreters dankenswerterweise auch Unix-Pfadnamen versteht, entspricht /backups in Perl dem Windows-Pfad \BACKUPS, im Normalfall also C:\BACKUPS.
|
||||
|
||||
Alle Dateien im Verzeichnis test, die seit einer Woche nicht modifiziert wurden, verschiebt (diesmal wieder in der Schreibweise für Unix-Shells)
|
||||
```shell
|
||||
perl -MFile::Copy -e 'for(<test/*>) \
|
||||
{move($_, "test.old") if -M > 7}'
|
||||
```
|
||||
|
||||
ins Verzeichnis test.old. Alles, was dort älter als drei Wochen ist, löscht
|
||||
```shell
|
||||
perl -e 'for(<test.old/*>) {unlink $_ if -M > 21}'
|
||||
```
|
||||
|
||||
kommentarlos.
|
||||
|
||||
## Uuencode und Base 64 entziffern
|
||||
|
||||
Für schnelles Dekodieren von uuencode- und Base64-kodierter Information stehen in Perl die unpack-Funktion sowie das Modul MIME::Base64 zur Verfügung.
|
||||
```shell
|
||||
perl -e 'print unpack("u", join("", <>))' data.uu
|
||||
```
|
||||
|
||||
entpackt die kodierte Information aus der Datei data.uu und leitet sie auf die Standardausgabe. Zu beachten ist jedoch, daß unpack nur die eigentlichen kodierten Daten verarbeitet, aus einer typischen UU-Datei, die zusätzlich noch den Namen der kodierten Datei und ein Ende-Tag im Format
|
||||
|
||||
`begin 644 data`
|
||||
`)2&D*:&D*:&D*`
|
||||
``
|
||||
`end`
|
||||
|
||||
enthält, sind vor der Bearbeitung die erste sowie die letzte Zeile zu entfernen. Die besonders in EMail verwendete Base64-Kodierung knackt das Zusatzmodul MIME::Base64. Der Einzeiler
|
||||
```shell
|
||||
perl -MMIME::Base64 -e 'print MIME::Base64::decode(join("", <>))' datafile
|
||||
```
|
||||
|
||||
gibt die dekodierten Base64-Daten in datafile auf die Standardausgabe aus, wobei - analog zur UU-Kodierung - darauf zu achten ist, daß in datafile nur der Base64-Buchstabensalat liegt, MIME-Header und die einleitende Sequenz, die unter anderem den Dateinamen festlegt, müssen vorher manuell entfernt werden.
|
||||
|
||||
Genug der Beispiele. Wer noch tiefer in die Syntax von Perls Kommandozeilenoptionen einsteigen will, dem sei die Manual-Seite empfohlen, die auf das Kommando perldoc perlrun zum Vorschein kommt.
|
||||
|
||||
Michael Schilli
|
||||
|
||||
arbeitet als Web-Engineer für America Online, Inc., San Mateo. Er ist Autor des im Juni bei Addison-Wesley erscheinenden Buches 'GoTo Perl 5'.
|
||||
@@ -1,38 +0,0 @@
|
||||
---
|
||||
title: Plugin Architektur
|
||||
tags:
|
||||
- IT/Development/Java
|
||||
- IT/Development/Architektur
|
||||
---
|
||||
|
||||
|
||||
|
||||
class PluginLink
|
||||
```java
|
||||
public PluginLink() { loader = new Classloader(); }
|
||||
public init() {
|
||||
Class clazz = loader.loadClass(strPluginClass);
|
||||
Object newInstance = clazz.newInstance();
|
||||
Plugin plugin = (Plugin)instance;
|
||||
plugin.init(this);
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
interface Plugin
|
||||
|
||||
destroy();
|
||||
init(PluginLink);
|
||||
getName();
|
||||
getDescription();
|
||||
```
|
||||
|
||||
|
||||
```java
|
||||
class PluginTest
|
||||
|
||||
addMenuItem
|
||||
addMenuAction(Action);
|
||||
getVersion();
|
||||
getParentFrame();
|
||||
```
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user